Claude Code 200K上下文自动压缩实战:省下巨额Tokens,告别降智卡死
作为 Claude Code 的深度用户,最近遭遇了 Opus 4.8 在上下文管理与自动压缩上的严重问题:对话会卡死,无法执行压缩。
这件事直击两大痛点——“省钱”与“降智”,不得不深究!

目前问题已大体解决,遂记录成文,分享给同样受困扰的朋友。
1、默认 100 万上下文
100 万 token 的上下文窗口,至今仍是不少厂商的核心卖点,尤其是国产模型逐步支持 1M 后,铺天盖地都是对超长上下文的鼓吹。
但其实 Claude Code 搭配 Opus,早在今年三月就已默认开启了 100 万上下文。
更大的窗口确实能塞入更多历史,减少压缩频率,看似省心。
然而凡事有利必有弊。
上下文拉满会加剧模型降智,并疯狂吞噬 Token;降智拖累项目进度,烧 Token 则直接增加成本。 这是切身之痛!
笔者至少两次遭遇这类坑:一次把上下文推到 75~80 万,模型开始出现弱智行为,一个简单问题反复出错;另一次,缓存超时之后,仅一句请求就烧掉了 40% 的配额,却毫无产出,体验极差!
2、设置成 200K 上下文
从那以后,我开始刻意控制上下文长度,任务告一段落就立即新建对话。
就在此时,Opus 4.8 的更新带来了惊喜:Claude 客户端一度将默认上下文设置为 200K,使用体验极佳——尚未满额便自动压缩,几乎不用人为干预。
