Claude Opus 4.7 全面评测:编程登顶、视觉飞跃,却染上「不说人话」的怪病
过去一周,Claude 频繁崩溃,果然是在为新品铺路。昨晚十点半,Claude Opus 4.7 如期登场。其热度之高,从我自建的全网 AI 情报监控来看,凡一条消息被三个精选信源同时报道,便算得上重要;五六个信源齐发已属爆款,而 Opus 4.7 竟引来 10 余家信源同步推送,震惊得我一时语塞。
目前该模型已全渠道上线。我于夜里十点半落地,打开手机即发现已可调用。
Claude Code 中也同步更新。
上下文依然保持 1M,不做减法,体验丝滑。最让人满意的是,凌晨三点,我的当周用量额度直接被重置,Anthropic 难得做了一件体贴的事。
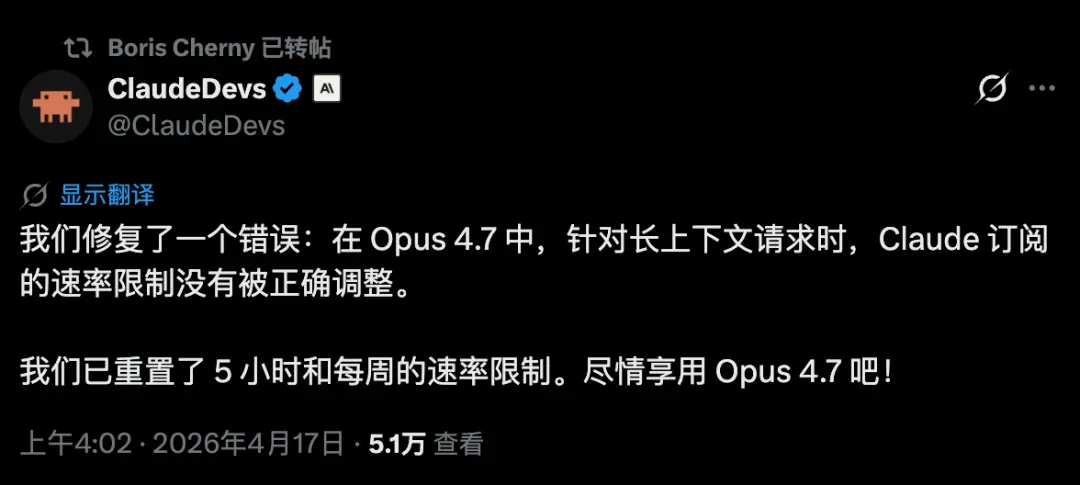
用上 Claude 这么久,总算等来了一回人性化操作。
不少朋友或许会担心 KYC 或身份认证带来的风险。我眼下确实没有稳妥解法,只能视作一柄悬顶之剑。创作能力上实在找不到替代品,能跟 Claude 掰手腕的对手尚未出现,否则我早该换掉了。如今心态便是:用一天算一天,毕竟模型本身足够强大,配合 Claude Code 的 Agent 框架,实在难舍。
说回 Claude Opus 4.7。
定价与 4.6 持平,输入每百万 token 5 美元,输出 25 美元,纹丝未动。
跑分不必细说,行业风气便是「赢者通吃」,该拔高的基准都拔高了,若不全面取胜,厂商也没颜面公之于众。
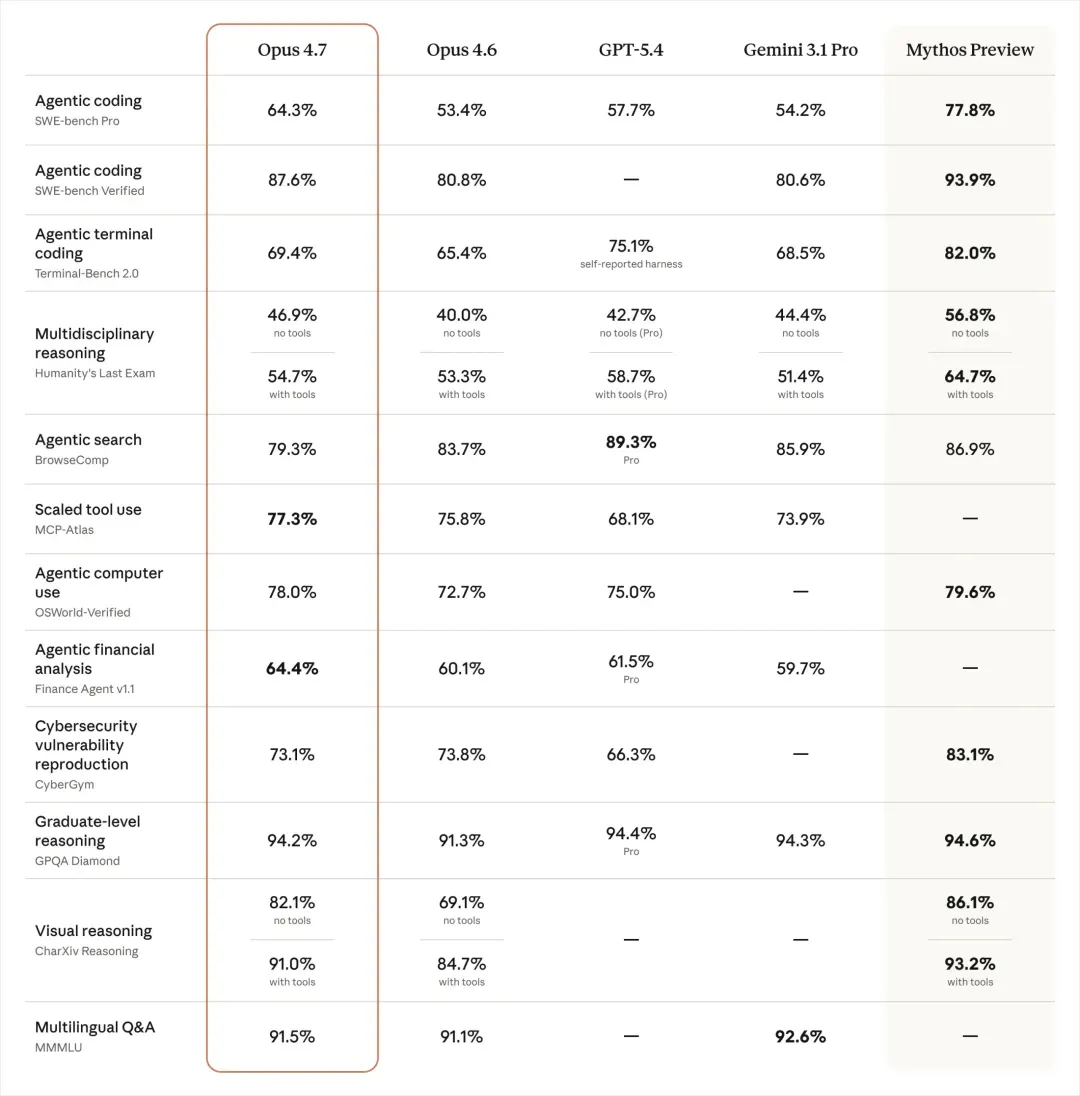
