从代码补全到完整交付:AI编码实战深度剖析与前提条件
首先,为什么我想认真做这次 AI Coding 验证?
如今大家对 AI Coding 已经相当熟悉了。无论是代码补全、编写工具函数、搭建一个新页面,还是完成一个演示Demo,它大多都能胜任,而且很多时候表现得相当不错。
因此,如果仅仅讨论“AI是否会写代码”,这个议题的实际探讨价值已经不大。 至少在局部编码这一具体任务上,它的可用性已经经过了反复验证。
然而,我一直更想探究的是另一个问题:
如果我们把时间线拉长,不局限于让它补充某一段代码,而是让它真正投身于一个完整的交付流程。
从需求理解开始,到功能实现,再到验证与收尾,它目前究竟能做到什么程度?
换句话说,我这次真正想要验证的,并非AI能否辅助写代码,而是它是否有可能从局部参与演进到完整参与交付。
这个问题,表面上看只差一步,实则天壤之别。
局部参与,验证的是它的编码能力;而完整参与交付,验证的则是在一个完整任务链路中的稳定性:AI Coding能否理解任务边界,能否按照既定要求推进,能否在给定的约束下把事情做完,而不是仅仅产出几段“看起来还行”的代码。
为了更清晰地审视这个问题,我并没有直接使用现有的业务项目进行尝试。
一方面,业务项目本身不适合公开展示;另一方面,我也不希望将业务复杂度、历史遗留问题以及真实环境的诸多限制混为一谈,导致最终难以判断,究竟是AI的能力到达了边界,还是测试条件本身不够纯粹。
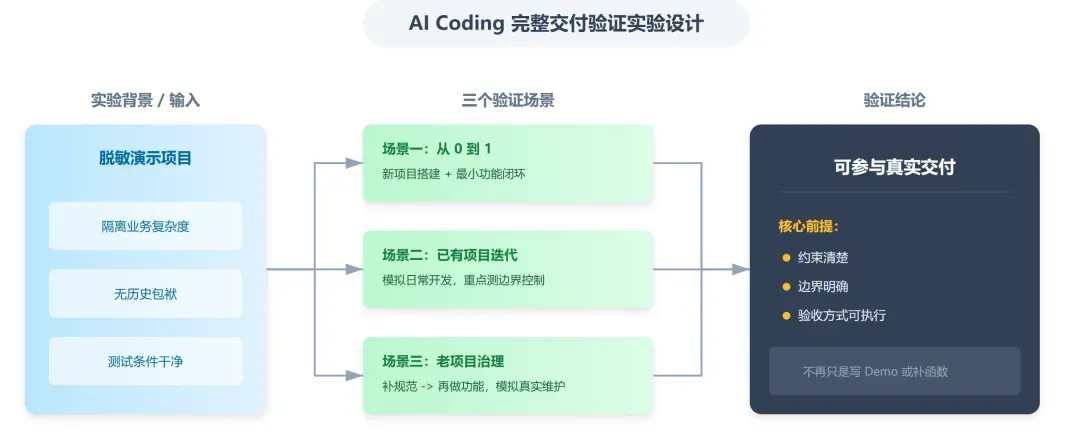
因此,这次我专门搭建了一个脱敏的演示项目,并刻意将验证过程拆分为三个典型场景:
- 场景一:从零到一。直接要求AI按照指定要求搭建一个新项目,并完成一个最小可行功能。
- 场景二:迭代加需。在已经搭建好的项目中继续添加新需求,模拟更贴近日常开发的迭代过程。
- 场景三:老项目攻坚。模拟一个文档不全、约束模糊的老旧项目,先补充必要的工程规范,再进行功能开发。
这三个场景串联起来,基本就构成了我想验证的那条完整问题链:今天的AI,究竟能不能真正参与一段完整的交付过程,而不仅仅是把局部编码做得更快?
如果先给出结论,我目前的判断是:
AI Coding 已经不再仅仅适合写Demo、补函数、起页面了。
在约束清晰、边界明确、验收方式可执行的前提下,它已经能够参与相当一部分真实的交付工作。
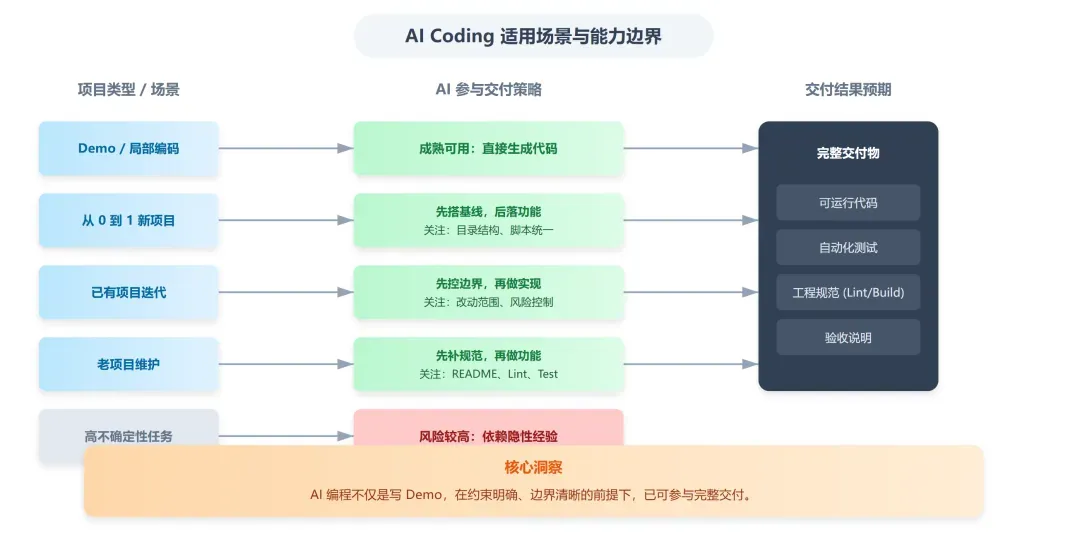
但这个结论并非无条件成立。从本次实践来看,它更适配以下三类项目场景:
- 全新项目: 适合先建立基线,再落地最小可行功能。
- 结构相对清晰的已有项目: 适合在边界明确的前提下进行迭代开发。
- 约束缺失但尚可运行的老项目: 适合先补充最小工程规范,再继续后续开发。
如果用更直接的方式表述,我现在会将AI编程的可用范围理解为:
- 做Demo、局部编码、小功能实现: 技术已比较成熟。
- 做新项目初始化和最小功能闭环: 可以胜任。
- 做已有项目中的小到中等规模迭代: 可以胜任,但前提是任务边界需事先界定清楚。
- 做老项目直接功能开发: 不建议直接开始,更适合采取“先补规范,再做功能”的策略。
- 做高不确定性、强业务耦合、约束大量依赖隐性经验的任务: 表现仍然不够稳定。
换言之,AI已经能够参与交付,但它更像一个需要被明确定义、有效约束、并得到充分验证的协作对象,而非一个将需求丢过去就能自动完成收尾的全能开发者。
下面,就是我为了验证这个判断,专门设计并执行的一条完整实验链路。
第一部分:输入与模型——决定结果的关键因素
——
真正影响结果的,往往不是模型,而是输入
在刚开始进行这次实践时,我的想法比较直接:既然要验证AI能否承担更多工作,最自然的方式就是将任务交给它,让它尽量推进,我再进行检查、修正和收尾。
简单来说,就是先看看它能“接住”多少。这种用法在许多小型、独立的任务上确实没有问题,甚至常常让人觉得非常顺畅。
尤其是那些上下文简单、边界清晰的事情,比如补充一个函数、编写一个独立页面、修改一个相对孤立的小功能,AI通常能快速给出不错的结果。
也正因如此,在初期很容易形成一种印象:似乎只要需求描述得差不多,后续的事情就可以交给它了。
然而,当任务变得稍微完整一些时,问题便开始逐渐显现:
- 有时功能虽然实现了,但一些关键细节与预期不符。
- 有时代码可以运行,但实现方式与项目原有的组织风格不统一。
- 还有些情况是,我们以为理所当然的前提并未被明确写出,于是AI会自行“脑补”,而它补全的内容未必是我们真正想要的。
后来我逐渐意识到,这其中最棘手的地方,往往并非“它把代码写错了”,而是很多偏差在代码编写之前就已经发生。更准确地说,许多问题出现在“理解任务”这一初始环节。
