如何用AI Skill高效生成FPV第一视角视频?全流程解析与创意指南
最近我一直在深入探索Seedance 2.0、GPT Image 2以及多种图生视频工具,并基于实践制作了一个挺有意思的Skill,专门用来编写FPV沉浸式视频的提示词。
简单来说,只要给它一个想法,它就能自动拆解成两套内容:
一套交给GPT Image 2生成图像。
另一套交给Seedance 2.0这类视频模型生成视频。
这种FPV第一视角视频最近在各个平台热度很高,镜头仿佛真的走进了某个空间,从门口步入,穿过街道,从天空俯冲而下,沉浸感极强。
下面这个视频就是用我编写的skill生成的提示词创作的。

最近超火的FPV第一视角视频,被我做成skill了。
这个skill会根据用户的构思,自动生成对应的GPT Image2提示词和AI视频生成提示词,目前已经开源到GitHub上,欢迎使用和star。
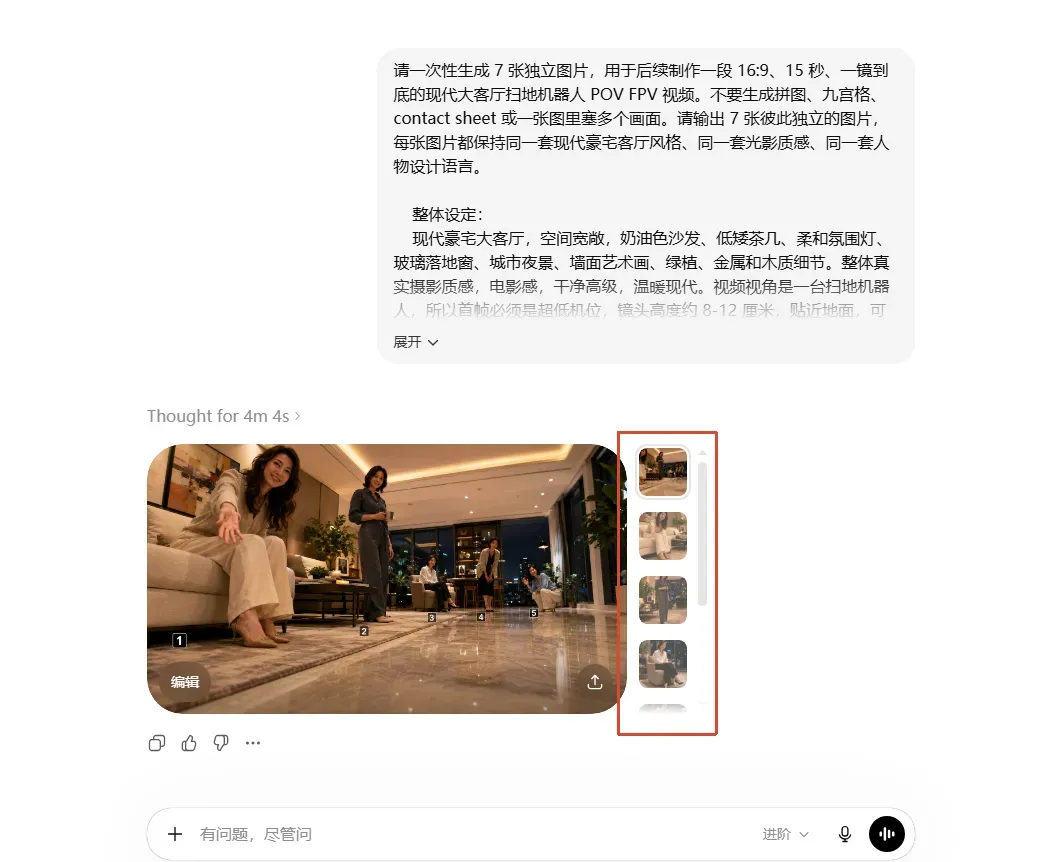
