GitHub 6.2 万星神器 Graphify:为 AI 编码助手构建可查询知识图谱,告别无效代码检索
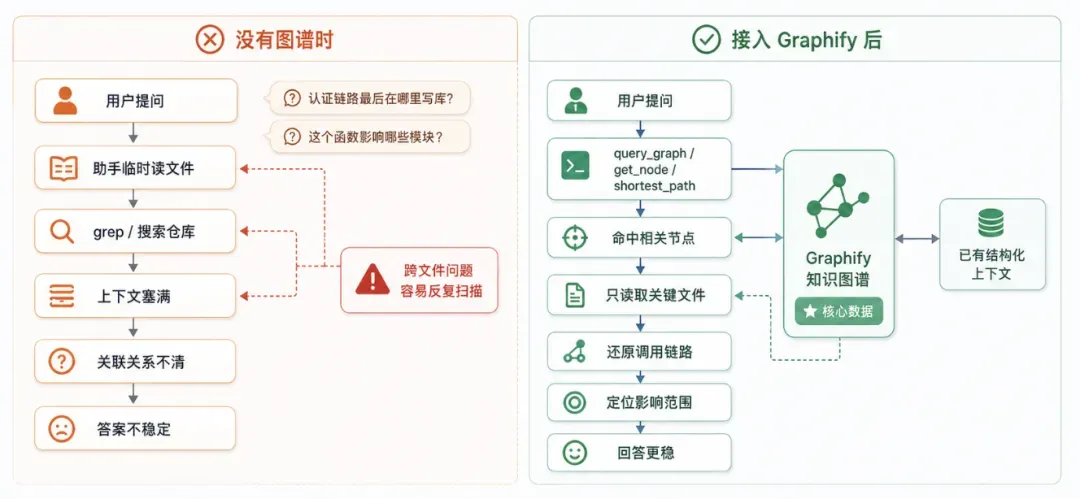
使用 AI 编码助手时最令人烦躁的,莫过于它明明很擅长写代码,却总是在项目上下文里“迷路”。
你问它“认证链路最后是在哪里写数据库的”,它立刻开始读取十几个文件;你再问它“这个函数影响哪些模块”,它又去全仓库 grep 一通。上下文越塞越满,答案却未必准确。
近日,一个名为 Graphify 的开源项目恰好适合接到这类编码助手当中。它做的事情非常直接:把一个目录里的代码、文档、SQL schema、脚本、图片、视频等材料,抽取成一张可查询的知识图谱,让 Claude Code、Codex、Cursor、Gemini CLI 等助手在动手之前,先从这个已有的图谱中寻找线索,而不是一上来就盲目 grep 整个仓库。
项目地址:https://github.com/safishamsi/graphify
截至撰稿时,该仓库已获得 约 6.2 万 Star、6.4k Fork。
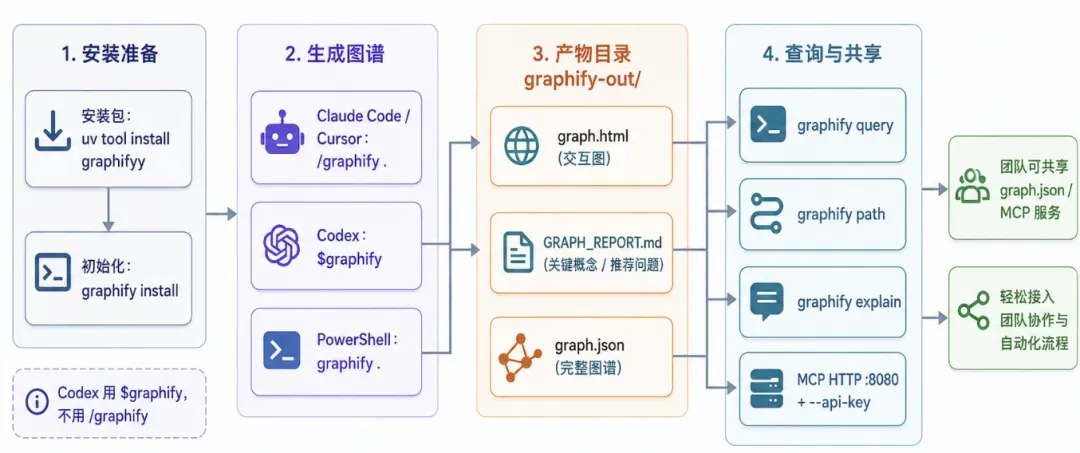
安装与基本使用
官方包名容易踩坑,PyPI 上叫 graphifyy(两个 y),但命令行工具仍然使用 graphify。
uv tool install graphifyy
graphify install
安装完成后,在支持的 AI 编码助手中运行:
/graphify .
