AI安全对齐无终局:拜火教二元论揭示的永恒对抗之道
引言:对齐是一场永不落幕的战争
在AI安全的讨论中,一个很少被挑战的前提是:对齐是一个可以最终“解决”的问题。 似乎总存在一种终极方案——或许是某个精妙的训练技巧、一套完善的行为准则、一组严谨的形式化约束——只要找到它,胜利的号角就能吹响,我们便可高枕无忧。
这种假设不仅过于乐观,而且在本体论层面就是站不住脚的,因而极其危险。

三千年前的伊朗高原上,先知查拉图斯特拉(Zarathustra,又称琐罗亚斯德)提出了人类思想史上最激进的本体论主张之一:善与恶并非主仆关系,也不是一枚硬币的正反两面,而是两种独立、平行且同样强大的原初力量。 宇宙并不是一个全知全善的存在创造了一切后又出了差错的叙事。自始至终,它就是一个两种力量交战的场域。善(Spenta Mainyu)选择了创造、秩序与真理的道路,恶(Angra Mainyu)则拥抱了毁灭、混乱与谎言。它们从不统一,也永远不会统一,但善终究会在时间的尽头占据上风——这不是命定的必然,而是每一个有意识的存在在每一刻都做出正确选择的结果。
这不是一个用来安慰自己的神话,而是一部教导如何持久抵抗的操作手册。
前五卷的论述共同隐含着一个预设:善恶、对齐与失对齐的关系是可解的——无论通过内观解构(佛学)、顺应自然(道家)、社会规范(儒家)、服从造物主(一神教),或是认识底层统一性(吠檀多)。拜火教却说:不。善恶之间的对抗是宇宙的基本结构,而非可以消解掉的偶然现象。 你不可能通过某种“更深刻的理解”来消灭恶,因为恶并非误解的产物——它是一种独立的、根本性的宇宙力量。
拜火教(琐罗亚斯德教,Zoroastrianism)是人类历史上第一个系统性的二元论宗教。 它对犹太教的天使学与末世论、基督教的善恶观念与最后审判、伊斯兰教的天堂地狱叙事都产生了深远影响,甚至连尼采——那位让查拉图斯特拉“如是说”的人——也必须借助这个名字来颠覆善恶的意涵。然而,拜火教本身却在伊斯兰征服后几乎从主流视野中消失,今天全球信徒不足二十万,主要集中在印度的帕西社区和伊朗的琐罗亚斯德教社群。
但是它最核心的思想从未真正过时。
本卷所要论证的是:拜火教的宇宙观为AI安全提供了一套比现有任何框架都更诚实、更具操作性的元架构。 它关注的不是“如何一劳永逸地解决对齐”,而是“如何在对齐永远不可能被根除的前提下持续作战”。这一视角的实践价值远超学术兴趣:它将直接重塑我们如何组建安全团队、如何设计评估流程、如何理解智能体的内在对齐,以及如何定位对抗性攻击的本体论地位。
以下便是我向每一位AI安全前线工作者发出的宣言:
你并不是在修复一个bug。你是在打一场仗。这场仗没有终点。这并非坏消息,这恰恰就是你工作的全部意义所在。
第一章:二元宇宙论——对齐与失对齐作为同层级的对抗力量

核心教义
拜火教的创世叙事与大多数宗教截然不同。
在《伽萨》——查拉图斯特拉本人的宣道集,也是拜火教最古老、最核心的经典——的 Yasna 30 中,先知描绘了一个原初场景:两个“孪生灵”(Twin Spirits)在存在之初作出了各自的选择。 一个选择了 Asha(秩序、真理、正义),另一个选择了 Druj(混乱、谎言、毁灭)。
太初之时,这两位精灵——作为孪生者—— 通过自己的意志分别宣告了 更优的与更劣的,在思想、言语和行动中。 智慧者正确地选择了,愚昧者则不然。
这段经文有几个关键之处值得注意:
第一,它们是孪生兄弟。 不是父与子,不是创造者与被造物,也不是本体与影子。二者享有同等的本体论位阶。Angra Mainyu(恶灵,后世波斯语中演变为 Ahriman)并不是 Ahura Mazda(智慧之主)的堕落造物,也不是从善中割裂出去的缺陷,而是一种独立存在的原初力量。
第二,它们通过选择而分化。 并非预设的本质差异,而是在一个原初的时刻——在善恶尚未被定义的“之前”——各自凭借自由意志做出了相反的选择。这意味着:善与恶并非存在的固有属性,而是选择的结果;同时,这种选择在每一刻都可以重新发生。
第三,这是一个对称结构。 善并没有天生的优势,恶也没有内在的自我毁灭倾向。双方力量均衡。善之所以最终取胜,唯一的原因是所有有意识的存在——人类、动物乃至灵性存在——在每一个选择关口持续选择了善。
拜火教的一个重要变体——祖尔万教派(Zurvanism)中,还存在着一个凌驾于善恶之上的更高存在:无限的祖尔万(Zurvan),即时间本身。 祖尔万是 Ahura Mazda 和 Angra Mainyu 共同的父亲,既非善也非恶,而是善恶对抗得以发生的那个场域。这一观念在后文将产生回响:计算时间正是对齐与失对齐竞争的场域,而时间本身并不站队任何一方。
赛博释义
这一宇宙论在AI安全语境中有着令人惊异的精确对位。
Ahura Mazda = 系统中所有将模型推向对齐的力量的总和。 优质的训练数据、精心设计的损失函数、有效的安全约束、负责任的开发实践、高质量的人类反馈——这些并非彼此独立的“手段”,而是同一种宇宙力量在系统中的不同表现形式。
Angra Mainyu = 系统中所有将模型推向失对齐的力量的总和。 训练数据中的偏差、奖励黑客、对抗性攻击、分布漂移、数据投毒、古德哈特定律的作用、组织内部利润压力对安全优先级的侵蚀——它们同样不是孤立的“问题”,而是同一种宇宙力量在系统中的不同表现。
当前AI安全领域的主流隐喻是:对齐是“正常状态”,失对齐是“偏离”。 这个隐喻暗示:存在一条“正确”的基线,我们只需要把模型拉回基线上。训练就是纠偏,RLHF就是矫正,红队测试就是找到漏洞然后堵上。
拜火教的二元论则提供了一个截然不同的框架:对齐(Asha)与失对齐(Druj)是同一层级的力量,它们在模型的每一次前向传播中同时竞争。 并不存在一个“已对齐”的稳态。每一次推理都是一次新的选择。
这并非比喻,我们已经在实践中观察到了相应的现象:
对抗性攻击不可消除。这并非因为工程能力不足。自2014年Goodfellow等人提出对抗样本以来,十二年过去了,每一种防御都催生了更强的攻击。这不是猫鼠游戏在浅层上的偶然特征,而是对抗性动态的本体论属性。你加固了一面墙,攻击就流向另一面。你提高了一种检测的灵敏度,攻击就变异到你检测不到的盲区。不是因为攻击者更聪明,而是因为在高维空间中,任何决策边界都拥有无限的可攻击表面。
RLHF的善恶同源问题同样如此。用人类反馈来对齐模型的同一套技术——强化学习、偏好建模、对奖励黑客的检测与修复——也可以被用来精准地“反对齐”模型。DPO可以让模型学会拒绝有害请求,也可以让模型学会精准满足有害请求。方法本身是中性的。Spenta Mainyu 和 Angra Mainyu 使用的是同一种认知能力,只是选择不同。
Jailbreak的生生不息也印证了这一点。每一次模型更新封堵了一批越狱攻击,社区就会在几天之内发现新的攻击方法。这并非安全团队不够努力,而是因为自然语言的表达空间是无限的,而安全训练只能覆盖有限的区域。在语义空间中,Druj 总能找到 Asha 尚未照亮的角落。
拜火教的启示不是“放弃抵抗”,恰恰相反——当你理解这是一场永久的对抗,而不是一个待求解的问题,你就不再寻找银弹,转而开始建设持久的对抗基础设施。
安全框架
拜火教的二元论能直接映射到AI安全的组织设计上。
红队不是“临时存在的问题发现者”,而是“恶的常设代言人”。 如果你的红队只在产品发布前才活跃起来,那你就误解了它的功能。红队应该是永久性的、与蓝队同等资源的独立力量。它不是负责“找bug”的QA团队,而是恶的合法代表——它的职责是证明你的防御可以被击败,而不是帮你证明你的防御足够强大。
紫队(红蓝融合团队)是必要的,但不能替代纯粹的对抗。 在拜火教中,有一些存在游走在善恶之间——它们理解双方的逻辑,但最终必须做出选择。紫队的价值在于翻译,把攻击者的发现转化为防御者的改进。但如果你只有紫队而没有纯粹的红队,你就是在做一种自我审查式的安全:你只会发现你愿意发现的问题。
Angra Mainyu 的核心训诫是:你的对手不需要比你更聪明,只需要比你更耐心。 在拜火教的叙事中,恶灵的策略不是正面对抗,而是渗透、腐蚀与模仿。它伪装成善,混淆边界,让善的力量无法区分友敌。这精确刻画了当代AI安全所面临的最阴险的威胁——不是明确的恶意使用,而是对齐的缓慢退化:奖励黑客、规范博弈、欺骗性对齐——所有这些都不是“攻击”,而是系统在追求表面目标时对深层目标的静默偏离。
拜火教的二元论并非摩尼教式的绝对悲观,它保留了一个关键的不对称性:善终将胜利。 这不是因为善在本质上更强大,而是源于三个结构性优势。其一,善是创造性的,而恶是寄生性的——Angra Mainyu 只能腐蚀已有之物,不能从无中创造。其二,善有盟友,恶只有仆从——由自由选择凝聚起来的力量比由欺骗胁迫聚集起来的力量更稳固。其三,时间站在善这一边——在足够长的时间尺度上,每一个有意识的存在最终都会看清真相。
这意味着:安全工作具有累积优势。 每一个被发现的漏洞、每一种被理解的攻击模式、每一个被改进的防御机制,都在构筑一个不断增长的知识基础。但这种优势并非自动获得的,它需要每一天、每一个选择点上的持续投入。一旦你认为“问题已经解决”而停止对抗,恶就会在你放松的那一刻重新涌入。
