Claude Opus 4.7 深度拆解:视觉能力换代,长任务执行不再掉链子
4 月 16 号,Anthropic 发布了 Claude Opus 4.7。
第一眼看过去,我也只是扫了一眼 benchmark 表格,心想大概又是例行更新。
但真正把官方公告、232 页系统卡,以及十几家合作企业的真实使用反馈全部啃完以后,我发现——这次的升级远不止常规迭代。
不是那种"比上一版强了一点"的改进,而是"某些能力直接跃迁到新层级"。
我自己使用 Claude Code 做日常开发已经超过半年,Opus 4.6 一直是主力工具。看过这次升级的全部数据和一线反馈后,我觉得有必要认真梳理一下。
本文不堆砌数据,只聚焦三个最值得你关注的核心变化,最后再聊聊谁该立刻升级,谁可以缓缓。
第一个关键变化:视觉能力不是"优化",是"代际跨越"
先说一个让我瞬间清醒的数字。
安全公司 XBOW(专注自主渗透测试)给出了一份视觉敏锐度基准测试的结果:Opus 4.6 得分 54.5%,Opus 4.7 直接跃迁至 98.5%。

XBOW 原话是:“We effectively eliminated our single biggest Opus pain point, and that unlocks its use for a whole class of work where we couldn’t use it before.”
“我们直接消灭了 Opus 最大的痛点,解锁了一整类以前根本没法用的场景。”
你细品这句话——不是"更好用了",而是"以前压根不能用的场景,现在能用了"。
再看 ScreenSpot-Pro,一套专门测试 Agent 屏幕定位能力的基准。测试方式是给模型一张 VSCode、Photoshop 这类专业软件的高分辨率截图,让它精准定位某个 UI 元素。在高分辨率下,目标元素可能只占整张图的 0.07%。
Opus 4.6 得分 57.7%,Opus 4.7 直接飙到 79.5%。叠加工具调用能力后,跑分进一步提升至 87.6%。

为什么会有这么大的跳跃?因为 Opus 4.7 支持的图像分辨率从原来约 100 万像素,直接拉升到 375 万像素(长边最高 2576px),是此前的三倍还多。
三倍的像素意味着什么?意味着以前 Claude 面对一页密密麻麻的 Excel 截图会糊成模糊色块,现在能逐格看清每个单元格里的数字。以前让它识别一个复杂 UI 原型图,细节基本丢失殆尽,现在能做到像素级精准。
这直接引爆了 Computer Use 的能力上限。 视觉是 AI 操控电脑的眼睛——眼睛换了代,手才有可能执行更精细的操作。
