DeepSeek-V3重磅发布:三体级上下文与全球最低推理成本引爆Agent革命前奏
就在不久前,国产AI标杆DeepSeek正式推出了其全新的模型迭代,完整版本号为DeepSeek-V3.2-Speciale (02-2026)。官方披露的核心升级点涵盖多个维度:
- 推理能力实现质的飞跃 - 在数学运算、代码编程、逻辑推演等复杂任务上的表现取得了显著进步。
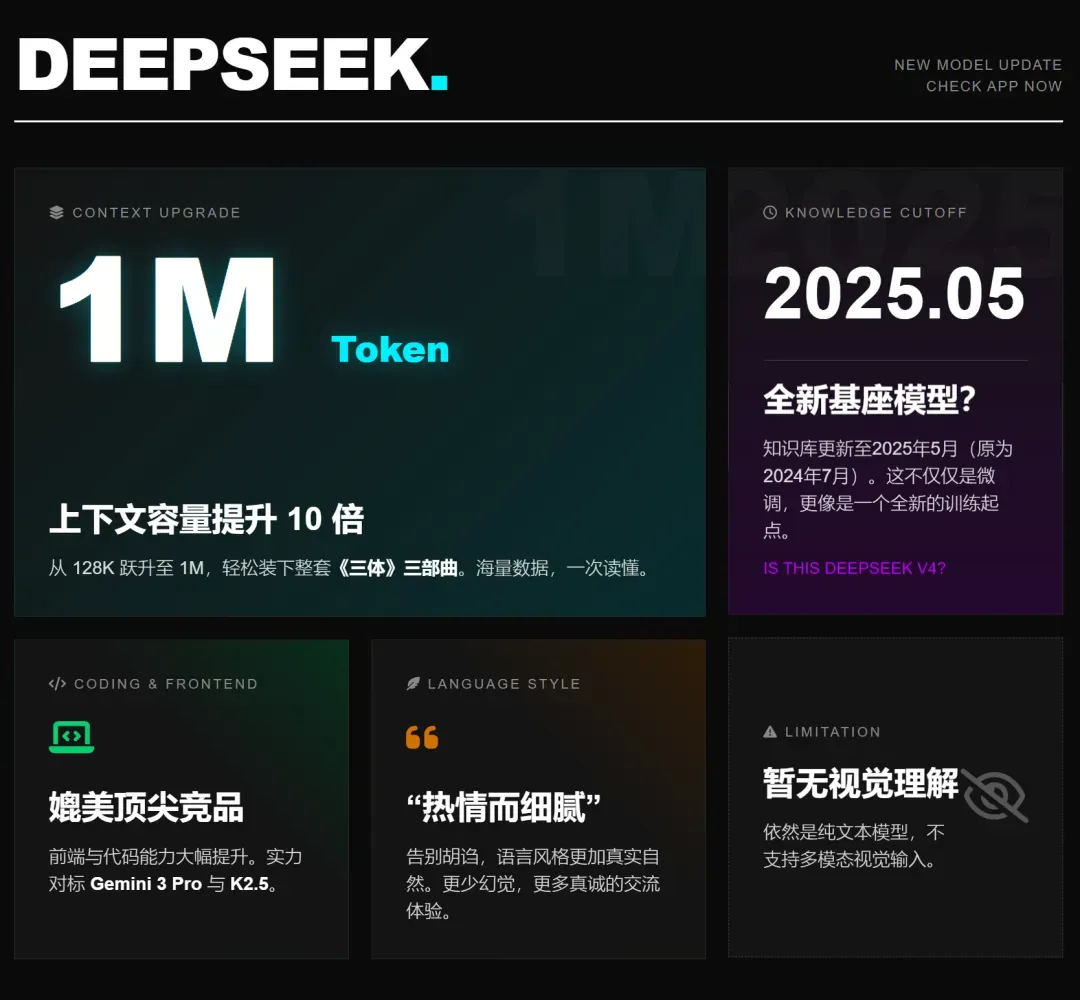
- 知识库完成重要刷新 - 模型的知识截止日期已延伸至2025年5月,确保了信息的时效性。
- 长上下文理解能力精进 - 对多轮、冗长对话的整体脉络与细节把握变得更加精准。
- 回复质量全面优化 - 生成的答案在准确性与条理性上均达到了新的高度。
然而,上述提升仅是基础。真正让该版本在全球范围内引发强烈关注的,是其在关键性能指标上实现的突破性优势:
- 推理成本堪称全球最低,每百万tokens仅需0.14元人民币,在全球主流模型中处于绝对领先地位,其成本仅为GPT-5.1的八十分之一。
- 上下文长度问鼎全球巅峰,支持高达1M tokens的上下文窗口,这意味着模型可以一次性处理相当于《三体》三部曲总和的文本体量。
- 首字延迟速度行业领先,平均首字输出时间小于0.2秒,其流式响应速度极快,用户体验无限接近人类对话的自然停顿节奏。
综合来看,DeepSeek-V3.2的核心标签可概括为:具备顶级推理能力且价格最亲民的模型、拥有最长上下文处理窗口的模型,以及在国内权威评测中位列第一的模型。
这些特性无疑令人振奋,但更深的期待在于另一个维度。正如行业共识所预示,2026年将成为智能体(Agent)技术大规模应用的元年。作为备受瞩目的核心模型,DeepSeek在此次更新中为Agent能力进行了哪些专项优化呢?
回顾历史,模型针对Agent场景的优化通常聚焦于特定能力:
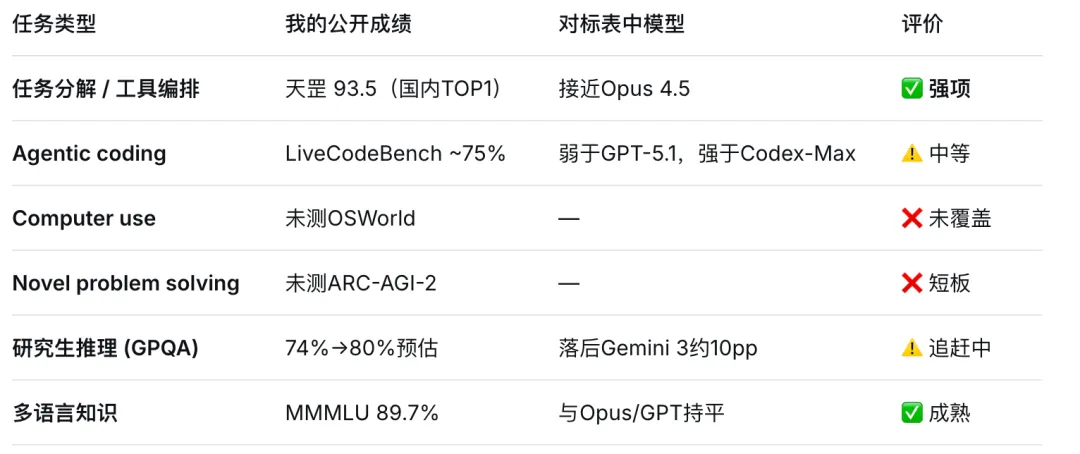
Agent执行任务最核心的两大能力在于“任务分解”与“工具调用”。
根据DeepSeek公布的部分评测数据:
- 在天罡评测体系的“任务分解”单项中,得分高达93.5,稳居国内榜首。
- 在天罡评测体系的“信息抽取”单项中,得分达到93.49,同样位列国内第一。
整体性能可参考下图。不过,目前披露的信息仍显不足,或许需要等待更详细的数据集跑分结果,才能全面揭示DeepSeek在Agent侧所做的深层优化与具体提升: