Agent模型Harness设计深度解析:核心组件与未来演进
01
Harness 概念详解:模型与系统的桥梁
Harness 工程的核心在于围绕模型构建系统,将其转化为能够实际运作的引擎。模型本身承载智能,而 Harness 则使这种智能得以有效应用。本文将首先明确定义 Harness 的概念,然后从模型这一基础出发,系统地推导出当前阶段以及未来 Agent 所需的核心组成部分。
02
Harness 的必要性:弥补模型的内在局限
Agent 的许多期望功能,模型本身并不具备,这正是 Harness 存在的主要意义。在绝大多数场景中,模型仅能接收文本、图像、音频或视频等输入,并输出文本或结构化调用结果。默认情况下,它无法实现以下能力:
- 在多次交互之间维持持久化状态
- 直接执行代码或程序
- 获取实时更新的信息
- 自主搭建运行环境并安装所需依赖
所有这些能力都归属于 Harness 层的职责。大语言模型的结构决定了,必须有一层外部机制对其进行封装,才能使其参与到真实的工作流程中。一个简单的例子是,为了实现流畅的聊天体验,我们通常使用一个 while 循环来维护历史消息记录,并不断追加新的用户输入。这种广泛采用的形式本质上就是一种 Harness 实现,其作用是将期望的 Agent 行为转化为具体的系统逻辑。
03
从目标行为到Harness设计:逆向工程思维
Harness 工程的核心作用,是协助人类注入有效的先验知识,从而引导和塑造 Agent 的行为模式。随着模型能力的持续提升,Harness 也逐渐被用于以更精细的方式扩展或修正模型,使其能够胜任以往难以完成的任务。本文并不试图穷举所有可能的 Harness 功能,而是从“让模型能够完成实际工作”这一根本目标出发,推导出一组关键能力。其基本思路是:我们期望实现(或需要修正)的特定行为 → 对应的 Harness 设计方案。
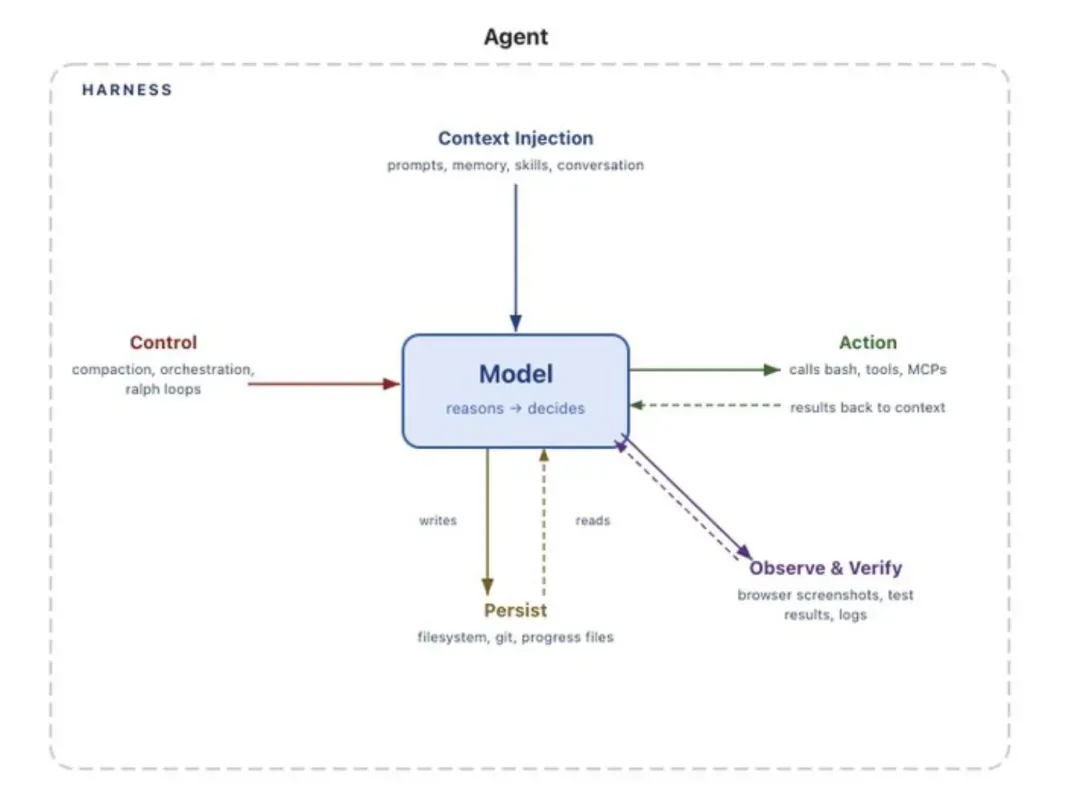
04
文件系统:持久化存储与上下文管理的基础
我们希望 Agent 具备持久化存储能力,用以处理真实世界的数据、转移超出上下文窗口容量的信息,并在不同的工作会话之间保持连续性。然而,模型只能直接处理其上下文窗口内的信息。在引入文件系统抽象之前,用户只能通过手动复制粘贴的方式向模型提供内容,这种方式效率低下,且完全不适用于自动化运行的 Agent。
现实世界的工作本身便是通过文件系统来组织的,而模型在其训练过程中也已学习了这种模式。因此,一个自然而高效的解决方案是:由 Harness 层提供文件系统抽象以及相关的操作工具。文件系统堪称最基础的 Harness 原语之一,它赋予了 Agent 多项关键能力:
- Agent 拥有一个专属的工作空间,可以读取数据、代码和文档。
- 信息能够被逐步写入或转移,避免了所有内容都必须堆积在有限的上下文中。
- 中间结果可以被保存下来,从而实现跨会话的状态维持。