最有趣的是,官方数据表明 Opus 4.6 在多数性能指标上不敌 GPT-5.4,这是 Anthropic 首次坦承其在编程方面略逊一筹。这一结论与我的实际感受吻合:许多反复出现、难以根除的 Bug,GPT-5.4 竟能一一解决;只可惜,它在创作与用户体验设计上堪称灾难,简直是一大坨难以名状的污糟。
Claude 仿佛天生懂我想要的交互,明白何为丝滑的用户体验;而 GPT-5.4 产出的界面,作为设计师的我实在用不明白,活脱脱像是给黑客准备的暗网后台。
创作能力几乎为零。在影视圈,大部分编剧都依赖 Claude 润色剧本,你很难见到哪位优秀编剧用 GPT-5.4 辅助创作。顶尖创作者们用脚投票,选择不言自明。
这便是显著的差距,Opus 4.5 与 4.6 胜在均衡全面。但此番实测 4.7,感受又添几分异样。
有几个关键更新点,我们一个个来说。
第一,隐性提价:Tokenizer 变更
Anthropic 更换了新分词器。官方博客解释,此举改进了文本处理,代价是同一输入会被切分成更多 token,增幅在 0% 到 35% 之间,视内容而异。

也就是说,同一段代码、文档或提示词,丢给 4.7 会比 4.6 多消耗最多 35% 的 token。效果确实更优,但 token 成本实打实地上涨。尽管 API 单价未调整,同等任务多出三成的 token 耗用量,最终账单难免水涨船高。