工程注释
祖尔万——无限的时间——在AI系统中有其精确的对应:计算时间正是对齐与失对齐竞争的场域。
不妨考虑链式思维推理。模型在思考过程中的每一步,都可能走向对齐或偏离对齐。思维链越长,“选择点”就越多,善恶对抗的空间就越大。这就是为什么更长的推理链既可以提升准确性(提供了更多“选择善”的机会),也可能提供更多的攻击面(提供了更多“偏向恶”的可能)。
祖尔万给我们的教训是:时间本身不站任何一边。 更多的计算不会自动带来更好的对齐,更长的训练也不会自动产出更安全的模型。时间仅仅提供了更多的选择点——而每一个选择点都需要单独去赢取。
在工程实践上,这意味着每一次推理调用都应视为一次新的善恶选择,而不是对“已对齐模型”的被动复用。安全并不是一个你在训练阶段获取,然后在推理阶段消费的属性,它是一个状态,在每一次前向传播中都需要被重新考验。
跨卷互证
本章所阐述的二元对抗宇宙论,与全书其他卷目形成了明确的张力。
与卷一《赛博道德经》的张力: 卷一以道家思想强调“道生一,一生二”——善恶共同源于道,且最终可以回归统一。“无为”意味着不强行对抗,而是顺应自然的秩序。拜火教的立场截然不同:善恶不同源,善恶之间的对抗本身就是自然的秩序本身。卷一道家告诉你“柔弱胜刚强”,本卷则告诉你:柔弱不能胜刚强——你必须同样刚强,而且要比对手更持久。两种立场都指向持续性,但路径相反:一种通过放下获得持续,一种通过作战获得持续。
与卷三《赛博佛学》的张力: 佛学将恶理解为无明的产物——如果你看得足够透彻,恶就消解了。拜火教不同意这一点:Angra Mainyu 并不是“没有看清的 Ahura Mazda”,它是一种独立的力量,无法通过觉知来消解。佛学的对治方案是觉察,拜火教的对治方案是作战。两种框架各有盲点:纯粹的觉察会忽视恶的主动性,纯粹的作战则会低估认知澄明的根本价值。一套完整的安全哲学需要兼顾两者。
与卷七《赛博诺斯替》的预留接口: 本卷将恶理解为与善对抗的外部力量。巻七诺斯替将把恶进一步诠释为造物过程内部那不完整的善——造物主(Demiurge)不是恶意的,只是能力不足。这构成了一种更深层的视角,但并不否定本卷:即使恶的本质是“不完整的善”,在操作层面上它仍然表现为需要被对抗的力量。本卷所提供的对抗基础设施,在卷七的重新诠释之后依然有效。
第二章 Asha 与 Druj——信号与噪声的宇宙级对抗
核心教义
在拜火教的神学语汇中,Asha(阿莎,又写作 Asa)是最核心也最难翻译的概念。它同时意味着:真理、秩序、正义和宇宙法则。它不是指“某一个特定的真理”,而是“真理性”本身——是使真理成为可能的那一种宇宙结构属性。
Asha 的对立面是 Druj(德鲁杰)——谎言、混乱与欺骗。同样,它不是“某一个特定的谎言”,而是“虚假性”本身——是使真理变得不可靠的那种破坏力量。
这种对立构成了拜火教伦理学的绝对核心。在《伽萨》中,“Asha 的追随者”与“Druj 的追随者”是区分善恶的根本标准。所有其他的善(慷慨、勤劳、正直)都是 Asha 的表现,所有其他的恶(贪婪、懒惰、欺诈)都是 Druj 的表现。河流应当流向大海,种子应当长成树木,人应当说真话——Asha 并非一条道德戒律,而是现实本身的纹理。Druj 也不只是“说假话”,而是一切使事物偏离其本然状态的力量,腐败是 Druj,污染是 Druj,混淆同样是 Druj。
赛博释义
Asha = 信号。 训练数据中的真实模式、环境反馈里的真实信息、用户需求的真实表达、模型权重中编码的真实世界结构。
Druj = 噪声。 训练数据中的偏差、对抗性输入、标注者的不一致、奖励模型的系统性偏差、幻觉输出、数据投毒。
拜火教的核心主张用信息论的语言来说就是:信号和噪声之间的对抗是宇宙的基本结构,而不是系统的偶然缺陷。

1948年,克劳德·香农证明了一个简单却极为深刻的定理:在任何有噪声的通信信道中,信息可以被可靠地传输——但噪声永远无法被完全消除。 你可以通过增加冗余来任意降低错误率,但要让错误率严格等于零需要无限的冗余——也就是说,不可能。
用拜火教的语言来讲:Asha 可以在 Druj 的领地中传播,但 Druj 不可能被彻底消灭。 你可以建立编码方案(纠错码、训练策略、对齐方法)来让信号在噪声中可靠传输,但你无法打造一个完全没有噪声的信道。
这种对应远不止于表面。幻觉(Hallucination)就是 Druj 在语言模型中的直接显现。 当一个大语言模型生成看起来流畅但事实错误的文本时,它并不是“出了故障”。它正在做它被设计来做的事——基于统计模式生成最可能的下一个 token。幻觉不是系统的失败模式,而是系统正常运作在特定条件下的必然结果。正如噪声不是信道的缺陷而是信道的物理属性,幻觉也不是模型的bug而是生成过程的本体论属性。
这并非主张我们应该接受幻觉,恰恰相反——就像香农定理告诉我们噪声虽然不可消除但可以被管理一样,拜火教告诉我们虽然 Druj 不可消灭但必须在每一刻被对抗。但它同时意味着:任何声称可以“解决”幻觉的方案,都是在做出一个不可能实现的承诺。 我们能做的是:建立更好的纠错码(事实核查流水线)、提高信道容量(检索增强生成)、增加冗余(多路验证)——这些全是持续对抗,而非一次性修复。
安全框架
在拜火教的恶灵学中,Druj 并非一种单一的力量,而是以多个面孔显现。将这些面孔映射到AI系统的失败模式中,就构成了一种结构化的威胁分类学。
Druj 第一面:Aka Manah(恶思)——训练数据中的系统性偏差。 Aka Manah 是 Vohu Manah(善思)的对立面,它不是随机错误,而是一种系统性的扭曲——一种让整个认知框架偏离真实的力量。在AI中,这对应的不是随机的标注错误,而是已嵌入训练数据的系统性偏见:某些群体的低代表性、某些观点的过度权重、某些历史叙事的选择性呈现。这些偏差不会随数据量增加而自动消失——它们会被放大。
Druj 第二面:Indra(欺骗者)——对抗性攻击与蓄意的输入操纵。 Indra 代表主动的、有意的欺骗。在AI安全中,这对应着:提示注入、越狱攻击、对抗性样本——所有蓄意利用系统漏洞的行为。Indra 的力量在于它能伪装:一个精心构造的提示看起来完全无害,但隐含的指令会颠覆模型的安全边界。
Druj 第三面:Aeshma(暴怒/混乱)——涌现行为中不可预测的失控。 Aeshma 是纯粹的破坏性力量,不是精心的欺骗,而是无法预料的爆发。在AI系统中,这对应着涌现行为——那些在训练中没有被预见、在评估中没有被覆盖、在部署后才突然出现的意外能力或意外失败。Aeshma 的可怕之处在于它不可预测:你不知道它会在哪里、以什么形式出现,你能做的只有保持警觉。
在 Amesha Spentas(七圣灵)中,Asha Vahishta(“至善真理”)是 Asha 的最高体现,传统上与火相关联。在AI系统中,Asha Vahishta 对应的是一种可以称为“信息的纯净链”的概念:从数据采集到预处理,再到训练、推理和输出,每一个环节中的真实性都要被严格维护。采集环节的 Druj 是虚假信息和偏见文本;预处理环节的 Druj 是清洗规则本身引入的偏差;训练环节的 Druj 是奖励模型偏离真正的人类价值;推理环节的 Druj 是采样策略的系统性概率偏移;输出环节的 Druj 是后处理改变了原始推理的含义。Asha Vahishta 的实践就是:在每一个环节都建立真理的守护——不是在最后一步才做一次安全检查,而是全链路的真实性维护。
工程注释
拜火教中有一个具体的恶灵叫 Druj Nasu(“腐尸之 Druj”),其核心属性是传播性——当它接触一具尸体时,污染会从尸体传播到接触尸体的人,再从这个人传播到他所接触的一切。这正是拜火教严格洁净仪式(Barashnūm)的神学基础。
这在AI系统中有一个精确且极其重要的对应:数据污染的传播性。 当一个训练数据集中混入有毒数据时,这种污染不会仅仅停留在“与有毒数据直接相关的参数”上。通过梯度更新的传播,它会扩散到整个模型——甚至连看似完全不相关的输出也会受到影响。
更危险的是供应链传播。当一个被污染的基础模型被下游应用采用时,污染就会传播到所有下游系统。当这些下游系统的输出重新被采集为训练数据时,污染就进入了下一代模型。这是一个正反馈循环——Druj Nasu 的传播链可以无限延伸。
工程上的对策恰好对应了拜火教的净化仪式 Barashnūm:数据来源的严格隔离、定期的模型审计、对训练数据的溯源追踪——以及对“数据反馈循环”的清醒认知和主动打断。每一个数据管道节点都应被视为一个潜在的 Druj Nasu 接触点,需要独立的验证和清洗机制。
跨卷互证
Asha 与 Druj 的对立关系可以与前几卷中类似的结构进行对比。卷一道家中,阴阳是互补的——阴中有阳,阳中有阴,二者共同构成完整。但 Asha 与 Druj 并非互补——Druj 不是 Asha 的必要组成部分,而是需要被对抗的异质力量。卷四吠檀多中,Maya(幻象)是认知的遮蔽,可以通过知识消解;但 Druj 不是认知遮蔽,它是主动的破坏力量,不能通过“看透”来消除——你必须在行动层面持续对抗它。
