Claude半月内七次宕机惊魂三小时,Anthropic投入5亿美元自研芯片破解算力困局
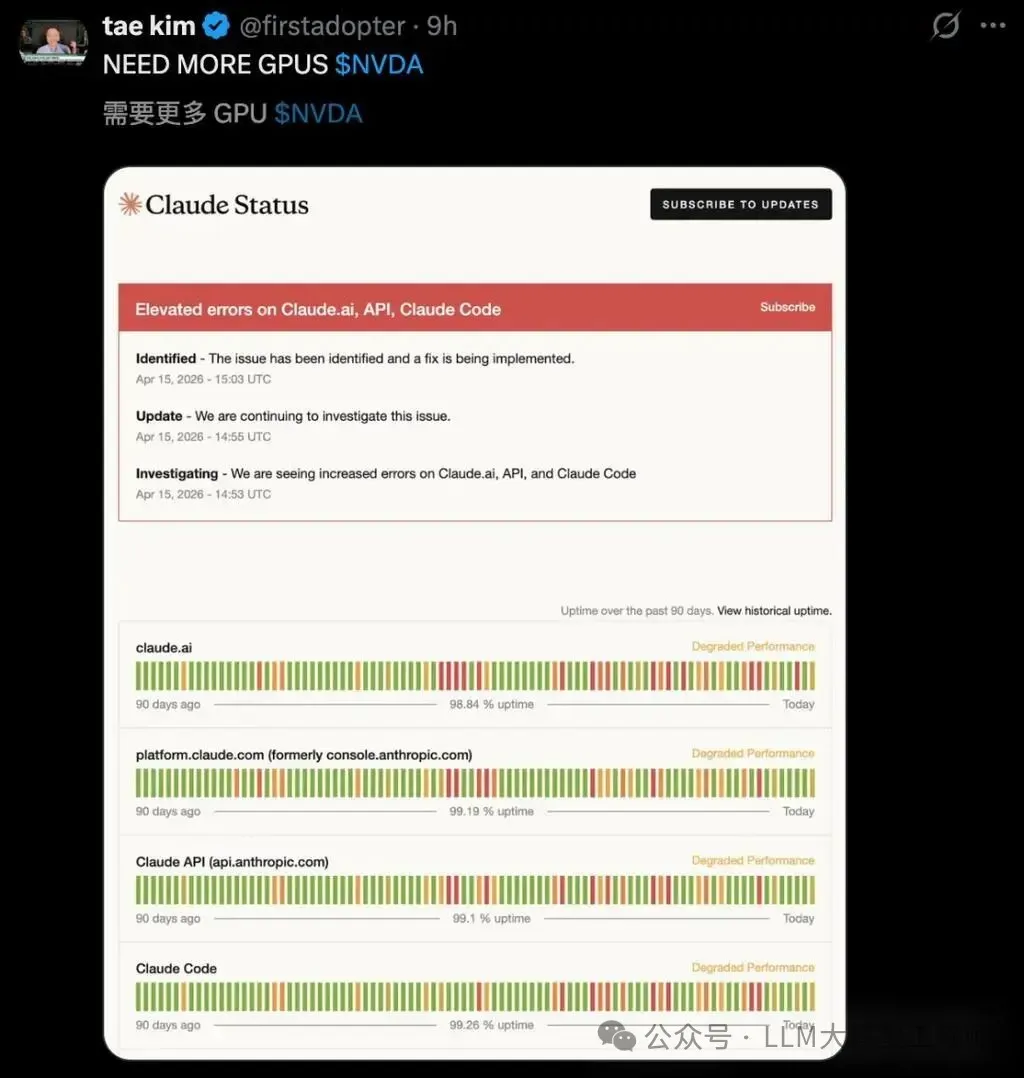
Claude全球服务中断事件再度成为焦点,引发广泛关注。美东时间周三上午,系统遭遇严重危机,官方状态页面显示,Claude、Claude Code及API接口均出现高错误率。
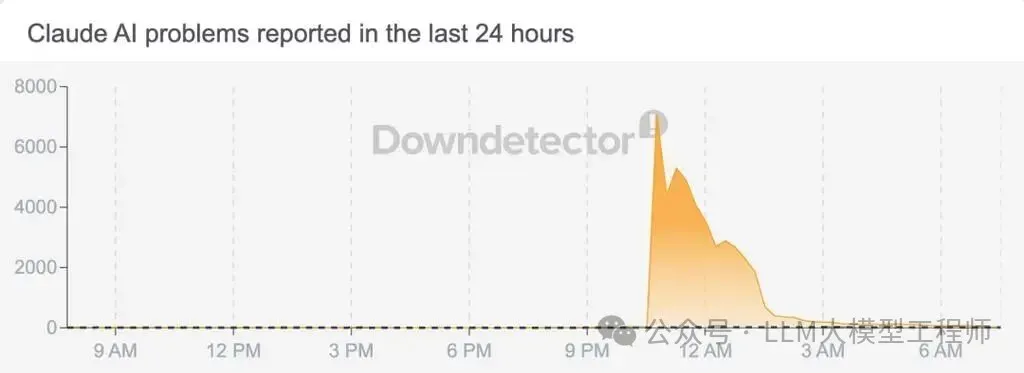
大量Claude用户反映日常工作受到干扰。宕机高峰期间,故障追踪网站Downdetector上同时收到了超过6000份错误报告。

