DeepSeek DSPark 推理加速:Token 成本跌至 0.03 美元/百万,智能已廉价到无法计量

一篇论文在 Hacker News 上引发了超过 300 层的热辩。DeepSeek 采用“先猜测、后验证”的推测解码方案,把推理吞吐量提升了 51%–400%,社区同时看到了技术红利、开源驱动力和定价权的历史拐点。
16%–31%
数学/代码任务提升
729
Hacker News 热度分
2-3x
整体推理加速比
DeepSeek 的最新论文 DSPark 一举登上 Hacker News 热门榜首(729 热度分、305 条评论),社区评分达 8.0/10。中文社区也同步热烈转发讨论。有网友翻译成了一句调侃:“你怎么能不喜欢 DeepSeek 呢,感谢温锋大人继续让智能变得太廉价以至于无法计量。”这句话看似玩笑,实则点中了三个层面的实质变化:技术路线在转变,开源策略在迭代,定价逻辑也随之重构。
推测解码并非全新概念,但 DeepSeek 将其打造成了可落地的生产级方案
DSpark 的本质是让一个小模型快速生成候选 token,再由主模型批量验证。这在学术上被称为 speculative decoding,Google 早在 2022 年就提出了框架;Gemma 4 今年也发布了多词预测(MTP)代码,NVIDIA 的 Nemotron 3 Super 同样搭载了 MTP。DeepSeek 的独特贡献在于,它提供了一整套可训练、可评估、可部署的完整技术栈:DeepSpec 开源项目包含了数据准备、草稿模型训练、基准评测全流程,且默认支持 DSSpark、DFlash、Eagle3 三种算法。
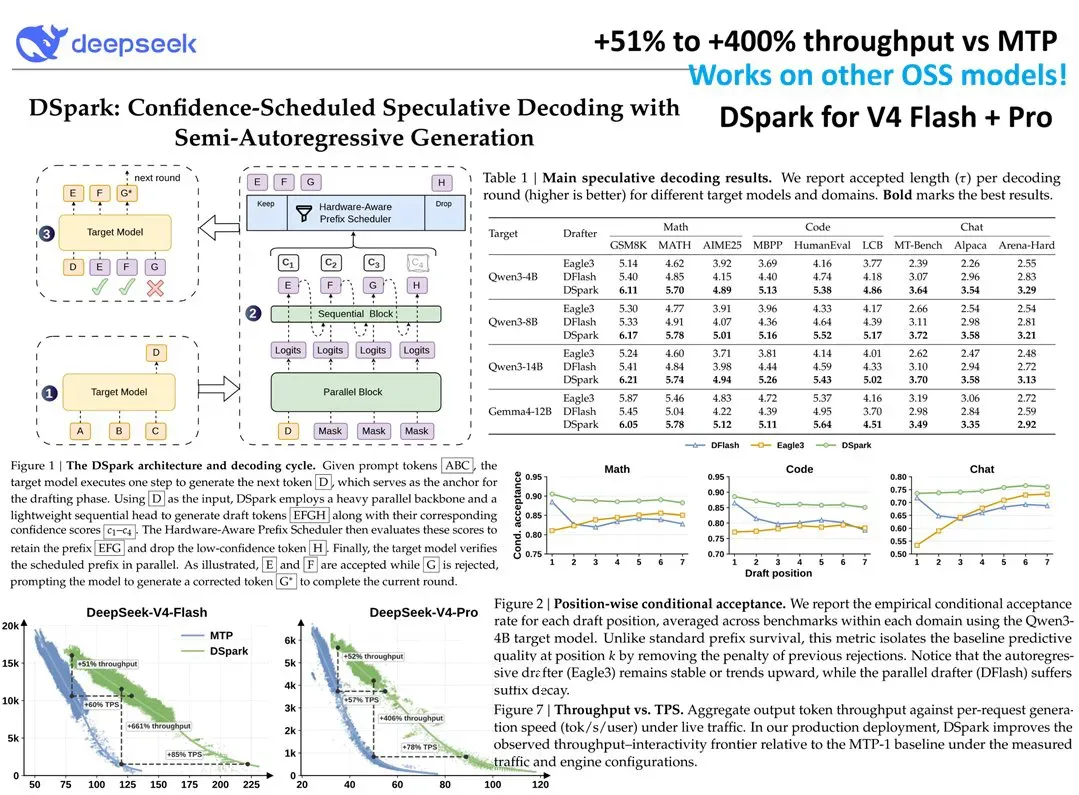
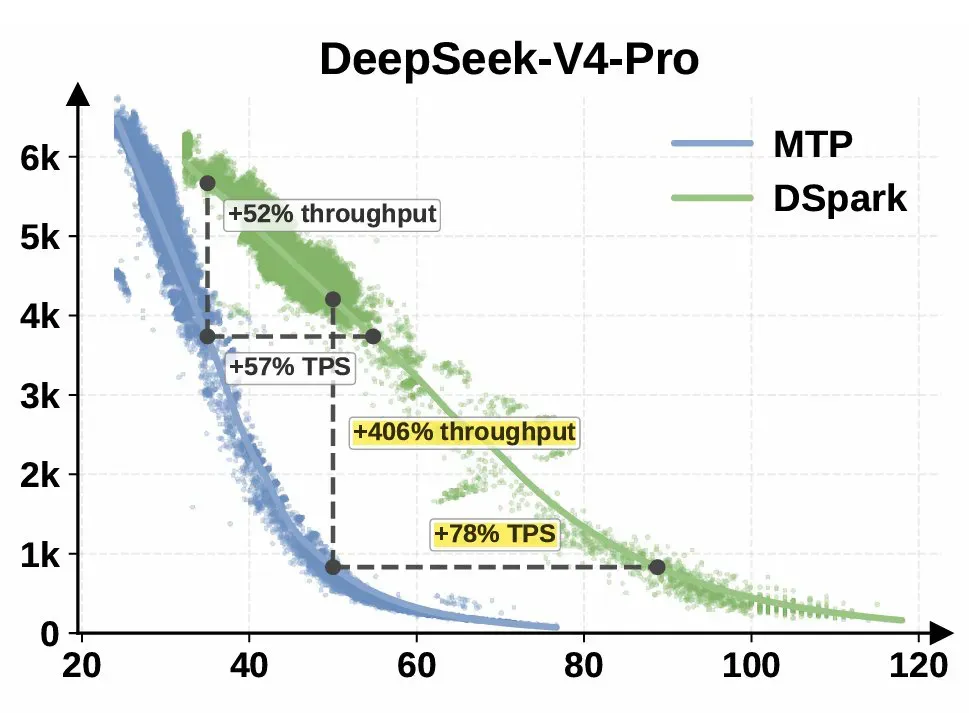
此次发布的特别之处在于,DeepSeek 直接将两种成品模型部署到了 Hugging Face 上:DeepSeek-V4-Flash-DSpark 和 DeepSeek-V4-Pro-DSpark。用户无需自行训练草稿模型,下载后即可使用;官方声明在保证输出质量不打折的情况下实现了更快的 token 生成,整体推理速度提升 2 至 3 倍。对于已经熟悉 DeepSeek-V4 的开发者而言,这无异于一次零摩擦的性能飞跃。
