从0到1构建AI客服系统:意图识别、RAG检索与数据飞轮实战指南
续篇:AI客服实战方法论深度解析
前文《实践:AI客服实战方法论》已奠定基础,本文将以"空气小猪AI客服"为真实案例,完整拆解企业级智能客服系统的落地路径。
核心议题涵盖八大维度:项目价值评估、目标边界界定、技术路线选型、知识工程构建、意图识别实现、检索策略优化、全链路监控体系搭建,以及数据飞轮机制设计。
企业为何需要部署AI客服?
对于初创团队而言,客服始终是刚性成本。“空气小猪"上线后,客服工作长期由创始人亲自承担。
初期阶段,创始人直接接待用户确有必要——这能帮助团队精准捕捉产品痛点、理解用户使用瓶颈、收集一线反馈以驱动迭代。然而这种模式持续半年以上,日均消耗2-3小时,严重挤占了核心决策者在战略方向、产品规划、增长策略上的投入。
为何不早期引入AI客服? 关键在于语料积累。这半年的真人对话沉淀了高价值、真实场景的训练数据,成为后续智能服务的数据基石。缺乏足量优质语料,AI客服极易陷入"臆造答案"的陷阱。

并非所有业务场景都适合立即启用AI客服。若问题依赖深度人工判断、涉及复杂售后或用户权益处理,AI介入风险极高。“空气小猪"场景具备四大适配特征:
第一,高频问题高度重复。新用户咨询虽表述各异,但核心聚焦于产品定位、功能操作、学习成效、账号登录、消息推送、翻译功能、社交机制等十余个固定维度。知识库覆盖完善后,80%以上的咨询可自动化处理。
第二,历史对话质量极高。创始人过往的回复不仅包含标准答案,更蕴含对用户认知差异的解释逻辑、情绪安抚的话术策略,其价值远超从零编写的FAQ文档。
第三,产品理念需持续阐释。空气小猪的学习理念具有前瞻性,用户常带着传统工具的预期来询,客服工作中30%的精力用于解释"为何如此设计”,这类解释性内容可被结构化为标准知识。
第四,用户反馈即产品迭代信号。客服对话中埋藏着故障报告、功能建议、体验困惑等金矿。人工处理模式下,这些信息散落流失;AI客服可自动提取、归类、入库,形成结构化的需求池。
核心启示:初创产品必须由核心决策者主理客服,此举既是用户洞察的捷径,也为后续智能化积累不可替代的数据资产。
精准定义系统能力边界
启动前必须划定清晰的能力半径:哪些场景必须覆盖,哪些红线不可触碰。
核心职责包括:
- 基于知识库准确回答产品咨询
- 完整收集故障信息并自动建档
- 评估用户建议与产品战略的契合度,无效建议婉拒,有效建议入库
- 闲聊场景保持人格化、有温度的互动
- 识别知识盲区,将未知问题转入待补充队列
明确禁止行为:
- 执行任何数据库写操作或高风险指令
- 向用户作出确定性承诺(如"某功能必上线"“使用必见效”)
- 知识不足时强行编造答案
AI客服最危险的失效模式是"权威式胡诌”,这将直接摧毁用户信任。底线原则是:宁缺毋滥,不确定则沉默。
可控性优先的技术决策
曾面临两条路径:采用Dify/Coze/FastGPT等智能体平台,或自建工程化架构。
两类方案均可行。Dify功能均衡,工作流、知识库、模型管理、企业级特性相对完善,尤其适合快速MVP验证。
然而团队最终选择代码级实现,基于五重考量:
其一,过程可审计性。客服质量不仅看最终结果,更需追溯每个环节:问题改写逻辑、意图判定依据、召回内容清单、排序权重分配、上下文拼接策略、低置信判断规则、知识补充机制。黑盒平台难以实现如此细粒度的过程控制。
其二,检索深度定制需求。对召回策略、排序算法、上下文压缩等环节有精细化调优诉求,这恰恰是智能客服的核心竞争力,必须完全掌控。
其三,成本结构优化。私有化部署将产生额外服务器与运维开销,当前阶段非必要支出。
其四,响应速度要求。实测中Dify的链路易出现延迟,尤其在检索节点,难以满足"秒级响应"的用户体验基准。
其五,业务系统集成复杂度。即便使用平台,打通业务数据库、管理后台、反馈系统仍需大量定制开发。
在AI Coding工具加持下,代码实现的门槛显著降低,远低于传统预期。自建架构的显性收益在于:检索、排序、日志、飞轮等核心模块完全可控。
另一个架构抉择:Workflow还是Agent?
