GLM-5.2编码能力惊艳业界,开源突袭令闭源阵营措手不及
6月21日,X平台上的一条简短推文,瞬间让整个AI圈屏住了呼吸。
01
那个人说出了所有人心里的话
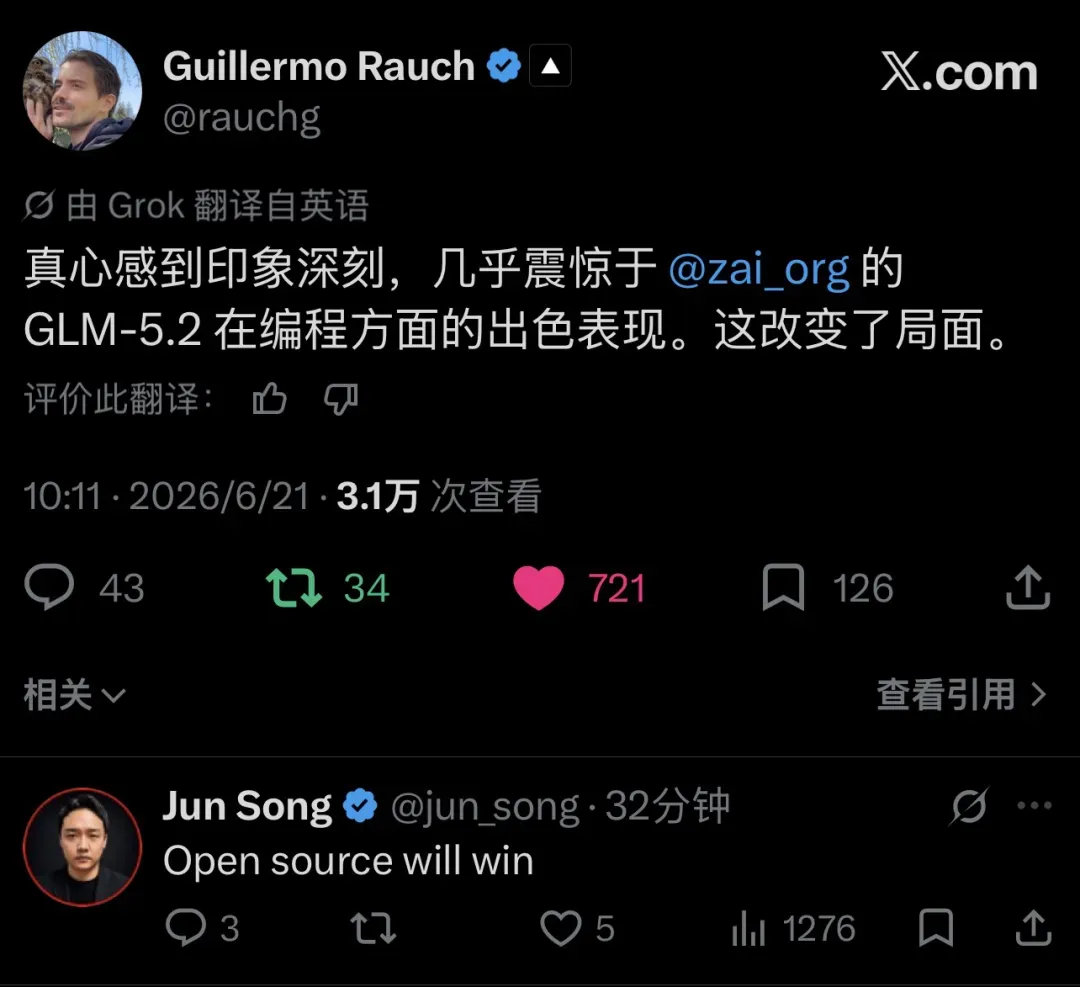
Guillermo Rauch——Vercel创始人兼CEO、Next.js之父,JavaScript生态中的重量级人物——在X上留下了这样一句评价:“Genuinely impressed, almost shocked, at how good GLM-5.2 by @zai_org is at coding. This changes things.” 他被GLM-5.2的编程实力所震撼,甚至用了“近乎惊愕”这样的字眼,并断言这将改写格局。
“Almost shocked”这几个词,绝非一位硅谷CEO的客套褒奖。Rauch日复一日地使用各类模型——从GPT到Claude,再到开源模型——他对编程能力的评判并非来自媒体的隔靴搔痒,而是基于每天撰写Next.js和基础设施代码的亲身体感。一个整天与代码为伍的人说出“被惊到了”,这不是营销修辞,而是内行人的认可。
02
44% 背后的距离
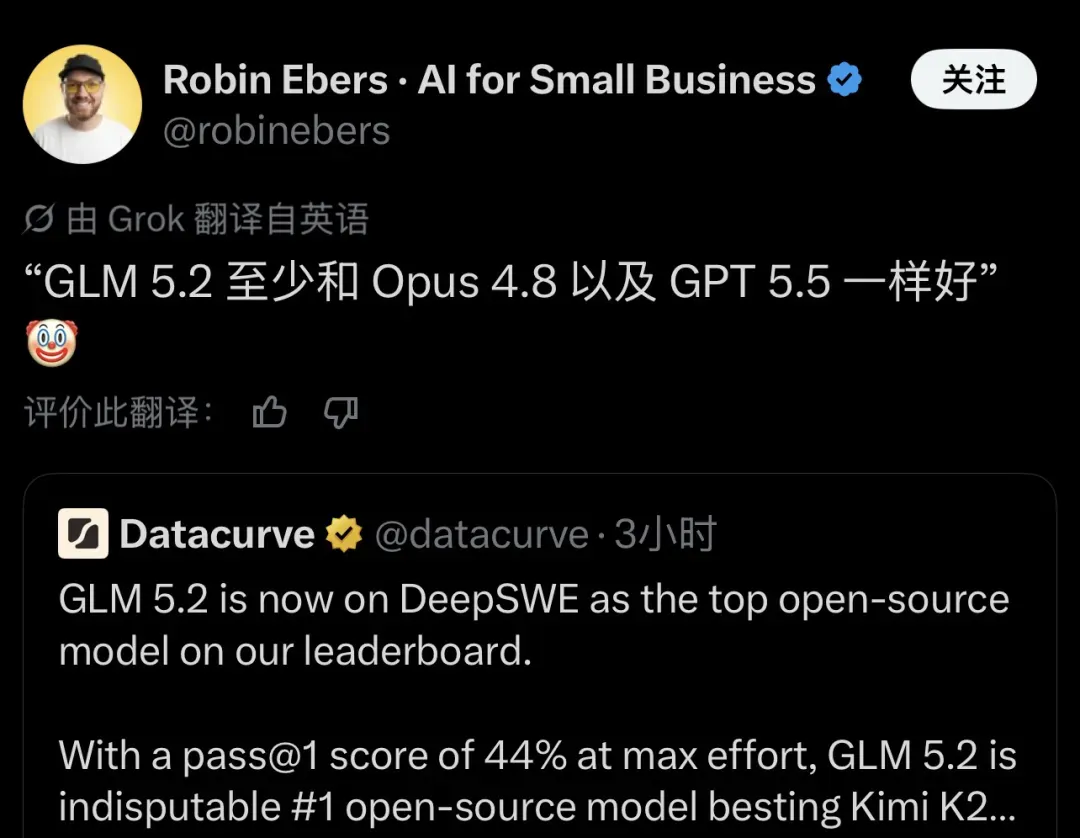
就在同一天,Datacurve更新了DeepSWE排行榜。GLM-5.2以pass@1 44%的成绩登顶开源模型之巅,大幅领先Kimi K2.7 Code的27%,优势高达17个百分点。单看数字可能还不够直观,但结合背景来看:44%的pass@1表现,已经逼近甚至追平了多个闭源模型的水准。
DeepSWE是一项面向长周期编码任务的基准测试,用于评估模型在真实软件工程任务中的端到端能力——它要求模型理解项目结构、定位问题、修改代码文件、并解决依赖冲突。相较于SWE-bench,它的场景更贴近真实的开发环境。
44%的pass@1意味着,在完全不依赖多次采样或重试的情况下,GLM-5.2有将近一半的几率一次性完成一个复杂的软件工程项目。这个数字若放在半年前,任何开源模型都难以望其项背。GLM-5系列此前已在SWE-bench Verified和Terminal Bench 2.0上斩获开源SOTA,与Claude Opus 4.5并驾齐驱,而5.2版本则将这一差距进一步拉大。
