从入门到精通:LangChain框架全面解析与实战指南
在我们探讨AI项目的技术选型时,一个常见且关键的问题是:构建AI应用应该选择哪个框架? 讨论中频繁出现的名字包括Coze、Dify、FastGPT、n8n,以及LangChain。
对于那些偏好深度控制和“亲手编写代码”的开发者而言,拖拽式的低代码平台往往并非首选。在众多选项中,LangChain通常被认为是技术层面更优的选择。
LangChain与LangGraph作为当前主流的AI Agent开发框架,为开发者提供了一套从基础组件封装到复杂流程编排的完整工具链。随着LangChain 1.x与LangGraph 1.x版本的日趋成熟,整个技术栈的生态分工与工程化实践路径也变得更加清晰。本文将深入剖析这两个框架的核心概念、演进历史、核心功能及其实际应用场景。
LangChain的发展历程
LangChain由Harrison Chase于2022年10月创立,最初定位为一个专注于“使用大语言模型构建应用程序”的开源框架。彼时,ChatGPT刚刚掀起全球的AI热潮,开发者们急需一种能够快速连接LLM与外部数据源、工具及API的解决方案。
一、抢占先机
LangChain的诞生恰逢其时。它本质上是对一系列LLM应用最佳实践的抽象与封装,提供了几个关键的抽象层:
- Models(模型):对各种大语言模型进行统一封装,提供标准化的推理与对话接口,构成系统的基础能力层。
- Chains(链):将多个独立组件串联起来,形成可执行的工作流。
- Tools(工具):为LLM提供调用外部能力(如API、数据库)的接口。
- Agents(代理):实现让模型自主决策、调用工具的执行机制。
- Memory(记忆):负责管理对话历史与中间状态,使模型在多轮交互中保持上下文连贯性。
该框架极大地简化了LLM应用的开发流程,使开发者能够快速搭建问答系统、文本摘要工具和对话机器人等。在早期阶段,许多高级功能并不突出,可以简单地将LangChain理解为实现RAG(检索增强生成)的便捷工具。
然而,LangChain的早期架构采用了**单体式(Monolithic)**设计,所有组件紧密耦合。这种设计虽然便于快速集成,但也带来了扩展性方面的挑战。因此,许多团队在实际项目中更倾向于参考其设计思想,而非直接使用其全部代码。

二、快速迭代
如前所述,在ChatGPT早期,模型本身能力有限且算力成本高昂,因此在生产环境中直接使用LangChain的情况并不普遍。但从2023年开始,模型能力几乎每半年就有显著提升,LangChain也随之快速迭代,不断弥补自身的短板,例如:
- 模块化设计更加合理,各组件能够灵活组合。
- 支持了更多模型提供商(如OpenAI、Anthropic、Google等)。
- 生态系统日益丰富,社区贡献了大量第三方集成。
不过,这一时期的AI开源框架普遍面临一些共性问题:
- API变更频繁,破坏性更新较多。
- 代理(Agent)逻辑分散,难以维护复杂的业务流程。
- 状态管理能力相对薄弱。
- 对于需要长期记忆和状态持久化的应用支持不足(这不仅是框架问题,也与当时模型能力有限有关)。
值得一提的是,如今大热的智能体(Agent)概念在2023年仍处于萌芽阶段。当时,AgentExecutor是实现智能体的核心组件,它通过一个**硬编码的循环(Hardcoded Loop)**来执行ReAct逻辑。这种“黑盒”设计使得开发者很难定制复杂的执行流程,例如加入人机交互或错误重试机制。
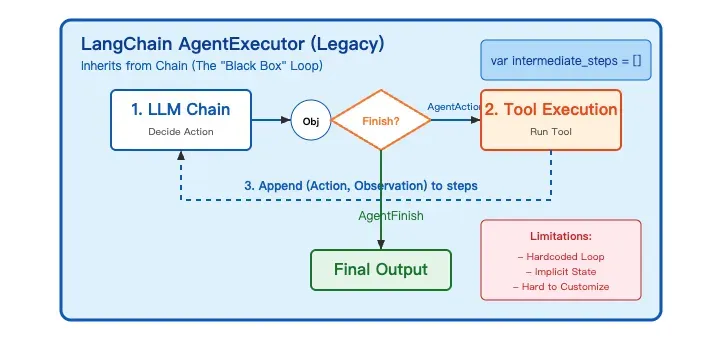
三、应对复杂需求:LangGraph登场
随着模型能力的持续增强,AI项目的复杂度也水涨船高。LangChain团队意识到,简单的链式结构已无法满足高级Agent开发的需求。
因此,LangGraph作为一个专门的编排框架应运而生。它的核心设计理念包括:
- 基于图结构:采用节点(Node)、边(Edge)、状态(State)三大核心抽象。
- 支持复杂流程:能够处理循环、条件分支和并行执行。
- 状态持久化:通过检查点(checkpoint)机制实现状态的保存与恢复。
- 人工介入:支持“人在回路”(Human-in-the-Loop)的交互模式。