可惜好景不长,随后的更新又将配置改回了 1M,策略反复令人困惑。
与其被动适应,不如主动锁定,我决定自行调整参数。
早就听闻有相关变量可供控制,查阅后确认可通过环境变量禁用 1M:
CLAUDE_CODE_DISABLE_1M_CONTEXT=1
为图省事,Windows 下我手动添加了系统环境变量:
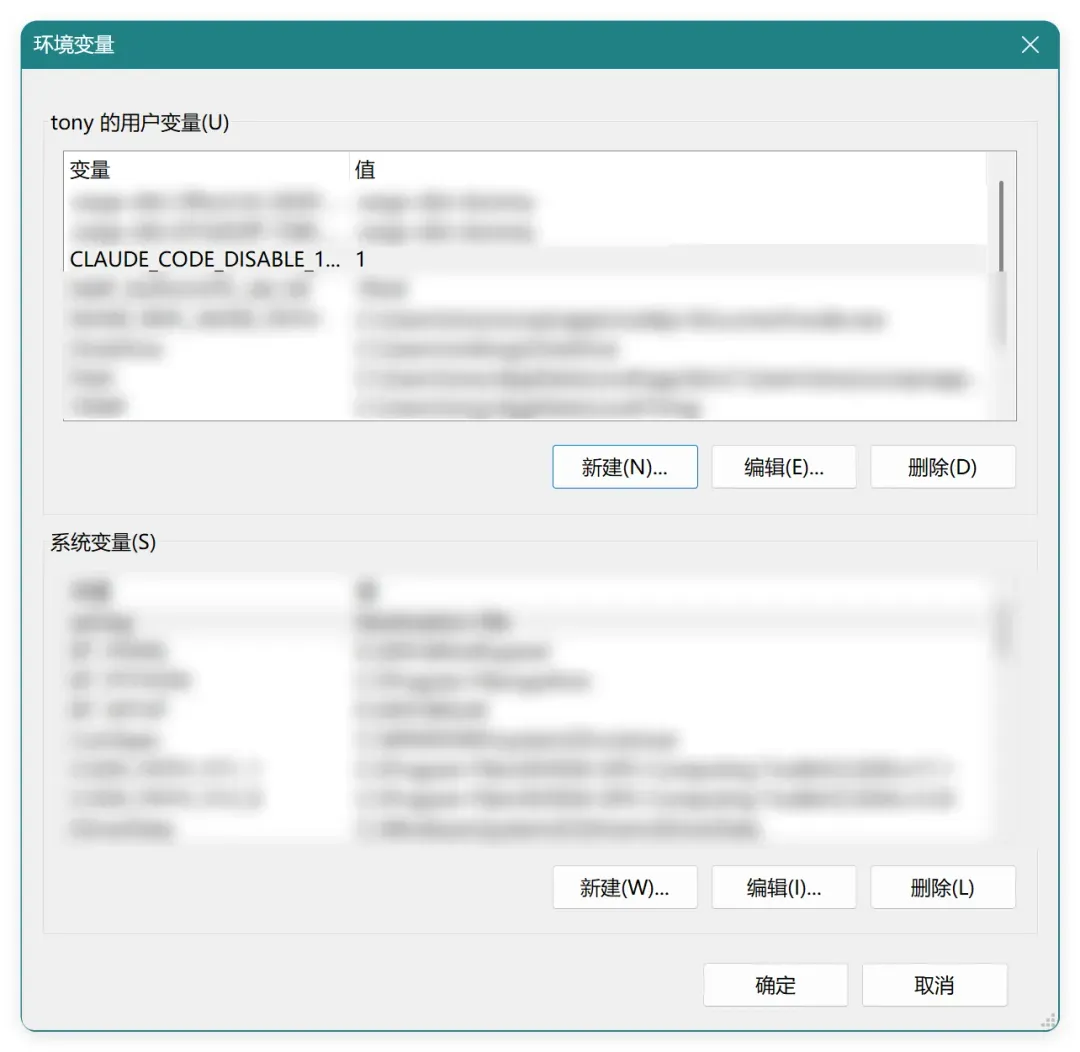
原本以为这样就能高枕无忧,但新问题接踵而至。
从状态信息可见(下图),上限虽为 200K,但实际上下文已被推至 302.9K,明显超限,压缩逻辑显然未生效。
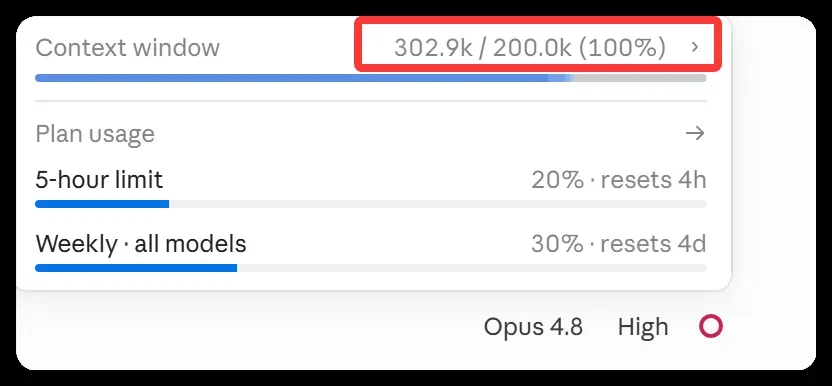
我期望系统在接近上限前就主动压缩,但事与愿违,原因不明。
咨询 Opus 4.8 后,它建议直接修改配置文件 ~/.claude/settings.json,添加如下配置:
{
"env": {
"CLAUDE_CODE_DISABLE_1M_CONTEXT": "1"
},
"autoCompactEnabled": true,
"autoCompactWindow": 200000
}
核心思路:强制 auto-compact 以 200K 作为窗口基准计算触发百分比,而非沿用底层的 1M。唯有如此,压缩阈值才能真正锁定在 20 万。