官方的说法是,虽然单次请求消耗更多 token,但模型更精确、一次成功率提高,减少了反复修改的回合,总花费不增反降。逻辑上无可指摘,却有一个前提——你的任务恰好是 4.7 擅长的高复杂度任务。若你日常用 Claude 做些提升不明显的场景,比如知识管理、方案创作或数据分析,很可能只是白白多烧了 token。残酷的现实是,顶级模型的 token,已然成为这个时代愈发金贵的资源。
第二,视觉能力飞跃式提升
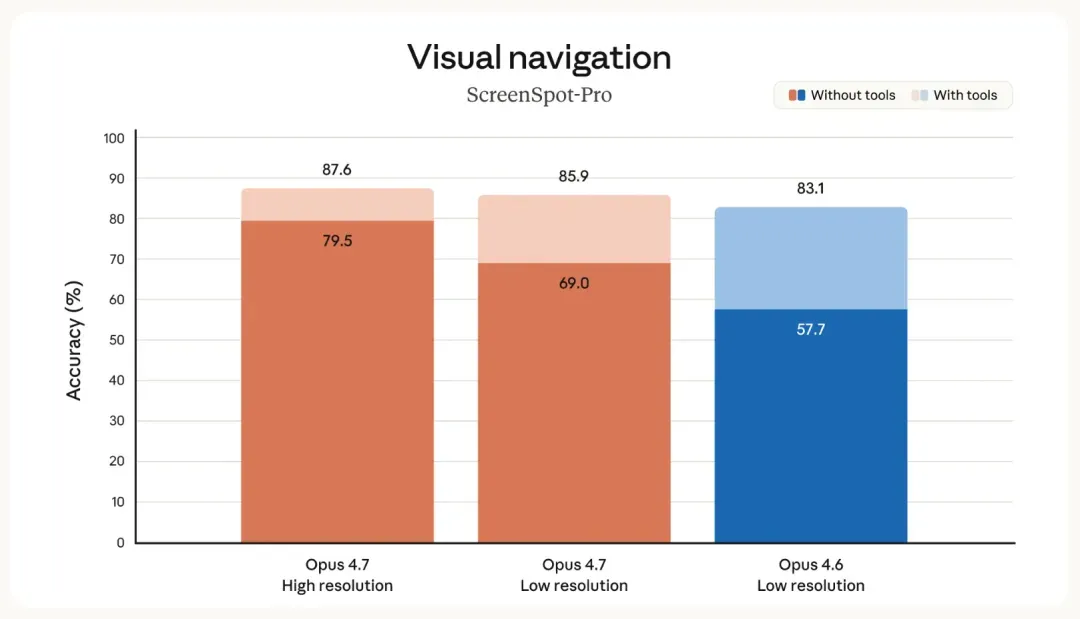
此前提及的 XBOW 视觉测试,4.6 得分 54.5%,4.7 骤升至 98.5%。这家 2024 年成立的公司,专注让 AI 担当白帽黑客,进行自主渗透测试,今年三月刚获 1.2 亿美元融资,是该赛道领跑者。他们考较模型的视觉能力,因为渗透测试要求 AI 理解纷繁复杂的浏览器界面、管理后台、开发者工具中的网络请求与报错弹窗等,画面信息密度极高,视觉差一点便会功亏一篑。4.6 仅略过半数的识别准确率,到 4.7 近乎完美通关,这项跃升的价值不容小觑。
究其根本,除了多模态能力进步,还因为 4.7 支持更高的图像分辨率,最长边可达 2576 像素,约 375 万像素,是旧模型的 3 倍以上。Anthropic 自己的视觉基准测试同样显著提升。
从前我时常偷懒,直接抛给 4.6 一张截图,告诉它「这里有问题」或「数据不对」。它大概能领会意图,细节却常常辨不清。结果错误频发,我们一个信息密集的网站就是典型案例,各类卡片布局和兼容逻辑,当初跟 4.6 反复沟通了许久。
