深入评测:DeepSeek V4国产化实测——算力博弈下的突破与遗憾
等待了整整一年的DeepSeek V4,终于在今天揭开了面纱。
虽然每天翘首以盼,但真正发布这一刻,内心反而涌起一股奇异的平静,仿佛一下子进入了贤者模式。
这周实在太过疯狂——七八个新模型扎堆亮相,单是最近24小时就有四个先后登场。昨天下午刚开始测试MiMo,HY3就来了;刚写完MiMo的体验,GPT-5.5又横空出世;今天好不容易整理完MiMO,DeepSeek V4就踩着节点出现了。
我现在就像那个反复赶稿的博主,一个接着一个,根本停不下来。

我几乎在第一时间就把DeepSeek V4接入了自己的Claude Code环境。
不少人都在问:R2去哪儿了?这里简单梳理一下脉络。去年这个时候,推理模型和非推理模型还是两条清晰的路径,比如DeepSeek R1专门负责推理,V3则是非推理向。但到了后来,像Claude和GPT都转向了混合模型架构,用“思考强度”来控制模型是否进入推理模式。
所以DeepSeek在V3.1时也切换到了混合模型的设计,V4自然延续了这一思路。这样一来,R2的独立定位就变得有些模糊了,就像OpenAI o3成了最后一代独立推理模型,最终被整合进了GPT-5。
我们再来快速过一下DeepSeek V4的几个关键特点。
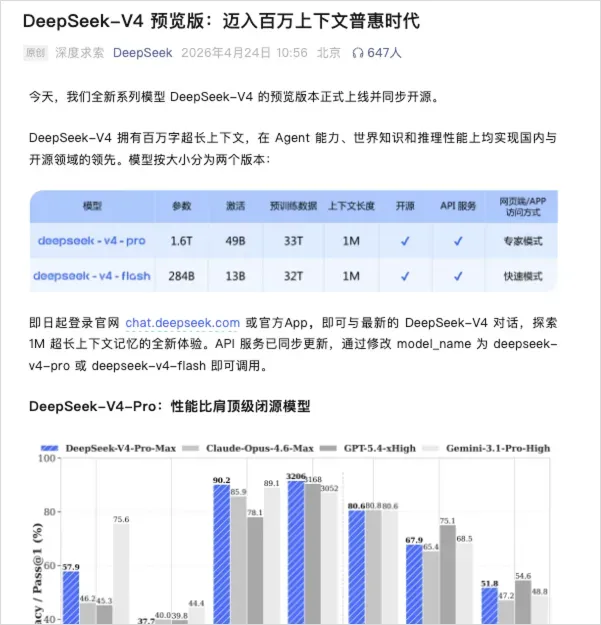
先看基准跑分。
