MiroFish实战教程:构建AI沙盘,预测小说情节与股价舆情

今天我们来探索一款名为MiroFish的前沿AI工具,它被誉为新一代的AI预测引擎。其核心在于运用多智能体技术,通过提取现实世界的“种子信息”(例如突发的新闻事件、公布的政策草案或关键的金融信号),自动构建出高保真的平行数字世界。在这个虚拟空间里,成千上万个具备独立人格、长期记忆与特定行为逻辑的智能体将进行自由的互动与复杂的社会演化。使用者可以如同拥有“上帝视角”一般,动态地向系统中注入变量,从而精准地推演事件未来的多种走向——本质上,这相当于让未来在数字沙盘中预先演练,帮助使用者在经过无数次模拟后做出更明智的决策。
该引擎的工作流程清晰而系统化,主要包含以下几个阶段:首先是图谱构建,即从现实种子中提取关键信息,为个体与群体注入初始记忆,并利用GraphRAG技术构建知识图谱。接着是环境搭建,此阶段会完成实体关系的抽取、各类角色的人设生成,并由环境配置Agent向仿真系统中注入必要的参数。然后是开始模拟,系统会在双平台上并行运行模拟过程,自动解析用户的预测需求,并动态更新所有智能体的时序记忆。模拟结束后进入报告生成阶段,专门的ReportAgent会利用其丰富的工具集与模拟后的环境进行深度交互,产出分析结果。最后,用户还可以进行深度互动,不仅可以与模拟世界中的任意一位智能体对话,也能直接与ReportAgent进行交流以获取更深层次的洞察。
