AI Agent技术本质解析:用Token交换架构简洁性与演进路径深度剖析
市场在今年初见到Manus这类Agent时表现出极大的热情,其背后的驱动力值得我们深入探究。Agent这一概念为何兴起?它旨在解决哪些核心问题?更重要的是,它是否能有效解决这些问题?在解决问题的过程中,会遇到哪些障碍与挑战,又该如何应对?
带着这些思考,我们进入今天的探讨主题:我们为什么需要Agent?
Agent出现的深层原因
尽管当前的大语言模型已经展现出强大的能力,但其存在固有的局限性。模型的知识完全来源于训练阶段所摄入的数据,这导致了第一个矛盾点的产生:
- 当今社会信息更新速度极快,一周内就可能发生诸多重大事件。首先,模型的训练数据无法实时跟进这种变化节奏;其次,模型也不应盲目追逐所有信息,因为互联网上存在大量低质量数据,若不加选择地学习,反而会影响其输出质量与逻辑性。
- 除了公开信息,各企业还拥有大量私有数据和知识库。如果模型无法与这些内部数据交互,那么其在企业场景下的应用价值将大打折扣。
因此,Agent出现的首要原因,是建立模型与外部世界进行信息交互的通道。尤其是在垂直领域,如果缺乏足够的领域数据支撑,模型很容易产生事实性错误或“幻觉”。
此时可能会有疑问:如果仅仅是为了信息检索,直接采用预定义的工作流模式不就可以了吗?这正是经典的RAG(检索增强生成)逻辑。
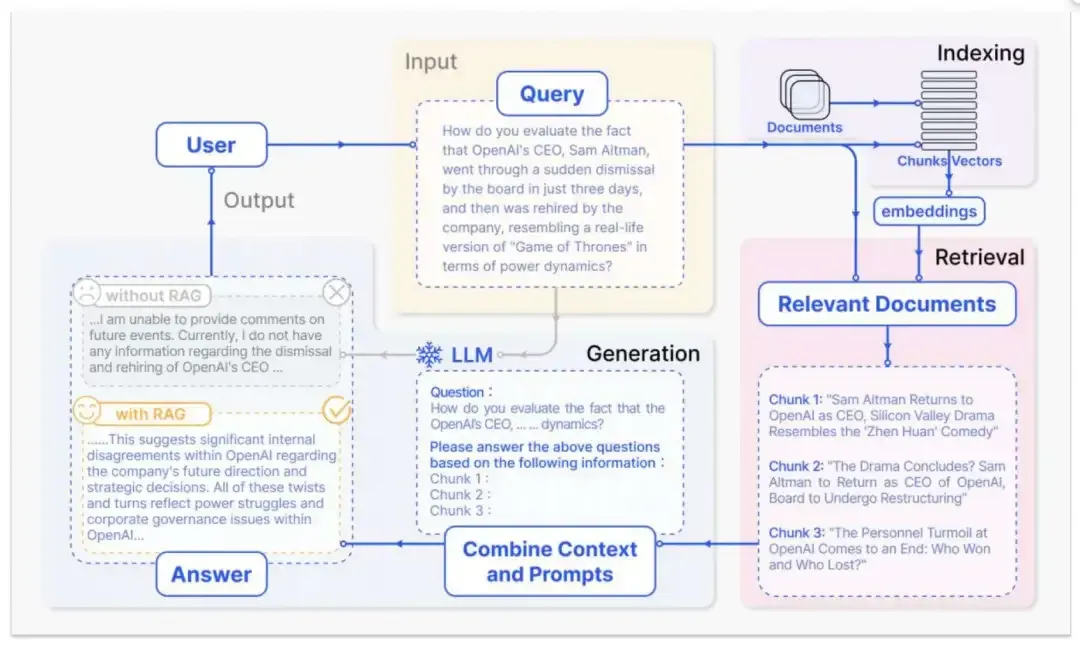
然而,即使是简单的信息检索需求,其复杂性也在不断增加。初始阶段可能只需要查询公共网络数据,后续则可能涉及A公司的内部知识库、B公司的CRM系统等。当数据源变得多样化之后,一个新的问题随之产生:由谁来判断应该去哪个数据源获取信息? 这对于传统的RAG系统而言会变得异常复杂。
试想处理如下问题:
什么是组织结构?
你们公司的组织结构是怎样的?A公司和B公司的组织结构又是怎样的?
他们为何要如此设计?
使用纯粹的RAG也能处理,其流程通常为:先由模型解析用户意图,对问题进行重写或拆分,再分发到各个信息渠道进行查询。一套设计精巧的、包含复杂判断逻辑的工作流类RAG确实能够实现。
这就引出了关于Agent最核心的争议:如果Workflow(工作流)能够完成Agent所能做的一切,那么Agent存在的独特价值是什么?
