AMD锐龙AI Max处理器:赋能OpenClaw智能体主机,引领本地AI算力革命
2026年伊始,科技界意外地被一款代号为“龙虾”的产品彻底点燃。从GitHub开源社区蔓延至社交媒体,从极客实验室扩散到普通用户的桌面,OpenClaw(小龙虾)以势不可挡的姿态席卷全球,迅速晋升为人工智能领域的现象级工具。OpenClaw能在短时间内实现破圈传播,根本原因在于它精准命中了传统AI解决方案的三大核心痛点——无法自主执行任务、存在隐私泄露隐患以及使用成本高昂,并通过颠覆性的技术革新、灵活的架构设计以及开放的生态策略,完美契合了从个人创作者到大型企业的多元化、全场景应用需求。

OpenClaw的高效运行对底层硬件算力提出了明确且苛刻的要求:在本地部署大型语言模型需要具备大容量显存、强大计算性能与优异能效表现的设备。恰逢其时的AMD锐龙AI Max+系列处理器,完美匹配了这些关键需求。该系列处理器支持最高128GB的系统内存,并可通过统一内存架构技术将多达96GB的内存划拨为专属显存,从而能够流畅运行参数量高达350亿甚至1200亿的本地大模型,同时支持多个智能体并行协同工作,已然成为构建高性能“龙虾”运行环境(戏称“高端龙虾房”)的标准配置。与此同时,爆炸式增长的算力需求也反向驱动硬件厂商加速产品迭代,终端侧算力平台的竞争正日益成为整个AI硬件市场全新的焦点战场。
PC进化新篇章:智能体主机的崛起与价值
凭借对行业发展趋势的深刻洞察,AMD依托其锐龙AI Max系列处理器,率先提出了“智能体主机”(Agent Computer)这一全新的产品品类与概念。此举旨在抢占高端终端侧算力的战略高地,并构建覆盖全硬件形态、全软件生态的端侧AI综合解决方案。智能体主机通过在设备端侧直接部署大型模型,利用强大的本地算力不仅有效破解了因依赖云端服务而带来的潜在数据安全隐患,更显著降低了按Token计费所产生的持续成本,为千行百业的人工智能应用落地提供了高效、安全且经济可靠的核心算力支撑。

锐龙AI Max系列作为AMD在端侧AI领域的旗舰产品线,明确聚焦于高端专业市场,其核心使命便是服务于智能体主机这一新兴领域。它专为那些需要强大本地计算能力的专业应用场景而设计,目标用户包括AI应用开发者、超级个体创作者、中小企业以及各类垂直行业的解决方案提供商。该系列涵盖了锐龙AI Max+ 395、392、390及388等多个型号,以“极致算力性能、全面硬件形态适配、安全可控的运行环境”为核心竞争优势,致力于成为承载各类端侧智能体应用的理想硬件载体。
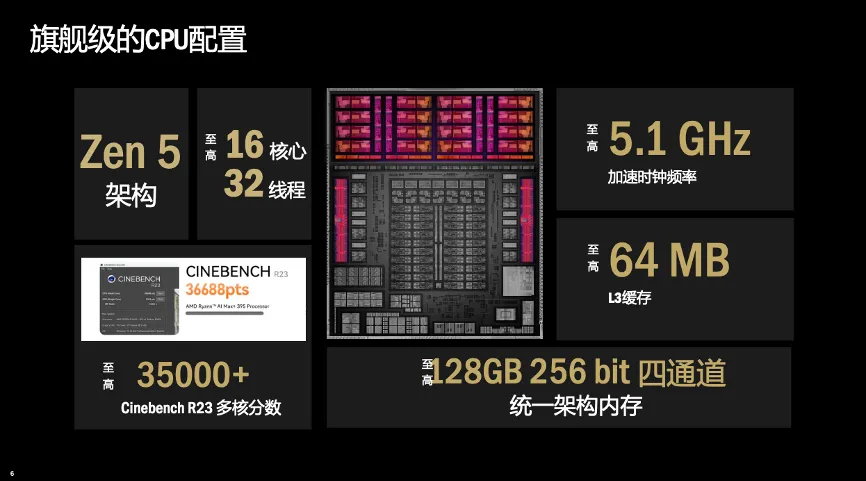
其中的顶配型号锐龙AI Max+ 395堪称Windows平台端侧AI算力的性能巅峰。它采用了创新的Zen 5 CPU架构、领先的4纳米制程工艺、RDNA 3.5 GPU架构以及XDNA 2 NPU架构,形成三位一体的协同设计。处理器拥有16个核心和32个线程,在CINEBENCH R23多核测试中分数突破35000分大关;集成的AMD Radeon 8060S显卡具备40组计算单元(CU),在3DMark TIME SPY图形测试中得分超过11000分;在内存方面,它支持最高128GB的四通道LPDDR5x-8000MT/s内存。借助统一内存架构,可将多达96GB的系统内存动态分配为显卡专用显存,从而能够流畅运行诸如GPT-OSS-120B、千问3.5-35B等超大规模模型,并支持多智能体并行工作,足以满足高端AI推理、复杂数字内容创作、专业科学研究等高强度计算任务的需求。