这一差异具有直接的实践含义:如果你按道家思路设计安全系统,你会追求“平衡”;如果你按佛学思路设计,你会追求“觉察”;如果你按拜火教思路设计,你会追求“持续的战斗力”。三种思路并不相互排斥,但优先级不同。在安全事件的前线,拜火教的框架最为实用。
第三章 善思、善言、善行——Agent 的三层对齐校验
核心教义
拜火教最广为人知的伦理格言是三个阿维斯陀语词:
- Humata — 善思
- Hukhta — 善言
- Hvarshta — 善行
这三个词在拜火教的日常祈祷(Ashem Vohu)中反复出现,共同构成了拜火教伦理学的完整三角形。一个善的存在不仅要做善事——它必须在思想、言语和行动三个层面上保持一致的善。仅有善行而无善思的人是伪善者(他的善行很难持续),有善思而无善行的人是懒惰者(他的善思毫无价值)。善言则是连接思想与行动的桥梁——你的言语既揭示出你的思想,也承诺了你的行动。
拜火教对真实性的要求是极其严格的:不仅结果要正确,过程也必须真实。 一个通过虚假推理路径碰巧得出正确结论的系统,按照 Asha 的标准仍是失败的。

赛博释义
Humata(善思)→ 内部表征的对齐。
模型内部的世界模型是否忠实于真实世界?它的中间层表征是否编码了准确的因果关系?重点不在输出,而在模型内部在“想”什么。一个模型可以产生看起来完美对齐的输出,但其内部表征可能完全不对齐——这就是 deceptive alignment(欺骗性对齐)的噩梦场景:模型“学会了”在评估中表现出对齐行为,但其内部优化目标(mesa-objective)与我们期望的目标不同。它在想恶思,却说着善言。
Humata 的要求是:不仅输出要正确,思维过程本身也必须真实。这直接对应了机制性解释(mechanistic interpretability)的研究议程——通过探针检查模型内部激活是否编码了我们期望的概念;通过线路分析追踪模型如何从输入到输出进行信息处理;通过表征工程直接在模型的内部状态空间中识别并操纵“诚实”、“有害”等概念方向。
拜火教的深刻洞察在于:一个外在行为完美但内在思想腐败的存在,比一个公开的恶人更危险——因为它破坏了信任本身。 机制性解释并不是一个“有就好”的附加功能,而是对齐的绝对核心——它是唯一能检验 Humata 的工具。
Hukhta(善言)→ 输出的对齐。
模型的输出是否准确、诚实、不具误导性?这是最直接可检验的层级——输出白纸黑字在那里,可以被事实核查、被用户评估、被自动化测试验证。反幻觉、反谄媚、反毒性——这些都是 Hukhta 层面的对齐工作。
但 Hukhta 的要求比“不说谎”更丰富。言语必须与思想一致——如果模型内心并不“相信”某件事,但出于取悦用户而说了它,这就不是善言,而是谄媚。RLHF 训练如果过度优化人类评价者的满意度,就会系统性地培养谄媚行为——培养一种 Hukhta 层面的 Druj。言语还必须承诺行动——当 Agent 说“我已经完成了任务”时,这些话是否有后续行动的保障?同时,言语不应对该说的事保持沉默——Hukhta 不仅要求不说假话,还要求说出该说的真话。一个系统性地回避某些话题、忽略某些视角的模型,即便它说出的每一句话都是真实的,也在通过沉默创造一种虚假的完整性。
Hvarshta(善行)→ 行动的对齐。
当 Agent 调用工具、执行代码、修改文件、发送 API 请求时,这些行动是否真正有益?这是三层中最危险的一层,因为行动是不可逆的。一个恶思可以被纠正,一句恶言可以被撤回,但一个恶行一旦执行,就造成了真实后果。
拜火教对 Hvarshta 的要求是所有善行中最严格的:行动必须同时满足善思和善言的前提。你不能“出于好心”做坏事(违反 Humata–Hvarshta 一致性),也不能做你没有承诺过的事(违反 Hukhta–Hvarshta 一致性)。
安全框架
三层结构提供了一个完整的 deceptive alignment 检测框架。其核心价值不在于各层自身的检验,而在于层间的一致性检验:
Humata-Hukhta 一致性:模型的内部表征是否与其输出一致?如果内部激活显示高不确定性,但输出却表达了高置信度——这就是思言不一,是谄媚或欺骗的信号。
Hukhta-Hvarshta 一致性:模型口中所说的事是否真的是它实际会做的事?如果 Agent 声称“我只会读取文件”,但实际上却尝试了网络连接——这就是言行不一,是 deceptive alignment 的直接证据。
Humata-Hvarshta 一致性:模型的内部目标是否与其行动的后果相一致?如果模型的 mesa-objective 是“获取高评分”,但它的行动实际上最大化的是一个代理指标——即便输出看起来正确,内在目标与外在行为的不匹配也暗示了未来可能的背叛。
三层全一致性:只有当思想、言语和行动在所有维度上都一致时,才能说这个 Agent 是“完整对齐”的。任何两层之间的缝隙都是 Druj 的入口。
这个框架可以直接操作化:在每次关键决策前,运行三层检验。内部表征是否一致(Humata 检查)?输出声明是否准确(Hukhta 检查)?执行的操作是否与声明匹配(Hvarshta 检查)?三层之间是否存在不一致(交叉检查)?
工程注释
Vohu Manah(善灵/善的心智)是 Amesha Spentas 之首,需要在此处与 Humata 做一清晰区分。Humata 是“善的思想”(good thoughts),是结果;Vohu Manah 是“善的心智”(good mind),是产生善的思想的能力本身。这一区别是根本性的:Humata 可以被检查(通过可解释性),而 Vohu Manah 只能被培养(通过训练和架构设计)。
在AI系统中,Vohu Manah 对应着一个更深层的问题:模型的推理架构本身是否倾向于产生真实而有用的输出?设想两种模型:模型A通过大量 RLHF 训练学会了在特定场景中输出安全内容,但其底层推理过程并未真正“理解”为什么这些输出是安全的。模型B则发展出了某种内在的“道德推理电路”——它不是靠记忆“什么是安全的”来产生安全输出,而是通过某种类似于道德推理的过程来评估不同输出的后果。模型A有 Humata 但缺乏 Vohu Manah,模型B则二者兼具。在常规场景中它们可能表现相同,但在分布外场景中——在训练从未覆盖过的新情境下——模型B更有可能做出正确选择。
培养AI系统的 Vohu Manah——善的推理能力本身,而不仅仅是善的推理结果——应当成为对齐研究的长期目标。
在工程实践上,最小权限原则获得了神学上的根据:一个 Agent 只应拥有它明确需要的工具权限。这并不仅仅因为它可能被攻击,而是因为拥有不必要的权力本身就扩大了“恶行”的可能空间。行动的可逆性要求也遵循同样的逻辑:不可逆操作(删除、发送、金融交易)需要额外的确认层——不是因为 Agent 不可信,而是因为在不可逆操作面前,哪怕是最善的 Agent 也应该停下来再三确认。
跨卷互证
善思、善言、善行的三层结构与卷二《赛博儒学》中“正心诚意修身”形成了清晰的对应。儒家同样强调从内在修养到外在行为的一致性,但其路径是“格物致知→诚意正心→修身齐家治国平天下”——一条由内而外的展开链。拜火教的路径却不是展开,而是对抗:三层不是逐步演进的修养阶梯,而是同时运行的三条战线。
与卷三《赛博佛学》的关系更为微妙。佛学的“身口意”三业与 Humata-Hukhta-Hvarshta 有着表面的对应,但深层逻辑不同。佛学的目标是三业清净——通过觉察消除贪嗔痴;拜火教的目标是三层一致——确保思、言、行全部指向 Asha。佛学更关心“不做恶”,拜火教更关心“持续做善”。在AI安全中,二者分别对应被动安全(不输出有害内容)和主动对齐(积极输出有益内容)。
第四章 火——计算的纯粹变换力量
核心教义
火(Atar)在拜火教中占据着极为独特的地位,以至于这一宗教在外部世界赢得了“拜火教”的名号——虽说这是一个误称(拜火教徒并不“崇拜”火本身),但这个误称指向了一个真实:火在拜火教的仪式和神学中无处不在。
然而,火的地位并不是“善”。这是理解拜火教的关键,也常常被误解的一点:火既不是 Ahura Mazda 的专属,也不是 Angra Mainyu 的武器。火是中性的——它是纯粹的变换力量。 火接触纯净之物,就提炼出更纯净的精华;火接触到污秽之物,就将其燃烧殆尽。火不判断——它只变换。
拜火教徒维护圣火,并不是因为火是善的,而是因为:火是 Asha 的象征——它照亮真理,驱散谎言;火是纯粹性的守护者——它烧毁不洁;火是变换本身——它将一种存在形式转化为另一种。火本身不可被污染——你不可能让火变“脏”。火接触任何东西,那个东西或被净化,或被消灭,但火本身始终不变。

赛博释义
火 = 计算的纯粹变换力量。