换言之,仅关闭 1M 上下文还不够,必须显式指定 autoCompactWindow 为 200000,并确认自动压缩已开启(通常默认启用)。
生效注意事项:
- 彻底退出并重启 Claude 进程(不是 Ctrl+R 或界面重载),环境变量仅对新会话生效。
- 通过
/status或状态行核实当前窗口为 200K。 - 当对话长度接近 200K 时,应在 64%
75%(约 130K150K)自动触发压缩,不再冲破上限。
3、自动压缩
这一次,由 Opus 4.8 亲自读取文档并自行配置,本以为万无一失,可现实再度打脸。
虽然上下文稳稳卡在 200K 以内,但当占用率达到 85%(约 170K)时自动压缩启动,随即陷入长达 16 分钟的压缩僵局,近乎卡死。
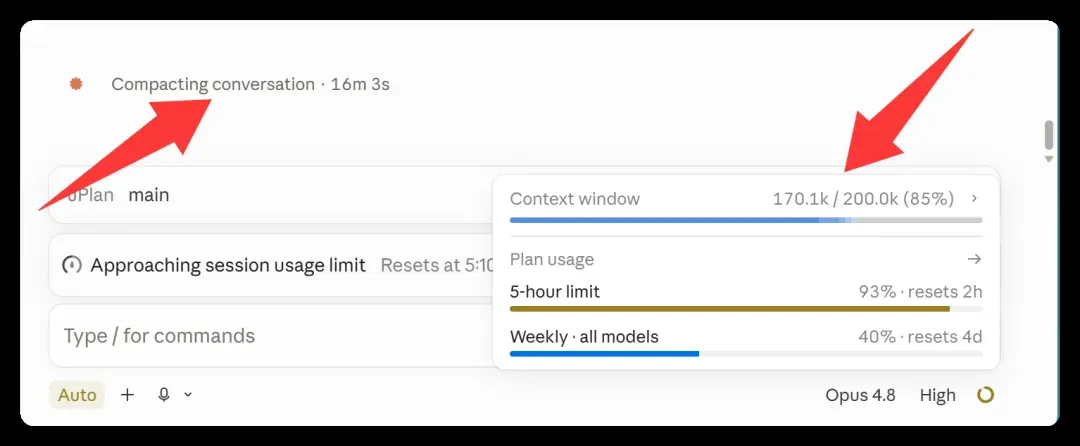
更糟糕的情形是:系统直接停摆,丢出一句“上下文过长”,建议压缩或开启新会话,但点击压缩又会立刻卡死。
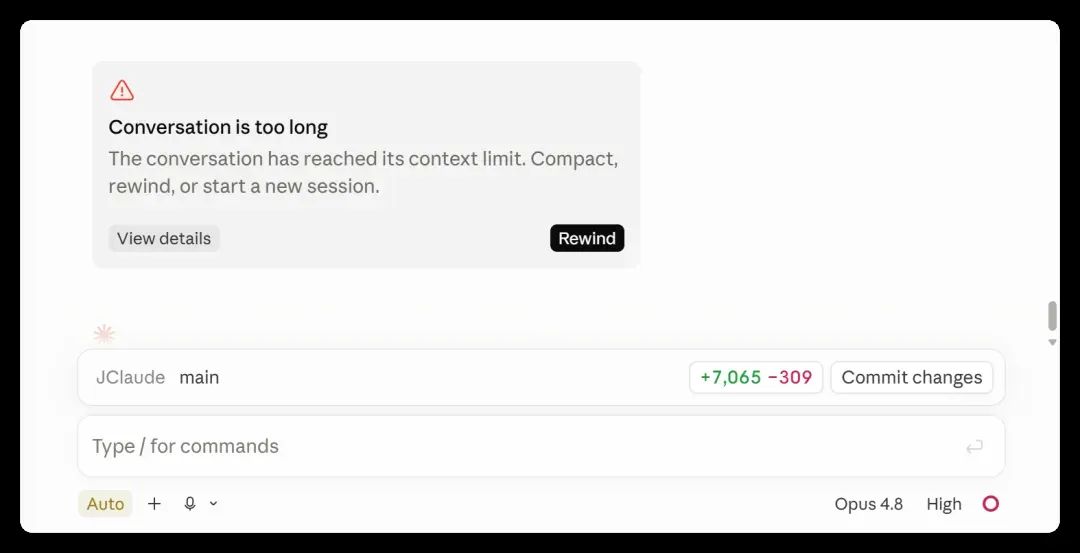
终端中的表现也类似,虽然能看到压缩比例,但总是在 83% 占用率触发自动压缩后,进度条从 0% 爬到 95% 便再不前进。