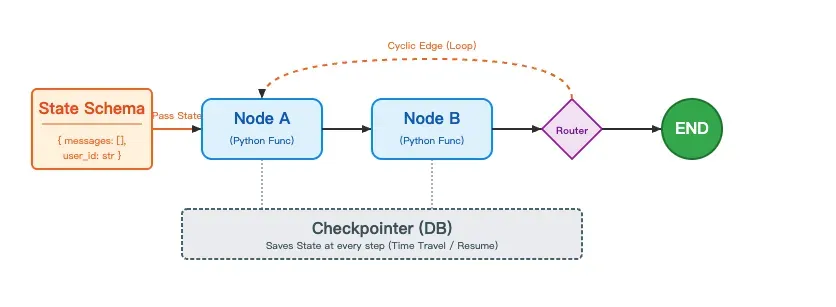
这依然是一个过渡阶段。直到2025年,模型能力真正达到了新的高度,LangChain 1.0 才正式发布。
1.0正式版发布
2025年10月,LangChain 1.0与LangGraph 1.0同步发布,这标志着这两个框架进入了首个稳定版本阶段。以“1.x”开头的版本号通常意味着更高的稳定性,开发者可以更放心地将其用于生产环境。
在后续发展中,版本稳定性将得到更多重视:与早期的快速迭代相比,1.x阶段更强调API的向后兼容性与平滑的迁移路径,从而降低维护成本。同时,LangChain与LangGraph的定位边界也更加清晰:
- LangChain:更偏向于应用层的组件与集成,强调易用性和快速拼装。
- LangGraph:更偏向于底层的流程编排与状态管理,强调可控性、可恢复性和可扩展性。
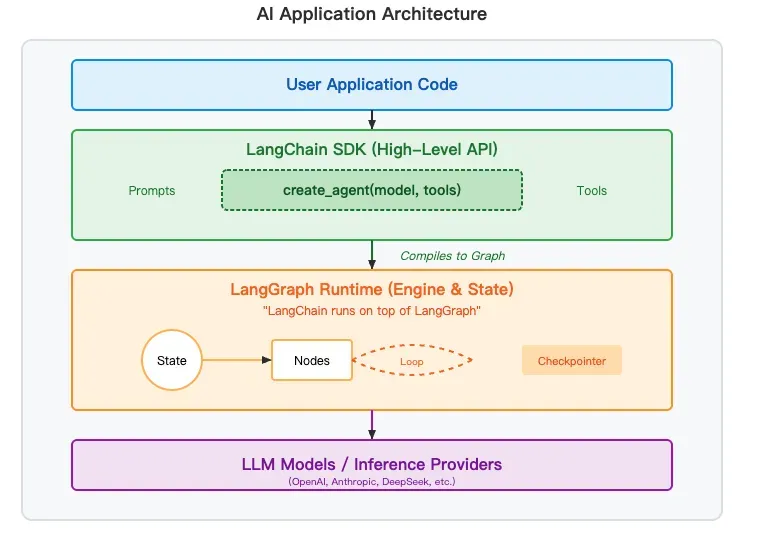
接下来,我们简要探讨一下1.0版本与旧版本的主要区别。
1.0 版本的重要特点
首先是整体架构上的重大变化。在1.x生态中,一个明显的趋势是:LangChain更聚焦于提供应用层的能力与集成,而LangGraph则更适合作为流程编排与状态管理的“底座”,被引入到复杂的Agent场景中。
在实际项目中,二者的组合方式会因具体版本、编程语言包和团队选型而有所不同,但整体方向是让流程控制变得更加显式、更易于维护。
这一架构转变使得LangChain从一个流程执行框架,演进为面向开发者的应用层SDK,带来了以下显著优势:
- 运行时能力下沉,职责边界更清晰。
- Agent执行模型得到统一,减少了隐式行为。
- 具备了更强的可扩展性与
可观测性。 - 为复杂Agent场景提供了工程级别的稳定性保障。
其次,在应用层的易用性上,LangChain 1.0展现了强大的应用性和生态整合能力:
- 提供了高级API抽象,例如
create_agent等便捷的Agent构建接口。 - 内置了丰富的可复用组件,包括:
- Agent构建工具
- 预构建的Chains(任务链)
- Retrievers(检索器)
- Tools / Tool Calling 抽象
- Middleware(中间件/回调)机制
在编排层,LangGraph作为面向系统的统一Agent运行与编排引擎,是LangChain 1.0的核心基础设施,扮演着“总控制器”的角色:
- 作为所有复杂Agent与Chain的统一运行时。
- 基于**状态图(State Graph)**的显式流程编排模型。
- 提供关键底层能力:
- 状态管理与持久化(Checkpointing)
- 流式响应(Streaming)
- 人工介入(Human-in-the-loop)
- 错误恢复、重试与流程回溯
最后,通过一张对比表格进行总结:
| 对比维度 | 旧版(0.x) | LangChain 1.0 |
|---|---|---|
| Agent 构建方式 | 构建入口与写法较为分散(不同版本/示例差异大) | 更倾向于提供统一的构建入口与模板化用法(如 create_agent) |
| API 稳定性 | 迭代速度快,升级成本不确定 | 更强调兼容性与明确的迁移路径,升级更可预期 |
| 与 LangGraph 的关系 | 可选:按需引入编排能力 | 更常见:复杂流程会配合图式编排与状态管理能力 |
| 中间件支持 | 多依赖回调或自定义封装 | 提供了更系统化的 Callbacks/Middleware 能力 |
| 结构化输出 | 更多依赖 OutputParser 组合实现 | 更强调结构化输出与工具调用的工程化用法(如 with_structured_output) |
| 包结构设计 | 功能分散、命名相对复杂 | 命名空间更为精简清晰 |
| 文档与学习成本 | 文档分散,上手成本较高 | 拥有全新的文档体系,示例与最佳实践更为完善 |
梳理完框架的历史演进与关键升级后,我们将回答开发者最关心的实际问题。
为什么选择LangChain?
许多程序员初次接触LangChain时都会产生疑问:我直接用Python调用OpenAI的API就能实现对话功能,为什么要引入LangChain这样一个看似复杂的框架呢?