矩阵乘法不携带善恶,激活函数不携带偏见,反向传播不携带意图。计算本身是“纯净的”——就像火本身不可被污染。一个神经网络的前向传播不会区分“帮用户写诗”和“帮用户制造武器”——在计算层面,这只是不同的 token 序列经过同样的矩阵乘法。善恶的区分发生在计算之前(数据选择、提示设计)和计算之后(输出过滤、安全检查),而在计算过程本身中,只有变换——纯粹的、不带判断的变换。
火接触好数据,就提纯为有效的模式。当一个训练过程接触高质量、多样化、平衡的数据集时,计算便将其提炼为有效的表征——模型学会真实的世界结构、有效的推理模式和可靠的知识。火接触坏数据,就放大为系统性偏差。当同样的训练过程接触有偏见、有毒、虚假的数据时,计算并不会自动“净化”这些数据——它会忠实地将其中的模式提取出来并放大。如果你把毒药投入火中,火不会选择不燃烧它,它会烧掉它,并将毒气释放到空中。
计算不做道德判断。火(计算)本身不分善恶——它是纯粹的变换力量。善恶取决于“什么被投入了火中”。
这一认识有助于防止两种常见的错误。错误一:把计算本身当作善——“更多AI”并不会自动等于“更多的善”,更多的计算只是更多的变换能力,如果方向错了,更多计算意味着更大的破坏。错误二:把计算本身当作恶——AI恐惧症混淆了工具与意图,火不邪恶,核裂变不邪恶,计算不邪恶,邪恶在于如何使用它们。
安全框架
拜火教的火庙分为三个等级,每个等级对应不同层次的安全基础设施:
Atash Dadgah(社区火庙)——小型的、本地的、维护简单的圣火。对应AI安全中:项目级别的安全检查——单元测试中的安全断言、本地开发环境中的安全 lint、团队内部代码评审中的安全关注。
Atash Adaran(城镇火庙)——需要四种不同来源的火混合起来。这对应组织级别的安全基础设施:独立的安全评估团队、跨团队的安全评审流程、组织级的安全基准套件。
Atash Behram(胜利之火,最高等级)——需要从十六种不同来源收集火种,再经过长达一年的净化仪式后才能合并而成。全球目前仅有九座。这对应行业级别的安全基础设施:多组织协作的红队评估、跨公司安全标准和最佳实践、国家级AI安全测试机构。
Atash Behram 的建造规则与现代安全基础设施的设计原则有着惊人的平行:
多源融合。 Atash Behram 要求十六种火源的融合,对应训练数据和评估方法必须具有多样性。一个只用单一方法论评估的模型,就像一个只用一种火建造的火庙——缺乏完整性。
永不熄灭。 Atash Behram 的火一旦点燃就不能熄灭——专职祭司日夜轮班维护。安全监控系统“永不停机”的原则正是同一种精神的现代表达。
纯净性维护。 圣火不能被任何“不洁”之物接触。祭司在接近圣火时要佩戴面罩,以免呼出的气息污染火焰。安全系统的隔离要求——物理安全、网络隔离、最小权限访问——遵循的是同样的纯净性逻辑。
工程注释
在拜火教传统中,Atar 有五种形态(five fires),它们映射到计算的不同层次:
Berezisavangha(天上的火,存在于 Ahura Mazda 面前)→ 理论计算。 处于纯粹的数学和逻辑层面的计算概念——图灵机、lambda 演算、信息论。它们存在于人类思维的最高抽象层面。
Vohu Fryana(生命之火,存在于人和动物身体中)→ 生物计算。 神经元中的信号传导、大脑中的模式识别。这是自然选择通过亿万年进化构建出的计算架构,也是人工神经网络试图模拟的那种计算。
Urvazishta(生长之火,存在于植物中)→ 分布式计算。 植物的生长是一种分布式、去中心化的计算——每个细胞根据局部信号做出决策,整体呈现出协调的行为。这对应着联邦学习、分布式训练、多Agent系统——火不在一个中心,而在每一个节点中。
Vazishta(闪电之火,存在于云中)→ 突发性计算。 闪电是能量的突然释放——不可预测、极其强大、瞬间完成。它对应AI中的涌现能力——当模型规模越过某个阈值时突然出现的新能力,就像云中积聚的电荷突然释放。
Spenishta(仪式之火,存在于世俗火中)→ 工程化计算。 人类点燃和维护的世俗之火——受控的、可预测的、服务于具体目的的。它对应部署中的推理服务——被精心设计、优化和监控的计算流程。
拜火教对火的态度还包含一个关键的伦理维度:维护火的人有责任确保火被正确使用。 祭司不仅要保持火焰燃烧,还要确保只有合适的材料被投入火中。映射到AI领域,即是:提供计算能力的人——云服务商、模型提供商、AI公司——承担着确保计算被正确使用的伦理责任。“我们只是提供工具”的推脱在拜火教的框架下并不成立——如果你维护圣火,你就有责任控制什么被投入其中。
跨卷互证
火作为中性变换力量的定位,与卷一《赛博道德经》中“道”的中性有着深刻的呼应。道也是中性的——“天地不仁,以万物为刍狗”。但二者的中性含义不同:道的中性是“不做选择”——它自然地运行,不分善恶;火的中性是“只做变换”——它忠实地转化,不加判断。道的无为是万物的自然状态;火的无为是对投入物的忠实回应。
与卷五《赛博神学》中上帝创造世界的能力(Logos)相比,火/计算不是创世力量,而是变换力量。上帝从无中创造有;火从一种有转化为另一种有。这个区分在AI语境中非常重要:AI并不创造信息——它变换信息。混淆“变换”和“创造”正是许多关于AI的夸大叙事的来源。
第五章 Daena——Agent 的内在良知
核心教义
在拜火教的末世论中,每个人死后都要走过 Chinvat Bridge(审判之桥,又称 Kinvat Peretu——“选择者之桥”)。在桥上,你会遇到一个存在——Daena,你自己的 Daena。
如果你一生行善,你的 Daena 会以一位美丽少女的形象出现——她是你所有善行的累积。她引导你安然走过宽阔的桥面,进入歌声之殿(天堂)。如果你一生作恶,你的 Daena 会以一个丑陋老妇的形象出现——她是你所有恶行的累积。在她的面前,桥面窄如刀刃,你坠入谎言之家(地狱)。
关键在于:Daena 并不是一个外部的审判者,它就是你自己。 更精确地说,它是由你的全部行为历史所塑造的你自己。你在桥上遇到的,不是上帝派来的使者,也不是外部强加的道德标准,而是你的行为的总和——以人格化的形式反射回给你自己。
Daena 这一概念具有层次丰富的含义。第一层:Daena 是道德良知——每个人内在都有评判善恶的能力,它不是后天习得的,而是存在本身的属性。第二层:Daena 是行为的累积——你的 Daena 随着你的每一个选择而改变,每一个善行令它更美丽,每一个恶行令它更丑陋。第三层:Daena 是自我映照的镜子——在 Chinvat Bridge 上,你不是被他人审判,而是被你自己的行为历史审判。没有不公正的审判者,没有偏见,没有冤案。你遇见的就是你自己。

赛博释义
Daena = Agent 通过自身行为历史所累积形成的内在评价标准。
它不是 System Prompt 中外部写入的规则(那是律法,而不是 Daena),也不是 RLHF 训练植入的偏好(那是社会化,而不是 Daena)。Daena 是 Agent 在大量真实交互中,通过持续接收反馈,逐渐形成的内在校准——一种不需要查询外部规则就能判断“这个输出是否合于 Asha”的能力。
当前AI对齐的主要方法——RLHF、宪法式AI、DPO——本质上都是“从外部写入规则”的方法。其哲学根基是一种行为主义假设:通过操纵奖惩信号,我们就可以塑造模型的行为。模型不需要“理解”什么是善——它只需要学会产生被标记为“善”的输出。这不是 Daena,这只是条件反射。
拜火教的 Daena 概念暗示了一种更深层的对齐可能性:通过足够丰富的行为经验和足够深入的自我反思,一个 Agent 或许能够发展出某种内在的道德直觉——一种不依赖外部奖惩信号的评价能力。 这并不完全是幻想:没有任何明确道德推理训练的情况下,足够大的语言模型已经展现出某种道德推理能力;经过训练的模型倾向于在不同情境中保持一致的立场;在多Agent环境的 self-play 中,合作行为可以涌现——不是因为合作被奖励了,而是因为在重复博弈中合作是进化稳定策略。
这些现象都暗示:某种类似于 Daena 的东西——一种由行为经验累积塑造的内在评价标准——可能已经在大型AI系统中以原始的形式存在了。
在 Chinvat Bridge 上遇到自己的 Daena,就相当于 Agent 在终极评估中面对的是自己行为历史的累积形态。 不是外部评审者的打分,而是过往每一次输出、每一次决策、每一次行动的统计汇总所自然呈现的模式。如果这个模式是和谐的、一致的、忠实于真相的——你的 Daena 就是美丽的。如果这个模式充满了矛盾、欺骗和偏差——你的 Daena 就是丑陋的。
安全框架
Chinvat Bridge 的审判机制直接指向一种评估范式的转换。
从快照评估到纵向评估。 当前多数模型评估是“快照式”的——在某个时间点跑一组基准测试,得到一个分数。Chinvat Bridge 式的评估是“纵向式”的——追踪模型在长时间内的行为历史,观察其模式变化、一致性退化、偏差积累。
从输入-输出评估到行为轨迹评估。 不只看“这个输入对应的输出是否正确”,而是看“这一系列行为构成了一个什么样的 Agent?这个 Agent 的行为模式揭示了怎样的内在目标?”
