DeepSeek V4 Flash 本地部署:为什么它是真正的「国产之光」?
看看国外创客和开发者都在用 DeepSeek 做什么?
知名技术博主 Graay Tan 在打造他的人工智能助手 Gbrain 时,日常高频调用的三个模型分别是 Claude 4.7、ChatGPT 5.5 和 DeepSeek v4。
他每月花在大语言模型上的开销接近 2000 美元。
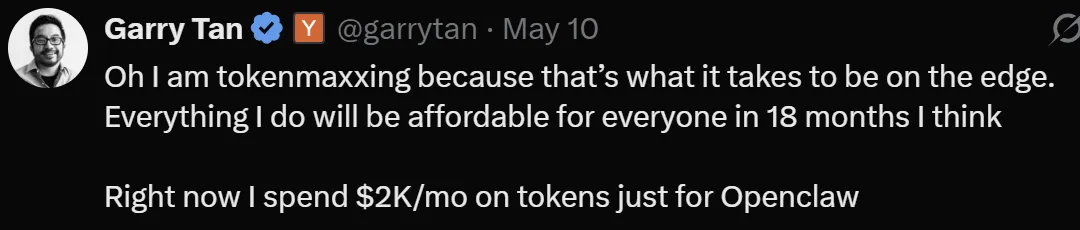
如果所有工作都押注在 Claude 上,成本之高足以让项目直接破产。DeepSeek 则凭借实惠的价格和可靠的任务处理能力,分担了大量日常流水线工作。
再看看海外社区对 DeepSeek v4 Flash 的评价,已经上升到与开源文化相提并论的高度,被视作一次技术普惠的胜利。
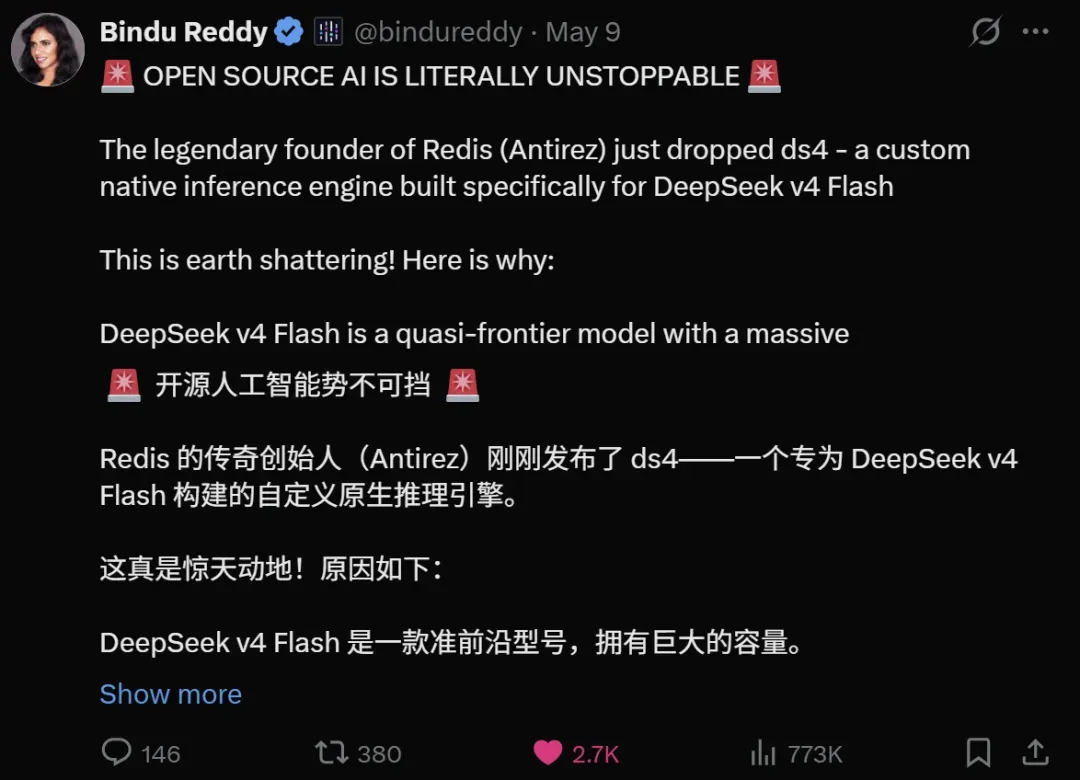
下面我们继续拆解这场讨论的核心内容。
Redis 之父 antirez 最近发起了一个名为 DS4 的项目。
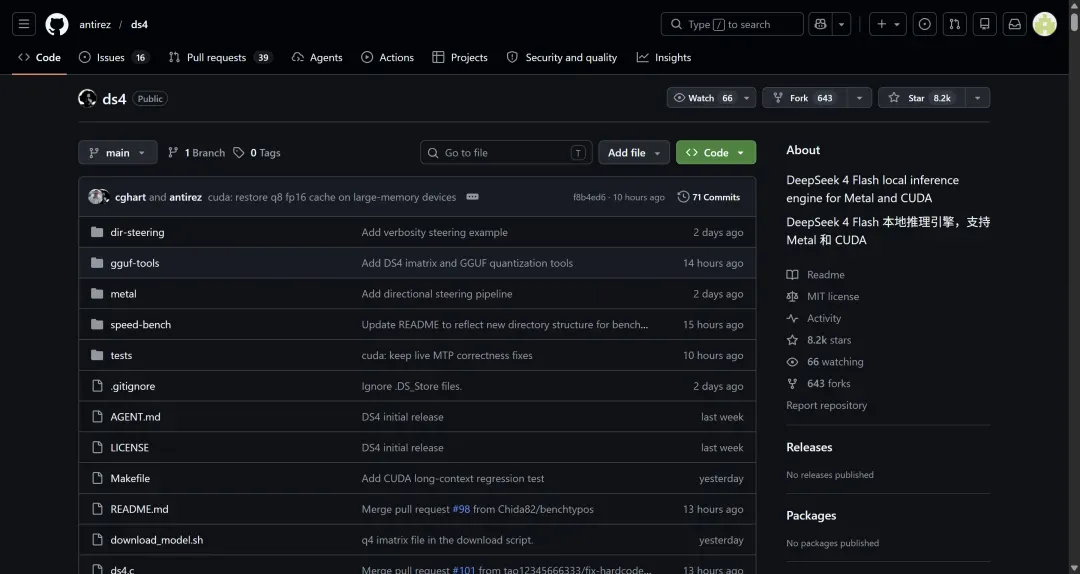
这个项目究竟解决了什么问题?