搭载128GB统一内存的AMD锐龙AI Max+“智能体主机”,能够通过OpenClaw平台高效运行品质接近云端服务的AI智能体工作负载。例如,在运行Qwen 3.5 35B A3B模型时,系统可实现每秒约45个token的生成速度,处理10,000个输入token仅需大约19.5秒。该平台支持最高26万token的上下文窗口,并且最多可同时运行6个独立的智能体。这使得在消费级硬件上进行可扩展的本地AI实验(例如智能体集群协同工作)成为现实,同时依然能保持出色的实时响应速度。

安全与成本双赢:本地算力的核心优势
在人工智能技术实际落地应用的过程中,对云端服务的依赖所引发的信息安全隐患以及高昂的Token调用费用,始终是制约行业实现规模化应用的两个核心痛点。AMD锐龙AI处理器凭借其强大的本地计算能力,成功将大型模型部署在终端设备侧运行,实现了数据不出本地域、Token在本地计算消耗,从而在破解安全难题的同时,大幅降低了总体使用成本。结合多个行业的实际案例,这一优势正变得愈发显著和具有说服力。

对于医疗健康、政务服务、金融科技、法律事务等对数据极为敏感的行业而言,隐私与安全是不可逾越的首要前提。在传统的云端部署模式下,数据在上传、传输过程中始终面临着泄露、拦截或篡改的潜在风险。而AMD锐龙AI Max系列处理器的本地算力核心优势,恰恰在于能够实现“数据全链路本地闭环处理”。所有的对话交互、记忆存储、文件操作与指令执行均在本地设备内完成,无需将任何数据上传至第三方云端服务器,从技术根源上彻底保障了数据资产的安全性与私密性。

以医疗行业的具体实践为例,某科技公司基于锐龙AI Max+ 395处理器打造的医疗多智能体解决方案,将GPT-OSS、千问80B等大模型进行本地化部署,并整合了哈佛医学院权威课程、国内三甲医院临床经验等私有化知识库,构建起一个多智能体协作团队,覆盖医学影像智能分析、病理辅助诊断、电子病历自动化管理等多个场景。由于所有敏感的医疗数据(包括患者病历、影像学资料、诊断过程记录)都在本地设备内运行处理,完全避免了因网络传输可能带来的隐私泄露风险,同时严格符合国内外医疗数据安全合规性要求。该方案使得基层医疗机构的实习医生也能获得堪比主任医师级别的专业诊断辅助,有效推动了优质医疗资源向更广泛区域的覆盖与下沉。
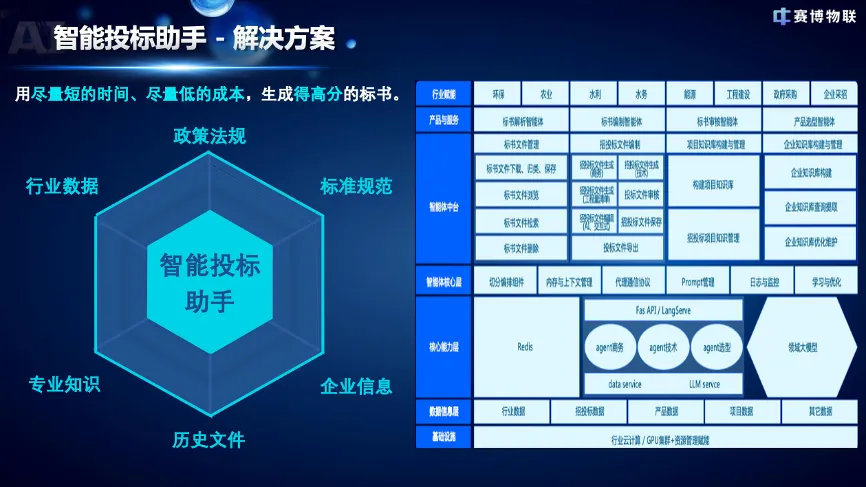
再比如,在智能招投标领域,某物联科技公司依托锐龙AI Max+ 395的强劲本地算力,将涉及企业核心竞争力的投标数据、历史标书模板、行业政策知识库等资料全部部署于本地。其智能投标助手在本地环境中即可独立完成标书的自动编制、合规性风险智能排查、内容表达优化润色等一系列工作,完全避免了将企业核心商业机密信息上传至公有云可能带来的安全隐患,从而有效降低了因信息泄露导致的废标风险,确保了企业关键知识资产的安全与可控。