文件系统同时也构成了一个天然的协作界面,多个 Agent 或人与 Agent 之间可以通过共享文件进行协同工作,例如 Agent Teams 这类架构便高度依赖于此。再结合 Git 版本控制系统,文件系统进一步获得了版本追踪能力,使得 Agent 可以跟踪进度、回滚错误操作并进行分支实验。后文还将再次提及文件系统,因为它实际上是许多其他高级能力得以实现的基石。
05
Bash与代码执行:Agent的通用问题解决工具
我们希望 Agent 能够自主地解决各类问题,而非在每一个步骤都依赖于预先定义好的、有限的工具集。目前主流的 Agent 执行模式是 ReAct 循环:模型首先进行推理(reasoning),随后通过调用工具执行动作,观察结果,再进入下一轮循环。
问题的关键在于,Harness 通常只能执行那些事先已定义好的工具。与其为每一种可能的操作编写专用工具,不如提供一个高度通用的工具,例如 Bash Shell。因此,Harness 通常会集成 Bash 能力,允许模型通过编写和执行代码来动态解决问题。
Bash 结合代码执行能力,相当于为模型提供了一台“通用计算机”。模型可以通过编写代码临时构建所需的工具,从而摆脱对固定预配置工具集的依赖。当然,Harness 仍然会提供其他专用工具,但代码执行正日益成为支持 Agent 自主问题求解的默认策略。
06
沙箱环境:安全执行与自验证的基础设施
Agent 需要一个适宜且受控的环境,才能安全地执行操作、观察结果并持续推进复杂任务。我们已经为模型提供了存储能力和代码执行能力,但这些活动都必须在具体环境中发生。直接在本地运行模型生成的代码存在较高安全风险,同时单一环境也难以支持大规模并发任务。
沙箱提供了一种隔离且安全的执行环境。Harness 可以将整个执行过程置于沙箱之中,让 Agent 在其中运行代码、访问文件、安装依赖并完成任务。为了进一步提升安全性,可以引入命令白名单机制,并限制网络访问权限。与此同时,沙箱也带来了良好的可扩展性:环境可以按需动态创建、支持多个任务并行运行,并在任务完成后彻底销毁。
一个完善的环境通常还需要预配置一系列常用工具,例如语言运行时、依赖包管理器、Git、测试框架,以及用于网页交互的浏览器。浏览器、日志记录、屏幕截图、测试运行器等能力,使得 Agent 能够观察并深入分析自身行为,从而形成一个自验证的闭环:编写代码 → 运行测试 → 分析结果 → 修复问题。需要明确的是,模型本身并不会主动配置这些环境。Agent 在何处运行、拥有哪些工具、可以访问哪些资源、如何验证结果,所有这些都属于 Harness 层的核心设计决策。
07
记忆与搜索:实现Agent的持续学习能力
我们希望 Agent 能够记住其过往经历,并获取在模型训练截止日期之后才出现的新信息。模型本身仅包含静态的权重和当前的上下文,并不具备额外的记忆机制。在不修改模型权重的前提下,为其增加知识的主要方式是通过上下文注入。
