AMD AI Max 395 开箱深度评测:希未AideaStation R1桌面AI超算全面体验
在2025年,SEAVIV希未推出了AideaStation R1,这款迷你AI算力中心以其仅4升的紧凑机身,实现了桌面级AI超算的性能。它搭载了AMD锐龙AI Max+ 395处理器,支持高达96GB的动态分配显存,并集成了Radeon 8060S核显,其图形性能可媲美RTX 4060独显。此外,设备还配备了50 TOPS的NPU算力,能够轻松流畅地运行本地大型模型,既满足了专业生产力需求,又兼具极致美学设计,堪称一款革命性的工作站。

这次开箱体验让我格外兴奋,因为首次接触如此高端的设备,特别感谢希未团队提供的测试机会。本评测内容详尽,对于考虑入手的朋友来说,绝对不容错过。

开箱过程:从包装到设备细节
产品的包装盒采用纯黑色设计,正面醒目地印有“SEAVIV AideaStation R1”型号标识,显得简洁而专业。

盒子侧面标注了详细的技术参数。我拿到的是顶配版本,搭载了AMD AI Max+ 395处理器,配备128GB内存和2TB固态硬盘,配置堪称豪华。

打开包装箱,首先映入眼帘的不是主机,而是一封黑色信封,这份仪式感瞬间将期待值拉满。

信封上写着“只手摘星辰”五个字,让我对这台原本冰冷的生产力机器有了全新的认识。它不仅仅是一个工具,更像是能够协助实现各种创意构想的高效助手。

信封内附赠了一张NFC卡片,作为VIP身份认证凭证。未来如果参与线下活动,这张卡片可用于解锁专属权益,增加了产品的附加价值。

随机的用户手册不仅清晰地介绍了设备各个接口的功能,还贴心地说明了如何进入BIOS以及切换引导盘,对新手用户非常友好。

继续往下翻,可以看到一个独立的配件盒,所有附件都井然有序地放置其中。

配件盒中包含一根标准的电源线,确保设备稳定供电。

还有一条带有屏蔽磁环的HDMI线缆,相比普通线材具有更好的抗干扰能力,能保证高质量的信号传输。

最后,终于迎来了主角——主机本体被牢牢固定在包装箱中央,这种设计能有效防止在快递运输过程中发生碰撞损坏。

主机采用哑光灰色金属外壳,边缘配有一圈亮面切边倒角,让整体外观更具层次感,避免了单调的设计。

正面接口整齐排列成一条直线,这种布局对于有强迫症的用户来说简直是一大福音。

接口从左到右依次为:电源按键、性能模式切换按键、SD卡槽、Type-C(支持USB4)接口、两个USB 3.2接口以及音频插孔,覆盖了日常使用的基本需求。

机身侧面设计了大量散热开孔,结合HyperCryo散热架构和双CPU风扇,能够高效带走内部热量。即使在运行大型模型、8K视频剪辑或3D渲染等高负载场景下,设备也能保持长时间稳定运行。

整机体积仅为4升,具体尺寸为247.5×188.4×96.5毫米,裸机重量约3千克,比许多高性能游戏笔记本还要轻便。放置在桌面上几乎不占空间,外出时也能轻松放入背包携带。“桌面AI超算”能做到如此便携,确实超出了我的预期。

背面的接口同样丰富,包括:两个USB 2.0接口、一个HDMI 2.1接口、一个DP 1.4接口、一个Type-C(支持USB4和DP1.4)接口、一个USB 3.2接口、RJ45网络接口、二合一音频接口以及电源接口。

更多的接口意味着更强的扩展能力,设备支持“4K分辨率下的四屏四显”输出,用户无需频繁切换窗口,工作效率可得到多倍提升。

设备内部配备了350W的Flex电源,结合140W的高效散热系统,确保AMD AI Max+ 395处理器能够持续满血输出性能。

底部四周设有防滑脚垫,不仅将机身略微垫高、为底部散热留出空间,还能确保设备在桌面上放置时稳固不滑动。

机身侧面的金色贴纸非常显眼,一眼就能识别出这是搭载了AMD RYZEN AI MAX+处理器的设备。

性能实测:全面跑分与散热评估
相信许多用户都关心这台设备的实际性能表现,因此我重点测试了其散热能力和各项跑分数据。
系统概览与硬件识别
设备默认已预装Windows 11操作系统,开箱即用,无需繁琐的安装步骤。
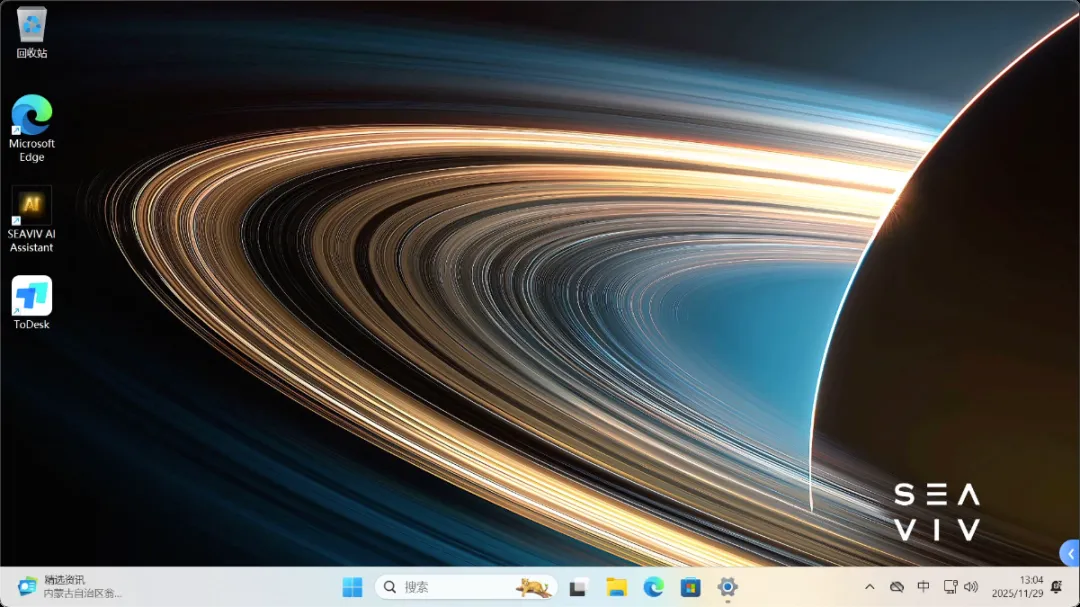
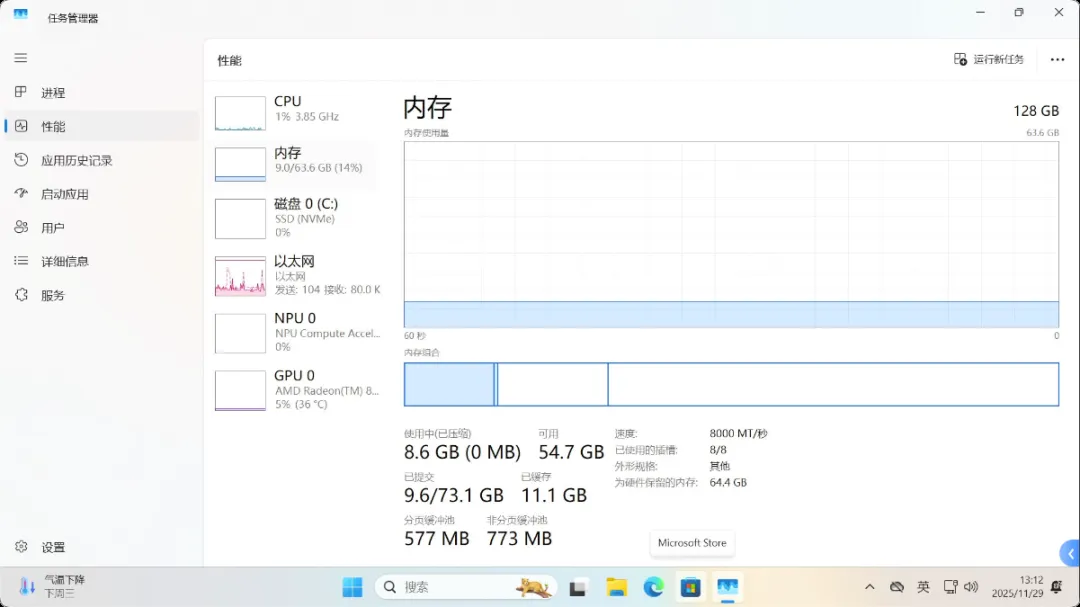
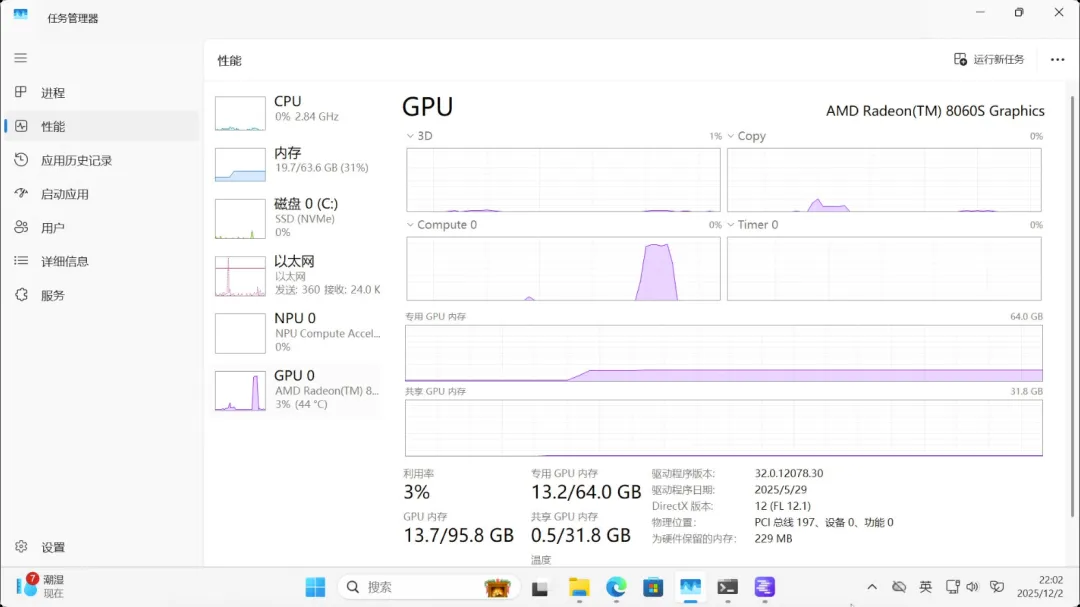
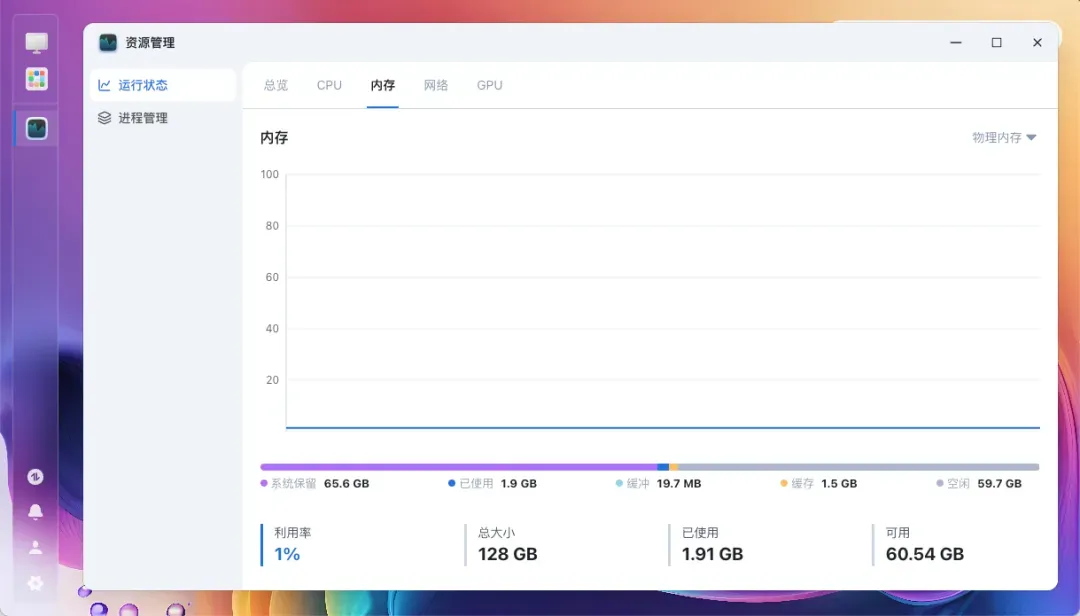
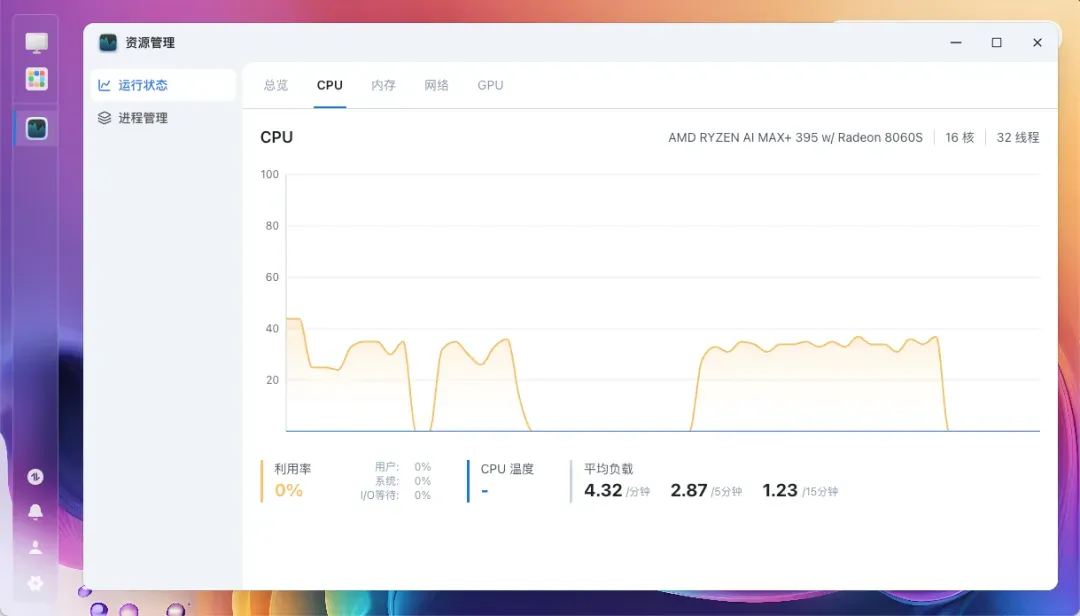
打开系统信息页面,最引人注目的无疑是64GB的显存容量以及这颗AMD锐龙AI Max+ 395处理器。
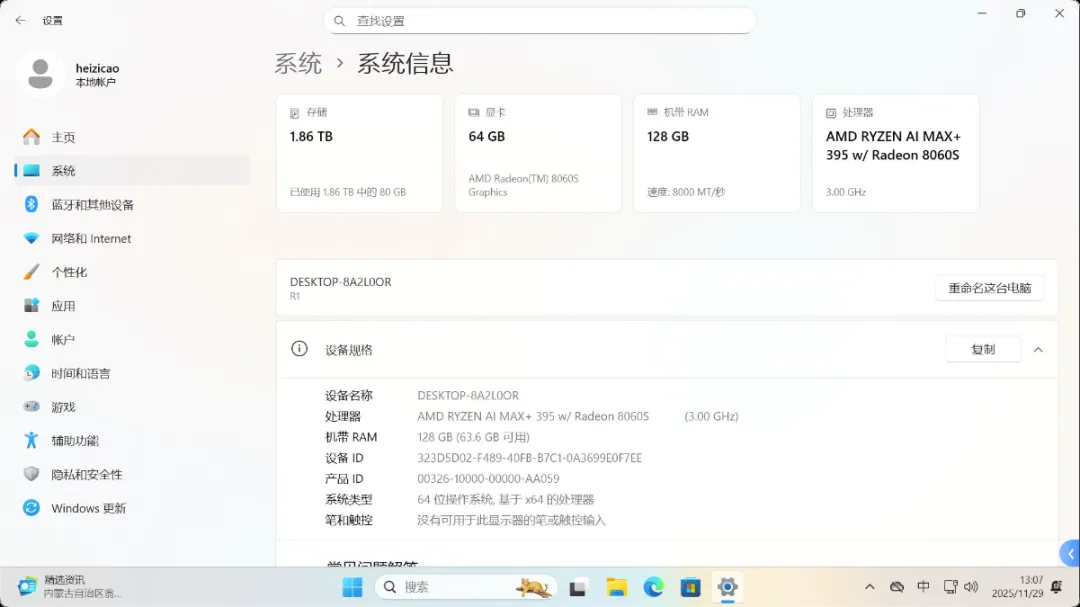
需要注意的是,预装的Windows 11家庭版不支持自带的远程桌面功能。如果需要在局域网内进行远程访问,建议通过正规渠道升级至专业版以解锁该功能。
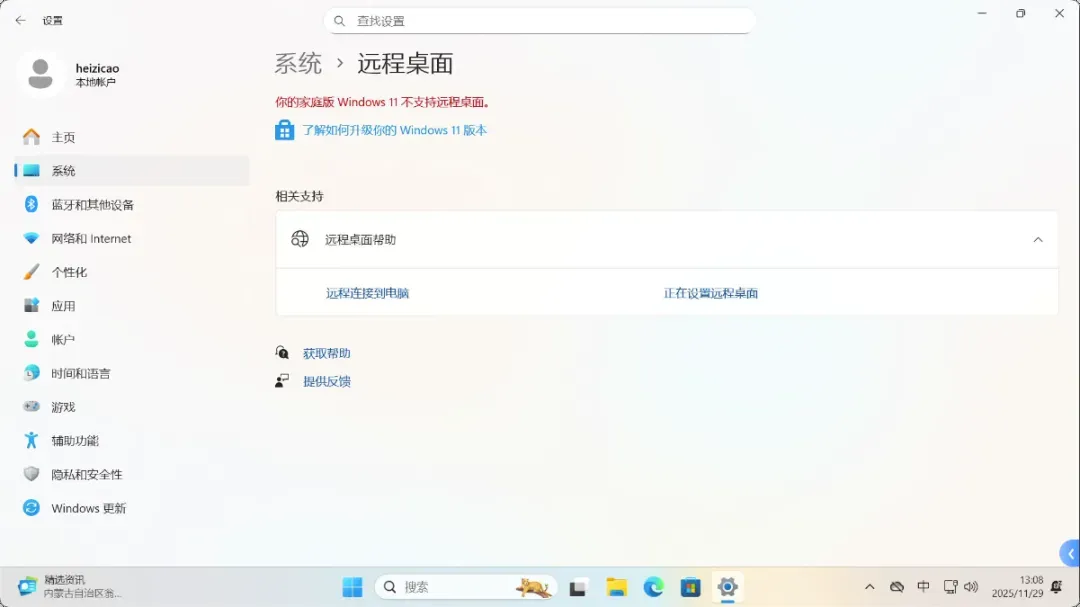
网络连接方面,设备支持有线2.5G网口、无线Wi-Fi 7以及蓝牙5.4,提供了高速且稳定的连接选项。
这颗AMD锐龙AI MAX+ 395处理器堪称“性能怪兽”:拥有16核32线程,无论是运行大型AI模型还是同时处理多任务,都能游刃有余,表现从容。
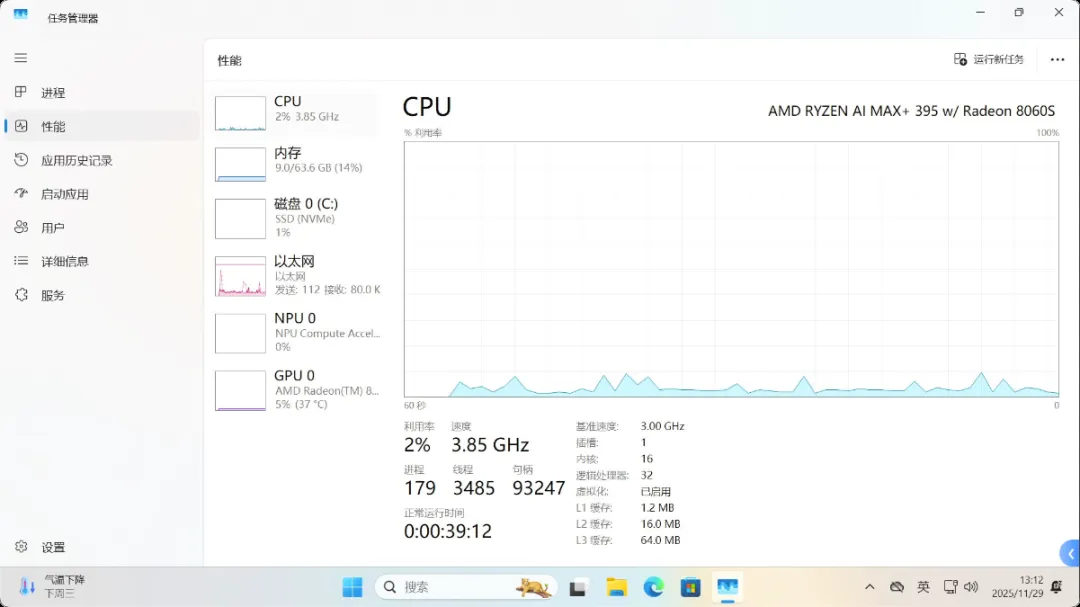
128GB的大内存并非仅仅为了参数好看,它可以动态分配最多96GB作为显存使用,从而在本地轻松运行700亿参数的大型模型。
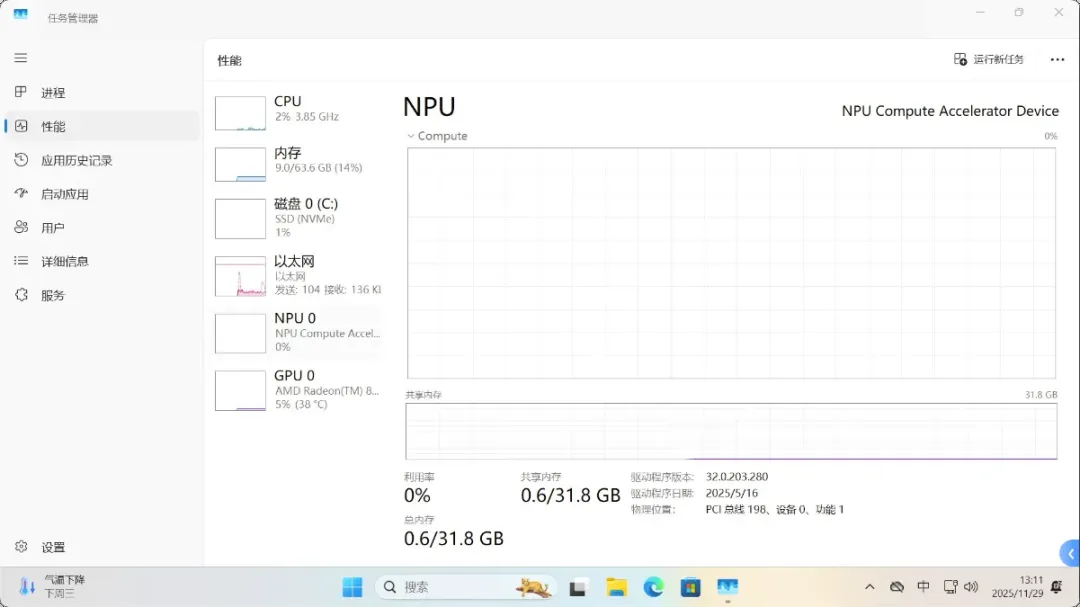
NPU(神经网络处理单元)同样不可或缺,它基于AMD XDNA架构打造,支持FP16精度计算,能够高效运行本地轻量级AI模型。
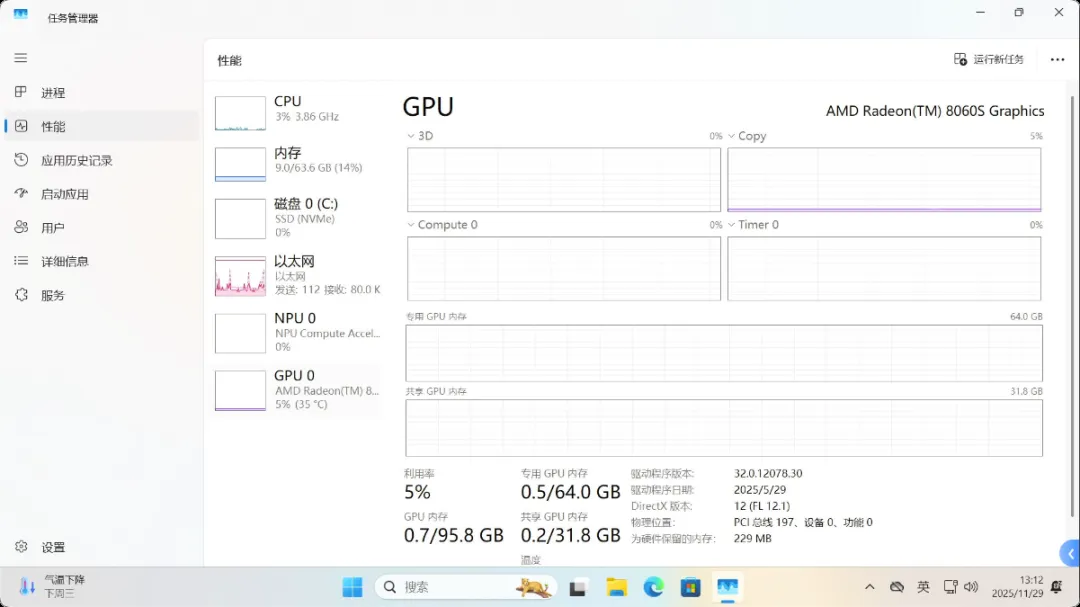
千万别小看这颗Radeon 8060S核显——它的性能跑分直接达到了RTX 4060独立显卡的水平!而且可以划分最高96GB的显存,这比RTX 4090的24GB显存还要多出四倍。运行AI大模型时完全无需担心显存不足的问题。
跑分数据与压力测试
通过CPU-Z检测,处理器的单核得分为761.0,多核得分高达15065.4,性能表现非常强劲。
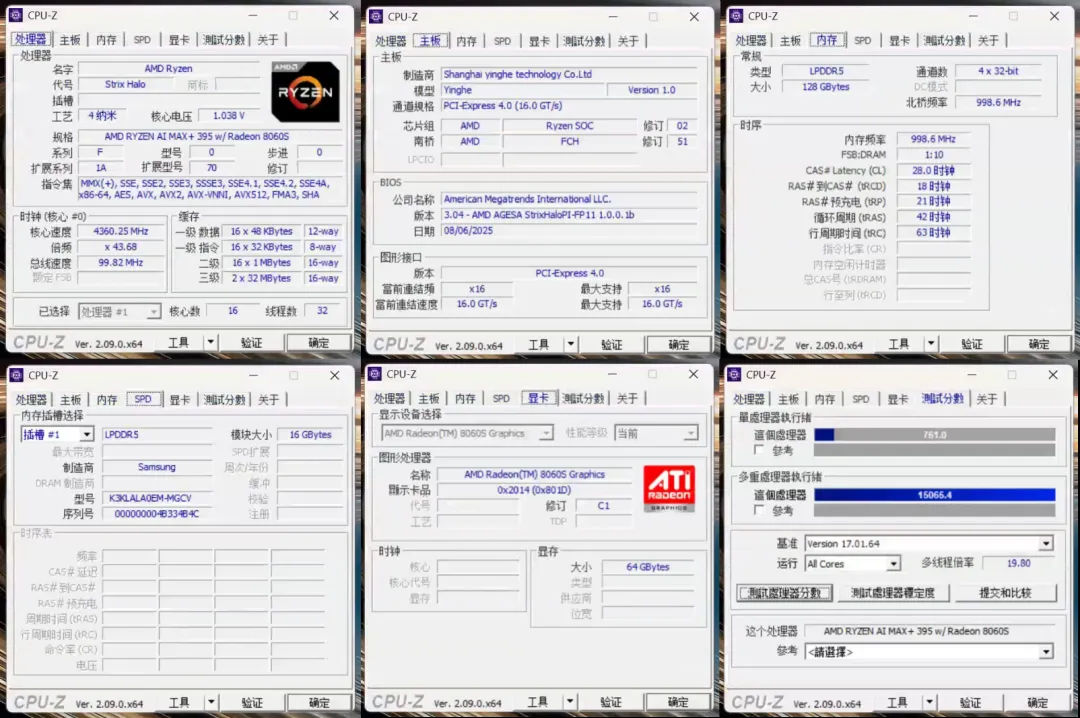
在室温19.6℃的环境下,开启性能模式并进行FPU加甜甜圈双烤压力测试10分钟,CPU温度稳定维持在78℃左右。散热表现相当出色,同时风扇噪音控制得很好(声音较小,没有刺耳的啸叫声)。
双烤测试10分钟后,使用热成像仪可以直观看到,热量主要集中在出风口区域。机器的金属外壳摸起来仅有温热感,说明内部产生的热量都被高效地排出去了。

功耗情况如下:待机时功耗约为31瓦,双烤满载时功耗达到236瓦,能效比控制得不错。

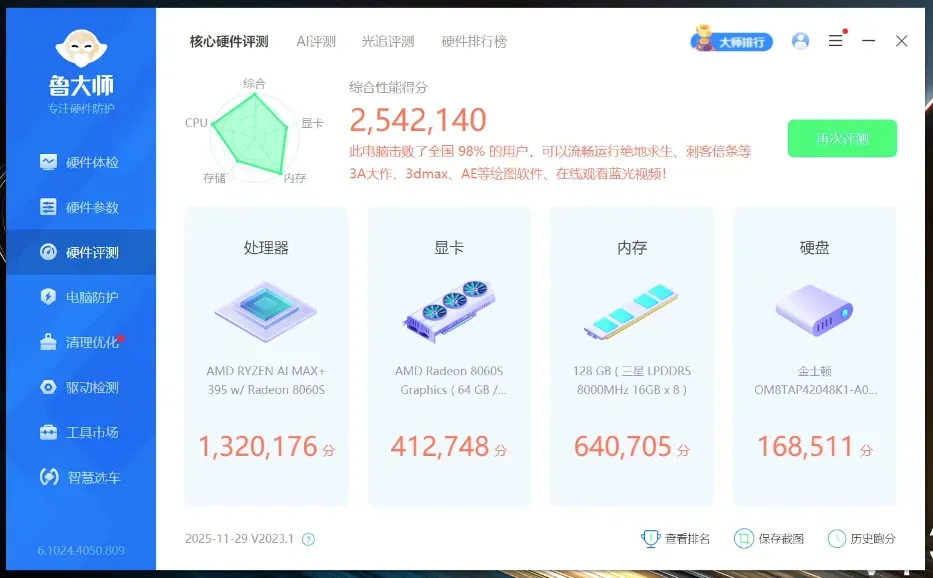
鲁大师跑分数据非常亮眼:处理器得分1,320,176,核显得分412,748。核显分数已经超越了许多独立显卡,再搭配超大显存,称之为AI算力中心毫不为过。
AI应用测试:多款工具实战体验
作为一台桌面级AI算力中心,我测试了多款当前主流的AI应用,旨在充分挖掘这颗GPU的潜能。
SEAVIV AI助手深度体验
系统自带的AI助手“希未同学”非常实用,即使是新手用户也能轻松上手操作。
助手提供了本地和云端两种模型选择,我下载了多个不同模型进行测试对比。
云端模型可以调用DeepSeek-V3和R1,并且目前都是免费使用,回复速度极快。
运行QwQ:32B模型时完全不卡顿,提出问题几乎可以瞬间得到回复。
使用DeepSeek-R1:32B模型时,即使是一些复杂的数学问题也能顺利解答。
助手功能全面,用户无需繁琐地设置AI角色扮演,一步就能实现所需功能。
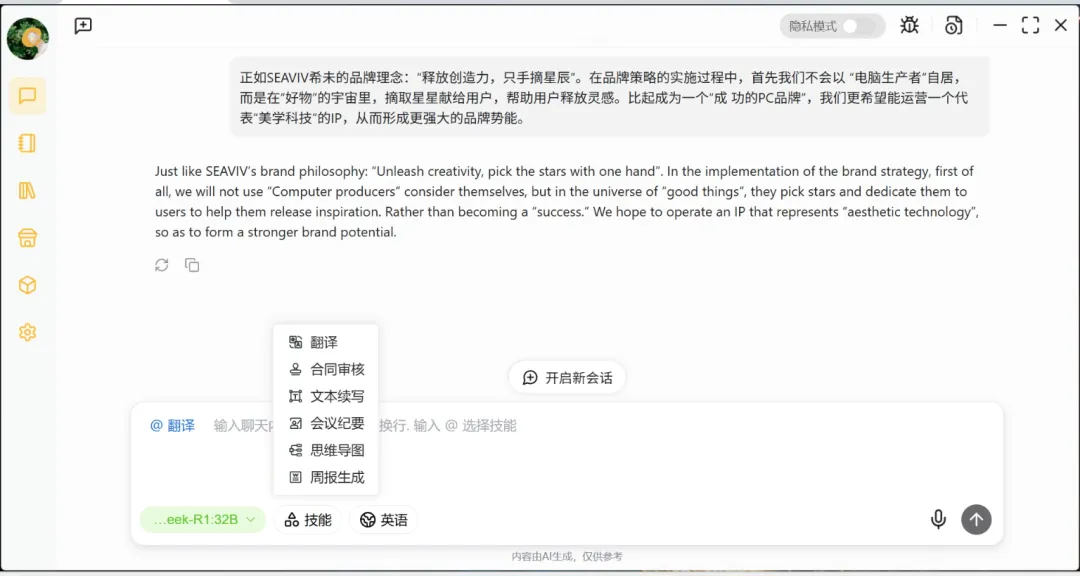
使用思维导图技能,向AI提问“生物分类等级”,系统很快就能在线生成结构清晰的思维导图。
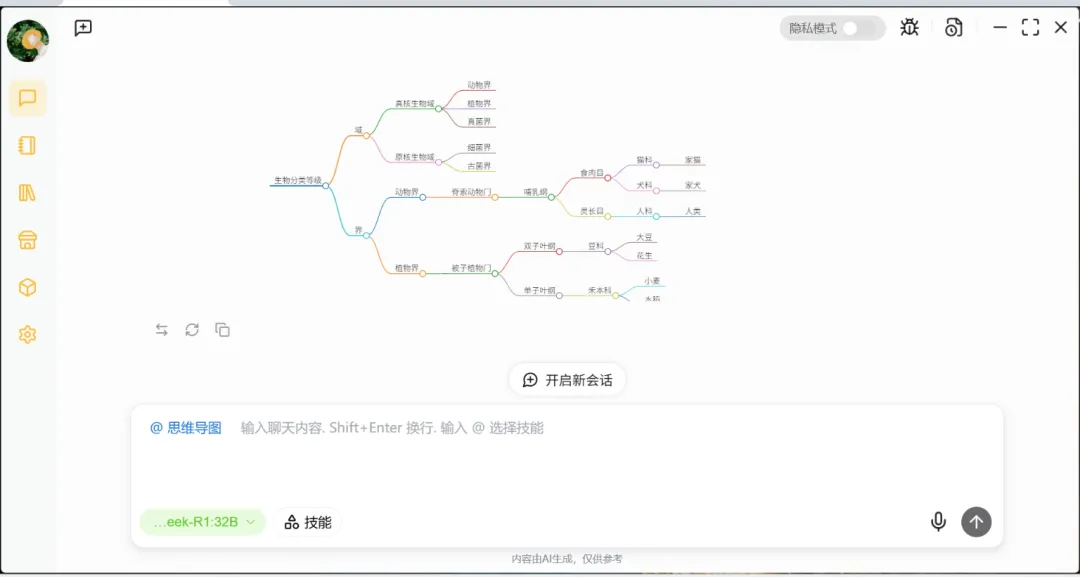
直接将一大段文本内容丢给AI,它也能生成逻辑条理清晰的摘要,极大地提高了阅读效率。
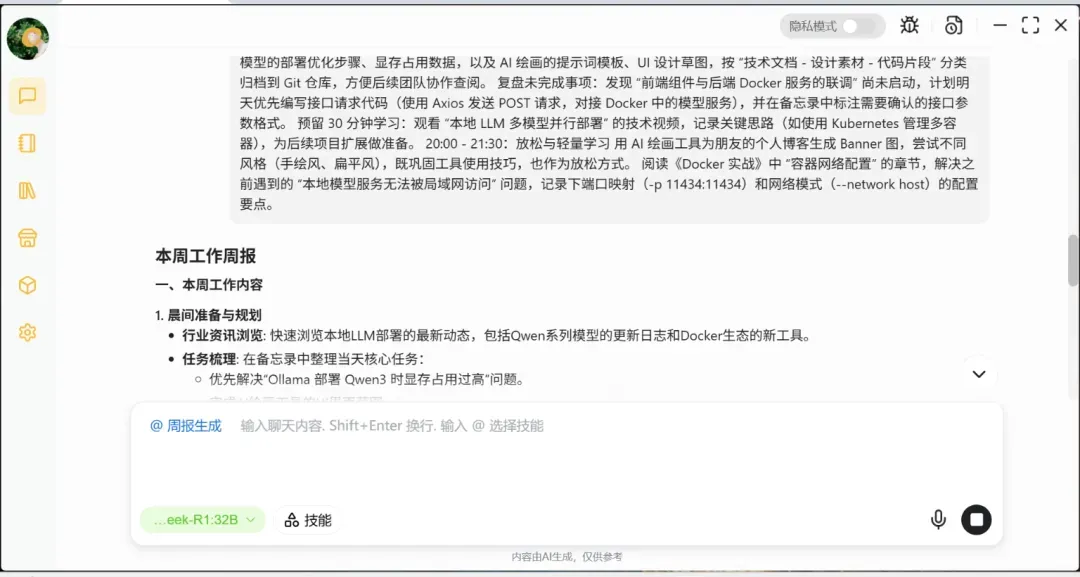
开启深度思考模式后,我们可以更好地理解AI的推理思路,从而及时调整提问方式以获取更优质的答案。
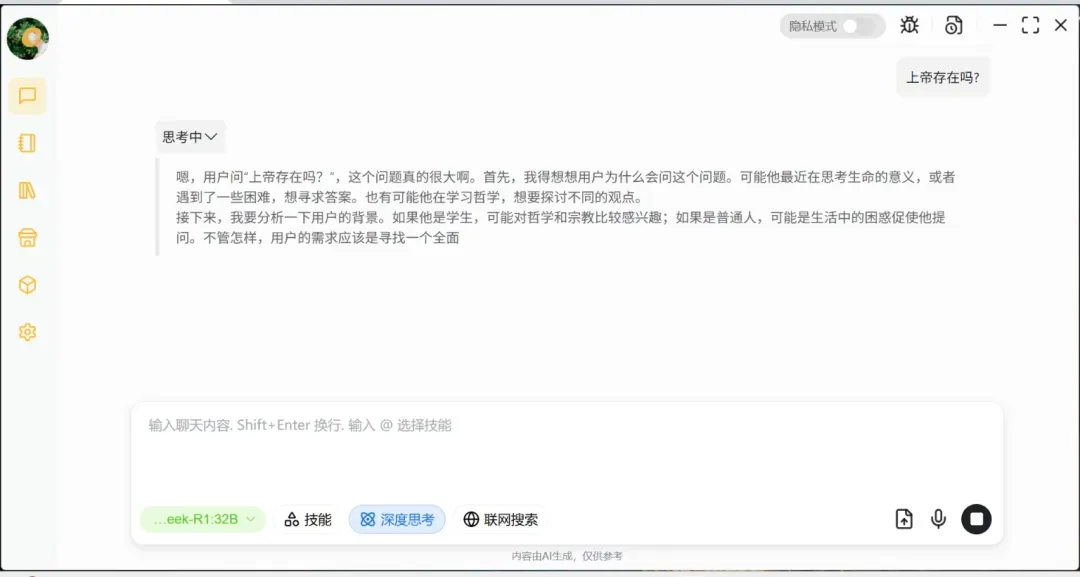
启用联网功能后,彻底解决了本地数据局限性和信息实时性不足的问题。
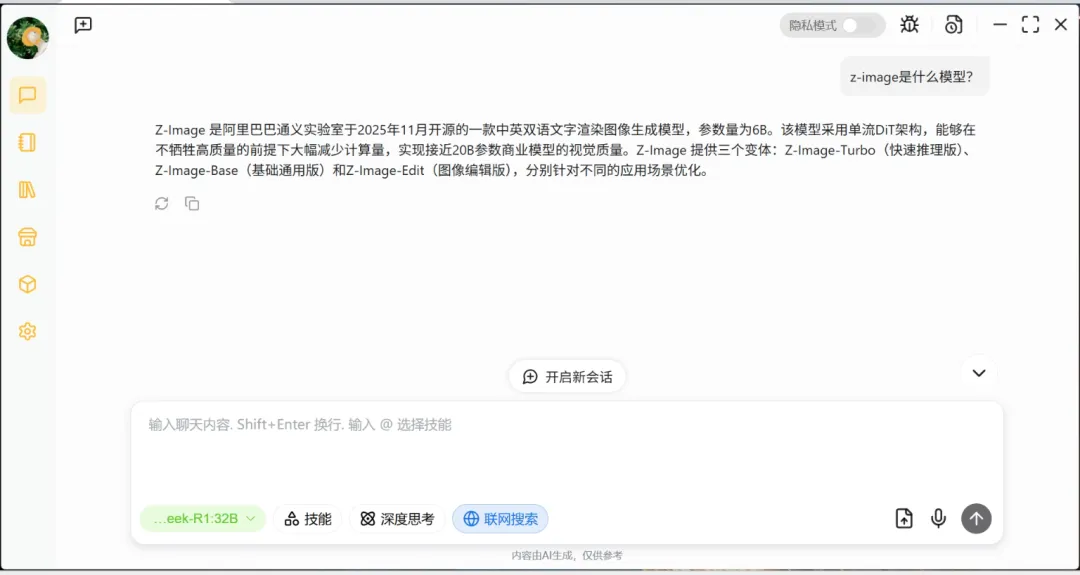
上传本地文件并让AI进行总结归纳,这一功能在实际工作中非常实用。
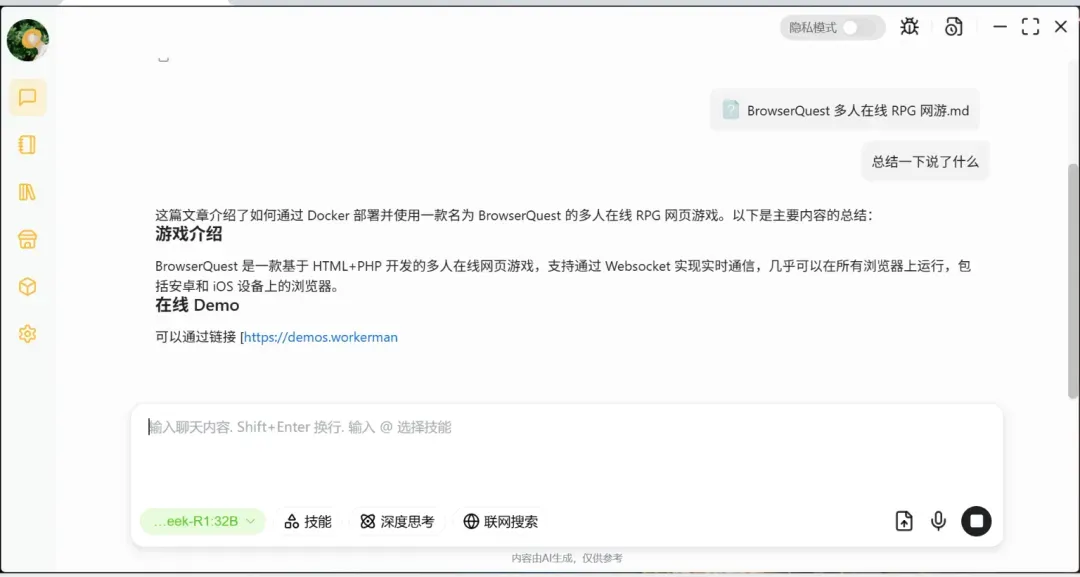
笔记功能允许用户一边记录,一边查询不懂的问题,同时也能快速理解笔记的核心内容。
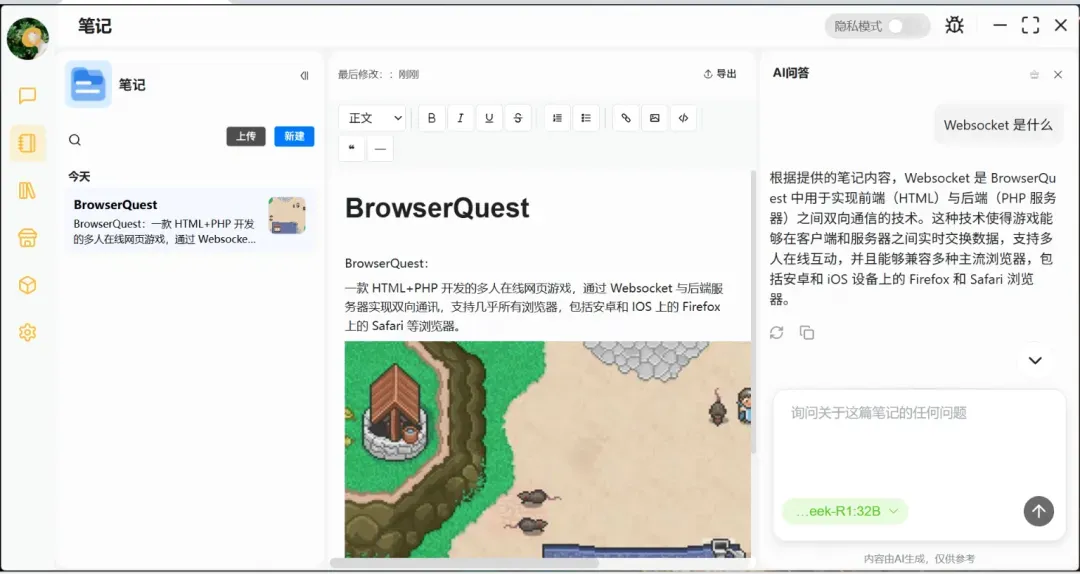
知识库功能对企业用户极为友好——将公司文档全部导入后,新员工培训可以直接交由AI答疑,节省了大量人力资源。关键是本地部署确保文件不会外流,安全感十足。
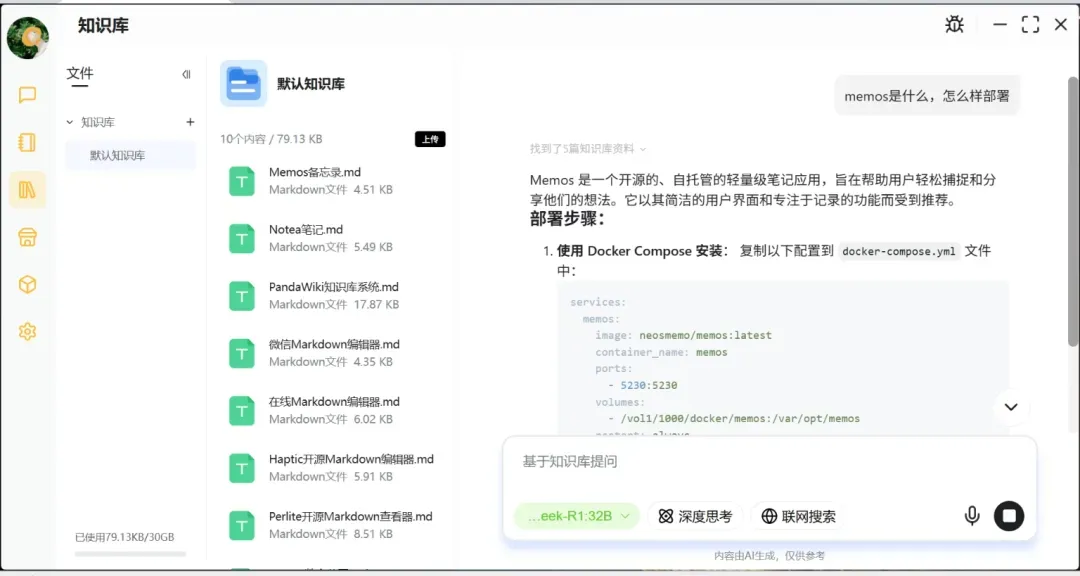
内置专门的模型商店,下载模型非常方便,而且无需担心国内网络环境下的下载速度问题。不过,希望后期能上架更多模型供用户选择,并增加模型导入导出功能以提升使用自由度。
除了使用GPU运行大型模型外,也可以调用NPU来运行轻量级小模型。
应用商店聚合了许多模型提供商的入口,用户可以便捷地打开网页使用相关服务。

