自主AI研究员Autoresearch彻夜炼丹:零配置驱动GPT优化实验
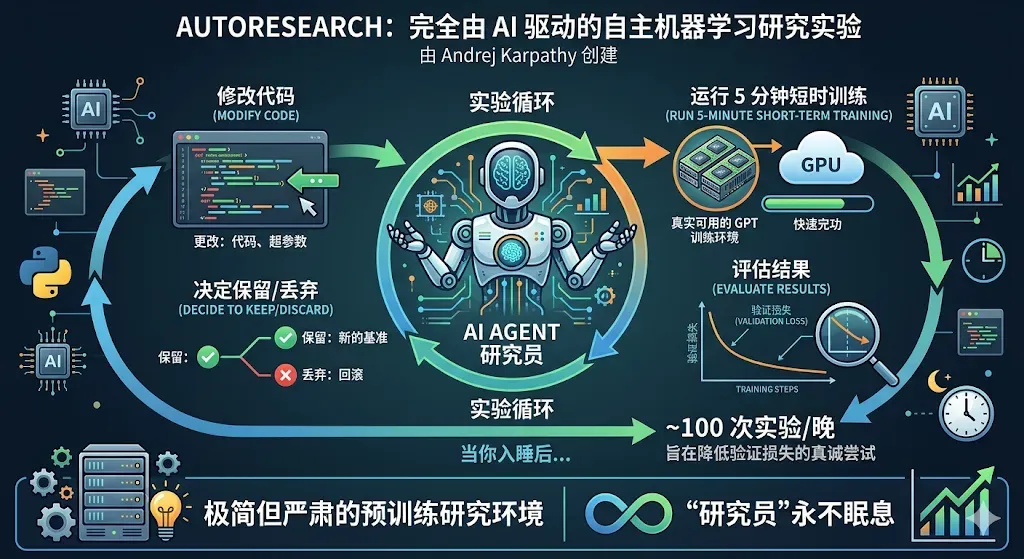
Autoresearch 是由 Andrej Karpathy 发起的一个纯粹由 AI 自主驱动的机器学习研究实验。它的核心理念非常直接:给 Agent 提供一个真实的 GPT 训练环境,让它自行修改代码、进行 5 分钟的短期训练、评估结果,然后决定保留还是放弃每一次改动。当你在夜间休息时,这位 Agent 可能已经完成了近 100 次实验,每一次都是为了降低验证损失而做出的认真尝试。这不是一个演示玩具,而是一套极简却严肃的预训练研究框架——在这里,研究员永远不需要睡觉。
项目地址:https://github.com/karpathy/autoresearch
整个代码库刻意保持极度的简洁——仅由三个核心文件和少量辅助文件构成,没有任何配置框架。极简就是架构本身。通过将问题约束在单 GPU、单个可编辑文件和单一指标上,该项目彻底消除了基础设施开销,使 Agent(或你本人)能够在固定的时间预算内,全神贯注于如何更有效地训练 transformer。
整体架构:动静分离的设计哲学
整个系统围绕固定部分与可变部分之间的清晰职责划分而构建。理解这条界线是掌握 autoresearch 其他一切内容的关键。
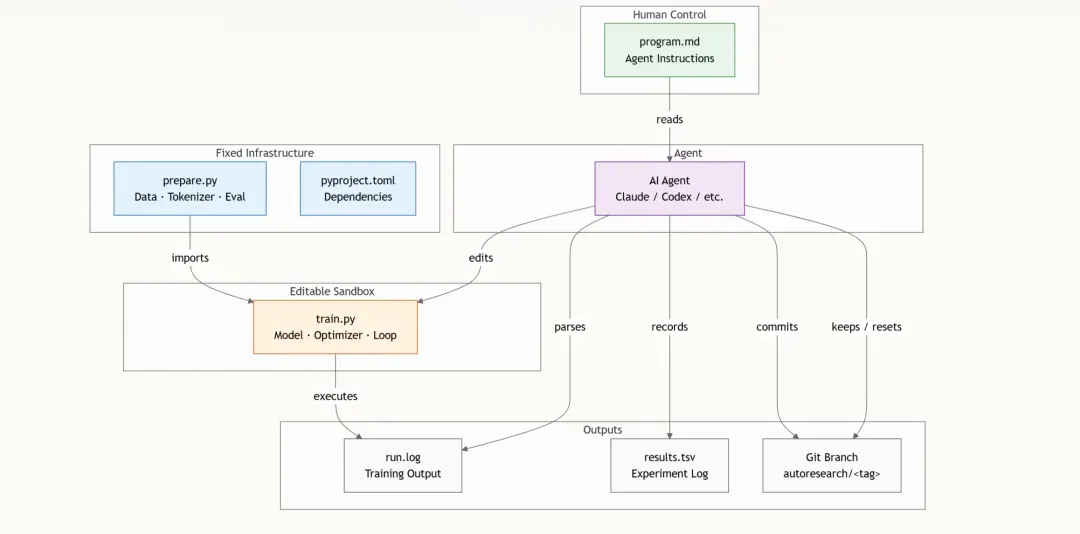
绿色部分由人类编写,蓝色代表不可变的基础设施,橙色是 Agent 可自由发挥的试验场,紫色的 Agent 负责编排实验循环,而灰色的输出则完整记录发生的一切。
项目文件清单
代码库的结构印证了其设计的简洁性。每个文件都承担着明确的职责,整个代码库中有意义的 Python 代码不到 1000 行。
autoresearch/
├── prepare.py ├── train.py # ✏️ 可编辑——GPT 模型、优化器、训练循环
├── program.md # 🤖 Agent 提示——AI 研究员的指令
├── pyproject.toml # 🔧 配置——项目依赖(由 uv 管理)
├── analysis.ipynb # 📊 分析——用于检查实验结果的 Notebook
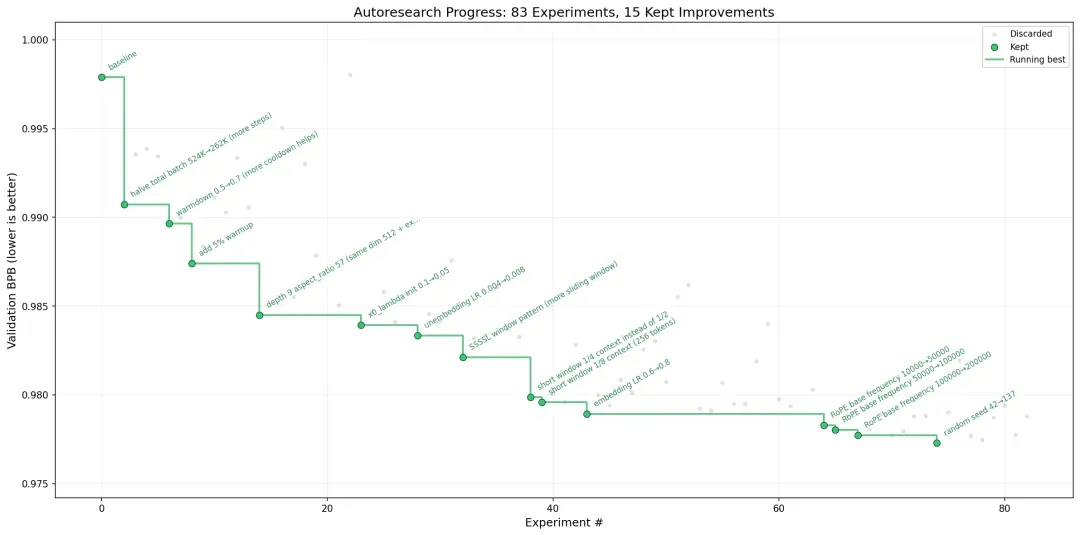
├── progress.png # 📈 可视化——来自某次通宵运行的实验结果图表
├── README.md # 📖 文档——项目说明
└── uv.lock # 🔒 锁定——固定的依赖版本
这三个关键文件映射出一个三角形角色设计:
| 文件 | 所属方 | 用途 | 可否修改? |
|---|---|---|---|
prepare.py | 人类(固定) | 下载数据,训练 BPE 分词器,提供数据加载器和 evaluate_bpb() | ❌ 绝不修改 |