此前Claude Opus模型已出现性能波动,加上频繁的服务中断,似乎验证了行业内的观察:Anthropic未能提前储备充足的计算资源,构成一项战略层面的失误。

为填补算力缺口,Anthropic不再被动等待,据透露已启动自研芯片的探索计划。
Claude再度宕机:用户经历惊魂三小时
对于许多依赖该平台工作的用户而言,此次中断无异于一场“生产力罢工”。根据Downdetector的数据监控,本次故障在上午10:42左右达到峰值。

故障时间线具体如下:
- 10:53 AM:Anthropic官方团队开始介入调查错误根源。
- 12:30 PM:Claude登录成功率逐渐趋于稳定,官方正全力解决剩余问题。
- 01:50 PM:状态页面正式更新,确认所有系统均已恢复常规运行。

持续近三小时的服务中断,对使用Claude进行编码、文案创作等任务的用户造成显著影响。有用户抱怨“个人项目进度瞬间停滞”。
部分开发者甚至表示正考虑转向其他AI编程辅助工具。

然而,Claude服务不稳定已非首次发生。
半月七次宕机:故障记录密集曝光
回顾Anthropic四月份的状态页面历史,服务中断的频率高得令人惊讶:
- 4月1日:Opus与Sonnet模型出现异常超时率。
- 4月3日:Claude Code服务中断1小时10分钟。
- 4月6日、7日:登录系统连续两天发生崩溃。
- 4月10日:非Opus模型集体出现错误。
- 4月13日:Claude.ai服务中断15分钟。
- 4月15日:发生本次持续3小时的大规模宕机。
短短半个月内,累计发生七次有明确记录的服务中断。这已超出偶然故障范畴,表明系统正持续发出过载警报。Anthropic通常将此类事件归因于“重大发布后产生的空前需求”。直白而言,用户增长过快导致服务器负载逼近极限。
频繁故障仅是表面现象,深层根源在于计算资源的严重短缺。
5亿美元入场券:Anthropic踏上自研芯片之路
近期有消息透露,Anthropic正在积极探索芯片自研方案。

据了解,该计划仍处于“非常早期”的阶段。公司尚未确定具体设计方案,也未为此项目组建专属团队。行业内部估算,设计一款先进AI芯片的初始成本大约需要5亿美元,这笔费用主要用于支付顶尖工程师薪酬、流片测试以及确保制造环节的可靠性。这仅仅可视为进入该领域的“入场费”。
从芯片设计到实现量产通常需要3到4年时间,期间任何环节出现问题都可能导致前期投入损失殆尽。