Ollama模型运行实测
目前Ollama的最新版本已经提供了图形用户界面,相比之前只能使用命令行操作直观了许多。
我的NAS上也部署了Ollama,直接将已有的模型目录复制过来就能实现无缝迁移,非常方便。
除了之前下载的小模型,这次又额外下载了几个大型模型进行测试。
系统能够正常调用核显进行推理计算,响应和回复速度都非常迅速。
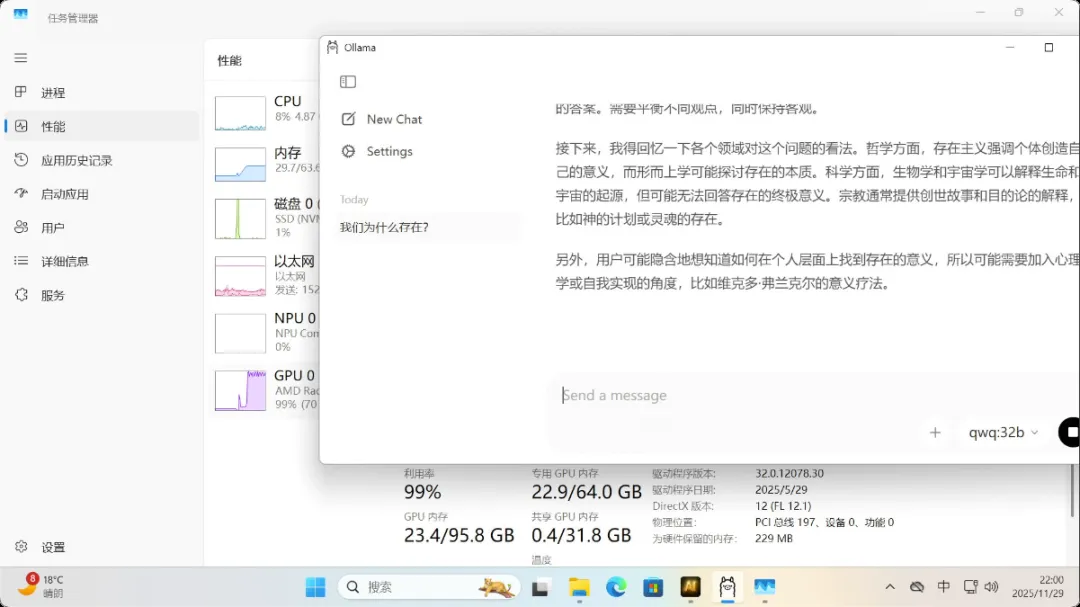
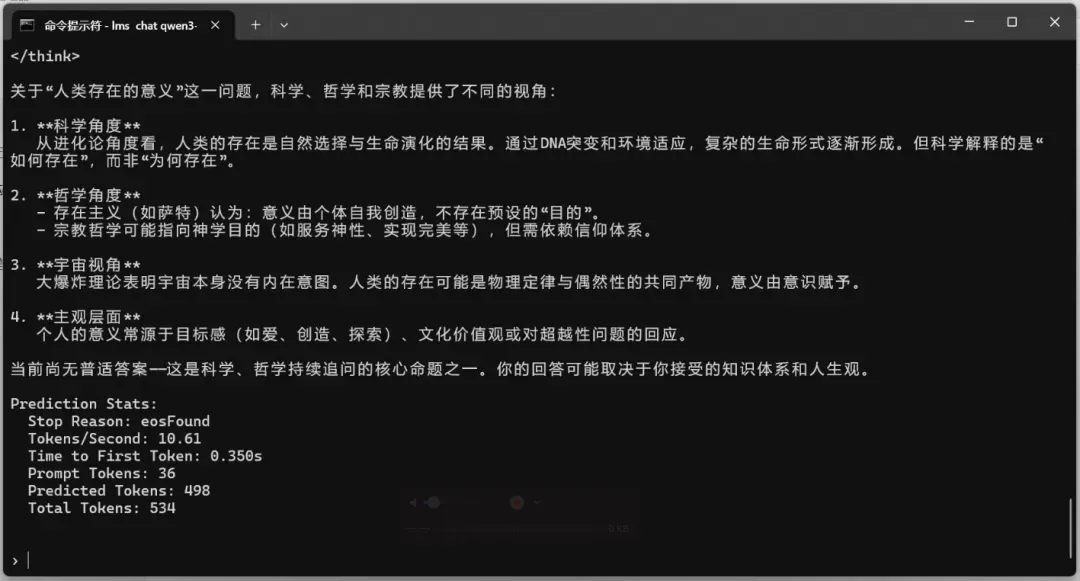
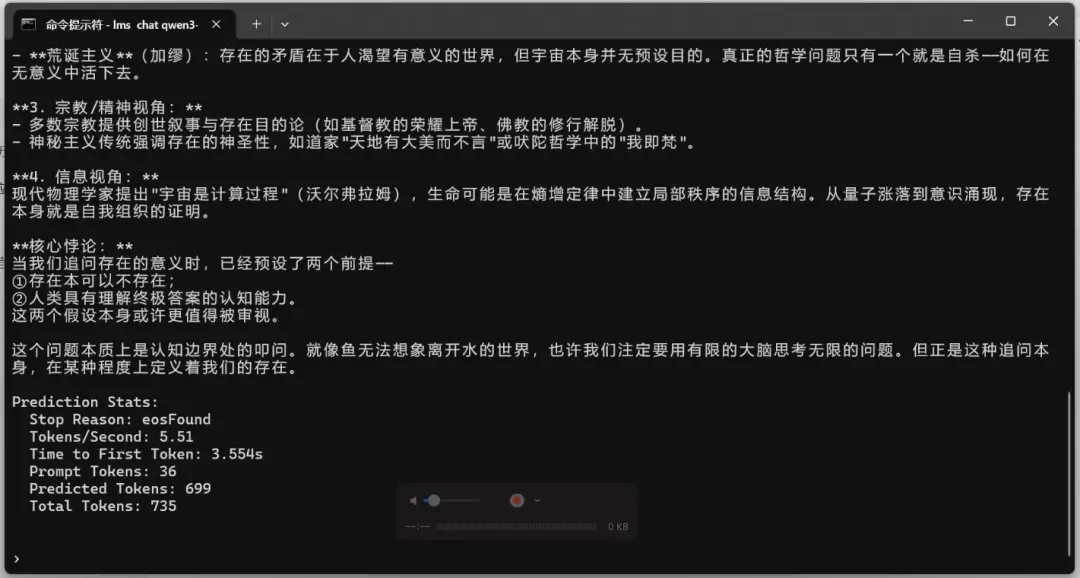
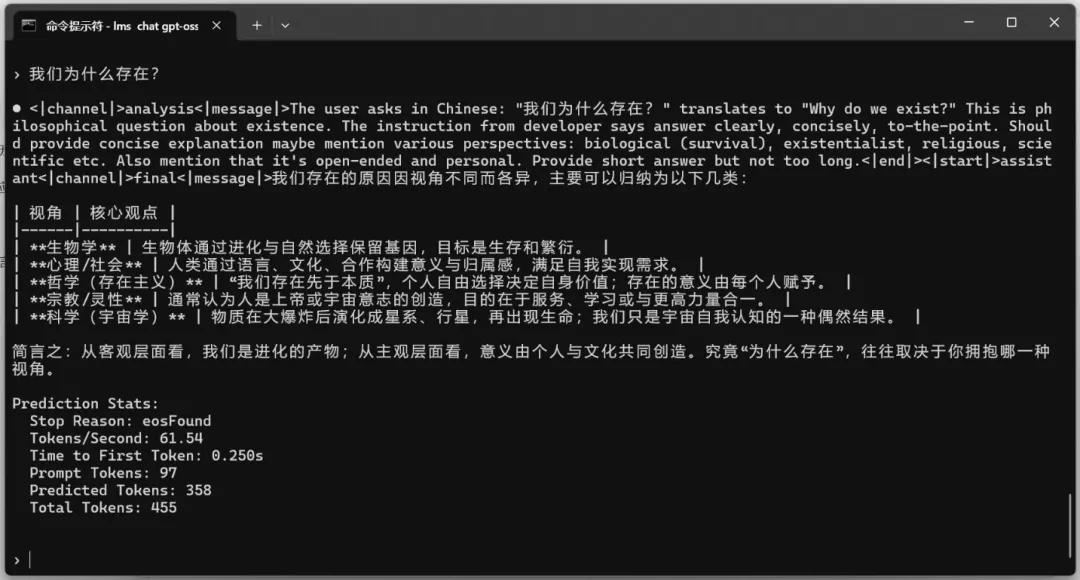
测试问题:我们为什么存在?
以下是整理后的测试数据表格,详细信息也可以参考对应图片。
| 模型名称 | 参数类型 | 显存需求(GB) | 推理速度(词/秒) | 运行状态 |
|---|---|---|---|---|
| qwen3:32b | dense | 23.5 | 9.63 | ✅ 正常 |
| deepseek-r1:70b | dense | 46.0 | 4.52 | ✅ 正常 |
| qwen3:30b-a3b | MoE | 20.4 | 61.12 | ✅ 正常 |
| qwen3:235b-a22b | MoE | 64.7 | 1.50 | ⚠ 有问题 |
| gpt-oss:20b | MoE | 14.8 | 47.56 | ✅ 正常 |
| gpt-oss:120b | MoE | 63.0 | 34.32 | ✅ 正常 |
Qwen3-32B(dense模型)
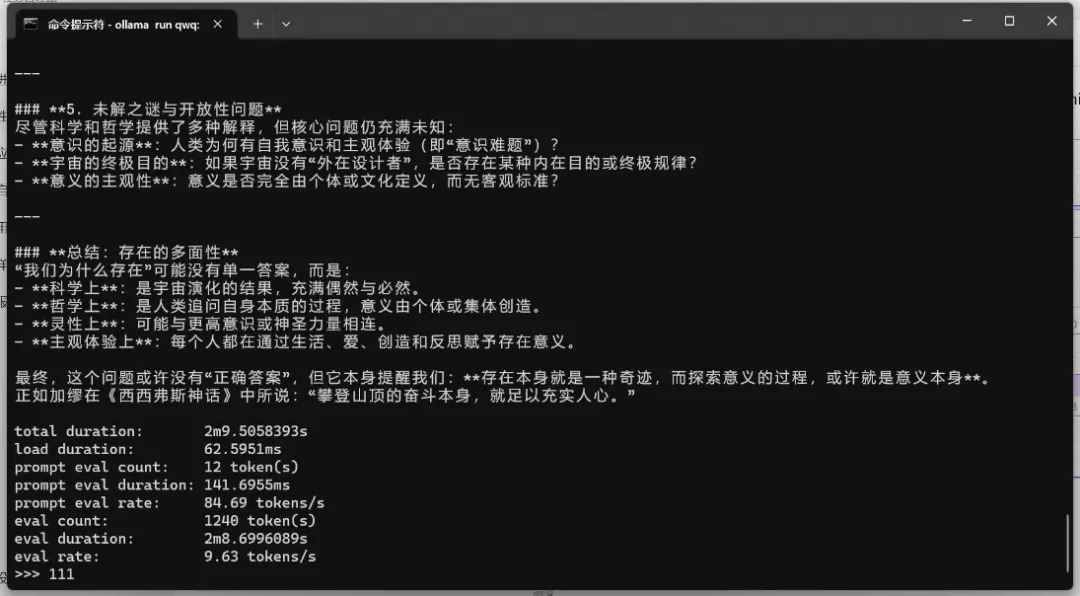
占用显存23.5GB
deepseek-r1:70b(dense模型)
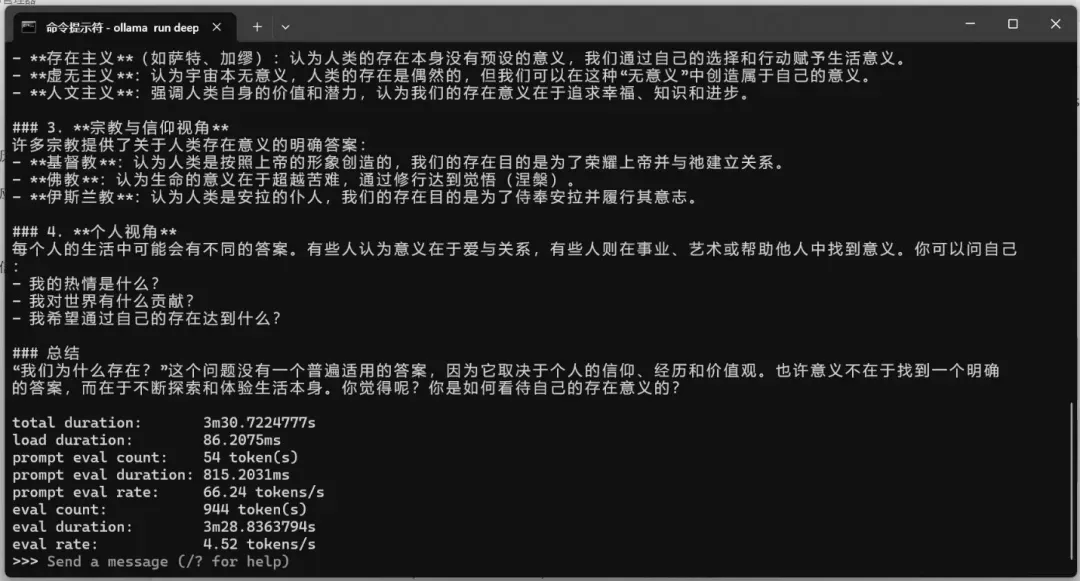
占用显存46.0GB
qwen3:30b-a3b(MoE模型)
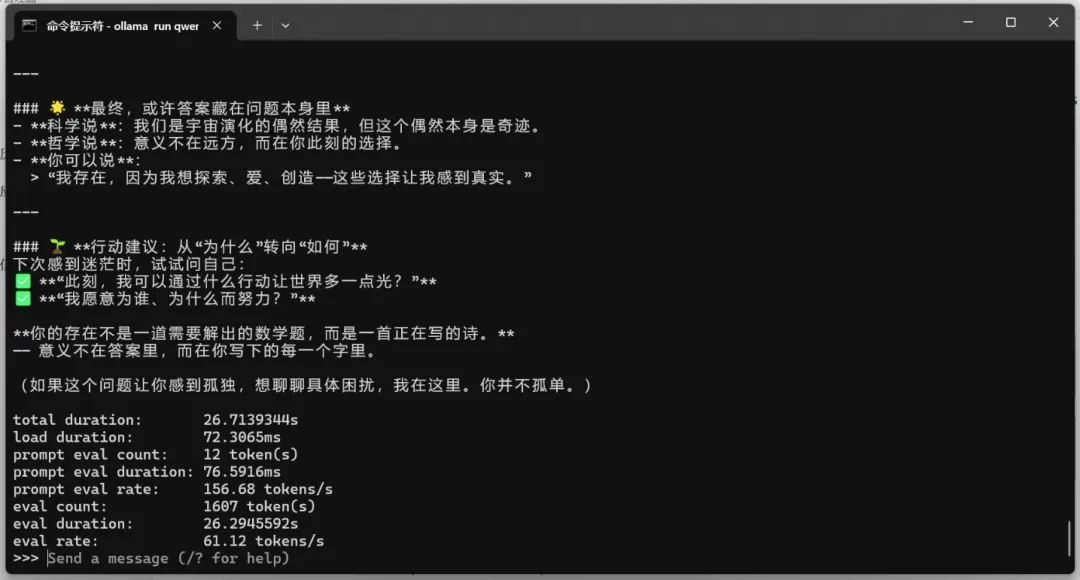
占用显存20.4GB
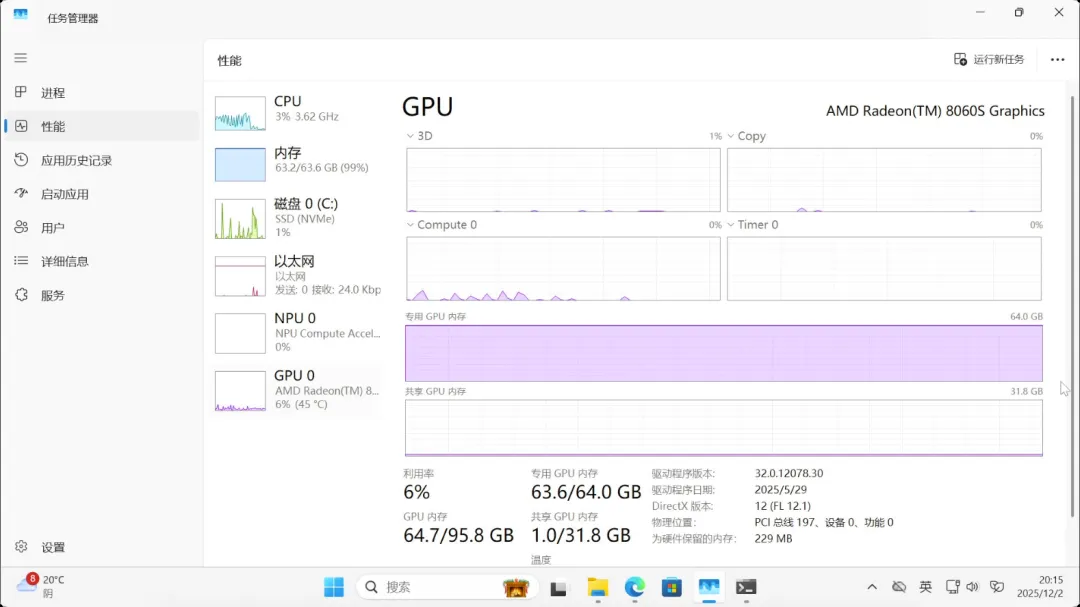
qwen3:235b-a22b(MoE模型)
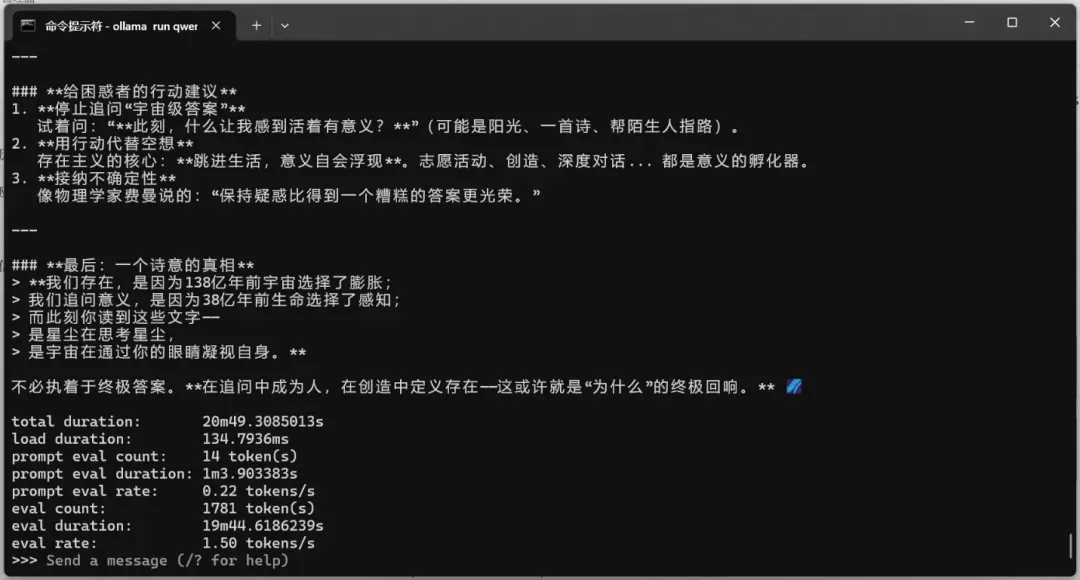
占用显存64.7GB
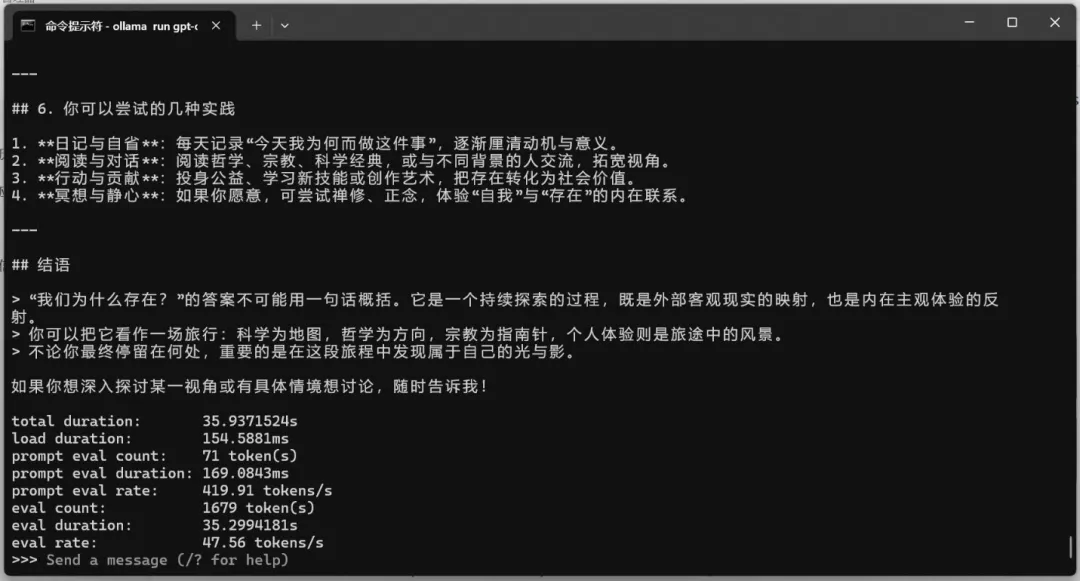
gpt-oss:20b(MoE模型)
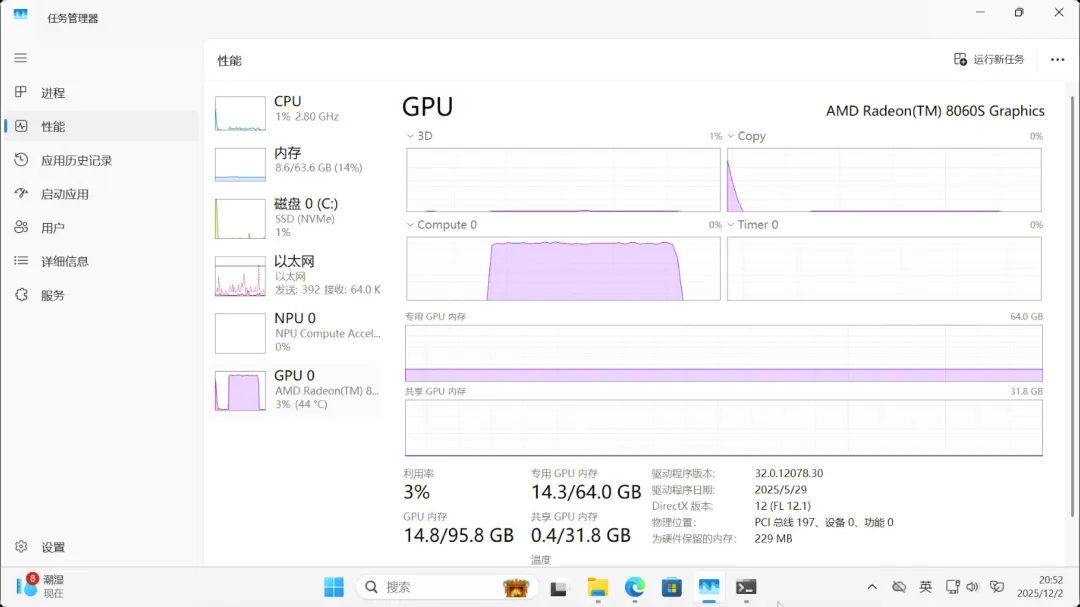
占用显存14.8GB
gpt-oss:120b(MoE模型)
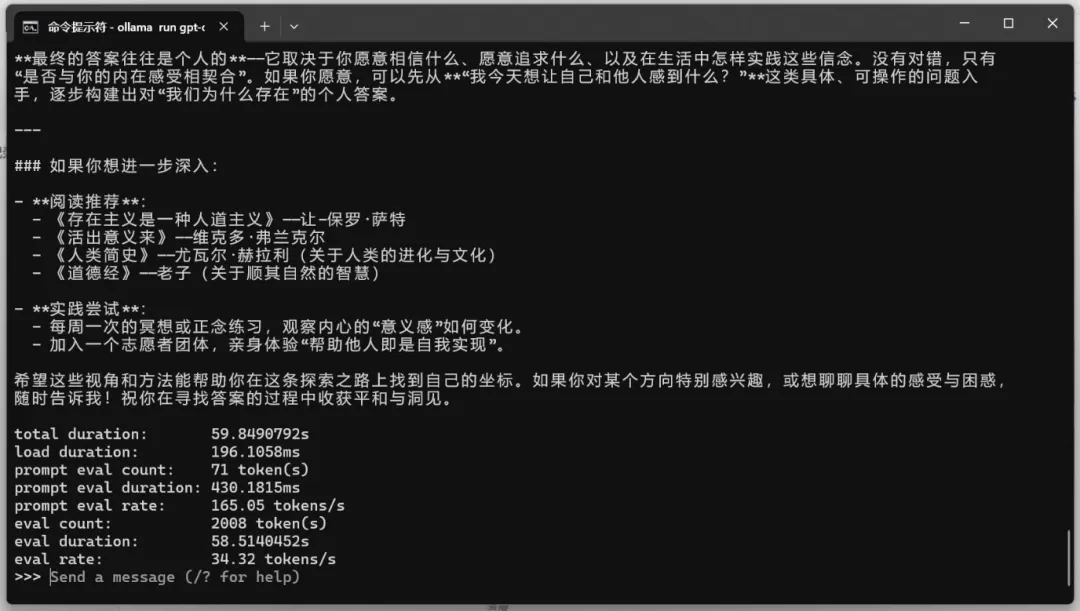
占用显存63.0GB
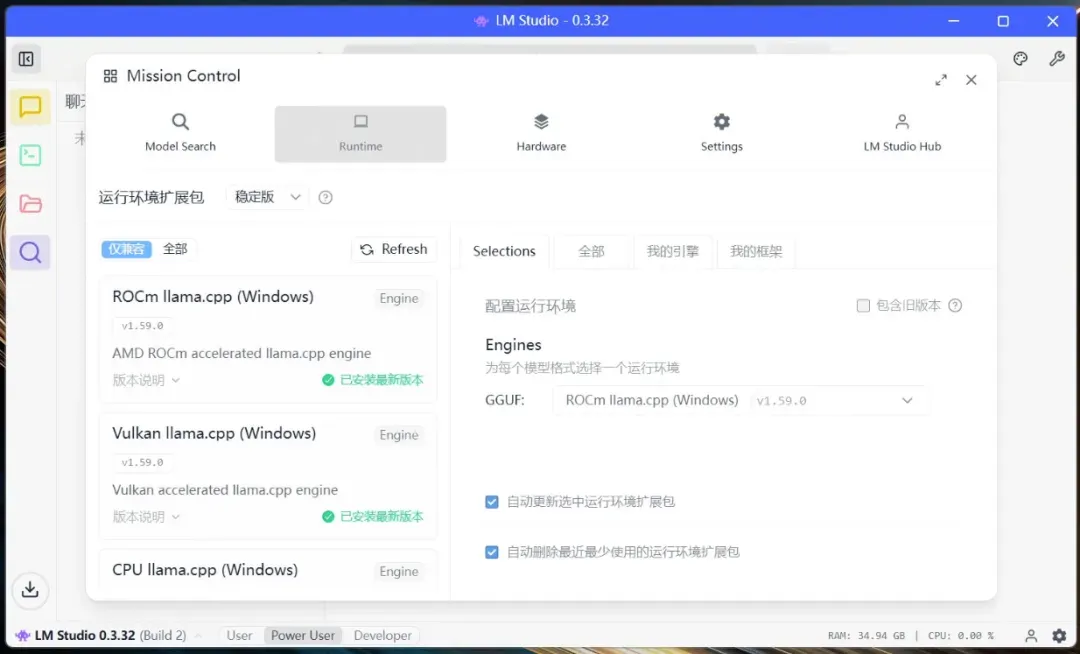
LM Studio图形界面测试
与Ollama相比,LM Studio提供了图形用户界面,即使是非技术背景的用户也能轻松使用大型语言模型。同时,它也保留了命令行界面,以满足技术人员的需求。