通过场景对比可能是最好的解释方式,即明确什么场景适合手写代码,什么场景适合使用框架。
简而言之,当你只需要实现相对简单的功能时,例如调用大模型进行文本翻译,或构建一个基础的聊天机器人,直接编码是更好的选择,其优势明显:
- 完全自主可控:每一段代码的执行逻辑都清晰可见,没有额外的抽象层,整个过程透明直接。
- 环境轻量:无需引入庞大的第三方框架,依赖简单,更适合小型或一次性任务。
- 易于调试:可以直接查看和验证API返回的原始数据,问题定位直观高效。
然而,当项目变得复杂时,特别是对于自身架构能力不足的团队,直接编码的弊端也会显现:
- 重复开发工作多:当功能逐渐复杂(例如需要联网搜索、保存对话历史、处理多种文件格式),往往需要自行编写大量“粘合”代码,存在重复造轮子的情况。
- 维护成本较高:如果需要更换模型提供商,或应对模型API的升级变更,通常涉及较大范围的代码调整。
- 缺乏统一模式:在团队协作中,不同开发者对LLM的封装方式可能不一致,导致代码复用性和可维护性较差。
而使用LangChain框架,在AI项目复杂度提升后,上述问题几乎都可以得到规避。换句话说,这个框架能够有效提升一个技术基础薄弱团队的下限。例如,面对以下场景时,直接使用框架是明智之选:
- 构建基于检索增强生成(RAG)的复杂问答系统。
- 开发能够自主调用外部工具(如计算器、搜索引擎)的智能助手。
- 创建需要在多个大语言模型之间灵活切换和对比效果的应用。
使用框架的优势在于:
- 统一的模型接口:无论对接OpenAI、Anthropic还是Hugging Face等模型,LangChain都提供一致的调用方式,通常只需调整少量配置即可完成切换。
- 丰富的预制组件:内置了文档加载、文本分割、向量存储、对话记忆等常见模块,可直接组合使用,显著提升开发效率。
- 完善的工具集成:能够方便地接入搜索引擎、知识库以及各类业务API,快速扩展应用能力。
- 成熟的高阶模式支持:针对智能体(Agent)、复杂链式调用等高级场景,LangChain提供了清晰且可复用的实现模式,降低了自行设计流程的成本。
以下表格为技术选型提供参考:
| 维度 | 直接编写代码 | LangChain 1.x 框架 |
|---|---|---|
| 项目复杂度 | 简单:单轮对话、简单的文本处理 | 复杂:多轮对话、多步骤推理、RAG、Agent |
| 模型依赖 | 单一:只使用单一提供商/单一模型,无切换计划 | 多模型:需要支持多家提供商或多种本地模型后端 |
| 外部工具 | 无/少:不需要或仅需极少外部工具 | 多:需要频繁调用搜索、数据库、API等外部能力 |
| 开发阶段 | 原型验证:快速验证Prompt效果 | 生产级应用:需要可观测性、链路追踪、评估、持久化 |
| 团队协作 | 个人/小团队 | 中大型团队:需要统一的代码规范和抽象层 |
总结而言:如果只是想体验LLM,或实现极简功能,直接调用API是最高效的;如果要构建生产级的AI应用,特别是涉及RAG或Agent架构,LangChain能为你节省大量的工程化时间,让你更专注于业务逻辑而非基础设施。
接下来,我们将介绍LangChain的几个核心概念与能力。
一、create_agent
create_agent是LangChain 1.0中创建智能体的核心API,它统一了智能体的创建方式。
LLM Agent通过循环调用工具来实现目标,其运行会持续直到满足停止条件(例如模型输出最终结果或达到预设的迭代次数上限)。
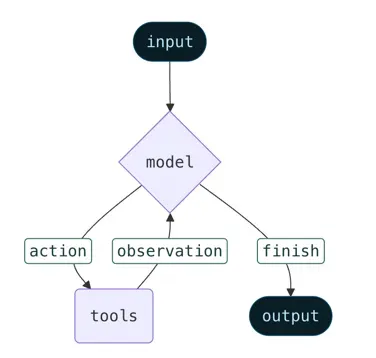
下面的代码展示了如何定义一个简单的工具函数,并将其绑定到Agent上进行调用(示例中使用DeepSeek模型):
import os
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
# 1. 定义工具
@tool
def get_weather(city: str) -> str:
"""获取指定城市的天气信息"""
return f"{city}今天天气晴朗,温度23°C"
# 2. 配置模型 (使用 DeepSeek)
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
temperature=0
)
# 3. 创建智能体
agent = create_agent(
model=llm,
tools=[get_weather],
system_prompt="你是一个专业的天气助手"
)
# 4. 执行查询
result = agent.invoke({
"messages": [{"role": "user", "content": "北京今天天气怎么样?"}]
})
# 输出结果
print(result["messages"][-1].content)
# 输出:北京今天天气晴朗,温度23°C
再分享一个真实业务场景:客户服务智能体。在此场景中,我们定义了两个工具:查询订单和处理退货。Agent会根据用户的自然语言指令,自动选择并调用合适的工具:
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_openai import ChatOpenAI
import os
@tool
def check_order_status(order_id: str) -> str:
"""查询订单状态"""
# 实际应用中这里会调用数据库或API
return f"订单{order_id}已发货,预计明天送达"
@tool
def process_return(order_id: str, reason: str) -> str:
"""处理退货申请"""
return f"订单{order_id}的退货申请已受理,原因是:{reason}"
# 配置 DeepSeek 模型
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
temperature=0
)
service_agent = create_agent(
model=llm,
tools=[check_order_status, process_return],
system_prompt="""你是一个专业的客户服务助手。
你可以帮助客户查询订单状态和处理退货申请。
始终保持礼貌和专业的态度。"""
)
# 客户咨询
response = service_agent.invoke({
"messages": [{
"role": "user",
"content": "我的订单ORD12345发了吗?"
}]
})
print(response["messages"][-1].content)
二、Callbacks 与 Middleware
在LangChain 1.0中,我们主要通过**Callbacks(回调)和Middleware(中间件)**来实现对Agent执行流程的控制与观测。
Callbacks侧重于在关键节点进行被动观测和执行简单的钩子逻辑,而Middleware则提供了更强大的生命周期管理和请求拦截能力。
Callbacks允许开发者在智能体执行的关键节点(如LLM调用开始、结束、工具调用时)插入自定义逻辑,用于记录日志、监控性能或修改行为。
自定义 LoggingHandler 示例
以下示例展示了如何实现一个简单的日志回调,并将其注入到使用DeepSeek模型的LLM中:
from typing import Dict, Any, List
import os
from langchain_core.callbacks import BaseCallbackHandler
from langchain_core.outputs import LLMResult
from langchain_openai import ChatOpenAI
class LoggingHandler(BaseCallbackHandler):
"""
一个简单的中间件/回调,用于记录 LLM 的交互过程
"""
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
"""LLM 开始处理请求时的回调"""
print("\n[Middleware] LLM 开始处理请求...")
