无需API Key,7大平台免费搜索30天数据:last30days-cn v2.0 完全指南
“配置 API Key 实在太麻烦了,完全弄不好。”
仔细想想,这个痛点确实很真实。v1.0 版本覆盖了 8 个平台,其中有 4 个必须提前申请 API Key 才能正常使用:
微博 → 要去开放平台申请 OAuth Token
小红书 → 要注册第三方服务 ScrapeCreators
抖音 → 要注册 TikHub
微信 → 要找第三方 API
每个平台的申请流程各不相同,有的需要等待审核,有的则直接要求付费。一个原本用来快速搜索信息的工具,光环境配置就已经劝退了将近一半的用户。
这样的情况肯定不行,必须要彻底改变。
01 使用方式澄清:你几乎不用动手
很多读者看完前两篇文章之后产生了一个误解:以为需要自己一步一步手动敲命令来操作。
其实完全不是这样。
这个项目本质上是一个 AI Agent 技能(Skill)。你不需要去关心底层怎么实现,只要把它安装到你常用的 AI 工具里,AI 就会自动去调用它。
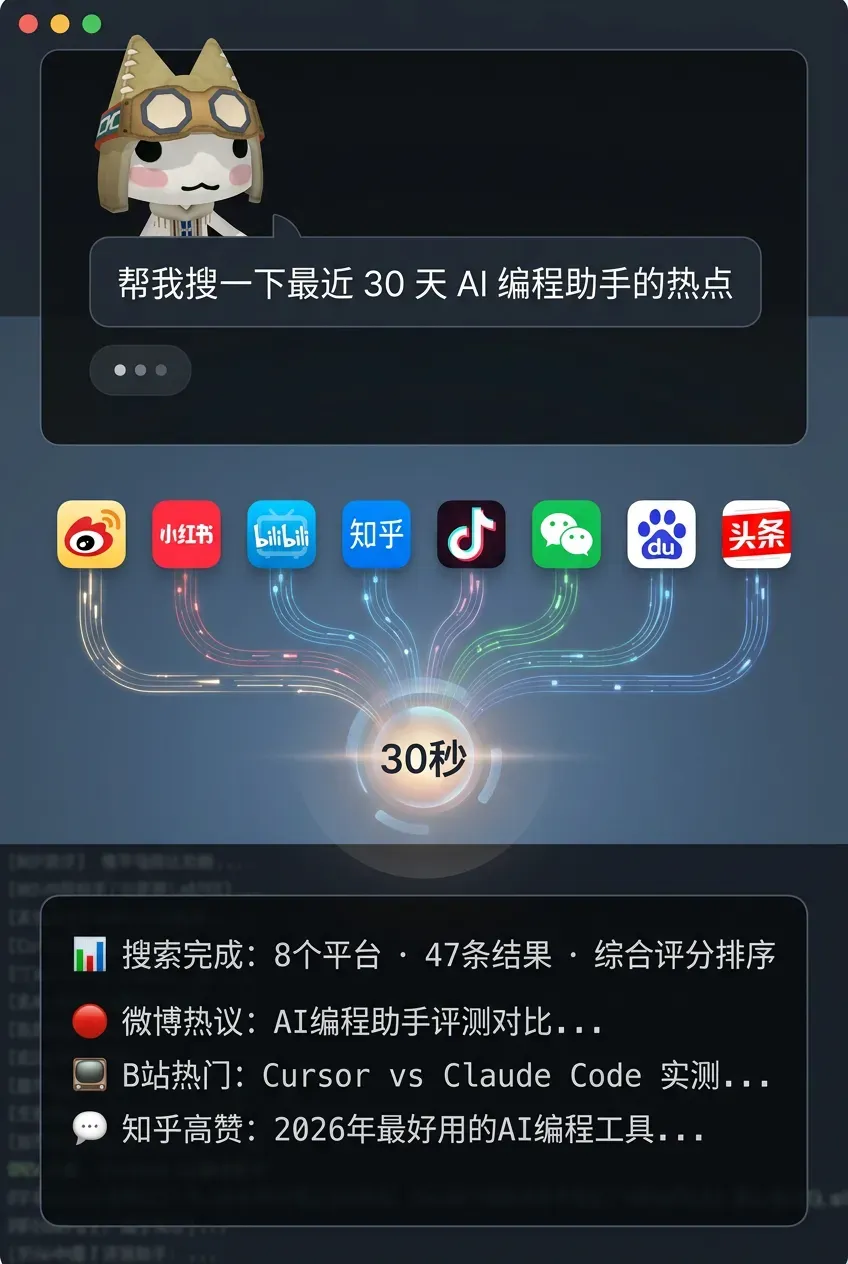
这就好比你在手机上装了一个 App。你完全不必知道 App 内部的代码是怎么写的,只需要对它说“帮我搜一下最近 AI 编程的热点”,AI 就会自动在 8 个平台上搜索、归纳分析,然后生成一份结构化的报告。
你要做的,仅仅是复制一行安装命令而已。
“帮我搜一下最近 30 天 AI 编程助手的热点”
装完就可以忘记它的存在,把剩下的工作全部交给 AI。
02 摆脱 API Key 的技术思路
在探索解决方案的过程中,我在 GitHub 上发现了一个非常巧妙的项目:NanmiCoder/MediaCrawler。
这个项目专门针对中文互联网平台进行数据采集,已经很好地支持了微博、小红书、抖音、B 站、知乎等主流站点。
它最核心的思路尤其聪明:
不去逆向解析加密算法,也不去破解接口签名,而是直接用 Playwright 驱动一个真实的浏览器。
具体来说:
传统爬虫的思路:分析接口 → 逆向加密 → 模拟请求 → 经常触发风控被封禁
MediaCrawler 的思路:打开浏览器 → 像真实用户一样操作 → 直接读取页面上的数据 → 极难被检测出来
一个是“努力假装成一个人”,另一个是“根本就是用人的方式在操作”。这两种思路在稳定性上完全不在同一个量级。
我把这个设计理念融入了 last30days-cn,实现了一个名为 crawler_bridge.py 的爬虫桥接模块。实现时并没有照搬 MediaCrawler 的代码,而是借鉴了它的架构思想,专门针对“多平台搜索”这一场景做了精简和适配。
03 v2.0 到底带来了哪些升级
用一句话来概括就是:从“必须有 Key 才能用”变成了“装好就能直接用”。

版本对比一目了然
| v1.0 | v2.0 | |
| 免配置即可使用的平台数量 | 4 个 | 7 个 |
| 需要 API Key 的平台 | 微博/小红书/抖音/微信 | 仅微信 |
| 数据获取方式 | API + 公开接口 | API + 爬虫引擎 + 公开接口 |
| 上手难度 | 需要逐个配置 API Key | 复制一行安装命令 |
| marketplace.json | 缺失 owner 字段,直接导致安装报错 | ✅ 已修复 |
04 三级降级策略:让每一次搜索都不会落空
这是 v2.0 当中我个人最满意的一项设计。
系统在搜索每一个平台时,会自动按以下三级策略依次尝试:
优先级 1: API 模式(仅在配置了 API Key 时启用)
↓ 调用失败或根本没有配置 Key
优先级 2: 爬虫模式(通过 Playwright 实现浏览器自动化)
↓ 调用失败或者 Playwright 未安装
优先级 3: 公开接口(直接发起 HTTP 请求,完全零配置)
这到底意味着什么?
无论你有没有配置 API Key、有没有安装 Playwright,只要让 AI 跑一次,就一定能把数据带回来。

用一个搜索“AI 编程”的例子来说明:
- 如果你配置了微博的 API Key → 系统会优先走 API,数据最完整;
- 如果没有配 Key,但电脑上已经装了 Playwright → 自动切换到爬虫模式,打开浏览器去搜索;
- 如果连 Playwright 也没有装 → 则自动使用公开的移动端接口,一样能成功搜到内容。
整个过程全自动推进,你完全不需要操心任何一个环节。
再来看一下各平台在不同模式下的覆盖情况:
| 平台 | API 模式 | 爬虫模式 | 公开接口 |
| 🔴 微博 | WEIBO_TOKEN | ✅ Playwright | ✅ m.weibo.cn |
| 📕 小红书 | SCRAPECREATORS | ✅ Playwright | ✅ 备用接口 |
| 📺 B 站 | — | ✅ Playwright 备用 | ✅ 公开 API |
| 💬 知乎 | ZHIHU_COOKIE | ✅ Playwright 备用 | ✅ 公开搜索 |
| 🎵 抖音 | TIKHUB_KEY | ✅ Playwright | ✅ 备用接口 |
| 💚 微信 | WECHAT_KEY | — | ✅ 搜狗搜索 |
| 🔵 百度 | BAIDU_KEY | — | ✅ 公开搜索 |
| 📰 头条 | — | — | ✅ 公开接口 |
8 个平台当中,有 7 个完全不需要你做任何配置就能开始搜索。唯一仍然要求 Key 的是微信公众号,这是因为公众号的搜索确实没有一个稳定、可用的公开入口。
05 爬虫桥接的核心实现细节
下面稍微展开一下技术层面的设计,方便感兴趣的同学深入了解。
5.1 Playwright 可用性检测
def is_playwright_available() -> bool:
global _playwright_available
if _playwright_available is not None:
return _playwright_available
try:
from playwright.sync_api import sync_playwright
_playwright_available = True
except ImportError:
_playwright_available = False
return _playwright_available
模块在第一次调用时检测 Playwright 是否可用,并把结果缓存起来。如果没有安装 Playwright,函数会直接返回 False,既不会抛出异常,也不会导致程序崩溃。
5.2 Cookie 持久化
登录一次之后,后续再次使用就不再需要重复登录:
~/.config/last30days-cn/browser_cookies/
├── weibo_cookies.json
├── xiaohongshu_cookies.json
├── douyin_cookies.json
└── ...