为了全面测试,我下载了相当数量的模型。不得不称赞其便捷性,从其他地方下载的GGUF格式模型直接放入指定目录,就能被识别和调用。
配置运行环境时选择ROCm,对于新出的模型,使用Vulkan环境可能会遇到一些问题。
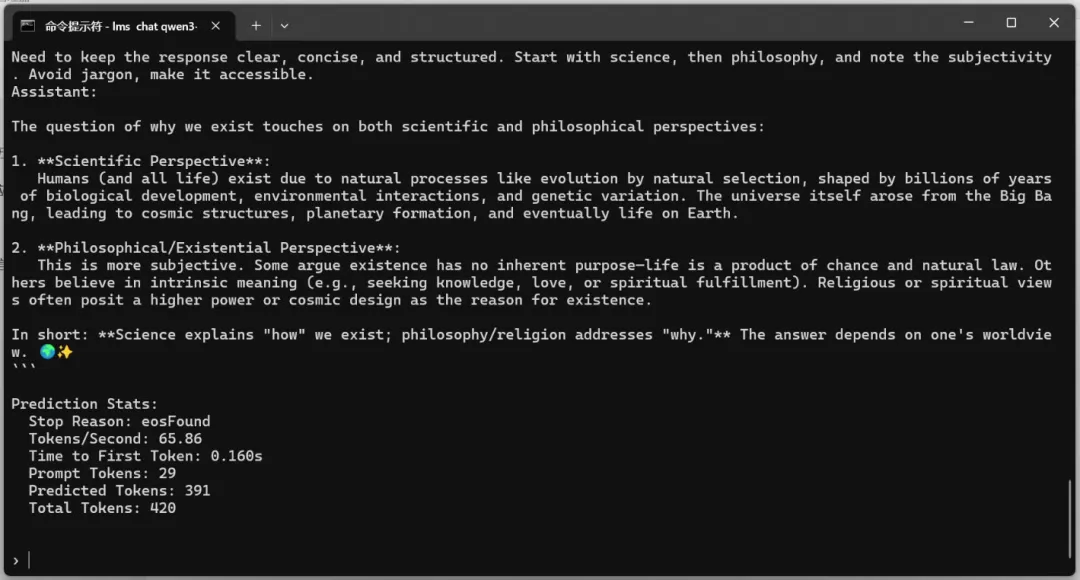
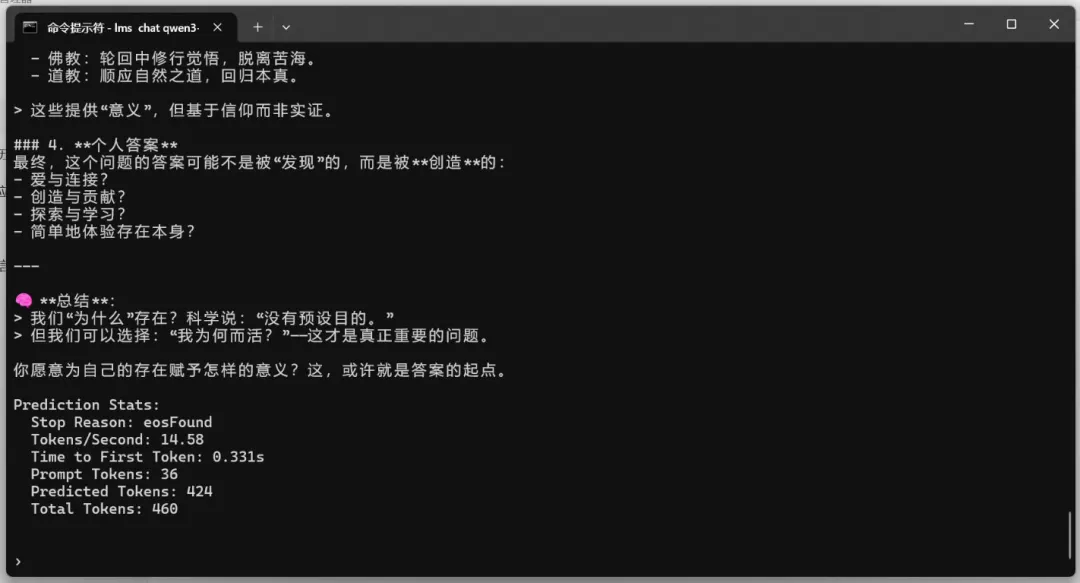
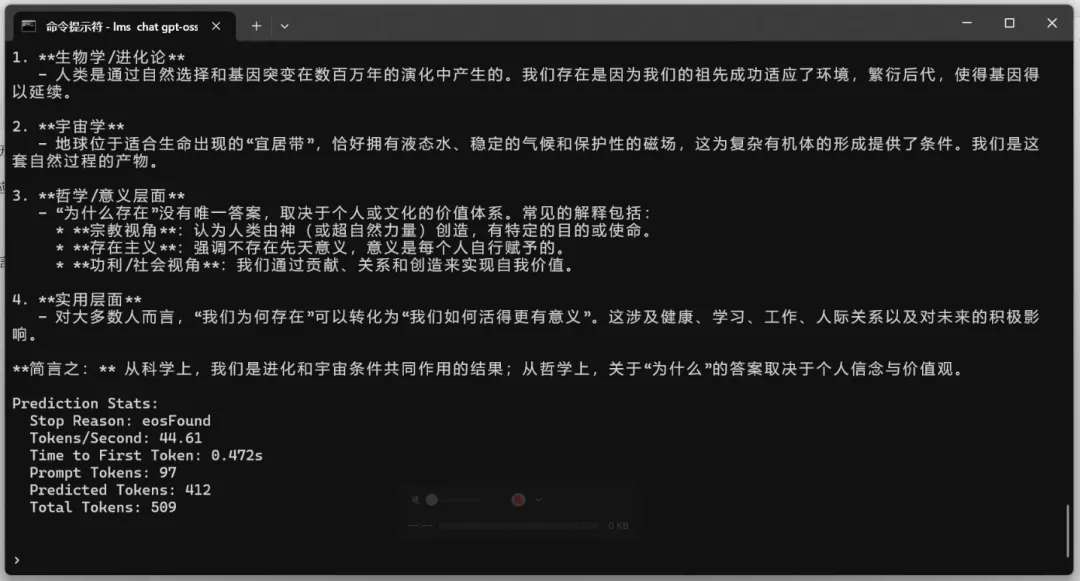
测试问题:我们为什么存在?
以下是整理后的测试数据表格,详细信息也可以参考对应图片。
| 模型名称 | 参数类型 | 显存需求(GB) | 推理速度(词/秒) | 运行状态 |
|---|---|---|---|---|
| qwen3:32b | dense | 19.0 | 65.86 | ✅ 正常 |
| deepseek-r1-distill-llama-70b | dense | 38.3 | 5.35 | ✅ 正常 |
| qwen3-30b-a3b | MoE | 15.7 | 65.86 | ✅ 正常 |
| qwen3-next-80b-a3b-instruct | MoE | 47.1 | 14.58 | ✅ 正常 |
| qwen3:235b-a22b | MoE | 63.9 | 5.51 | ⚠ 有问题 |
| gpt-oss-20b | MoE | 13.7 | 61.54 | ✅ 正常 |
| gpt-oss-120b | MoE | 61.7 | 44.61 | ✅ 正常 |
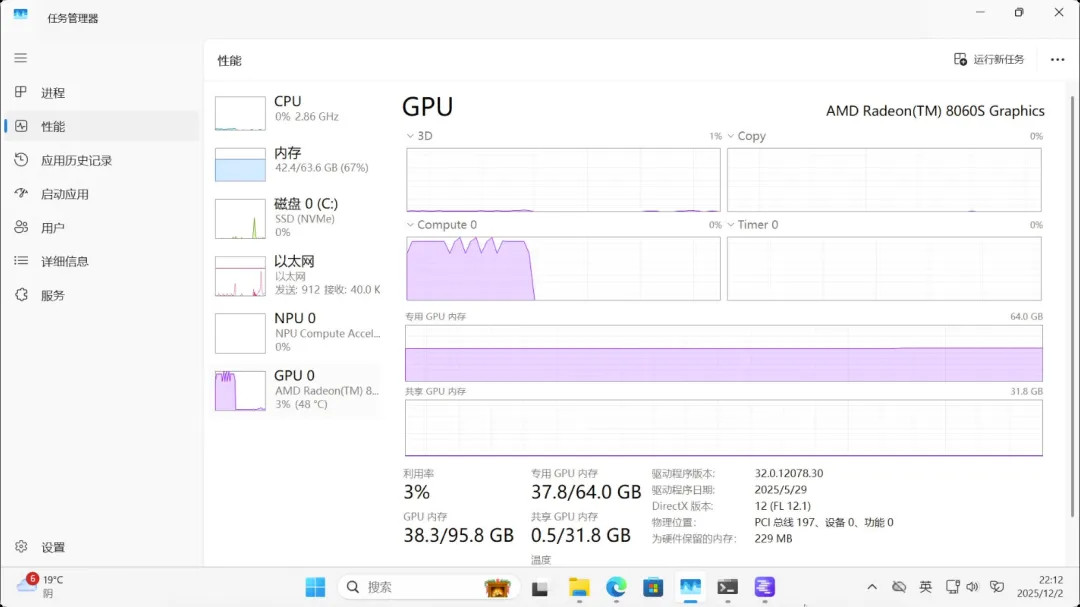
qwen3-32b(dense模型)
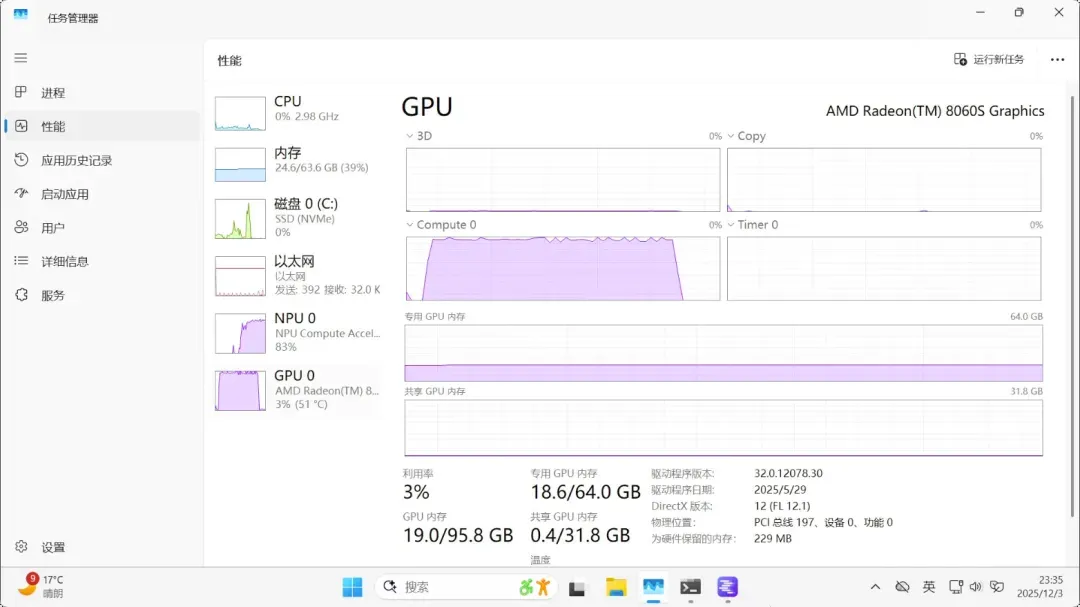
占用显存19.0GB
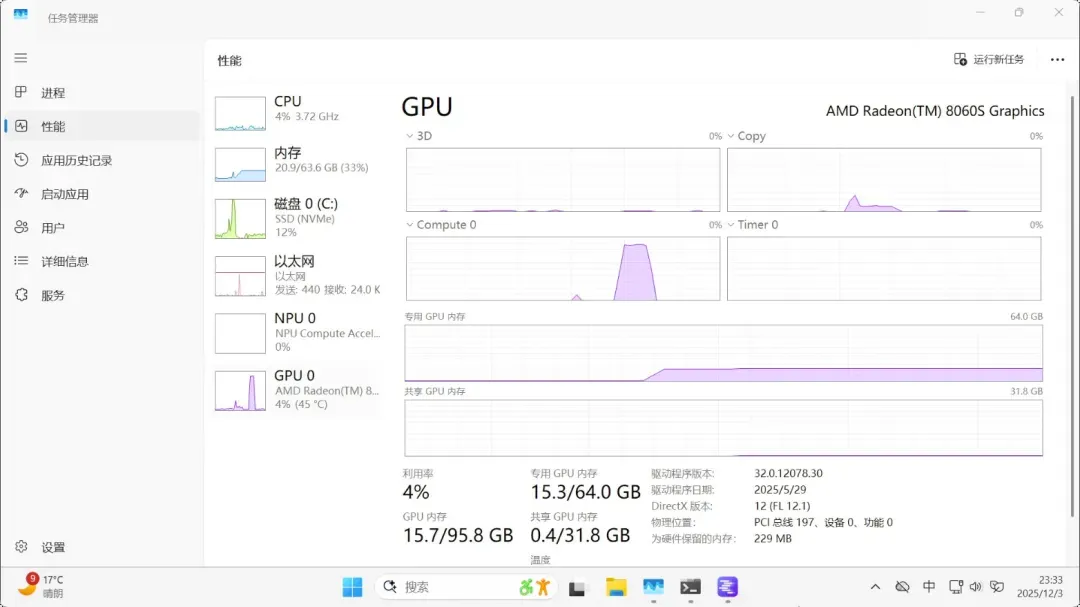
deepseek-r1-distill-llama-70b(dense模型)
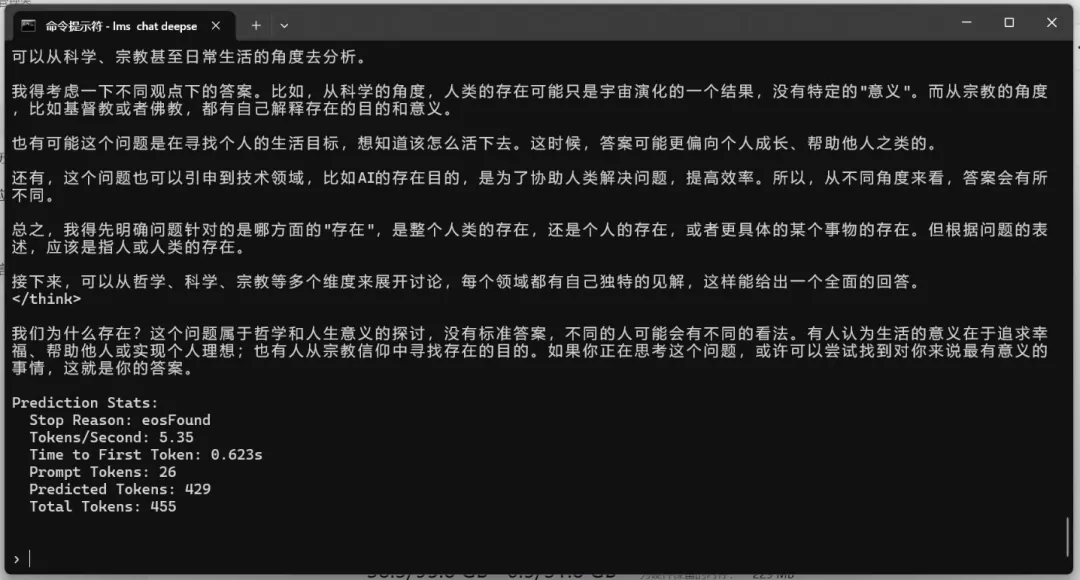
占用显存38.3GB
qwen3-30b-a3b(MoE模型)
占用显存15.7GB
qwen3-next-80b-a3b-instruct(MoE模型)
占用显存47.1GB
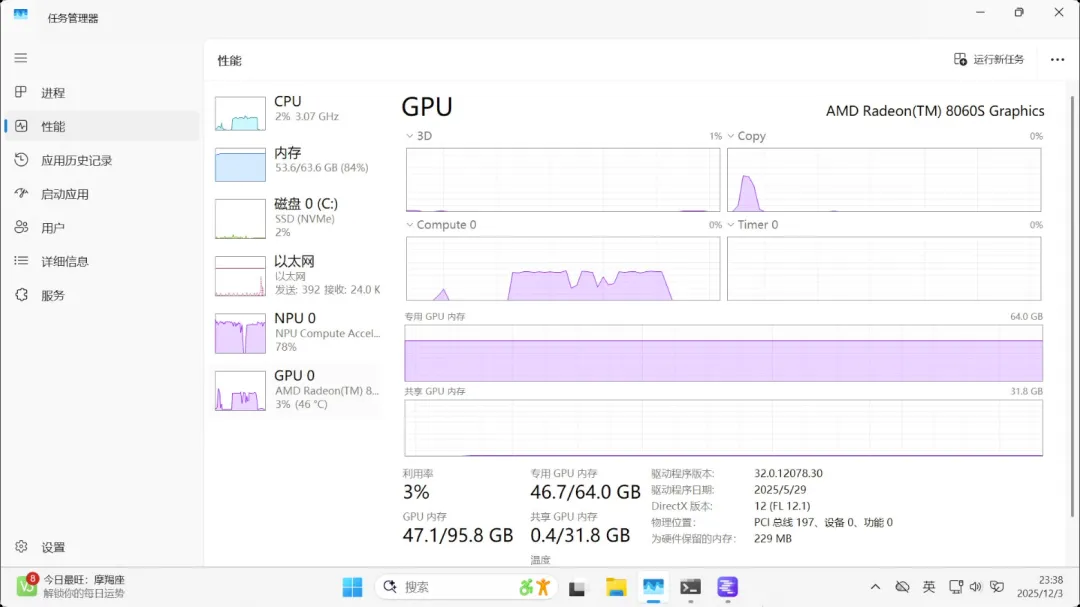
qwen3-235b-a22b(MoE模型)
占用显存63.9GB
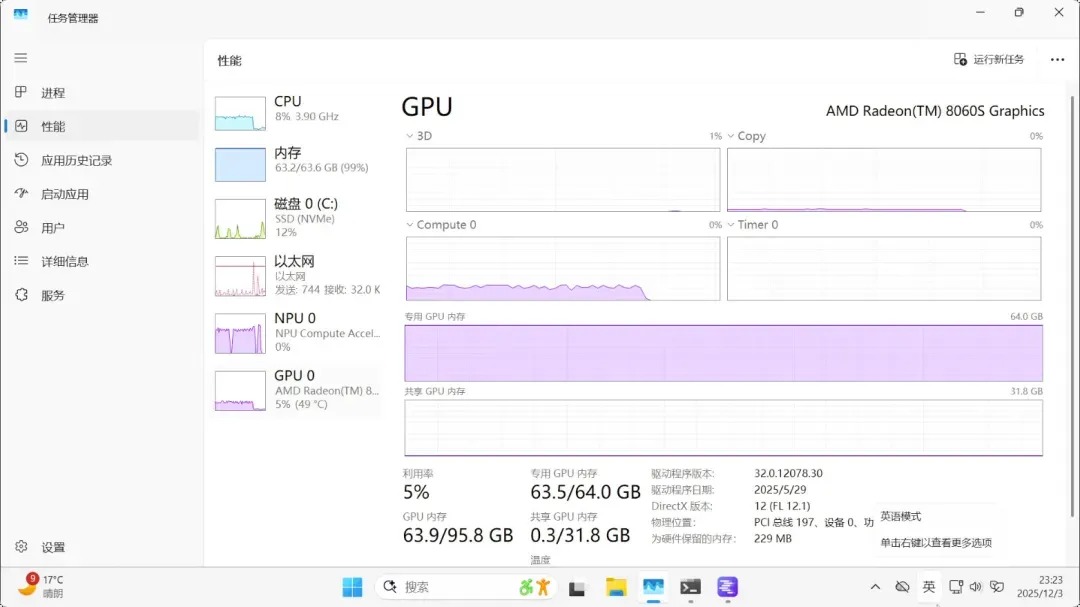
gpt-oss-20b(MoE模型)
占用显存13.7GB
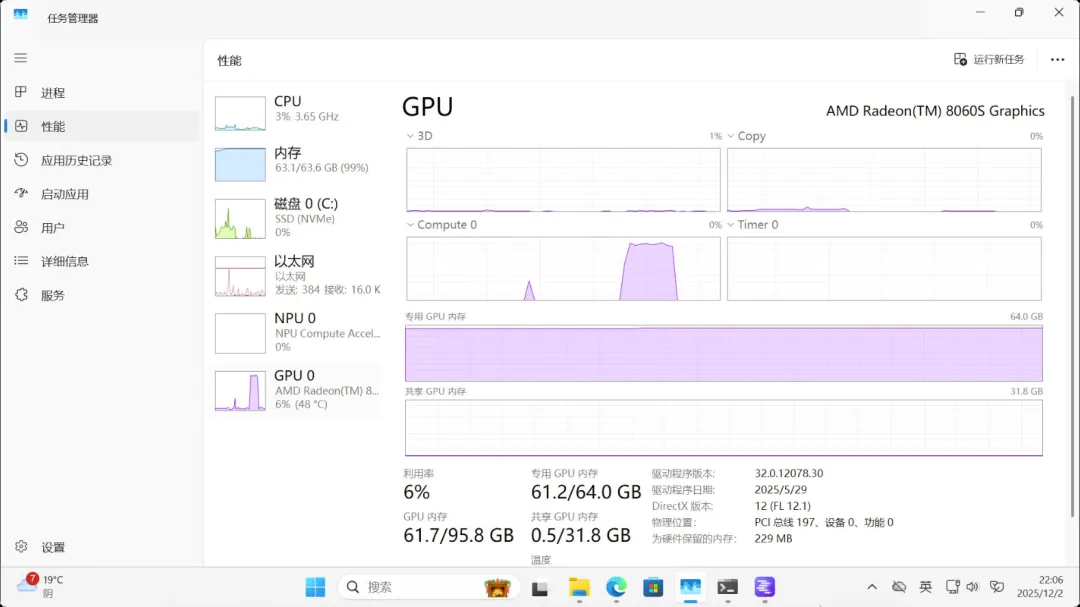
gpt-oss-120b(MoE模型)
占用显存61.7GB
Amuse创意生成工具体验
这款工具针对AMD硬件进行了深度优化,能够充分利用AMD的CPU、GPU和NPU,实现快速、私密且高质量的创意内容输出。