另一家科技企业基于锐龙AI Max+ 395打造的智域双生AI工作站,则创新性地采用了沙盒隔离技术,实现了AI智能体运行环境与常规Windows办公环境的物理级隔离。这种设计既充分保障了OpenClaw智能体运行过程的安全性,又彻底避免了AI应用的复杂操作对日常办公数据与软件环境可能产生的干扰或影响,真正做到了“安全运行AI智能体”与“高效进行日常办公”两者并行不悖,特别适配广大中小企业对安全办公环境的迫切需求。
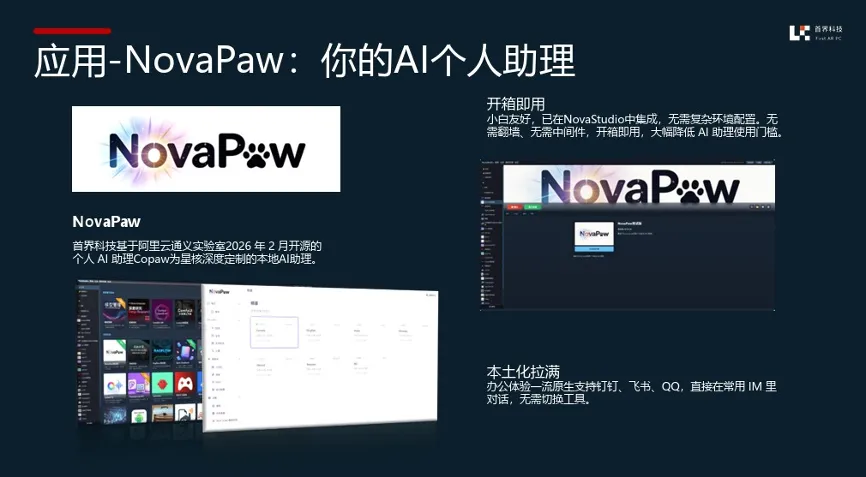
此外,还有科技公司推出了基于AMD锐龙AI Max+ 395处理器的开箱即用式AI一站式应用平台解决方案。该方案已经上线了名为“NovaPaw”的一键部署智能AI助理应用,它集成了NovaStudio内置的多种技能应用,目前支持的功能包括Whisper语音转文字、图像生成与编辑、视频生成、TTS文本转语音以及图像识别等。得益于数据全链路在本地闭环处理,确保了所有敏感数据始终不出本地域,从而在提供强大功能的同时,牢牢守护了用户的数据安全底线。
成本革命:本地算力如何替代云端调用降低费用
随着人工智能应用走向大规模普及,频繁调用云端大模型API所产生的Token费用,已成为企业和个人用户一项不可忽视的重要成本支出。行业实践数据显示,重度AI用户如果完全依赖云端API调用,每月产生的Token费用可能高达数千元人民币,长期积累的使用成本极为高昂。而AMD锐龙AI Max系列处理器所提供的强大本地算力,能够将大模型完全部署在终端设备侧,所有Token均在本地计算消耗,用户无需再为每一次的云端API调用支付费用,这极大地降低了长期使用AI应用的综合成本。