每次爬取任务完成后,系统会自动保存当前上下文中有效的 Cookie,下一次启动时则自动加载,模拟已登录状态。
5.3 浏览器资源管理
这次的质量加固特别关注了浏览器资源的回收问题。通过 try/finally 结构,确保无论中间发生什么错误,浏览器实例都一定能够被关闭:
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
try:
# ……爬取逻辑……
save_cookies("weibo", context.cookies())
finally:
browser.close()
这样一来,任何一个异常都不会导致浏览器进程残留,避免了系统资源被白白占用。
06 质量打磨:不写完就算完,还要跑得稳
v2.0 的开发部分完成后,我并没有立刻发布,而是进行了一轮完整的质量加固。
修复的一系列问题
❌ 浏览器资源泄漏 → 5 个爬虫函数全部加上 try/finally 结构
❌ 版本号不统一 → Gemini 扩展仍显示 1.0.0,UI 仍显示 v1.0 → 全部统一为 2.0.0
❌ 死代码残留 → 清理了未使用的 import 以及已经废弃的函数
❌ 参数文档缺失 → 在 README 中补充了 --timeout 和 --save-dir 的说明
❌ Windows 环境不友好 → 在配置指南中增加了 PowerShell 的等价命令
❌ 误导性提示 → 头条明明不需要 API Key,却仍然提示用户去配置 → 已修复
测试覆盖情况
✅ 162 个已有测试全部通过
✅ 新增 crawler_bridge 相关专项测试 7 个
✅ 对所有 .py 文件进行了语法编译检查,全部通过
顺手修掉了一个安装 Bug
有用户在 GitHub 上提了 Issue #1,反馈安装时出现 “Invalid input: expected object, received undefined” 的报错。追查下来,原因是 marketplace.json 中缺少了 owner 字段。一个非常小的字段缺失,却导致整个 Claude Code Marketplace 安装流程直接失败。v2.0 中已经一并修复。
07 关于爬虫,必须认真说几句
这个话题不能绕开。
在国内,爬虫一直是一个需要谨慎对待的敏感领域。
近些年因为爬虫行为被判刑的案例并不少见:
- 有人爬取简历数据,被判定为侵犯公民个人信息罪;
- 有人爬取航班数据,以非法获取计算机信息系统数据罪被起诉;
- 有人爬取视频网站的付费内容,最终以侵犯著作权罪担责。
参考:中国爬虫相关法律案例汇总
在技术实践当中,务必遵守法律法规,尊重平台的 robots.txt 协议以及用户数据隐私。
08 开箱即用:复制命令就行
选择你正在使用的 AI 平台,复制对应命令,安装完成后直接让 AI 自己去搜:
Claude Code(推荐):
claude install Jesseovo/last30days-skill-cn
Cursor:
git clone https://github.com/Jesseovo/last30days-skill-cn.git
OpenClaw:
git clone https://github.com/Jesseovo/last30days-skill-cn.git ~/.agents/skills/last30days-cn
装好之后,你只需要对 AI 说一句:
“帮我搜一下最近 30 天 ______ 的热点”
大约 30 秒之后,来自 8 个平台的搜索报告就会呈现出来。整个过程你不需要记任何参数,也不需要手动执行脚本,AI 自己就能把所有事情处理妥当。
结语
v1.0 解决的是“中文互联网内容搜不到”的问题。
v2.0 解决的则是“配置太复杂,导致根本用不起来”的问题。
回过头来看,这两个版本的迭代方向其实非常一致,那就是:不断降低使用门槛。
一个好的工具,不应该要求用户花半天时间去折腾环境。装完就能用,用完之后能得到真实的价值——这才是对的。
在此也特别感谢:
- mvanhorn/last30days-skill —— 原版项目,一切探索的起点;
- NanmiCoder/MediaCrawler —— 提供了爬虫引擎至关重要的技术灵感。
没有这两个项目,就不会有今天的 v2.0。
项目地址:
项目基于 MIT 协议开放使用,欢迎 Star 表示支持,也欢迎通过 Issue 给出你的建议。