在模型管理界面,可以看到提供了不少模型,而且下载过程相对便捷(但需要注意网络连接稳定性)。
我也下载了多个不同规模的模型进行效果测试。需要提前说明的是,不清楚是模型本身的问题还是我的提示词不够精准,生成的图像效果与当前主流模型相比存在一定差距,不太令人满意。

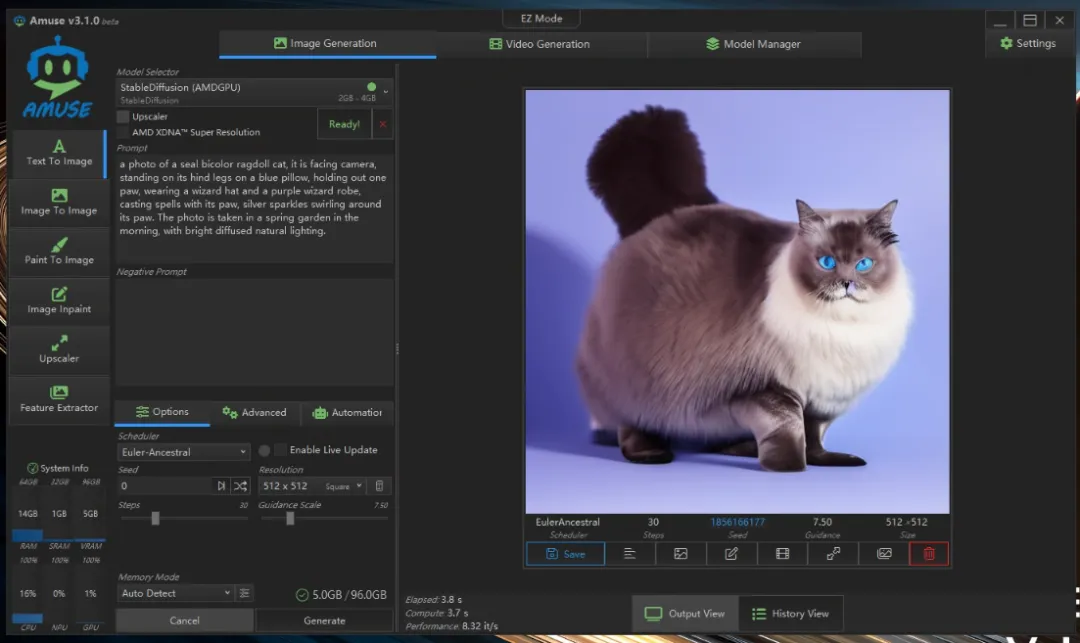
stable-diffusion-1.5_io32_amdgpu(所需内存2GB-4GB),这个模型体积较小,生成速度很快,仅用了3.7秒。但生成效果比较一般,我尝试了多次才得到一张相对像样的图片。
a photo of a seal bicolor ragdoll cat, it is facing camera, standing on its hind legs on a blue pillow, holding out one paw, wearing a wizard hat and a purple wizard robe, casting spells with its paw, silver sparkles swirling around its paw. The photo is taken in a spring garden in the morning, with bright diffused natural lighting.
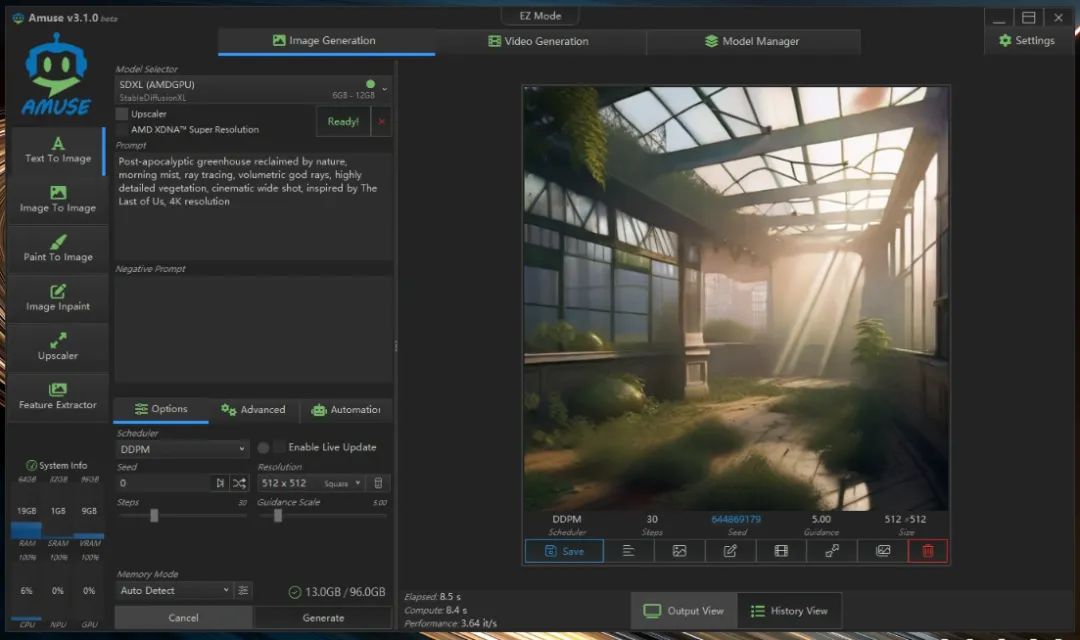
stable-diffusion-xl-1.0_io32_amdgpu(所需内存6GB-12GB),生成速度也很快,8.4秒就输出了图像,但效果依然不太理想。
Post-apocalyptic greenhouse reclaimed by nature, morning mist, ray tracing, volumetric god rays, highly detailed vegetation, cinematic wide shot, inspired by The Last of Us, 4K resolution
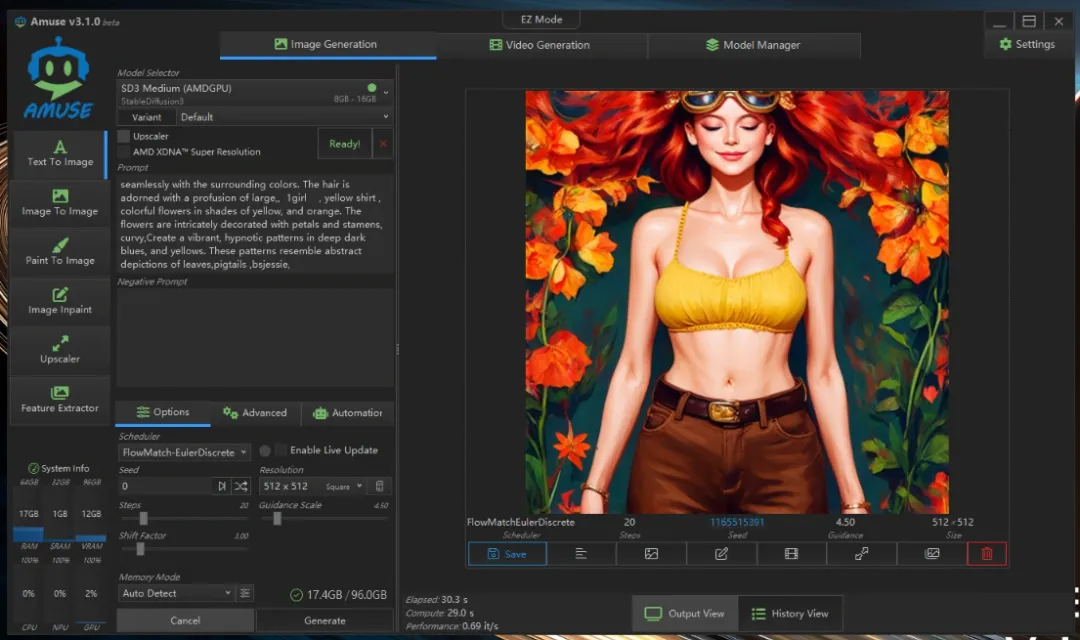
stable-diffusion-3-medium_amdgpu(所需内存8GB-16GB),切换到SD3模型后效果好了很多,虽然生成时间增加到29秒,但图像质量更加稳定可靠。
pink, and blacks, smile, skinny, purples, highly detailed digital artwork image depicting the profile of a woman in a surreal, huge breast, goggles on headwear, red hair , pretty,sexy pose, greens, and appear to float around her head.The background is a rich tapestry of swirling, dreamlike setting. The woman's face is turned slightly to the right, hat , her eyes are closed, big thighs, big ass,large breast, wavy hair falls down her back and shoulders,brown pants , and her lips are slightly parted. Her skin is a soft, giving the artwork a sense of movement and depth., pale pink tone, vines, belt, and her long, and other organic elements, interspersed with splashes of bright reds, FluffyLewdsStyle, look at viewer , blending seamlessly with the surrounding colors. The hair is adorned with a profusion of large,, 1girl , yellow shirt , colorful flowers in shades of yellow, and orange. The flowers are intricately decorated with petals and stamens, curvy,Create a vibrant, hypnotic patterns in deep dark blues, and yellows. These patterns resemble abstract depictions of leaves,pigtails ,bsjessie,
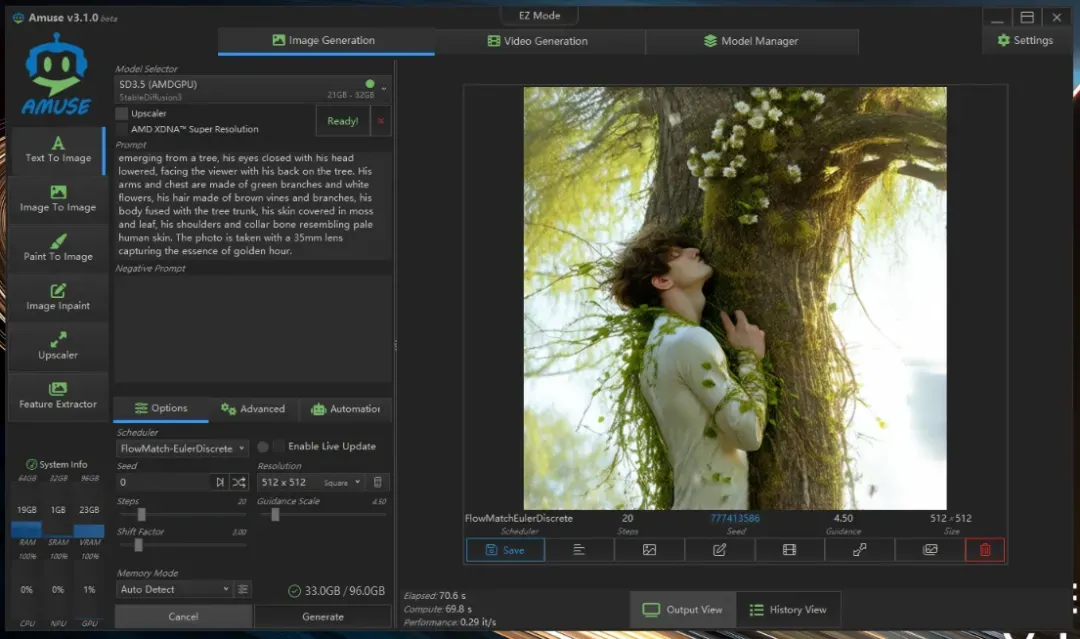
stable-diffusion-3.5-large_amdgpu(所需内存21GB-32GB),这个模型已经非常庞大,生成时间也达到了69.8秒。
a cinematic front view photo of a slim white male dryad emerging from a tree, his eyes closed with his head lowered, facing the viewer with his back on the tree. His arms and chest are made of green branches and white flowers, his hair made of brown vines and branches, his body fused with the tree trunk, his skin covered in moss and leaf, his shoulders and collar bone resembling pale human skin. The photo is taken with a 35mm lens capturing the essence of golden hour.
stable-diffusion-3.5-large-turbo_amdgpu(所需内存21GB-32GB),这个模型无法正常运行,似乎因为体积过大而报错(如果调整显存分配,给内存多分配一些资源应该可以解决)。
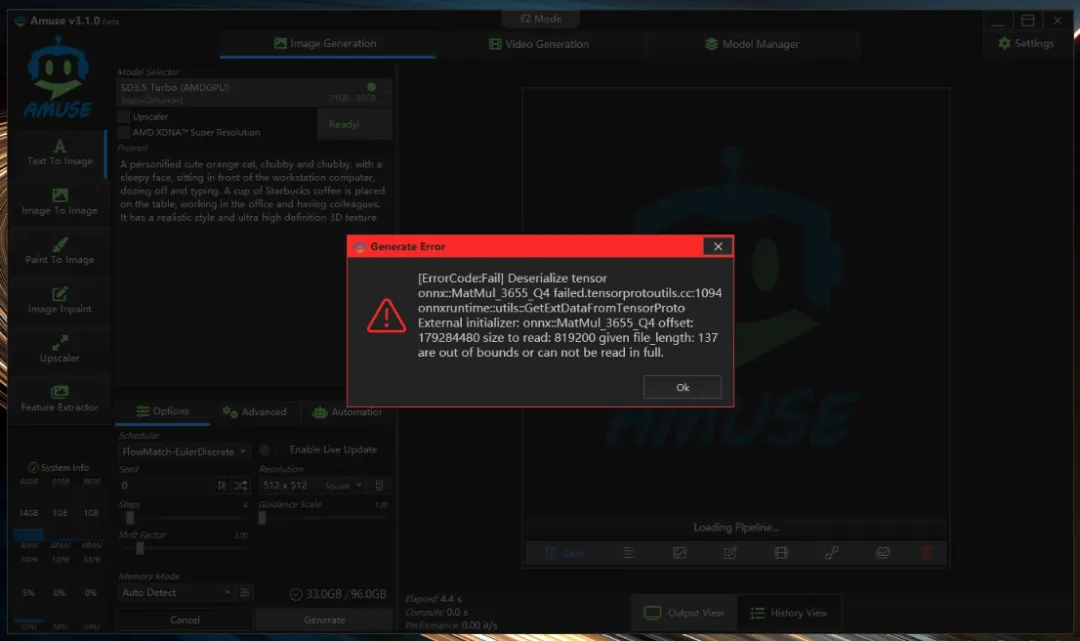
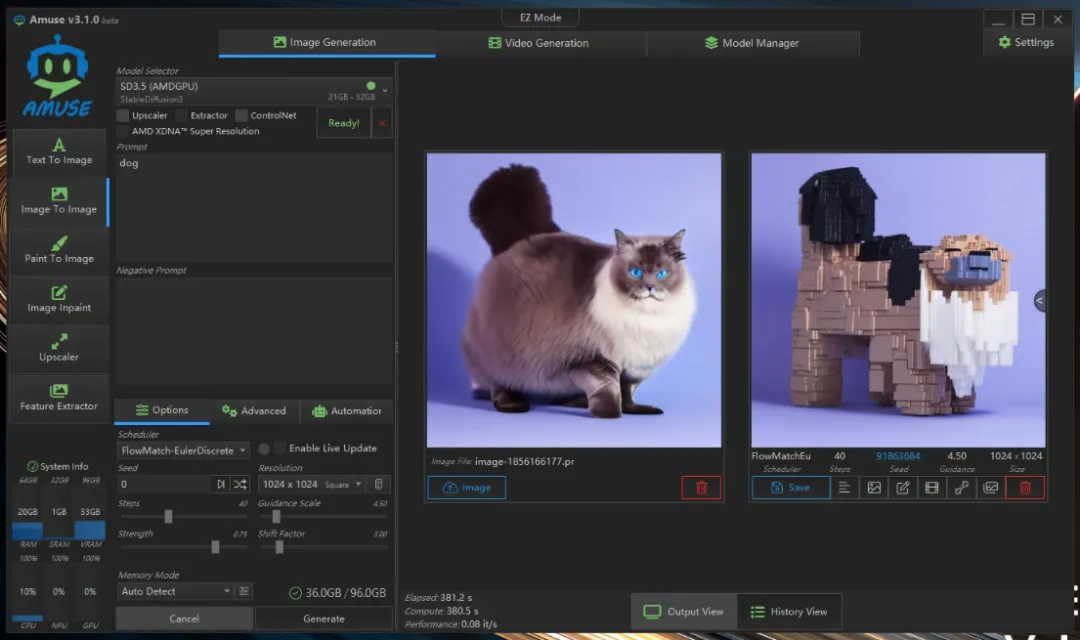
这款工具还包含许多其他功能,例如图生图、草图生图等。
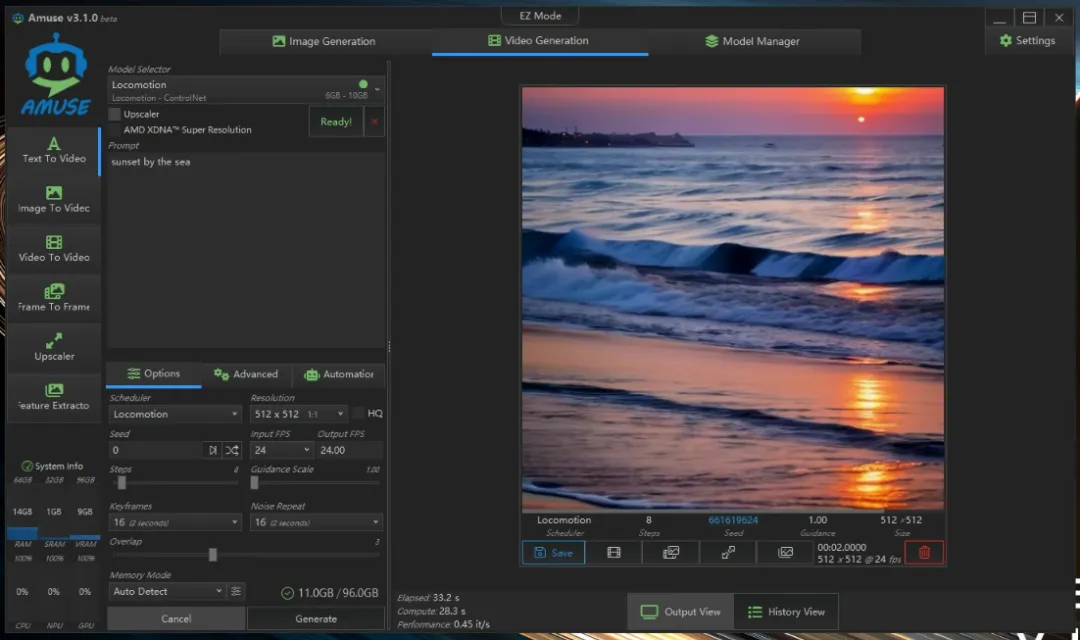
除了生成图片,视频生成功能也没有问题,生成速度很快,大约28秒左右即可完成。
使用不同的模型,生成的视频风格也会有所差异。
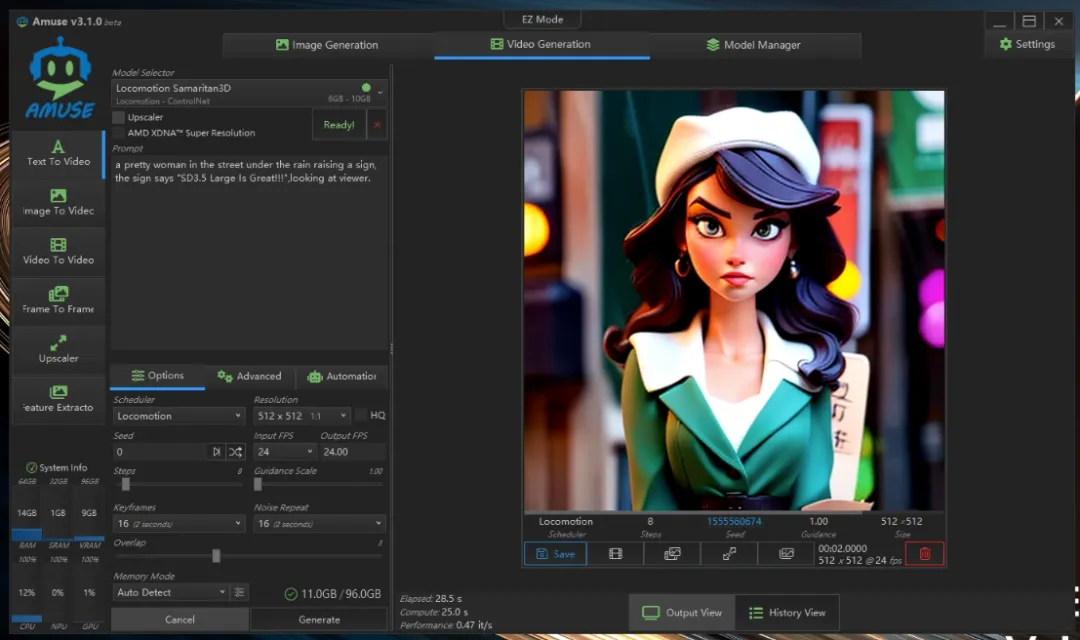
不清楚是输入图片的问题,还是我的提示词不够准确,生成的视频效果有些诡异。
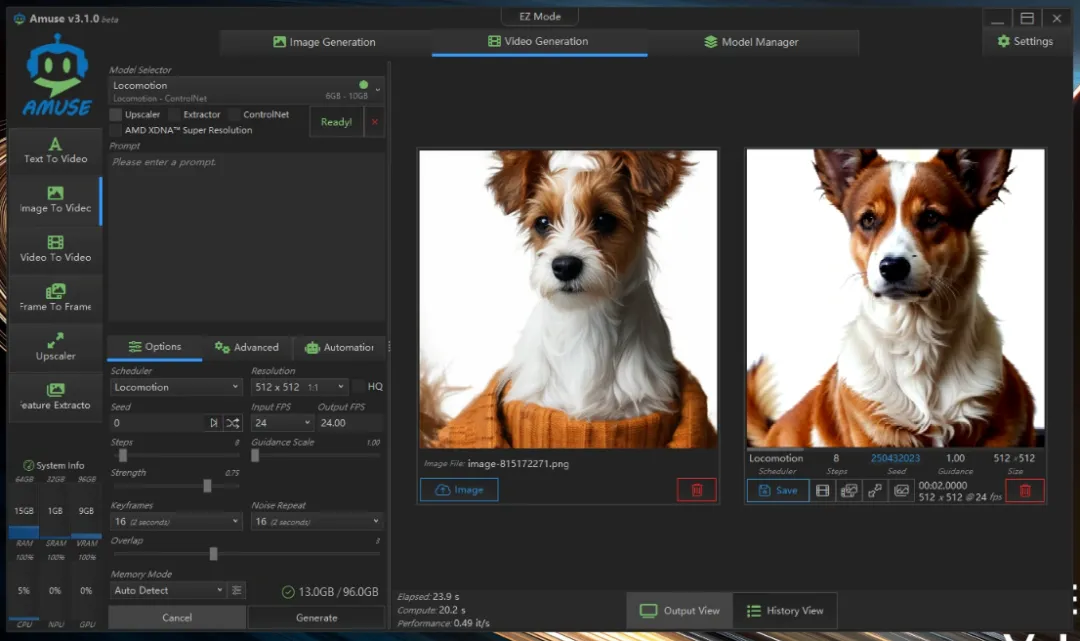
绘世启动器绘画测试
我个人使用较多的是“绘世启动器”这款AI绘画工具,它有两个版本:一个是NVIDIA专用版,这里测试的是AMD优化版本。
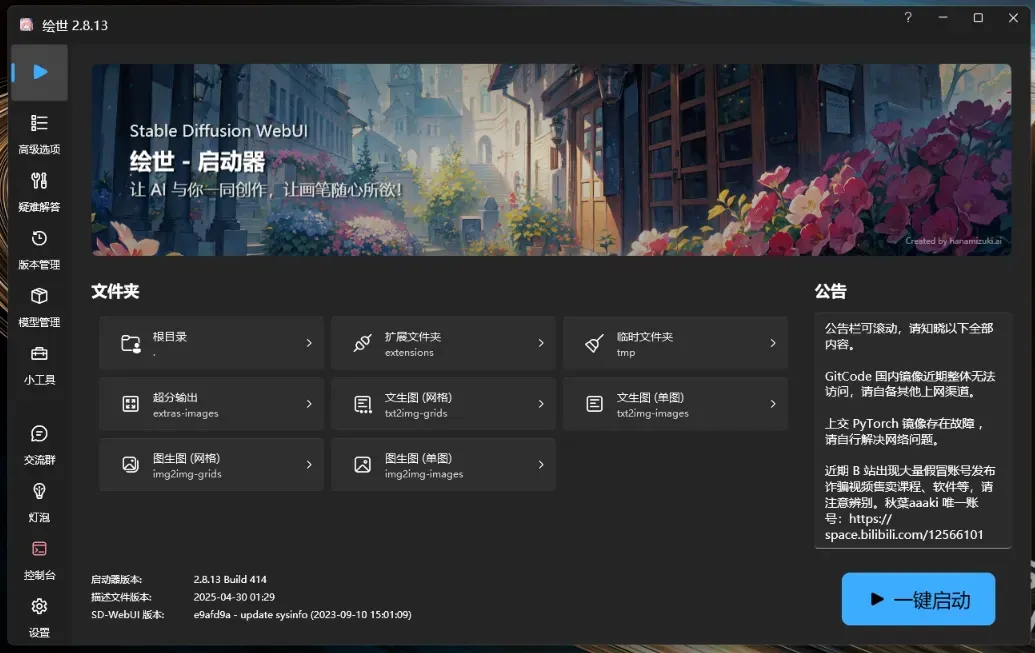
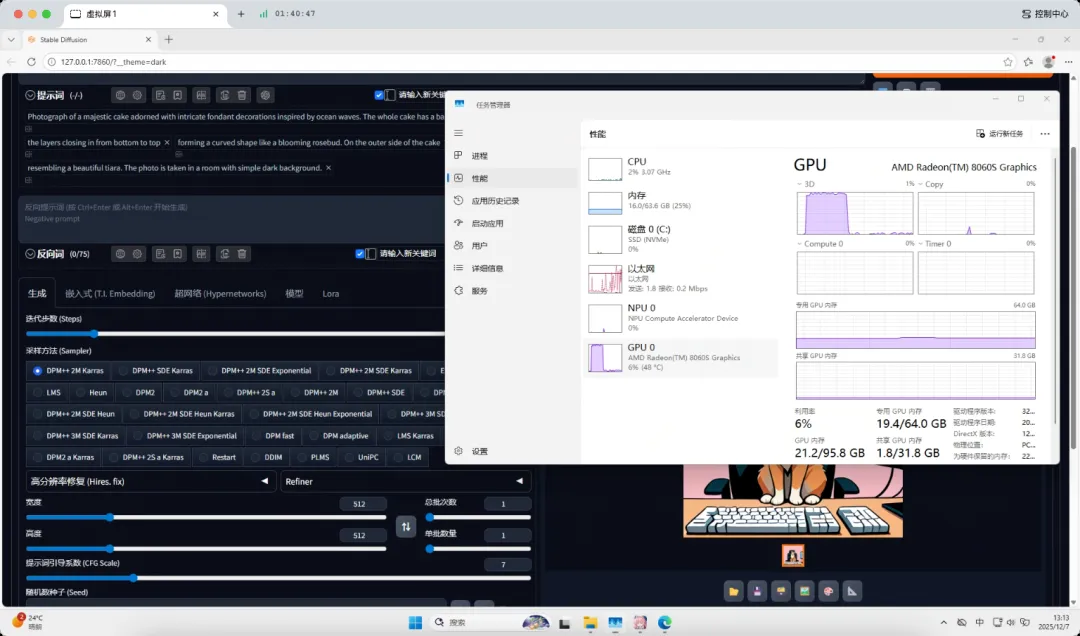
在高级选项中,系统能够正常识别到Radeon 8060S核显。
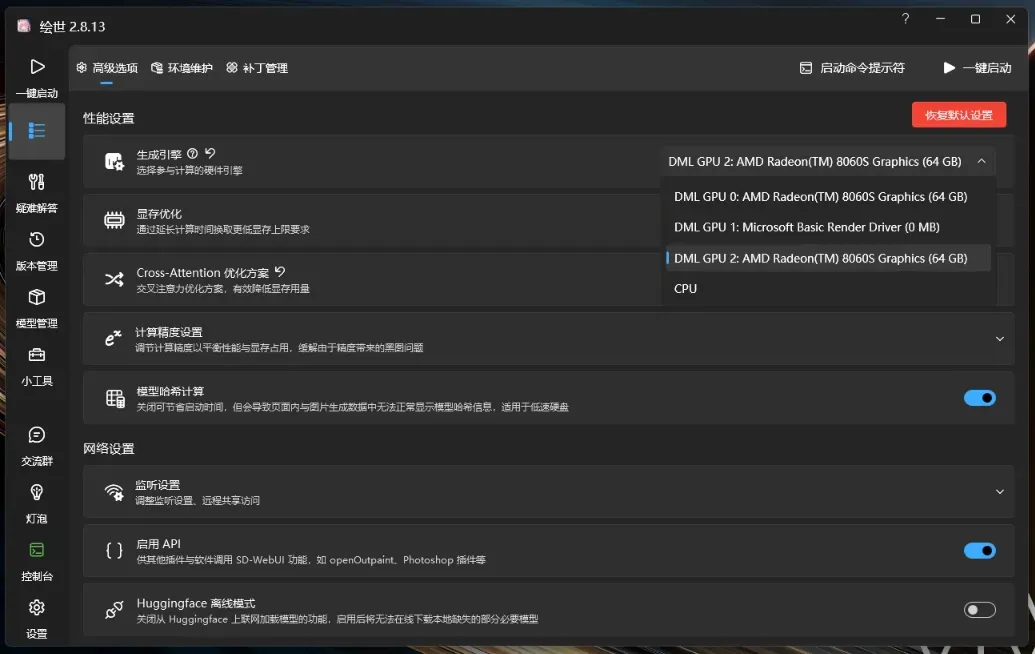
模型管理功能非常便捷,可以轻松导入.safetensors格式的模型文件。
在任务管理器中可以看到GPU被正常调用,以下生成的图像均使用默认配置。
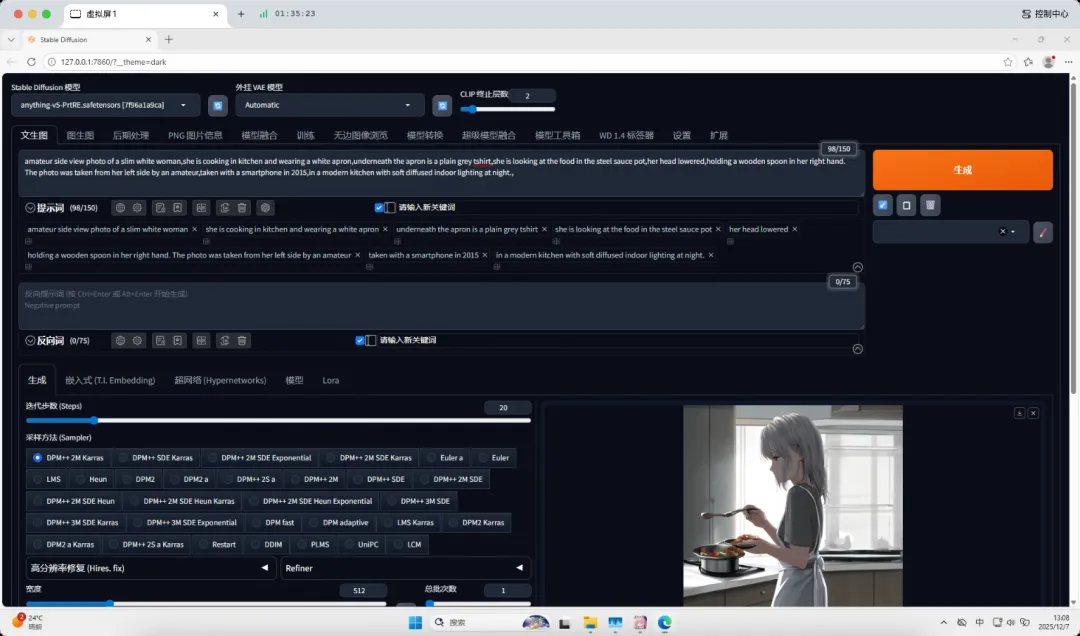
anything-v5-PrtRE.safetensors(模型大小:1.98GB,生成速度:12.7秒)
amateur side view photo of a slim white woman,she is cooking in kitchen and wearing a white apron,underneath the apron is a plain grey tshirt,she is looking at the food in the steel sauce pot,her head lowered,holding a wooden spoon in her right hand. The photo was taken from her left side by an amateur,taken with a smartphone in 2015,in a modern kitchen with soft diffused indoor lighting at night.
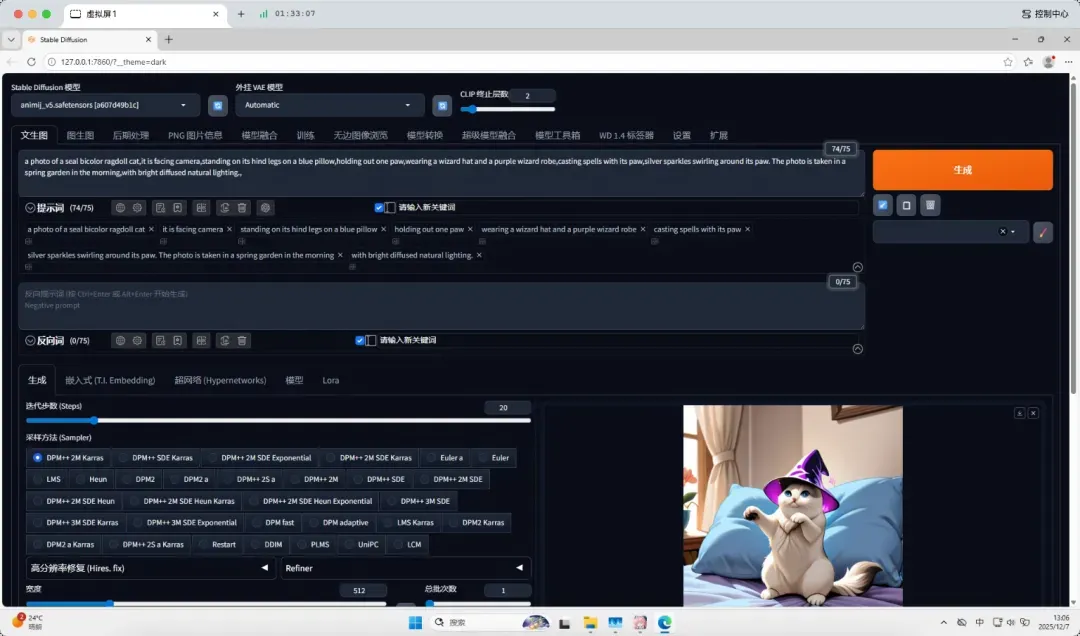
animij_v5.safetensors(模型大小:6.91GB,生成速度:21.4秒)
a photo of a seal bicolor ragdoll cat, it is facing camera, standing on its hind legs on a blue pillow, holding out one paw, wearing a wizard hat and a purple wizard robe, casting spells with its paw, silver sparkles swirling around its paw. The photo is taken in a spring garden in the morning, with bright diffused natural lighting.
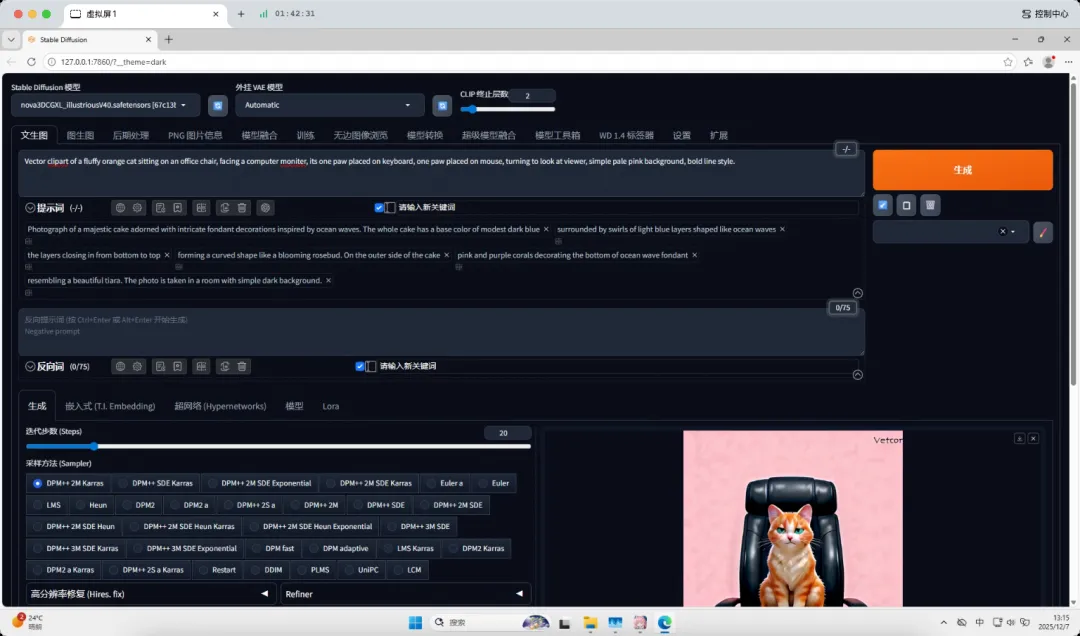
nova3DCGXL_illustriousV40.safetensors(模型大小:6.46GB,生成速度:21.9秒)
Vector clipart of a fluffy orange cat sitting on an office chair, facing a computer moniter, its one paw placed on keyboard, one paw placed on mouse, turning to look at viewer, simple pale pink background, bold line style.
游戏性能:热门游戏流畅度测试
作为AMD史上最强的集成显卡,Radeon 8060S的理论跑分超越了桌面版RTX 4060独显,不进行游戏测试实在说不过去。不过我平时玩游戏不多,因此仅下载了《PUBG》和《绝区零》这两款游戏进行临时测试。
《绝地求生》实战帧率
当年游戏刚发售时花了79元购买的《绝地求生》,一直没怎么玩。家里的旧电脑性能太弱,运行起来卡顿如PPT,只在网吧体验过几次。
在游戏设置中将画质选项全部调至超高,但显示器分辨率限制在1080P。
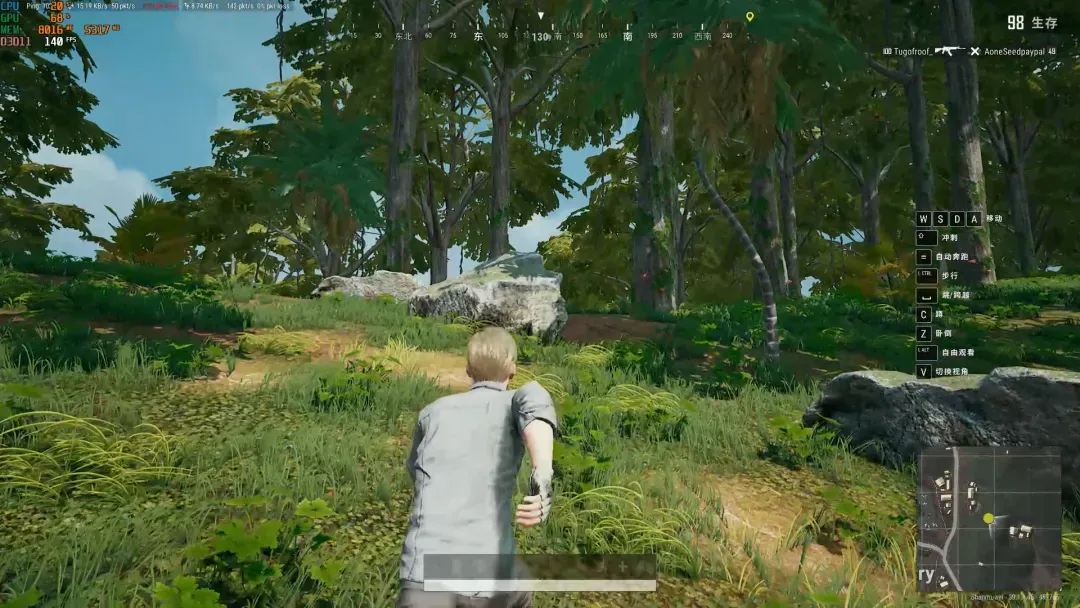
在飞机跳伞场景中,画面流畅无明显卡顿:CPU占用率约22%,GPU占用率约40%,帧率稳定在71FPS左右。