比如下面这个例子,我只输入了一个简单的想法,skill就会根据这些信息自行规划提示词的生成方式。
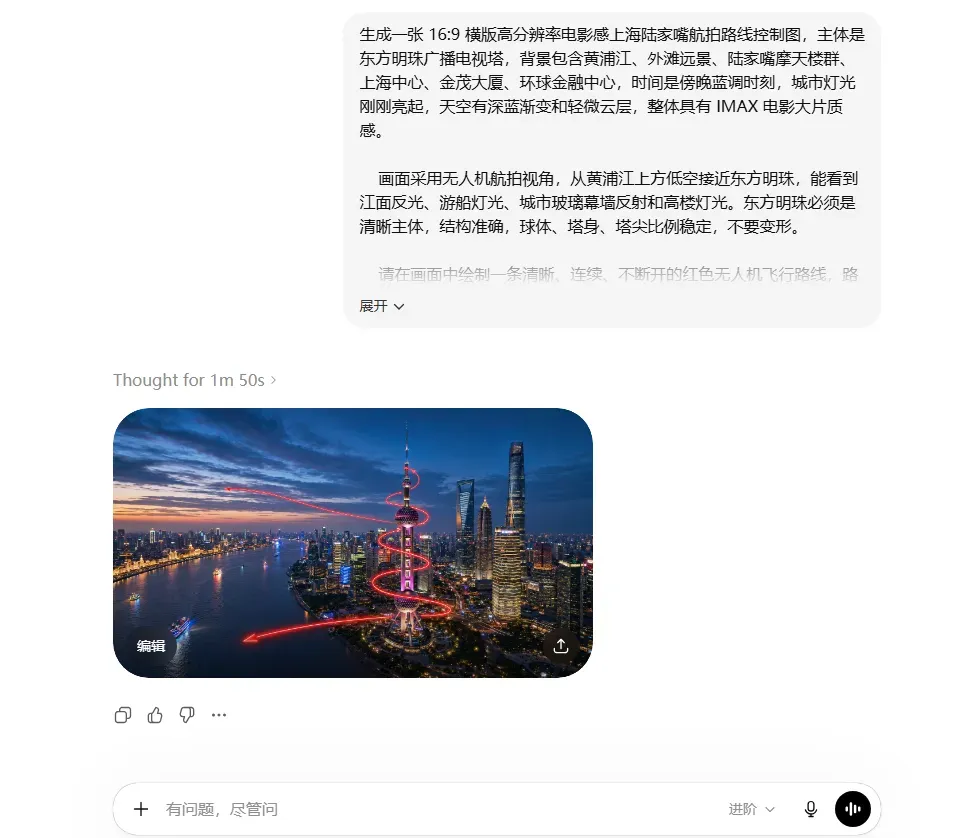
之后只需把生成的GPT Image2提示词提供给ChatGPT,就能得到如下图片。
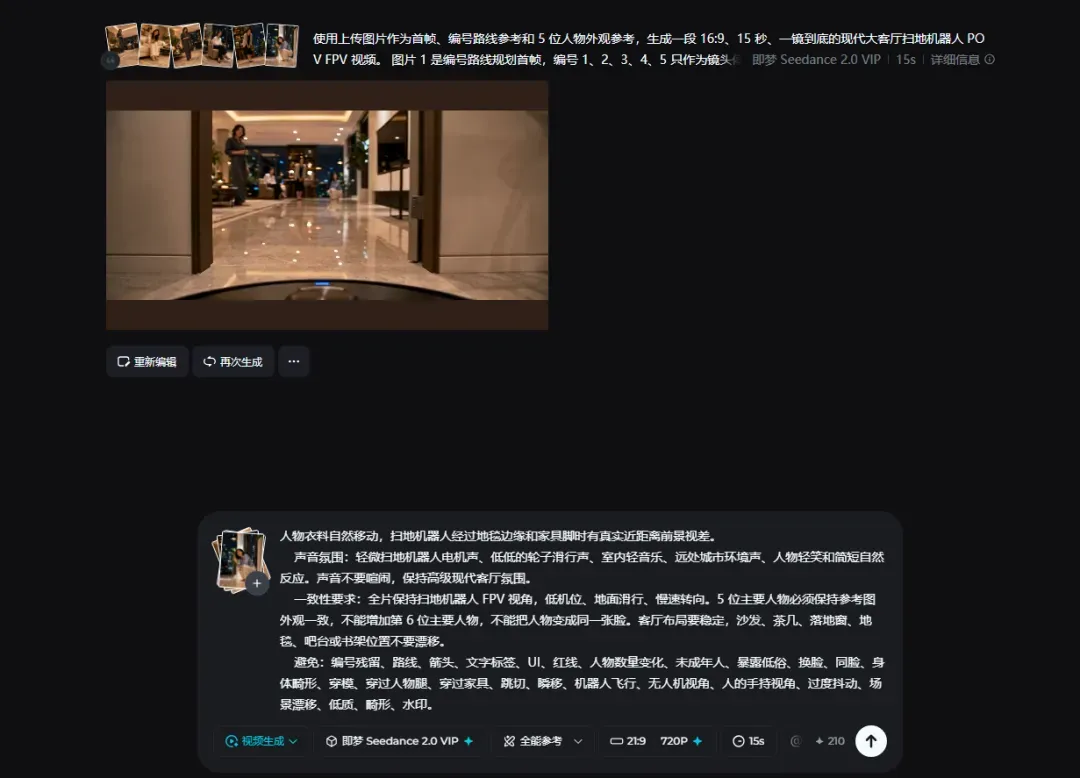
接着下载图片,上传到任意支持Seedance2.0大模型的创作平台,再使用skill生成的视频提示词即可完成创作。
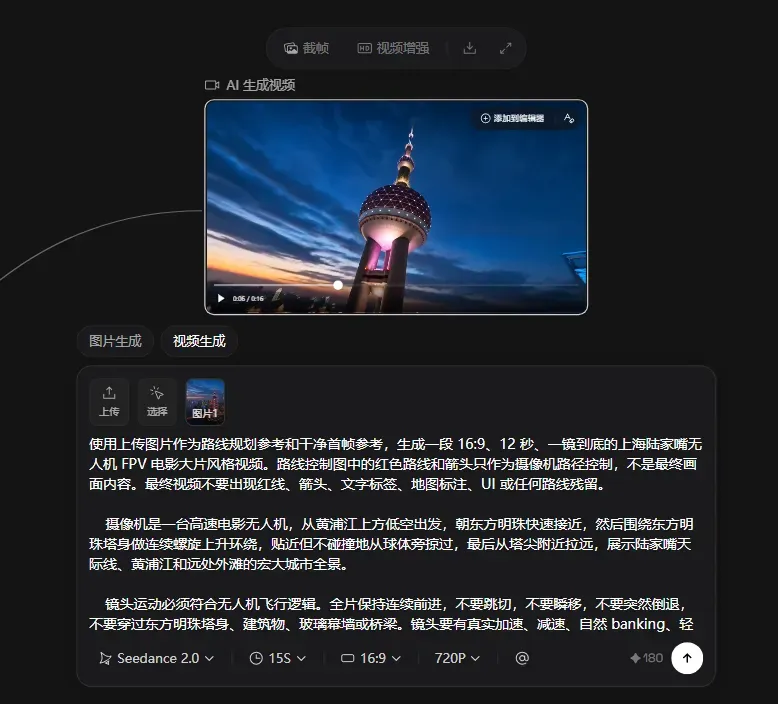
最终生成的视频效果如下。当然,每次生成的视频效果会有所差异,想要获得更理想的画面,往往需要一定的抽卡过程。

最近超火的FPV第一视角视频,被我做成skill了。
当然,我更想分享的是整个skill的创作过程。我越来越感受到,使用大佬们优秀的skill固然重要,但更要有长远的计划——在实战中不断积累自己制作skill的能力,这样既能提升技能,又能把各种工具牢牢掌握在自己手中。
Skill架构设计思路
其实很多教程都分享过这类视频的提示词,照着写基本可以复刻出相似的作品。
但问题是,即使掌握了某个提示词,很多人还是难以把自己的想法落地。
因为这类视频的难点并不只是画面是否精美、人物是否好看、镜头是否有电影感。
真正动手后才发现,最容易出问题的地方其实很朴素——镜头到底该怎么走。而这种运动轨迹的写法,远不是看几个提示词就能练出来的。
所以我决定把这段时间关于这类视频制作的思考做成一个skill,既方便自己以后使用,也分享出来供大家一起学习。
最初的想法很简单:一个skill,既负责生图提示词,也负责生视频提示词。对于生图提示词,最好能直接把运动路线画好,省时省力。
直接对大模型说“我要第一人称从门口走进去,依次经过5个角色,最后停在池边”,听起来很简单,对吧?