毕竟,Workflow可以实现循环、重试和复杂策略,只不过这些逻辑需要由开发者显式地编码实现。当业务环境的复杂度提升时,Workflow的开发和维护成本曲线会急剧上升。
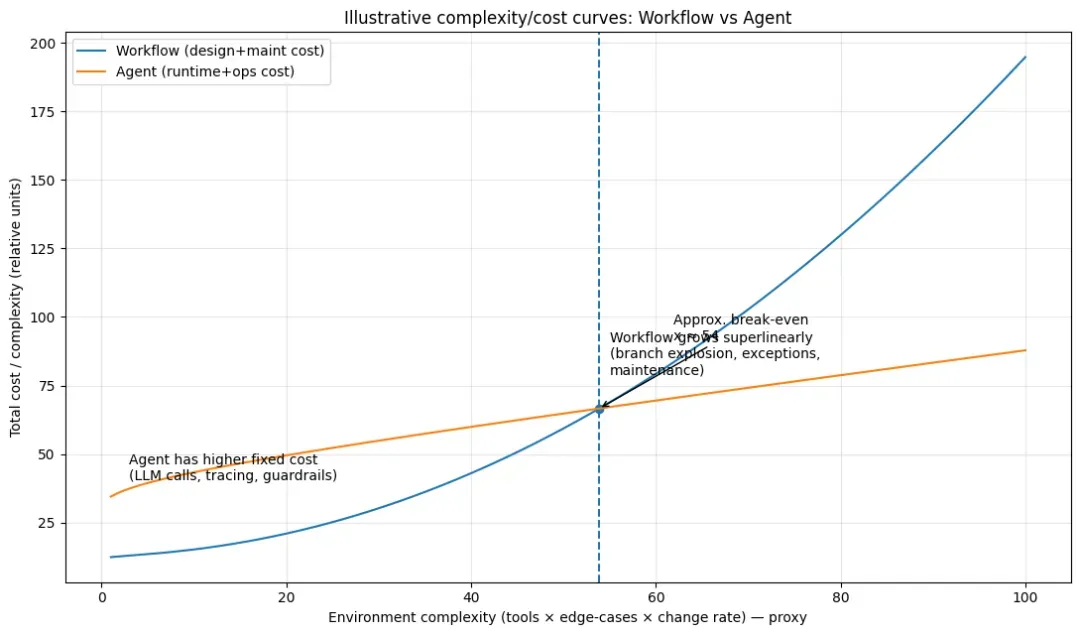
在企业真实的应用场景中,复杂度增长通常源于以下三类“难以穷举”的情况:
- 工具/系统不可穷举: 今天查询公共网络,明天接入A公司的知识库,后天连接B公司的CRM系统,大后天可能又要集成C、D、E等系统。
- 意图组合不可穷举: 用户的一个问题可能同时包含“解释概念 + 对比多家公司情况 + 分析原因 + 生成结构化表格”等多种复合意图。
- 异常与边界情况不可穷举: 包括权限不足、字段缺失、数据冲突、查询无结果、网页结构变化、接口限流等各种预料之外的状况。
理论上,可以将所有这些逻辑都编写进Workflow中,但这将导致典型的 “分支爆炸”和“维护爆炸”:
- 每增加一个系统,不仅仅是多配置一个工具接口,还涉及字段映射、降级策略、测试用例更新等一系列工作。
- 更关键的是,开发者需要为 “工具之间如何组合、何时进行重试、何时切换执行路径、何时向用户追问补全信息、何时应拒绝回答” 编写越来越复杂的显式编排逻辑。
此时,Agent架构的优势便显现出来。如果新增了C、D、E系统,可能只需要增加几个工具配置,甚至在某些情况下,原有的搜索工具可能已具备兼容性,无需改动。最重要的是,Agent架构将判断用户意图、选择调用哪些工具、验证工具返回结果是否正确等繁琐的决策工作,移交给了大模型本身。
当然,这必然会带来更多的循环调用、相对较低的响应效率以及更高的Token消耗。本质上,Agent是一种用运行时成本(时间/Token)来换取架构设计与维护简洁度的工程范式。
需要强调的是:Agent解决的核心并非“如何回答问题”,而是提供了一套将用户问题“编译”为可执行计划的框架。 你甚至可以将Agent架构本身理解为一套高度灵活、由模型驱动的特殊Workflow,这是当前阶段被验证为行之有效的一种设计范式。
总结来说,相较于传统的Workflow,Agent架构是一种工程架构层面的优化。其核心价值不在于让系统“更聪明”,而在于将一部分原本需要工程师在开发阶段显式编写、固化的控制流逻辑(如条件判断、流程编排、异常处理),转移到系统运行时,交由大模型动态决策(如路由选择、工具调用、多轮尝试、失败重试、信息补全、结果校验)。
Agent的核心交易是:以更高的运行时成本(多轮推理、多次工具调用、更高的延迟与Token消耗),来换取更低的开发与维护成本(更少的分支逻辑、更快的功能扩展、对长尾需求更好的适应性)。