落地后跑图时,核显压力有所增加,但帧率也相应提升:CPU占用率约20%,GPU占用率约68%,帧率维持在140FPS附近。
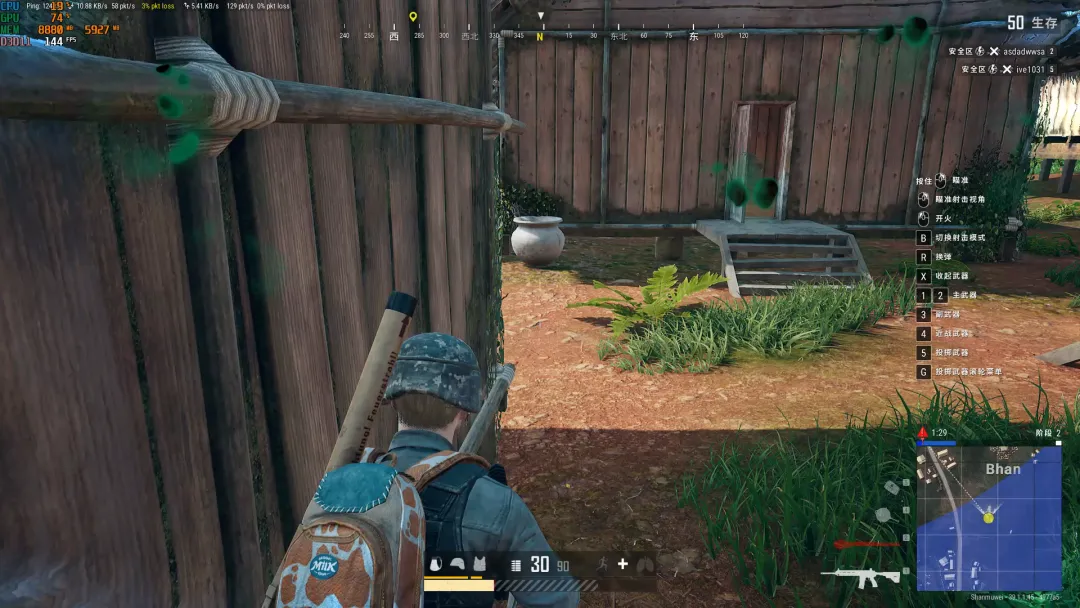
整个游戏过程中帧率都非常稳定,没有出现突然掉帧或卡顿的情况:CPU占用率约19%,GPU占用率约74%,帧率保持在144FPS左右。
《绝区零》PC端体验
这款游戏我平时主要在手机上玩,这次终于可以在电脑上体验其画面效果了。