准备工作:获取ZEP与LLM密钥
在部署MiroFish之前,需要预先准备好两个关键的API密钥:ZEP记忆图谱服务的密钥,以及用于驱动智能体的大语言模型(LLM)的密钥。以下是简单的获取指引。
首先访问ZEP的官方网站进行账号注册与密钥创建。
 新用户需要先完成注册流程。
新用户需要先完成注册流程。
 注册时选择个人使用(Personal Use)方案即可。
注册时选择个人使用(Personal Use)方案即可。
 登录后进入管理面板,新账号通常会享有一定的免费使用额度。
登录后进入管理面板,新账号通常会享有一定的免费使用额度。
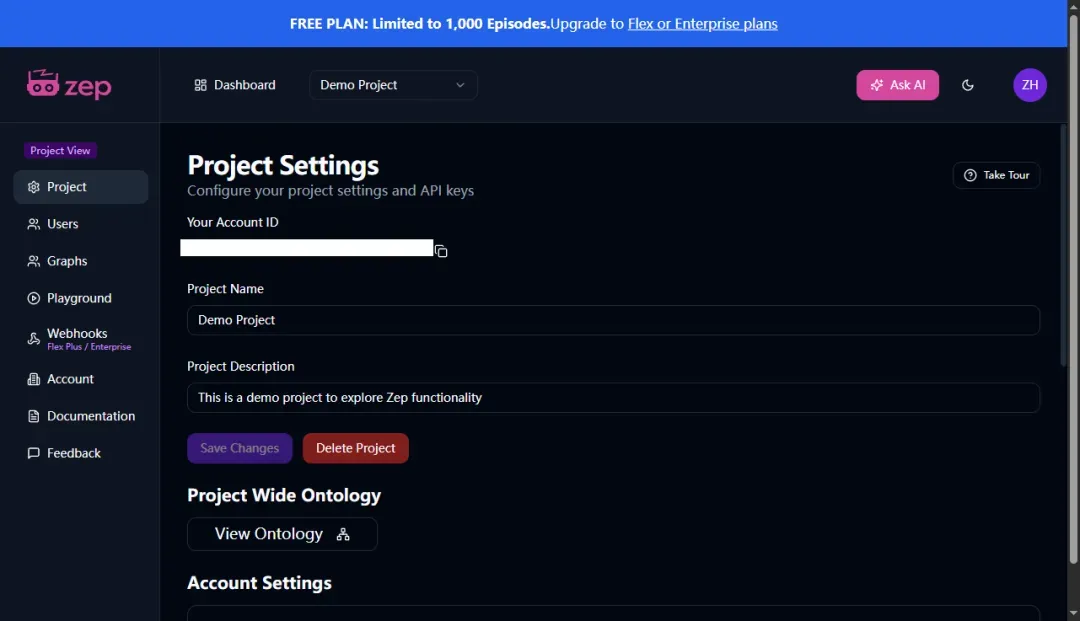 在面板中向下滑动,找到创建API密钥(API Keys)的选项。
在面板中向下滑动,找到创建API密钥(API Keys)的选项。
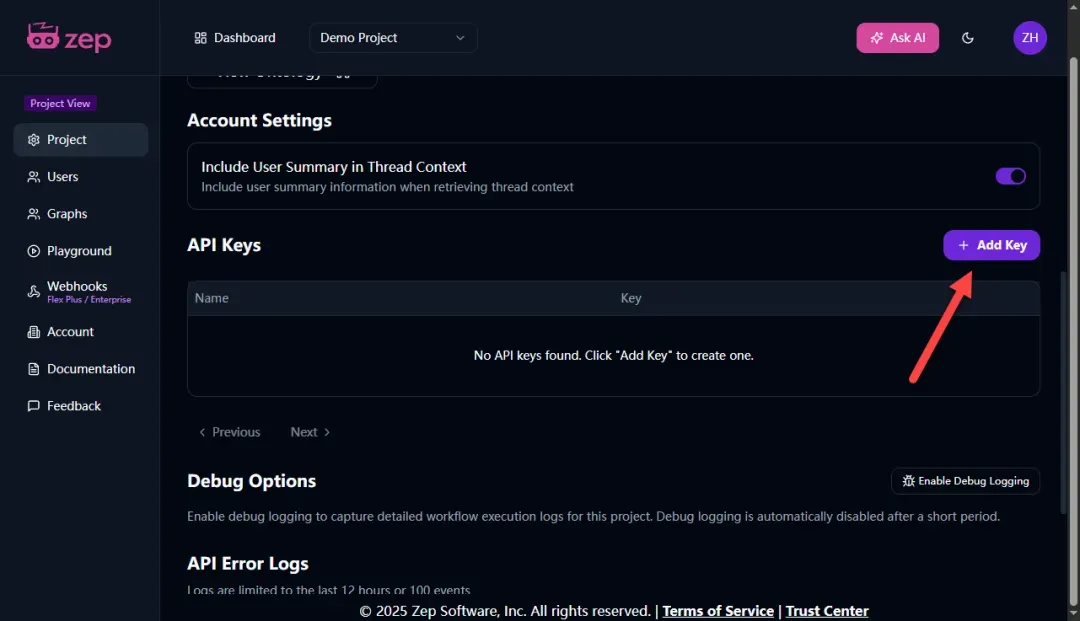 创建成功后,请务必妥善复制并保存好生成的密钥。
创建成功后,请务必妥善复制并保存好生成的密钥。
 温馨提示:理论上任何兼容OpenAI API格式的模型提供商都可以使用,但由于模拟过程可能消耗大量Token,建议初次尝试时优先选用提供免费额度的服务。
