Agent模型七层架构全解读:从执行环境到治理安全的深度剖析
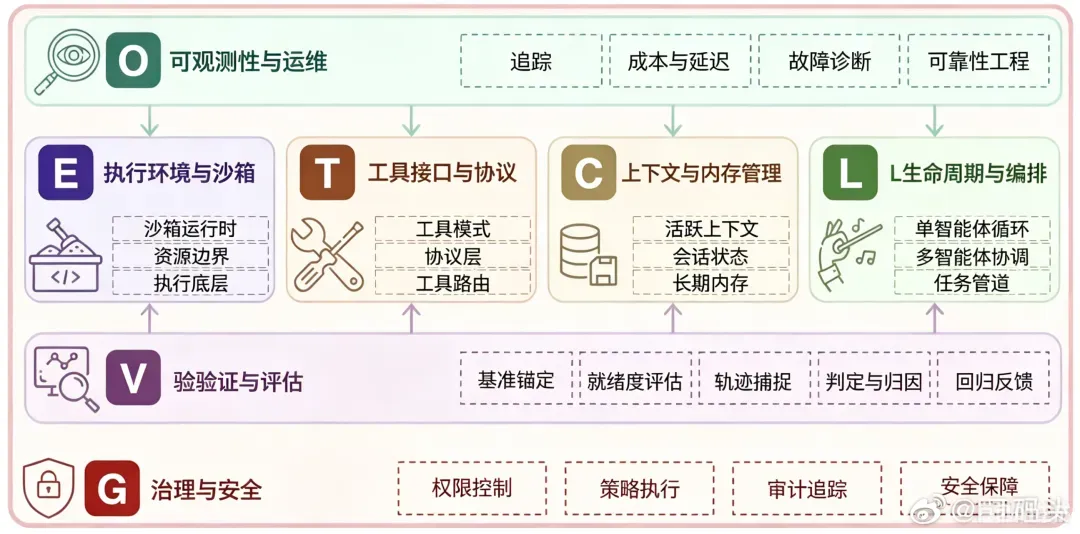
- 执行环境与沙箱:Agent究竟运行在何处?是本地环境、容器、浏览器、桌面,还是远程沙箱?它的安全边界与资源隔离如何定义?
- 工具接口与协议:工具如何被描述、发现及调用?当工具数量激增时,怎样防止模型做出混乱或错误的选择?
- 上下文与记忆管理:短期上下文(工作记忆)、会话状态及长期记忆分别如何管理?Agent的自我进化能力,在很大程度上体现在这一层。
- 生命周期与编排:一个Agent是仅单轮执行,还是支持多轮循环?人类在循环中如何适时介入?是使用单一Agent覆盖全流程,还是由规划器、执行器、审查器等多个子Agent协作分工?Agent之间需交接哪些关键信息?
以上四层构成了Agent的核心架构,外围还有三大支撑层:
- 可观测性与运维:不同应用场景的容错率有多高?每次模型调用、工具调用、检索过程、报错信息、重试机制、Token成本以及延迟波动,都必须做到可追踪、可分析。
- 验证与评估:任务结果是否正确,失败定位究竟是模型推理错误、工具执行异常、上下文偏差,还是测试环境本身的问题?对于客观标准明确的题目可以放心交由AI处理,而需要主观权衡的决策,仍需人类发挥最终把控作用。
- 治理与安全:Agent被授予了哪些权限?它能否发送邮件、修改代码、调用生产API或读取内部私有数据?审批和审计流程由谁执行?尤其在企业组织资产相关的初始化、访问、存储与回库环节,安全管控不容忽视。