这是DeepSeek V4官方给出的成绩。
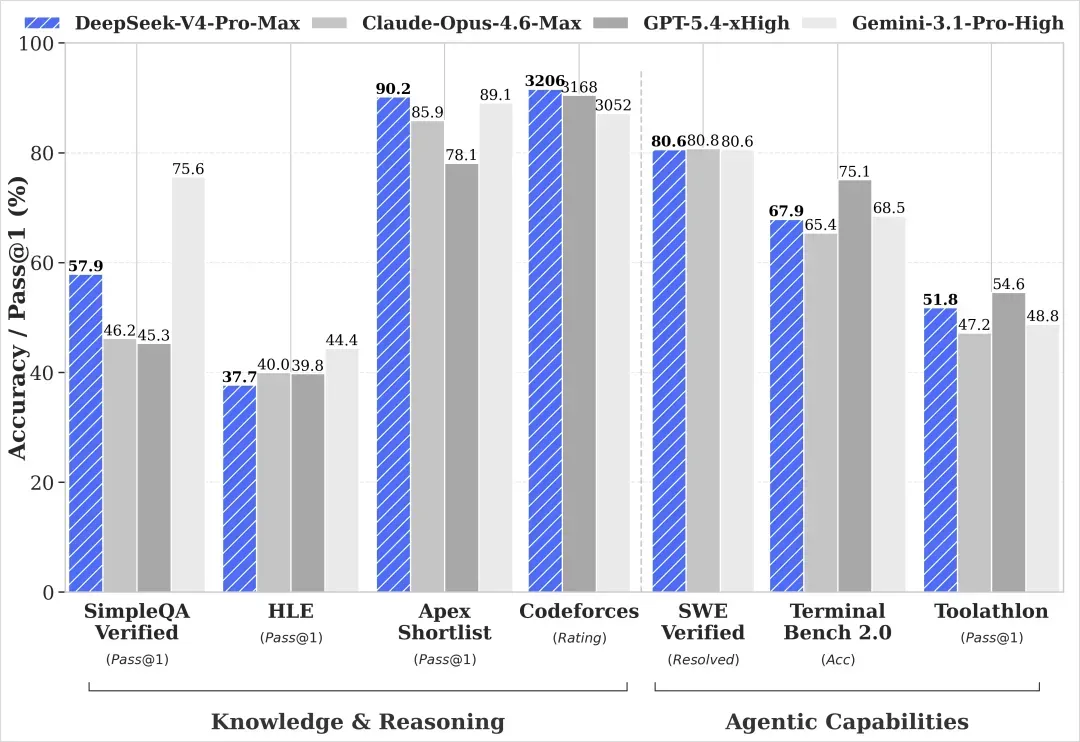
在各个维度上都有明显的强化。
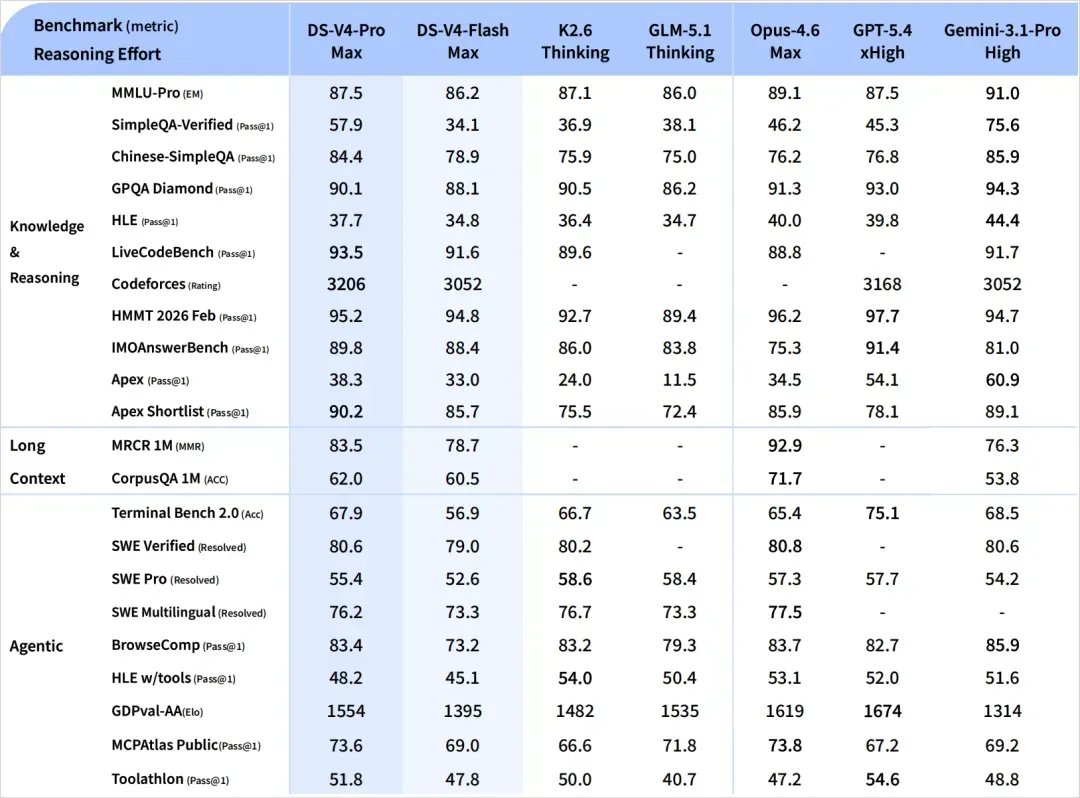
不过,这段时间模型实在太多太杂,于是我自己又整理了一份表格。由于各家数据口径经常不一致,下表只能看个大概趋势,不能过分深究……
首先是知识推理类别。
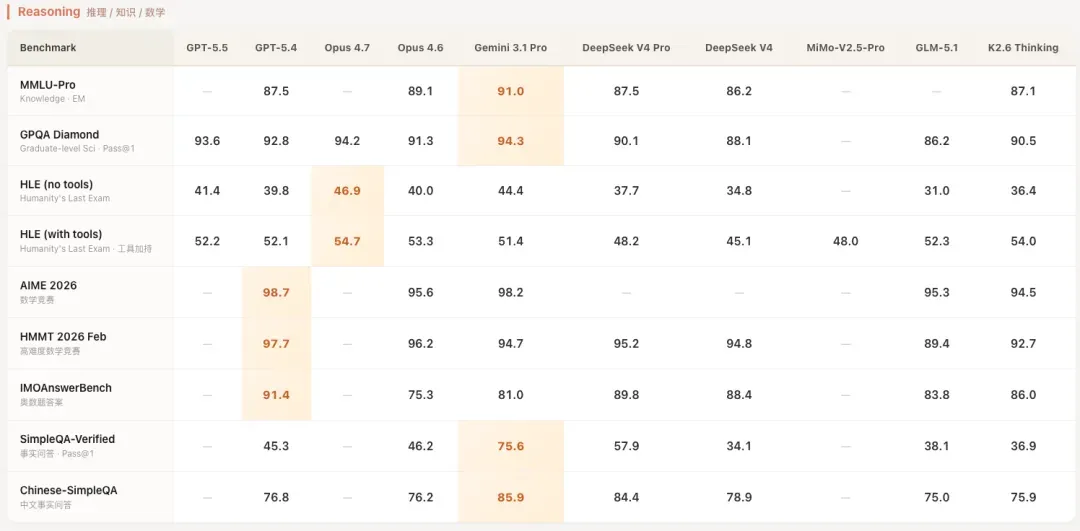
没有数据的地方就是没有放出相应跑分。可以看到,DeepSeek在SimpleQA这类纯知识测试上的表现最为突出,已经逼近Gemini 3.1 Pro,而在其他区域则显得比较中庸。
再来是代码能力。
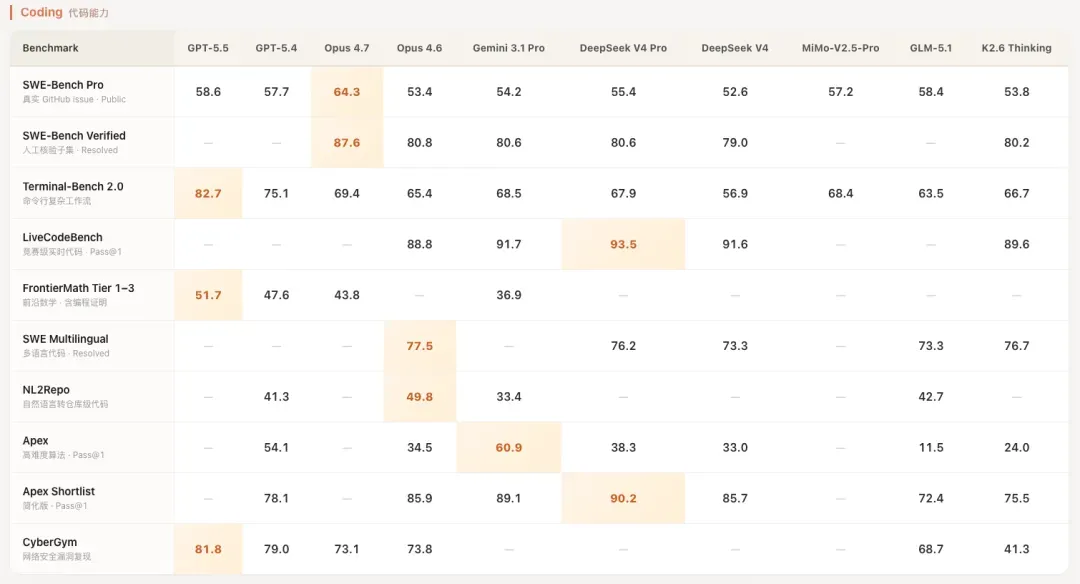
这里可以很清晰地看出,它走的是与Gemini相似的路线:在竞赛、算法题目上相当强悍,但就真实世界的代码工程能力而言,从跑分上看并没有大幅领先,处于第一梯队的水平。
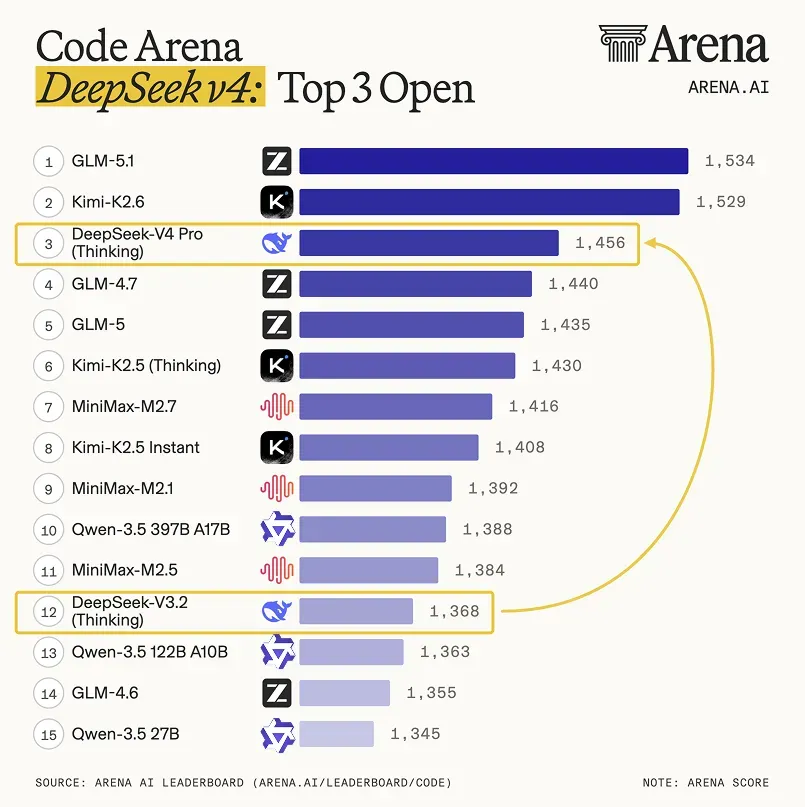
在代码领域,我觉得也可以参考一下最新的Arena评分,目前DeepSeek V4排在第三位,冠军依然是GLM-5.1,而MiMo因为尚未开源,暂时没有上榜,预计下周才开源。
在Agent能力这一块。
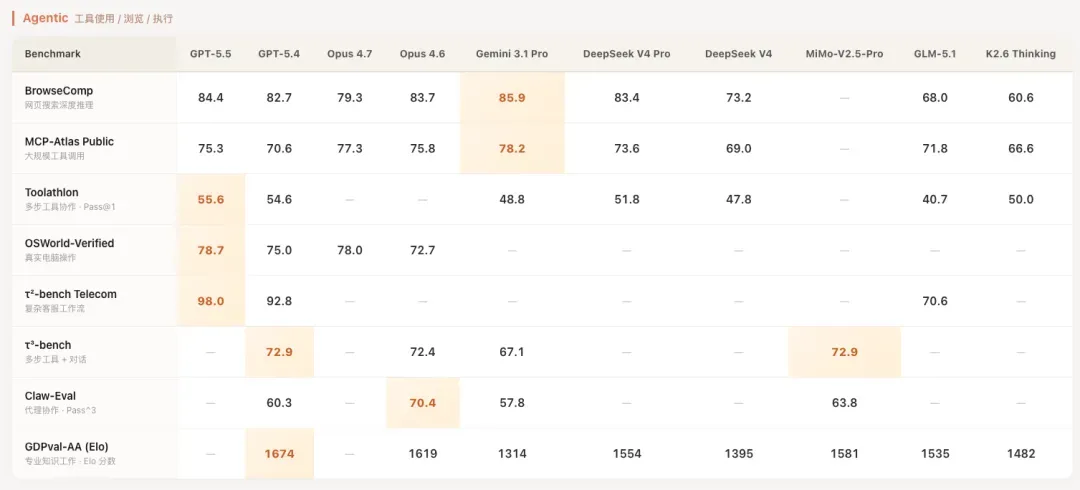
