VibeCoding 告别 AI 失忆:两大 9K+ Star 项目帮你节省 98% Token
在 VibeCoding 过程中,我们几乎总会撞上一个棘手的状况:
AI 编程助手频频“失忆”
来看看两个 Star 数超过 9K 的项目,分别给出了怎样的解决思路:
context-mode:专攻 AI Agent 上下文优化——最高减少 98% 的 token 消耗
claude-context:Claude Code 的代码搜索 MCP——把整个代码仓库变成可用的上下文
有趣的是,这两个项目瞄准的是同一个痛点,但走的路子却刚好相反。
01 几乎所有人都踩过的坑
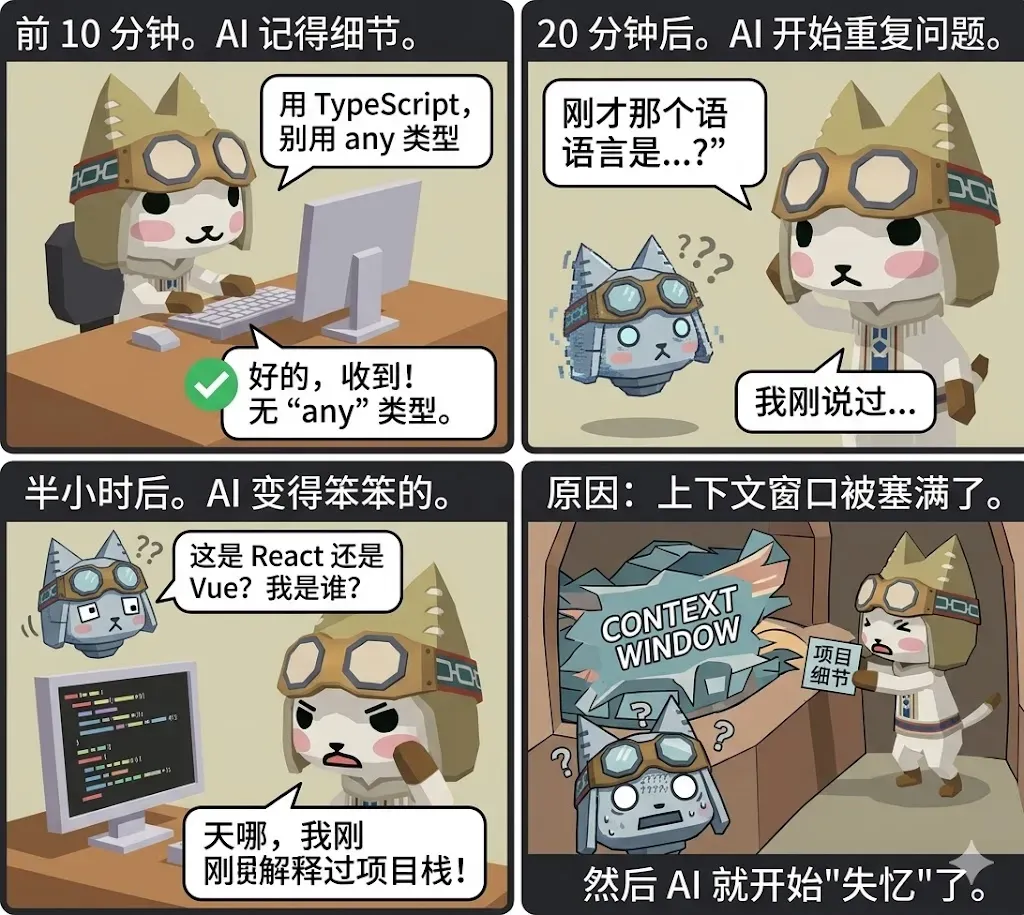
用 AI 辅助写代码的时候,你多半经历过这样的循环:
最初 10 分钟,AI 记得你说过的每一个要求。你嘱咐“用 TypeScript,禁止 any 类型”,它规规矩矩照办。
20 分钟过去,它开始重复询问你早就回答过的事情。
半小时之后,它变得迟钝又茫然,甚至问你“这是 React 还是 Vue?”