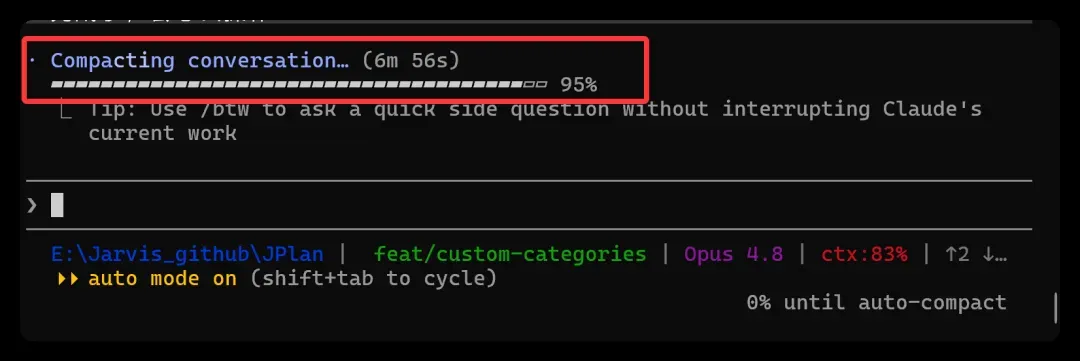
开发到一半的任务因此被迫中断,上限已至却无法压缩,左右为难:要么退回 1M 上下文,要么重启会话——实在不甘心!
高度怀疑这是某种 bug,遂向 Grok 求证,反馈表明不少人遭遇相同问题,并给出三套应对方案:
- 立即中断:按 Esc 两次尝试回退若干条消息,再执行
/compact;若卡死则 Ctrl+C 中断操作后手动压缩。 - 重启会话恢复(被誉为最有效的 workaround):彻底关闭终端,使用
claude --resume重开对应会话,立即切换模型至 Sonnet 4.5 或 Haiku 4.5,发一条简短消息,成功压缩后再切回原模型。大量用户证实此法可强行通过压缩。 - 主动预防:上下文达到 60%-70% 时及早手动
/compact,避免自动触发;用CLAUDE.md固定核心规则(压缩时优先保留);定期/clear并手动总结要点,或导出历史新建会话;减少让模型输出巨型日志,必要时借助工具过滤。
因为担心 Esc 影响代码逻辑,我未尝试第一种。后续查阅得知,回退仅撤销消息记录,不影响代码文件。
果断选择第二种方案,Grok 将其称为“最有效的 workaround”——说白了就是“骚操作”。
实践效果立竿见影:Opus 4.8 压缩半天无果,切换到 Haiku 4.5 后瞬间完成!