温馨提示:理论上任何兼容OpenAI API格式的模型提供商都可以使用,但由于模拟过程可能消耗大量Token,建议初次尝试时优先选用提供免费额度的服务。
接下来获取LLM的API密钥。这里以阿里云百炼平台为例进行说明。
 新用户注册后通常可获得免费体验额度,图中展示的是已开通服务的界面。
新用户注册后通常可获得免费体验额度,图中展示的是已开通服务的界面。
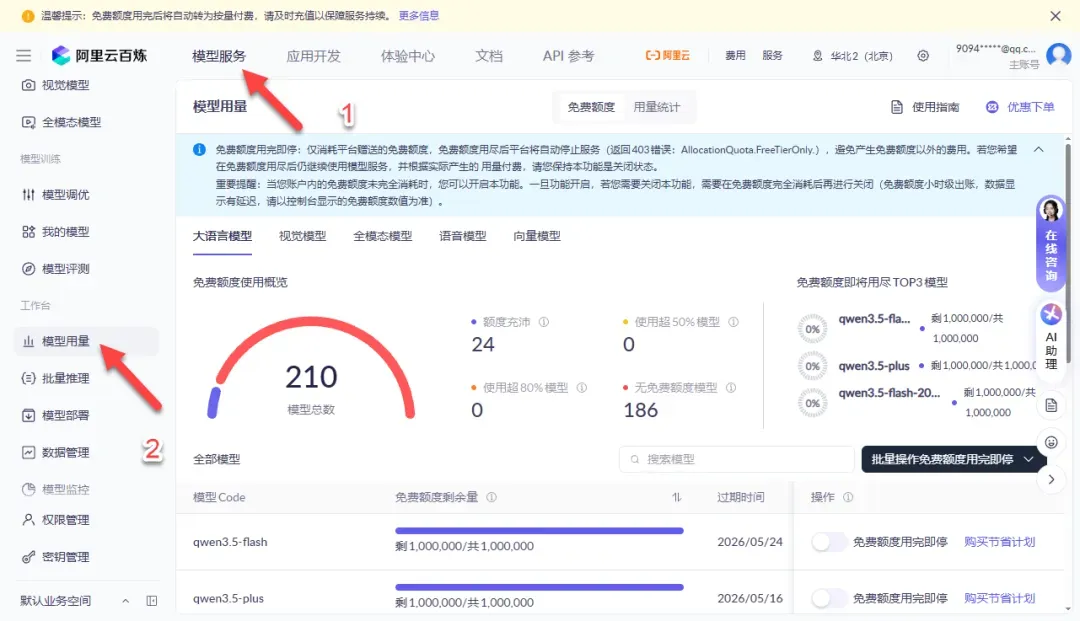 在模型列表页面,可以通过排序功能筛选出带有免费额度的模型,同时注意开启“免费额度用完即停”的选项以防意外扣费。
在模型列表页面,可以通过排序功能筛选出带有免费额度的模型,同时注意开启“免费额度用完即停”的选项以防意外扣费。
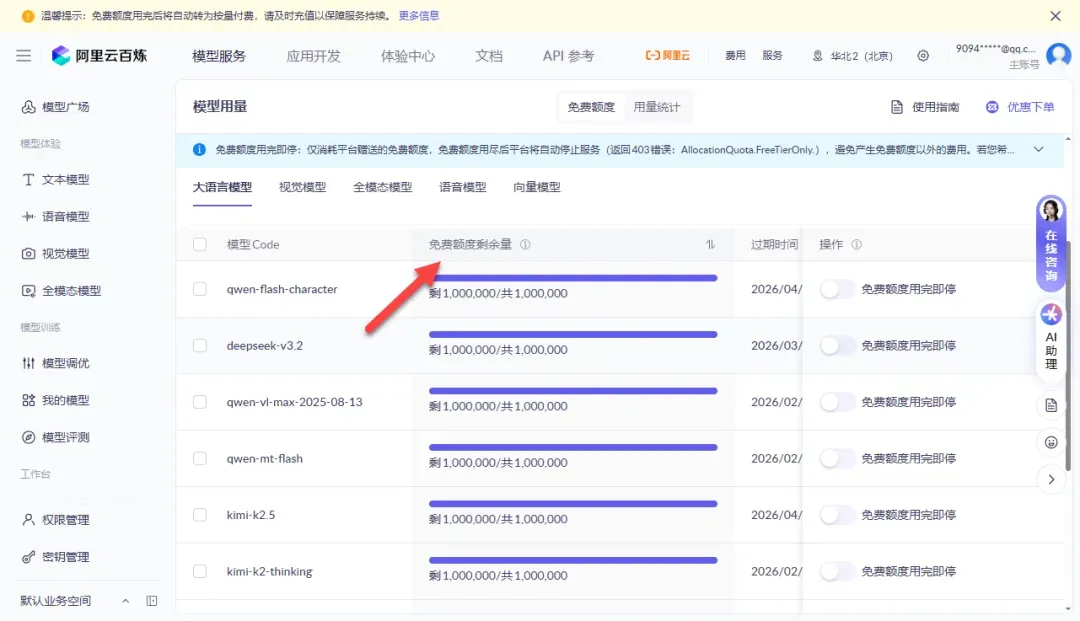 进入平台的密钥管理页面,创建一个新的API Key。
进入平台的密钥管理页面,创建一个新的API Key。
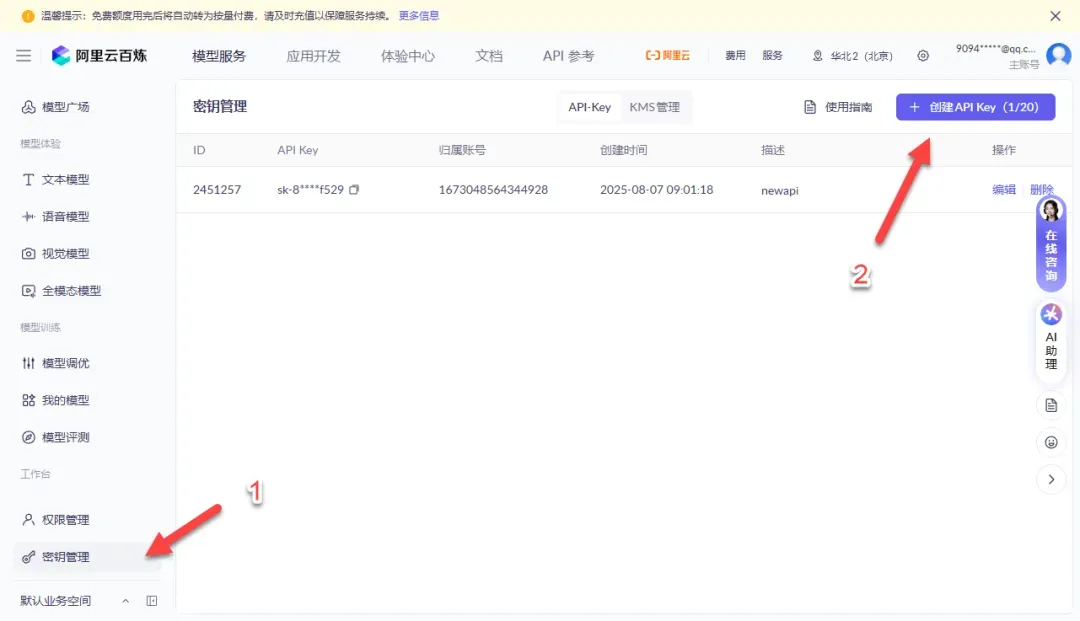 密钥创建完成后,同样需要立即复制并安全保管,后续配置时会用到。
密钥创建完成后,同样需要立即复制并安全保管,后续配置时会用到。
部署指南:使用Docker Compose快速搭建