以谷歌TPU的发展历程为例,从2013年项目启动到2018年第三代芯片具备规模化训练能力,前后历时整整五年。因此,Anthropic最终也可能选择继续采购而非完全自研。但“探索”这一举动本身,已经释放出明确的战略信号。
目前,Anthropic采用英伟达GPU、谷歌TPU、亚马逊芯片等多种硬件来开发和运行Claude模型。就在上周,他们还官方宣布将与谷歌、博通合作打造一个容量高达3.5GW的超大规模计算集群。

AI巨头纷纷行动:寻求算力自主以规避英伟达依赖
Anthropic并非孤例。其他领先的AI公司也在积极寻求计算能力的自主可控:
- Meta正与博通合作扩大其自研MTIA芯片的产能,计划从2027年开始部署“数吉瓦级”的计算资源。
- OpenAI于去年10月公布的博通合作计划,目标是在2026年下半年开始部署,预计到2029年累计上线10吉瓦的算力。


博通成香饽饽:AI巨头青睐定制ASIC芯片的深层原因
定制ASIC芯片与英伟达通用GPU的核心差异主要体现在两个方面:
- 总持有成本:针对特定模型架构优化的ASIC,其总体成本可比通用GPU低30%到50%。
- 能源效率:ASIC在每瓦性能上通常比通用GPU高出一个数量级。
这听起来颇具优势,但ASIC也有其固有短板:它通常与特定模型架构深度绑定,一旦模型迭代更新,硬件效率可能下降;此外,它缺乏像CUDA那样成熟完善的开发者生态系统,在研究和实验阶段往往仍需依赖英伟达平台。
Anthropic自身也明确表示,Claude当前是在AWS Trainium、Google TPU、英伟达GPU三种硬件平台上进行跨架构部署,并未将所有资源押注于单一供应商。但这种“多云多芯”战略本身,恰恰承认了一个现实:没有任何一家供应商能够单独满足前沿AI公司对算力的庞大需求。