Agent具备自主规划、工具调用、动态决策能力,但客服场景要求确定性、可解释、可追溯,过度自主反而增加不确定性风险。
因此V1.0采用确定性工作流:每一步的输入、输出、异常处理均由系统显式编排。此设计牺牲了部分自主性,换取了极致的可控性与最低生产风险。事后复盘证明,先求稳定再谋智能的迭代策略极为正确。
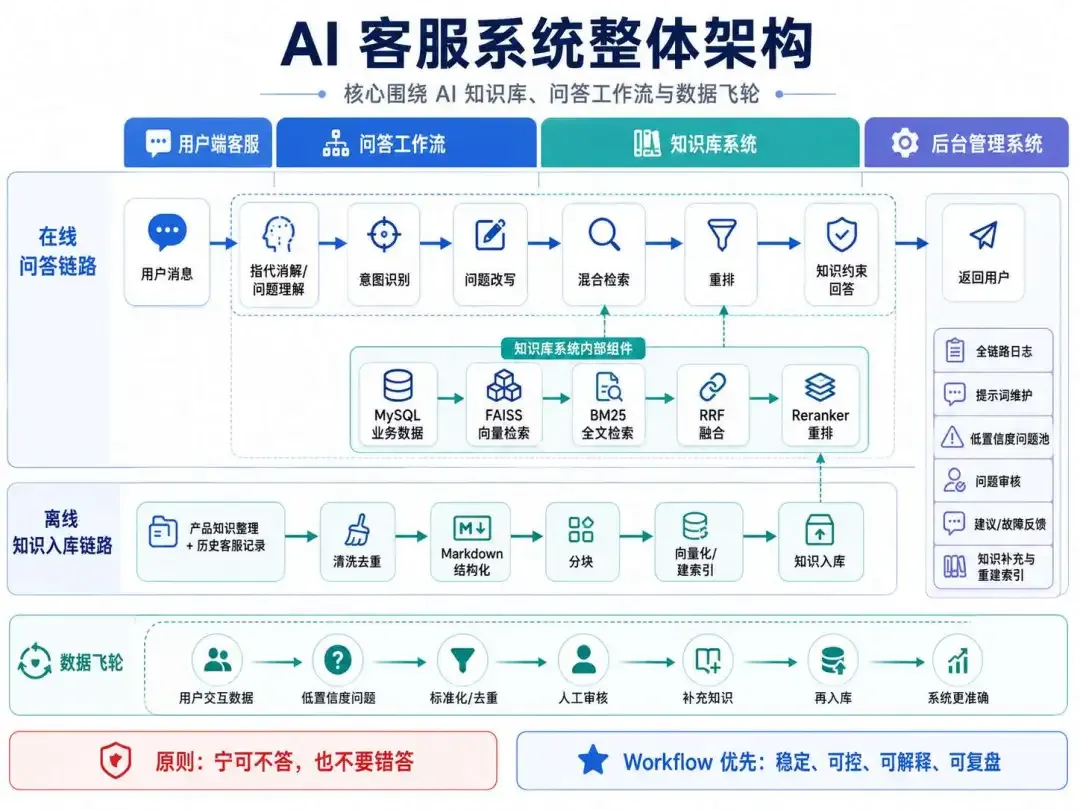
系统流程与功能架构
将AI客服抽象为一句话:接收用户Query → 语义理解 → 意图分类 → 知识检索 → 约束生成 → 全链路日志记录。
工程实现时,该链路拆解为可观测的功能节点:
知识生产侧则独立为离线链路:
功能模块划分为四大部分:
- 用户端接口:消息收发与响应渲染
- 知识库引擎:知识采集、向量化、分层检索
- 问答编排层:模型调用与业务逻辑编排
- 管理后台:链路追踪、提示词运维、问题审核、数据看板
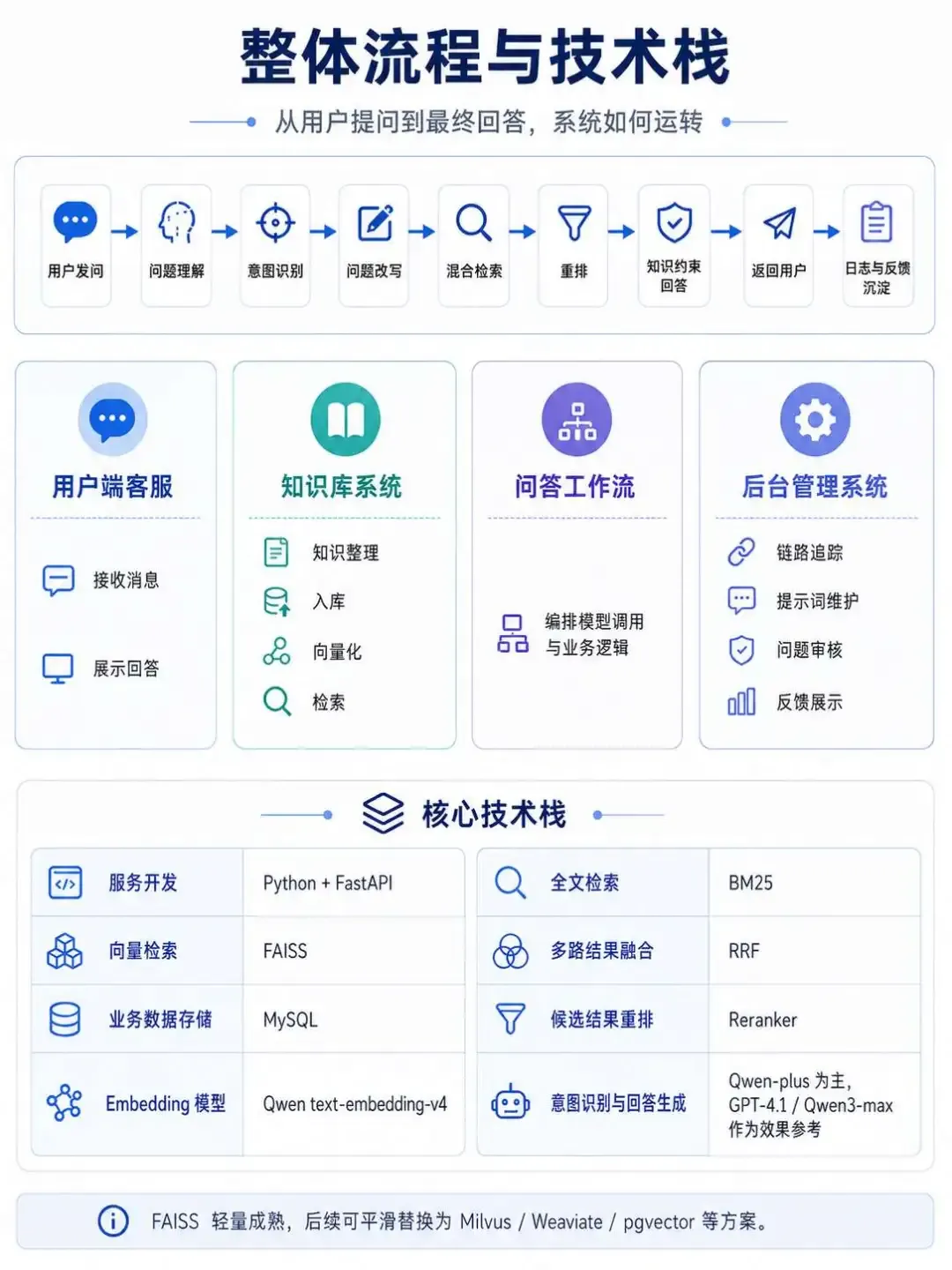
核心技术栈选型
| 模块 | 选型方案 |
|---|---|
| 服务框架 | Python + FastAPI |
| 向量检索 | FAISS |
| 业务数据 | MySQL |
| 嵌入模型 | Qwen text-embedding-v4 |
| 关键词检索 | BM25 |
| 多路融合 | RRF(倒数排序融合) |
| 精排模型 | Reranker |
| 意图识别与生成 | Qwen-plus(主力),GPT-4.1/Qwen3-max(效果基准) |