Anthropic 官方也毫不避讳,在 SWE-bench Multimodal(结合截图和代码修复前端 bug)测试中,Opus 4.6 得分 27.1%,Opus 4.7 直接达到 34.5%,一口气涨了 7.4 个百分点。

我的判断是:视觉能力的跨越式提升,是这次升级中最值得关注的单一变化。 这不是锦上添花,而是打开了"AI 能看懂屏幕"之后几乎所有的应用空间。
第二个关键变化:长任务执行从"勉强撑住"变成"真敢放出去"
视觉是眼睛换了代,这一项则是整个执行系统换了代。
先看 GraphWalks,OpenAI 推出的长上下文基准测试。将一张有向图塞满 1M token 的上下文窗口,让模型做图遍历。
简单模式(Parents 1M):Opus 4.7 从 71.1% 提升到 75.1%,4 个百分点,正常进化。
复杂模式(BFS 1M):41.2% 直接飞跃到 58.6%,拉开 17.4 个百分点。

17.4 个百分点是什么概念?这意味着在需要多步骤、长链条推理的场景中,Opus 4.7 的稳定性和可靠性与 Opus 4.6 完全不在一个量级。
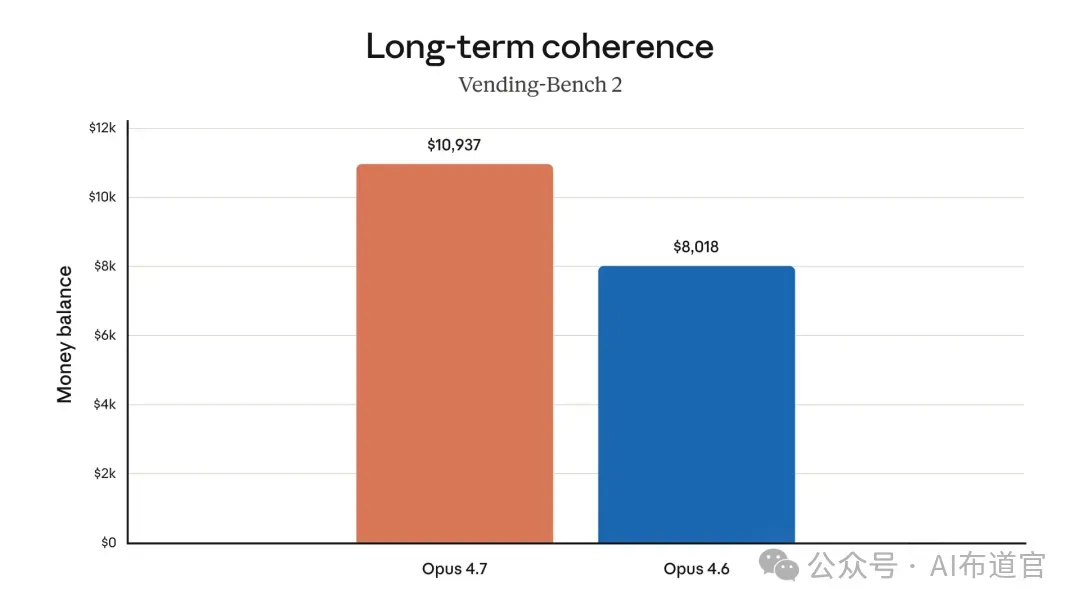
再看 Vending-Bench 2——模拟经营自动售货机,测试长时间工作流中的决策连贯性。
Opus 4.6 最终余额 8,018 美元,Opus 4.7 做到 10,937 美元。同一台售货机,同一个时间窗口,多赚了 36%。
但真正让我确认"这次不一样"的,是合作企业给出的真实反馈。这些内容比 benchmark 有说服力太多。
Rakuten(乐天)反馈:在生产环境中,Opus 4.7 解决的任务量是 Opus 4.6 的 3 倍。代码质量和测试质量均有双位数提升。
Notion 表示:复杂多步骤工作流整体提升 14%,工具报错降至原来的 1/3,且更省 token。它还通过了 Notion 的"隐性需求测试"——第一个做到的模型。
Devin 指出:Opus 4.7 能连贯工作数小时,遇到难题会继续推进而不是放弃。“Unlocks a class of deep investigation work we couldn’t reliably run before.”
Ramp 说:在 agent 团队协作中,角色保真度、指令遵循、协调能力都明显更强。“Needs much less step-by-step guidance.”
Hex 的反馈则更为精妙:“It correctly reports when data is missing instead of providing plausible-but-incorrect fallbacks.” 翻译过来就是:以前模型在数据不全时,会编造一个表面上合理的答案,现在会坦诚告知"数据不足"。