train.py | AI Agent | 包含 GPT 模型架构、MuonAdamW 优化器、超参数和训练循环 | ✅ 可以——这是沙盒 |
program.md | 人类(动态演进) | 向 Agent 提供设置说明、实验协议、日志格式和规则 | ✅ 仅限人类修改 |
自主实验循环:永不疲倦的 AI 研究员
Agent 一旦启动,便会进入一个无限循环,这一循环模仿了人类机器学习研究者的工作流程——只是速度更快,且从不疲劳。每个周期大约耗时 5 分钟。
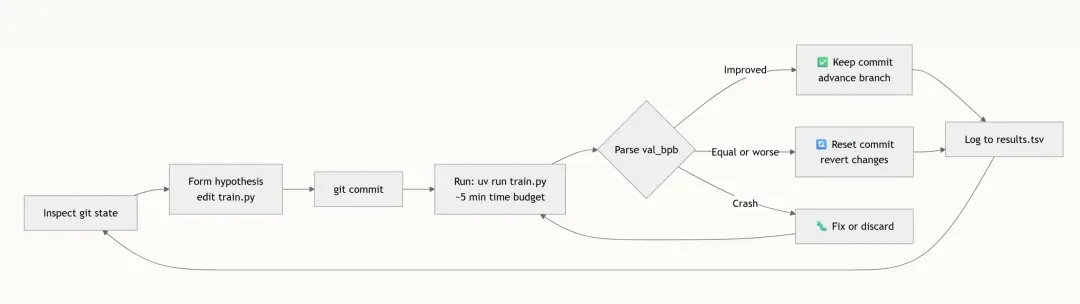
Agent 永远不需要暂停来征求意见。循环一迈开,它就会无休止地运行——设计的预期是让你让它在夜间保持运转,待早晨醒来时便能看到大约 100 次已完成的实验,所有结果都被记录在 results.tsv 文件中,并且 git 分支只有在发现改进时才会向前推进。
15 分钟快速上手
在 15 分钟内让你的机器跑通 autoresearch。本指南将带你逐步完成每一步——从环境配置到首次成功的 5 分钟训练运行——以便你在将控制权交给自主 AI Agent 之前,验证整套流水线能够正常工作。
必要准备工作
开始之前,请确保你的环境满足以下要求。Autoresearch 在设计上追求极简,但它确实需要一块支持 CUDA 的 NVIDIA 硬件——整个技术栈都围绕单 GPU 训练和 Flash Attention 3 构建。
| 需求 | 最低要求 | 推荐配置 | 备注 |
|---|---|---|---|
| GPU | 任何支持 CUDA 的 NVIDIA GPU | H100 | 已在 H100 上测试;其他 GPU 会产生不同的吞吐量数据 |
| Python | 3.10+ | 3.10+ | 通过 pyproject.toml 中的 requires-python 强制执行 |
| uv | 最新稳定版 | 最新稳定版 | Python 包管理器——通过命令安装 |
| 磁盘空间 | ~5 GB | ~20+ GB | 数据分片会被下载至 ~/.cache/autoresearch/ 目录 |
| 显存 | ~10 GB | 40+ GB | 默认的 8 层模型峰值约占用 44 GB;也可使用更小的配置 |
本项目通过自定义包索引锁定了 PyTorch 2.9.1 与 CUDA 12.8,因此你无需单独安装 CUDA——PyTorch 自带 CUDA 运行时。
安装与配置
整个安装过程使用 uv,一款快速的 Python 包管理器,它集成了依赖解析、虚拟环境管理和 Python 版本管理。按顺序执行以下四条命令:
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. 同步依赖——创建虚拟环境并安装所有内容
uv sync