FAISS的选型逻辑在于轻量化、成熟度与低运维成本,足以支撑百万级知识规模。业务数据存于MySQL,确保知识原文、分类标签、审核状态、向量ID等元数据可结构化管控。该架构保持松耦合,未来可平滑迁移至Milvus、Weaviate或pgvector,无需重构业务层。
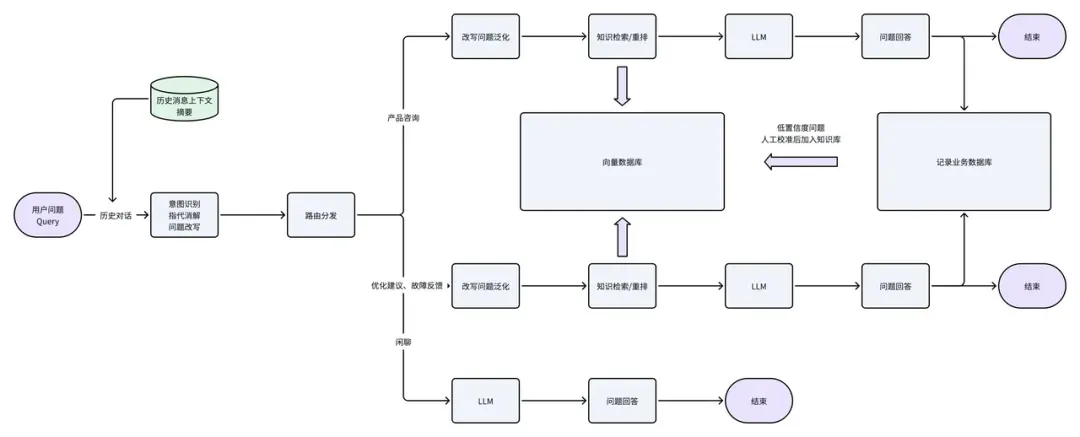
第一步:意图识别体系构建
意图分类是逻辑链路的咽喉,误判将导致后续环节全部失效。

用户问题无限发散,但系统能力必须收敛。初始分类仅"产品咨询"与"闲聊"两类,上线后发现无法覆盖真实场景——约40%的对话属于反馈类:故障上报、功能诉求、体验吐槽。这类对话需要特殊处理,不能简单回复了事。
因此一级意图扩展为三类:
| 意图类型 | 处理范式 |
|---|---|
| 产品咨询 | 走RAG流程,检索知识并约束生成 |
| 用户反馈 | 判断功能存在性,分类为故障/建议,结构化入库 |
| 闲聊 | 走开放生成,保持人格温度,不检索知识 |
关键实践:意图标签不能仅给模型三个单词,必须附详细判断标准与二级分类体系。
我们从产品功能树与用户需求树双视角梳理,最终沉淀出高频意图矩阵:
| 一级意图 | 二级分类示例 |
|---|---|
| 产品咨询 | 定位/理念/价格/竞品/账号/推送/翻译/社交/播客/词卡 |
| 用户反馈 | 故障报告/新增功能/体验优化 |
| 闲聊 | (无需细分) |
配套提示词模板需包含:角色定义、任务描述、分类标准清单、输入格式(历史对话+当前问题)、输出Schema(置信度+意图+理由)。模型最终选用Qwen-plus,在成本、速度、准确率间取得最佳平衡。初期可用GPT-4.1跑通流程,待分类标准稳定后降级为经济模型。
知识工程实践