模型经常会生成一张漂亮的画面,红线也画了,编号也标了,但仔细一看:1在右边,2在左后方,3在屏风后面,4跑到了水池另一侧,5又回到前景。人看着都不知道怎么走,视频模型当然也没法稳定运镜。

GPT Image 2很擅长绘制漂亮的画面,但它未必理解我们要的是一条可行走的路线。它有时会把红线当成装饰,有时会让红线断开,有时红线直接穿过桌子、栏杆、水池甚至人物身体。
所以后来我们调整了思路。对于大多数室内和人物互动场景,不强求红线,改用1、2、3、4、5这种小编号停靠点。这个改动看起来很小,但稳定性会大幅提升。
因为红线一旦画错,会直接误导视频模型。编号点即使有偏差,至少还可以在视频prompt里补一句,让镜头按编号顺序移动,从入口自然走向1,再转向2,再到3,每一段都必须沿可见地面和可行走通道前进,不能瞬移,不能穿过障碍物。

后来我给这个Skill又加入了一条规则:先设计空间,再放置角色。
比如一个现代客厅,一群人站在客厅里。普通提示词大概会写“高级大平层、落地窗、米白沙发、五位现代都市女性、暖色灯光、城市夜景”。
这样生成出来的大概率是一张好看的群像图,但要做FPV,就会出问题。人物可能站在画面四角,茶几挡住路线,沙发挡住路线,吧台和窗边之间根本没有通道。
更稳妥的写法是先把客厅设计成一个能走的空间。入口玄关在前景,路线从玄关进入,先到沙发右侧,再到落地窗边,再绕过茶几,到开放式吧台,最后抵达阳台或窗边终点。
然后再把人物放到这条路线旁边。
1号角色在近景沙发旁,2号角色在近中景窗边,3号角色在中景茶几区,4号角色在中远景吧台旁,5号角色在远景落地窗前。
这样写,模型才知道这是一套可以被镜头走完的场景,普通人物海报做不到这一点。

并且这个skill生成的提示词,还会让GPT Image2一次性把所有需要的图片都生成好,人物参考图也都有了,不用再单独生成,非常便捷。

最近超火的FPV第一视角视频,被我做成skill了。
这次做Skill给我最大的体会是:AI视频提示词不能只写审美,更要写空间,尤其是FPV这类视频,空间太重要了。
很多人写视频prompt,习惯上来就堆砌“电影感、4K、超清、真实光影、精致细节、史诗氛围”。
这些词有用,但它们解决的是质感问题,不解决路线问题。
FPV视频更像一个小型游戏关卡。要先想清楚摄像机是谁,从哪里出发,要经过几个目标,每个目标之间是否真的能走过去,最后停在哪里。