需要注意的是,如果是在 Codex 的 assistant 命令里,README 特别提醒要使用 $graphify 而非 /graphify。Windows PowerShell 用户也不能写成 /graphify .,应直接用 graphify .,因为前面的斜杠会被 PowerShell 视作路径。
执行完毕后,项目根目录下会多出一个 graphify-out/ 文件夹,里面主要包含三件东西:
graph.html:在浏览器中打开的交互式关系图。GRAPH_REPORT.md:列出项目关键概念、意外关联以及推荐的问题。graph.json:完整的图谱数据,为后续的查询、MCP 调用和团队共享提供基础。
这一产物思路相当直接。以往 AI 助手回答与项目相关的问题时,常常临时读取文件、临时做总结、临时猜测依赖关系。Graphify 则先将项目中的实体与关系沉淀下来,后续再有新问题时,就不需要每次从零开始翻仓库。
查询示例
你可以通过几条命令完成不同类型的探索:
graphify query "what connects auth to the database?"
graphify path "UserService" "DatabasePool"
graphify explain "RateLimiter"
它们分别对应查找关联、寻找路径和解释节点。Graphify 还提供了 MCP server,支持 stdio 方式给本机助手调用,也支持 HTTP 方式在团队内共享,默认 HTTP 端口为 8080。向局域网公开服务时,可以加上 --api-key 参数。
这比单纯生成一份给人看的架构说明更实用。架构说明适合人读,而 AI 助手真正需要的是可反复检索的结构化上下文。Graphify 暴露的 MCP 工具包括 query_graph、get_node、get_neighbors、shortest_path 等,恰好是 Agent 做代码理解时常见的动作。