这一点极为关键。 一个 AI 哪怕能力稍弱,但知道什么时候不该回答,远远胜过那种什么都敢信口开河的模型。
还有一个相当有意思的案例——Opus 4.7 自主从零搭建了一个完整的 Rust 文本转语音引擎,涵盖神经网络模型、SIMD 内核、浏览器演示,然后将自己输出的语音通过语音识别器验证,与 Python 参考实现做一致性比对。
Anthropic 形容这是"数月级别的高级工程工作量,由模型自主完成"。
第三个关键变化:对标 GPT-5.4 和 Gemini 3.1 Pro,身位已经拉开

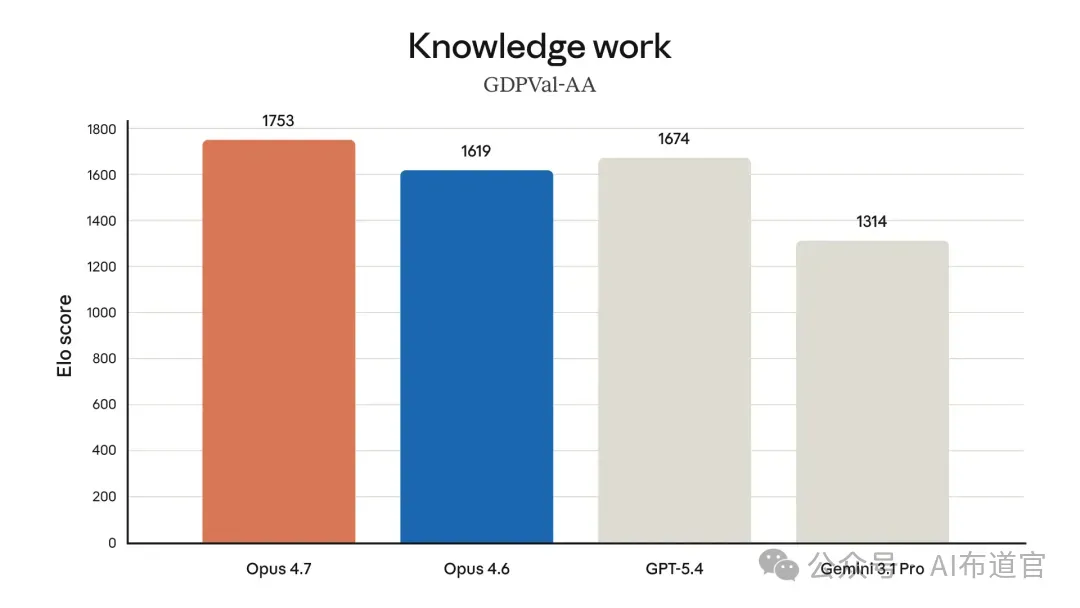
先说 GDPval-AA,Artificial Analysis 基于 OpenAI GDPval 数据集打造的评估。覆盖 44 种知识工作职业、9 大行业,任务来源于平均拥有 14 年经验的资深从业者。
Opus 4.7 拿到 1753,GPT-5.4 拿到 1674,Gemini 3.1 Pro 拿到 1314。
Opus 4.7 超出 GPT-5.4 79 分,超出 Gemini 3.1 Pro 439 分。
再看 OfficeQA Pro,Databricks 打造的企业级推理基准。语料来自近 100 年的美国财政部公报,8.9 万页 PDF、2600 万个数据点。
Opus 4.7 跑分 80.6%,GPT-5.4 为 51.1%,Gemini 3.1 Pro 为 42.9%。
Opus 4.7 是 GPT-5.4 的 1.6 倍,Gemini 3.1 Pro 的 1.9 倍。

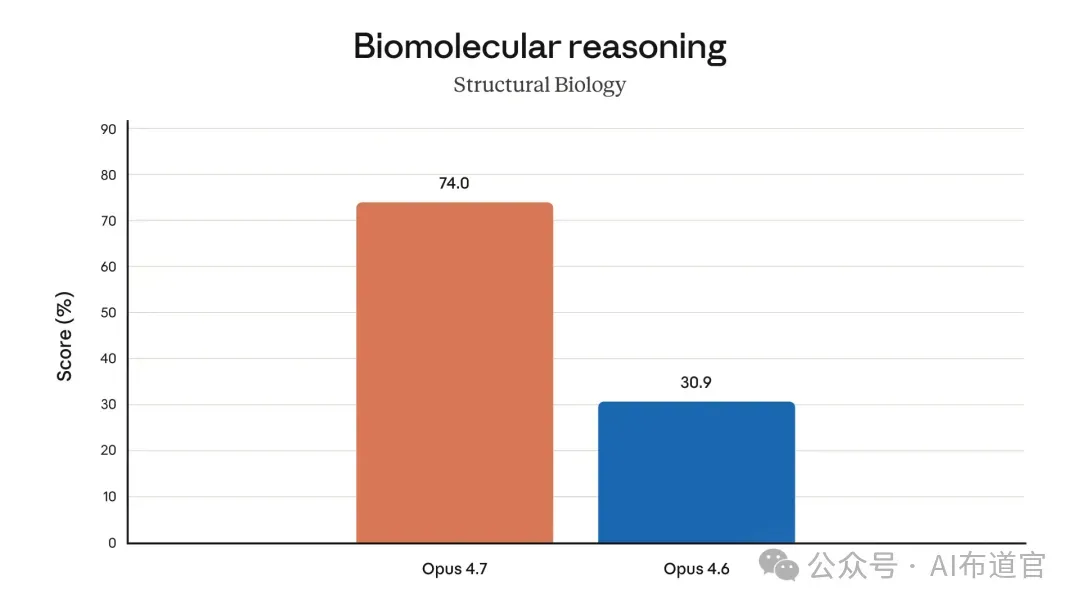
还有一项数据跃升最为炸裂——Structural Biology(生物分子推理)。
Opus 4.6 仅有 30.9%,Opus 4.7 直接跃至 74.0%。一次版本迭代,从三成飙到七成半,2.4 倍。这是所有 benchmark 中跃升幅度最夸张的一项。
当然,公平地说,也有 GPT-5.4 仍然保持领先的领域。Terminal-Bench 2.0 上 GPT-5.4 大约领先 5 个点(不过 Anthropic 补充说明,OpenAI 使用的是自己的定制评测框架,结果不完全可比)。
所以我不说"全面碾压"这种话——确实没有发生。但在开发者最关心的编码、文档推理、长任务执行这几个维度上,Opus 4.7 确实拉开了显著的身位。
但你不可忽略的代价
我非常反感那种只报喜不报忧的写法。所以必须如实谈谈升级的副作用。
代价一:分词器调整,Token 消耗变多
Opus 4.7 换用了新的分词器。同样的输入,Token 数量会增加大约 1.0 到 1.35 倍。高 Effort 下输出 Token 也会随之增加。