不用多想,上下文窗口已经被塞得满满当当。
紧跟着,AI 就开始出现“健忘症”。
02 Context Mode:用“暴力压缩”对抗遗忘
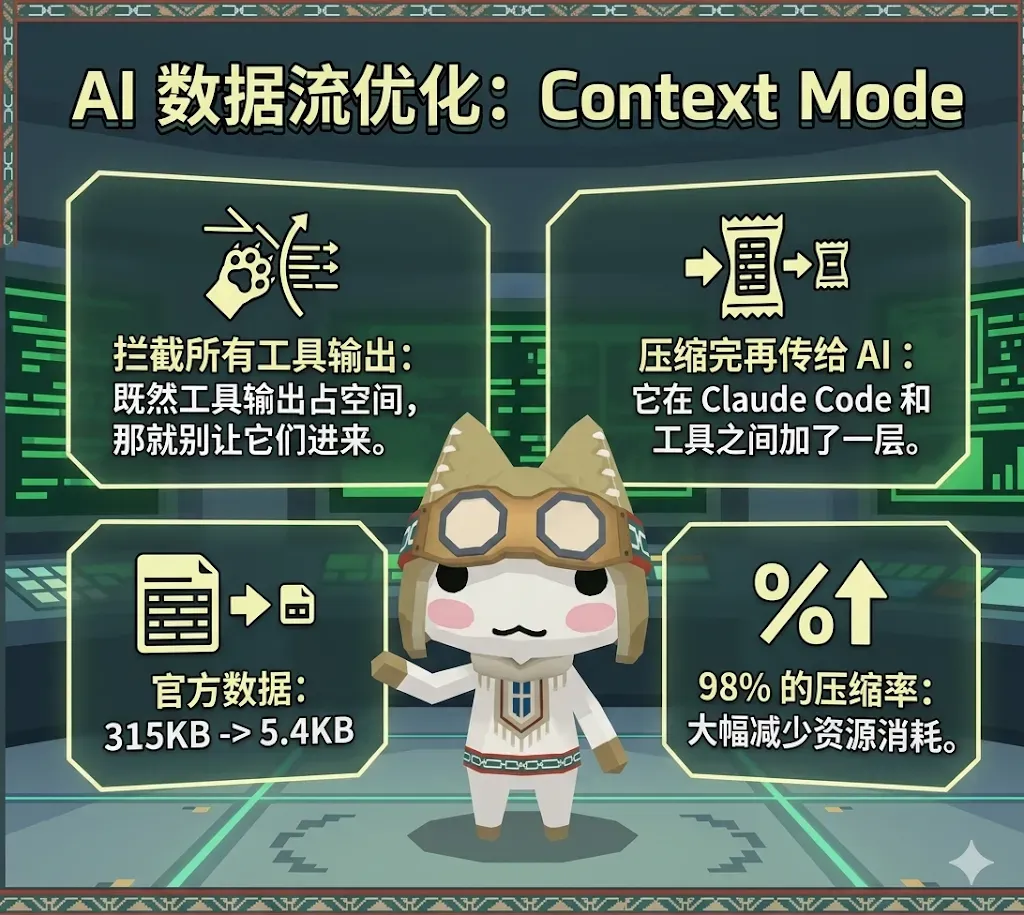
Context Mode 的思路相当直白:
既然工具输出太占地方,那就直接拦下来,别让它塞进上下文。
它在 Claude Code 和各种工具之间插了一层拦截器,把每一次工具产出的内容先压缩,再把浓缩结果传给 AI。
官方提供的数据是,从 315KB 压缩到 5.4KB,压缩率高达 98%。
它是怎么做到的?