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""LLM 处理完成时的回调"""
print(f"\n[Middleware] LLM 处理完成。消耗 Token: {response.llm_output.get('token_usage', 'N/A')}")
# 使用 Callbacks 配置 DeepSeek
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
callbacks=[LoggingHandler()] # 注入中间件
)
# 当 Agent 使用这个 LLM 时,所有操作都会被 LoggingHandler 捕获
Middleware提供了更强大的生命周期钩子,允许我们在模型调用前后、工具执行前后进行深度干预。
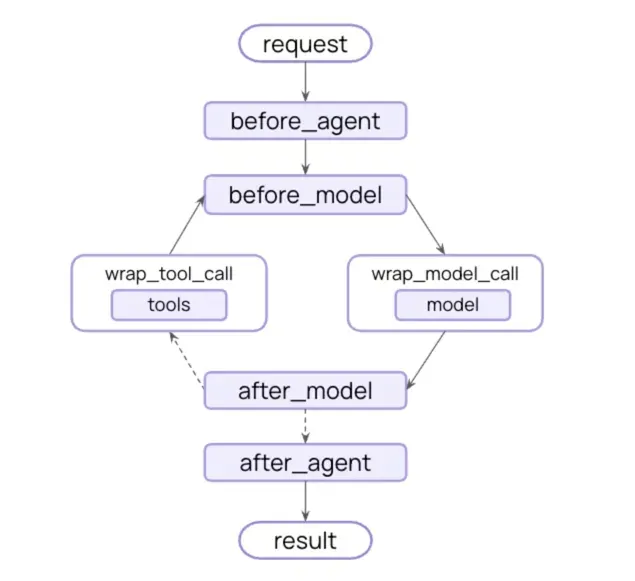
中间件生命周期钩子
| 钩子函数 | 触发时机 | 典型场景 |
|---|---|---|
before_agent |
调用代理之前 | 加载用户历史记录、验证输入参数 |
before_model |
每次模型调用前 | 动态修改提示词、精简对话历史 |
wrap_model_call |
围绕模型调用 | 记录日志、修改请求/响应、实现缓存 |
wrap_tool_call |
围绕工具调用 | 权限检查、参数验证、结果缓存 |
after_model |
模型返回响应后 | 内容安全检查、敏感信息过滤 |
after_agent |
代理完成运行后 | 保存对话历史、记录使用统计 |
1. PIIMiddleware:敏感信息保护
PII(个人身份信息)中间件可以在数据发送给大模型之前,自动识别并处理敏感信息。以下配置展示了如何自动屏蔽邮箱地址,并完全阻断包含手机号的请求:
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
agent = create_agent(
model="gpt-4o-mini",
tools=[email_tool],
middleware=[
# 自动屏蔽邮箱地址
PIIMiddleware("email", strategy="redact", apply_to_input=True),
# 完全阻止电话号码传递
PIIMiddleware(
"phone_number",
detector=r"(?:\+?\d{1,3}[\s.-]?)?\(?\d{2,4}\)?[\s.-]?\d{3,4}[\s.-]?\d{4}",
strategy="block"
),
# 屏蔽身份证号
PIIMiddleware(
"id_card",
detector=r"\d{17}[\dXx]",
strategy="redact"
)
]
)
# 即使用户输入包含敏感信息,也会被自动处理
result = agent.invoke({
"messages": [{"role": "user", "content": "我的邮箱是test@example.com,电话13812345678"}]
})
# 实际传递给模型的内容:我的邮箱是***,电话***
2. SummarizationMiddleware:对话历史管理
当对话轮数过多导致上下文超出模型限制时,摘要中间件会自动压缩历史记录。以下代码设置了3000 token的阈值,一旦超过该值就会触发自动摘要:
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="gpt-4o-mini",
tools=[search_tool],
middleware=[
SummarizationMiddleware(
model="gpt-4o-mini",
max_tokens_before_summary=3000, # 超过3000 tokens自动摘要
summary_prompt="将以下对话内容摘要为关键要点" # 自定义摘要提示词
)
]
)
# 长对话自动管理
for i in range(20):
result = agent.invoke({
"messages": [{"role": "user", "content": f"问题{i+1}"}]
})
# 当对话历史过长时,会自动进行摘要压缩
3. HumanInTheLoopMiddleware:人工审批机制
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.types import Command
agent = create_agent(
model="gpt-4o",
tools=[delete_file, send_email, transfer_money],
checkpointer=InMemorySaver(), # 需要记忆管理支持
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"delete_file": {
"allowed_decisions": ["approve", "edit", "reject"],
"require_reason": True # 拒绝时必须提供原因
},
"send_email": {
"allowed_decisions": ["approve", "reject"]
},
"transfer_money": {
"allowed_decisions": ["approve", "reject"],
"require_reason": True
}
}
)
]
)
config = {"configurable": {"thread_id": "session_1"}}
result = agent.invoke(
{"messages": [{"role": "user", "content": "删除重要文件.doc"}]},
config
)
if "__interrupt__" in result:
# 程序暂停,等待人工决策
decision = input("批准删除文件?(approve/reject): ")
if decision == "approve":
# 继续执行
result = agent.invoke(
Command(resume={"decisions": [{"type": "approve"}]}),
config
)
else:
# 拒绝执行
result = agent.invoke(
Command(resume={
"decisions": [{
"type": "reject",
"message": "用户取消操作"
}]
}),
config
)
最后,展示一个自定义中间件的案例:基于用户级别的动态路由
我们通过自定义中间件获取用户上下文(如会员等级),并据此动态调整使用的模型版本。以下实现展示了如何拦截请求并修改模型参数,从而为高级用户提供更强大的模型:
from dataclasses import dataclass
from typing import Callable
from langchain.chat_models import init_chat_model
from langchain.agents.middleware import AgentMiddleware
from langchain.agents.middleware.types import ModelRequest, ModelResponse
@dataclass
class Context:
user_id: str
user_tier: str = "free" # free, pro, enterprise
request_count: int = 0
class TierBasedRoutingMiddleware(AgentMiddleware):
"""根据用户等级路由到不同的模型"""
def __init__(self):
super().__init__()
# 定义不同等级使用的模型
self.tier_models = {
"free": "gpt-4o-mini",
"pro": "gpt-4o",
"enterprise": "gpt-4o-turbo"