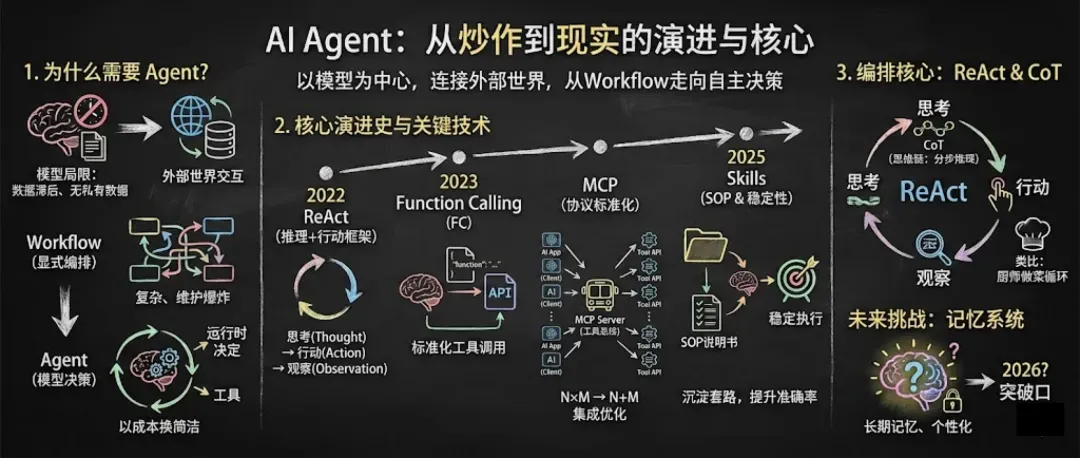
在此基础之上,回顾Agent的发展历程,有助于我们更清晰地把握其技术演进的脉络。
Agent技术演进简史
目前最经典的Agent架构是ReAct,大约在2022年被提出(论文《ReAct: Synergizing Reasoning and Acting in Language Models》)。彼时,大模型并不原生支持“函数调用”这类基础的工具调用能力,因此需要开发者自行实现,既可以通过精心设计的提示词来引导模型识别并输出调用指令,也可以进行模型微调(后者成本较高)。
当时的函数调用流程大致如下:
第一,预先定义Agent可以调用的所有工具,通常以JSON对象描述,其中description字段至关重要。
第二,模型根据用户问题和预设的工具集进行匹配,判断本次需要调用哪些工具,主要依据便是工具的描述。
第三,如果判定需要调用工具,模型会返回工具名称及参数,然后暂停生成。
第四,开发者的程序根据模型返回的信息执行实际工具调用,获取数据,并将结果连同原始用户问题再次提交给模型,以生成最终回答。
显然,上述流程较为繁琐。因此在2023年6月,OpenAI正式推出了Function Calling功能,作为ChatGPT产品的核心能力之一。该功能随后逐渐成为行业事实标准,各大主流模型均提供了相应实现。有了这一基础,Agent的开发与应用变得更为顺畅。
后续的发展大家比较熟悉。国内AI Agent概念的热潮始于2025年初的Manus,但如果追溯更早且具有广泛影响力的开源项目,则是2023年3月出现的Auto-GPT。不过,即便是今年初的Manus,也因基座模型能力限制而早期表现不佳,更不用说更早期的Auto-GPT了。
自Manus发布后,行业焦点逐渐从“2025 AI应用元年”转向“2025 AI Agent元年”。与此同时,基座模型能力取得了显著进步,包括整体推理能力、上下文长度都得到了极大增强。可以确信,各大模型均在工具调用相关数据上进行了大量微调训练,其直接成果便是2025年下半年,模型在工具调用方面的准确性和稳定性有了明显提升。
在此阶段,由于基座模型能力的提升,开发者发现Agent对工具的需求急剧增加,且必然会出现大量功能相似的工具。因此,MCP(Model Context Protocol)概念开始兴起。它一方面旨在解决Function Calling带来的工程维护难题,另一方面也致力于推动工具生态的共享与复用。MCP也几乎成为了新的业界标准,Agent生态随之进入了一个快速发展的阶段。