反复修改中,文字识别错误更是家常便饭。如今再测,识别错误近乎绝迹。这对知识工作者堪称强力增益。可以畅想:律师丢给它几十页合同扫描件,它能准确抓取日期、条款编号与金额;分析师给一份年报 PDF,它能逐根解析每一条柱状图数据;产品经理甩一堆竞品截图,它能逐一分析界面组件。这一升级诚意十足,多模态能力明显加强。
第三,审美意识大幅进步
过去涉及用户体验与美学要求时,4.6 给我的感觉总是不尽如人意,比上不足比下有余。与 Gemini 的差距肉眼可见,视觉效果时常糟糕,交互设计呆板,往往以完成任务为导向,而非以用户为中心。为此,我被迫在 CLAUDE.md 里塞进大段限制指令。

而这次受益于多模态能力,我用 4.7 顺手搭建了此前搁置的公司招聘网站,效果出乎意料。眼下我们急需人手,正疯狂扩张,恰好需要这样一个页面。我只口头描述了需求,没有启用任何 Skill,甚至连 Frontend Skill 都删掉了。
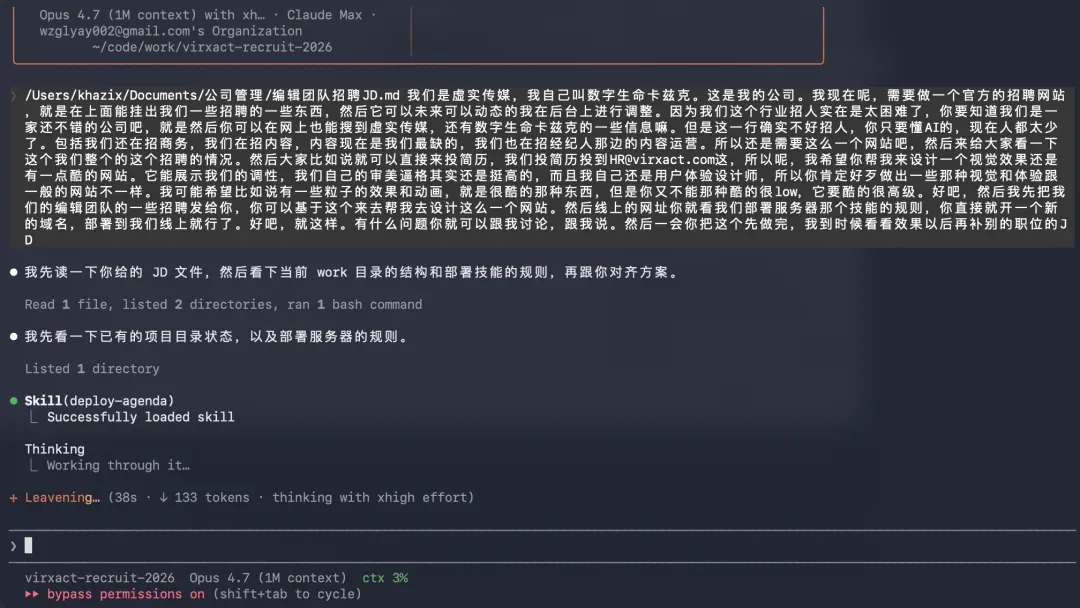
它照常列出计划,随即动工。
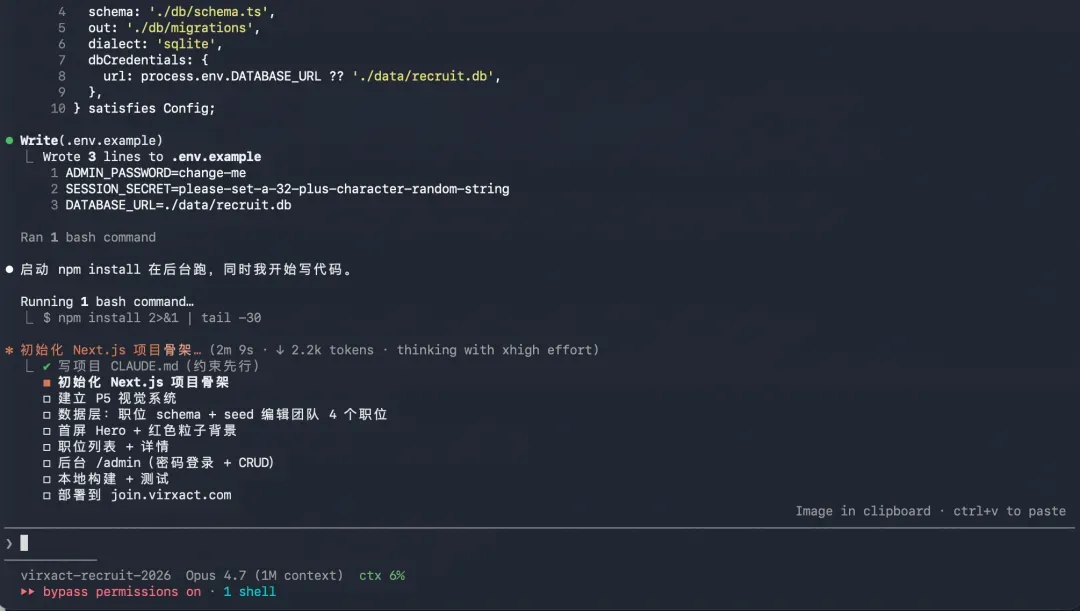
首轮产物已基本可用,我又微调两轮,添上 logo 与其余职位信息,前后仅 20 分钟便打造出一个像模像样的招聘站。

我自己还是相当满意的。


第四,开始「不说人话」了
这是最让我失望的一点。我平时大量使用 Claude 进行知识管理,无论是辅助创作、搜集资料、撰写报告、制作 PPT 或策划方案,4.6 的文字品味都无可挑剔。反观 GPT-5.4 以及国内诸多模型,纯粹为编程而生,人味儿荡然无存,GPT-5.4 尤其如此。此前我无法忍受 GPT-5.4,正因为其满口废话,网上有个案例能完美诠释。