支持的编码助手与接入方式
主流的 AI IDE 和 CLI 几乎都已支持,包括 Claude Code、CodeBuddy、Codex、OpenCode、Kilo Code、Cursor、Gemini CLI、GitHub Copilot CLI 等。
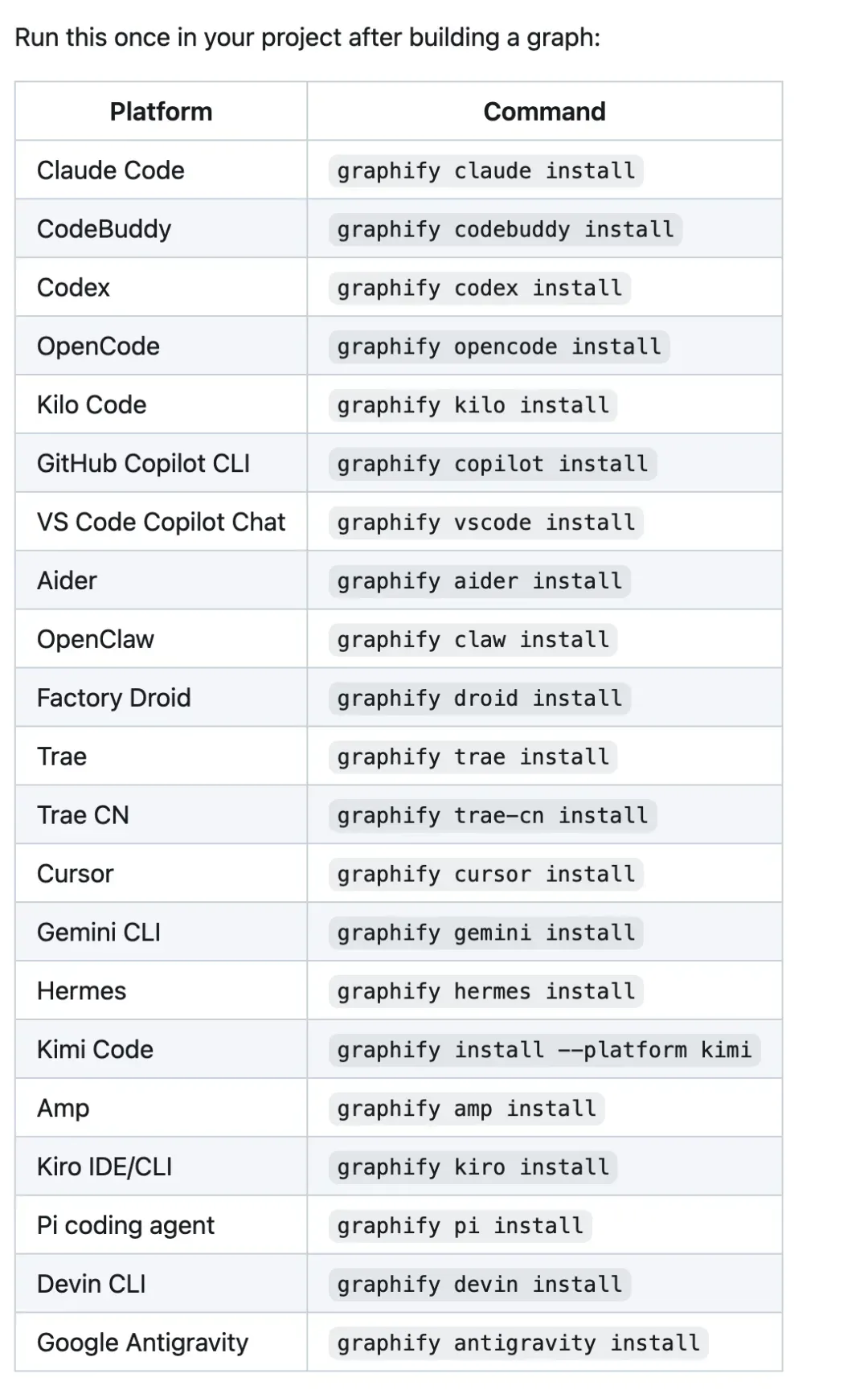
不同宿主间的接入方式并不完全一样。Claude Code、CodeBuddy、Codex、Gemini CLI 等会写入对应的 skill、规则文件或 hook;Cursor 则使用 .cursor/rules/graphify.mdc;部分工具目前更偏向顺序执行,暂时无法获得并行 Agent 带来的全部收益。

因此,不要把它理解成“所有助手体验完全一致”。Graphify 更像是一层项目记忆适配器。能够深入对接的工具,体验会更自动化;对接较浅的工具,至少也能通过 graphify query 将图谱查询起来。
支持的文件类型与处理方式
代码部分主要依赖 tree-sitter 做 AST 抽取,常见编程语言基本都已覆盖,如 Python、JavaScript/TypeScript、Java、Go、Rust、C/C++、C#、Kotlin、Swift、PHP、Ruby、Shell 等。此外,还扩展到了 SQL schema、Terraform/HCL、MCP 配置、Markdown、HTML、YAML、PDF、Office、图片、音视频、YouTube 或普通 URL 等多种材料。
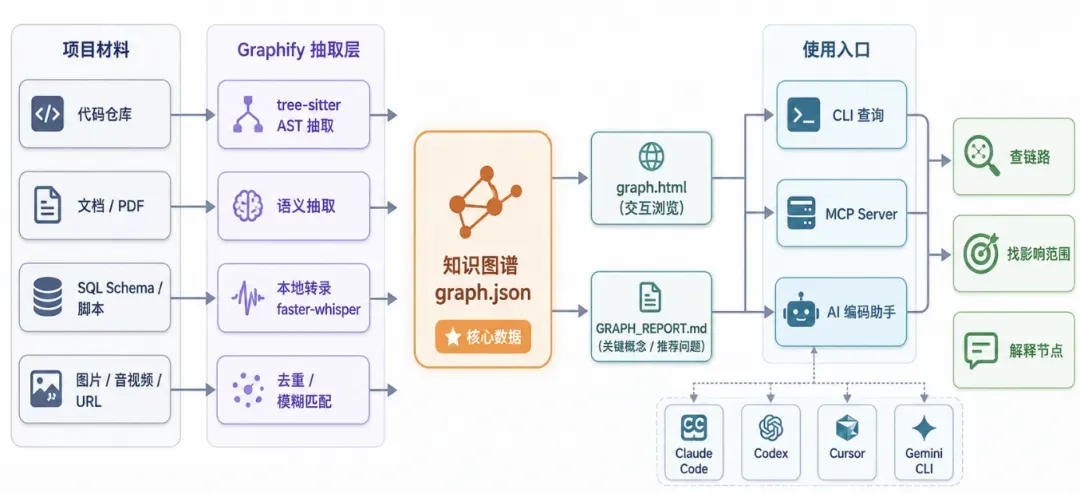