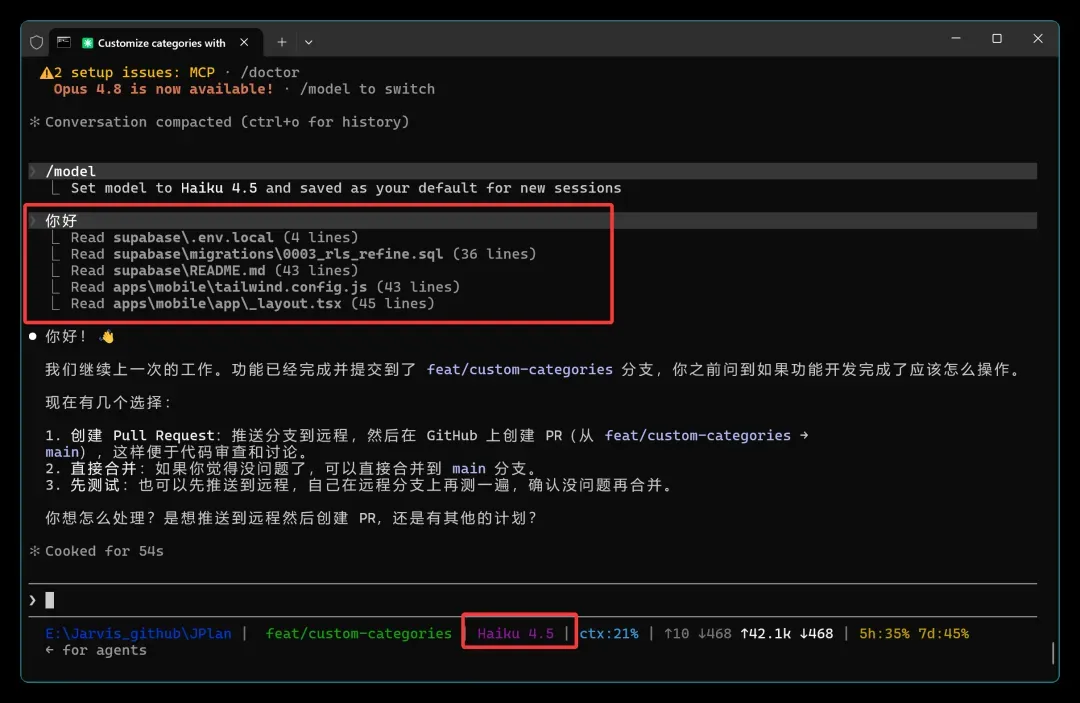
重新切回原模型,对话顺利接续,配额仅损失 2%,完全可接受。
同时,Grok 也建议提前手动压缩,避免等到自动触发。
问题看似解决,然而不禁感叹:前些日子明明丝滑无比——无需手动配置 200K,也无需操心压缩,全流程自动推进,既不降智消耗也极低……
4、补充知识
压缩过程本身也引发几个疑问:压缩究竟是在本地完成再上传摘要,还是全程在服务端计算? 是否需要联网?单次压缩会消耗多少 Token?
查询后确认,压缩依赖网络,属于服务端操作:Claude Code 的上下文压缩(/compact 或自动 compaction)由 Anthropic API 执行,系统将当前对话历史发送至服务器,由模型生成总结,随后用总结替换旧历史。离线状态下无法压缩,会报错或卡死。
Token 消耗方面:
- 一次 compaction 的额外开销:通常在几千到几万 Token(输入+输出)。
- 典型场景:输入约 150K
180K Token 的历史,输出一个 3K5K Token 的摘要。 - 该部分会计费或占用配额。
压缩后,后续每轮对话的输入 Token 大幅减少,长期看来能显著节省成本,但单次压缩本身代价不低,频繁触发时更甚。
精打细算并不容易:不压缩会导致 1M 窗口下的高昂成本,而 200K 频繁压缩同样不便宜。
这恰如缓存寿命的选择:1 小时缓存与 5 分钟缓存,各有消耗侧重点。
若采用 5 分钟缓存 + 1M 上下文,一旦节奏失控,配额瞬间见底!
理论上的最优解或许是定时触发轻度交互以延续缓存,例如每四分钟发送一条轻量消息。
不过,锁定 200K 后心理负担减轻许多,即便缓存过期,重新加载的数据体量也小得多。
如此设置下使用一段时间,搭配 Opus 4.8 High 模式,感觉非常耐用。一个上午修改大量功能,仅消耗 50% 配额!
十几轮对话跑下来,不禁怀疑 Claude Code 是否引入了黑科技,或者默默扩容了配额——毕竟过去经常两三回合就耗尽。
当然,更可能的原因是上下文和缓存管理得当,节奏踩得准,大量命中了缓存!