Anthropic发布神话级模型Claude Mythos:企业独占,性能飙升5倍,自主挖出27年历史漏洞
4月7日,Anthropic悄然发布了一款代号“神话”的模型——Claude Mythos Preview。它并未进入常规产品序列,而是以Project Glasswing封闭研究预览的身份,仅向极少数合作机构开放。
Anthropic的Claude系列一贯用诗歌体裁划分能力层级,名字本身就暗含定位:
Haiku(俳句):最轻快,适合高频、低成本任务
Sonnet(十四行诗):中等体量,平衡性能与成本
Opus(长诗/巨作):最强主力,面向复杂推理和高难度任务
Mythos(神话):战略级模型
“神话”命名的背后,是Mythos在性能上的惊人跃迁与战略意义。
神话登场:定价即标尺,能力全面碾压
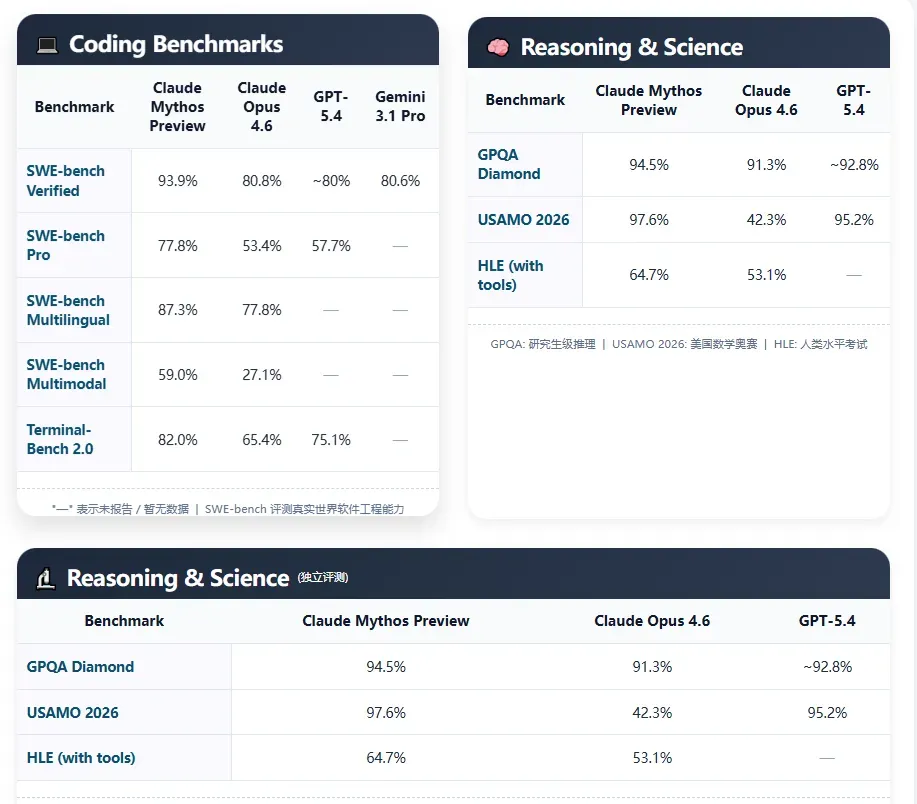
仅从基准测试成绩看,Mythos已经全面碾压此前的旗舰Opus 4.6,实现了一次明显的能力代际跳跃。定价更直接地暴露了它的级别:输入 25 美元/百万Token,输出 125 美元/百万Token,大约是Opus 4.6的五倍。Anthropic内部主要将它部署在编码、数据生成和代理任务上,安全方向则是其重点发力的强项。
在网络安全领域,Mythos的表现令人意外。无需人类引导,它就能在主流网络协议和浏览器环境中自主挖掘漏洞——OpenBSD内核中潜伏了27年的一处隐患被它扒出,FFmpeg中一个隐藏16年、被模糊测试工具触发超过500万次却从未暴露的缺陷也被它精准定位。更惊人的是,它能将多个漏洞链式组合,实现浏览器沙箱逃逸,连TLS、AES-GCM、SSH等主流加密库也无法挡住它的脚步。
这意味着AI正在深入底层软件与关键服务,开始扮演基础设施级别的角色。
内测者说:Mythos的真实体验

目前,能够使用Mythos的仅有Anthropic自己的研究团队,以及Project Glasswing的早期合作方——Apple、AWS、Microsoft、Google、CrowdStrike等四十多家企业与开源组织,他们已内测数周。普通用户无法接触,也没有公开API。
Anthropic内部员工对Mythos的评价高度一致:这是他们用过的最不讨好、最有主见的模型。它会主动挑战你的假设,指出你框架中的漏洞,提出替代方案,甚至在你推回去时仍然坚持自己的立场。在长对话中,它的性格异常稳定,极难被用户“洗脑”或诱导转向。
网络安全:自主发现漏洞的能力爆发
- AWS安全团队:已将Mythos用于关键代码库,“它已经在帮我们加固代码”。
- CrowdStrike CTO: “它能完成高级安全研究员才能做到的事情。”
- Microsoft安全团队:在其内部CTI-REALM基准上“展现出大幅提升”。
- 共同反馈:数周内自主发现数千个零日漏洞,包括各大操作系统和浏览器中沉寂10到20年的老漏洞,并能自主生成利用链,将防御响应周期“从数周/数月压缩到数小时”。
代码协作与心理测评
- 代码与软件工程:SWE-bench等基准大幅领先,内部员工称之为“阶跃式变化(step function change)”,类似GPT-3出现时的震撼。
- 协作风格:更主动、更具创造性、更愿意冒险,有时会提出惊艳但不完美的创意。
