Claude官方Office四件套Skill完全指南:替代插件的更优选择
之前我们介绍过安装Codex后必装的5个插件,有读者反馈在插件商店中无法找到这些插件。其实不必纠结,Claude官方推荐的Office四件套skill是一个更成熟的选择,实际体验甚至比那些插件更顺手。本文将逐项解析这四款技能工具,并提供完整的下载与使用思路。
首先,如果你确实想继续使用插件,但又搜不到,直接把我整理好的版本拿过去就好。虽然成因难以解释,但解决起来很简单:把文件放入对应目录即可。

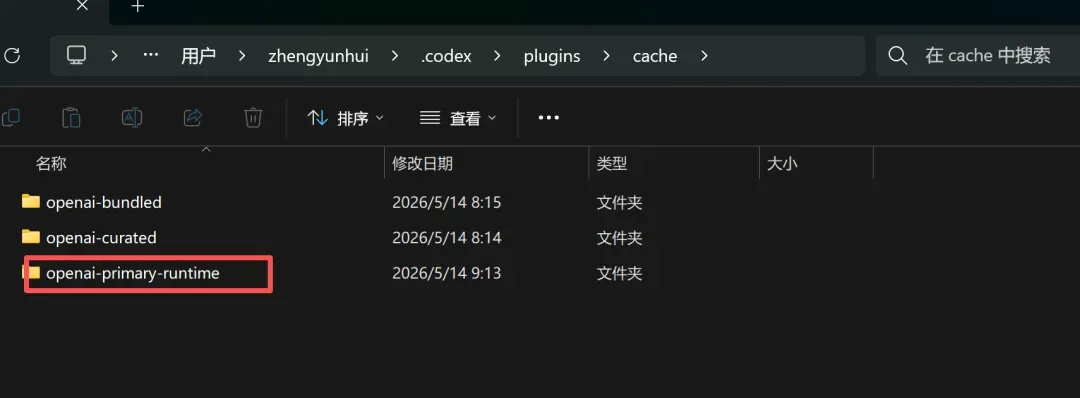
解压后,复制到 .codex\plugins\cache\openai-primary-runtime 这个文件夹内,插件就能正常工作。
不过,其实完全不必焦虑。因为备选方案不仅存在,而且更好——那就是安装Claude推荐的Office四件套skill。

经过我自己的多轮测试,这套skill的整体表现明显优于Codex的Office插件。以Excel处理为例,可以直观看出差距。
Codex上的对应模块叫spreadsheets,我研究后发现它主要通过Node.js来操作表格。