我读过它的实现思路,核心是一个三阶段的处理流水线:
第一阶段:剔除明显的噪声
重复出现的调试日志进度条里循环刷屏的信息(如“50%...51%...52%...”)
第二阶段:提取真正有价值的信息
错误描述警告提示状态变更(比如“构建成功”)
第三阶段:建立可检索索引 被压缩掉的内容并不会凭空消失,而是持久化存储在本地数据库中。AI 后续可以通过语义搜索重新找回这些信息,而不必让它们一直占着上下文窗口。
官方还给出了一项评估:在保证检索质量的情况下,token 使用量能够降低 40%。
同一条对话,要么成本降低 40%,要么会话有效时长延长 67%
安装起来只需要一行命令:
claude mcp add context-mode \
-e OPENAI_API_KEY=your-key \
-- npx context-mode@latest
部署完成后对操作习惯几乎是零影响,你依然可以像往常一样和 Claude 对话,压缩和检索在背后悄然运转。
03 Claude Context:用精准检索对抗遗忘
Claude Context 选择了一条截然不同的路线:
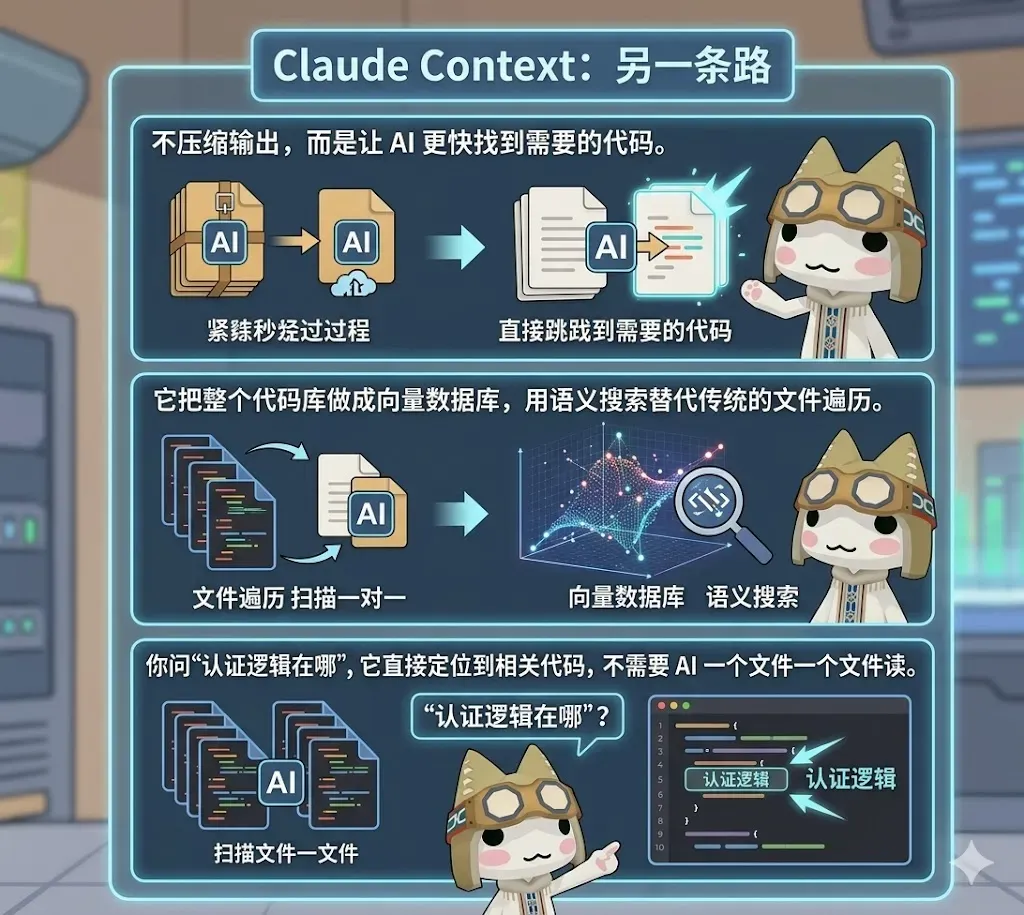
不靠压缩来节省空间,而是让 AI 更快速、更准确地找到真正需要的代码。
它将整个代码仓库构建成一个向量数据库,用语义搜索取代传统的目录遍历。
当你询问“认证逻辑在哪里实现”,它能直接定位到相关的代码片段,而不是让 AI 一个文件接一个文件地翻。
我仔细看了一下它的架构,大致包含:
向量数据库:Milvus(或者 Zilliz Cloud)
Embedding 引擎:支持 OpenAI、VoyageAI、Ollama、Gemini
代码切分:基于 AST 的智能分块
索引策略:Merkle 树驱动的增量更新
这里最值得注意的是增量更新这个设计。
大型项目动辄数万个文件,全量索引可能需要几分钟。但如果你只改了 10 个文件,就只重新索引这 10 个,几秒钟就能完成更新。
从架构上看,它同样以 MCP 服务器的形式存在,但它和 Context Mode 解决的问题切面完全不同。
| 维度 | Context Mode | Claude Context |
| 解决的问题 | 工具输出过于臃肿 | 代码检索效率低下 |
| 核心思路 | 减少进入上下文的信息总量 | 提升进入上下文的信息质量 |
| 适合场景 | 频繁执行命令的工作流 | 大型代码仓库的深度理解 |
假如你的项目只有几千行代码,Claude Context 的优势可能并不突出。