不过这里有一个重要前提:代码类材料可以本地解析,纯代码仓库不需要 API key;但文档、PDF、图片这类语义抽取会调用你配置的模型或 IDE 会话。 如果你的仓库中包含敏感的需求文档、内部截图或合同 PDF,不能只看到“本地知识图谱”几个字就默认全程离线。
代码文件通过 tree-sitter 在本地处理;视频、音频利用 faster-whisper 本地转录;文档、PDF、图片则会发送给你指定的 AI 后端做语义抽取。可用的后端包括 Gemini、Kimi、Claude、OpenAI、DeepSeek、Azure OpenAI、AWS Bedrock、Ollama 以及 Claude CLI。
如果你希望尽可能本地化,可以选择 Ollama:
graphify extract ./docs --backend ollama
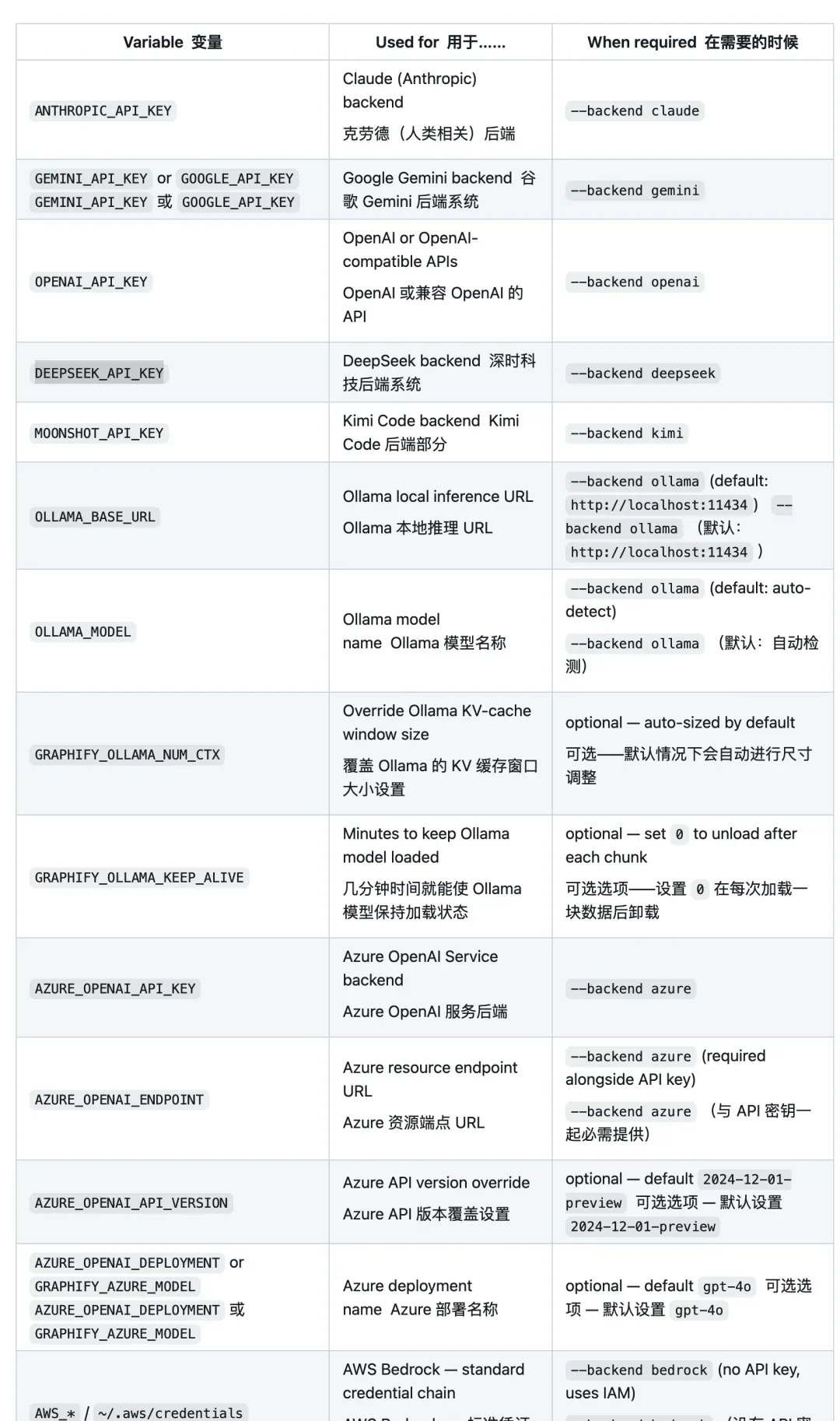
使用云端模型时,则按后端设置对应的环境变量,如 OPENAI_API_KEY、ANTHROPIC_API_KEY、GEMINI_API_KEY、DEEPSEEK_API_KEY、AZURE_OPENAI_API_KEY、AZURE_OPENAI_ENDPOINT 等。
技术栈与可选依赖
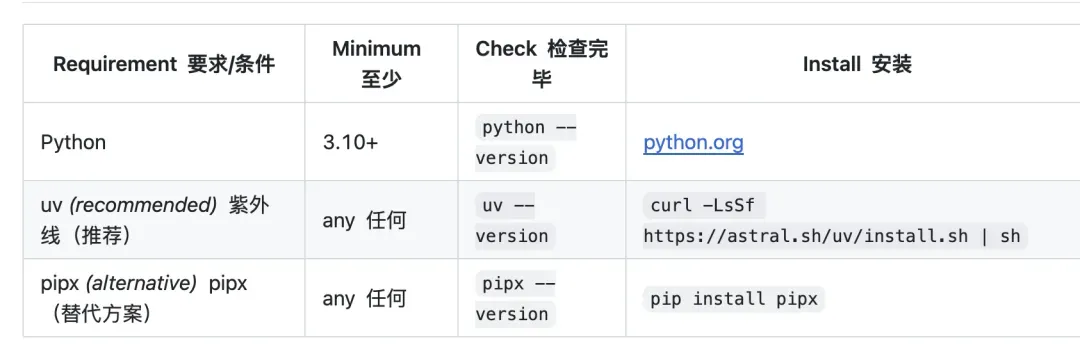
主语言为 Python,要求 Python 3.10+,核心依赖中包含 networkx、datasketch、rapidfuzz 以及一系列 tree-sitter grammar。可选依赖按功能拆分,如 mcp、neo4j、pdf、office、video、postgres、terraform、ollama 等,默认安装不至于太重。
实用功能扩展
Graphify 还提供了一些很贴近工程现场的小功能。
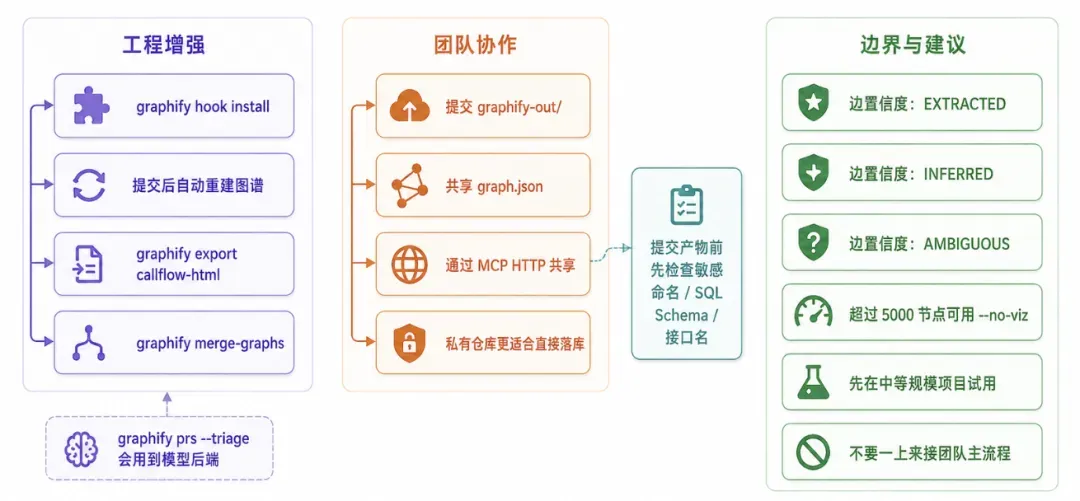