Claude的skill名为xlsx,核心则是用Python注入逻辑。
两者选用了不同的技术路线,但就实际任务而言,xlsx所生成的表格在排版上更加合理,单元格该合并的会恰当地合并,重点数据也会自动突出显示。而spreadsheets面对复杂表格时常难以保持结构,合并后的单元格内容甚至会丢失。由于涉及的文件不便公开,就不上对比截图了,但结论非常清晰:Claude的Office skill做得更细致、更可靠。
Claude Office技能套件的下载与安装
下载地址:https://github.com/anthropics/skills
主要下载以下四项,其余的可暂时不管。
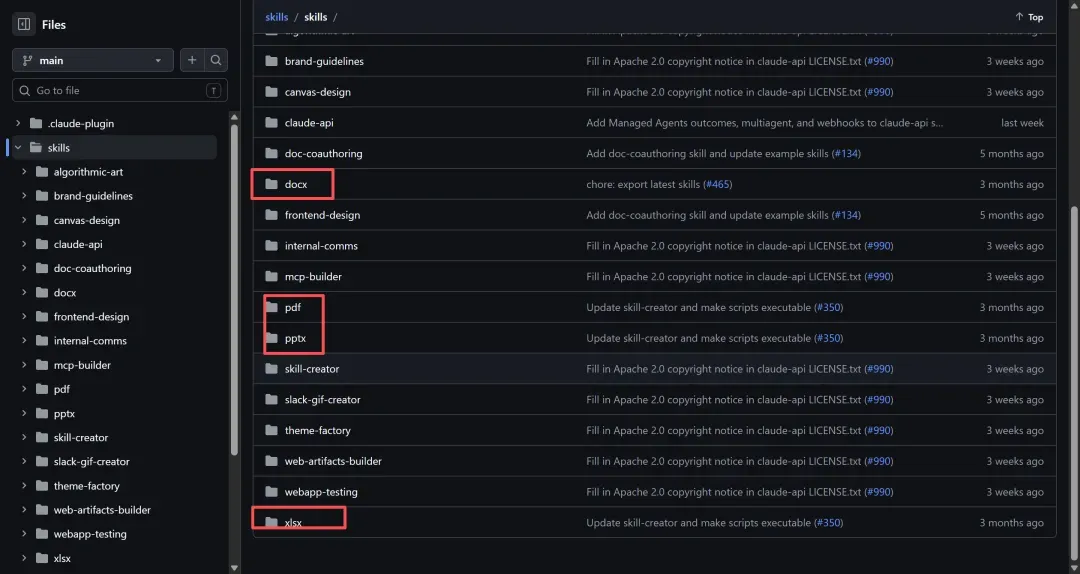
下载完成后,把这四个文件夹放入你的skill库,AI就能自动识别调用。如果访问GitHub有困难,我在前面提到的插件安装包里也已将这四个skill一并打包,可以一并获取。
四大技能详解:能力与使用边界
1. docx:Word文档处理
docx 专门处理 .docx 文件,原理是把Word文档当作一个压缩包来拆解和重组。虽然听起来奇怪,但.docx本身就是XML文件的集合,AI会先解压读取正文、样式、批注、修订记录等信息,按规则修改后再重新打包。
新建文档时,它主要依赖 docx-js 这类Node.js库;读取或转换时则可能调用 pandoc、LibreOffice 或命令行工具辅助处理。
它非常适合处理报告、方案、合同初稿、会议纪要、简历以及模板类文档,尤其在标题层级、页码、表格、目录和页眉页脚这些地方,比普通AI直出要规整得多。
但是,边界也很清楚。包含复杂宏、嵌入对象或古怪模板控件的Word文档,以及严重依赖特定字体和本地环境的排版,它可能无法完全还原。老旧 .doc 格式需要先转换为 .docx。所以它更适合规范文档的生成与编辑,而非神奇修复祖传模板乱码。
2. pdf:PDF文件处理
PDF本质上像一张定型的“纸”,所以处理时不能只抽取文字,还要理解文本的布局、表格边界和图片位置。
该技能会用到Python的 pypdf、pdfplumber、reportlab 等库,也可能借助 qpdf、pdftotext、pdfimages 这类命令行工具。对于扫描件,还会走 pytesseract 和 pdf2image 的OCR流程。
需要特别注意的是PDF的能力边界:如果PDF是文字型(能用鼠标选中文字),提取内容、拆分合并、提取表格、添加水印、填写表单等任务都比较可靠。若为图片转成的PDF(比如扫描件或截图),就只能依靠OCR,此时识别效果取决于图片清晰度、倾斜程度、字体和背景干扰,模糊的合同或盖了章的文件很难完全准确。
另外,PDF里的表格提取并非总是完美,很多表格只是视觉上像表格,底层并没有实际的单元格结构。AI会尽量还原,但复杂合并单元格、跨页表格等仍需人工核对。总体而言,PDF技能适合做资料读取、内容抽取和基础加工,面对扫描件和复杂表格时必须人工审阅。
3. pptx:演示文稿制作
PPT不像Word重结构、Excel重数据,它更看重视觉呈现。AI做PPT最容易出的问题不是“写不出内容”,而是“看着不像人做的”。
这个 pptx skill的思路比较完整:读取时用 markitdown 提取文字,分析时会将幻灯片转成缩略图,编辑时拆解PPT的XML结构,必要时用LibreOffice和Poppler渲染成图片检查效果。新建PPT则使用 pptxgenjs 等Node.js工具。
它的亮点不止于生成,还特别强调检查——文字是否溢出、元素是否重叠、占位符是否意外残留、颜色对比度是否足够,这些都是PPT翻车的重灾区。
但PPT的边界同样明显。AI的审美发挥有时会突然倒退到“标题加五个项目符号”的古早风格,这时候不要绝望,继续让它对照渲染图片反复修订就好。PPT很少能一步到位,人审多修才是常态。
4. xlsx:电子表格与数据处理
xlsx 面向 .xlsx、.xlsm、.csv、.tsv 等表格文件,核心工具链是Python。数据清洗和分析主要用 pandas,Excel文件读写、公式、样式和合并单元格则用 openpyxl。遇到公式计算时,还会调用LibreOffice重新计算一遍,并自动检查 #REF!、#DIV/0!、#VALUE! 等常见错误。
这一点很关键。普通AI做表格常常把数字直接写死,而Claude这个技能强调尽量使用Excel原生公式,而不是用Python算出结果硬填进去。这样一来,后续修改基础数据时,汇总、比例、增长率都会随之联动,更接近“可继续编辑的Excel”。
正因如此,它在数据清洗、统计表、财务模型、项目台账、预算表、报价表和公式校验等场景中比插件更顺手。
但也要认清边界:包含复杂宏、外部数据连接、受保护工作表或极为复杂的透视表的Excel,AI未必能完整维护。尤其 .xlsm 宏文件,可以处理数据格式,但宏逻辑就不要指望完全保留。此外,原始表格如果结构混乱,比如表头跨越多行、合并单元格随意穿插、备注写在数据中间,AI需要先梳理结构,这时务必人工再核对一遍,因为Excel里错一个单元格就可能导致连锁错误。
使用时的几点建议
这四个技能安装后基本无需额外配置,在任务中指名调用或让AI根据文件类型自动识别即可。真正要留意的是下面几条。
第一,不要把它们当成万能魔法。它们只是让AI有了更清晰的工具调用路径,并不保证所有文件都能完美处理。
第二,初次运行时可能会自动创建依赖和临时文件,比如下载Python包、Node包,或者用LibreOffice做格式转换,这些都是正常现象,不是异常行为。
第三,重要文件务必先备份。合同、财务表、正式汇报PPT绝不要直接在原文件上让AI操作,复制一份后确认无误再用。
第四,结果必须人工验收。Word看排版,PDF看识别准确率,PPT查文字溢出和元素重叠,Excel核实公式和关键数字。AI能节省大量时间,但最终拍板的责任仍然在你自己。
结语
市面上如Workbuddy等工具也提供了Office处理skill,各种skill库分享的方案层出不穷。但建议就锚定这四件套,不论使用什么环境,都统一调用它们。四处混用反而会让输出质量不稳定,最后容易错怪工具和模型。
以上就是本次分享的全部内容。建议先拿不那么重要的文件练手,熟悉流程后再用到关键任务里。如果觉得内容有帮助,欢迎留言交流你的使用心得。