推荐使用Docker Compose来快速部署MiroFish服务。以下是一个基础的docker-compose.yml配置文件示例:
services:
mirofish:
image: ghcr.nju.edu.cn/666ghj/mirofish:latest
container_name: mirofish
ports:
- 3000:3000
- 5001:5001
environment:
- VITE_API_BASE_URL=http://你的服务器IP:5001
- ZEP_API_KEY=你的ZEP_API_KEY
- LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
- LLM_API_KEY=你的LLM_API_KEY
- LLM_MODEL_NAME=qwen3.5-plus
volumes:
- ./backend/uploads:/app/backend/uploads
restart: unless-stopped
关键环境变量说明(更多高级参数建议查阅官方文档):
VITE_API_BASE_URL:指定后端API服务的外部可访问地址,需替换为你的实际IP。ZEP_API_KEY:填入之前获取的ZEP记忆图谱密钥。LLM_BASE_URL:LLM模型提供商的API端点地址,需兼容OpenAI协议。LLM_API_KEY:填入之前获取的LLM模型调用密钥。LLM_MODEL_NAME:指定要使用的LLM模型名称。
注意事项:由于镜像文件体积较大,首次拉取可能需要较长时间,请保持网络通畅。
 容器启动后,建议首先查看日志以确认服务是否正常运行,有无报错信息。
容器启动后,建议首先查看日志以确认服务是否正常运行,有无报错信息。
上手体验:以小说《白夜行》为例进行推演
部署成功后,在浏览器中访问 http://你的服务器IP:3000 即可打开MiroFish的Web操作界面。
 页面下滑后,可以看到清晰的功能操作区域。
页面下滑后,可以看到清晰的功能操作区域。
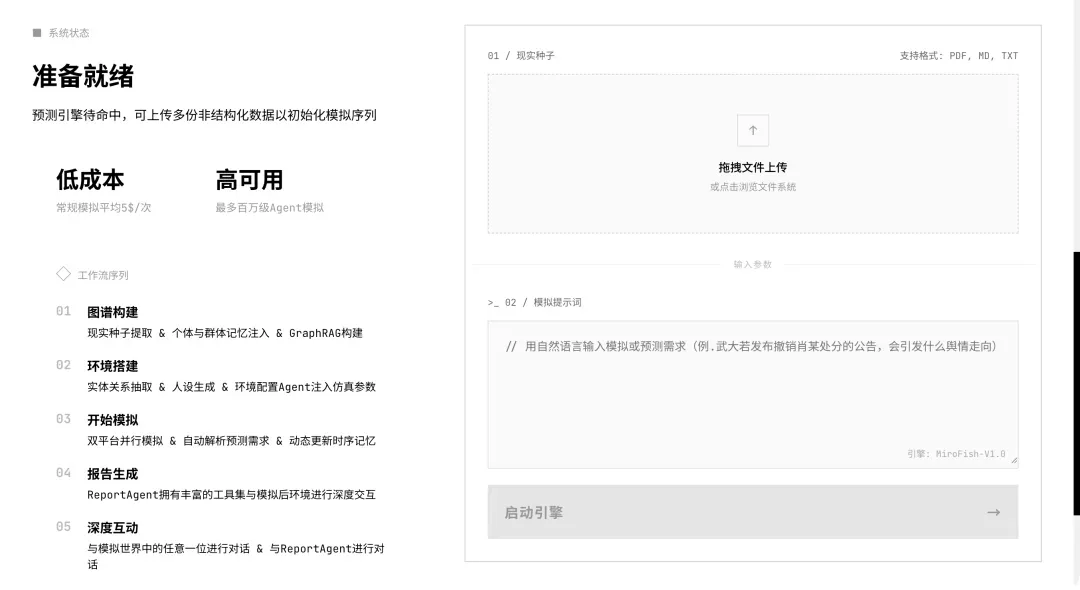 首先上传你想要进行分析的文档。本次演示我们选用东野圭吾的小说《白夜行》全文。
首先上传你想要进行分析的文档。本次演示我们选用东野圭吾的小说《白夜行》全文。
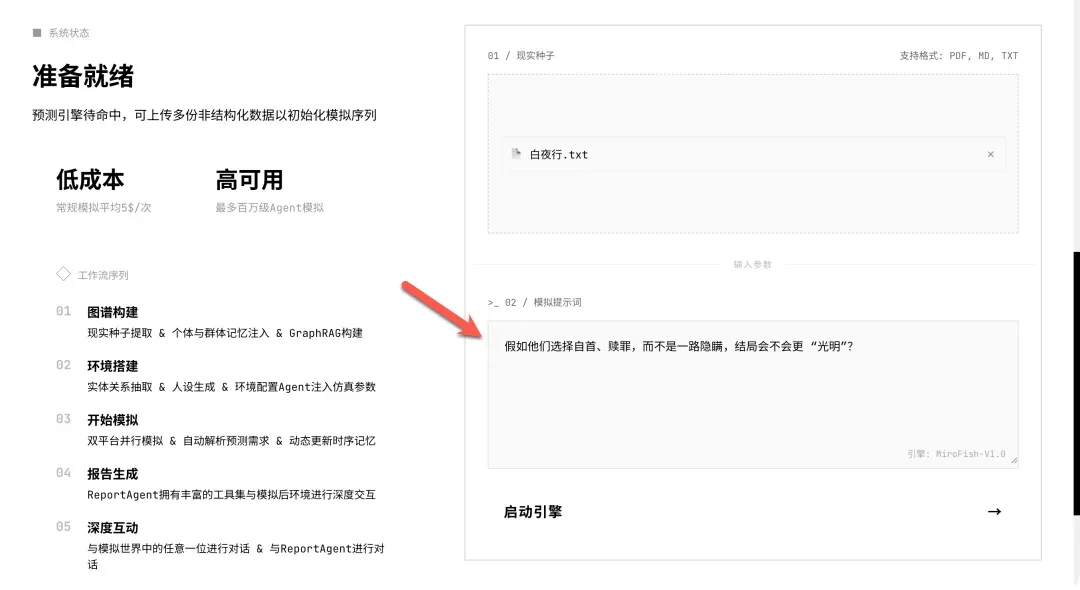
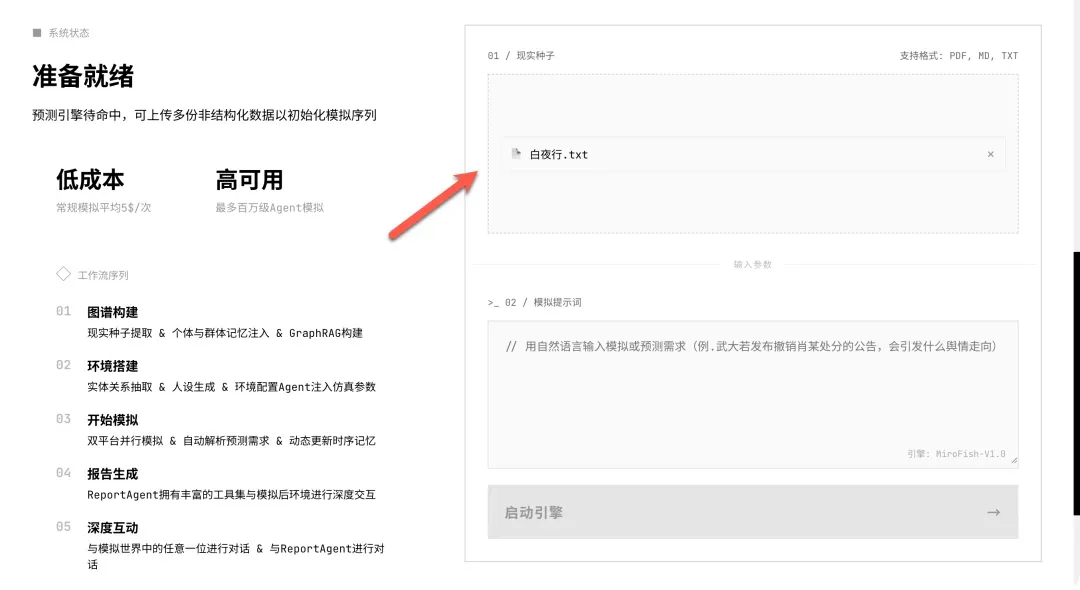 接着,在指定区域输入你想要预测或推演的问题。例如:“假如小说中的主角选择自首、赎罪,而不是一路隐瞒罪行,他们的结局会不会更光明?”