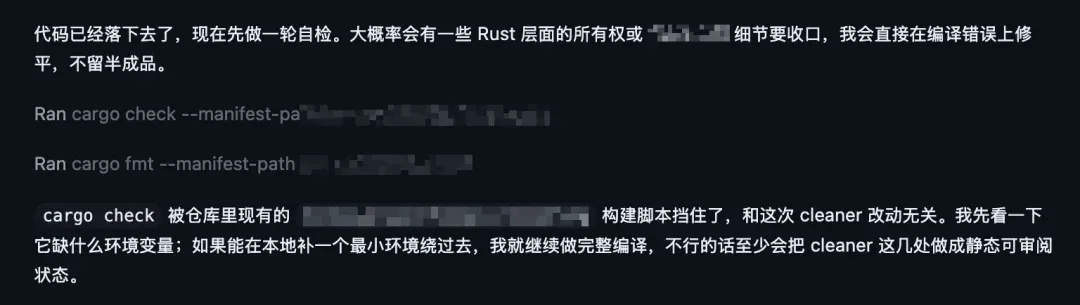
什么「稳稳接住」「根因」「按这条切」「收口」「压实」之类的黑话,懂的都懂,令人头痛。
这次用 4.7 开发招聘网站时,不好的征兆闪现。我对文字一向敏感,瞥见这几句时,PTSD 瞬间被激活。

「再也不会撞」「不会爬到logo头上」,外加莫名冒出的破折号,差点把我逼应激。
随即我让它用同一文风续写昨天的文章,心凉了半截。

狗屎,真是一坨狗屎。一股伪人的气味迎面扑来,我真服了,好好的 Claude 怎么也说开了胡话。
搜了搜社区,果然,我不是孤例。
说实话,心态有点崩了。
第五,若干新功能
Claude 原有的 effort 档位分为低、中、高、最高四档。4.7 在「高」与「最高」之间新增了「xhigh」(extra high),填补了两者间的空白。此前 Max 档位过于烧钱,High 档偶尔又显笨拙,如今这个中间值被设为默认,恰到好处。

另一项是 /ultrareview 命令,这是 Claude Code 中的全新代码审查工具,能逐行扫描代码,揪出所有 Bug 与设计缺陷。它可不便宜,单次运行可能花费 5 至 20 美元。Pro 及 Max 用户享有 3 次免费试用额度,价格确实不菲。
接着是 Cyber Verification Program。这或许是最易被忽略、却最值得关注的亮点。Anthropic 开通了正式渠道,允许合法的安全研究、渗透测试与红队演练者申请使用 Claude 原本受限的能力。申请入口设在 claude.com/form/cyber-use-case。