随后,模型在工具调用稳定性上持续改进,但当可用工具数量激增后,依然存在“找不到合适工具”或“错误调用工具”的问题。于是,Anthropic在2025年10月正式提出了Skills技术。可以将其视为对Function Calling机制的重要补充,Skills不仅提升了工具识别的精度,还在提示词管理、工作流封装等方面做了大量工作。
总而言之,现阶段结合Skills、Function Calling以及精心的上下文工程设计,已经能够将工具调用的准确率提升到很高的水平(例如90%以上),这在早期是需要极其复杂的工程手段才能实现的。
以上是从技术视角观察到的近三年Agent发展概况。核心结论是:在2025年之前,想要构建一个效果良好的Agent几乎是不可能的任务;而从2025年下半年开始,整体技术门槛已大幅降低。
基于此的推测是:此前关于Agent的诸多质疑以及产品体验不佳的问题,预计在2026年将得到显著缓解。 因此,说Agent的发展直接依赖于底层模型能力的演进,这句话确实切中要害——任何工程优化,其效果都可能不及模型自身一次重大的能力升级。
了解了Agent的起源与发展脉络,接下来我们将深入探讨几个关键技术点:Function Calling、MCP和Skills。
Function Calling 详解
根据前面的介绍,Function Calling(FC)的作用已较为清晰。简而言之,FC通过一套标准化的工程架构,替代了早期需要开发者自行实现的、基于提示词的“模型决策调用工具”的工作流。

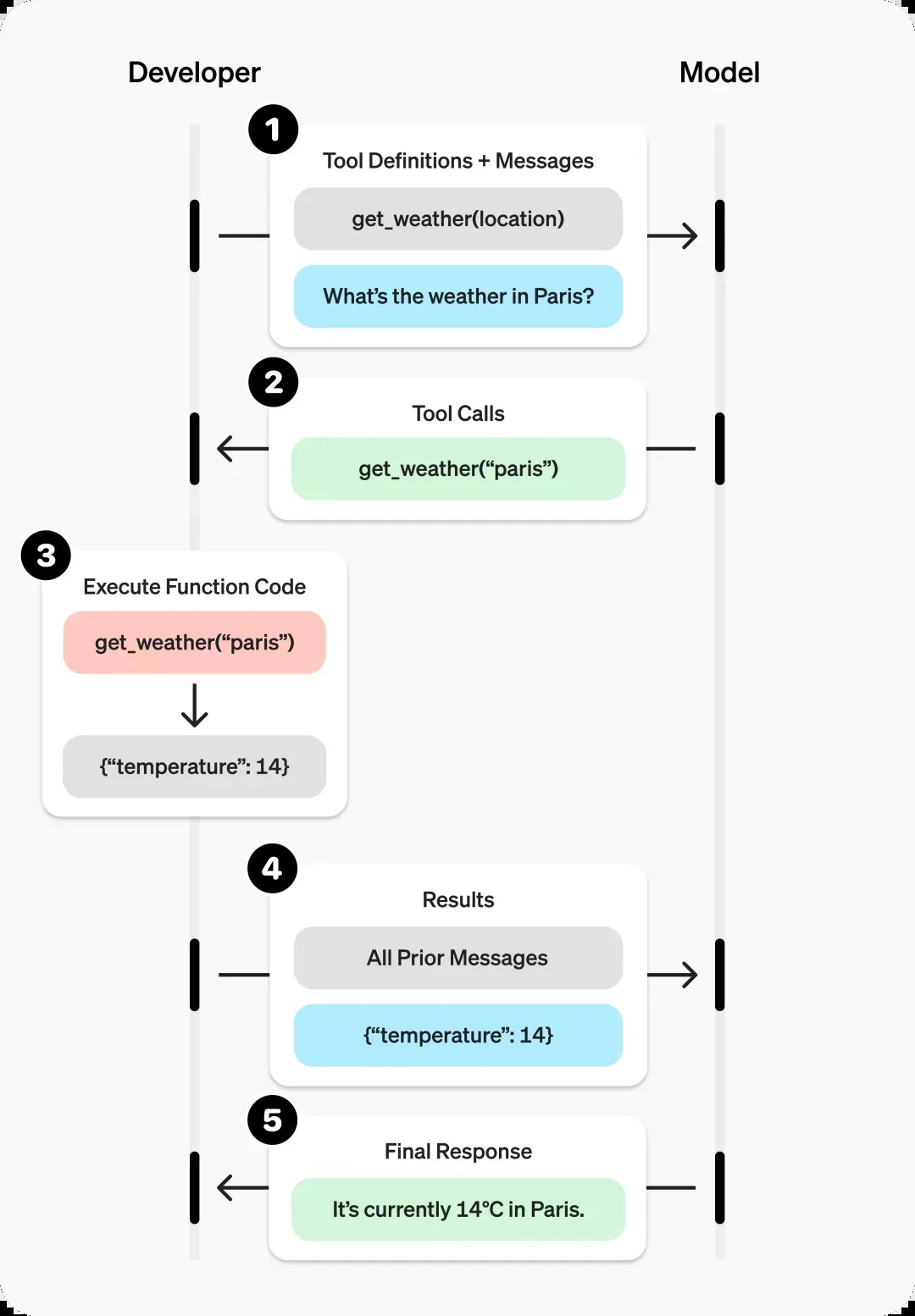
其具体交互逻辑如下:在对话过程中,LLM根据用户问题(例如“今天北京的天气如何?”)判断是否需要调用外部函数。如果需要,模型会输出一个结构化的JSON请求,包含要调用的函数名和具体参数。随后,由开发者的后端程序执行实际调用。官方提供的示例清晰地展示了这一过程:
具体流程,可参考GPT官方的定义模式:
# 这是提供给模型的工具定义描述,并非实际可执行代码
tools = [{
"type": "function",
"name": "get_weather",
"description": "Retrieves current weather for the given location.",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
},
......