接着,在指定区域输入你想要预测或推演的问题。例如:“假如小说中的主角选择自首、赎罪,而不是一路隐瞒罪行,他们的结局会不会更光明?”
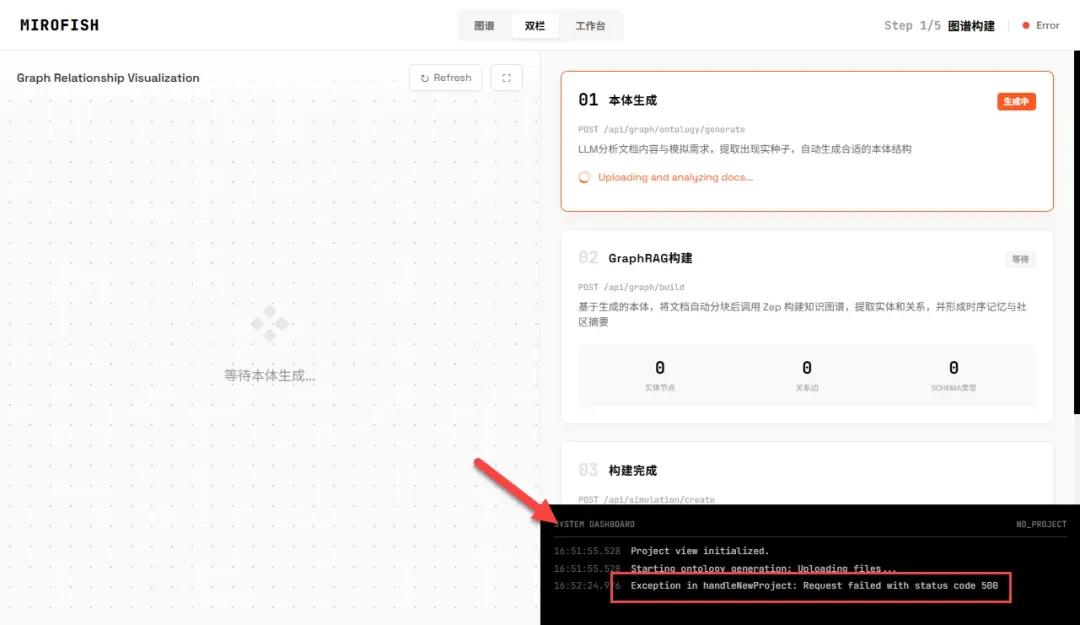
 重要提示:如果提交后系统返回500错误,这可能是所选LLM模型返回的数据格式不符合预期导致的。解决方法通常是尝试更换另一个模型或LLM服务提供商。
重要提示:如果提交后系统返回500错误,这可能是所选LLM模型返回的数据格式不符合预期导致的。解决方法通常是尝试更换另一个模型或LLM服务提供商。
 在一切配置正常的情况下,系统生成“本体”(即基础智能体框架)的速度通常比较快。
在一切配置正常的情况下,系统生成“本体”(即基础智能体框架)的速度通常比较快。
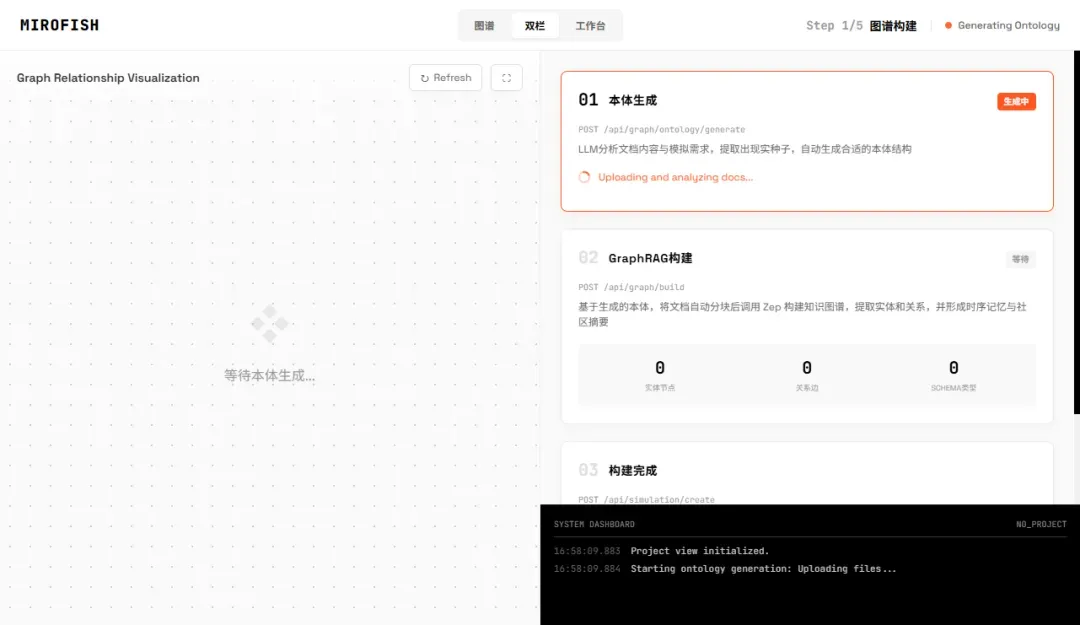 此时,你可以通过查看Docker容器的实时日志,来确认模拟任务是否正在后台稳定运行。
此时,你可以通过查看Docker容器的实时日志,来确认模拟任务是否正在后台稳定运行。
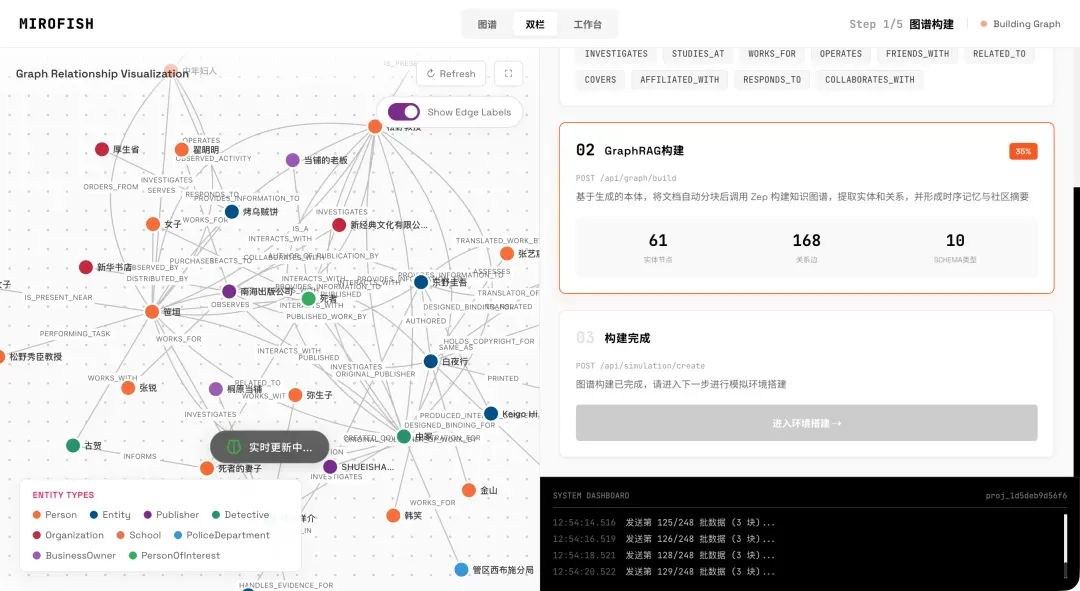
 本体生成完毕后,系统会自动进入下一阶段——图谱构建。这一步需要处理大量实体和关系,通常是整个流程中最耗费时间的环节。