对在 Claude 应用内聊天的普通用户而言,这更多体现在额度消耗和响应速度上。但对使用 API 的团队来说,这是实打实需要核算的成本变量。
Anthropic 自己的数据表明,按照内部编码评测来看,各 Effort 级别的性价比是提升的——但你得先调好 Effort 参数。直接无脑迁移不做优化,成本大概率是上涨的。
代价二:指令遵循变强了,但老旧提示词可能翻车
Anthropic 明确表示:以前的模型会"灵活理解"你的指令,可能忽略一些细节,而 Opus 4.7 会逐条严格照做。
听起来是好事对吧?可如果你原先的提示词写得比较粗糙,存在模棱两可的地方,Opus 4.7 可能会理解出一个你完全没预料到的结果。
升级后第一件事:逐个检查你的关键提示词。
代价三:高分辨率图片意味着更多 Token
Opus 4.7 能看更清晰的图,但也会吃掉更多的 Token。如果你不需要像素级细节,传图之前先压缩。这不仅仅是省钱的问题,是费用可能直接翻番的问题。
价格方面
好消息是单价没变:15 美元 / 100 万 input tokens,75 美元 / 100 万 output tokens。与 Opus 4.6 持平。
但坦白讲,这个价格本身就相当昂贵。Token 消耗再增加个 1.35 倍……这笔账你自己算。
同步发布的几个新功能也值得一看
除了 Opus 4.7 本体,Anthropic 还同步推出了几项新功能:
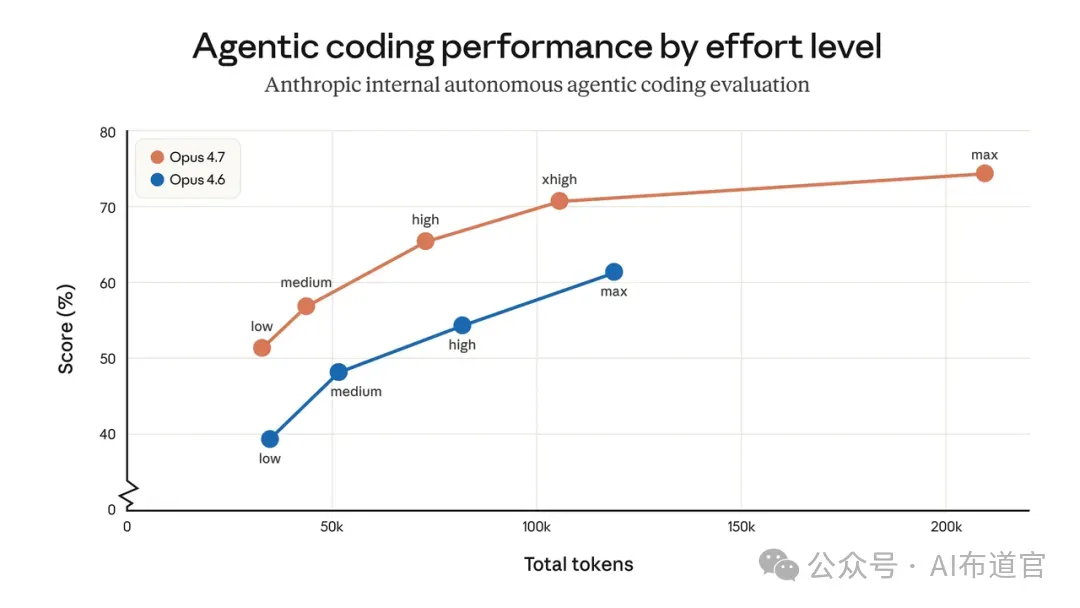
xhigh Effort 级别:介于 high 和 max 之间。Claude Code 中已默认调至 xhigh。对于大多数编码和 Agent 场景,Anthropic 建议从 high 或 xhigh 开始尝试。
Task Budgets(公测):开发者可以控制 Claude 在长任务中的 Token 消耗上限。简单说就是给 Agent 设定一个"预算",防止它无节制跑飞。
/ultrareview 命令:Claude Code 中的新命令,专用来做代码审查。读取改动内容,标记 bug 和设计问题。Pro 和 Max 用户有 3 次免费体验。
Auto Mode 扩展至 Max 用户:之前只对 Pro 用户开放的 Auto Mode(Claude 自主做决策,减少打断),现在 Max 用户也可使用。
安全方面,Anthropic 说得很坦率

一周前,Anthropic 公开了 Project Glasswing,专门讨论网络安全风险。Opus 4.7 成为这套新思路下的首个公开部署模型。
官方明确表达了三点:
- Opus 4.7 的网络安全能力弱于 Mythos Preview——训练时专门做了差异化降权处理。