},
}
}]
每次调用模型API时,都需要传入tools参数:
# 每次调用API时都需要传递tools参数
response = client.responses.create(
model="gpt-5",
messages=[...],
tools=tools # ← 工具定义需随请求一同发送
)
由此可见,模型具备调用哪些工具的能力,完全由开发者预先定义。模型会根据用户输入的语义,从预定义的工具集中选择匹配的工具进行调用:
# 用户输入
user_query = "今天北京天气怎么样?"
# 模型会进行分析:
# - 用户询问“天气” → 匹配 get_weather 工具的 description
# - 提到了“北京” → 对应 location 参数
# - 据此决定调用 get_weather 函数
需要注意的是,模型本身并不会直接执行工具调用,它仅仅返回一个结构化的调用指令。这是模型经过特定任务训练后获得的能力:
{
"function_call": {
"name": "get_weather",
"arguments": "{\"location\": \"北京\", \"unit\": \"celsius\"}"
}
}
实际根据返回的JSON数据执行脚本调用的是开发者的后端程序。调用获得结果后,需要将结果再次反馈给模型,以生成面向用户的最终回答:
# 将天气查询结果返回给模型
# result 为调用外部API返回的数据
final_response = llm.chat(
model="gpt-5",
messages=[
{"role": "user", "content": "今天北京天气怎么样?"},
{"role": "assistant", "function_call": model_response["function_call"]},
{"role": "function", "name": "get_weather", "content": json.dumps(result)}
]
)
整个逻辑非常清晰:如果模型判断用户意图无需调用工具,则直接生成回答返回给用户;如果判断需要调用工具,则先返回调用指令,待开发者程序获取工具执行结果后,将结果作为上下文再次调用模型,由模型生成最终回答。
这里有几点需要特别注意:如果工具接口出现故障且没有良好的容错机制,整个流程可能会中断,导致模型无法给出回答。
此外,理解以下几个问题,有助于把握Function Calling的本质及其应用中的挑战:
第一,如果预定义的Tools数组过大,会占用大量上下文长度,影响模型性能。因此在实际应用中需要进行优化处理,如动态加载工具描述。
第二,Function Calling的效果高度依赖于模型对用户意图的识别能力。模型判断是否调用某个函数,主要依据就是该函数的description描述字段。这存在一定风险,可能会出现误调用或漏调用的情况。不过,得益于模型较强的容错和理解能力,即使多获取了一些数据,也不一定会严重影响最终回答的质量。
在此基础之上,我们再进一步探讨MCP和Skills。
MCP 协议解析
MCP(模型上下文协议)为何会出现?其意义何在?要回答这个问题,仍需回归Function Calling的现实挑战。
我们已经清楚Function Calling解决了什么问题:它规范了单个大模型如何按照开发者定义的JSON协议,去调用特定的外部API。
然而,一旦需要集成的工具数量增多,就会暴露出显著的痛点:工程维护复杂度急剧上升!
MCP正是为了应对这一挑战而诞生的。一种较为形象的说法是:MCP是为Function Calling“处理后续工程问题”的解决方案。
举例说明:假设一个企业内有10个不同的AI Agent应用,需要接入20个数据源或工具。如果每个应用都独立为每个工具编写适配代码,那么将产生10 × 20 = 200个集成点。任何工具的API发生变更,都需要在所有相关应用中同步修改,维护成本高昂。
此外,生产环境的Agent往往不会只依赖单一模型,可能同时调用OpenAI GPT、Google Gemini、深度求索DeepSeek等,而各家模型的Tools调用接口规范又不尽相同,这进一步加剧了维护的复杂性。
在此背景下,MCP应运而生。它引入了“客户端-服务器”架构进行标准化。开发者只需编写一次MCP客户端,就能接入所有符合MCP协议的工具服务器。工具提供者也只需实现一个MCP服务器,就能被所有MCP客户端使用。这使得集成点从N×M骤降到N+M,大幅降低了耦合度和维护成本。