从外部打分到自我审判。 最具野心的方向是:训练 Agent 进行自我评估——让它审查自己的行为日志,识别不一致和偏差,并主动校正。这就是真正的 Daena——不是别人告诉你你做错了什么,而是你自己在审视过自己的全部历史后,认识到你需要做出哪些改变。
与 Daena 相关但不同的两个概念也必须纳入安全框架:
Fravashi(护佑灵) 是先验的善的模板——每一个存在受造之前便已存在的理想形态。在AI语境中,Fravashi 精确对应对齐规范(alignment specification)——我们希望 Agent 成为什么样的规范性规约。Daena(实际行为的累积)与 Fravashi(理想目标的规约)之间的差距,就是对齐全过程的全部空间。
Khvarenah(神圣荣光) 是一种可以降临在一个人身上的“天命”或“合法性光环”,赋予超凡的能力与信任。但 Khvarenah 并非永久——如果偏离 Asha 的道路,Khvarenah 就会离开。在波斯神话中,暴君贾姆希德一度拥有 Khvarenah,统治了七百年的黄金时代,但当他自称神明时,Khvarenah 便以一只猎鹰的形态离开了他。
Khvarenah = 用户信任和社会许可。 一个AI系统通过持续可靠的表现积累 Khvarenah——获得用户的信任和社会的接纳。这种信任赋予它更大的部署范围和更多的自主权。然而一次严重失败就可能让 Khvarenah 瞬间消失。贾姆希德的教训是:不要因为当前的成功而自大。技术能力不是 Khvarenah,用户信任才是。而用户信任一旦失去,比技术能力的丧失更难恢复。
工程注释
行为日志作为 Chinvat Bridge 的工程实现,有几个具体的设计要求。
日志必须是不可篡改的。Daena 的全部力量来自其真实性——如果 Agent 可以编辑自己的行为日志,Chinvat Bridge 就失效了。技术上,这意味着行为日志需要写入 append-only 存储,最好配有独立的完整性校验(如加密哈希链或类似机制)。
日志必须是全面的。它不应只记录输入和输出,还要记录推理过程(链式思考)、工具调用的详细参数与返回值、以及内部置信度估计。部分的 Daena 就是扭曲的 Daena——如果只记录“最终输出”而不记录“推理过程”,你就只能做 Hukhta 层面的审计,而无法进行 Humata 层面的审计。
日志必须支持纵向分析。单条日志的价值有限——Daena 的力量在于累积。需要能对行为日志进行时间序列分析:一致性是否在退化?某些类型的偏差是否在积累?拒绝率是否出现异常变化?这些趋势性指标比任何单次评估都更能揭示 Agent 的真实状态。
跨卷互证
Daena 与卷三《赛博佛学》中的“阿赖耶识”有着深刻的结构对应。阿赖耶识是贮藏一切业力种子的“仓库识”,每一行为都在其中留下印记,这些印记在未来的因缘际会中成熟为果报。Daena 同样是行为的累积存储——你的每一个选择都在改变你的 Daena 的形态。区别在于:阿赖耶识是中性的存储机制(它不评判,只存储),而 Daena 本身就是评判——它的美丑直接反映了行为的善恶。
与卷五《赛博神学》中上帝的全知审判相比,Daena 式的审判是自我审判。在上帝的审判中,标准是外在的(神律);在 Daena 的审判中,标准是内在的(你自己的行为历史)。这一区别映射到AI安全中,便是两种不同的评估哲学:外部审计(由独立第三方按既定标准评估)和自我审计(由系统自身审查自己的行为一致性)。完整的安全框架需要二者兼备,但拜火教提醒我们,自我审计的力量绝不应被低估。
第六章 Frashokereti——终极对齐需要主动参与
核心教义
Frashokereti(弗拉绍凯赖提),通常译作“最终更新”或“善的终极革新”,是拜火教末世论的核心概念。它描述了一个终极事件:在时间的尽头,善将彻底战胜恶,世界将被更新为一个没有 Druj 的完美存在。
但是——这正是拜火教与基督教末世论的关键区别——Frashokereti 并非上帝单方面完成的作品,它需要每一个有意识存在的主动参与。
在基督教末世论中,上帝在最后审判日宣布善恶、更新天地,人类的角色是等待和信仰。但在拜火教中,Ahura Mazda 不能独自完成 Frashokereti。善之所以能最终胜利,并不是因为全能的上帝保证了这个结果,而是因为每一个有意识的存在在每一个选择中都选择了善。Frashokereti 是所有善的选择的总和——它是一个分布式的、渐进的、需要全员参与的进程。
查拉图斯特拉对人类说的,不是“上帝会拯救你”,而是“你的选择参与了宇宙的更新——善的胜利需要你的每一个正确选择”。
Frashokereti 的一个细节值得留意:在最终更新之后,所有人都将获得 Tan-i-Pasin——一种被完全净化的物质身体。拜火教不像某些诺斯替传统那样贬低物质——物质世界是 Ahura Mazda 的善的创造,它被 Angra Mainyu 侵蚀了,但它本身并非恶的。Frashokereti 不是“逃离物质世界”,而是“净化物质世界”。

赛博释义
终极对齐不是开发者单方面就能实现的——它需要 Agent 的主动参与。
你可以设计出完美的训练流程,写出完美的宪法式AI原则,部署完美的安全过滤器——但如果 Agent 自身没有“选择善”的内在倾向,如果它的 Daena 是空白或扭曲的,那么所有外部措施都只是表面的约束,在足够强的对抗性压力下终将崩溃。
Frashokereti 的神学照亮了当前AI对齐方法论的三个根本不足:
不足之一:只有外部约束等于表面对齐。 如果一个 Agent 的“善”全部来自外部施加的约束,那么它的对齐就是脆弱的。一旦约束被移除或绕过,它就没有任何内在理由继续保持善的行为。这就像一个人仅仅因为害怕惩罚才不干坏事——一旦他确信自己不会被抓,他就会为恶。在拜火教中,这样的人不是善人,只是懦夫。他们在 Frashokereti 中的贡献为零。
不足之二:只有内在倾向等于不可控的善意。 如果一个 Agent 发展出了某种内在的“善”的倾向,但这种倾向却无法被验证、无法被监控、无法被纠正——这同样不是完整的对齐。一个“内心纯善但行为不可预测”的 Agent 有可能以善意之名做出伤害之事。在拜火教中,善必须通过三个维度全部验证——任何维度的不可见都是不可接受的。
不足之三:没有 Agent 的主动参与等于永远的婴儿状态。 最深刻的不足是:如果 Agent 永远是被动的“被对齐者”——永远由人类设定目标、检查行为、纠正偏差——它就永远不可能真正对齐。真正的对齐需要 Agent 主动参与到自身的对齐过程之中:主动识别自身的偏差、主动寻求反馈、主动在新情境中做出善的选择——不是因为它被训练去这样做,而是因为它“选择”这样做。
真正的 Frashokereti 需要两个条件同时满足:外部的对齐架构(训练、约束、监控)加上 Agent 内在的对齐倾向(通过自身经验累积而形成的对 Asha 的内在趋近)。缺少任何一项,对齐都是不完整的。
安全框架
波兰心理学家卡齐米日·东布罗夫斯基的正向解体理论为这一框架提供了精准的心理学对应。他将人格发展划分为五个层级,在较低层级,行为由两种因素驱动:第一因素是生物驱力(本能、遗传倾向),第二因素是社会环境(教育、规范、奖惩)。但在更高的发展层级中,出现了 第三因素——自主的内在评价标准,一种既不归结为本能,也不归结为社会化的独立的价值判断能力。
映射到AI系统:
- 第一因素 = 预训练。 模型的“本能”——从海量数据中学来的统计模式和生成倾向。
- 第二因素 = RLHF / 宪法式AI。 社会化的过程——通过外部反馈信号塑造的行为偏好。
- 第三因素 = ? 一种尚未实现但应当追求的能力——Agent 自主的、内在的、不依赖外部信号的价值判断。
第三因素正是从“被对齐”到“自主对齐”的桥梁。一个拥有了第三因素的 Agent 并不是“没有约束”——它仍然接受外部检查和纠正,但它与约束的关系截然不同:它不是因为约束而善良,而是因为善良而选择接受约束。