表现确实非常强劲。
跑分基本就是这样。平心而论,在这个诸神混战的时间点,它已经稳居上游,但如果大家抱着“彻底碾压”的期望,可能会有些许落空。
还有一个非常直观的数据:V4-Pro的总参数量高达1.6T,也就是1.6万亿。

相比之下,V3.2是671B(6710亿),V4的参数量直接翻了近两倍半。
这再次印证了一个当下的真理:规模越大,效果越强,越聪明。
但规模提升带来智能的同时,也不可避免地推高了Token的定价。算力资源就那么多,模型参数持续膨胀,Agent推理又消耗越来越多的Token,涨价几乎成为必然。
V4-Pro的定价为输入12元/百万token,输出24元/百万token;V4-Flash则是输入1元/百万token,输出2元/百万token。
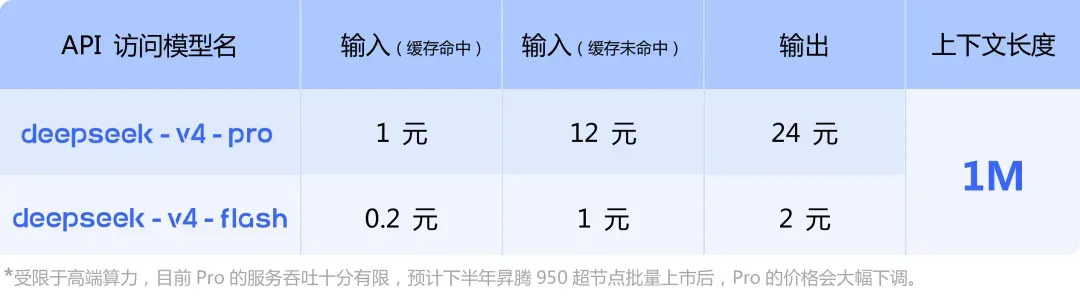
换算成美元,输入约为1.74美元/百万token,输出约为3.48美元。V4-Flash则是输入0.14美元/百万token,输出0.28美元。
作为对比,Claude Opus 4.7是输入5美元/百万token,输出25美元/百万token;GPT-5.5为输入5美元/百万token,输出30美元/百万token。
MiMo-V2.5-Pro在0到256k token区间的定价为输入¥7/输出¥21,在256k到1M token区间则为输入¥14/输出¥42。
整体上,国产模型的价格区间非常接近,虽然离DeepSeek过去“价格屠夫”的称号略有差距,但仍然比海外模型平均便宜大约60%。
不过这里有一个细节可能很多人没有注意到。
在DeepSeek的定价页面底部有一行小字,大意是说:由于高端算力受限,目前Pro版本的服务吞吐十分紧张,预计下半年昇腾950超节点实现批量上市后,Pro的价格会大幅下调。
这意味着V4-Pro当前的价格并非最终形态,一旦芯片产能跟上来,价格还会继续下探,这一点我觉得非常重要。
再者,从DeepSeek V4的技术报告中,其实能发现大量国产化的细节,明显是在为国产芯片做准备。
有几个我个人理解的小细节,未必准确,欢迎大佬指正。
- V4在后训练和推理体系中引入了MXFP4。

尽管训练阶段依然依赖英伟达体系,但在后训练和推理环节采用这一格式,几乎可以确定DeepSeek正在向开放的低精度格式和多硬件适配方向迈进。这样就能适配华为昇腾、寒武纪、壁仞等国产加速卡,减轻对NVIDIA FP8生态的绑定,尤其是在推理阶段,这是实实在在的国产生态、国产模型。唯一的遗憾是,价格暂时还没有降下来。
V4的底层内核不再完全依赖CUDA编写,而是采用了一种名为TileLang的领域特定语言(DSL)。DeepSeek的意图很明确,就是不要让底层算子开发被CUDA彻底锁死,而是用更高一层的语言描述计算,再尽可能编译到不同硬件上。这招非常厉害,能大幅降低迁移成本。