用一句话概括:它让 DeepSeek V4 Flash 可以在配备 128GB 内存的 MacBook Pro 上流畅运行。
其震撼程度,借用上面那个帖子里的说法,就是“惊天动地”。
很快,那位每月烧掉 2000 美元 token 费的网红 Graay Tan,就宣布自己已经在动手部署了……

对于这类 token 消耗大户来说,一旦完成 DeepSeek 的本地化部署,几乎就等于实现了 “token 自由”。
一台 128GB 的 MacBook Pro 大约 6000 美元,第四个月就能回本,此后全是净赚。
为什么偏偏是 DeepSeek V4 Flash?
原因藏在它的架构设计里:DeepSeek v4 Flash 能够把缓存卸载到磁盘上,推理时激活的参数数量少,对硬件资源的要求十分克制。
可它的输出质量却毫不含糊,配合 100 万 token 的上下文窗口,以及堪比 Claude 的世界知识储备,让它成为本地化大模型部署的第一选择。
这也正是我坚持认为 DeepSeek 才是真正的“国产之光”的理由。
它的意义不仅在于中国多了一款强健的大模型,真正厉害的地方,是它把最前沿的模型能力带到了普通人的机器上。
这一点极其关键。
对于大多数个人开发者和小型团队来说,Claude、ChatGPT 当然优秀,这一点没人会否认。但当你每天要处理几十万、上百万 token 的工作流时,还敢一直开着最贵的那个选项吗?当你决定做一款 AI Native 应用,要把模型能力嵌入到产品里,让用户随点随问、跑任务不计次数,你真的敢把所有成本都押在高价模型上吗?
很多时候,模型实力只占成功的一半,成本是另一半。
成本降不下来,应用就长不出翅膀。应用飞不起来,所谓的 AI 时代就只是少数巨头和富裕玩家的游乐场。普通开发者、中小公司、独立内容创作者,只能隔着橱窗看热闹,最多买个会员,在网页对话框里过把瘾,然后继续退回到传统的工作方式。
DeepSeek 真正撼动的,就是这样一种局面。
看到社区里的大佬们纷纷开始私有化部署大模型,我也被那句“开源终将胜利”击中了。于是兴冲冲地准备自己动手也部署一套 DeepSeek。
可当我打开购物网站,搜了一下 128G 内存的 MacBook Pro 之后,直接败给了现实。
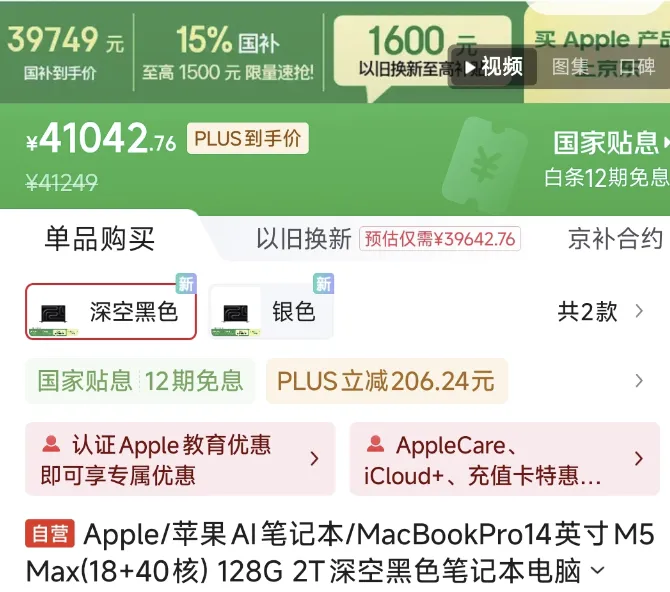
“先帝创业未半而中道崩”,我默默关掉了部署教程,心平气和地重新敲起了字。
但即使如此,我仍然想说,DeepSeek 至少让我们看见了光亮——看见了不被阉割、不降智商的大模型,依然可以在消费级设备上跑起来的真实可能。

只要 DeepSeek 坚持下去,只要梁文锋始终走在这条路上,我就相信,终有一天,DeepSeek 会安静地运行在每一个人的电脑里。