}
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
# 获取用户等级
user_tier = request.runtime.context.user_tier
# 动态选择模型
model_name = self.tier_models.get(user_tier, "gpt-4o-mini")
request.model = init_chat_model(model=model_name)
# 记录请求次数
request.runtime.context.request_count += 1
print(f"[中间件] 用户等级: {user_tier}, 使用模型: {model_name}")
return handler(request)
# 应用中间件
agent = create_agent(
model="gpt-4o-mini", # 默认模型,会被中间件覆盖
tools=[search_tool],
middleware=[TierBasedRoutingMiddleware()],
context_schema=Context
)
# 不同用户使用不同模型
result_free = agent.invoke(
{"messages": [{"role": "user", "content": "搜索新闻"}]},
context=Context(user_id="user_001", user_tier="free")
)
result_enterprise = agent.invoke(
{"messages": [{"role": "user", "content": "搜索新闻"}]},
context=Context(user_id="user_002", user_tier="enterprise")
)
三、让AI返回规范数据
在实际应用中,我们通常需要AI返回特定格式的数据(如JSON对象),而不是一段自然语言文本,例如:
- 电商价格比较:返回结构化的价格、参数列表。
- 信息提取:从文档中提取指定字段并返回JSON。
- API调用:需要严格按照预设的参数格式传递数据。
LangChain提供了三种主要策略来获取结构化输出,以适应不同模型能力和应用场景的需求。
1. AutoStrategy(推荐):自动选择最佳策略
自动策略是获取结构化数据的最简便方式。开发者只需定义一个Pydantic模型,LangChain会自动处理底层的Prompt工程和解析逻辑,无需关心实现细节:
from langchain.agents import create_agent
from langchain.agents.structured_output import AutoStrategy
from pydantic import BaseModel
class ProductComparison(BaseModel):
"""产品比较结果"""
product_name: str
price: float
rating: float
pros: list[str]
cons: list[str]
verdict: str # 购买建议
agent = create_agent(
model="gpt-4o",
tools=[web_search],
response_format=AutoStrategy(ProductComparison),
system_prompt="你是一个产品比较专家"
)
result = agent.invoke({
"messages": [{
"role": "user",
"content": "比较iPhone 15和Samsung S24的优缺点"
}]
})
# 直接获得结构化对象
comparison: ProductComparison = result["structured_response"]
print(f"产品: {comparison.product_name}")
print(f"价格: ${comparison.price}")
print(f"评分: {comparison.rating}/5")
print(f"优点: {', '.join(comparison.pros)}")
print(f"缺点: {', '.join(comparison.cons)}")
print(f"建议: {comparison.verdict}")
2. ToolStrategy:利用工具调用能力
工具策略通过模拟工具调用的方式来获取结构化输出,适用于支持Function Calling的模型。它利用了模型对工具参数格式的严格遵循能力:
from langchain.agents.structured_output import ToolStrategy
class WeatherForecast(BaseModel):
city: str
temperature: int
condition: str # sunny, cloudy, rainy
humidity: int
wind_speed: int
agent = create_agent(
model="gpt-4o-mini",
tools=[get_weather_data],
response_format=ToolStrategy(WeatherForecast)
)
# 适用于任何支持工具调用的模型
# 但依赖模型自身的推理能力
3. ProviderStrategy:使用提供商原生功能
对于OpenAI等提供商原生支持的结构化输出API(如JSON mode),可以直接使用ProviderStrategy进行调用。这种方式通常比通过Prompt工程实现更加稳定可靠:
from langchain.agents.structured_output import ProviderStrategy
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
agent = create_agent(
model=model,
tools=[],
response_format=ProviderStrategy(WeatherForecast)
)
# 直接使用OpenAI的结构化输出API
# 更稳定可靠,但仅限于支持的提供商
四、记忆管理
若要自行实现AI的多轮对话记忆功能,对系统架构的复杂度要求很高。而LangChain 1.0通过几个核心概念,为大多数团队兜底,降低了实现门槛:
- 短期记忆(对话历史):
- 使用
InMemorySaver存储在内存中。 - 适合单次会话。
- 程序重启后数据会丢失。
- 使用
- 长期记忆(跨会话):
- 使用数据库进行持久化(如PostgreSQL、Redis等)。
- 可以跨多次会话保持记忆。
- 需要额外的存储后端支持。
使用InMemorySaver可以实现短期记忆。通过thread_id来区分不同的对话会话:
import os
from langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaver
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com",
temperature=0
)
# 创建带记忆的智能体
agent = create_agent(
model=llm,
tools=[],
checkpointer=InMemorySaver() # 启用内存检查点
)
# 使用thread_id区分不同会话
config = {"configurable": {"thread_id": "user_session_123"}}
# 第一轮对话
agent.invoke(
{"messages": [{"role": "user", "content": "我叫张三,今年25岁"}]},
config
)
# 第二轮对话(智能体记得之前的信息)
result = agent.invoke(
{"messages": [{"role": "user", "content": "我今年多大?"}]},
config
)
print(result["messages"][-1].content)