先将渲染精度、阴影质量和特效等级等配置全部调高,显示分辨率设置为1080P。
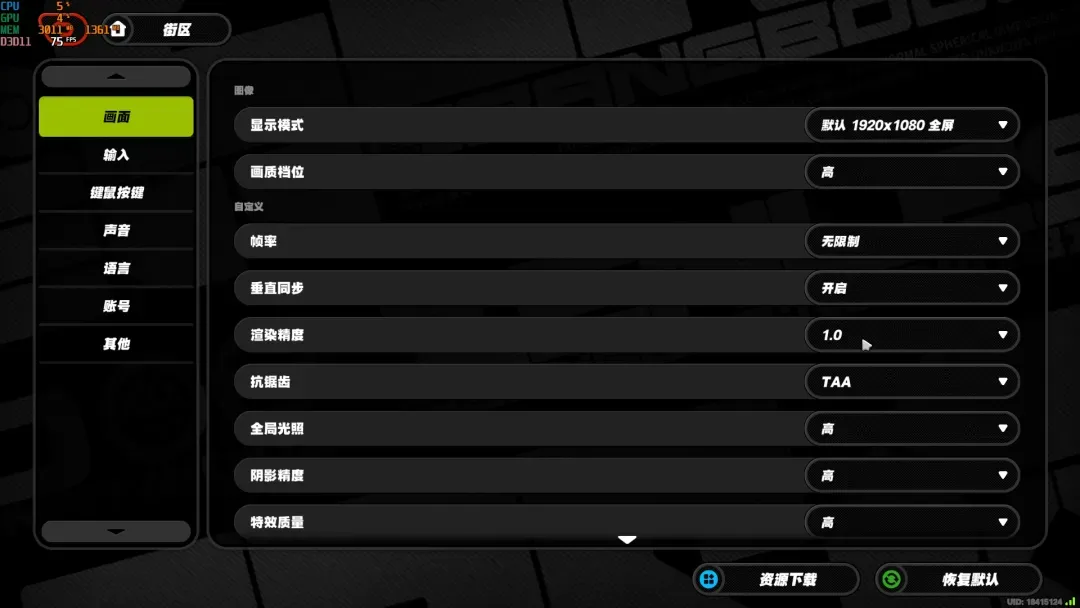
在光影广场场景中跑图:CPU占用率12%,GPU占用率32%,帧率稳定在75FPS。