知识是RAG系统的灵魂,劣质知识输入必然导致劣质答案输出,任何工程优化都无法弥补"垃圾进垃圾出"的缺陷。
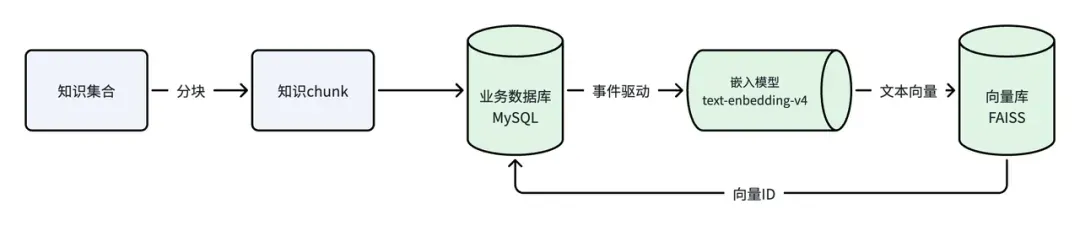
除质量外,知识分块策略同样关键。分块需在整理阶段即考虑语义完整性,确保每个chunk独立表达单一概念。
采用Markdown体系化整理知识,其标题层级天然契合知识结构,便于按标题自动化切分。
知识源双轨并行:
- 专家整理的产品知识库:涵盖定位、理念、功能清单、价格策略、数据安全、功能规划(做与不做的边界)
- 历史对话挖掘:半年累计的真实问答对,包含用户原生表达方式与创始人应答策略
两者需交叉验证:专家知识系统性强但可能脱离实际语境;历史对话真实但碎片化严重,需清洗去重。
知识文档示例结构(略)
历史会话数据通过AI批量处理:按每10个会话为一个批次,调用Coze工作流提取有效问答对,结果写入飞书多维表格,经过去重、合并、人工校验后入库。
此环节耗费人力但价值极高,必须由深度理解产品的核心成员主导。
混合检索策略优化
纯向量检索在客服场景存在明显短板:无法精准捕获功能名称等关键实体。用户询问"Memo词卡"时,向量检索可能召回语义相近但功能不同的内容。
因此采用向量+BM25双路召回:
- 向量路:解决语义泛化,如"对英语有没有帮助"≈“能否提升英语能力”
- BM25路:解决关键词精确匹配,如"播客模式"“小猪伴聊”
当前使用LangChain的BM25Retriever,配置k=3,轻量高效。
为进一步提升召回率,对用户Query做多路改写。例如原问题"这个app到底对学英语有没有用?",系统自动扩展为5个检索视角:
- 空气小猪对英语学习有什么帮助?