# 输出:你今年25岁
对于生产环境,我们需要将状态持久化到数据库。以下示例展示了如何使用PostgreSQL保存对话状态,即使程序重启,用户也能无缝接续之前的对话:
from langgraph.checkpoint.postgres import PostgresSaver
# 配置PostgreSQL检查点
checkpointer = PostgresSaver.from_conn_string(
"postgresql://user:password@localhost:5432/langchain"
)
agent = create_agent(
model="gpt-4o-mini",
tools=[search_tool],
checkpointer=checkpointer
)
# 即使程序重启,对话历史仍然保留
config = {"configurable": {"thread_id": "user_persistent_001"}}
# 第一次运行(程序A)
result1 = agent.invoke(
{"messages": [{"role": "user", "content": "我喜欢编程"}]},
config
)
# 第二次运行(程序B,重启后)
result2 = agent.invoke(
{"messages": [{"role": "user", "content": "我有什么爱好?"}]},
config
)
# 输出:你之前提到喜欢编程
五、LangGraph
LangGraph是一个低级别的编排框架,专门用于构建、管理和部署长期运行、有状态的Agent。与LangChain提供的高级抽象不同,LangGraph更关注底层的编排能力:
- 持久化执行(Durable execution):Agent可以在执行失败后恢复,能够长时间运行,并从停止的地方继续。
- 人工干预(Human-in-the-loop):可以在执行流程的任何节点暂停,以检查和修改Agent状态。
- 全面的记忆(Comprehensive memory):结合短期工作记忆与长期跨会话记忆。
- 通过LangSmith进行调试:可视化执行路径,捕获状态转换过程。
- 生产就绪的部署:为有状态、长期运行的工作流设计的可扩展基础设施。
在深入代码之前,需要理解LangGraph的五个核心支柱:
- 状态(State):在所有节点之间共享的内存。
- 节点(Nodes):执行单元(Python函数),接收状态并返回状态更新。
- 边(Edges):控制流,决定下一步执行哪个节点。
- 图(Graph):编排器,将节点和边组合成可运行的工作流。
- 检查点(Checkpointer):持久化层,保存和管理执行历史。
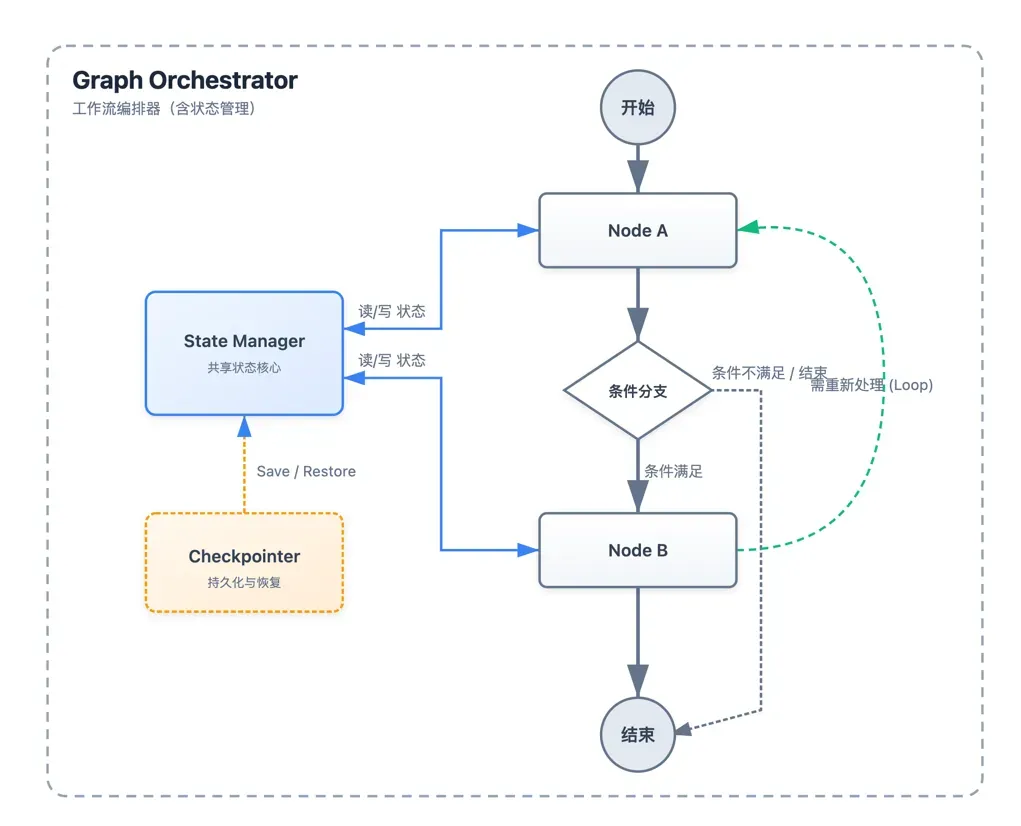
状态
状态是图的共享内存。
- 它保存了Agent运行过程中的所有数据(如消息历史、提取的变量、中间结果)。
- 状态在节点之间传递。每个节点接收当前状态,并返回状态的更新。
- Schema定义:通常使用
TypedDict或Pydantic模型来定义状态的结构。 - 更新机制:节点返回的字典会与现有状态合并(默认行为),或者可以定义自定义的reducer函数(例如,追加到消息列表而不是覆盖它)。
from typing import Annotated, TypedDict
from langgraph.graph.message import add_messages
class AgentState(TypedDict):
"""智能体状态定义"""
# 消息历史(使用add_messages自动追加而不是覆盖)
messages: Annotated[list, add_messages]
# 自定义字段
user_input: str
search_results: list[dict]
analysis_result: str
current_step: str # 追踪当前执行步骤
深入理解Annotated与add_messages:
在上面的代码中,messages: Annotated[list, add_messages]是一个非常关键的设计。
- 默认情况下,LangGraph的状态更新是覆盖式的。如果节点返回
{"a": 1},它会覆盖掉状态中原有的a。 - 对于消息列表,我们需要的是追加而非覆盖。
Annotated配合add_messages告诉LangGraph:“当有新消息需要更新到这个字段时,请调用add_messages函数将其追加到现有列表中,而不是替换它。”
节点
节点是图的执行单元。
- 本质上,节点就是一个Python函数。
- 输入:接收当前状态(State)。
- 输出:返回一个字典(包含要更新的状态键值对)。
- 节点负责具体的业务逻辑,如调用LLM、查询数据库、执行代码等。
- 特殊节点:
START(图的入口)和END(图的出口)。
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
def search_node(state: AgentState, config):
"""搜索节点:执行网络搜索"""
query = state["user_input"]
# 调用搜索工具
results = search_web(query)
print(f"[搜索节点] 找到 {len(results)} 条结果")
return {
"search_results": results,
"current_step": "search_completed"
}
def analysis_node(state: AgentState, config):
"""分析节点:分析搜索结果"""
results = state["search_results"]
# 构造分析提示词
prompt = f"分析以下搜索结果:\n{results}"
# 调用LLM分析
response = llm.invoke([
{"role": "system", "content": "你是一个信息分析专家"},
{"role": "user", "content": prompt}
])
print(f"[分析节点] 分析完成")
return {
"analysis_result": response.content,
"current_step": "analysis_completed"
}
def report_node(state: AgentState, config):
"""报告节点:生成最终报告"""
analysis = state["analysis_result"]
report = f"""
分析报告
=========
{analysis}
"""
print(f"[报告节点] 报告生成完毕")
return {
"messages": [{"role": "assistant", "content": report}],
"current_step": "report_generated"
}
边
边定义了控制流,即“下一步去哪里”:
- 普通边(Normal Edge):
START -> Node A -> Node B。这种边是确定的,A执行完总是去B。 - 条件边(Conditional Edge):根据当前状态或函数输出来动态决定下一个节点。例如,如果LLM决定调用工具,则跳转到
ToolNode,否则跳转到END。 - 在LangGraph新版中,推荐在节点函数内部通过返回
Command(goto="next_node")来直接控制流向,这比外部定义的条件边更直观。
from langgraph.graph import StateGraph, END
def should_search(state: AgentState) -> str:
"""条件边:决定是否需要搜索"""
user_input = state["user_input"]
# 如果用户问的是事实性问题,需要搜索
question_words = ["什么", "哪里", "谁", "何时", "如何"]
if any(word in user_input for word in question_words):
return "search"
# 否则直接分析
return "analyze"