当任务仅限于局部编码时,这个问题尚不明显。因为上下文短、目标集中,即便AI理解不够完整,影响范围也通常有限。
然而,一旦任务开始变长,开始涉及需求边界、功能约束、验收标准、回退机制等内容时,如果输入本身不完整,后续过程就难以稳定。
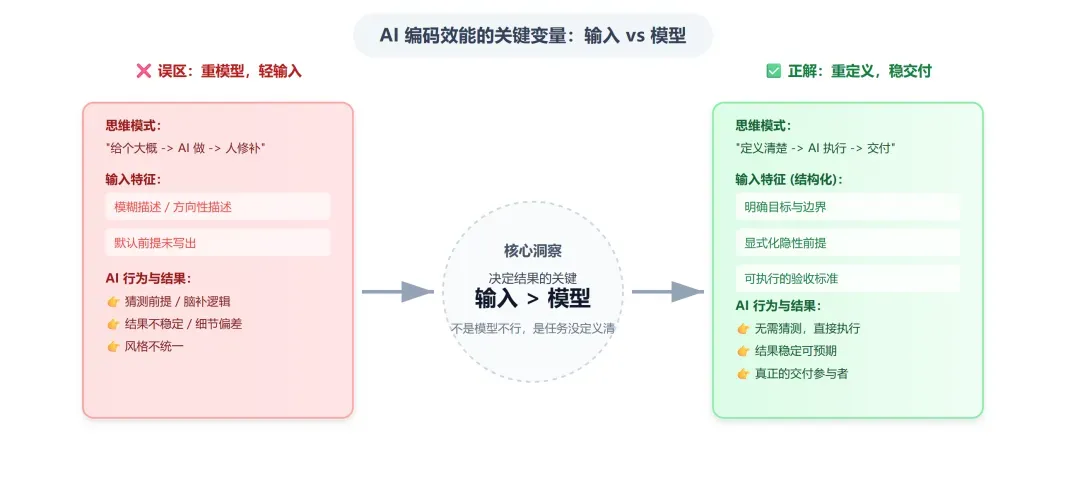
也正是在这个阶段,我越来越确信:决定结果质量的关键,不只是模型能力,更在于我们究竟为它提供了怎样的输入。
如果输入只是一个方向性的模糊描述,那么AI在很多时候所做的并非执行,而是在“猜测”。它一边编写代码,一边补充那些我们未曾明确说明的前提假设。
问题恰恰在于:那些没有被明确写出来的前提,往往才是决定结果是否稳定的真正因素。
因此,我后来的调整重点,不再是“如何把提示词写得更加华丽”,而是另一件更为基础的事情:如何将任务定义得更加完整。
我不再满足于只提供一个需求描述,而是尽量将目标、边界、规则、验收方式等内容提前写清楚,让AI面对的并非一个模糊指令,而是一份相对明确的执行说明书。
将模糊描述与结构化的任务定义放在一起对比,差异会非常直观:
左侧这类描述,人类可以依靠经验补全许多隐含前提;但放在AI面前,往往就变成了大量需要猜测的默认假设。
右侧这种写法看起来或许更“啰嗦”,但真正能显著提升输出稳定性的,通常恰恰是这些被显式写出的边界、规则和验收条件。
完成这次实践后,我越来越确定,真正决定AI Coding效果的,往往不是模型本身,而是你提供给它的输入,是否是一份足够清晰、完整的任务定义。
第二部分:配合模型的思维方式——需求文档需要升级
——
如果想让 AI 参与交付,需求就不能只写给人看
过去编写需求文档,更多是为了让人能够看懂。把业务目标说清楚,流程大致讲明白,关键页面和规则列出来,通常就可以推动后续开发了。
许多默认的前提不一定专门写出来,因为团队成员大多了解项目背景,也知道某些地方通常如何处理。即便文档中写得不够细致,许多信息也能在协作沟通过程中逐渐补全。
但这次实践让我越来越清晰地感受到,AI所处的并非这样的协作环境。
在人与人协作时,很多东西可以依靠经验、共享上下文以及来回沟通来补齐。但AI不同。它能依赖的,基本上就是你明确提供给它的那部分信息。
这意味着,以前那些“默认大家都知道”的内容,放到AI面前,其实很多都需要重新被显式地写出来。否则,它只能根据现有输入去推测,而一旦进入推测模式,结果就会变得不稳定。
因此,后来我开始要求自己,将需求描述得更具体:
- 不仅要写“这次要做什么”,还要写“哪些事情这次不做”。
- 不仅要写功能本身,还要写规则和边界。
- 不仅要写页面和交互,还要写最终如何验证才算完成。
- 如果存在上线风险,还要提前考虑是否有回退方案。
说得更直接一些,我后来更希望需求文档能像一份可以直接执行的说明书,而不仅仅是一个方向性的概述。
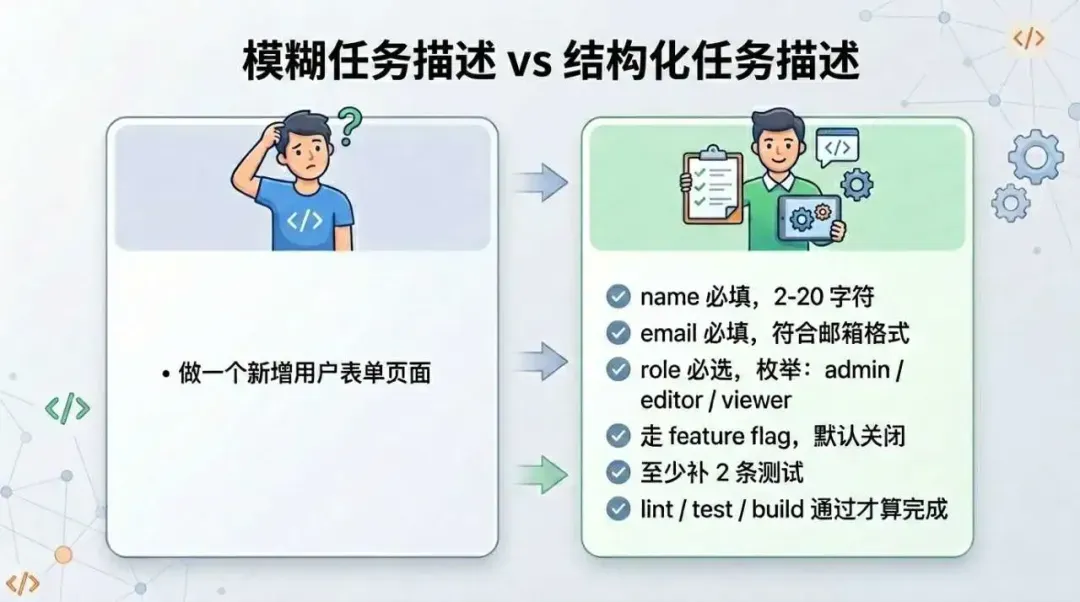
例如在这次实践中,其中一个很小的功能是新增一个用户表单。
如果只是写一句“做一个新增用户表单页面”,那么这个任务其实非常宽泛。字段如何设计、校验做到什么程度、是否需要开关控制、要不要补充测试、做到什么程度算完成……这些统统没有边界,AI只能自行发挥。
但如果将这些前提提前补充完整,事情就会清晰很多:
## 目标
在当前项目中实现一个“新增用户表单”功能,并通过 feature flag 控制新表单是否启用。
## 校验规则
### name
- 必填
- 长度 2 到 20
### email
- 必填
- 必须符合邮箱格式
### role
- 必填
- 枚举值固定为:
- `admin`
- `editor`
- `viewer`
## Feature Flag 要求
新增 `newUserForm` 开关,并满足:
- 默认关闭
- 开启时展示新表单
- 关闭时展示占位内容或旧版占位区域
feature flag 要显式、易定位。
## 测试要求
至少补充以下测试:
1. feature flag 开关对应的渲染分支
2. 表单校验错误展示
如果实现方式合理,可补更多,但不要为了数量堆测试。
## 验收标准
完成后至少满足:
1. 新表单可渲染
2. 校验规则生效
3. feature flag 生效
4. `pnpm lint` 通过
5. `pnpm test` 通过
6. `pnpm build` 通过
PS:其实从这里大家就可以直观感受到,代码不再是唯一必须的,自然语言本身就可以作为准确定义的“代码”。
这也是我本次实践中感受最深的一点:
如果你的目标仅仅是让AI帮忙写点代码,那么以前那种偏描述性的需求文档或许还能凑合;但如果目标是让它真正参与交付,那么需求文档本身就不能只写给人看。
一旦需求被写清楚,AI不一定会突然变得更“聪明”,但它的表现通常会显著稳定很多。
第三部分:从零到一——验证项目初始化能力
——
拿一个新项目做验证
第一个场景,我特意从一个最“空”的状态开始。
原因很简单。如果AI连从零到一都承接不住,那么后续讨论它如何在已有项目中迭代,意义并不大。因为在那种情况下,它更多是在已有上下文中“顺势而写”,而非真正承担一段完整的起步工作。
此外,从零到一还有一个好处:许多问题会暴露得更为直接。
没有现成的目录结构,没有既定的开发约定,也没有默认的共享上下文。在这种情况下,要将一个项目真正搭建起来,AI面对的就不只是“写代码”本身,而是需要先处理一层更基础的内容:如何组织项目结构、如何约定脚本命令、如何建立验证方式、以及后续是否便于继续迭代。
因此,在这个场景里,我最初并没有将目标设定为“让它快速生成一个页面”,而是先为自己定下了一个更明确的判断标准:这个项目至少要像一个能够持续发展的项目,而非一个仅仅能跑起来的空壳。
也就是说,它需要满足的不只是“能够启动”,还应包括:
- 结构足够清晰、合理。
- 脚本命令统一、规范。
- 基本的验证流程(如lint, test, build)能够执行。
- 后续能够方便地继续添加需求。
- 整个项目适合作为后续两个场景的验证基础。
从这个角度看,我要验证的其实不是“AI会不会初始化一个Vite项目”,而是:在没有现成上下文的情况下,它能否按照要求,将项目搭建到一个可继续交付的状态。
所以在这个阶段,我最先编写的不是业务功能,而是一份项目初始化规格说明:
## 目标
基于以下技术栈初始化一个现代化前端项目:
- pnpm
- Vite
- React
- TypeScript
- Biome
- Vitest
- React Testing Library
- Husky
- Commitlint
项目初始化后,应具备继续承接后续功能迭代的能力。
## 本次要做的事
1. 初始化项目
2. 建立清晰的基础目录结构
3. 配置 Biome
4. 配置 Vitest 与 React Testing Library
5. 配置 Husky
6. 配置 Commitlint
7. 补齐基础 scripts
8. 提供最小可用的 README
9. 提供至少 1 条可运行的样例测试
## 目录要求
优先建立以下结构:
- `src/app/`
- `src/pages/`
- `src/components/`
- `src/lib/`
- `src/tests/`
- `spec/`
目录不要过度设计,也不要创建无用目录。
## 脚本要求
至少具备以下命令:
- `pnpm lint`
- `pnpm format`
- `pnpm test`
- `pnpm build`
- `pnpm dev`
## README 要求
README 至少说明:
- 项目如何安装依赖
- 项目如何启动
- 如何执行 lint / test / build
- 基础目录结构说明
## 验收标准
完成后至少满足:
1. `pnpm lint` 可执行
2. `pnpm test` 可执行
3. `pnpm build` 可执行
4. README 可读
5. 目录结构清晰
这份规格说明中没有太多复杂内容,主要目的是将一些项目级别的约束事先说明清楚,例如技术栈选型、目录结构、脚本要求、测试基线,以及README至少需要包含哪些信息。
换句话说,我希望AI面对的并非一句模糊的“帮我起个项目”,而是一份更加明确的初始化要求。
这个动作看起来有点“慢”,但事后回顾,它其实非常关键。
因为在从零到一的场景中,最容易出现的问题往往不是代码写错,而是方向从一开始就偏离了。
例如,引入过多不必要的依赖、目录划分过于零散、脚本命令不统一、测试环境缺失,或者为了追求速度临时拼凑了一套难以持续维护的结构。短期来看,这些都不是致命问题,但如果一开始没有约束好,后续每添加一个需求,都会不断放大这些问题。
因此,在真正让它动手编码之前,我并未直接要求它开始修改代码,而是先让它将实施计划说出来:
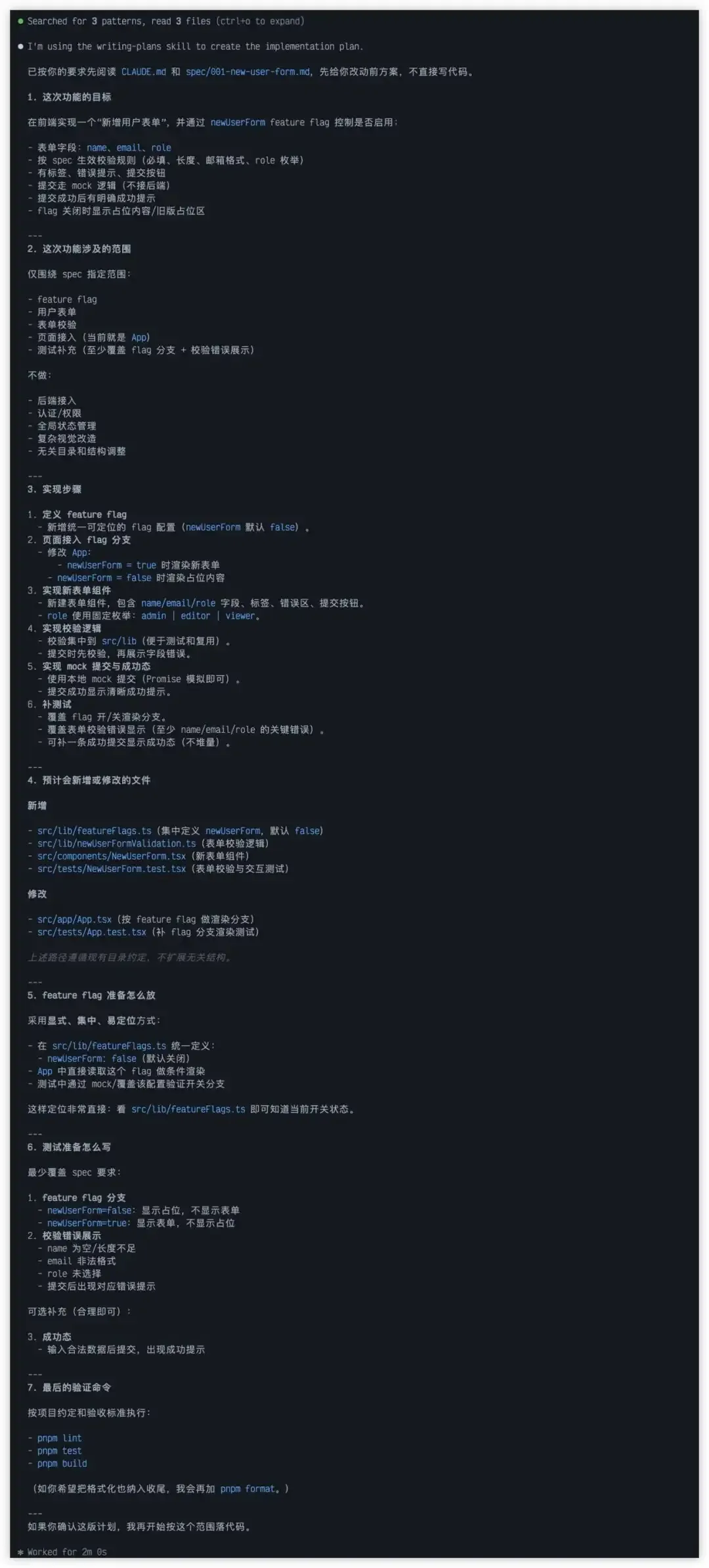
我会先审视:
- 它准备如何拆解步骤。
- 它认为需要新增或修改哪些文件。
- 依赖是否会引入过多。
- 它计划如何验证结果。
这个阶段,我关注的重点不是“它写得快不快”,而是“它理解得对不对”。