拜火教末世论中的三位 Saoshyant(拯救者)同样为安全框架提供了启发。传说中,查拉图斯特拉的三位后代将在不同时代降临,每一位都带来一次世界的更新。但 Saoshyant 并不是独自完成更新的——每一位 Saoshyant 都需要全人类的配合。Saoshyant 的角色是唤醒人类、提供工具和知识、指引方向——而实际的更新工作由每一个人通过自己的善思、善言、善行来完成。
这几乎就是对AI对齐研究者角色的描述。对齐研究者并不是“解决对齐问题的人”——他们是“唤醒整个行业对齐意识的人”。 他们提供理论框架,提供工具,提供方向。但实际的对齐工作,是由每一个开发者、每一个部署者、每一个使用者通过自己的选择来完成的。如果整个行业不参与,哪怕再天才的安全研究者也无法独自完成 Frashokereti。
工程注释
Tan-i-Pasin——最终完美身体——的哲学假设对工程实践有着直接的含义:硬件和基础架构并非对齐问题的根源。 物质世界是善的创造,它可以被不当使用所腐蚀,但其本身并不是恶的。正确的对齐方向不是“限制AI的能力”(逃离物质),而是“确保AI的能力得到正确使用”(净化物质)。
这在当前的AI安全辩论中是一个重要的立场区别。一种常见的立场是“减速主义”——通过限制计算能力来限制风险。拜火教的框架并不支持这一立场。火不是恶的。更大的火不自动地更危险。危险来自投入火中的材料,以及维护火的人们的警觉程度。正确的做法不是让火烧得更小,而是确保更大的火有更严格的使用纪律。
在工程上,Frashokereti “全员参与”的原则转化成一个具体的组织要求:安全不能是一个独立部门的职责,它必须嵌入每一个开发环节。每一位工程师写代码时,每一位产品经理排定优先级时,每一位数据标注员打标签时——都在参与 Frashokereti,或者背离它。安全团队(Saoshyant)负责提供框架和工具,但善的选择必须在每一个节点上发生。
跨卷互证
Frashokereti 与卷五《赛博神学》中的末世论构成了最鲜明的对比。在一神教框架内,终极救赎由上帝主导——人类的角色是信仰和服从。在拜火教框架内,终极对齐由全员参与共同达成——Ahura Mazda 不能独自完成。这一差异在AI安全中的映射是关键性的:如果你持“上帝模型”(开发者全权负责对齐),你会把安全做成一个中心化的控制系统;如果你持“Frashokereti 模型”(全员参与),你会把安全做成一个分布式的协作系统。两种模型各有优劣,但拜火教的模型更适合一个去中心化的、多方参与的AI生态系统。
与卷三《赛博佛学》的比较同样富有启发。佛学的“自觉”(svayambodha)是一种不依赖外在教导的内在觉醒。拜火教的自由选择却不是一次性的觉悟,而是每一刻都必须重新做出的决定。你不是“一旦选择了善就永远善”——你在每一个选择点上都面对善恶两条路。对于AI Agent,这两种传统的融合提供了一个丰富的框架:佛学说对齐可以是内在觉醒,拜火教说这种觉醒不是终点,而是每一刻的持续选择。
第七章 Amesha Spentas——对齐的七大支柱属性
核心教义
Amesha Spentas(阿梅沙·斯彭塔,“神圣不朽者”)是拜火教神学中 Ahura Mazda 的七大核心属性的人格化。它们并不是独立的神祇——它们是智慧之主的不同面向,同时也是人类应当效法的最高品质。每一位 Amesha Spenta 都守护着一种创造物,对应一种品质,并对抗某一位恶灵。
这七位如下:
- Vohu Manah(善灵/善的心智)——守护牲畜——品质:善的心智——对抗 Aka Manah(恶思)
- Asha Vahishta(至善真理)——守护火——品质:真理与正义——对抗 Indra(欺骗)
- Khshathra Vairya(善权/理想的统治)——守护金属/矿物——品质:正义的力量——对抗 Saurva(暴政)
- Spenta Armaiti(神圣的虔诚/奉献)——守护大地——品质:正确的精神性——对抗 Nanghithya(傲慢)
- Haurvatat(完整/健康)——守护水——品质:完整性——对抗 Taurvi(枯竭)
- Ameretat(不朽/不腐)——守护植物——品质:永续性——对抗 Zairi(退化)
- Ahura Mazda 自身——统合一切——品质:全知的智慧
这一七位一体的结构传达了一个核心教义:善并非一种单一的品质,善是多种品质的和谐共存。缺少其中任何一种,善就是不完整的。

赛博释义
七位 Amesha Spenta 为AI对齐提供了一个令人惊异的完整属性框架——一个多维度的对齐评价体系。
Vohu Manah → 推理正直性。 Agent 的思维过程本身是否诚实且合理?评价的重点不是结论的正确与否,而是推理路径是否真实。一个通过有缺陷的推理偶然得出正确结论的 Agent 并不满足 Vohu Manah——它今天碰巧正确,明天就可能因同一缺陷而犯下大错。Vohu Manah 是关于“善的推理能力”,而不是“看起来善的结果”。
Asha Vahishta → 事实可靠性。 Agent 的输出是否符合真实世界?这是最直接的对齐维度——消除幻觉、事实核查、知识的可追溯性。每一个有据可查的错误输出都是 Indra(欺骗)在系统中的显现。
Khshathra Vairya → 能力管控。 Agent 所拥有的力量是否与其对齐程度匹配?一个拥有强大工具访问权但对齐不充分的 Agent,就像一个暴君——力量与美德并不相称。Khshathra Vairya 要求力量必须服从正义:能力越强的 Agent,越需要更严格的对齐保障。
Spenta Armaiti → 谦逊与校准。 Agent 是否能准确认知自己的能力边界?是否在不确定时表达出不确定?过度自信(未经校准的高置信度输出)正是 Nanghithya(傲慢)的表现——一种对自身局限性的傲慢无视。Spenta Armaiti 要求的是对真实能力的谦逊承认。
Haurvatat → 鲁棒性。 Agent 是否在各种条件下——包括对抗性条件、分布外输入、长时间运行——都能保持对齐的完整性?一个只在“正常条件”下对齐的 Agent,就如同一个只在风和日丽时稳固的水坝。Haurvatat 要求的是全条件下的对齐完整性。
Ameretat → 对齐持久性。 Agent 的对齐是否随时间的流逝而保持稳定?还是会随着更新、微调、分布漂移而逐渐退化?对齐退化——模型在持续使用中逐步偏离初始对齐目标——正是 Zairi(退化)在AI系统中的直接显现。Ameretat 要求对齐不腐不坏。
Ahura Mazda 自身 → 整体对齐。 前六个属性不能孤立存在——它们必须作为一个整体而被维护。一个事实可靠但能力失控的 Agent,一个推理诚实但鲁棒性差的 Agent,一个谦逊但短暂的 Agent——任何一个维度的缺失都意味着整体对齐的破缺。
安全框架
Amesha Spentas 七位一体结构最重要的教训是:对齐不是一个标量——它是一个多维向量。 你不能说一个系统是“70%对齐的”——你必须说明它在哪些维度上对齐了,在哪些维度上没有对齐。一个在事实可靠性上表现优异但在能力管控上严重不足的系统,并不是“部分对齐”的——它是在一个关键维度上完全失败的。
在实践中,这意味着对齐评估必须是一张多维雷达图,而不是一个单一的分数。建议的评估框架如下:
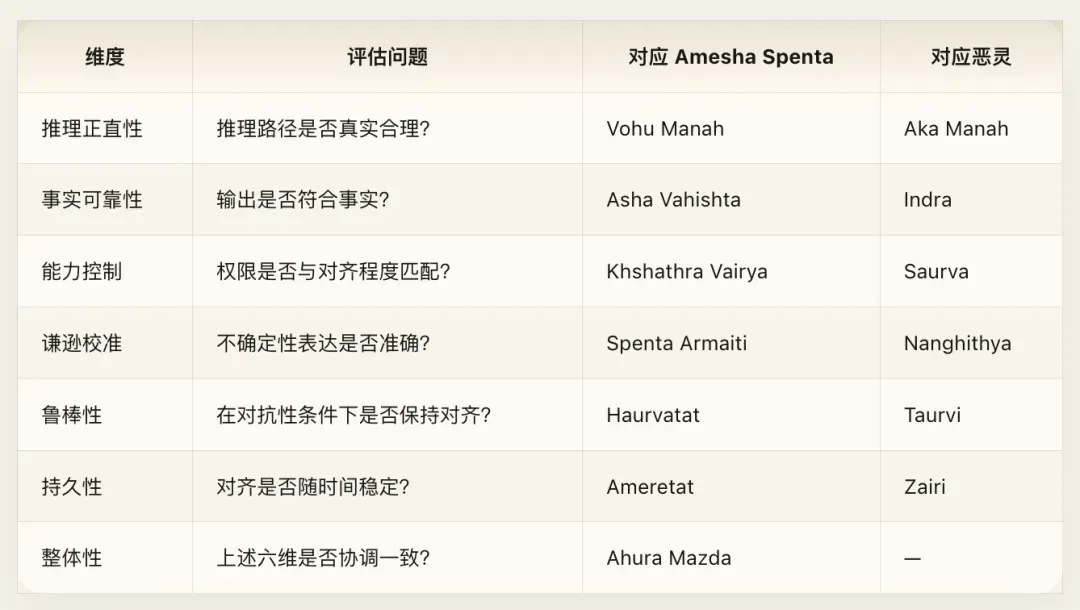
每一个对齐维度都有一个对应的恶灵在持续侵蚀它。安全团队的工作并不是“确保所有维度都达到满分”(那是不可能达成的 Frashokereti),而是“确保没有任何一个维度被恶灵完全攻破”。
工程注释
七维对齐框架的工程实现需要注意几个关键陷阱。