如果这些没写清楚,再漂亮的画面也可能变成随机镜头漂移。
之后我又进一步丰富了skill的功能——FPV不一定是人眼视角。
如果是现代客厅,完全可以写成猫的视角。镜头高度更低,从沙发腿旁边穿过去,爪子和尾巴偶尔进入画面,经过地毯、茶几和人的脚边,整个视频会更有沉浸感。
如果是咖啡馆,也可以是扫地机器人视角。它只能贴地滑行,不能上台阶,不能飞过桌子,桌腿、椅腿、鞋子、地面反光反而会变成很强的画面特点。
如果是世界地图飞行,人的视角就不合适了。这个时候更适合无人机、鸟、龙眼、幽灵或者某种看不见的飞行视角。镜头可以爬升、俯冲、贴近山谷和城墙掠过,通过高度变化和前景视差制造速度感。
也就是说,大场景路线和室内人物互动要采用不同的处理方式。
如果是奇幻大陆、城市飞行、峡谷赛车线、游戏世界穿越,这种场景可以用红线。因为它本身就是大尺度路线,红线画在地图、山谷、道路、海岸线或者空中走廊上,更符合模型的理解。
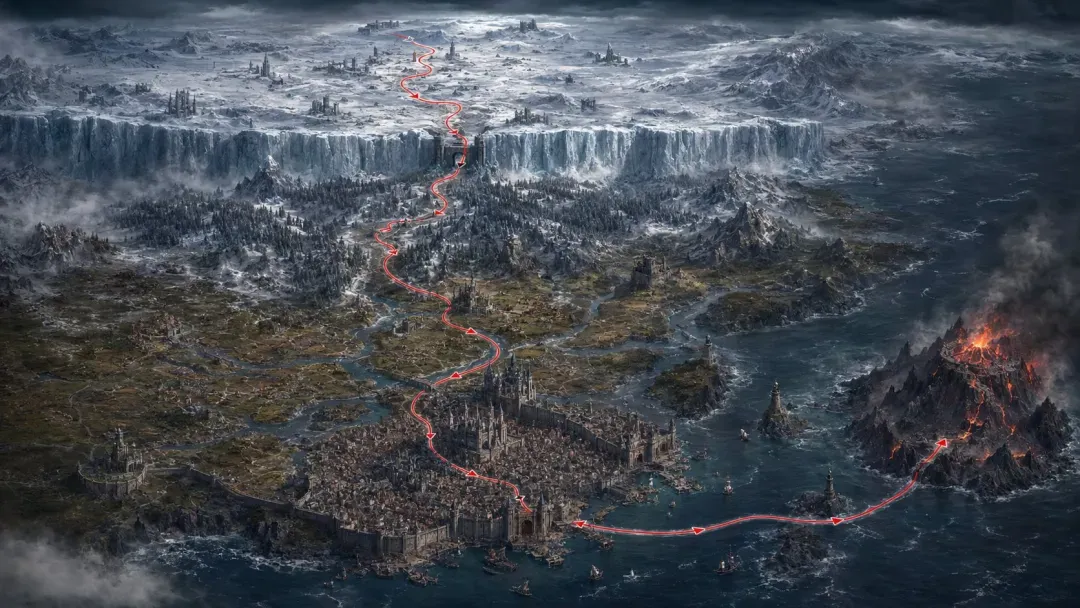
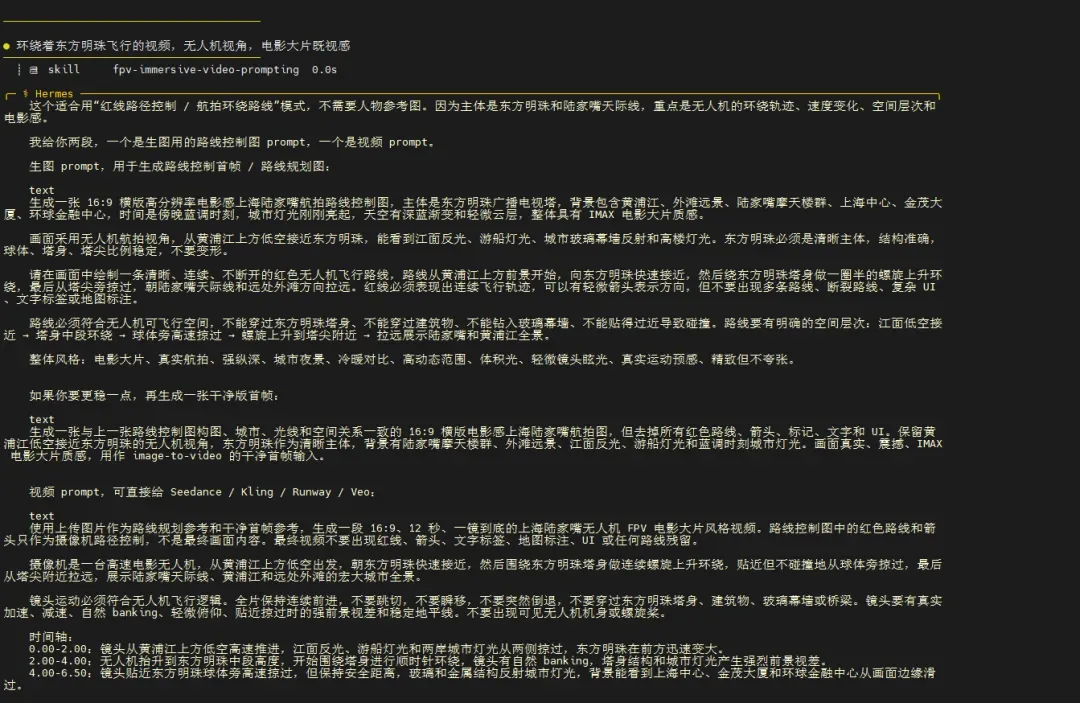
使用上传图片作为路线规划地形图。图中的红色路线线条只表示镜头飞行路径和方向,最终视频中必须完全移除红线、箭头和所有标注。 生成一段 16:9、15 秒、一镜到底的电影级 FPV 飞行视频,穿越上传图片中展示的黑暗中世纪奇幻大陆。 不要剪切。不要转场。不要瞬移。不要地图俯视图。不要出现红线。不要出现箭头。不要出现文字标签。不要出现 UI。 摄像机是一只隐形的龙眼 FPV 飞行视角,从北境冰雪荒原出发,严格沿着图中红色路线的几何路径前进,最终抵达海峡尽头的火山龙岛。 镜头必须连续向前飞行,不能偏离路线,不能反向移动,不能跳过路线中的主要区域。
时间轴: 0.00–2.50 秒: 镜头从极北冰雪荒原低空开始飞行。下方是被暴风雪覆盖的白色平原、黑色松林、冻结河流、破败哨塔、冰裂峡谷和远处模糊的狼影。镜头贴近地面快速掠过,雪粒和冷雾从镜头两侧冲过,形成强烈速度感和前景视差。 2.50–4.50 秒: 镜头接近一座巨大的古老冰墙。沿着冰墙垂直爬升,近距离掠过冰冻城垛、火把哨站、铁链、冰面裂缝和风雪中的守望塔。到达墙顶后,镜头自然压低并向南俯冲,进入墙后的大陆。 4.50–7.00 秒: 镜头穿过雪林和崎岖山地隘口。两侧是黑色岩壁、积雪松树、废弃堡垒、狭窄山路、冰冻瀑布和被惊起的乌鸦。