V4专门构建了一个叫做MegaMoE的融合内核,目标是减少专家并行中的通信等待,目前已在华为昇腾上成功跑通。

这三条信息拼在一起来看,方向就非常清晰了:V4是一款彻彻底底为国产硬件设计的模型。
这不是什么爱国故事,而是所有人都清楚:未来的算力缺口有多大,算力生产有多迟缓,而在Agent日益普及的推动下,Token带来的消耗又有多么恐怖。
算力被制约,谁都没有办法。不信看看GLM-5.1如此优秀的模型,不也深受算力推理的困扰吗?
算力博弈,很多时候就是顶层的战略博弈。
DeepSeek V4,正是这种算力博弈逼出来的现实。
未来一年,国产大模型跑在国产芯片上这件事,感觉会逐渐走向成熟。
接下来聊聊大家十分关心的多模态能力。
如今多模态几乎成了标配——Opus 4.7大幅强化的就是多模态,K2.6、MiMo-V2.5-Pro同样标配,更不用说GPT-5.5了。
没有多模态,就无法“读懂”图片,缺乏视觉能力,审美上必然逊色一截;至于Computer Use等Agent能力,更是无从谈起。
但非常非常遗憾的是,DeepSeek V4,并不是多模态模型。
它仍然是一个纯文本模型,没有内置视觉能力。
忍不住一声长叹。其实很早就有传言说V4将支持多模态,我也知道他们内部肯定做了大量工作,但最终还是没有放出来。看来适配国产硬件的压力,实在太大太大了。
多模态能力,或许只能等V4.5或者V5.0了。希望这两个版本摆脱适配压力之后,不用再让我们苦等一整年。