但当你面对几万行甚至几十万行规模时,语义搜索带来的效率提升就是一次质的飞跃。
安装步骤
这里需要自己配置向量数据库,稍微多几步:
git clone https://github.com/zilliztech/claude-context.git
cd claude-context
# 按需配置环境变量
export MILVUS_URL=your-milvus-url
export OPENAI_API_KEY=your-key
npm install
如果你觉得手动配置麻烦,完全可以把上面的命令直接丢给 Agent,让它帮你完成。
04 我的实际搭配方案
Context Mode:
✅ 你经常在对话里执行测试、部署、调试等命令
✅ 单次对话时长经常超过 30 分钟
✅ 工具输出频繁刷屏(比如构建日志几百行持续滚动)
以前大半个小时一过,AI 就开始忘东忘西,现在它能稳定撑到两小时以上。
唯一的代价是本地会占用一点磁盘空间,索引数据库通常几百 MB 左右。
Claude Context:
✅ 项目代码规模超过 1 万行
✅ 经常做架构分析、重构等需要全局理解的活儿
✅ 反复问“某个功能在哪儿实现的”这类问题
对于几千行的小项目,它带来的体感变化不大
但换到大项目里(我亲自在一个 5 万行的仓库上试过),提升非常明显。
过去问一次“用户认证模块在哪”,AI 得挨个读十几个文件。现在靠一次语义搜索就能直接定位。
要注意的是,它依赖外部向量数据库
可以选择 Zilliz Cloud(有免费额度),也可以自己在本地部署 Milvus。
我自己的配置
目前我两个都装上了:
Context Mode 常驻后台,负责日常对话的上下文优化
Claude Context 在接手大项目时按需启用,专门解决代码全局检索问题
效率和流畅度的提升相当直观。
写在最后
AI 编程助手的竞争已经悄然转向
不再是“谁的底层模型更强”,而是“谁的工具链更完整、更顺手”。
Context Mode 和 Claude Context 只是这股趋势的一个开端。
接下来很可能还会有更多工具冒出来,一一攻克其他长期存在的痛点:
代码审查
测试生成
文档和代码的自动同步……
这才是 AI 编程真正走向成熟的模样:
生态的逐渐完善,就是下一阶段角力的关键所在。
项目地址:
Context Mode: https://github.com/mksglu/context-mode
Claude Context: https://github.com/zilliztech/claude-context