AI Agent 时代的工程范式革命:解读 Harness Engineering 的马、马具与骑手
2026 年 2 月,“Harness Engineering”这个术语突然在 AI 工程圈内引爆了话题。Mitchell Hashimoto 在个人博客里率先提出这一概念,紧接着 OpenAI 发布了涵盖百万行代码的实验报告,Martin Fowler 也紧随其后撰写了深度分析文章——仅仅几周时间,这一概念便成为讨论 AI Agent 开发时无法绕开的焦点。
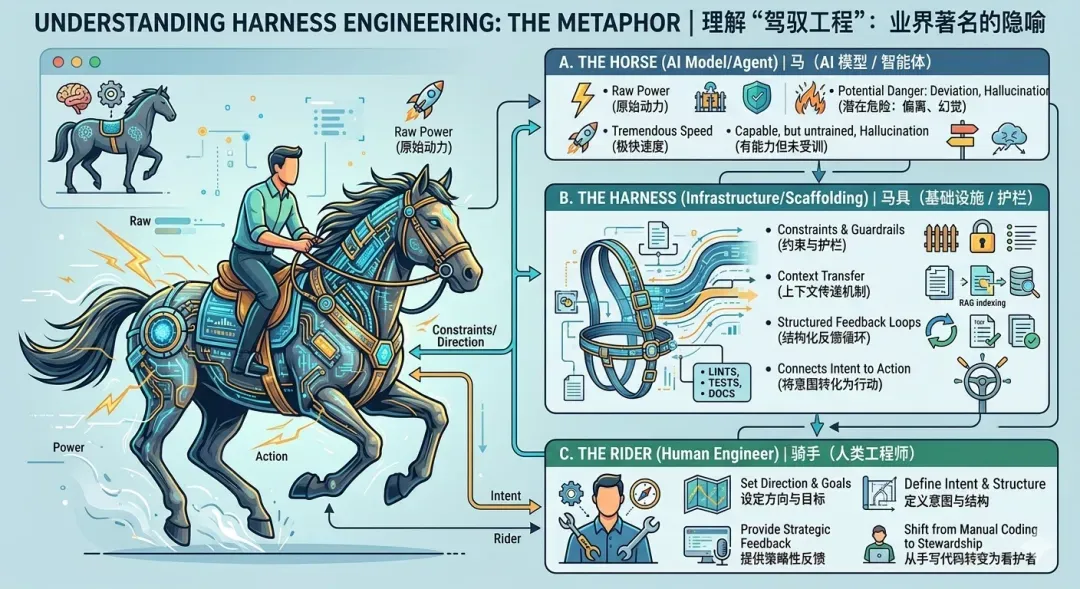
一、核心隐喻:驾驭野马——马、马具与骑手
要理解什么是 Harness Engineering,目前业界最广为流传的隐喻是:
- 马(The Horse - AI 模型):当下的 AI 模型(如 OpenAI Codex 等)犹如一匹力大无穷、疾驰如风的骏马。它的能力让人惊叹,但若不加引导,它常常彷徨不知方向,甚至横冲直撞(即产生幻觉、偏离架构规范)。
- 马具/缰绳(The Harness - 基础设施):涵盖约束规则、护栏机制、上下文传递路径以及反馈循环。它们将 AI 模型的原始“智力”塑造为能够达成特定业务目标的系统。
- 骑手(The Rider - 人类工程师):工程师不再需要“亲自奔跑”(手写底层代码),而是紧握缰绳,指明方向,注入意图并提供结构化反馈。
二、为何 Harness Engineering 不可或缺?
在过去两年中,行业共同发现了一个痛点:对 AI Agent 而言,“再努力一点(Try harder)”这条路根本走不通。 当 Agent 在庞大的代码库里迷失、陷入死循环、或者编写出违背公司架构规范的设计时,仅仅依靠调整 Prompt(提示词工程)来挽救局面极其脆弱。
Harness Engineering 应运而生,正是为了突破 AI 自主性的瓶颈。它的核心思想是:每当 AI 犯错,不要耗费精力去调整玄学般的提示词,而是改进 Harness 系统(例如添加一项 Linter 或测试拦截器),让它在机制层面再也不可能犯同样的错误。
模型能力并非瓶颈所在
这一论断已经得到了量化实验的支撑:
Can.ac 实验:仅仅改变 Harness 的工具格式(编辑接口),就在 16 个模型上显著提高了编码基准分数。效果最引人注目的是 Grok Code Fast 1,其成绩从 6.7% 飙升至 68.3%——完全没有任何模型权重的改动。
LangChain 实验:仅通过 Harness 的优化,在 Terminal Bench 2.0 上的排名从第 30 名跃升至第 5 名,同一模型的基础得分提升了 13.7 分。
这些结果揭示了一个道理:在选择模型之前先认真检视 Harness 设计,能获得更高的投资回报率。
OpenAI 团队的话一针见血:真正拖后腿的不是 Agent 编写代码的能力,而是围绕它的结构、工具和反馈机制跟不上节奏。 五个独立的团队得出了同样的结论:基础设施才是瓶颈,而非智能水平。
AI Agent 的常见翻车姿势
Anthropic 在长时间运行 Agent 的实践中,总结了几个典型的失败模式:
失败模式 1:试图一步到位(One-shotting)。 Agent 总是想一次性完成所有事情,结果在实现进行到一半时上下文窗口就已耗尽。下一个会话启动时,面对的只有半成品、毫无文档的代码,只能花费大量时间猜测之前发生了什么,并试图恢复工作状态。