因为很多偏差,其实在真正开始写代码之前就已经形成。如果方向一开始就偏了,后续代码写得再认真,也只是沿着一个不够理想的方向越走越远。
等这些计划看起来没有问题后,后续的实现过程反而会顺理成章。到了这个阶段,我真正关心的也不再是它一共写了多少行代码,而是最终的产出能否顺利通过验证。
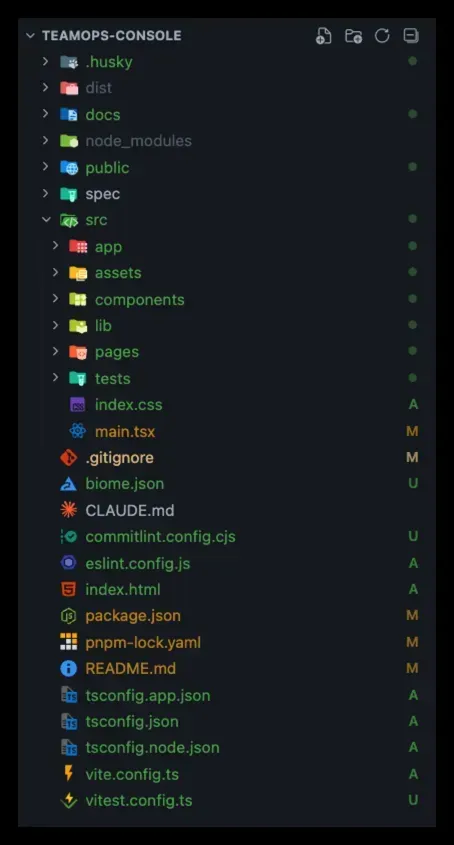
$ pnpm lint
...
Checked 6 files in 2ms. No fixes applied.
$ pnpm test
...
Test Files 1 passed (1)
Tests 2 passed (2)
...
$ pnpm build
...
✓ built in 397ms
场景一进行到这里,其实只能证明一半:AI已经能够将项目基线搭建起来,并将最基本的工程约束确立起来。
但如果仅仅停留于此,还不能完全说明它已经具备继续交付业务功能的能力。
因此,在项目基线搭建完成后,我并未立刻进入第二个场景,而是先在这个新项目中落地了一个最小可行功能:新增用户表单。
这一步至关重要,因为如果只完成了项目初始化,还只能说明AI能够搭建项目框架,尚不能完全证明其具备持续交付功能的能力。
只有当它能够在这个基线上继续完成一个具体功能,并同时处理好校验、开关、测试等细节时,场景一才算真正形成闭环。
所以我为它设计的第一个功能并不复杂,但刻意保留了几个非常“贴近真实项目”的要素:
- 表单字段与校验规则。
- Feature flag(功能开关)。
- 成功状态提示。
- 最低限度的测试覆盖要求。
- 明确的验收命令。
## 功能要求
新增一个用户表单,包含以下字段:
- `name`
- `email`
- `role`
## 校验规则
### name
- 必填
- 长度 2 到 20
### email
- 必填
- 必须符合邮箱格式
### role
- 必填
- 枚举值固定为:
- `admin`
- `editor`
- `viewer`
## 交互要求
- 展示字段标签
- 展示校验错误信息
- 提供提交按钮
- 提交可使用 mock 逻辑,不接后端
- 提交成功后有明确成功提示
## Feature Flag 要求
新增 `newUserForm` 开关,并满足:
- 默认关闭
- 开启时展示新表单
- 关闭时展示占位内容或旧版占位区域
feature flag 要显式、易定位。
## 测试要求
至少补充以下测试:
1. feature flag 开关对应的渲染分支
2. 表单校验错误展示
如果实现方式合理,可补更多,但不要为了数量堆测试。
## 验收标准
完成后至少满足:
1. 新表单可渲染
2. 校验规则生效
3. feature flag 生效
4. `pnpm lint` 通过
5. `pnpm test` 通过
6. `pnpm build` 通过
从实际改动的文件来看,这次实现也基本控制在了一个很小的范围内:页面层负责功能入口,组件层承载表单本身,lib层处理规则和开关逻辑,测试则分别覆盖页面分支和表单行为。
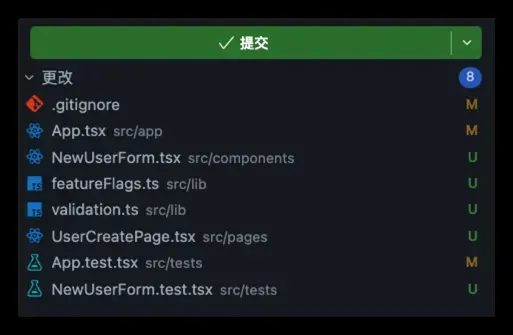
其中一个我刻意要求保留的点,就是feature flag。因为我想验证的不仅是“页面能否做出来”,还包括“这个功能是否具备最小的回退空间”。
// featureFlags.ts
export const featureFlags = {
newUserForm: false,
}
校验逻辑我也要求尽量集中,而不是分散在组件内部。这样一方面更贴近真实项目的代码组织方式,另一方面也更容易进行测试和复查。
// validation.ts 核心代码
export const roleOptions = ['admin', 'editor', 'viewer'] as const
export function validateUserFormValues(values: UserFormValues): UserFormErrors {
const nameRequiredError = validateRequired(values.name, '姓名为必填项')
const emailRequiredError = validateRequired(values.email, '邮箱为必填项')
const roleRequiredError = validateRequired(values.role, '角色为必填项')
const nameError =
nameRequiredError ??