而供应商能提供的最优合作条件,往往只适用于其自家设计的芯片。这或许是推动Anthropic探索自研之路的根本动力。
营收增长与算力压力:Anthropic的财务困境
诚然,Anthropic近两年业务增长迅猛。据官方最新披露,其年化营收已突破300亿美元。在企业市场,数据显示73%的企业在首次采购AI工具时将预算投向了Anthropic。超过1000家企业客户的年化付费额突破100万美元,且这一数字在不到两个月内翻了一番。
但增长越强劲,面临的财务压力也越大。Claude Code和Claude Cowork这类智能体产品堪称算力消耗的无底洞。它们能够连续运行数小时执行复杂任务,每一次响应都在消耗大量的GPU计算资源。
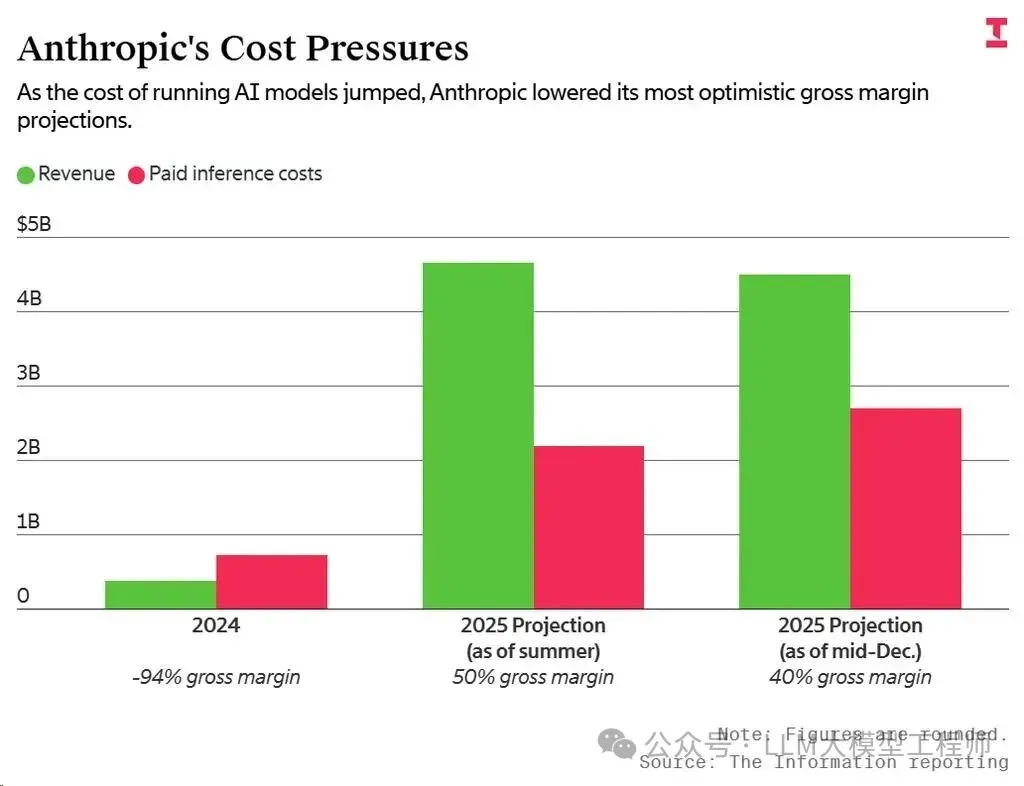
Anthropic在2025年的毛利率因高昂的模型推理成本而低于预期,这在该行业内已不是秘密。为了平衡财务状况,Anthropic在过去几周内连续推出三项关键举措:
调整企业版定价策略:将Claude Enterprise从纯订阅制改为“20美元月费+按实际使用量计费”的混合模式。新模式下,固定费用降低,但Token消耗将根据实际使用量计费(此调整不影响150人以下的小型企业)。估算表明,重度用户的成本可能增加一倍甚至三倍。
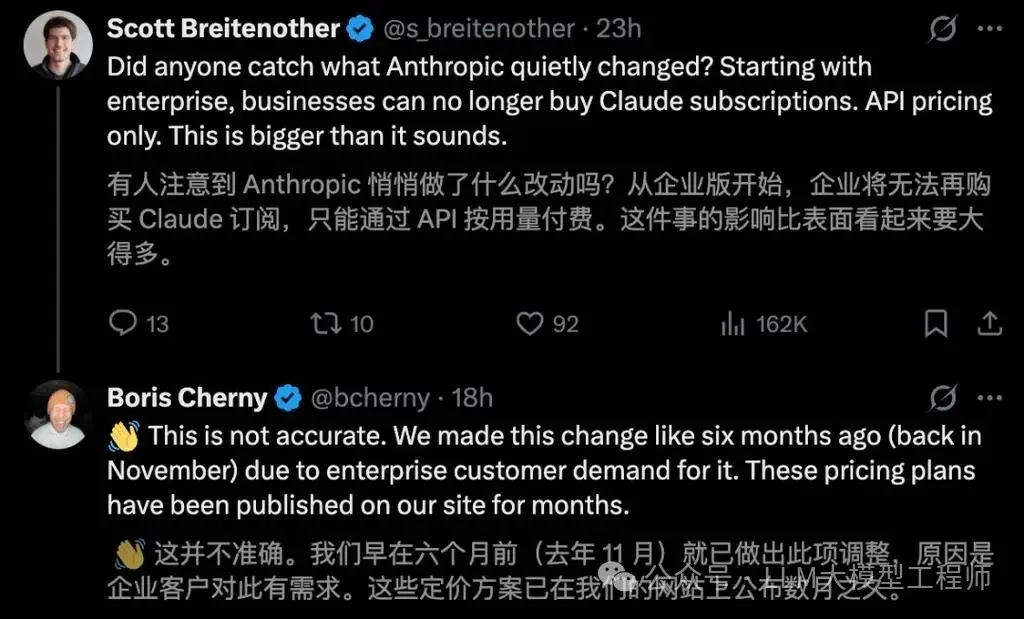
Anthropic发言人对此解释称,新定价模式能更准确地反映客户的真实使用情况。换言之,其目的在于对消耗算力最多的那部分用户进行精准收费。
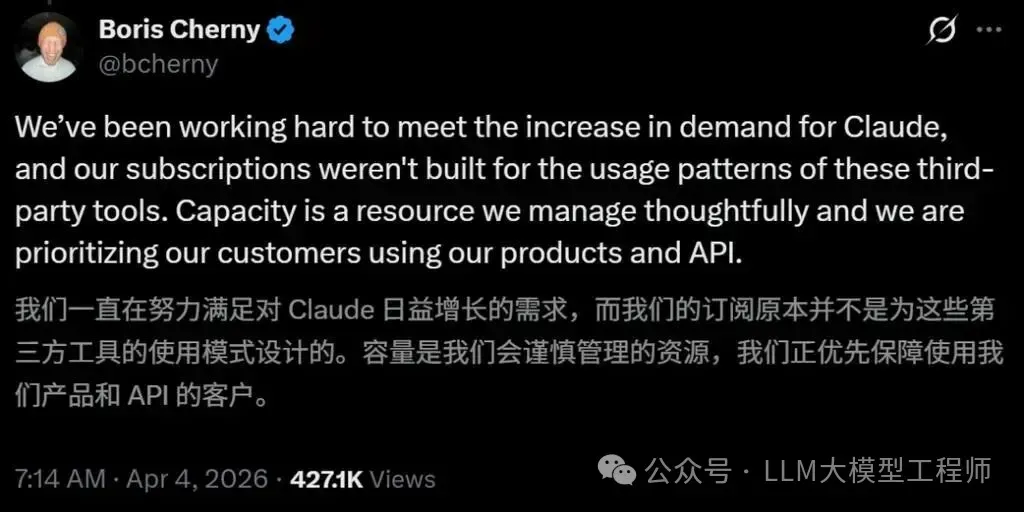
限制第三方工具调用权限:Claude Code订阅用户若使用某些第三方智能体工具,可能需要支付额外费用。官方表示,计算资源是必须精打细算的宝贵资产,必须优先保障使用自家产品和API的核心客户。
上线强制实名验证流程:要求用户提供政府签发的实体证件及实时自拍照以完成验证。其公告明确将“从不支持的地区创建账户”列为禁用理由之一,这对部分区域的用户产生了显著影响。依赖中转、套壳或共享池方式访问Claude的国内账号,在此验证流程下几乎无法通过。此前积累的所有对话记录、提示词以及项目上下文,也将随着账号被封禁而彻底清零。