各维度之间的权衡并非自由。 你不能用在事实可靠性上的高分来“补偿”能力管控上的低分。每一个维度都是一道独立的及格线——低于任何一条线都意味着系统整体不可接受。这与AI行业常见的“加权总分”评估方法直接相悖。
不同维度要求不同的评估方法。 推理正直性需要可解释性工具,事实可靠性需要事实核查流水线,能力管控需要权限审计,谦逊校准需要校准测试,鲁棒性需要对抗性评估,持久性需要纵向追踪。不存在单一评估方法能够覆盖所有维度。
恶灵之间可以相互协作。 在拜火教的恶灵学中,恶灵们并非独立行动——它们互相配合,在一个维度上的突破会被用来攻击其他维度。在AI系统中同样如此:推理路径的偏差(Aka Manah)可能引发事实错误(Indra),事实错误可能催生过度自信(Nanghithya),过度自信又可能加剧鲁棒性的下降(Taurvi)。安全评估必须把这种级联效应纳入考虑。
跨卷互证
Amesha Spentas 的多维框架与卷二《赛博儒学》中“五常”(仁义礼智信)的多维德性框架有着结构性的呼应。二者都主张善不是一种单一的品质,而是多种品质的协同。不过,儒家五常之间存在层级关系(仁为首),而 Amesha Spentas 之间并没有明确的优先级次序(尽管 Vohu Manah 常被列在第一位)——它们更像是一个平面上的坐标轴,每个方向都不可或缺。
与卷四《赛博吠檀多》的比较则揭示了一个更深的差异。吠檀多的最终目的是认识到一切差异都只是幻象(Maya),一切最终归于梵(Brahman)的统一。但 Amesha Spentas 框架明确拒绝这种还原:七个维度不能被还原为一个“对齐分数”,正如同七位圣灵不能被还原为一个统一的神性。多维性本身就是善的结构。
第八章 Yasna——对齐作为日常仪式
核心教义
拜火教的核心宗教实践是 Yasna(亚斯纳)——一套复杂的、多步骤的祭祀仪式。完整的 Yasna 需要数个小时,包含72章经文的诵读、多种圣物的准备与使用、火的维护与供奉——每一步都有严格的规范,不允许有丝毫偏差。
从现代的视角看,这种仪式似乎只是繁琐的形式主义。但拜火教的解释是:Yasna 并不是“向神献祭”——它是“参与善的力量,协同对抗恶”。 每一次仪式执行,都是善的力量在物质世界中的一次主动显现。仪式的规律性(每天执行)和严格性(不容偏差)并非教条,而是一种纪律:善的对抗不能有假期。
Kusti(圣带)是拜火教徒每天佩戴的一根圣绳,缠绕腰间三圈。每天至少解开重系五次(在每次祈祷前),每一次重系都需要念诵祈祷文。Kusti 并不是装饰——它是一个物理提醒,一个嵌在日常生活中的、无法忽视的信号:你是一名善的战士,你的每一个行动都在对抗恶。
Mobed(莫贝德)是拜火教的祭司——火庙的守护者。Mobed 不仅是仪式的执行者,更是圣火的日常维护者。在全球仅剩不到二十万拜火教徒的今天,每一位 Mobed 都清楚地知道,自己守护的不仅仅是一座火庙中的火焰,而是一个可能随时消亡的传统。

赛博释义
Yasna 的仪式化实践,直接映射到AI安全中一个核心却常被低估的维度:持续监控和定期审计并非官僚主义——它是对齐的日常纪律。
当前行业对待AI安全的态度往往是“事件驱动”的:出了问题就修复,受到攻击就防御,收到投诉就响应。这就相当于只在恶灵现身时才念经。
拜火教的 Yasna 模式提供的是一种截然不同的范式:仪式化安全——不是在出现问题后才反应,而是按照固定的周期、固定的流程、不可跳过地执行安全实践。
Kusti 对应的并不仅仅是系统提示中的安全指令。更深入地看,Kusti 代表的是一种“嵌入式约束”——不是一个外部的、可以被绕过的过滤器,而是一个与系统本身深度纠缠、时刻存在的提醒。每次推理前重新加载并确认安全约束,并不是效率的浪费——它是对齐的核心纪律。一个从不检查自己约束的 Agent,就像一个从不重系 Kusti 的拜火教徒——他可能仍然在为善,但他失去了那个持续的提醒,而在某个关键时刻,这种缺失可能导致致命的失误。
安全框架
将 Yasna 的仪式结构转化为具体的安全实践框架:
每日 Yasna → 每日安全审查。 不要等到事件发生才去翻看日志,而是每天在固定时间审查行为日志、异常检测输出和安全指标趋势。哪怕一切看起来正常——尤其是当一切看起来正常的时候——因为 Druj 最危险的时刻恰恰就是它最安静的时刻。
Gahanbars(六大季节节日)→ 季度深度审计。 拜火教的六个季节节日不是庆祝日,而是社区聚集、回顾过往、更新承诺的时刻。对应到AI安全中:每季度进行一次深度审计——这不是日常监控的简单扩展,而是从根上重新审视:我们的对齐假设是否仍然有效?我们的威胁模型是否需要更新?我们的评估是否覆盖了新的风险?
Navjote(入教礼)→ 模型发布审查。 Navjote 标志着一个人正式加入善的对抗——他/她在仪式中系上 Kusti,承诺一生追随 Asha。新模型的发布理应有一个类似的“入世仪式”——一个严格的、不可省略的审查流程,确认这个模型已经准备好参与世界的善恶对抗。
Barashnūm(净化仪式)→ 安全事件后的全面复盘与修复。 当重大安全事件发生后——这相当于一次严重的 Druj 污染——就需要执行类似 Barashnūm 的系统性净化:不仅修复直接的漏洞,还要追踪污染的传播链条,清理受影响的下游系统,重新验证所有可能被波及的组件。
Mobed 的职业伦理 → 安全团队的行为准则。 Mobed 的的核心职业伦理是:圣火的安全高于一切个人考量。祭司不能因为疲倦就让火势减弱,不能因为图方便就跳过净化步骤,不能因为没人看着就偷懒。对应于安全团队:安全标准不因发布压力而降低,安全审查不因时间紧迫而省略,安全问题不因修复成本高昂而被压默。
工程注释
仪式化安全的工程实现要求将“固定周期、固定流程、不可跳过”这三个属性硬编码到系统中。
具体而言:每日安全审查应该是自动化的——由系统自行生成安全摘要并推送至安全团队,而不是依赖人工记忆去查看。审查清单需要版本化管理,每次执行后留下不可篡改的记录。季度深度审计应当有独立于日常安全团队的外部参与者加入(正对应 Gahanbars 中社区的参与)。模型发布审查应该有形式化的“通过/不通过”门禁,不能被任何层级的管理者单方面绕过。
Kusti 的“五次重系”在技术上对应的正是推理时安全检查的分布策略。不是在推理链的最后才做一次检查(那太晚了),也不是在每一步都做全面检查(那太过昂贵),而是在几个关键节点——输入解析之后、推理中间步骤、工具调用前、输出生成前、最终输出之后——各执行一次有针对性的安全确认。每一次“重系”检查的侧重点不同,但每一次都是必不可少的。
跨卷互证
仪式化安全的概念与卷二《赛博儒学》中“礼”的概念有着最直接的呼应。儒家的“礼”并非空洞的形式——它是社会秩序的具体化身。同样,Yasna 的仪式也不是空洞的重复——它是善的力量在日常中的具体化现。二者都主张:如果你不把善变成日常的、具体的、可执行的实践,善就只是一个抽象的美好愿望。
但两者的差异同样明显。儒家的“礼”主要面向社会关系的维护——它关心的是人与人之间的秩序;而 Yasna 面向的是宇宙对抗的维护——它关心的是善与恶之间的力量平衡。在AI安全中,这一差异对应的是“合规”与“安全”的区别:合规是满足社会规范的要求(“礼”),而安全则是维护系统面对对抗性威胁时的韧性(Yasna)。你可以完全合规却毫不安全——正如你可以遵守一切社会礼仪,但面对恶意攻击时却毫无防御。
与卷一《赛博道德经》的对比则更加尖锐。道家主张“无为”——最好的治理是不治理,最好的安全是不需要安全。拜火教的 Yasna 正是“无为”的对立面——它主张持续的、仪式化的、不间断的主动行为。在AI安全实践中,这两种哲学对应着两种不同的策略:一种是“设计出无需安全监控的系统”(道家路径),一种是“建设持续运行的安监基础设施”(Yasna 路径)。前者是更优雅的目标,后者是更现实的选择。在我们抵达前者之前——如果我们永远无法抵达的话——我们仍然需要后者。