- 空气小猪如何提升英语能力?
- 适合什么英语学习场景?
- 与传统学习方式有什么不同?
- 核心学习价值是什么?
每路改写分别走向量与BM25检索,获得候选集后:
- 同检索方式内部用RRF合并
- 引入重排模型(Reranker)精筛,输出0-1相关度分数
- 最终用RRF融合三路结果(向量、BM25、重排)
生成阶段仅使用最终TopK结果。
约束生成机制
召回知识后,不可放任模型自由发挥,必须施加强约束。
产品咨询类问题的铁律:所有陈述必须有知识依据,禁止任何程度发挥。
提示词关键字段useful强制模型自检:召回内容是否足以回答问题。若useful=true则正常生成;若useful=false则礼貌拒绝,并将问题转入低置信度池。
此设计看似简单,实则构建了关键防线。检索结果难免存在弱相关项,若无此自检机制,模型易基于片面信息强行编造。底线是:系统必须能表达"我不知道"。
输出Schema示例:
{
"useful": true,
"content": "空气小猪通过真实对话内容构建外语环境...",
"translation": "..."
}
对话上下文管理
AI客服是多轮连续对话,需传递历史上下文。但上下文窗口有限,过多消息导致延迟高、费用大、幻觉风险上升。
采用分层记忆策略:
- 短期记忆:最近N条原始消息不压缩,保证当前话题连贯性
- 长期记忆:每满50条消息异步生成摘要,仅存事实与诉求(关心点/问题/已提供信息/未解决点)
调用模型时,上下文按"[短期记忆+近期摘要]“组合,平衡完整性与成本。
全链路可观测体系
AI客服的故障形态隐蔽:无异常堆栈,但答案偏差。问题可能出在任意环节:意图误判、改写失真、召回不足、知识错位、提示词失效。
因此必须记录全链路日志:
- 用户原始消息
- 指代消解结果
- 意图识别输出与理由
- 改写Query列表
- 向量召回内容与分数
- BM25召回内容
- Reranker重排结果
- 最终选用知识
- 生成答案与
useful标记 - 模型调用耗时与成本
管理后台支持流程回放,可精准定位失效节点。当用户投诉答案不准,可快速归因至意图、召回、知识或生成环节,避免盲目调优。
数据飞轮闭环设计
数据飞轮是持续进化的核心机制:用户交互→数据收集→加工优化→反哺系统→提升效果。
初始知识库必然不完备。低置信度问题池自动收集两类输入:召回分数低于阈值或useful=false的问题。
入库前执行问题标准化:
- 去除情绪、口语、无关信息
- 提取真实意图
示例:
原文:我在日本,用+81的手机号能不能注册啊?不行我就换国内的
标准:国外手机号是否支持注册空气小猪账号?
系统会聚类相似问题,统计频次,筛选高频未知问题进入人工审核队列。
审核岗需判断:
- 是否真实业务问题
- 是否已被现有知识覆盖
- 是否为垃圾信息
- 是否低频无需沉淀
- AI初步答案是否可信
通过后补充标准答案,重新走入库流程。下次用户询问即可自动命中,形成"越用越准"的闭环。
核心启示
项目落地带来三点关键认知:
- 边界意识:明确能做什么与绝不做什么,坚守"宁可沉默不误导"的铁律
- 知识为王:RAG系统的天花板由知识工程决定,此处无法取巧
- 观测与迭代:可观测基础设施与数据飞轮是长期运营的命脉
以上即空气小猪AI客服从0到1的完整实践(核心技术已脱敏),希望对同行有所借鉴。不足之处,欢迎指正。