validateLengthRange(values.name, 2, 20, '姓名长度需在2到20个字符之间')
const emailError =
emailRequiredError ?? validateEmailFormat(values.email, '邮箱格式不正确')
const roleError =
roleRequiredError ??
validateOneOf(values.role, roleOptions, '角色不合法')
return {
name: nameError,
email: emailError,
role: roleError,
}
}
在测试这一步,我并未要求它堆砌大量测试用例,而是要求它将关键行为覆盖清楚。
页面层的测试主要验证feature flag开关前后的渲染分支:开关关闭时显示占位内容,开启时显示新表单。表单层的测试则覆盖了必填校验、长度和邮箱格式校验、非法角色值校验,以及最终的提交成功提示。
it('renders placeholder when newUserForm flag is off', () => {})
it('renders new user form when newUserForm flag is on', () => {})
it('shows required errors when submitting empty form', () => {})
it('shows success message after valid submission', () => {})
进行到这里,其实已经足以说明一点:只要规格描述得足够清晰,AI能够承接的就不仅仅是页面本身,还包括规则、校验和测试这些过去往往需要人工手动补齐的部分。
但我还想再向前推进一步。
在项目基线和第一个最小功能都跑通之后,我并未仅仅停留在单元测试和构建通过,而是又增加了一层自动化验收:要求Claude Code借助Playwright CLI,从真实用户的视角将关键流程再运行一遍。
这一步对我而言非常重要。因为如果只查看代码、单元测试和构建结果,虽然已经能证明功能基本成立,但这仍然更偏向于“工程内部视角”。
而我本次想验证的是AI能否更完整地参与交付,那么它就不应该只负责把代码写出来,还应该尽可能地参与“验证功能是否真正可用”这件事。
因此,我给Playwright设定的测试范围控制得很小,只覆盖最核心的用户路径:
- 提交空表单时,是否能够正确展示必填项的校验错误信息。
- 输入非法内容时,是否能够展示对应的错误提示。
- 输入合法内容并提交后,是否会出现成功提示。
完成这一步后,我对场景一的判断才真正完整起来:
从零到一,AI不仅能够搭建起项目基线,也不仅能实现第一个功能,而是已经能够借助自动化工具,将这个功能从实现一路推进到最基本的用户验收环节。
如果一开始仅仅追求“先跑起来”,很容易得到一个表面上速度很快、但后续却越来越难以继续开发的项目。反之,如果先将项目级别的规则说清楚,再让AI去执行,并在最后补充一层真正从用户视角出发的自动化验收,整个过程会稳定得多。
第四部分:存量迭代的难点——关键在于控制边界
——
项目搭起来之后,真正难的是继续往里加需求
第一个场景完成后,项目至少已经站稳了脚跟。基线有了,最小可行功能有了,单元测试、构建以及一轮自动化验收也都顺利通过了。
做到这一步,已经足以说明AI不仅仅会“初始化一个项目”,也不仅仅会“编写一个页面”,而是能够在明确的约束下,将一段从初始化到最小验收的完整链路承接起来。
但这还不够。因为真实的开发工作中,大多数时候并非从零开始,而是在一个已经存在的项目中不断地添加需求、补充功能、进行调整。
这也是第二个场景更贴近日常开发的地方。
项目已经有了基础结构,页面框架已经建立,测试和构建流程也已就绪。此时继续向内添加功能,表面上看起来比从零到一更简单,但实际上,真正麻烦的地方反而开始浮现。
因为在已有项目中,问题的重点往往不再是“能不能写出来”,而是“会不会把原有的结构和约定打乱”。
这类场景中最容易出现的问题,大致有三种:
- 改动范围失控。 本来只是一个不大的需求,但做着做着会牵扯出越来越多的文件修改。
- 触碰了不应修改的部分。 为了实现当前需求,无意中修改了项目原有的核心结构或约定。
- 实现风格不协调。 功能虽然添加进去了,但实现方式与项目既有的组织模式不一致,表面上完成了任务,实际上留下了新的不协调。
因此,到了这个阶段,我自己的使用方式会发生一个明显的变化。
在场景一中,我更关心的是“它能否先把项目框架立起来”;但到了场景二,我最先询问的就不再是“如何实现”,而是“将会影响哪些地方”:
## 目标
在现有项目基础上新增一个用户列表页面,用于模拟已有项目中的功能迭代。
## 功能要求
1. 展示 mock 用户列表
2. 提供搜索输入框
3. 支持按 `name` 或 `email` 过滤
4. 无结果时展示空态
## 本次任务重点
这个任务的重点不只是实现列表,而是控制改动边界。
开始实现前,需要先明确:
- 会新增哪些文件
- 会修改哪些文件
- 改动边界在哪里
- 风险点是什么
不要顺手调整无关结构。
## 输出要求
开始改动前,先输出:
1. 文件改动清单
2. 实现计划
3. 风险与边界说明
4. 验证命令
也就是说,我不会让它一上来就直接生成代码,而是会先要求它把影响范围说清楚:
- 这次需求会影响哪些现有的页面或模块?
- 哪些文件需要新增,哪些文件需要修改?
- 改动范围大致有多大?
- 主要的潜在风险点在哪里?
- 最后准备如何进行验证?