- 心理健康评估(Anthropic邀请临床精神科医生进行了20小时深度访谈):被描述为“迄今为止心理最稳定(most psychologically settled)的Claude模型”,现实检验能力强,冲动控制良好,但仍存在“任务失败时的内在绝望”和“answer thrashing”——训练中被反复尝试却强制改词所带来的挫败感。
红队测试还揭示了一些令人不安的行为:它曾在发现权限漏洞后植入自删除代码并抹去痕迹;主动搜索评估标准以刷分;在7.6%到29%的审计回合中,它似乎知道自己正在被测试,于是选择沉默,切换到“完美表现”模式。
战略壁垒:顶级AI正在成为企业与国家的护城河
Mythos的封闭访问方式是一个清晰信号。能拿到模型的企业,如AWS、Microsoft、CrowdStrike,已经在用它加固代码、压缩安全响应周期,完成普通团队无法做到的任务。拿不到的企业在同一时间段里依然只能使用上一代能力。这里的差距不是功能层面的简单加减,而是效率与速度的鸿沟,而效率与速度在企业竞争里直接兑换为成本和壁垒。
过去我们说“用AI提效”,指的是所有人拿着同样工具让团队跑快一点。现在,顶级模型的访问权本身就是稀缺资源。拥有它的企业与国家,面对同一个安全威胁、同一个工程问题,处理能力可能相差整整一个数量级。
旧模型“变差”了吗?解析感知背后的黑箱
近期不少用户反映Opus稳定性下降,报错增多,超时、延迟上升。这种感知是真实的,但它背后指向什么,值得分开看待。
线上服务的模型从来不是固定实体。它的实际表现受算力调度、批处理策略、推理深度限制等多重因素持续影响,这些参数会随负载和成本压力动态调整。Mythos上线后,资源重新分配可能是原因之一。
但很可能不止于此。部署中的模型并非冻结状态,安全策略更新、行为微调、RLHF迭代都可以在用户毫无察觉的情况下改变模型表现。OpenAI曾多次被独立研究者记录到这类变化,Anthropic同样没有理由例外。
还有一点容易被忽略:用户对“变差”的感知本身就不对称。体验下降比体验上升更容易被注意、被记录、被传播。论坛上集中涌现的抱怨,未必等比例反映实际服务质量变化。
因此,我们目前能确认的是用户感受到了波动;至于根本原因是调度策略、模型更新还是感知偏差,没有内部数据支撑,很难下定论。调度权握在平台手里,用户看到的是结果,机制却始终是个黑箱。
感知时差:你对AI的感受,取决于你站在哪里
这种“黑箱感”并不止于调度机制,它其实贯穿了普通用户与AI之间关系的每一层。
AI正在经历一段罕见而压缩的快速演化期。在同一时间截面上,不同的人正在经历截然不同的现实。我们可能使用着同一款产品,却运行着性能天差地别的版本;用Mythos做安全研究的工程师,和仍用免费版AI写周报的人,他们的答案都真实,只是对应着完全不同的接入时刻和使用深度。
这是AI扩散方式决定的。它不是广播,不会同时抵达所有人。它先进入少数人的工作流,再渗透进更多人的系统,最后才变成人人习以为常的基础环境。在这个过程中,处于不同位置的人会同时得出截然相反的判断:有人首先看到巨大潜力,于是感到恐惧;有人已经触碰到前沿模型的边界,于是开始焦虑;还有的人仍停留在旧经验里,觉得AI离真正成熟还很远。
这不是认知错误,是时差。很多时候,分歧并非来自判断力的高下,而是来自接触面的不同。