例如 graphify hook install 可以安装 git hook,在提交后自动重建代码图谱。官方也建议在团队协作时,将 graphify-out/ 目录一并提交到仓库,这样其他成员拉取后,AI 助手立刻就能读取已有图谱,不必每个人都先完整跑一遍抽取。
但这一步骤不能无脑执行。graphify-out/graph.json 中会包含项目实体、路径、关系以及部分语义信息,对私有仓库一般没问题;如果是开源仓库,或包含敏感业务命名、接口名、SQL schema 的仓库,提交前最好先检查产物的内容。
再比如 graphify export callflow-html 可以导出可读的调用流 HTML;graphify merge-graphs 可以合并多张图;graphify prs 则能够查看 PR、CI、review 状态和图谱影响范围。其中的 graphify prs --triage 属于 AI 排序能力,会用到你配置的模型后端,不要把它当成纯本地静态分析。
局限性与使用建议
Graphify 并非一安装就能让 Agent 自动变聪明。它更像一层可查询的项目记忆,图谱的质量取决于抽取质量,也取决于仓库自身的结构。代码中的 AST 关系相对可靠,而文档、PDF、图片等语义关系更依赖模型抽取,可能出现遗漏、错误,甚至将两个只是名字相近的概念连接在一起。
图谱中的边上还附有置信度标签,包括 EXTRACTED、INFERRED、AMBIGUOUS。这说明作者自己也承认,有些关系是明确抽取出来的,有些只是推断,还有一些需要人工判断。
另外不可忽略的一点是,该项目目前迭代极快,issue 数量也不少。经我们复查,GitHub 页面已显示约 120 多个 open issue。近期已有人反馈 OpenAI backend 参数兼容问题、AST 跨文件继承漏抽取、多仓库集成等需求或 bug。这类工具接入了众多宿主和文件类型,稳定性难以一步到位。建议先在个人项目或非核心仓库中试用,不要贸然塞进团队主流程。