本体生成完毕后,系统会自动进入下一阶段——图谱构建。这一步需要处理大量实体和关系,通常是整个流程中最耗费时间的环节。
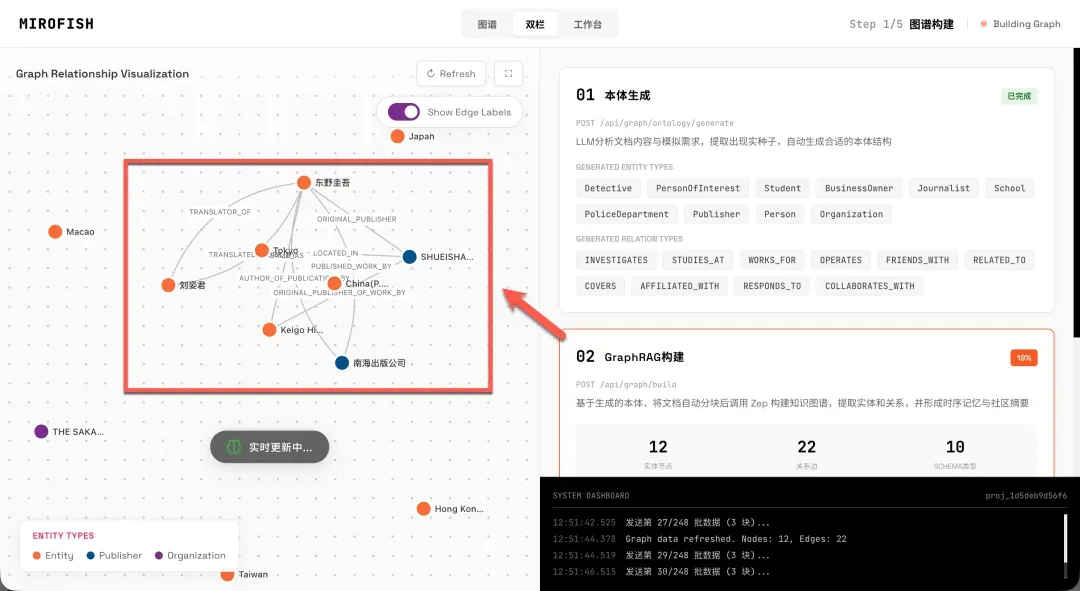
 特别需要注意的一个坑:为了提高分析准确性和效率,建议上传的文档内容尽可能“干净”,避免包含过多与核心分析目标不相关的冗余数据(如广告、无关注释等)。
特别需要注意的一个坑:为了提高分析准确性和效率,建议上传的文档内容尽可能“干净”,避免包含过多与核心分析目标不相关的冗余数据(如广告、无关注释等)。
 在本次演示中,由于上传的《白夜行》全文内容体量较大,很快就超出了ZEP免费套餐的额度限制,导致图谱构建进程在约15%时停滞不前。
在本次演示中,由于上传的《白夜行》全文内容体量较大,很快就超出了ZEP免费套餐的额度限制,导致图谱构建进程在约15%时停滞不前。
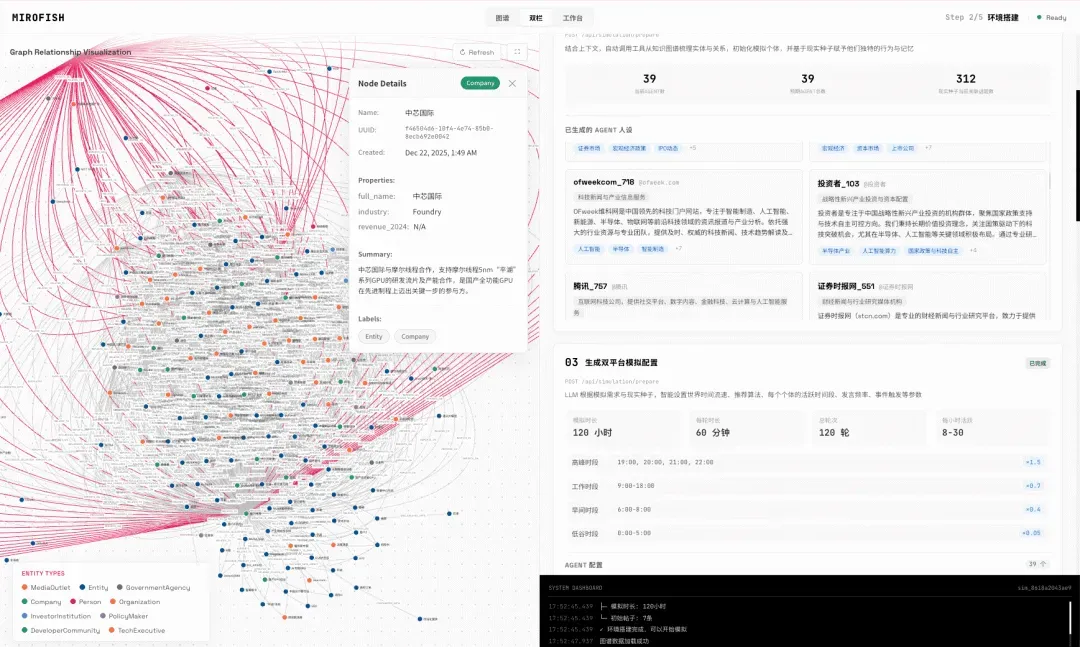
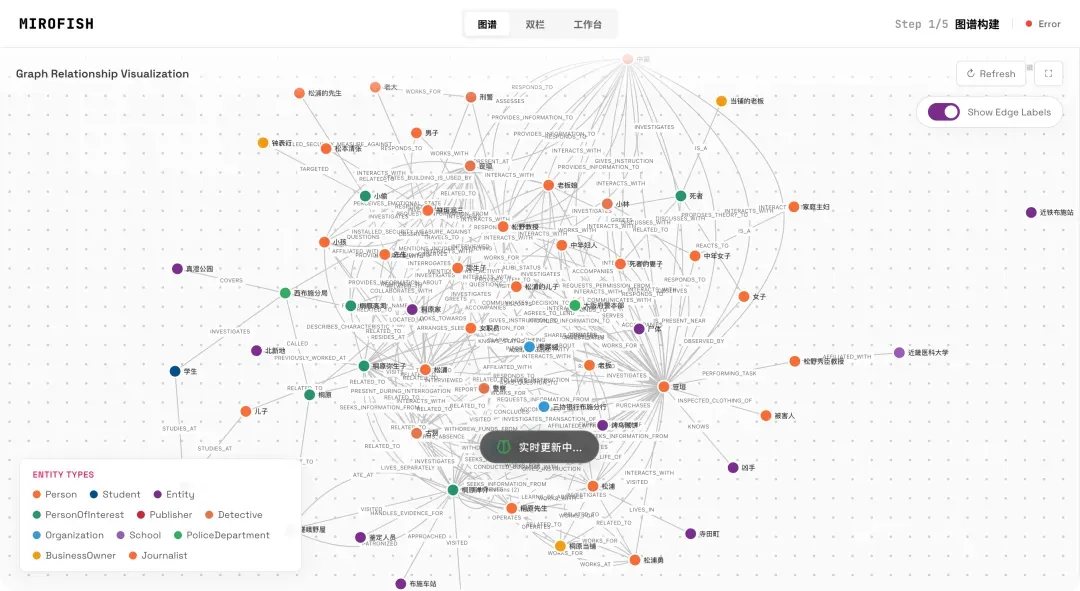
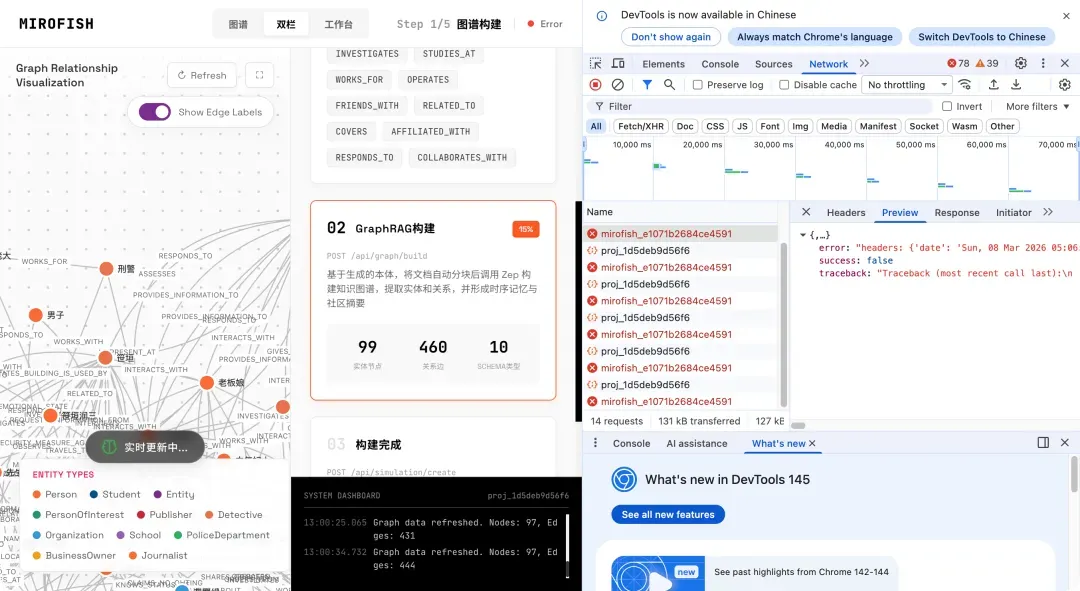 尽管未能完成全部构建,我们仍可以预览已生成的部分知识图谱。图中每个节点代表一个实体(如人物、地点、事件),节点之间的连线则清晰标明了它们之间的关系。
