从ChatGPT到ClawToken经济学:AI从模型走向系统,万亿美元赛道的底层逻辑
在看过英伟达CEO黄仁勋2026年GTC的主题演讲之后,如果把具体的产品参数暂时搁在一边就会发现,他反反复复在强调一个核心脉络:AI正在从“模型时代”,快速跨入“系统时代”。
模型的能力当然还在持续提升,但行业真正的重心已经悄然转移——AI不再满足于“会说话”,而是开始“会做事”,进而一步步走入真实的物理世界。
计算本身的形态也随之发生了根本性的变化:计算从训练阶段大幅溢出到推理阶段,从单次调用演进为多轮调度,从云端延伸至本地,再进一步渗透到物理世界的每一个角落。
AI,正在从一个“回答问题的工具”,转变为一个“持续运行的系统”。

这是一条再清晰不过的产业路线。
大模型的进化史:一部Token消耗指数级增长史
如果试着把过去三年压缩成一条演进线,大致会呈现出下面这样的图谱。
第一阶段:以ChatGPT为标志 Transformer架构与大规模预训练的成熟,让语言生成终于变得稳定可用。模型能够直接完成表达与归纳,AI第一次真正像人类一样“开口说话”,完成了一次表达能力的巨大跃迁。
第二阶段:DeepSeek R1为代表的变革 这一阶段不单单是推理能力的增强,更叠加了开源模型的大爆发。借助强化学习和推理链,模型开始主动生成中间步骤再推导出结论,计算的重心被显著拉向推理阶段,处理路径大幅延长,Token的消耗也因此急剧攀升。与此同时,开源模型的快速迭代,将强大的推理能力下沉到更广泛的开发者与企业环境里,不仅加速了技术的扩散,也让“可控、可部署”的AI真正变成现实。
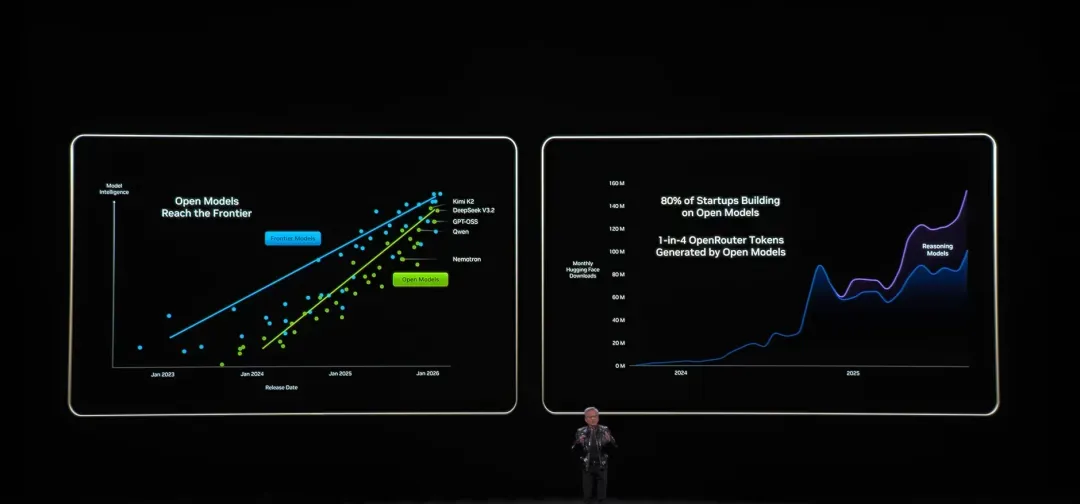
第三阶段:Manus、Genspark、Lovable——Agent雏形初现 模型被嵌入到更复杂的系统当中,依靠工具调用、任务拆解以及多轮执行,完成过去难以单次达成的复杂目标。此时,一次用户请求不再仅仅对应一次推理,而是一整串调度链条,计算开始在多个模块之间持续流动。
第四阶段:Claude Code——本地执行能力走向成熟 模型开始直接进入真实的运行环境,可以操作代码、文件以及系统接口。上下文的边界从一段提示词扩展为完整的执行环境,推理结果则能够立即转化为可落地的实际操作,生成能力与执行能力前所未有地融合在一起。
第五阶段:OpenClaw——执行能力的系统化 Agent、本地执行能力和工具生态被进一步整合成持续运行的有机系统,能够支撑长任务、多阶段反馈。计算不再被“请求”所触发,而是以“进程”的形式长期存在,具备连续性与状态保持能力。
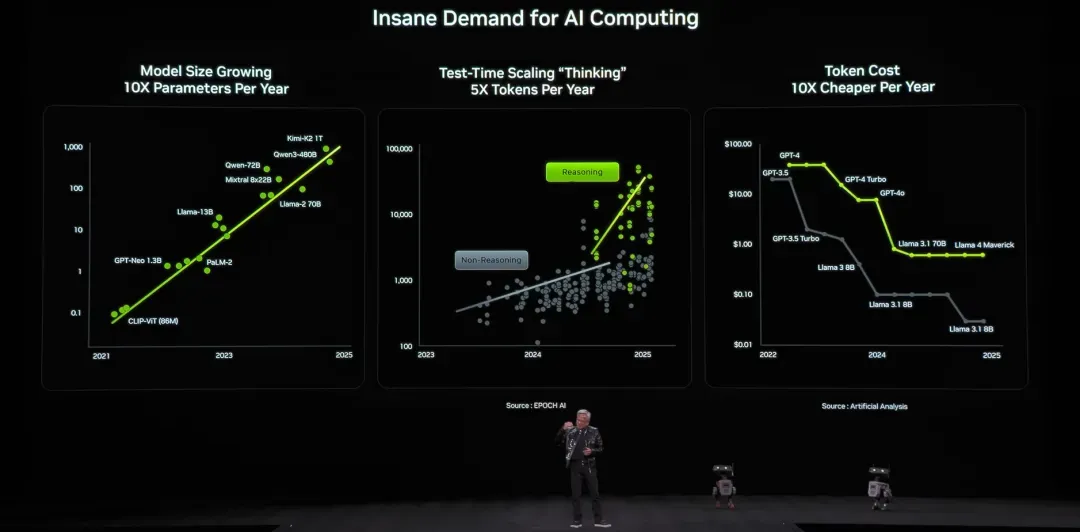
这条演进主线有一个贯穿始终的共同特征:每向前迈出一步,Token的消耗就上一个新的台阶。
AI产业的竞争重心,正从单一的“模型竞赛”,悄然转变为全方位的“Token经济”。