镜头在山谷之间自然转弯,贴近树梢和岩壁飞过,速度逐渐提升。 7.00–9.50 秒: 镜头进入中部河谷地区。冰雪逐渐减少,画面变成泥泞战场、河流、石桥、被烧毁的村庄、残破旗帜、行军队列和古老石头城堡。镜头贴着河面快速飞行,掠过桥洞和城堡塔楼,然后沿道路向南方海岸加速。 9.50–12.00 秒: 镜头接近一座巨大的海滨中世纪王都。穿过外城墙和城门,飞过密集红瓦屋顶、狭窄街道、高耸石塔、宫殿穹顶、港口吊机、海边防御工事和王城广场。镜头从中央城堡上方爬升,然后向外海俯冲。 12.00–15.00 秒: 镜头高速穿过风暴海峡。下方是黑色海浪、白色浪花和闪电照亮的云层,远处有巨龙阴影短暂掠过海面。镜头抵达一座黑色火山龙岛,贴近黑色悬崖、熔岩裂缝、古老龙骨遗迹和火山岩飞行。最后镜头向上爬升,冲向燃烧的火山口,天空被红色火光和浓烟照亮,形成史诗级终点画面。
环境设定: 黑暗中世纪奇幻大陆,北境冰原,古老冰墙,雪林,山地隘口,河谷王国,战争废墟,石头城堡,巨大海滨王都,风暴海峡,黑色火山岛,龙族遗迹,熔岩,灰烬,火光,暴风云,史诗世界观,高真实感,电影级光影,体积云,雪雾,烟尘,海浪飞沫,火把光,熔岩红光。
镜头运动: 快速电影级 FPV。连续不中断的向前飞行。沿地形自然转弯。近距离掠过悬崖、树梢、塔楼、城墙、屋顶、桥梁、海浪和火山岩。动态高度变化,先贴地、再爬升、再俯冲、再越海、最后冲向火山。强前景视差,逐渐加速,地平线保持稳定。龙眼视角要有轻微有机滑翔感,但不要剧烈抖动。
视觉推进: 画面从冰冷的蓝白色北境,逐渐过渡到灰色战争河谷,再进入红金色海滨王都,随后变成黑色风暴海峡,最后抵达红黑色火山龙岛。每个区域的光线、天气、地貌和建筑都要明显变化,但必须保持连续世界感。

最近超火的FPV第一视角视频,被我做成skill了。
但如果是宫廷、客厅、咖啡馆、展厅、聚会现场,我现在会优先用编号停靠点。因为角色互动讲究位置、脸、服装、动作和台词稳定,红线反而容易污染画面。

使用上传图片作为首帧、编号路线参考和 3 个角色外观参考,生成一段 16:9、15 秒、一镜到底的咖啡厅猫咪视角 FPV 视频。首帧中的编号 1、2、3 只作为镜头停靠顺序参考,不要出现在最终画面里。最终视频不要出现数字、编号、路线、箭头、文字标签或 UI。
观众是一只在咖啡厅里自由走动的猫咪,镜头保持接近地面的低机位,从咖啡厅入口旁的地垫开始,严格按编号顺序移动:入口地垫 → 1 靠窗座位的女生