社区中也出现了不同看法。有观点指出,Qwen 3.6 和 Step 更早将 MTP 实现为与主模型共享内部状态的单文件方案,而 DeepSeek 将草稿头放在独立文件中,推理引擎需要额外“粘合”。拥护者则认为分离式设计反而更灵活,草稿模型可以独立替换、独立训练,不受主模型版本约束。这无关对错,只是不同的工程取舍。
● 轻量草稿模型快速预测下一批 token
● 主模型用马尔可夫头批量验证,只修正真正出错的位置
● 置信度不达标的片段回退串行,保证准确率不丢
● DeepSeek-V4 生产环境吞吐提升 51%–400%,不依赖更大 GPU 集群
● Hugging Face 已上架 Flash/Pro 双版本,开箱即用
● DeepSpec 全栈开源(MIT),含训练/评测 pipeline
论文中的基准测试显示,在数学和代码类任务上,DSpark 对比 DFlash、Eagle3 取得了 16%–31% 的提升。与 DeepSeek-V4-Pro 原生推理相比,高负载下的吞吐量改善更加明显,说明这类方法在“长回复、重计算”场景中红利最为突出。
为什么有人评价“让智能变得廉价”
维护一套更高速的推理策略,本质上是在管理供需:同一组 GPU 集群,在相同时间窗口里可以多处理 1.5–5 倍的请求。对 DeepSeek 自身或者下游 API 服务商而言,模型调用的成本都将随之走低。网友那句“让智能变得太廉价以至于无法计量”,描绘的正是这个拐点——当效率提升速度快于单位算力折旧时,按 token 计费的单价终将被市场压到新的低位。
**注意:**提速不等于自动降价,只有当效率增益被服务商明确以折让形式回馈终端,或促成更多调用量摊薄固定成本时,用户端的预算才会真正缩减。
**判断:**DeepSeek-V4 自价格锚定以来,连续数月的技术动作都指向“让赛道更拥挤”。对于 API 用户而言,策略应优先转向“用批处理/缓存承担高吞吐任务,把延迟敏感的工作保留给旗舰模型”。
开源动机:不仅仅是利他主义
Hacker News 评论区针对“为什么 DeepSeek 开源”展开了长达 300 层的辩论。归纳下来,社区普遍接受的三层解释是:
● **芯片约束催生优化:**无法获取顶级 GPU 的实验室,只能在算法效率上寻找突破。限制往往激发更聪明的工程设计。
● **基础设施定位:**DeepSeek 脱胎于量化对冲基金,内部视角是把 AI 当作基础设施而非直接变现产品。ROI 来自交易 alpha,不是 API 收入。