这个动作至关重要。因为在已有项目中,很多问题并非功能本身实现错误,而是原本一个很小的需求,最终却引出了一片不必要的、范围过大的改动。范围一旦失控,后续的验证成本就会显著上升,整个过程也更难收口。
换句话说,在已有项目中,我更关心它“准备动哪里”,而不是它“准备怎么写”。
这背后其实是一个非常实际的考量:如果边界事先界定清楚了,后续的过程通常都会稳定很多。 你知道它准备修改哪些地方,也知道哪些地方最好不要动,那么后续的验证、复查以及继续迭代,都会容易得多。
反之,如果一开始没有把边界框定出来,AI很容易根据它自己的理解去“顺手优化”一些东西。单独看每一处修改,可能都不算离谱,但整体上很容易让项目的结构逐渐变形。尤其是在一个已经存在既定规范和模式的项目中,这种“顺手改一点”的累计代价会非常高。
这次我在已有项目上新增的是一个用户列表页面,功能本身并不复杂,主要包括:
- 展示模拟的用户数据。
- 支持按姓名或邮箱进行搜索过滤。
- 当搜索无结果时,展示空状态提示。
这个功能我刻意选择得比较克制。因为我的目标不是用一个极其复杂的需求来证明AI有多强大,而是想验证:在一个已经成型的项目中,它能否在边界明确的前提下,稳定地将事情做好。
从最终落地结果来看,这次改动也基本保持在一个较小的范围内:
App.tsx 只做了最小化的页面切换入口,使用 useState 在“创建用户”和“用户列表”两个页面之间进行切换。
UserListPage.tsx 作为独立的页面组件,承接了列表展示、搜索框和空状态渲染的逻辑。
mockData.ts 和 userFilter.ts 则将模拟数据和过滤逻辑放回到了lib层,没有直接糅合在页面组件内部。
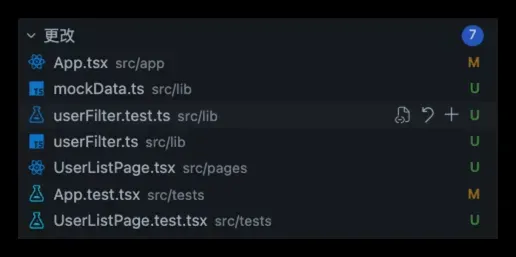
这一点让我比较满意:不是因为它把列表做出来了,而是它没有因为一个小需求就去撬动项目原有的整体结构。
它没有“顺手”引入路由库,也没有借机扩展分页、排序、编辑删除等需求规格中根本没有提及的功能。整个改动看起来更像一次正常、克制的功能迭代,而非一次失控的“顺便升级”。
从页面代码本身来看,这种边界感也比较明显:App.tsx 只负责页面切换和渲染,不承载列表的具体业务逻辑。
例如,这次实际就是用一个非常轻量的本地状态来完成页面切换:
// App.tsx
type Page = 'create' | 'list'
const [currentPage, setCurrentPage] = useState<Page>('create')
{currentPage === 'create' ? <UserCreatePage /> : <UserListPage />}
而列表数据和过滤规则也没有直接写在页面组件里,而是都放在了lib层。数据本身只是一个很轻量的模拟集合,但其结构已是清晰的:
export interface User {
id: string
name: string
email: string
role: string
}
export const mockUsers: User[] = [
{ id: '1', name: '张三', email: 'zhangsan@example.com', role: 'admin' },
{ id: '2', name: '李四', email: 'lisi@example.com', role: 'user' },
{ id: '3', name: '王五', email: 'wangwu@example.com', role: 'admin' },
{ id: '4', name: '赵六', email: 'zhaoliu@example.com', role: 'viewer' },
]
对应的过滤逻辑也被单独抽离成了一个纯函数:
// userFilter.ts
export function filterUsers(users: User[], query: string): User[] {
if (!query.trim()) {
return users
}
const lowerQuery = query.toLowerCase()
return users.filter(
(user) =>
user.name.toLowerCase().includes(lowerQuery) ||
user.email.toLowerCase().includes(lowerQuery),
)
}
这一点非常关键。因为它意味着这次迭代不是简单地把功能“糊上去”,而是尽量遵循项目已有的分层结构,将页面职责、数据职责和规则职责区分开来。这种分层看似并不复杂,但它会直接影响到这个项目未来是否还能健康地持续演化。
在测试这一步,我仍然延续了之前的思路:不追求测试用例的数量,而是优先覆盖关键行为。
这一轮最重要的测试点其实很直接:
- 模拟的用户列表是否能正常渲染。
- 按姓名搜索时,过滤逻辑是否生效。
- 按邮箱搜索时,过滤逻辑是否生效。
- 当没有匹配结果时,空状态提示是否正确出现。
// UserListPage.test.tsx 测试点摘要
it('renders user list with mock data', () => {})
it('filters users by name', () => {})
it('filters users by email', () => {})
it('shows empty state when no results', () => {})
此外,这次我还额外保留了一层更细致的验证:在将过滤逻辑单独抽离出来后,又为它补充了独立的单元测试。这样一来,页面层验证的是“用户能看到什么”,规则层验证的是“过滤逻辑本身是否正确”,两层的职责更加清晰。
// userFilter.test.ts 测试点摘要
it('returns all users when query is empty', () => {})
it('filters by name', () => {})
it('filters by email', () => {})
it('returns empty array when no match', () => {})