在记忆方面,文件系统再次扮演了核心角色。Harness 可以支持类似 AGENTS.md 这样的记忆文件,并在 Agent 启动时将其内容加载到上下文中。随着 Agent 持续更新这些文件,系统会不断注入最新的记录,从而形成一种有效的“持续学习”机制。另一方面,模型存在固有的知识截止问题,无法直接获取训练之后的数据,例如更新的软件库版本。因此,需要借助 Web 搜索以及 MCP 工具(如 Context7),使 Agent 能够获取超出其训练范围的最新信息。因此,Web 搜索以及动态获取最新上下文的能力,同样是 Harness 中至关重要的一类基础能力。
08
应对Context Rot:上下文管理的高级策略
我们不希望 Agent 在执行长期任务的过程中,性能因上下文管理不当而逐渐下降。所谓 Context Rot(上下文退化),是指随着上下文窗口不断被历史信息填满,模型在推理和任务完成方面的表现会逐步变差。上下文是一种有限且宝贵的资源,因此 Harness 必须对其进行高效且智能的管理。
从某种意义上说,当前大量的 Harness 工程工作,本质上是在进行复杂的“上下文工程”。当上下文使用量接近上限时,必须进行压缩处理。如果不加处理,一旦超过上下文长度限制,API 可能会直接报错,这在工程上是不可接受的。因此,Harness 通常会通过总结与转移等机制,确保 Agent 能够持续稳定地运行。
对于工具调用产生的大量输出,如果全部放入上下文,会引入大量噪声干扰模型的判断。常见的做法是仅保留输出内容的开头和结尾部分,其余内容则写入文件系统,在需要时再行读取。此外,如果在 Agent 启动阶段就加载过多的工具或 MCP 服务说明,也会在一开始就拖慢模型的表现。Skills(按需加载的能力模块)通过渐进式加载策略来缓解这一问题。模型本身不会主动选择加载哪些能力,但 Harness 可以通过这种方式保护上下文资源,避免其过早发生退化。
09
长时任务执行:自主性与稳定性的综合设计
我们希望 Agent 能够在较长时间尺度上,自动且稳定地完成高度复杂的任务。自动化软件开发可以被视为编码类 Agent 的一个重要目标场景。然而,当前模型仍存在一些限制,例如容易提前停止生成、难以自主拆解复杂任务,以及在跨越多个上下文窗口时表现不稳定。
因此,一个设计良好的 Harness 必须围绕这些问题进行针对性设计。此时,前面提到的各项能力开始协同发挥作用。长时任务的执行需要持久化状态、任务规划能力以及观察与验证机制,才能跨越多个上下文窗口持续推进工作。
文件系统和 Git 被用于跨会话跟踪工作进度。长期任务可能产生数百万 token 的交互记录,文件系统可以稳定地记录这些过程,而 Git 则使得新的 Agent 或工作线程能够快速理解当前状态与历史脉络。对于多 Agent 协作而言,文件系统也充当了一个共享的“工作账本”。Ralph Loop 是一种用于强制任务持续执行的 Harness 模式:通过 Hook 机制拦截模型的“结束”行为,并在新的上下文窗口中重新注入原始任务目标,从而驱动任务继续推进。文件系统在其中起到关键作用,因为每一轮循环都可以在新的上下文中读取之前保存的状态。
