OpenHuman:能记上下文的开源桌面AI代理,连接118+服务自动生成记忆树
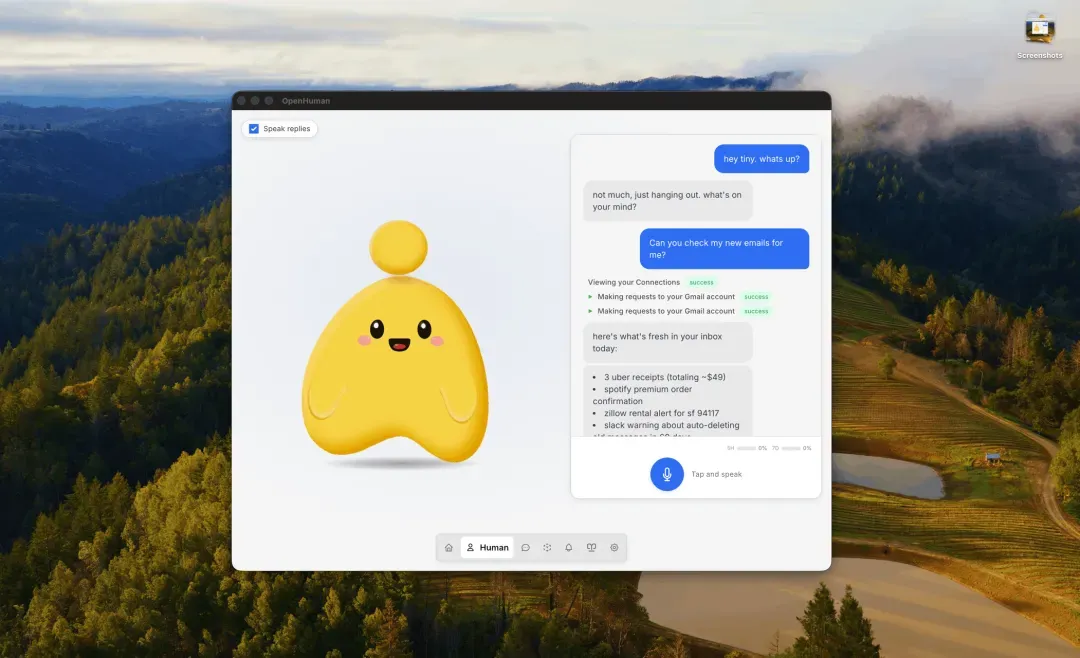
当你把 Gmail、GitHub、Slack、Notion 等超过 118 个常用服务通过 OAuth 授权给 OpenHuman 之后,它会每 20 分钟自动同步一次数据,将全部信息压缩成层级分明的“记忆树”,并同时存放在本机 SQLite 数据库和一个 Obsidian 知识库目录下。你不需要绞尽脑汁去写提示词,这个代理已经在默默阅读你的上下文了。
31.9k
GitHub Stars
118+
集成服务
20min
自动同步周期
这个项目究竟在做什么
OpenHuman 是一个开源的桌面 AI 代理,由开发者 Steven Enamakel(@senamakel)发布后,仅用两天就冲上了 GitHub Trending 榜首。它既不是普通的网页对话窗口,也不是又一个编程助手,而是一个常驻桌面的 AI 伙伴,拥有可视化的表情、语音交互和持久的记忆能力。
它的核心运作方式非常直接:将你在工作中使用的各类 SaaS 账号(邮箱、日历、代码仓库、文档系统、即时通讯等)通过 OAuth 连接到 OpenHuman,之后它便会在后台每 20 分钟自动拉取新产生的数据,并将这些信息加工为 Memory Tree(记忆树) 存入本地的 SQLite 数据库。与此同时,它还会生成一套 Obsidian 可以直接打开和编辑的 .md 格式知识库。当你向它提问时,它会基于已经掌握的上下文即时作答,你再也不必反复上传文件或粘贴历史聊天记录。
该项目基于 Rust + Tauri 构建,前端使用了 TypeScript 和 React 19,代码中 Rust 占了约 65%。安装后得到的是一款原生桌面应用,支持 macOS、Windows 和 Linux 三大平台,并采用 GPL-3.0 开源许可。
快速上手:五分钟从零到可用
对于 macOS 用户,最可靠的方式是通过 Homebrew 安装:
brew tap tinyhumansai/core
brew install openhuman
Debian 或 Ubuntu 用户可以添加官方的 apt 仓库,Windows 用户则直接下载 .msi 安装包。此外,GitHub Releases 页面也提供了 .dmg 和 .AppImage 格式的手动安装文件。
第一次启动后,引导流程会带着你完成三个关键步骤:
▸ 选择模型来源:你可以使用 OpenHuman 提供的订阅服务(统一涵盖推理、搜索和语音功能),也可以填入自己的 OpenAI 或 Anthropic API 密钥,或者连接到本地运行的 Ollama 和 LM Studio 模型。
▸ 连接你的在线服务:打开集成面板,一次性 OAuth 授权 Gmail、Calendar、GitHub、Slack 等你想让代理访问的工具账号。
▸ 等待首次同步:成功连接后,自动抓取任务会在 20 分钟内触发。你可以在 Memory 面板中点击 View vault in Obsidian,直接打开已经生成好的 /wiki/ 目录。
当第一次同步完成后,可以试着这样问它:「总结本周还没有读的客户邮件」「有哪些 PR 等待我来 review」「帮我起草上周二设计会议的跟进消息」。它不需要你反复交代背景,因为上下文已经在那里了。
重点提醒:Memory Tree 生成的全部 .md 文件都保存在你的本地硬盘上,路径为 ~/wiki/。你可以直接用 Obsidian 打开、搜索甚至编辑这些文件,代理在下一次同步时会读取到你的修改。
核心能力深度拆解
OpenHuman 做的事情可以分为几个重要层面:
▸ Memory Tree 记忆树:每一份接入的数据会被切分成不超过 3000 token 的 Markdown 分块,然后根据来源、主题和日期进行分层打分,最终存入本地 SQLite。同时,这些块也会落地为 Obsidian 兼容的 .md 文件。与向量数据库不同的是,这是一种人类可读、可编辑的结构化知识表示。
▸ Auto-fetch 自动抓取:当连接了 Gmail、GitHub、Notion、Slack 和 Calendar 等服务后,后台会每 20 分钟自动拉取新数据并写入记忆树。早上打开电脑时,It 已经知道你凌晨收到了哪些邮件。
▸ TokenJuice 压缩:在进入模型之前,所有工具调用、网页抓取内容、邮件正文和搜索结果都会先经过一个压缩层,把 HTML 转为 Markdown,缩短长 URL,并去除重复摘要。官方声称最多可减少 80% 的 token 消耗,且中文和 emoji 会按字符原样保留。