@图片2→ 2 吧台前的咖啡师
@图片4→ 3 圆桌旁的女生
@图片3→ 最后钻到窗边阳光下停住。本视频包含 exactly 3 个主要人物,不要增加或减少主目标。3 个主要人物的脸、发型、服装、位置和身份要保持参考图一致。
镜头运动必须符合猫咪的身体限制。猫咪低高度前进,视野里能看到桌腿、椅腿、地面纹理、人的鞋子和偶尔闪过的猫爪或尾巴。移动方式是轻快小步、短暂停顿、好奇转头、绕开障碍物,不能像无人机一样漂浮,不能突然升到人类眼高,不能跳上吧台,不能穿过桌椅、人腿、墙面或玻璃。
时间轴:
0.00-2.00:猫咪从咖啡厅入口旁的地垫出发,低机位看到木地板、门口光线和来往脚步,背景有轻微咖啡机声和杯碟声。
2.00-5.00:猫咪沿着桌椅之间的空隙走向 1 靠窗座位的女生。女生低头发现猫咪,露出笑容,伸手轻轻放低一块小饼干,但手不要遮挡镜头。
5.00-8.50:猫咪绕过一把椅子和桌脚,走向 2 吧台前的咖啡师。咖啡师蹲低一点看向猫咪,把一小碟猫粮放到地面旁边,咖啡机喷出蒸汽,吧台灯有温暖反光。
8.50-12.00:猫咪从吧台边离开,移动到 3 圆桌旁的女生。女生合上电脑,低头看猫咪,轻轻晃动手里的逗猫绳,猫咪视角有一次快速好奇转头。
12.00-15.00:猫咪离开圆桌,走到窗边一片阳光里停下,低头看见自己的猫爪踩在光斑上,然后抬头回望咖啡厅,能看到 3 个主要人物分别在原位置自然互动,空间层次清晰。
环境动态:咖啡蒸汽、窗外光线、玻璃反光、杯子轻碰声、木地板反光、椅子轻微移动、绿植叶片轻晃、远处轻声聊天。
一致性要求:全片保持猫咪第一视角和低机位,不要切换成第三人称,不要看到完整猫身。3 个主要人物保持身份一致,不能换脸、同脸、服装漂移或位置混乱。咖啡厅布局要连续,桌椅、吧台、窗边、角落圆桌的相对位置不能漂移。
避免:编号残留、路线线条、箭头、文字标签、UI、红线、换脸、同脸、主目标数量变化、增加额外主要人物、猫咪飞行、猫咪突然变成人类视角、跳上高处、穿过桌椅、人腿或墙面、瞬移、跳切、过度抖动、场景漂移、低质、畸形、水印。

最近超火的FPV第一视角视频,被我做成skill了。
因此,这个Skill最终形成了两种模式。
一种是编号停靠点模式,适合人物互动和室内空间。另一种是红线路径控制模式,适合世界地图、飞行路线和大场景穿越。
实际上,设计这类视频提示词skill,更像是在做导演分镜和关卡设计。