● **市场策略:**开源是最高效的获客手段。假设从不开放,收入可能是 0 而非 1 亿美元。
争论也延伸到了中美实验室的不同文化:美国前沿实验室受资本市场估值压力,倾向于把优化变成壁垒;中国实验室缺少“无限购买 NVIDIA”的条件,开源反而成为构建开发者生态的捷径。Hacker News 上的欧洲用户评价得很直接:DeepSeek 确实在推动前沿研究走向公开,而美国实验室已不像过去那样频繁发布深度技术报告。
真实账单:15 亿 token,40 美元
社区中最扎眼的数字不是论文分数,而是一条用户自报账单:有开发者在 Hacker News 上分享,用 DeepSeek V4 Pro 在 6 月份的 27 天里处理了 15 亿个 token,总成本约 40 美元,已计入缓存命中的节省。这并非实验室的理想条件,而是真实生产环境中的流水账。
细算下来:每 1M token 不到 0.03 美元。这个价格已经把模型调用从“高价值决策”拉成了“基础设施损耗”。再追问“能不能更便宜”已没有意义,真正的问题变成:在你的工作负载里,还有多少环节可以继续迁移到这个价格带上。
初学者如何利用这份红利
● **普通用户:**通过 DeepSeek API 或网页端调用,长文摘要、代码解释、数学推理将明显更快获得响应。
● **轻量级开发者:**从 Hugging Face 直接下载 DeepSeek-V4-Flash-DSpark 或 DeepSeek-V4-Pro-DSpark,开箱即用。想进一步控制 pipeline 可以按 DeepSpec 文档走 3 步:数据准备 → 训练草稿模型 → 评测。
● **团队 / Agent 编排:**多 Agent 链路的串行调用会累积成本,将 DSPark 接入流水线能显著压缩账单。
不适合的人群:如果你从事重度 Agent 长程代码生成、多轮重新规划,或每次决策都需接近 100% 准确率的链路,保留原生强模型更为稳妥。“先猜后验”的策略不应以牺牲质量为代价。
适用场景
高吞吐批处理、长文本摘要、代码解释、数学推理、Agent 多步流水线、成本敏感型服务
暂缓场景
100% 准确率决策链、重度 Agent 长程代码、多轮复杂重新规划、对延迟极度敏感的单步交互
来源
DeepSeek 官方公告; DeepSpec GitHub 仓库; Hacker News 讨论 (aurenvale, 6月27日); Google Gemma/SpecForge 交叉引用.