▸ 桌面吉祥物与语音交互:一个 Rive 动画角色出现在桌面上,具备语音输入和语音输出功能,支持唇形同步。它还可以作为正式参会者加入 Google Meet,实时听取会议内容、记录笔记甚至发言。
▸ 原生工具集:内置了网页搜索、爬虫、文件系统操作、git、lint、test、grep 等常用工具,无需安装插件就能够读写文件和编写代码。
▸ 智能模型路由:系统会根据任务类型自动选择最合适的模型,一个订阅就能涵盖所有模型,不需要为不同模型分别购买 API 密钥。
谁适合用,谁最好再等等
如果你日常同时使用五个以上 SaaS 工具,希望 AI 能全面理解你的上下文而不是每次从零开始,并且比较关注数据隐私,那么 OpenHuman 的设计思路恰好击中了这些需求。独立开发者、自由职业者和小团队运营者会尤其受益,因为它的上下文构建成本几乎为零——接上账号,等上 20 分钟,它就已经认识了你。
但反过来,如果你的环境对安全审计有强制性要求,不太能接受 beta 版偶尔的崩溃或配置变动,或者希望 AI 代理能够处理企业级别的复杂归集任务,那可能还需要再观望一段时间。项目目前仍然处于早期 beta 阶段,还没有经过第三方安全审计,且 Windows 上的稳定性也有部分用户反馈问题。
适合的场景
- 对隐私敏感的个人用户
- 多工具重度使用者
- 自由职业者 / 小型团队
- 愿意尝鲜的早期采用者
暂时不太适合的场景
- 需要安全审计的企业环境
- 不接受 beta 版不稳定的场合
- 仅将 AI 用于代码编写的人员
- 以 Windows 为主要工作平台的用户
社区的声音与反馈
项目发布后的传播速度在开源 AI 工具中非常罕见。5 月 12 日上线当天便冲上 GitHub Trending 第一,两周内收获了超过 29k stars,同时拿下 Product Hunt 的单日和单周双料第一。到 6 月中旬,stars 数已增长至 31.9k。多位独立评测者给出了 3.5/5 到 4/5 的综合分数。
在汇总的反馈中,被提及最多的亮点有三点:第一,记忆树以可读的 Markdown 文件呈现,区别于黑盒的向量数据库,这在同类工具中很独特;第二,跨服务联动的体验令人惊喜,有用户写道“周五下午它提醒我有三个周一到期的工单,确实很有用”;第三,Google Meet 的参会功能能够真正在会议中做笔记、使用工具并发言,实用性很强。
创始人 Enamakel 的创业故事也引发了不少共鸣。他在 X 上分享道,最初的代码源于一次失败的尝试——他想给父亲安装一个现成的开源 AI 代理,但配置 API key 和 YAML 文件折腾了三个小时后两人都放弃了。OpenHuman 正是在那个晚上之后写出来的。
来自老手和社区的实用建议
关于安装安全:官方推荐优先使用 Homebrew tap 或 apt 仓库安装,而不是采用 curl | bash 这样的一键脚本。多名做过安全性评测的专业人士都明确建议,下载安装包后最好检验签名,或者利用包管理器自带的验证链路。
关于 OAuth 聚合风险:所有集成通过一个单一的客户端持有全部访问令牌。虽然将数据留存本地减少了云端泄露的可能性,但一旦端点被攻破,攻击者可能会获取到成体系的全量数据。因此,建议先用低风险账号进行测试,确认安全后再接入主力邮箱和代码仓库。
关于“本地优先”的边界:记忆树、Wiki 和运行时状态确实是存储在本地,但默认的模型路由、搜索代理以及 OAuth 握手都需要经过 OpenHuman 托管的云端后端。如果你很介意数据离开本机,则需要手动配置 BYO 模型和 Composio 直连模式。
关于起步策略:社区普遍认为,目前最好的使用方式是从低风险场景切入,先连接 Calendar 和 GitHub,待熟悉记忆树的结构和代理的行为模式后,再逐步接入 Gmail 和 Slack。OpenHuman 与 Cursor、Claude Code 这类编程代理并不冲突,前者主要处理邮箱和日历中的信息,后者专注于代码,它们工作在不同的数据层面。
SOURCES
GitHub 仓库 · github.com/tinyhumansai/openhuman
官方文档 · tinyhumans.gitbook.io/openhuman
OpenHuman Review (openhuman.guide) · openhuman.guide/openhuman-review
Chew Loong Nian, “I Gave OpenHuman 118 of My Apps”, Medium
ZavCloud OpenHuman Install Guide · zavcloud.com