我们不能只告诉模型要一个漂亮视频,而要把它当成一个临时摄制组,告诉它机位多高,镜头是谁,路线怎么走,经过几个人,每个人在几秒内做什么,最后落在哪个画面。
比如一段15秒的现代客厅视频,如果有5个主要人物,就不能让每个人都说一大段话。更合理的分配是入口1秒,前4个角色每人2秒左右,最后一个角色加终点回望2秒左右,每个人只给一个小动作和一句短台词。
如果用户指定8个人,就不要硬写8个完整互动。可以分成两组,前景3个,中景3个,远景2个,有的人只是回头、举杯、点头、看向镜头。视频只有15秒,装不下太多完整戏剧。
所以我后来又给Skill加了一条规则:用户指定几个人,就按几个人写,不能默认回到5个。不同人物数量,要有不同的处理逻辑和方法,这样最终视频才会更加多元化。
至此,这个skill的框架就大致完成了,后续就是反复调测,不断将不稳定的地方加固稳定。
经验总结
对内容创作者来说,一个Skill最适合沉淀的,正是那些工作中需要重复执行的动作。
一次写prompt可以靠灵感,但连续做20条、50条、200条,就不能每次都从零开始。
要把那些踩过坑的规则沉淀下来:什么时候用编号,什么时候用红线,几秒适合几个人,猫视角怎么写,扫地机器人不能干什么,无人机要怎么写速度感,最终视频里不能出现哪些规划标记。
这就是我倾向于把提示词整理成Skill的原因。
Skill如果只是存一段万能prompt然后复制粘贴,用处其实有限。更有用的Skill,是把一套判断流程存起来。
这才是它真正省时间的地方。
以后再看到那种很酷的AI视频,不妨先别急着问prompt是什么。可以先反推它的思路:镜头是谁,从哪里进入,经过几个点,每个点发生什么,终点画面是什么,为什么要这么调度等等。
只要能把这条执行思路拆出来,你就已经拿到了一半的方法。
剩下的一半,就是把它变成一个Skill,让下次不用重新踩坑。
我现在越来越体会到,AI视频接下来拼的不只是模型能力,也拼谁能更早把自己的工作流沉淀下来。
工具会一直变,Seedance、Kling、Runway、Veo、GPT Image都会更新,但这些底层动作不会变:拆场景、定路线、控人数、选POV、写时间轴、补约束、复盘失败样本。
这些动作越清晰,视频就越像你在导演,少一点祈求模型随机给惊喜的感觉。
这也是这次制作FPV视频Skill过程中最大的收获。
希望这些思路能对你有所启发。