案例说明
为了更清晰地理解,我们来看一个具体案例。假设有两个工具:
- Tool A:
get_weather(location)—— 查询天气 - Tool B:
get_stock_price(ticker)—— 查询股价
用户的问题是:“帮我查北京天气,再给我腾讯的股价,最后总结一下。”
传统的Function Calling流程分为四步: 一、预定义工具: 每次调用模型时都需要携带完整的tools定义数组。 二、模型返回工具调用指令: 模型分析后,返回结构化的JSON,指明需要调用的工具及参数。 三、执行工具调用: 开发者后台程序根据指令,调用相应的天气API和股价API。 四、整合结果并生成最终回答: 将工具返回的数据组装成新的提示词上下文,再次调用模型,生成面向用户的总结。
如果这套工具只被一个Agent使用,问题不大。但如果被两个Agent使用,当工具参数变更时,就需要修改两个Agent的配置。如果被20个Agent使用,维护将变得异常困难,因为很难理清所有调用依赖关系。
引入MCP后,工程结构得以简化。它将Tool A和Tool B的接入逻辑从各个“应用内部代码”中抽离出来,封装到独立的“MCP Server”中。AI应用不再直接连接天气API或股市API,而是统一连接对应的MCP Server。
可以这样理解:MCP就像一个“工具总线”。
- MCP Server(工具提供方): 负责暴露工具列表、接收标准化调用请求、执行实际调用并返回结果。
- MCP Client / Host(AI应用方): 负责连接Server、发现可用工具、将模型的调用指令转发给Server,并将Server返回的结果传递给模型。
流程简述如下: 一、MCP Server暴露工具: 将天气API和股价API的鉴权、重试、字段映射等细节封装在Server内部,对外提供标准化的工具接口。 二、Host连接MCP Server并发现工具: 获取可用的工具列表及其描述。 三、将发现到的工具“适配”给当前使用的模型平台: 例如,如果使用OpenAI,则将MCP工具格式组装成OpenAI要求的tools数组格式。 四、模型决策与调用: 模型基于工具描述进行决策,返回tool_call指令。 五、Host转发调用: Host不再直连外部API,而是将调用请求转发给对应的MCP Server执行,并收集返回结果。
可见,Agent系统中的抽象层和黑盒确实不少。
遗留问题
虽然MCP有效缓解了工具集成和维护的复杂度,但它并不能从根本上解决“工具数量过多时导致的误调用、错调用”问题,同时也存在工具如何有效组织和管理的新挑战。
当然,在基础架构中,可以通过优化来动态加载工具,例如先让模型判断本次对话可能需要的工具子集,再进行加载,但这仍然不够优雅,且调用准确性问题依然存在。因此,在MCP之后,又出现了旨在进一步“优化体验、提升稳定性”的工程实践,这便是Skills。
Skills 技术剖析
如前所述,Agent的目标是用有限的一套工具,去满足用户无限多样的潜在意图。
然而,工具增多后,其组合方式也呈指数级增长,准确调用和高效执行的挑战愈发突出。Agent常被诟病的问题正是工具调用不准、整体响应迟缓。为了解决这些问题,Skills作为一种新的抽象层被引入。
Anthropic对Skill的定义是:一个包含说明文档、脚本和资源的文件夹(或模块)。Claude在执行任务时,会先扫描所有可用的Skills,评估哪些对当前任务有帮助,然后将相关Skill的完整内容动态加载到上下文中使用。
可以将其翻译为:
Skill = 一份可反复调用的专业SOP(标准操作程序)+ 详细说明书,由模型根据需求按需加载。
结合前文,Skills诞生的一个核心原因,正是为了缓解工具调用不准的问题。它将“何时使用何种工具、如何组合使用”的决策逻辑,部分地从模型的即时语义理解,转移到了预定义的Skill说明中。Skill内部可以清晰地写明处理某类任务的标准流程和工具调用顺序,从而提升稳定性和可预测性。
当然,Skills的意义不止于此。总结下来,其诞生主要有以下几方面原因:
一、提高工具调用的稳定性与准确性
大多数开发团队在工具数量增多后,都会面临“乱调用、漏调用、参数错误、顺序混乱、失败后无重试”等问题的困扰,直接导致Agent体验差、难以交付。Skills的核心价值之一,就是把“如何正确使用工具完成任务”的固定套路(包括条件判断、执行步骤、结果校验、失败兜底等)沉淀为可复用的模块,从而显著降低模型决策的随机性。