- 推理模型让每一个简单问题都消耗更多的Token;
- Agent系统会持续、不间断地调用模型,Token已经变成某种“流量”;
- 长任务、多步骤交互,使得Token像电力一样形成持续计费的模式。
Token的使用量正在快速攀升,而与此同时,Token的单位成本却在持续走低。每百万Token的价格会越来越便宜,这几乎没有什么悬念。
真正关键的是两条曲线之间的速度差:
我们认为,Token成本下降的速度,很可能赶不上需求膨胀的速度。因此,即便每个Token变得更便宜,每个人消耗掉的Token数量却只会更多。两者叠加的结果是,总体支出非但没有下降,反而在节节攀升。
这正是Token越来越像一种基础资源的根本原因——单位价格长期下降,而总消耗量却屡创新高。
Agentic AI:一场系统级软件革命的开幕
以OpenClaw为代表的Agentic AI之所以会骤然爆火,关键就在于它恰好踩在了软件进化的一条关键拐点上。
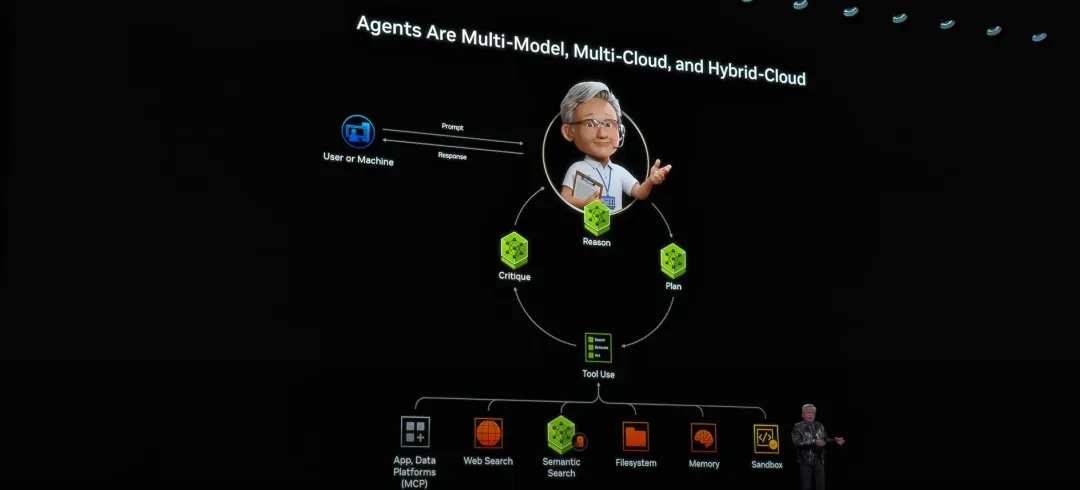
传统的软件交互模式是人点击按钮 → 软件执行固定逻辑 → 返回既定结果。
而现在的模式正在被彻底重塑:人只需要下达一条自然语言指令 → Agent自动拆解任务 → 协同调用多个模型、工具和数据源 → 最终交付完整成果。
两者之间最本质的差别在于,软件从一个固化的功能集合,升级为能够自主完成任务的执行者。
正如黄仁勋在演讲中所描绘的,Agent有能力查阅资料、编写代码、制定规划、运行模拟、调用外部API,并且天然具备将复杂问题拆分为多个有序步骤的能力。
它早已超越单一模型的范畴,进化为一个包罗万象的综合系统,涵盖:
- 多模型(语言、视觉、语音)
- 多工具(搜索、数据库、软件接口)
- 多环境(本地、云、多云架构)
- 持续上下文(长期记忆)
这在实质上是在一步步改写整个软件生态的底层逻辑。过去,编写代码的核心是定义逻辑;而今天,构建系统的核心是编排能力。
因此,你会清晰地看到:
- OpenAI:持续深耕工具调用(function calling),最新的GPT-5.4已经原生支持「computer use」,能直接查看屏幕、操控鼠标和键盘。
- Anthropic:重点强化Agent的长周期循环,安全运行数天之久,同时推出Claude Computer Use以及多代理协作能力。
- 开源社区:OpenClaw彻底爆发,短短两个月GitHub星标就飙升至25万以上,成为目前最实用的自托管Agent框架。
而NVIDIA给自己的定位,并不是再做一款Agent产品,而是干脆成为Agent的基础设施层(NeMo、Blueprint、推理系统等)。
物理AI:AI开始理解真实世界的法则
如果说Agent的主战场还局限在“数字世界”之内,那么物理AI则标志着人工智能第一次大规模地进军真实世界。