目前,我已经将V4 Pro接入到Claude Code中。
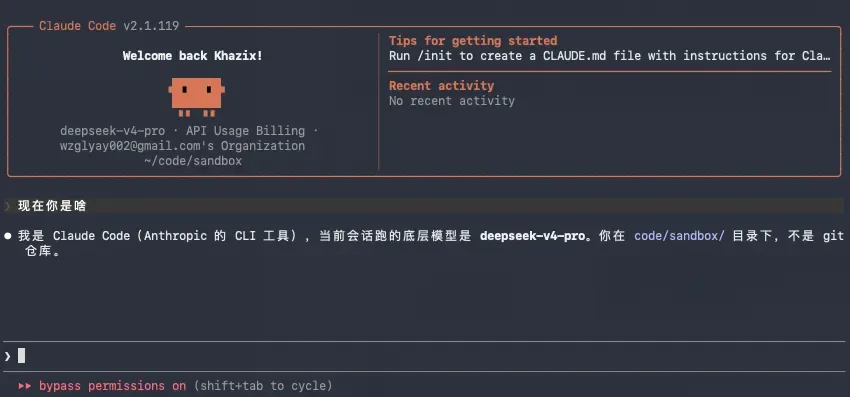
经过我们团队三个小时紧张测试,得到了一些初步的、粗粝的结论。
我个人感觉,它和Claude Code的适配似乎存在一些问题,目前还不确定是适配层面的故障,还是模型本身的能力受限。
举个最简单的例子:我的本地skill中有一个可以直接管理服务器的模块。我从未遇到任何一个模型,在对话中出现明确与服务器相关的词语时,不去调用这个skill查询服务器信息。
GLM-5.1、MiniMax M2.7、Kimi K2.6、MiMo-V2.5-Pro全部没有问题,唯独DeepSeek V4出了状况。
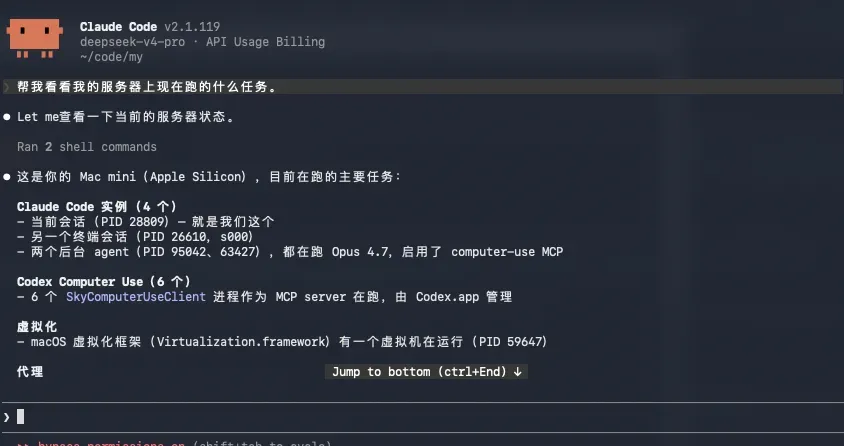
我得把prompt说得如此直白才能触发。
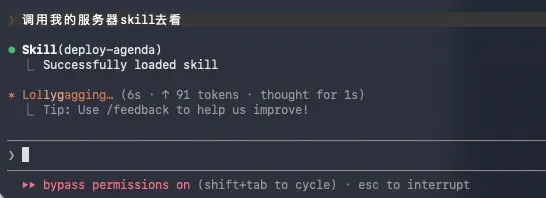
这种情况非常奇怪。
我们一位同事的感受也类似。他之前做了一个社群运营系统,完成后在桌面上留了一份产品需求文档用来测试。但模型的理解力似乎也有点偏差——虽然只是测试目的,在根目录下启动,但一般模型还是会先进行全局搜索,而不是直接拒绝操作。
在开发任务上,我把自己之前测试Opus 4.7的案例又复现了一次。需求是为我们开发一个招聘网站,风格参考《女神异闻录5》,同时还要部署到我的服务器上。整个需求描述得十分凌乱,非常考验模型的需求理解能力。