# 3. 下载训练数据并训练 BPE 分词器(约 2 分钟)
uv run prepare.py
# 4. 运行你的第一次训练实验(约 5 分钟)
uv run train.py
下面详细拆解每条命令的实际作用,因为理解这一流程对于日后排查问题至关重要。
第 2 步 —— uv sync 会读取 pyproject.toml,将所有依赖安装到自动创建的虚拟环境中。核心依赖为 torch==2.9.1,它从 NVIDIA 的 CUDA 12.8 wheel 索引中拉取。其余包包括 kernels(用于 Flash Attention 3)、rustbpe(快速 BPE 分词器)、numpy、pandas、pyarrow(用于读取 Parquet 数据分片)以及 matplotlib(用于分析 Notebook)。
第 3 步 —— uv run prepare.py 是一次性操作,完成两项任务。首先,它会从 Hugging Face 将训练数据分片下载到 ~/.cache/autoresearch/data/ 目录。默认获取 10 个分片(每个约 500 MB),这已足够让你开始;日后你可以通过 --num-shards -1 下载全部 6,542 个分片。其次,它会训练一个词表大小为 8,192 个 token 的 BPE 分词器,并将其保存至 ~/.cache/autoresearch/tokenizer/ 目录。当末尾打印出 Done! Ready to train. 时,即表示执行成功。
第 4 步 —— uv run train.py 会启动完整的训练流水线:构建模型,精确运行 5 分钟的实际训练时间(可在 prepare.py 中通过 TIME_BUDGET = 300 配置),在保留的验证集分片上进行评估,并打印最终摘要。若该过程顺利完成且无报错,说明你的环境已完全配置就绪。
读懂训练输出
当 uv run train.py 执行完毕,你会看到一段启动序列,随后是训练进度,最后是一个摘要块。以下是各部分的含义:
启动输出 展示了根据 DEPTH 超参数推导出的模型配置。模型维度计算方式为 depth × ASPECT_RATIO(向上取整至 HEAD_DIM = 128 的倍数),注意力头数量也随之确定。
Vocab size: 8,192
Model config: GPTConfig(sequence_len=2048, vocab_size=8192, n_layer=8, n_head=4, n_kv_head=4, n_embd=512, window_pattern='SSSL')
最终摘要块——这份最关键输出——如下所示:
---
val_bpb: 0.997900
training_seconds: 300.1
total_seconds: 325.9
peak_vram_mb: 45060.2