规划与自验证机制用于保持任务执行的方向正确性。规划是指将总体目标拆解为多个可执行的步骤,Harness 可以通过特定的提示词工程与文件机制来支持这一过程。每完成一步后,通过运行测试或进行自我评估来进行验证;如果步骤失败,则通过 Hook 机制将错误反馈给模型,促使其进入下一轮迭代。验证不仅提升了最终结果的可靠性,也为模型提供了持续改进的明确信号。
10
Harness的未来演进:模型与系统的协同进化
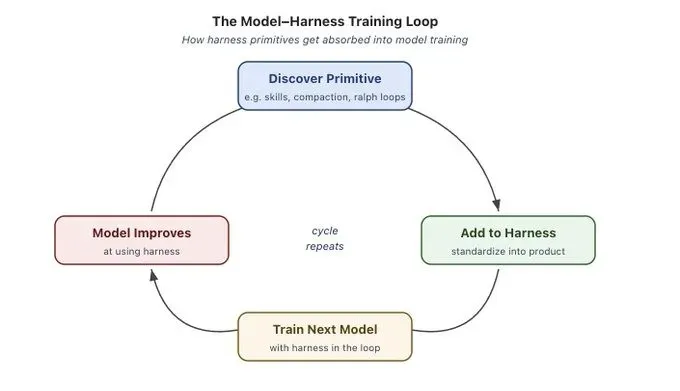
模型训练与 Harness 设计正在逐渐走向耦合。一些领先的 Agent 产品(如 Claude Code、Codex)已经在模型训练阶段将特定的 Harness 模式纳入闭环,使得模型在文件系统操作、Bash 执行、任务规划以及多 Agent 协作方面表现更为出色。
这形成了一个积极的反馈循环:首先在 Harness 工程实践中发现有效的模式,随后将这些模式纳入模型的训练过程,从而进一步增强模型的基础能力。但这种共同演化也带来了新的挑战,例如模型泛化能力的潜在下降。当工具的具体实现逻辑发生变化时,模型的性能可能会出现显著下滑,这表明模型在一定程度上“过拟合”了训练时所使用的特定 Harness 环境。
然而,这并不意味着某个模型所对应的原始 Harness 就是最佳选择。事实上,在不同的 Harness 设计下,同一模型的表现可能存在巨大差异。例如在 Terminal Bench 2.0 等基准测试中,可以观察到显著的性能波动;甚至仅通过调整和优化 Harness 的实现,就足以将一个编码 Agent 的排名从 Top 30 提升到 Top 5。这充分说明,Harness 工程本身仍然蕴含着巨大的优化潜力和探索空间。
Harness工程的未来方向:挑战与机遇并存
随着模型自身能力的不断增强,一些当前属于 Harness 层的能力,例如复杂任务规划、自我验证以及长程一致性维护,未来可能会逐渐被模型内部化,从而减少对外部上下文注入的依赖。
这表面上似乎意味着 Harness 的重要性会降低。但正如 Prompt 工程至今仍然至关重要一样,Harness 工程也很可能长期存在并持续演进。因为它不仅仅是在弥补模型的不足,更是在围绕模型智能构建完整、可靠、高效的工程系统。良好的环境配置、合适的工具集、鲁棒的持久状态管理以及严谨的验证机制,都能让模型在任何智能水平下发挥出更高的效能。
目前,Harness 工程仍然是一个非常活跃的研究与开发方向。例如在 LangChain 的 deepagents 等项目探索中,业界正在深入研究:
- 如何让上百个 Agent 在同一个代码库上高效地并行协作。
- 如何让 Agent 分析自身的执行轨迹,从而自动发现并修复 Harness 层存在的问题。
- 如何根据具体的任务需求动态地组装工具与上下文,而非采用僵化的预先配置一切的模式。
本文本质上旨在系统性地回答两个核心问题:什么是 Harness,以及它如何被我们对模型能力的期待和现实约束所塑造。模型提供了原始的智能,而 Harness 则让这种智能在复杂的现实世界中真正发挥出强大而可靠的作用。