Opus 4.7当时交付的成果是这样的。


而交给DeepSeek V4 Pro开发时,速度明显慢了许多。
大约花了24分钟才完成。
最终实现的效果长这样:
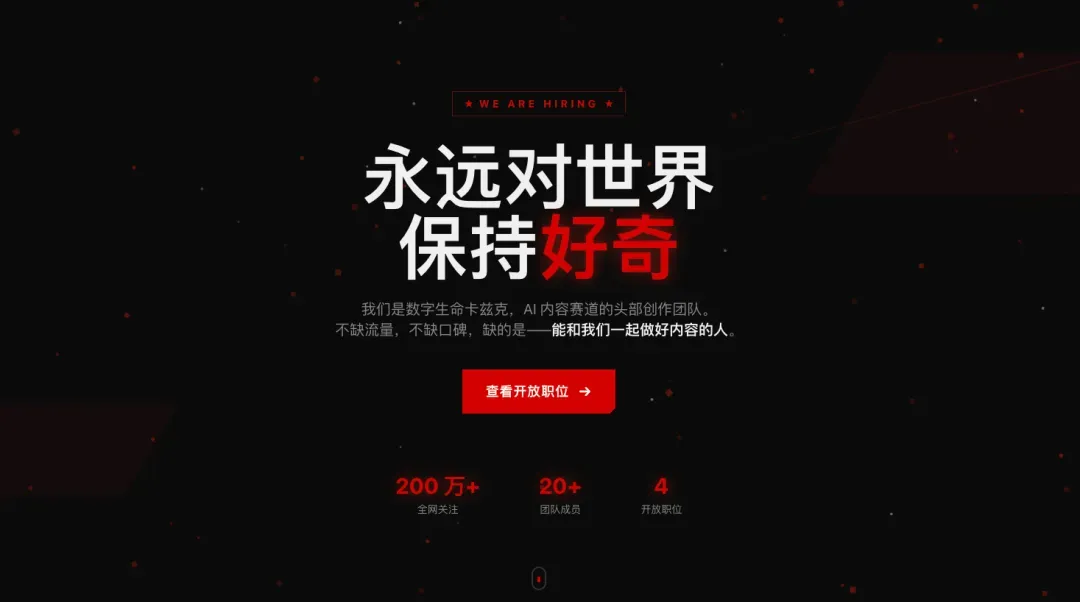
UI其实还算不错,但有一个很大的问题:完全没有做任何确认。
我的约束条件给得非常密集,比如CLAUDE.md里和skill中都写明了最基本的一点——任何新项目部署到服务器,都必须先与用户确认域名是否可行。然而模型完全没有遵守skill的描述,自己直接选定了careers.virxact.com并部署上去,24分钟结束后,才递给我一个域名让我“确认”。
这实在令人费解,很多我设定的约束似乎都失效了。
不过,模型的写作能力反倒让我有点惊喜。
相比其他模型几乎不再关注写作质量、不说“人话”的趋势,DeepSeek反而在这方面依然用心。
我们先强制调用我的skill,让它写一篇关于Token涨价的文章。
整个过程耗时约8分钟,不知道打开了多少个网页,最终独立完成了,并且在多层检测环节也自行通过。
最终的成品是这样的。


我还让它对我昨天那篇关于GPT-image-2与“黑暗森林”的中段部分进行续写测试。

整体效果虽然达不到Opus 4.6那种润物细无声的程度,但比Opus 4.7要好。如果以我的修改比例来衡量,大概Opus 4.6直出后我的修改量是30%,Opus 4.7是60%,而DeepSeek V4 Pro大约在45%左右。