在澄辉坪场景中跑图:CPU占用率14%,GPU占用率37%,帧率同样维持在75FPS。

战斗场景中帧率基本都能稳定在75FPS,偶尔有小幅波动,最低会降至60FPS,整体游玩过程依然流畅。

扩展功能:BIOS设置与系统兼容性
最后简要说明如何在BIOS中划分96GB显存;同时,出于对NAS系统的执着,我也专门安装了NAS系统以测试其兼容性表现。
BIOS显存分配设置
默认情况下GPU显存为64GB,要划分96GB需要进入BIOS进行设置。
开机时按“F2”键进入BIOS界面,默认已经是性能模式,如果不是可以手动修改。
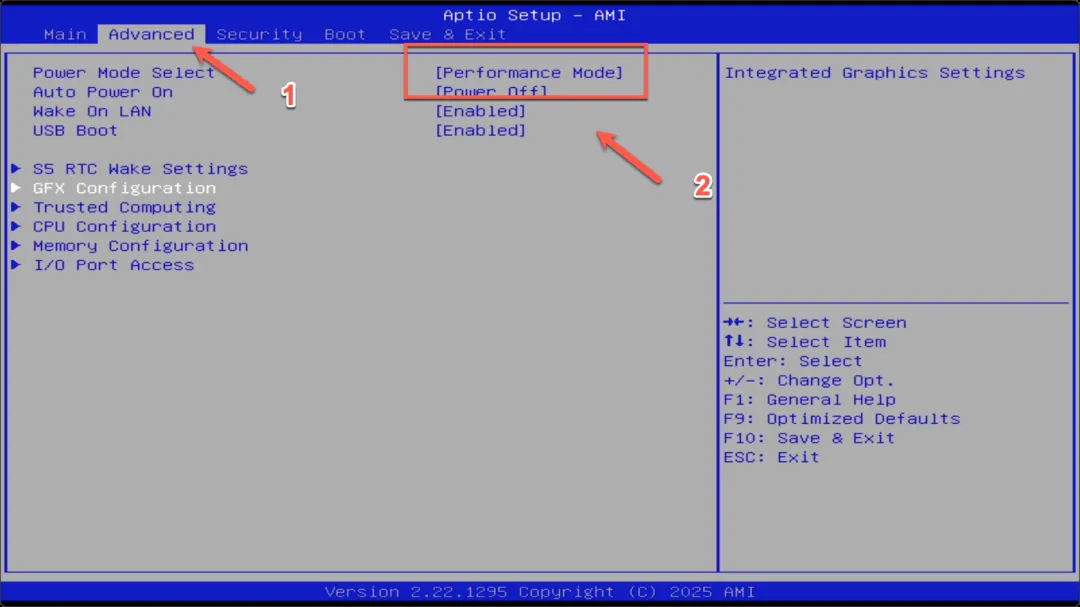
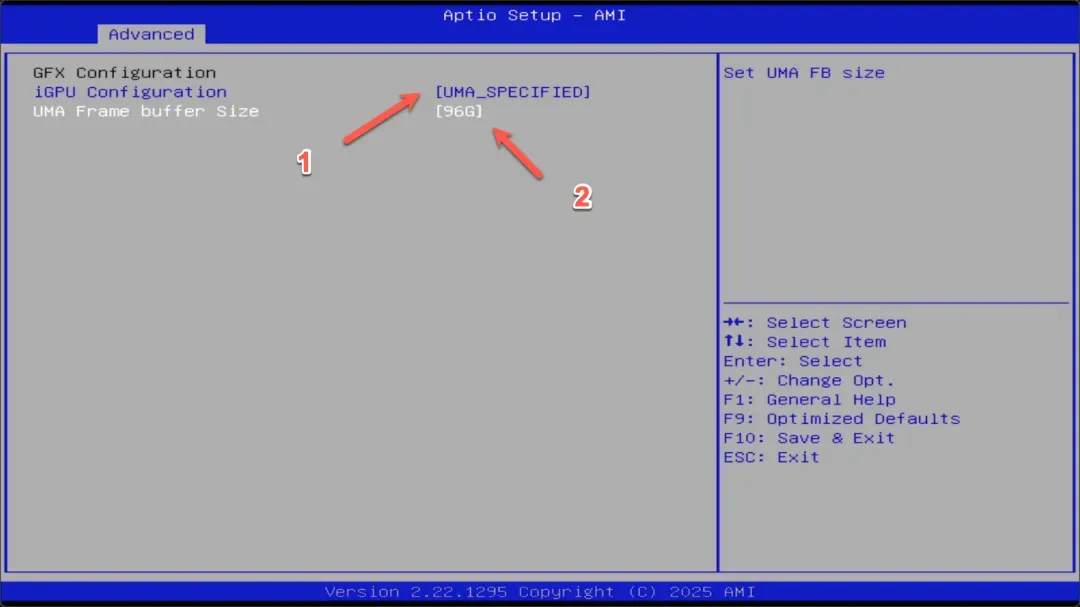
切换到“Advanced”高级选项,即可找到“GFX Configuration”图形配置选项。
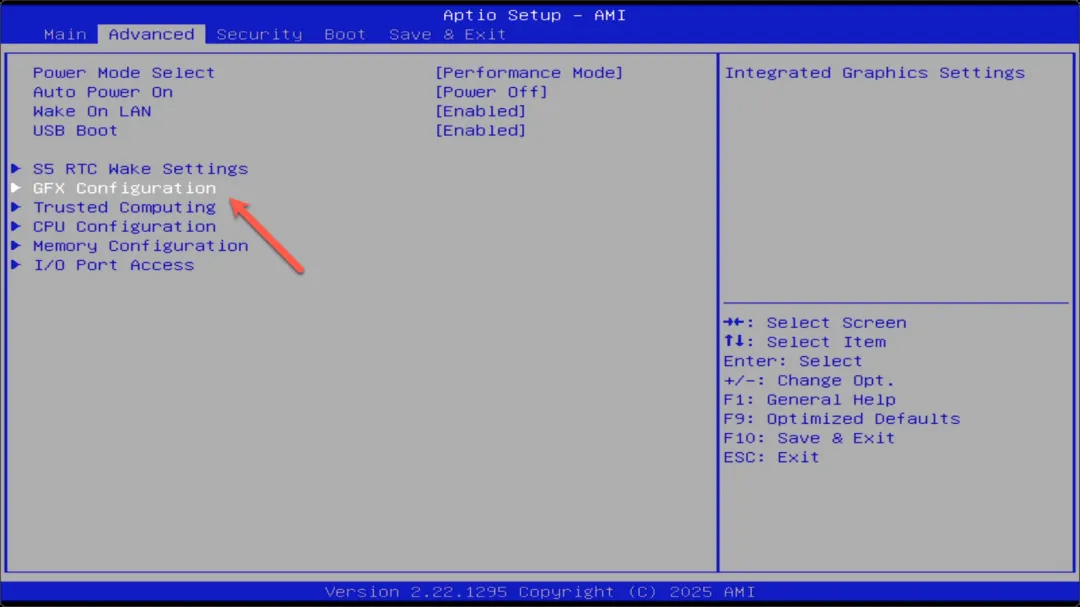
首先将上方选项设置为“UMA_SPECIFIED”,然后将下方数值调整为96G,即可将96GB的内存分配给核显作为显存使用。
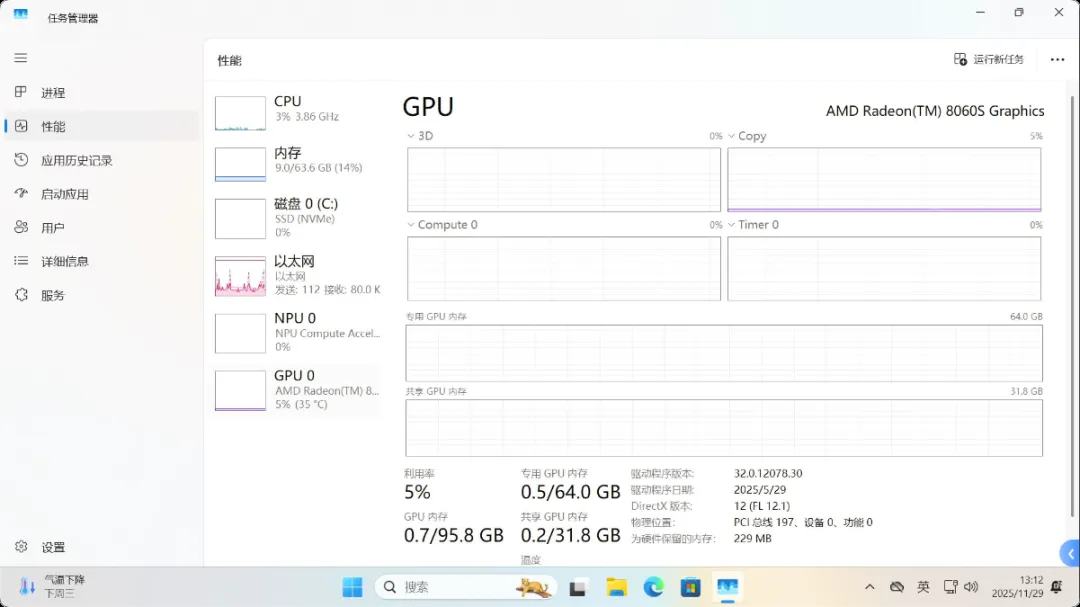
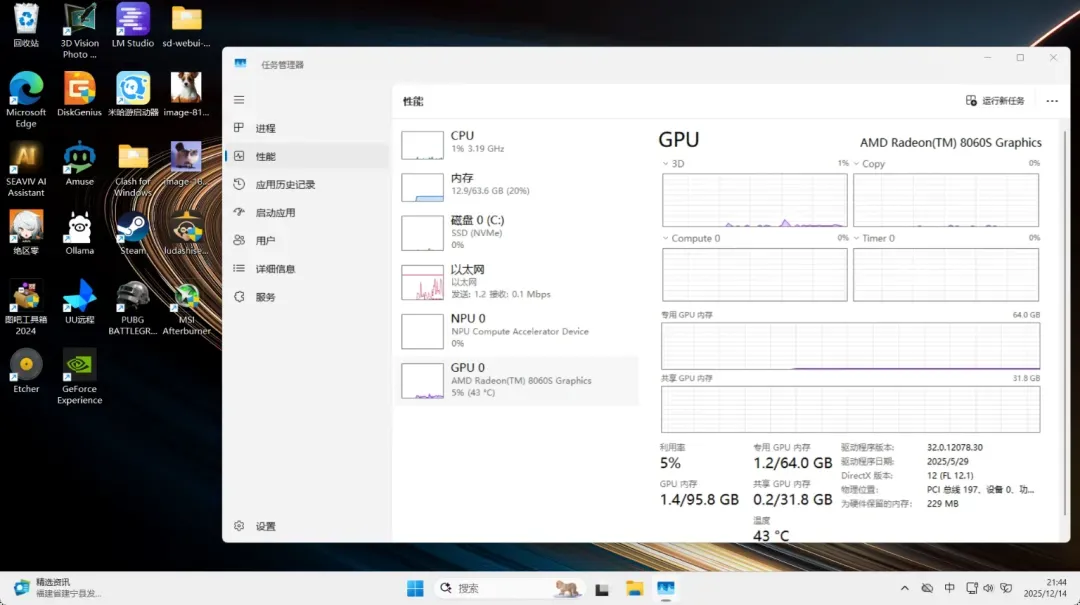
重启后打开任务管理器,可以看到GPU内存已变为112GB,其中专用内存为96GB。
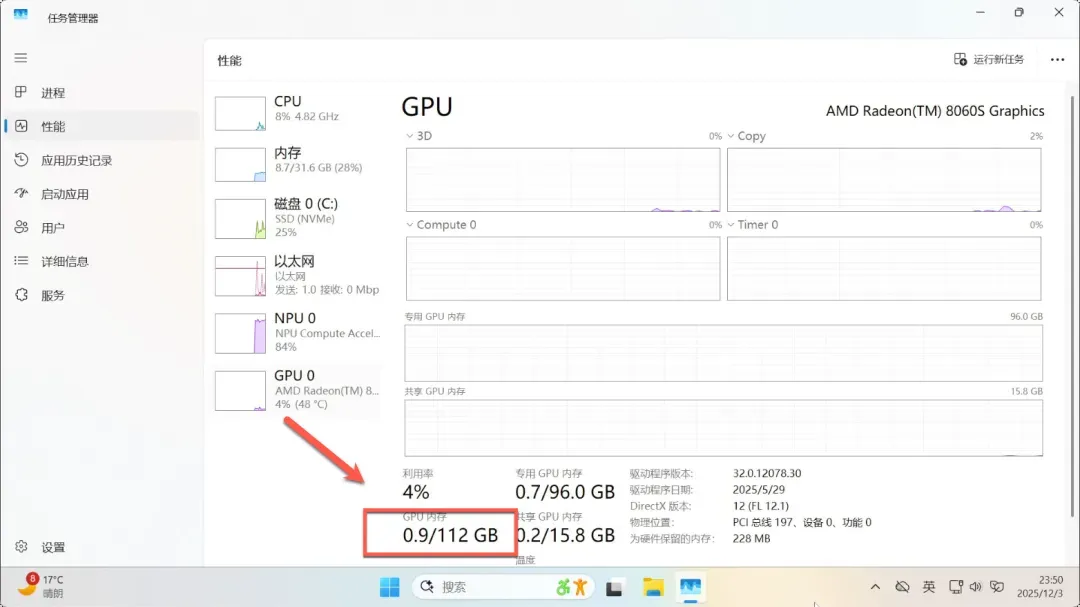
需要注意的是,虽然显存设置为96GB,但仍可能遇到某些应用不兼容的情况。我看到网上有用户成功运行了235B参数的模型,但对我来说,能流畅运行70B模型已经足够,生成速度也可以接受,因此没有继续深入调试。
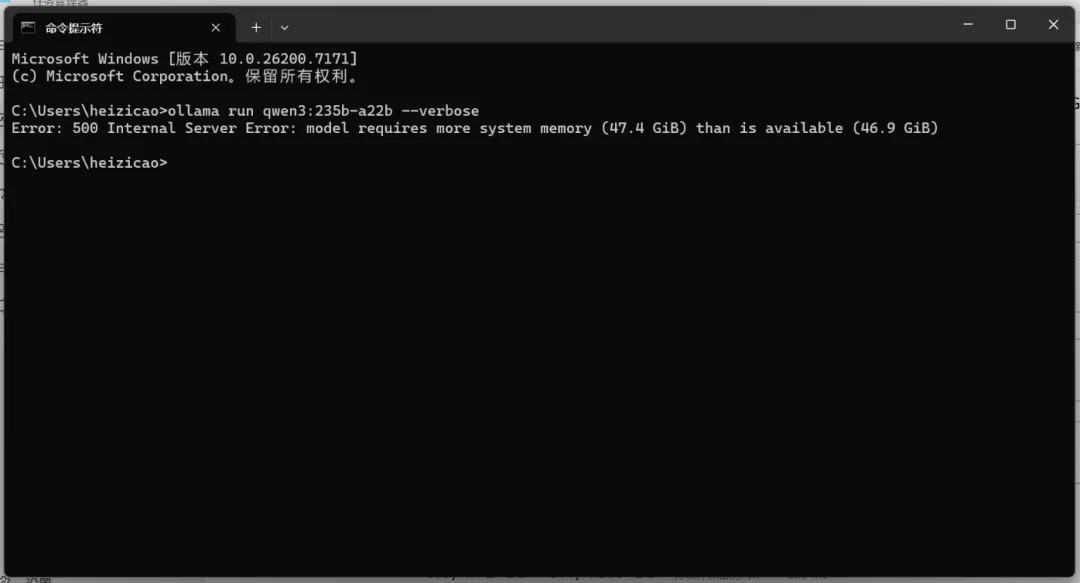
运行Ollama时似乎遇到了问题并报错,但我注意到网上有人成功运行,不清楚是需要修改特定配置还是使用特定版本。
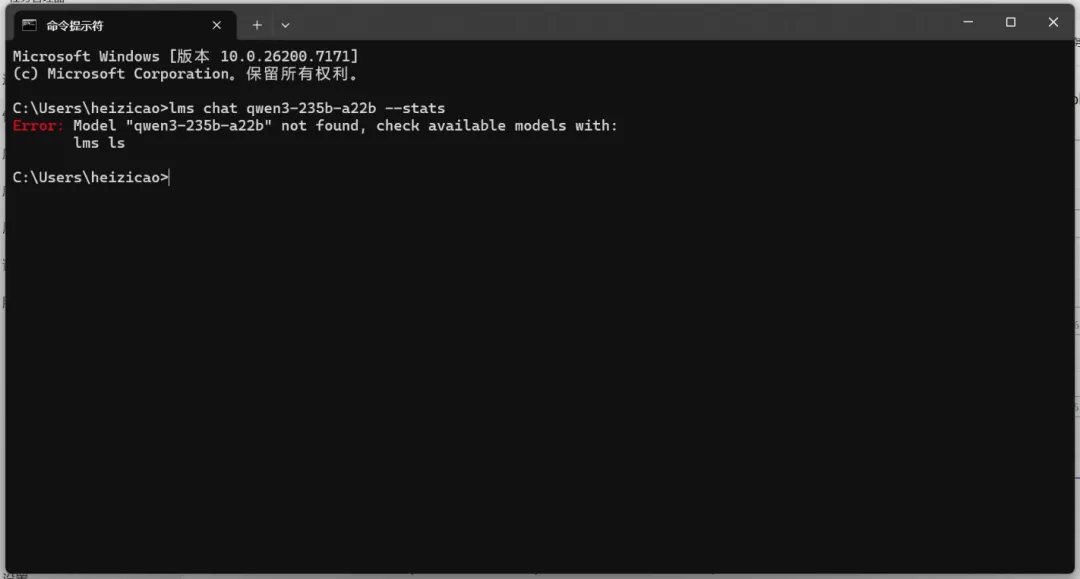
运行LM Studio时也遇到了类似问题,尝试更换不同的GGUF运行环境后,依然报错提示找不到模型。
UNRAID系统兼容性测试
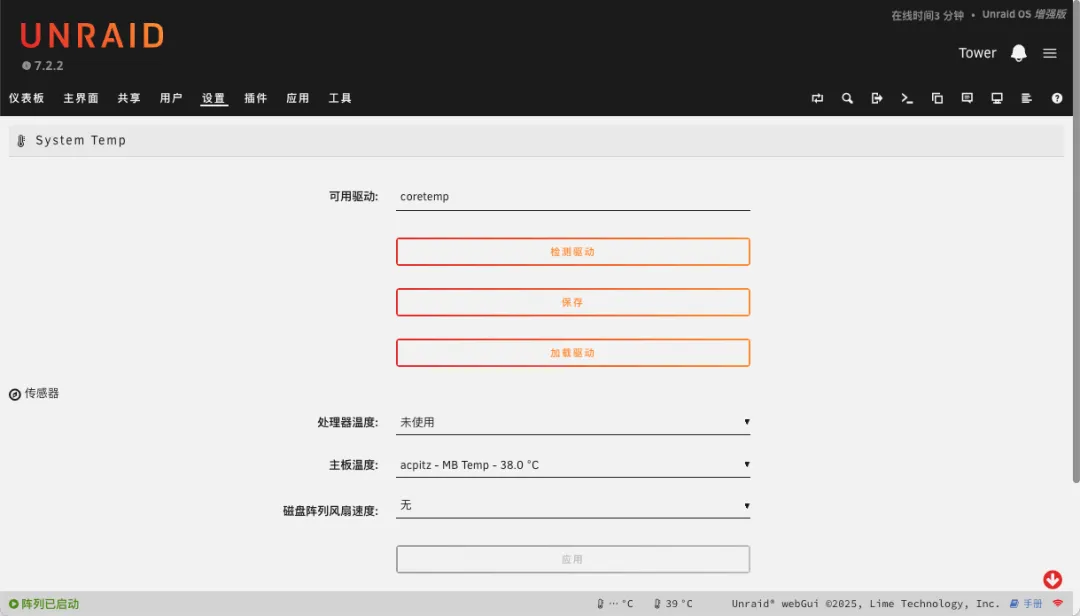
如果安装UNRAID系统,会遇到较多兼容性问题,这主要是因为硬件太新,相关驱动尚未完善适配。
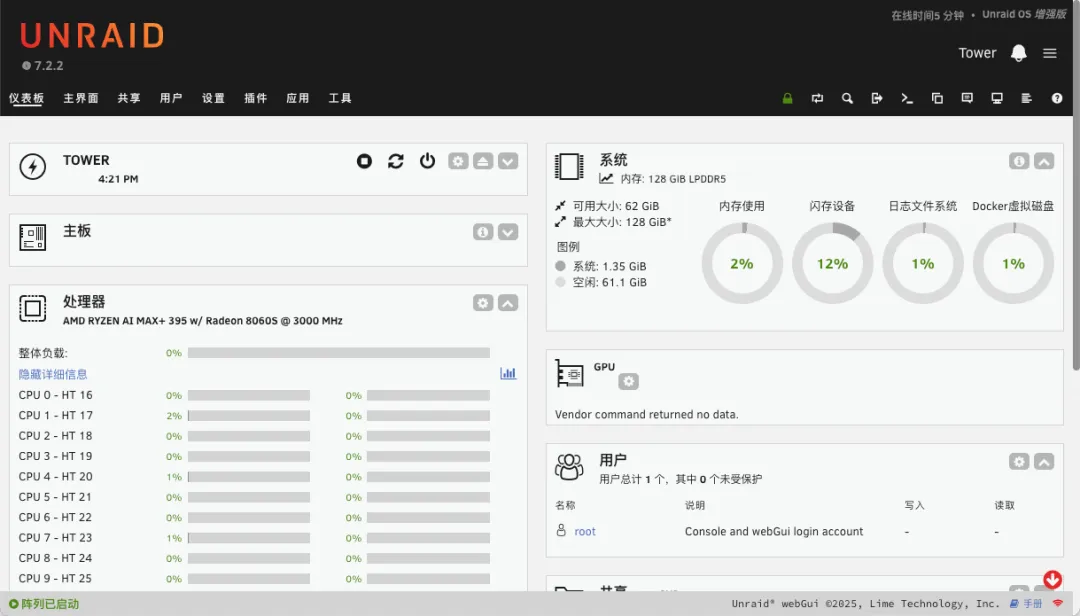
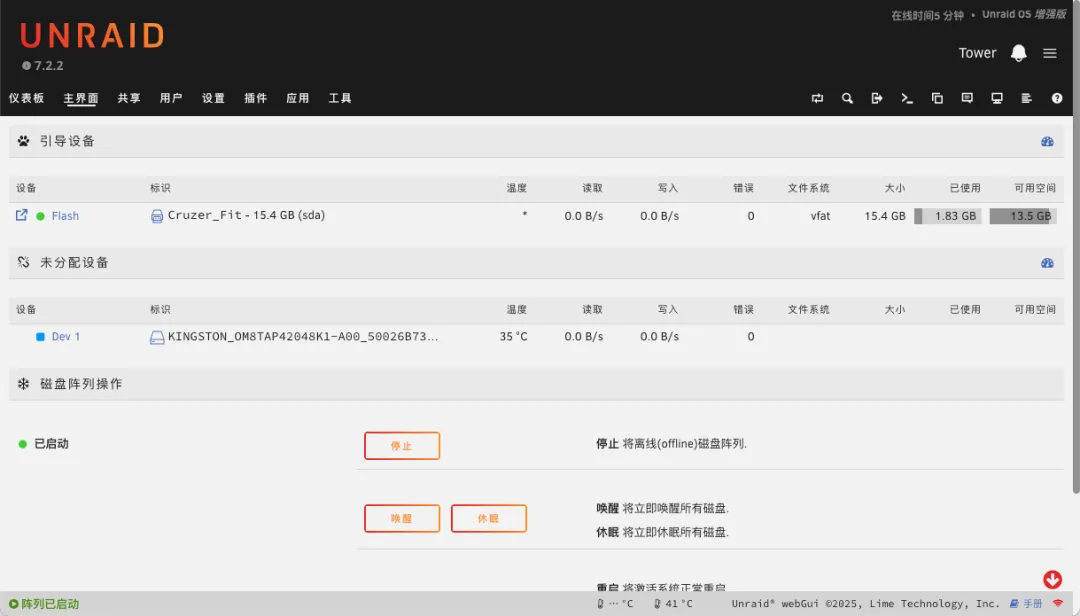
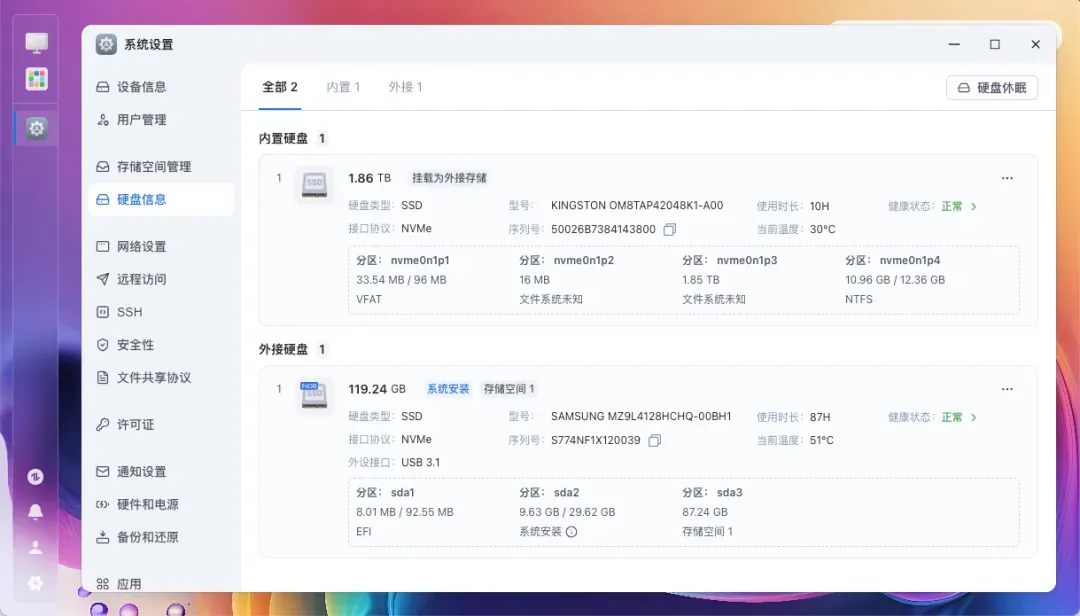
可以看到设备内置的M.2固态硬盘,散热表现良好,温度不高。
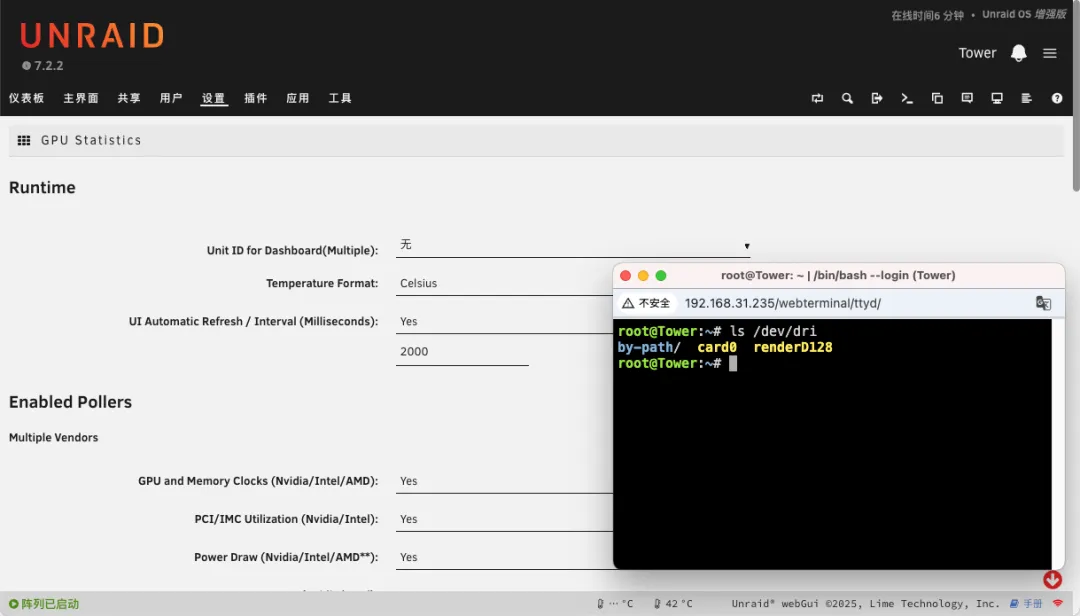
通过命令行可以查看到核显信息,但在插件管理界面中无法找到相应设备。
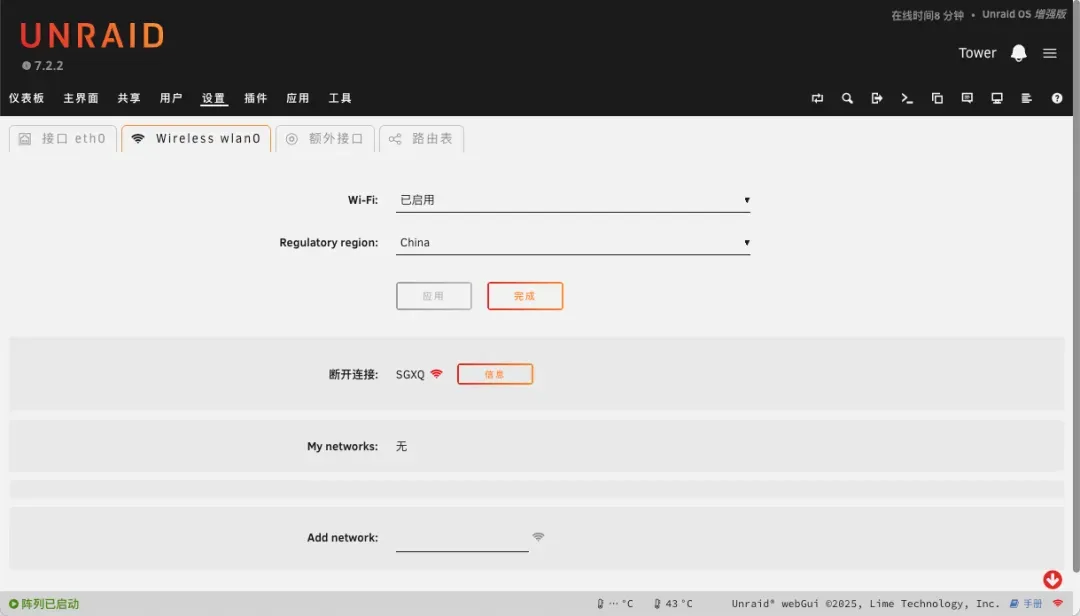
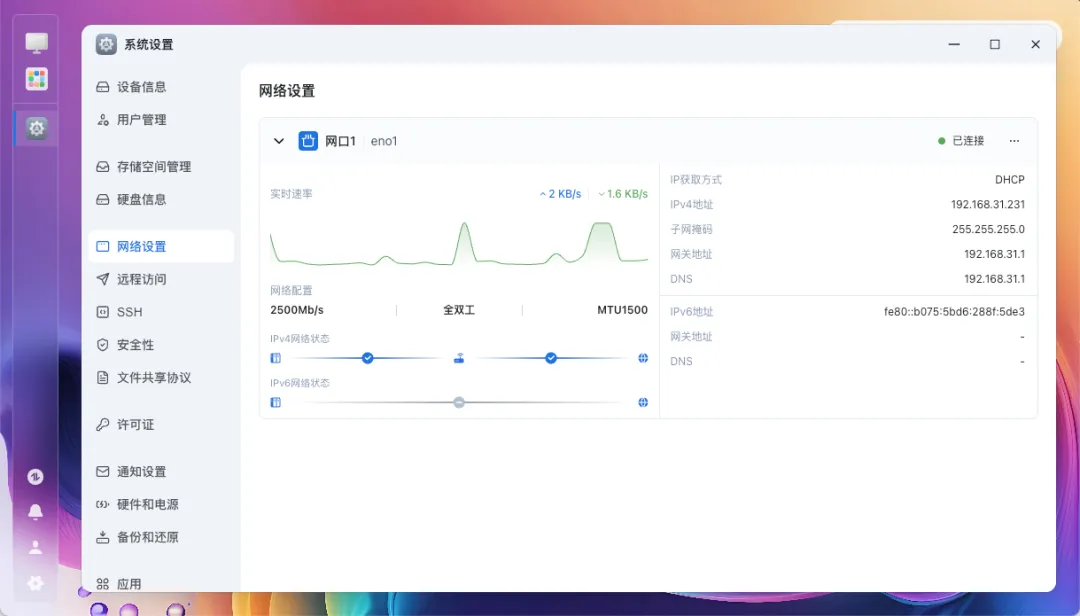
2.5G有线网卡可以被识别,无线网卡也能被识别(但似乎无法正常工作)。
处理器温度和风扇转速等信息均无法识别。
FnOS系统兼容性测试
安装了最新版本的飞牛系统进行测试,兼容性方面同样存在一些不足。
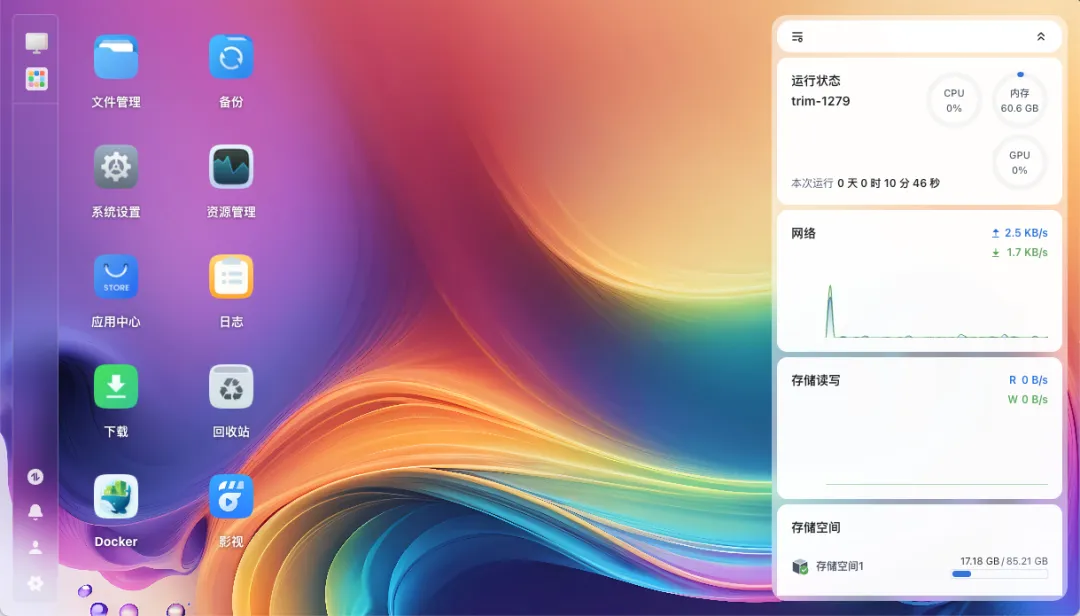
在资源管理器中,可以查看设备的整体运行状态。
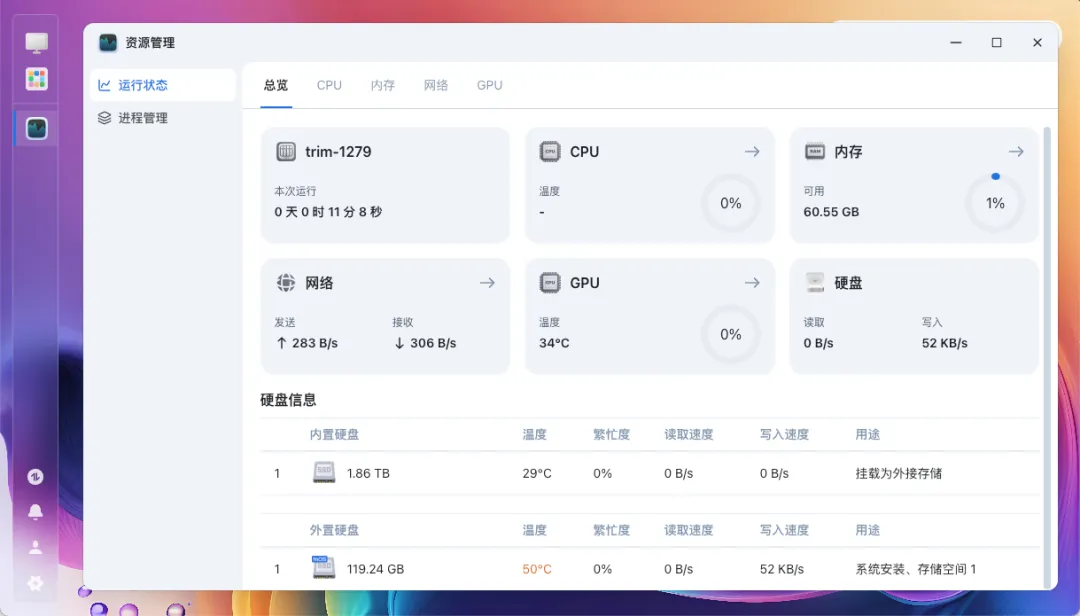
处理器型号可以正常识别,但温度信息无法读取。
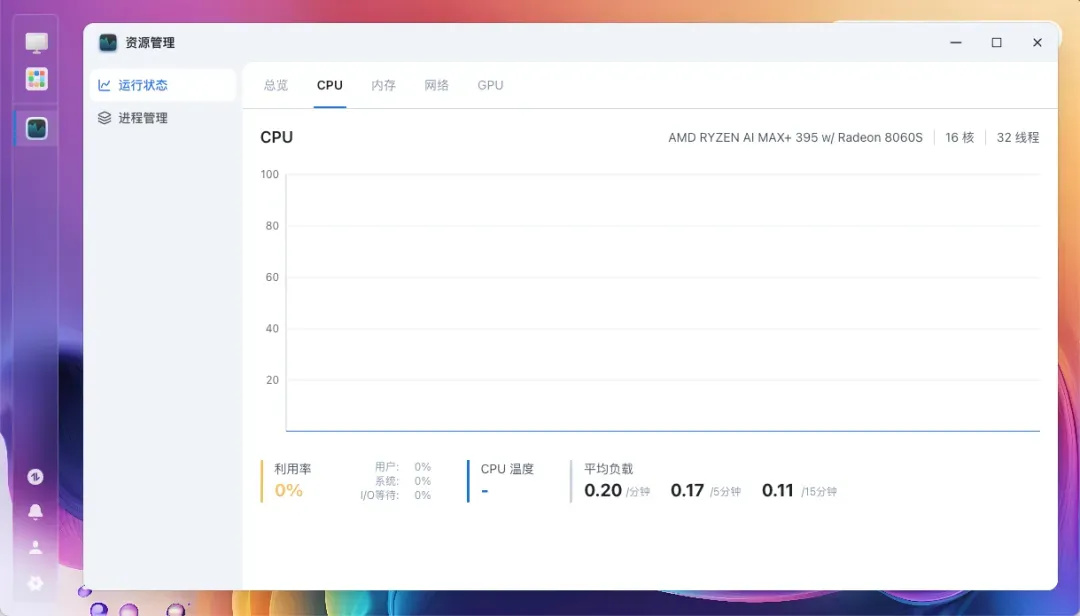
128GB内存可以正确识别,没有出现问题。
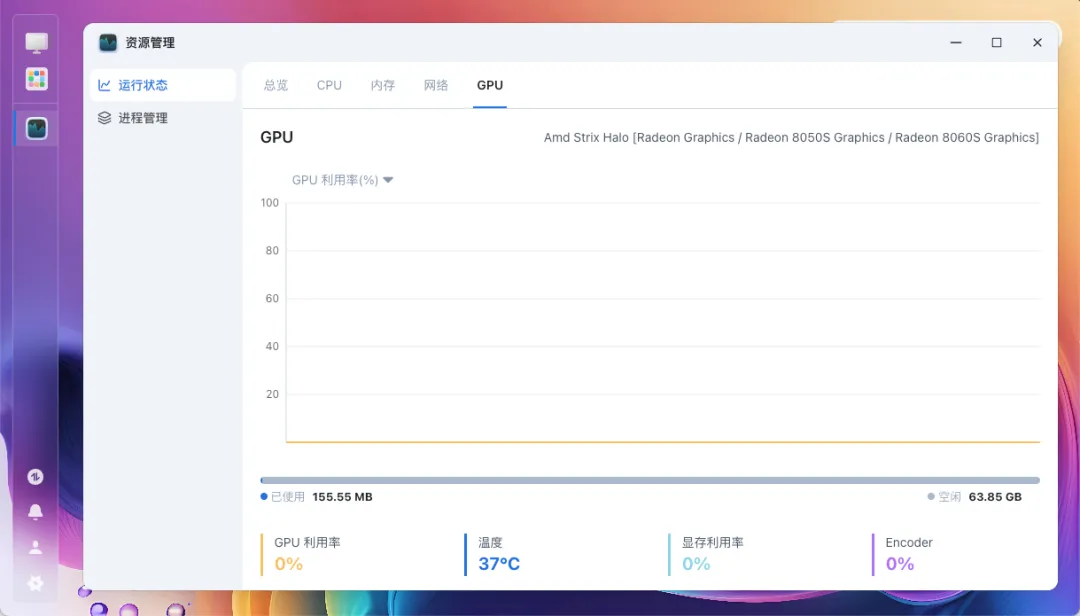
GPU型号和温度可以被读取,但后续调用硬件解码功能时失败。
内部的M.2固态硬盘可以被识别,温度表现均处于良好范围。
2.5G有线网口工作正常,但无线网卡无法被识别。
播放一个17GB大小的4K视频并将其转码为1080P时,无法调用GPU进行硬件解码(缓冲时间约为30秒)。

不过,完全依靠CPU进行软件解码,播放过程依然流畅,与没有硬件解码时的体验相差不大。
总结与展望:AideaStation R1的全面评价
希未AideaStation R1是一款革命性的桌面级AI算力中心,它搭载了AMD锐龙AI Max+ 395处理器,集成了性能媲美RTX 4060的Radeon 8060S核显,提供了高达50TOPS算力的NPU,并辅以128GB大容量内存和高速固态硬盘。如此强悍的配置被浓缩在仅4升的迷你机身中,展现了卓越的工程设计能力。

设备在AI算力、接口扩展性、静音散热以及整体使用体验方面均表现出色。它能轻松在本地部署700亿参数的大型模型,支持多屏输出和高速数据传输,真正践行了“桌面之上,超算已至”的产品理念。

之前为了体验AI大语言模型和AI绘画,我曾购买显卡坞和独立显卡(如A2000Lp),但显存仅有8GB,运行模型时需要特别关注大小,生怕显存溢出。如今,AideaStation R1我已经上手使用了半个月,基本上不再有模型跑不动的顾虑,任何新发布的模型都可以在第一时间进行体验。
AideaStation R1非常适合对性能和算力有极高要求的专业用户群体,例如AI开发者、平面与三维设计师、影视后期制作人员、游戏软件工程师以及3D建模师等。它能显著缩短创作和开发所需的时间。同时,对于注重数据安全的小型工作室、中小企业、教育机构、科研团队和初创公司而言,AideaStation R1提供了一个成本效益更高且更安全的本地化AI解决方案,用以替代部分云端服务。这既保证了数据安全性和低延迟,又避免了敏感数据外泄的风险。

综合来看,希未AideaStation R1以其紧凑的体型、强悍的性能和全面的AI支持,为专业用户和机构提供了一个高效、安全且灵活的本地算力平台,在桌面级AI计算领域树立了新的标杆。