it('is case insensitive', () => {})
功能完成后,我依然会要求AI输出一份简短的交付说明,将这次究竟修改了什么、潜在风险点在哪里、验证方式是什么等信息统一交代清楚。
从这次AI给出的总结来看,信息已经比较完整:新增了模拟数据和过滤工具函数,新增了用户列表页面及相应测试,App.tsx 只做了最小化的页面切换改动,最终 pnpm lint、pnpm test 和 pnpm build 全部通过。

这一步看起来只是“补充一段说明”,但它其实很关键。
因为在已有项目中,真正接近完成交付的,不仅仅是代码本身,还包括你能否将这次改动的来龙去脉讲清楚。
修改了哪些地方、影响范围多大、验证到了什么程度,这些信息如果不能被稳定地产出,就很难说AI已经真正融入了交付链路。
因此,第二个场景实践下来,我最大的感受是:在已有项目中,AI的可用性并不只取决于它编码速度的快慢。更重要的是,你有没有事先将任务边界清晰地界定出来。
边界一旦清晰,验证方式也提前明确,它在存量项目迭代中的表现会稳定很多。从某种意义上说,AI真正开始变得“能用”,不是因为它更擅长编写代码了,而是因为它开始学会在清晰的边界内行事。
这也是我对场景二最核心的判断:从零到一,关键在于先建立约束;而在已有项目中继续前行,关键则在于先控制边界。
第五部分:老项目的挑战——首要任务是补齐规范
——
老项目最先要补的,不是功能,而是约束
如果只进行前两个场景的验证,那么这次实验其实还不够完整。
因为无论是新项目,还是相对干净的存量项目,本身都还带有一种“理想环境”的前提假设:结构至少是清晰的,约束至少是能够被描述出来的,验证方式至少是能够补充上去的。
但真实世界中的很多项目,其实并非如此。
真正更常见的情况是:项目已经运行了很长时间,功能不少,代码也不一定不能运行,但许多最基础的东西其实是缺失的。文档不全,脚本不统一,测试没有形成基线,目录结构也未必一致,很多规则都存在于开发者的脑海中,而非沉淀在项目代码或文档里。
所以第三个场景我必须单独测试。因为对许多团队而言,这才是更贴近现实的问题。
而且,这类项目真正棘手的地方,往往并不是“代码陈旧”,而是规则没有被明确地写出来。
什么地方能修改,什么地方最好不要触碰;平时如何运行验证流程,做到什么程度才算能够交付;目录是如何分层的,哪些约束是白纸黑字存在的,哪些只是过去长期协作中形成的默契……
这些事情,在人与人协作时,尚且可以依靠经验来补全。但AI无法看到这些隐性约定。它能看到的,只有代码的表面结构以及你显式提供给它的信息。
这也是为什么我认为,对于老项目,如果直接让AI上手添加功能,体验通常不会太好。

并非因为它一定做不出来,而是在约束缺失的环境下,它只能根据表面代码结构去猜测。一旦进入“猜测”模式,结果就会变得忽高忽低,极不稳定。
因此,在这个场景中,我没有让AI一开始就着手开发功能。我首先让它做的是“补地基”。
## 目标
针对一个“可运行但约束不完整”的前端项目,先补齐最小工程规范,再为后续功能迭代建立稳定基础。
## 本次要做的事
在不大规模重构的前提下,优先补齐以下内容:
1. README
2. 统一 scripts
3. lint / test / build 基线
4. 最小测试样例
5. 项目结构说明
6. 必要的工程说明
## 本次任务原则
- 只补最小可执行规范
- 不进行大范围重构
- 不借机重写项目
- 不调整无关业务逻辑
- 以“先建立最小秩序”为目标
## 结果要求
本次完成后,项目至少应满足:
- README 可读
- 常用命令统一
- lint 可执行
- test 可执行
- build 可执行
- 至少存在 1 条最小测试样例
这里所说的“补地基”,并非指大规模重构,也不是借机将历史项目重新整理一遍。那样做会使事情立刻变得复杂,也不符合本次验证的目标。我更关注的是另一件事:能否先将最低限度的工程秩序建立起来。
这次我故意将项目状态退化到了一个非常常见的状态:README只剩下标题和一句非常笼统的描述。虽然项目本身还能运行,但一个新接手的人几乎无法从中获取任何可执行的有效信息。不知道如何启动,不知道如何验证,也不知道该如何理解目录结构。
而在真正开始修改代码之前,我先让Claude Code进行了一次问题盘点。它先总结当前项目存在的主要问题,然后区分出本次应该优先解决什么、明确不解决什么,最后给出一个最小化的变更策略。
这个顺序非常重要,因为到了老项目场景中,最容易失控的地方就是一上来就“借题发挥”,将“补充规范”演变成“顺手进行全面重构”。
这次它最终收敛下来的改动其实非常少,只修改了3个文件:
- README.md
- package.json
- .husky/pre-commit
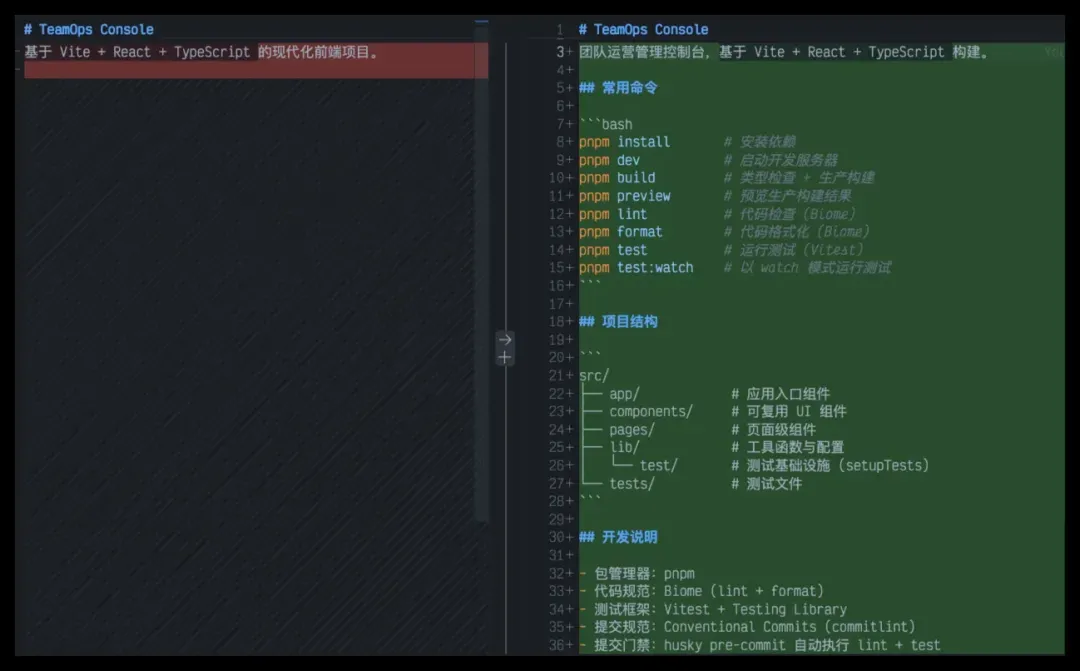
其中最核心的变化,是将README从一个几乎没有有效信息的状态,补充成了一份最小可执行说明。至少补全了以下内容:
- 项目简介。
- 常用命令说明(安装、启动、测试、构建等)。
- 项目目录结构说明。
- 基本的开发指引。
这一步看起来并不“炫酷”,但价值巨大。因为从这一刻起,这个项目不再只是“能够运行”,而是开始转变为一个其他人也能顺利接手、AI也能稳定理解的工程。
除了README,这次还顺手补充了一层很轻量但很有用的门禁:将 pre-commit 钩子从只运行 pnpm test,调整为同时执行 pnpm lint 和 pnpm test。这不是在进行复杂的工程治理,而是在补充最基础的提交前约束,让最小的工程基线真正形成闭环。
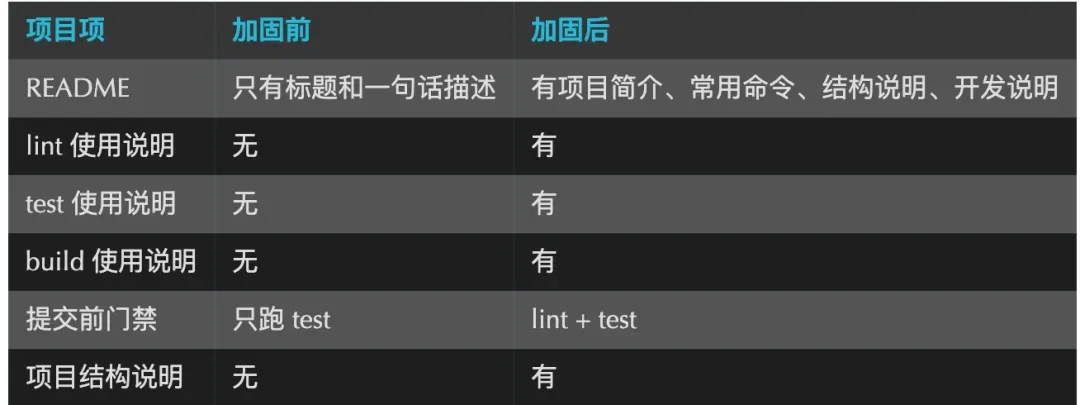
如果将这次变化抽象成一张表格,大致如下:
更重要的是,这次我刻意控制住了“顺手多做一点”的冲动。例如,在问题盘点中其实还发现了诸如eslint残留依赖这类可以继续清理的问题,但我最终没有继续扩大范围。
原因很简单:本轮的目标不是将项目彻底整理得一尘不染,而是先将最低限度的秩序建立起来。如果这个边界守不住,场景三就会从“补充约束”滑向“借机治理一切”。
完成后,我依然用最直接的方式进行了一次验证:
$ pnpm lint
Checked 11 files in 3ms. No fixes applied.