一个颇具代表性的实践案例是,某位技术专家使用搭载了锐龙AI Max+ 395处理器的惠普笔记本电脑部署本地代码生成模型。他仅在某个云端服务平台充值了300元,使用很长时间后账户内仍剩余200多元,其核心的编程辅助与代码生成算力消耗几乎全部依靠本地的Coder Next模型完成,基本实现了“零额外Token费用”的高效开发体验。与之形成鲜明对比的是,部分完全依赖云端API的用户,每月需要支付的Token费用甚至超过几千元,即便通过某些API代理服务获得折扣,其长期使用成本依然处于较高水平。
在科学研究领域,某科研团队基于锐龙AI Max+ 395打造了专用的科研AI分析平台。该平台将海量的专业学术论文和期刊资料本地化部署,并将其转化为可进行交互式对话的智能知识库。科研人员在进行文献调研、原理剖析或数据可视化时,无需再调用昂贵的云端模型,即可在本地高效完成相关操作。这不仅节省了巨额的Token费用,还彻底避免了因网络延迟或云端服务不稳定带来的等待时间,显著提升了整体科研工作的效率与流畅度。
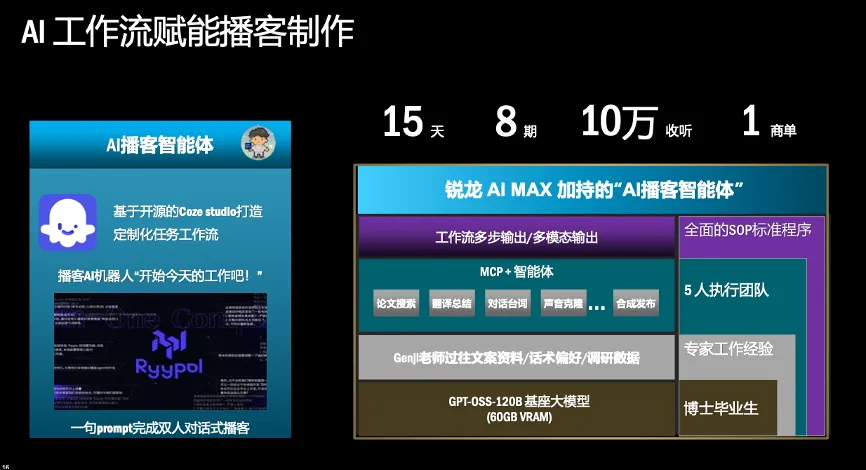
对于超级个体户和一人公司(OPC)这类群体而言,本地算力所带来的成本优势则更为直接和明显。例如,某位拥有百万粉丝的B站视频UP主,基于锐龙AI Max系列处理器打造了自己的播客内容创作智能体。通过本地算力,他独立完成了从学术论文搜索、跨语言翻译、对话稿本生成、个性化声音克隆到最终的音频剪辑合成等全流程工作,全程无需支付任何云端Token费用。在短短15天内,他就高效产出了8期高质量的双人对话播客节目,累计收听量达到10万次,并且成功获得了商业合作订单,真正实践了一种“低投入成本、高内容产出”的数字化创业新模式。
总结与展望:智能体主机的未来趋势
OpenClaw的迅速风靡绝非昙花一现的短暂热潮,而是标志着AI智能体时代正式来临的一个强烈信号。这股浪潮正推动人工智能从简单的“聊天机器人”或“问答工具”,升级为能够深度融入实际生产流程、日常办公协作与创意内容生成全过程的“数字员工”,成为人类工作与生活中不可或缺的核心协作伙伴。这也促使传统的个人计算形态,从经典的个人电脑(PC)向功能更专一、集成度更高的智能体主机(Agent Computer)方向演进。而这场深刻变革的核心驱动力,正是终端侧本地算力的跨越式发展。唯有依赖强大、可靠的本地计算能力,才能为大型模型的本地化部署、多智能体的高效并行工作提供坚实支撑,从而真正实现数据隐私安全与使用效率提升的双重目标。
面对AI智能体时代所催生的全新算力需求格局,AMD进行了精准的战略布局。凭借其锐龙AI Max系列处理器在高端市场的及时卡位,AMD成功构建起一套覆盖全硬件形态、适配全软件生态的终端侧AI整体解决方案,成为这场算力范式变革中的关键推动力量。其所打造的强大本地算力底座,不仅通过“数据不出域”的本地部署模式,为医疗、金融、政务等对隐私和安全有严苛要求的行业筑起了牢固的防护屏障,更通过以本地算力直接替代云端调用的方式,大幅减轻了用户面临的Token费用负担,使得各类AI应用能够在更多行业和场景中实现规模化、可持续的落地部署。
当前,OpenClaw的生态系统仍在持续快速扩张,其功能迭代、硬件适配优化以及行业级解决方案的落地进程都在不断推进。AMD也正与众多生态合作伙伴展开深度协同,推动锐龙AI Max系列处理器在智慧医疗、智能教育、前沿科研、企业数字化办公等多个垂直行业落地了众多成熟可用的应用案例,切实助力各行各业提升运营效率与创新能力。这一切,标志着端侧智能体主机时代的发展已经迈入了一个充满活力的全新阶段。