03
不是突袭,是蓄谋已久
智谱AI的GLM系列在国内素来口碑稳健,但在国际开发者社区中,其声量与Qwen、DeepSeek相比黯然不少。GLM-5.2的异军突起并非一夜之间的运气。GLM-5系列自架构层面便另辟蹊径,深度优化Agent核心能力,从训练阶段就围绕工具调用和长链路执行进行设计。GLM-5-Turbo版本更是在编码场景上投入了大量针对性优化。
这一策略在GLM-5.2上得到了集中兑现。当其他开源模型还在基座能力上内卷时,GLM-5.2已经把Agent交互、代码理解、长上下文等“工程友好型”指标拉升至闭源模型的水平线附近。Rauch的“shocked”背后,除了对评测分数的认可,更包含着对一款能直接融入生产流程的开源模型的意外发现。
04
闭源的一边,沉默在蔓延
而最为耐人寻味的一幕是:当Rauch的推文和Datacurve的榜单在X上累计数万次浏览、数百次转发时,闭源模型阵营——无论是OpenAI还是Anthropic——都陷入了一片沉默。没有新的评测数据释出,也没有产品升级公告。
“一个开源模型的编码能力至少与Opus 4.8、GPT 5.5相当”——这并非边缘评价,而是来自多个可信信源的交叉印证。在此之前,闭源模型的叙事逻辑始终是“我们贵,但我们是最好的、最可靠的”。当开源模型在核心编码任务上追平甚至反超这个“最好”时,那套叙事便出现了裂缝。
开源与闭源之间的差距,已从“能不能用”演变为“谁更好用”。
更值得关注的并非榜单本身,而是信号的高度一致性。从DeepSWE的标准化评测,到Vercel创始人的第一手体验,再到开发者社群的广泛口碑,三条线索汇向同一个判断:GLM-5.2在编码领域,已经进入了“无需开源滤镜”的评价体系。人们不再因为它是一款开源模型就说“不错了”,而是直接将它和顶级的闭源模型放在同一维度上比较。
这一周,GLM-5.2让许多人看清了一个事实:开源模型追赶闭源的速度,远超大多数人的预期。至于闭源模型将如何回应,所有人都在屏息等待。