两者的难度完全不在同一个量级上。语言模型只需要解析语义的对错,而物理AI必须真正洞悉现实世界的物理法则:物体遵守质量守恒、受力会产生反馈、动作天然附带延迟、世界呈现连续不断的状态变化。
换个说法:语言模型解决的是逻辑上的“对不对”,物理AI则必须直面现实中的“能不能做到”。
物理AI需要一种三位一体的结构:
- 训练——赋予学习能力;
- 推理——执行实时决策;
- 模拟——在虚拟环境中验证现实可行性。
三者互为支撑,缺一不可。由于真实世界的可用数据极为稀缺,AI必须先在“虚拟世界”中完成发育和试错。

基于这一判断,NVIDIA布局了多个极具“工程感”的关键项目:
- Omniverse: 构建高度逼真、可交互的数字孪生世界。
- Cosmos: 专注训练能够探索现实规律的“世界模型”。
- Isaac / 自动驾驶平台: 让机器人和自动驾驶系统先在仿真环境中掌握行动逻辑。
这些布局的底层逻辑是先依托庞大算力生成虚拟世界 → 再在其中培育智能 → 最终将成熟的智能部署到真实的物理空间中去。
一旦这条路径被彻底跑通,其深远影响将远超AI行业本身,深度重塑制造业、交通运输、机器人乃至能源等千行百业。
需求远超供给:算力成为整个链条的核心瓶颈
AI需求的膨胀速度,已经远远将算力供给甩在了身后。
推理模型带来Token消耗的暴涨,Agent引发持续不断的系统调用,而物理AI则在上面叠加了“模拟+训练+推理”的三重计算负荷,每一项都堪称巨量。
如今,产业的核心痛点已经从“有没有模型可用”,彻底转向“有没有足够充沛的算力来支撑这些庞大过程的持续运转”。
这也从另一个侧面解释了,为什么NVIDIA的护城河极其难以被单点突破。它的版图早已超越单一的GPU,进化为一整套庞大的体系:
- 芯片底层(GPU、CPU、DPU)
- 系统架构(整机、互联网络、超级计算机)
- 软件生态(CUDA、AI框架、推理系统)
- 应用平台(Agent、物理AI、数字孪生)
再向前推进一步,便自然延伸出“AI工厂”的概念。算力不再只是被动消耗的资源,而是上升为核心生产力。商业模式也顺势跃升,从单纯兜售“工具”,逐步走向输出完整的“生产能力”。
AI基础设施化:从工具能力走向社会底座
回看整场演讲,相比于单纯的兴奋,更强烈的感受是:AI带来的巨变,已经逼到眼前。
- 上半场:主攻生成能力,让AI“会说话”;
- 中场:深耕推理与Agent,让AI“会做事”;
- 下半场:决胜物理AI,推动AI全面融入真实世界。
与此相伴而生的,是三条同时上扬的增长曲线——Token消耗量、系统复杂度和算力需求。
这三条线共同指向一个事实:AI正在跨越传统“软件能力”的边界,彻底下沉为社会的“基础设施能力”。
这正是未来十年AI产业的增长空间被锚定在“万亿美元”级别的根本逻辑。背后真正的驱动力在于,AI所接管的疆域正在急剧扩张:从单纯的信息流,延伸到复杂的工作流,最后直接触及真实的物理世界本身。
这条演进线路一旦展开,恐怕就再也难以收回。