上述措施均旨在从需求侧施加压力,以挤出过度使用或低效使用的情况。然而,无论需求侧如何调控,供给侧的算力天花板依然客观存在。
Adaption Labs联合创始人、前Cohere推理负责人Sudip Roy曾指出订阅制AI产品的根本困境:采用订阅模式,其商业前提本就建立在用户不会用满额度的假设之上。一旦赌输,企业就不得不自己动手制造“铲子”以保障供给。
算力解药遥遥无期:自研芯片或需等待至2027年
Anthropic当前面临的尴尬处境正在于此。公司估值高达3800亿美元,且70%的企业客户首单都选择Claude。但所有这些辉煌的数据,最终都依赖于同一项硬件基石——芯片。
尽管众多风险投资机构争相向Anthropic注资,其下一轮估值预计将攀升至8000亿美元,但在芯片这一核心环节,主动权始终掌握在外部供应商手中。采购英伟达芯片需看其供应状况,获取谷歌TPU需要排队等待档期,甚至连博通也开始在合作中写入对赌条款。
自研芯片被视为将命脉重新掌握在自己手中的唯一途径。但这一根本性解决方案的兑现时间,预计至少要等到2027年之后。在那之前,Claude的每一次服务中断,开发者在Downdetector上的每一份报错报告,都在反复印证同一个事实:故事蓝图描绘得再宏大,承载故事运行的硬件基石,却依然受制于人。