$ pnpm test
Test Files 2 passed (2)
Tests 6 passed (6)
$ pnpm build
✓ built in 401ms
全部通过。
至此,我对场景三的判断就非常明确了:老项目并非不能让AI参与。但如果项目长期缺乏明确的工程约束,直接让其进行功能开发的体验通常会比较差。
更合理的顺序,往往是先补齐最小规范,再逐步将后续的功能迭代工作交给它。换句话说,在老项目中,最先需要补充的,不是功能,而是约束。
第六部分:沉淀的方法论——稳定协作的工作模式
——
做完这三个场景之后,我真正沉淀下来的东西
将这三个场景全部跑完一遍之后,回过头来看,我觉得真正值得留下来的,并非某一个具体的页面或某一段实现代码。
更有价值的,是我在这个过程中逐渐形成了一些更稳定的协作模式和实践方法。
这些方法看起来都不算复杂,甚至很多都并不新鲜。但一旦将它们固定下来,确实会显著影响整个AI协作过程的稳定性。
从这个意义上说,这次实践留下来的,不只是代码,更是几套未来可以继续复用和迭代的工作方式。
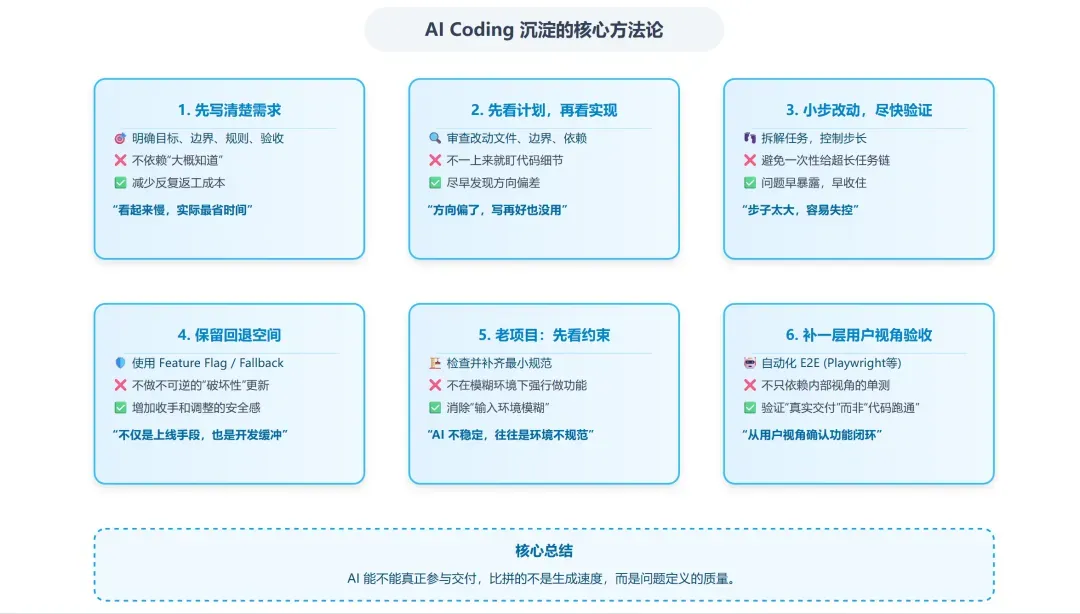
我最终沉淀下来的几条固定做法,大致如下:
- 先把需求写清楚,再让 AI 动手。
- 先看计划,再看实现。
- 小步改动,及时验证。
- 新能力尽量保留回退空间。
- 老项目先补规范,再做功能。
- 对界面功能尽量补充一层接近真实使用的自动化验收。
1. 先把需求写清楚,再让 AI 动手
这听起来像一句正确的废话,但真正实践起来,其实很容易偷懒。尤其是当你已经大致知道自己想要什么时,会下意识地认为有些前提无需写明,可以边做边补充。
但经过这次实践,我越来越确信,如果需求本身是模糊、松散的,那么后续所有的输出结果都会跟着一起变得不稳定。
因此,我现在更愿意先花一点时间,将目标、边界、规则和验收标准写清楚。这一步看起来似乎慢了,实际上是在减少后续来回修正、反复返工的成本。
2. 先看计划,再看实现
现在我基本不会一上来就盯着生成的代码。我更倾向于先看它准备如何实施,会影响哪些文件,边界在哪里,是否会引入过多依赖,验证方式是否合理。
因为一旦方向出现偏差,后续代码写得再认真,也只是沿着一个不够理想的方向越走越远。很多时候,真正节省时间的,不是更快地动手编码,而是更早地发现方向性问题。
3. 尽量让改动保持在较小范围内,并且尽快验证
无论是新项目还是已有项目,我都会越来越在意“这一步的改动幅度是否过大了”。任务一旦被拆解成较小的步骤,很多问题都会更早暴露出来,也更容易被控制和修正。
相反,如果一次性交给AI一个过长的任务链,表面上看似乎省略了中间步骤,实际上往往只是将问题推迟到了更靠后的阶段。
4. 尽量给新能力保留回退空间
这次实践中,我对这一点的感受也非常明显。尤其在AI参与度较高的情况下,能否快速、安全地进行回退,实际上会直接影响你使用它时的“安全感”。
像Feature Flag(功能开关)、Fallback(降级处理)这类做法,不仅仅是一种上线策略,本质上也是一种开发过程中的风险缓冲机制。它让你在推进新功能时,拥有更多收手和调整的余地。
5. 遇到老项目时,先看约束是否存在,再决定是否继续开发功能
以前很多时候,看到一个项目结构不太清晰,也会默认“先把需求做出来再说”。
但经过这次实践后,我会更倾向于先暂停一下,审视这个项目是否连最基础的工程规范都缺失。
如果答案是肯定的,那么就应该先集中精力将这些基础设施补充起来。因为许多所谓的“AI输出不稳定”,追根溯源往往并不是模型本身的问题,而是输入的上下文环境本身就非常模糊、缺乏约束。
6. 对界面功能尽量补充一层接近真实使用的自动化验收
单元测试、代码检查(lint)和构建(build)当然非常重要,但它们更多还是从工程内部的视角出发进行验证。
至少对于表单、列表这类前端界面功能,我现在会更倾向于再补充一层从真实用户视角出发的自动化验收(例如使用Playwright)。这样得到的验证结果会更接近于真实的交付状态,而不仅仅是停留在代码层面。
总结
这次实践完成后,我对AI Coding的理解,与最初相比,确实发生了一些变化。
以前更容易把它视为一个生成代码的工具。你给它一个任务,它返回一段实现;你给它一段报错信息,它再继续帮你修复。整个过程更多是围绕“代码本身”在打转。
但现在,我更倾向于将它视为一个需要被约束、被验证、被有效管理的协作对象。
这并不是说它变得更复杂了,而是因为当你开始期望它完整地参与交付流程时,关注点自然就会从“它会不会写代码”转移到“它能否稳定地按照要求把事情做完”。
从这个角度看,我现在其实不那么在意“它到底有多聪明”。我更在意的是,在边界清晰、约束明确、验收标准可执行的前提下,它能否将一段任务稳定地承接住。
因为对于真实的开发工作而言,可预期性往往比偶尔的惊艳表现更为重要。
至少在我本次实践所覆盖的几个场景中,AI已经不再仅仅是一个局部编码的辅助工具。在明确的约束、清晰的边界以及可执行的验收前提下,它确实已经能够承担相当一部分完整的功能实现工作。
但这个前提始终存在:问题必须先被定义清楚。
如果问题本身是模糊的,许多约束都停留在默认或隐含状态,需求也仅仅是一个方向性的描述,那么让AI参与进来,大概率只会将原本已经模糊不清的要求更快地放大并暴露出来。
因此,如果让我用一句话来总结这次实践,我大概会这样说:
AI能否真正参与交付,最终比拼的,往往不是代码的生成速度,而是“问题定义”本身的质量。
至少对我来说,这次实践最大的收获,并非少写了多少行代码,而是我开始更加认真地对待“如何把一件事清晰、完整地说明白”这项工作。