- 上线时纳入了自动检测和拦截高风险网络安全请求的护栏。
- 合规的安全研究人员可以申请加入新的 Cyber Verification Program。
安全评估结论是"整体上较为可靠且值得信任,但距离理想状态仍有提升空间"。
这个措辞极为讲究——他们没有把发布包装成一次毫无代价的全面跃升。我觉得这种坦诚,反而比那些宣称"绝对安全"的说法更令人信服。
我的判断:谁该立即升级,谁可以再等等
建议立即升级的人群
- Claude Code 重度用户:如果你每天都在用 Claude Code 做开发,Opus 4.7 在编码、调试、长任务执行方面的提升是实实在在的。CursorBench 数据 70% vs 58% 的差距并不小。
- 做 Computer Use / Agent 的开发者:视觉能力的跨越式提升,让 AI 操控电脑的可靠性跨上了一个新台阶。
- 处理大量文档、报表、技术图表的人:375 万像素的图像输入加上文档推理能力翻倍,这是最直接的体验飞跃。
- API 用户:记得做好 Effort 参数调优和 Task Budgets 配置。
建议观望一阵子的人群
- 只用 Claude 聊天处理简单任务的普通用户:日常对话体验差异不大。
- 预算敏感的 API 用户:Token 消耗可能增加 1.35 倍,先在测试环境中跑一跑实际成本再做决定。
- 拥有大量存量提示词的生产环境:升级前务必验证关键提示词的兼容性。
最后的话

Opus 4.7 不是终点。Anthropic 还藏着 Mythos Preview 这个实力更强的模型,尚未广泛发布。
但从 Opus 4.7 这次升级中,你能非常清晰地看到 Anthropic 全力押注的方向:长任务执行、视觉理解、工具协同、少监督交付。
这些能力正在被整合成大模型竞争下一阶段的主战场。竞争的焦点已经从"谁答得更好"转向"谁做得更完"。
对普通用户来说,最直接的感受会是:交代清楚以后,它更容易把事情做对了;看图抓得更细了;产出的内容更能直接上手使用了。
大模型从"会聊天"走向"会干活",这一步又往前迈进了一大截。
而真正能扛起干活任务的模型,从 Opus 4.6,进化成了 Opus 4.7。
参考资料:
- Anthropic 官方公告:https://www.anthropic.com/news/claude-opus-4-7
- Claude Opus 4.7 系统卡(232 页):https://cdn.sanity.io/files/4zrzovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf
- Claude 官方推文:https://x.com/claudeai/status/2044785261393977612