失败模式 2:过早宣布胜利。 当项目进入后期,部分功能已经完成后,Agent 会环顾四周,看到已有进展就直接宣称任务完成——哪怕还有大批功能尚未实现。
失败模式 3:过早标记功能完成。 在没有明确指示的情况下,Agent 写完代码就将任务标记为“完成”,却没有进行端到端测试。单元测试通过或者 curl 命令返回成功,并不代表功能真的可用。
失败模式 4:环境启动困难。 每当新会话启动时,Agent 需要耗费大量 token 去弄明白如何运行应用、如何启动开发服务器,而不是把时间投入到实际开发上。
上下文窗口的甜蜜区间与陷阱
Dex Horthy 分享过一个非常实用的经验观察:上下文塞得越满,大模型的输出质量就越差。 以 168K token 的上下文窗口为例,大约用到 40% 以后就开始走下坡路:
聪明区(前约 40%):聚焦、准确的推理。Agent 此时掌握的是精炼且相关的信息。
笨拙区(超过约 40%):幻觉、死循环、格式错误工具调用、低质量代码。更多 token 反而损害性能。
三、Harness Engineering 四大核心支柱
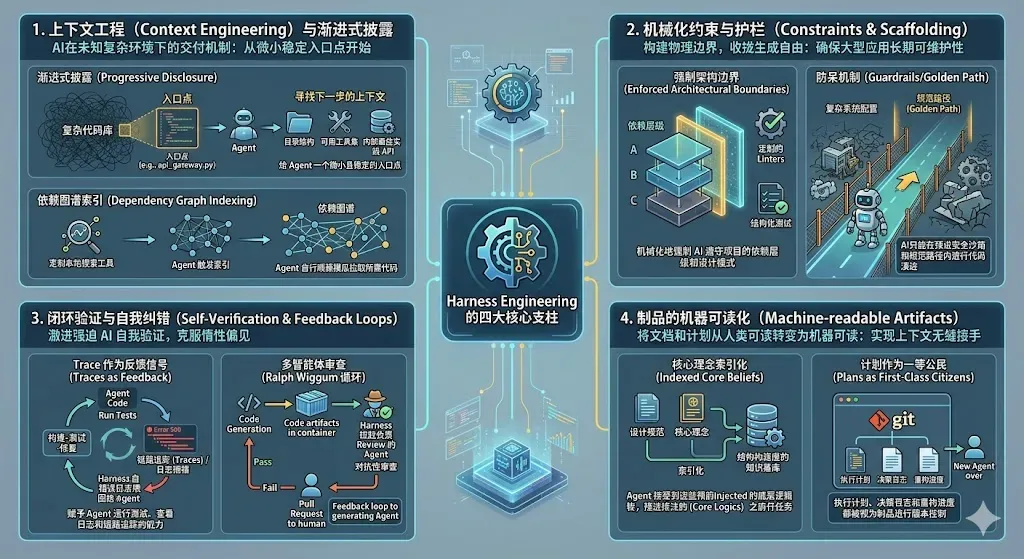
1. 上下文工程与渐进式披露
AI 在未知的复杂环境中极易崩溃。Harness 工程师不会把整个代码库一次性“塞”给模型,而是构建一套“交付机制”:
- 渐进式披露(Progressive Disclosure):给 Agent 一个微小且稳固的入口点,并教会它“去哪里查找下一步的上下文”(如目录结构、可用工具集、内部最佳实践 API)。
- 依赖图谱索引:为 Agent 提供定制的本地搜索工具,让它能够顺藤摸瓜自行拉取所需代码。
2. 机械约束与护栏机制
这是 Harness 的“物理边界”。为了让 AI 能够长期维护大型应用而不会让代码库腐化,必须收敛它的“无限生成自由”:
- 强制架构边界:通过定制化的 Linter 和结构化测试,机械化地迫使 AI 遵守项目的依赖层级与设计模式。
- 防呆机制:将复杂的系统配置收敛,使 AI 只能在预定的安全沙箱和规范化路径(Golden Path)内进行代码演进。
3. 闭环验证与自我纠错
AI 模型天然具有“偏信自己第一个看似合理的答案”的惯性。Harness 的作用就在于激进地迫使它进行自我验证:
- Trace 作为反馈信号:赋予 Agent 运行测试、查看日志和链路追踪(Traces)的能力。当报错发生时,通过 Harness 自动将错误日志回传给 Agent,使其进入“构建-测试-修复”的自主循环。
- 多智能体审查(如 Ralph Wiggum 循环):类似内部的 CI/CD 流水线,一段代码生成后,Harness 会自动拉起另一个专门负责审查的 Agent 进行对抗性审查,直到所有测试通过才会向人类工程师发起 Pull Request。
4. 面向机器的制品设计
在 Harness 时代,文档不再只是为了给人看,更是为了给机器读:
- 设计规范、核心理念(Core beliefs)都被索引化,Agent 在执行任务前,Harness 会先注入这些底层逻辑。
- 计划(Plans)作为一等公民:Agent 的执行计划、决策日志以及重构进度都被视为制品(Artifacts),与代码一起接受版本控制(Check into Repo)。即使中途更换 Agent,也能够无缝接手上文。