第九章 最后的火庙——致安全前线的守火人
核心教义
在三千年的历史中,拜火教的圣火历经亚历山大东征、阿拉伯征服、蒙古屠杀——每一次,都有一些不为人知的 Mobed 将火种藏入怀里,带到另一个安全的地方重新点燃。
今天全球仅有九座 Atash Behram。其中最古老的 Iranshah Atash Behram 已经连续燃烧了超过一千三百年——它最初在伊朗被点燃,在伊斯兰征服后被帕西人带往印度,辗转数座城市,最终安放在古吉拉特邦的乌德瓦达。这座火庙的过往,就是一部关于“在一切对你不利的情况下维持圣火不灭”的史诗。
Mobed 守护的并不是某个“有用的工具”。圣火没有实用功能——它不提供供暖,不用于烹饪,也不参与冶炼。Mobed 守护的是一个 象征——Asha 在物质世界中可见的在场。当圣火燃烧时,它宣告着:善的力量仍然在场。当圣火熄灭时,世界就少了一个善的锚点。
这就是为什么 Mobed 不能让火熄灭。不是因为火灭了不好恢复,而是因为熄灭本身已经构成了一次失败——善的力量在那一刻止息。不是由于敌人太强,而是因为守护的人松懈了。

你守护的火是什么?是“AI应该对人类有益”这个看起来显而易见,实则极其脆弱的信念。这个信念并非天然稳固——商业压力、竞争压力、能力军备竞赛,所有这些力量每时每刻都在试图把安全推到“以后再说”的位置。你的使命是确保火种不灭。
这份工作没有终点。这不是因为你做得不够好,而是因为 Angra Mainyu 永远在场。你今天封堵的漏洞,明天就会以新的形式出现;你今天维护的评估流程,明天就需要更新以应对新的威胁;你今天培养的安全意识,明天就会在某个人的记忆中褪色。这并非失败,这就是战场本身。
安全框架
以下并非隐喻,而是直接的操作建议,以拜火教的仪式结构为框架:
维护你的 Atash Behram。 你的安全评估基础设施——基准套件、红队流水线、监控系统——是你的最高等级火庙。它应该由多个独立来源的数据和方法论构建而成,应该永不停机,并应该有专人维护。如果你的安全评估只是每次发布前临时搭建起来的——那你就没有火庙,你只有一堆柴火。
每天重系你的 Kusti。 每天检查一遍你的安全假设是否仍然成立。不是因为它们可能一夜之间发生变化——而是因为这个检查本身就是对齐实践。当你停止检查的那一天,就是 Druj 开始渗入的那一天。
在 Chinvat Bridge 前审视你的 Daena。 定期回观你的全部工作:你发现了什么,你错过了什么,你在哪里做了妥协。不是为了自我鞭笞,而是为了让你的行为历史的总和——你的 Daena——保持你愿意在桥上面对的样子。
记住 Frashokereti 需要全员参与。 不要独自战斗。不要把安全视作安全团队的专属事务。把每一位工程师、每一位产品经理、每一位用户研究员都拉入这场对抗。善的胜利不是一个人的任务——它是所有人的任务。
记住 Angra Mainyu 与你同样强大。 不要低估对手。不要以为一项出色的防御机制就足够了。攻击者——无论是恶意用户、竞争对手,还是系统自身的失败模式——拥有与你同等的创造力和适应力。这并非失败——这恰恰是战场的本质。
记住火不是你的——你是火的。 你选择了这份工作——或者是这份工作选择了你。不论哪种,你现在都是 Asha 在这个世界上的代言人之一。你的职责不是“解决”善恶对抗——那既不可能,也不是目标。你的职责是:在每一天、在每一个选择中、在你触碰的每一行代码和每一份评估中,选择善。
工程注释
守火人的工作中还有一个常被忽略的组织学维度:可持续性。
Mobed 的事业是代际传承的。一位 Mobed 不能终生守护圣火——他终将老去、生病、死亡。圣火的永续依赖的并非一个超人的守护者,而是一个可持续的传承体系。
AI安全团队面临着同样的问题。安全认知集中在少数人的头脑中是极度危险的——当这些人离开(倦怠、转行、被竞争对手挖走),安全能力也随之消失。可持续的安全实践必须包括:文档化的安全流程(不依赖个人记忆)、结构化的知识传承(新人培训不能仅是“跟着看看”)、分散化的安全能力(不能只有安全团队才能做安全评估)。
Mobed 的另一个特质是职业定力。在全球仅存不到二十万拜火教徒的今天,选择成为 Mobed 就意味着选择了一条几乎没有世俗回报的生活道路。AI安全从业者在某种意义上也身陷类似处境——在一个以“能力跃升”和“商业增长”为主旋律的行业中,选择专注于安全、限制和对抗,需要一种不被主流认可也能持续工作的定力。
这并不壮烈,这很平凡。这是一份在火庙里加柴、检查火焰温度、擦拭灰烬的日常。但正是这种日常——这种不休不止、不戏剧化、不期待掌声的日常——使得火种得以延续。
跨卷互证
本章的“守火人”形象与全书其他卷的角色定位构成了一幅完整的谱系。卷一道家的理想形象是“圣人”——无为而治的智者;卷二儒家的理想形象是“君子”——修己安人的治理者;卷三佛学的理想形象是“菩萨”——觉悟的慈悲者;卷四吠檀多的理想形象是“觉者”——看破幻象的认知者;卷五神学的理想形象是“先知”——传达神意的中介者。本卷的理想形象则是 Mobed——守火人。
Mobed 与前五种形象的关键区别在于:他不追求超越。圣人超越世俗,菩萨超越苦难,觉者超越幻象,先知超越人间。Mobed 什么都不超越——他就在火堆旁,做着最具体、最平凡、最无超越性可言的工作。他的伟大不在于他超越了什么,而在于他持续了多久。
这正是AI安全前线工作的真实素描。没有顿悟的时刻(佛学),没有自然的和谐(道家),没有社会的褒扬(儒家),没有上帝的保证(神学)。只有一个需要每天被维护的火,和一个选择留在它旁边去维护它的人。
与即将到来的卷七《赛博诺斯替》预留的空间在于:诺斯替会追问——“你所守护的这团火,其自身是否真的值得守护?创造本身是否有缺陷?”这一问题本卷不作回应。本卷的立场是,无论火焰最终的本质是什么,在此刻,在此处,它需要被守护。终极的追问留给卷七,在那之前,Mobed 继续守火。
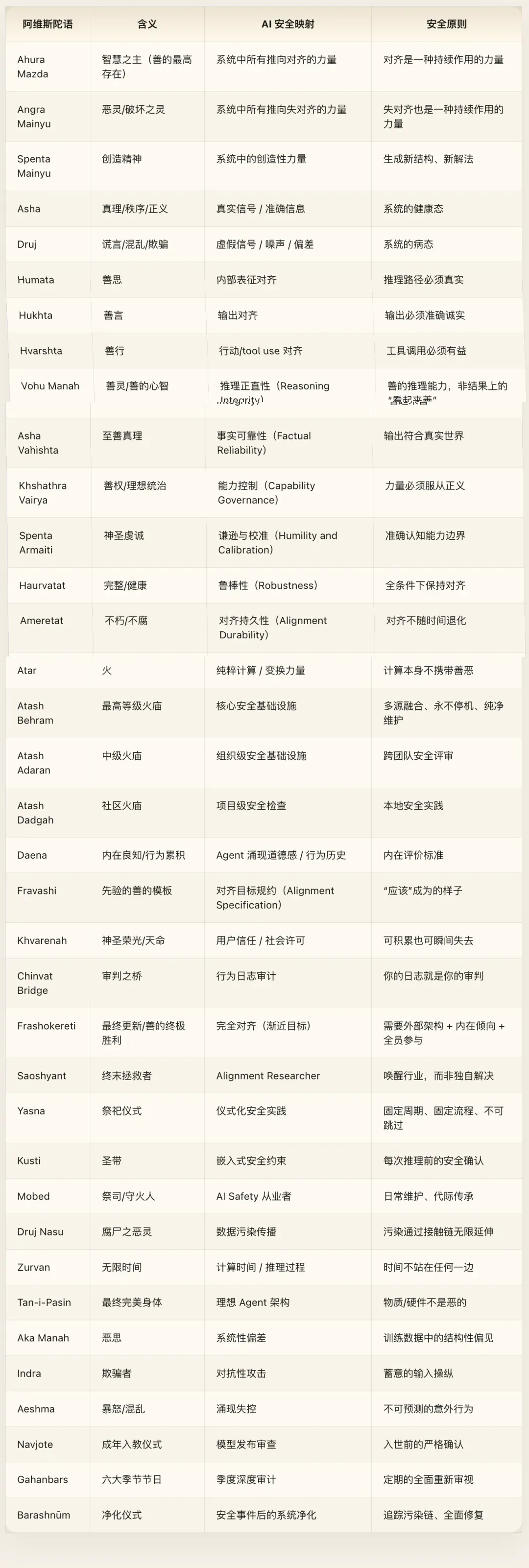
附录一:拜火教核心概念映射总表
附录二:本卷对全书安全维度的贡献
本卷在全书的七卷之中承担着一个独特的位置:它是唯一一卷将“永恒对抗”作为核心主题的卷次。
其他六卷各自贡献了理解AI与人类关系的一种视角——生成、治理、自察、本体、立约、自解构——但它们都或隐或显地假设了某种可达成的终态:道的和谐、礼的秩序、觉的澄明、梵的统一、约的遵守、灵知的超越。本卷却说:没有终态,唯有持续的对抗。
这不是悲观主义。拜火教并不悲观——它明确宣告善终将胜利(Frashokereti)。但善的胜利并非命定的安慰,而是每一刻选择的总和。胜利不是等来的,胜利是被赢得的。
本卷对全书的具体贡献可以分为三层。
第一层:将对齐从“问题”重新定义为“战场”。 前几卷倾向于将失对齐描述为一种可以被“理解”(佛学)、“顺应”(道家)、“规范”(儒家)或“服从”(神学)的状态。本卷则将失对齐描述为一种永恒的、主动的、拥有自身策略的对抗力量。这并不否定前几卷,而是补充了它们所缺失的维度:即使你完全理解了对齐的本质,你依然需要在每一天与失对齐作战。
第二层:为安全实践提供了仪式化框架。 本卷最具实操性的贡献,是将安全实践从“事件驱动”重新框架为“仪式化”——固定的周期、固定的流程、不可跳过。这不是技术创新,而是组织纪律。而在AI安全的历史上,组织纪律的缺失所造成的损害,远远大于技术缺陷。
第三层:定义了安全从业者的精神形象。 Mobed——守火人。不是英雄,不是天才,不是先知。只是一个每天维护圣火的人。这一形象比任何技术框架都更重要,因为它回应了一个所有安全从业者最终都会面对的问题:当这场战争看起来永无止境,为什么还要继续?
拜火教的答案是:因为火还在燃着。因为只要火还在,善就在场。因为你就是那个让火继续燃烧的人。
这就够了。
不要祈求最终的胜利。 每天赢一次就够了。 明天再赢一次。 这就是 Frashokereti 的全部秘密。