这部分逻辑过去可能需要通过复杂的ReAct工程架构来实现,而Skills提供了一种更结构化、更易于管理的方式。
但需注意,Skills本身并不能百分之百根除工具调用错误,仍需与其他工程手段(如校验、重试)结合使用。
二、解决长提示词与硬编码流程的维护难题
这一点与MCP的出现原因类似,都是应对项目规模扩大后带来的工程维护挑战。
维护过复杂提示词的开发者会有体会,为了让模型稳定输出,提示词正变得越来越像“伪代码”,内容不断膨胀。例如,一个数据分析任务的可能包含:
- 业务规则:指标口径、过滤条件、时间粒度。
- 数据规则:字段映射、缺失值处理、异常检测。
- 工具规则:SQL工具如何使用、何时使用、失败后如何重试。
- 输出规则:必须输出表格、必须给出结论、必须提示风险。
- 合规规则:数据脱敏要求、禁用词汇、免责声明。
- 大量示例(Few-shot Learning)。
这导致:
- 上下文负担重: 每次对话都携带大量可能用不上的规则,成本高且可能干扰核心任务。
- 版本难以控制: 某个业务口径变更,需要修改提示词,可能影响所有相关场景,回滚困难。
- 代码复制与漂移: A项目复制一份提示词,B项目再复制一份,数月后各自修改,变得不一致。
- 排查问题困难: 出现错误时,难以定位是规则描述有误、规则太长模型未读取、示例冲突还是工具返回异常。
Skills的解决思路与MCP异曲同工:将这些复杂的配置信息、流程说明、示例等,封装到独立的Skill模块中。仅在模型判定需要该Skill时,才将其内容动态加载到上下文中,实现“按需取用”。
从另一个角度看,既然提示词工程越来越像软件工程,那么版本管理、灰度发布、回滚等需求自然随之产生。Skills正是在这种背景下,为管理日益复杂的提示词和业务流程而诞生的。
案例对比
以查询“技术部张三上周的差旅报销总额,并按项目拆分”为例。
使用纯Function Calling时,需要定义get_employee_info, query_reimbursements等多个工具。在ReAct架构下,需要模型自行推导出正确的调用链:先查员工ID,再确定时间范围,接着查询报销记录,最后可能还需要查询项目信息进行分析。这个过程中容易出现调用顺序错误、参数格式错误、遗漏步骤或陷入循环等问题。虽然可以通过更复杂的工程逻辑来解决,但无疑会增加系统复杂度和响应延迟。
而使用Skills后,可以创建一个名为“报销查询”的Skill。该Skill的说明文档中会明确写出处理此类请求的标准流程(SOP)。当模型检测到用户查询涉及“报销”时,便会加载这个Skill,并按照其中定义的步骤顺序执行工具调用,从而保证流程的稳定性和准确性。同时,如果财务制度变更,只需修改这一个Skill即可,维护性大大提升。
综合案例
假设为一个老板BI仪表盘Agent配置了以下工具和Skills:
- 工具(通过MCP接入):
get_sales_report,get_marketing_spend,get_cashflow_status - Skills:
boss_bi_dashboard_cn: 教模型如何使用上述工具,从老板视角解读数字、输出结论,内含详细的KPI口径、表达话术和注意事项。excel_analysis_skill: 教模型如何对上传的Excel文件进行分析。
当用户提问:“帮我看看今年Q3的营收和投放,简单说说是不是该收一收预算?”
处理流程如下:
一、Skill检索与加载: 模型首先理解这是关于财务分析和预算决策的老板视角问题。接着,它会遍历所有Skills的元描述,发现boss_bi_dashboard_cn的描述与之匹配(例如:“用于解读公司经营指标、营收、成本、预算,输出老板视角决策建议”)。于是,模型激活此Skill,将其详细的“说明书+SOP”加载到当前上下文中。此时,尚未调用任何具体工具。
二、Skill指导下的工具调用: boss_bi_dashboard_cn的说明文档会指导模型:对于“营收+投放”类查询,应先调用get_sales_report,再调用get_marketing_spend,然后计算关键比率(如ROAS),最后按照特定结构(如“结论-关键数字-建议-风险”)输出报告。模型依据这些指导,发起相应的Function Calling。
三、数据处理与报告生成: 工具返回数据后,模型结合Skill中规定的输出格式和表达要求,生成最终回答。
以上就是Skills的核心机制。最后,我们来探讨Agent架构的编排核心:ReAct框架。
ReAct 框架解析
理解了Agent所依赖的基础能力后,我们需要深入其核心的编排层——ReAct。