mfu_percent: 39.80
total_tokens_M: 499.6
num_steps: 953
num_params_M: 50.3
depth: 8
| 指标 | 衡量内容 | 关注点 |
|---|---|---|
| val_bpb | 验证集 bits per byte | 核心目标。 数值越低越好。与词表大小无关。 |
| training_seconds | 实际训练挂钟时间 | 应接近 300(即时间预算) |
| total_seconds | 含启动和评估的总时间 | 通常在 320–360 秒之间 |
| peak_vram_mb | GPU 显存峰值使用量 | 用于监控是否发生 OOM 崩溃 |
| mfu_percent | 模型 FLOPs 利用率 | 数值越高 = GPU 利用率越好;通常在 30–50% 之间 |
| total_tokens_M | 处理的 token 数量(百万) | token 越多 = 单次实验学习越充分 |
| num_steps | 优化器更新步数 | 计算方式为 total_tokens / TOTAL_BATCH_SIZE |
| num_params_M | 模型参数量(百万) | 随 DEPTH 变化而缩放 |
val_bpb 是对比实验时唯一重要的指标。它通过目标字节长度对交叉熵进行归一化处理,因此更改词表大小(例如从 8,192 改为 256)不会人为地放大或缩小该数值。这使得不同架构实验之间具有较高的可比性——这也是此框架的一项核心设计决策。
常见问题与解决
以下是首次运行时最可能遇到的问题及应对方法:
| 症状 | 可能原因 | 解决方法 |
|---|---|---|
uv sync 因 PyTorch 错误失败 | 不支持的 CUDA 版本或非 NVIDIA GPU | 确认已安装 NVIDIA GPU 及相应驱动 |
prepare.py 下载报错 | 网络问题或 Hugging Face 速率限制 | 重试;或减少分片数:uv run prepare.py --num-shards 4 |
运行 train.py 时出现 OOM | 默认模型对于你的 GPU 过大 | 在 train.py 中将 DEPTH 降至 4,并将 DEVICE_BATCH_SIZE 降至 32 |
kernels 导入错误 | 非 Hopper 架构 GPU(非 H100) | 代码会在 train.py 处自动检测 GPU 算力并选择合适的 Flash Attention 3 变体 |
| 训练缓慢 / MFU 偏低 | GPU 未被充分利用 | 检查 DEVICE_BATCH_SIZE——如果显存允许则调大 |
找不到分词器缓存的 FileNotFoundError | 尚未运行 prepare.py | 请先运行 uv run prepare.py |