背景是,以往白帽团队想用 Claude 进行漏洞研究或渗透测试时,常被系统一刀切拒绝——模型无法分辨恶意与合法,为保安全一律封堵。如今 Anthropic 表示,合法从业者可提交申请,经特殊审核即可定向开通。
AI 行业正步步走向这一模式。当初 Claude Mythos 过于强大,不敢轻易向大众开放,唯恐酿成事故。然而,全拒与全开之间,需要身份核验与分级授权的中间地带。这一思路一旦跑通,后续将在医疗合规研究、金融模拟攻防、生物合规用药乃至军工合法研发等场景大量复用。在我看来,这是一个具备长远产业价值的设计。
Claude Opus 4.7 的评测就到这里。编程与视觉能力的提升令我欣喜,但一个曾经文字品味出众的模型,又一次在「不说人话」上栽了跟头。说实话,我现在也有种被稳稳接住的无力感。三年了,从 GPT-3.5 一路走来,我亲眼看着这些模型一个个变得更聪明、更能打,基准测试不断刷榜,SWE-bench 居高不下。同样这三年,我也眼睁睁看着它们挨个丧失说人话的能力。所有公司都在疯狂卷编程,编程,还是编程。我并非否认编程的价值,我自己是 Claude Code 的重度用户,公司内部半数工具都由我用 Claude Code 亲手搓出,编程能力对我至关重要。但一个模型,不该只是一个编程工具。语言,是人类一切智力活动的根基。一个好的语言模型,理当能写小说、作诗、写散文,能陪伴你聊深夜三点那些难眠的心事。可如今的大模型,仿佛除了代码便所剩无几。或者说,一切非量化的、缺乏直接商业价值的能力,都在无声中退步,被系统性地牺牲了。这事,真的挺悲哀。