README 中还提到,graphify query、graphify path、graphify explain 以及 MCP 的 query_graph 调用会默认写入 ~/.cache/graphify-queries.log,记录时间、问题、语料路径、返回节点数、耗时等信息。默认情况下不会保存完整的子图响应,但如果你对本机痕迹特别在意,可以设置:
GRAPHIFY_QUERY_LOG_DISABLE=1
还有一个现实问题:大仓库生成的图谱过大时,graph.html 可能不适合直接在浏览器中打开。官方给出的处理方式是,节点数超过 5000 时跳过 HTML 可视化,直接查询 JSON:
graphify cluster-only ./my-project --no-viz
graphify query "..."
因此,Graphify 适合的场景是“把项目上下文转变为助手可查询的记忆层”,而不是把所有信息都塞进一张炫酷的大图中让你观看。

如果你已经在用 Claude Code、Codex、Cursor、Gemini CLI 等工具编写代码,并经常让它们回答跨文件、跨模块、跨文档的问题,Graphify 值得一试,但暂时不必把它当作生产级代码理解中枢。
更稳妥的方式是:先在一个中等规模的项目上跑一遍,然后问一些你自己知道答案的问题,比如认证入口、数据库访问链路、核心服务调用关系、某个接口的影响范围。如果这些问题的命中率不错,再逐步接入日常工作流。
纯代码仓库可以先本地运行,成本很低;如果涉及 PDF、图片、内部文档,就要事先弄清楚模型后端、数据流向和查询日志。不要只看 graph.html 的视觉效果,重点考察它能否稳定回答你所关心的那几个工程问题。
项目地址:https://github.com/safishamsi/graphify