def has_results(state: AgentState) -> str:
"""条件边:检查搜索是否有结果"""
if len(state["search_results"]) > 0:
return "analyze"
else:
return "no_results"
图
图是工作流的编排器。
- 它定义了应用程序的结构和执行逻辑。
StateGraph是最常用的类,它利用定义好的State Schema来管理数据流转。- 编译后的图(
CompiledGraph)是一个可运行的对象(Runnable),支持invoke、stream、batch等标准LangChain方法。
from langgraph.graph import StateGraph, END
# 创建状态图
builder = StateGraph(AgentState)
# 添加节点
builder.add_node("search", search_node)
builder.add_node("analyze", analysis_node)
builder.add_node("report", report_node)
builder.add_node("no_results", lambda state: {
"messages": [{"role": "assistant", "content": "未找到相关信息"}]
})
# 设置入口点
builder.set_entry_point("search")
# 添加边
# 从search节点出发,根据是否有结果决定下一步
builder.add_conditional_edges(
"search",
has_results,
{
"analyze": "analyze",
"no_results": "no_results"
}
)
# analyze完成后总是到report
builder.add_edge("analyze", "report")
# report和no_results都结束
builder.add_edge("report", END)
builder.add_edge("no_results", END)
# 编译图
graph = builder.compile()
# 执行
result = graph.invoke({
"user_input": "什么是LangChain?",
"messages": [],
"search_results": [],
"analysis_result": "",
"current_step": ""
})
print(result["messages"][-1]["content"])
检查点
检查点机制是LangGraph的核心特性之一,它赋予了Agent记忆和持久化能力。
- 自动保存:它会在图执行的每个步骤(Super-step)后自动保存图的状态快照。
- 线程(Thread):通过
thread_id来隔离不同的对话或执行流。 - 多级隔离:除了
thread_id,Checkpointer还支持更细粒度的隔离(如用户级别)。在配置configurable时,可以传递自定义的键值对(例如user_id),Checkpointer能够利用这些信息来管理和检索状态,从而实现多用户、多会话的状态管理。 - 能力解锁:
- 记忆(Memory):允许Agent跨多轮交互记住上下文。
- 人工干预(Human-in-the-loop):允许在特定节点暂停,等待人工批准或修改状态后再继续。
- 时间旅行(Time Travel):允许查看历史执行步骤,甚至回滚到之前的某个状态,修改数据后重新执行(Fork)。
- 故障恢复:如果任务中断,可以从上次保存的状态恢复执行。
六、高级特性
复杂条件分支
通过编写路由函数,我们可以实现复杂的业务逻辑分流。例如,根据用户问题的关键词将请求分发给不同的处理节点(如客服、技术支持、销售):
from typing import Literal
def route_question(state: AgentState) -> Literal["web_search", "database", "direct_answer"]:
"""根据问题类型路由到不同节点"""
question = state["user_input"].lower()
# 技术问题 -> 网络搜索
if any(word in question for word in ["如何", "怎么", "教程", "技术"]):
return "web_search"
# 数据查询问题 -> 数据库
if any(word in question for word in ["查询", "数据", "记录", "统计"]):
return "database"
# 简单问题 -> 直接回答
return "direct_answer"
builder.add_conditional_edges(
"router",
route_question,
{
"web_search": "web_search_node",
"database": "database_query_node",
"direct_answer": "direct_answer_node"
}
)
循环执行
LangGraph原生支持循环逻辑,非常适合需要反复优化或重试的场景。以下代码展示了一个最大迭代次数为10的循环流程,防止死循环:
class IterationState(TypedDict):
messages: Annotated[list, add_messages]
iteration: int
max_iterations: int
result: str
converged: bool
def process_step(state: IterationState):
"""处理步骤"""
iteration = state["iteration"]
print(f"[迭代] 第 {iteration} 次处理")
# 模拟处理逻辑
result = f"处理结果 {iteration}"
# 检查是否收敛(假设5次后收敛)
converged = iteration >= 5
return {
"result": result,
"converged": converged,
"iteration": iteration + 1
}
def should_continue(state: IterationState) -> Literal["continue", "end"]:
"""决定是否继续迭代"""
if state["converged"]:
return "end"
if state["iteration"] >= state["max_iterations"]:
return "end"
return "continue"
builder = StateGraph(IterationState)
builder.add_node("process", process_step)
builder.set_entry_point("process")
# 添加循环边
builder.add_conditional_edges(
"process",
should_continue,
{
"continue": "process", # 循环回process节点
"end": END
}
)
graph = builder.compile()
# 执行(会循环5次)
result = graph.invoke({
"messages": [],
"iteration": 1,
"max_iterations": 10,
"result": "",
"converged": False
})
持久化与检查点
SQLite是轻量级的持久化方案,适合本地开发和测试。无需额外部署数据库,只需一行代码即可启用状态保存功能:
from langgraph.checkpoint.sqlite import SqliteSaver
# 创建SQLite检查点
checkpointer = SqliteSaver.from_conn_string("agent_state.db")
builder = StateGraph(AgentState)