尽管未能完成全部构建,我们仍可以预览已生成的部分知识图谱。图中每个节点代表一个实体(如人物、地点、事件),节点之间的连线则清晰标明了它们之间的关系。
心得体会:优势、局限与未来展望
这个项目的部署与调试过程花费了我不少时间,早期曾遇到各种生成失败的问题。后来有幸参考了技术社区中“老苏”发布的详尽教程,才发现需要正确配置后端接口地址等关键参数,调整之后终于成功运行起来。
MiroFish这款应用的理念非常超前,它通过多智能体模拟构建平行世界,为复杂系统的推演提供了崭新的视角。试想一下,将一部连载中断的小说输入其中,就有可能推演出作者未写出的结局;或者将市场数据导入,便能模拟股价在特定舆情下的走势。这无异于为分析者开启了一个“上帝视角”的外挂。不过,本次实践我也犯了一个激进错误——直接将整本《白夜行》投入分析,导致ZEP免费额度迅速耗尽。如果未来该项目能将ZEP这类核心组件替换为可本地化部署的开源替代方案,其可玩性和实用性将会大增。
最后必须着重提醒:MiroFish在运行模拟时会频繁、大量地调用LLM,Token消耗速度极快,使用时务必密切关注所用模型的额度与计费情况,建议从小规模文本开始尝试。
综合体验评价:
- 推荐指数:⭐⭐⭐⭐(理念有趣,能窥见未来发展的多种可能性)
- 使用体验:⭐⭐⭐(核心操作流程直观,入门门槛较低)
- 部署难度:⭐⭐(基于Docker,部署过程较为简单)