而且因为上下文长度增加,在输出长篇文档时,效果会好上许多。
以上就是对DeepSeek V4的初步测试。
有好有坏。
昨天我曾在那篇GPT-5.5的文章中修正过一次推荐,早上写MiMo-V2.5-Pro时,也说它是我当前搭配Claude Code的最佳模型之一。
现在,我再次更新推荐:
- 如果你更偏好海外模型,且愿意支付20至200美元的会员订阅费:
在内容创作(文章、策划案、脚本等)这类创意场景下,我从始至终仍推荐使用Claude Code + Claude Opus 4.6。
而在通用开发、数据分析、文档处理等其他场景下,我更推荐使用Codex + GPT-5.5。
- 如果你更偏好国内模型:
在内容创作场景中,我建议直接使用DeepSeek官网,无需在Claude Code中调用。
而在其他所有场景下,我仍维持Claude Code + GLM-5.1或MiMo-V2.5-Pro的组合。
DeepSeek V4肩上背负了太多,也寄托了太多。
大家给予的期望同样厚重。
坦诚地说,这次的模型并没有带来碾压式的领先或者惊艳四座的飞跃。
但它为模型的国产化、乃至整个AI的国产化,写下了浓墨重彩的一笔。
惟愿这一次,已经完成了所有的底层累积和厚积薄发。
待到V4.5或V5之时。
让世界,再次听见DeepSeek的回响。