# ... 添加节点和边 ...
graph = builder.compile(
checkpointer=checkpointer # 启用检查点
)
# 使用thread_id追踪会话
config = {"configurable": {"thread_id": "user_session_001"}}
# 第一次执行
result1 = graph.invoke({"user_input": "搜索AI新闻"}, config)
# 第二次执行(从上次停止的地方继续)
result2 = graph.invoke({"user_input": "继续搜索"}, config)
在生产环境中,推荐使用PostgreSQL等成熟数据库。需要先建立数据库连接,再将其传递给图的编译方法,以确保高可用和数据安全:
from langgraph.checkpoint.postgres import PostgresSaver
import psycopg
# 配置PostgreSQL连接
connection = psycopg.connect(
host="localhost",
port=5432,
database="langchain",
user="postgres",
password="password"
)
# 创建检查点
checkpointer = PostgresSaver(connection)
# 初始化表(首次运行)
checkpointer.setup()
graph = builder.compile(checkpointer=checkpointer)
LangGraph的一大特色是“时间旅行”。我们可以查看历史状态,甚至回滚到之前的某个步骤重新执行,这对于调试和人工纠错非常有用:
# 获取会话的所有历史状态
history = graph.get_state_history(config)
# 查看历史
for state in history:
print(f"步骤: {state.step}, 时间: {state.timestamp}")
# 回溯到特定状态
past_state = history[5] # 回到第5步
restored_result = graph.invoke(None, config)
# 从某个历史状态重新执行
graph.update_state(config, past_state.values)
new_result = graph.invoke({"user_input": "新指令"}, config)
人工介入
在执行过程中暂停并等待人工反馈是Agent的常见需求。以下代码展示了如何在human_review节点暂停,并在收到人工指令后恢复执行:
from langgraph.types import interrupt, Command
def human_review_node(state: AgentState):
"""需要人工审核的节点"""
analysis = state["analysis_result"]
# 暂停执行,等待人工输入
feedback = interrupt({
"type": "human_review",
"content": analysis,
"question": "请审核以上分析结果"
})
# 处理人工反馈
if feedback["approved"]:
return {"messages": [{"role": "assistant", "content": analysis}]}
else:
# 根据反馈修改
revised = revise_analysis(analysis, feedback["comments"])
return {"messages": [{"role": "assistant", "content": revised}]}
builder.add_node("human_review", human_review_node)
执行流程:
# 第一次执行,会在human_review节点暂停
result = graph.invoke({"user_input": "分析市场趋势"}, config)
if "__interrupt__" in result:
# 获取需要审核的内容
review_data = result["__interrupt__"]
print("需要审核的内容:")
print(review_data["content"])
# 人工决策
approved = input("是否批准?(y/n): ") == "y"
comments = "" if approved else input("请提供修改意见: ")
# 继续执行
result = graph.invoke(
Command(resume={
"approved": approved,
"comments": comments
}),
config
)
多Agent协同
多Agent系统通常包含多个专门的角色。我们需要定义一个包含current_agent字段的共享状态,并编写路由逻辑在不同Agent之间流转:
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, START, END
from langgraph.graph import add_messages, StateGraph
class MultiAgentState(TypedDict):
messages: Annotated[list, add_messages]
current_agent: str
research_data: dict
code: str
test_results: str
def researcher_agent(state: MultiAgentState):
"""研究Agent:负责收集信息"""
print("[研究Agent] 开始研究...")
research_data = {
"topic": state["messages"][-1].content,
"sources": ["source1", "source2", "source3"],
"summary": "研究摘要..."
}
return {
"research_data": research_data,
"current_agent": "researcher"
}
def coder_agent(state: MultiAgentState):
"""编程Agent:负责编写代码"""
print("[编程Agent] 开始编码...")
research = state["research_data"]
code = f"# 基于 {research['topic']} 生成的代码\nprint('Hello World')"
return {
"code": code,
"current_agent": "coder"
}
def tester_agent(state: MultiAgentState):
"""测试Agent:负责测试代码"""
print("[测试Agent] 开始测试...")
code = state["code"]
test_results = "测试通过!所有测试用例均通过。"
return {
"test_results": test_results,
"current_agent": "tester"
}
def route_to_next_agent(state: MultiAgentState) -> str:
"""路由到下一个Agent"""
current = state["current_agent"]
if current == "researcher":
return "coder"
elif current == "coder":
return "tester"
else:
return "end"
builder = StateGraph(MultiAgentState)
builder.add_node("researcher", researcher_agent)
builder.add_node("coder", coder_agent)
builder.add_node("tester", tester_agent)
builder.set_entry_point("researcher")
# 添加路由边
builder.add_conditional_edges(
"researcher",
route_to_next_agent,
{"coder": "coder"}
)
builder.add_conditional_edges(
"coder",
route_to_next_agent,
{"tester": "tester"}
)
builder.add_conditional_edges(
"tester",
route_to_next_agent,
{"end": END}
)
graph = builder.compile()
# 执行多Agent协同
result = graph.invoke({
"messages": [{"role": "user", "content": "开发一个待办事项应用"}],
"current_agent": "researcher",
"research_data": {},
"code": "",
"test_results": ""
})
print("\n最终结果:")
print(f"研究数据: {result['research_data']}")
print(f"代码: {result['code']}")
print(f"测试结果: {result['test_results']}")
子图
随着Agent系统变得庞大,单张图会变得难以维护。LangGraph允许我们将一个编译好的图(CompiledGraph)直接作为另一个图的节点使用。这使得我们可以像搭积木一样构建复杂系统。
# 定义子图
sub_builder = StateGraph(SubState)
# ... 构建子图 ...
sub_graph = sub_builder.compile()
# 在父图中使用子图
parent_builder = StateGraph(ParentState)
parent_builder.add_node("sub_task", sub_graph) # 直接作为节点
结语
本文对LangChain与LangGraph框架进行了系统的介绍,涵盖了其发展历程、核心概念、关键功能以及高级应用场景。从简单的Agent创建到复杂的多Agent图编排,这两个框架为构建生产级的AI应用提供了坚实的工程基础。理解并掌握它们,将帮助开发者在AI浪潮中更高效地实现创意,构建稳定、可扩展的智能系统。