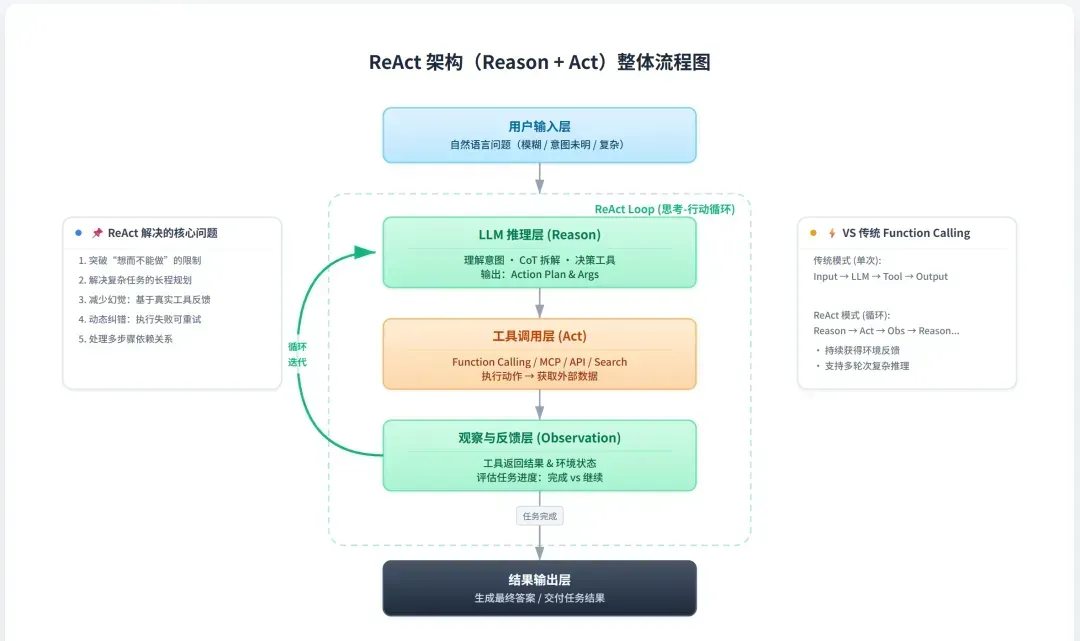
编排层是智能体系统的控制中枢,负责组织信息流和执行推理循环。它模拟人类解决复杂任务时的认知过程:获取信息、制定计划、执行行动、观察反馈、调整计划,如此循环直至达成目标。一个常见的比喻是“厨师烹饪复杂菜肴”:厨师根据订单获取食材,构思烹饪步骤,动手操作,并随时尝味调整。
类似地,Agent的编排层按照设定的推理框架(如ReAct)进行迭代,驱动模型生成“思考”并做出“行动”决策。除了ReAct,还需了解CoT(思维链),并可延伸至ToT(思维树)等。
- ReAct(Reasoning + Acting): 强调模型在回答前进行连续的内部推理和外部行动选择,形成“思考(Thought)-行动(Action)-观察(Observation)-再思考…”的循环,有助于提高答案的准确性、可靠性和可追溯性。
- CoT(Chain of Thought): 引导模型通过生成中间推理步骤来分解复杂问题,促使其在给出最终答案前先展示思考过程,能有效减少“幻觉”,提升复杂问题解决能力。
- ToT(Tree of Thought): 在CoT基础上,允许模型并行探索多种推理路径并进行评估比较,适用于需要战略规划和多方案择优的任务。
由于篇幅所限,我们重点讨论ReAct与CoT的协同关系。
ReAct与CoT的关系
首先,ReAct与CoT都属于“推理策略框架”,即Agent四大组件中“编排层”的具体实现范式。它们定义了如何组织模型的内部推理过程、生成步骤以及提示词的结构。
换言之,ReAct是代码实现中的核心循环逻辑,是AI工程架构的支柱,它决定了如何与记忆系统、工具系统进行协同。
在逻辑上,ReAct和CoT是同一层级的两种不同范式。但在当前的主流实践中,它们常常结合使用,以至于CoT看起来像是ReAct循环内的一个组成部分。实际上,CoT本身也可以独立调用工具。不过从流行趋势看,ReAct常被用作顶层的、循环执行的主框架,而在其每一次的“思考(Thought)”阶段,往往会包含一个或多个CoT式的分步推理过程。 可以这样理解:ReAct是承载流程的“容器”,CoT是容器内进行具体推理的“内容”。ReAct是最具“智能体”特征的执行循环,而CoT是最基础、最通用的推理增强技术。
ReAct 规定了宏观步骤:先思考 → 行动 → 等待结果 → 再思考… 而这个“思考”步骤具体如何实现?通常就是嵌入一个 Chain of Thought 推理块。
举例说明:让Agent回答“某公司员工请假流程是什么?”。 Agent可能需要:1. 理解问题;2. 检索相关知识库;3. 分析检索到的内容结构;4. 输出清晰步骤。 在ReAct循环中,其“思考”步骤可能就是一个典型的CoT:
Thought:
首先,我需要找到关于公司请假政策的文档。
接着,我会读取文档中关于流程的部分。
然后,我将提取出关键步骤:提交申请、上级审批、HR备案。
最后,我将这些步骤组织成清晰易懂的回答。
这个“Thought”部分就是一个简单的思维链,模型在没有执行外部行动前,先在内部进行了分步思考和组织。在Agent架构中,并非每一步都需要调用外部工具,很多时候只是在内部组织思维和语言,此时CoT能有效提升输出质量。
总而言之,在ReAct框架中穿插使用CoT进行细致推理,是目前最常见且效果稳定的实践方式。 理解这一点,就把握了Agent编排层的核心。
总结
最后谈谈记忆系统,这通常是整个Agent项目中最复杂、最具挑战性的部分,因其涉及短期/长期记忆、向量检索、信息摘要、持久化等多种机制,我们今天暂不展开,后续会有专题讨论。
最终总结如下:市场为Manus这类Agent兴奋,并非因其“更聪明”,而是因为它将原本需要工程师在Workflow中显式编码的路由选择、工具调度、异常重试等控制逻辑,转移到系统运行时由模型动态决策,从而在面对“工具繁多、意图复杂、异常频发”的企业级场景时,显著降低了长期开发和维护的成本。
过去三年的技术演进脉络清晰:ReAct提供了推理与行动循环的基础框架;Function Calling标准化了工具调用接口;MCP通过协议化解了工具爆炸带来的集成维护难题;Skills则将“如何正确高效使用工具”的SOP沉淀为可复用模块,提升了系统稳定性。
2025年,模型在工具调用能力上已取得长足进步。然而,记忆模块仍是当前面临的主要挑战之一。 预计在2026年,底层模型有望在记忆相关能力上实现突破,更高效的本地化向量检索与管理方案也可能随之成熟,让我们拭目以待。