GLM-5.2词链推理排第29:分数翻倍背后的效率暗礁
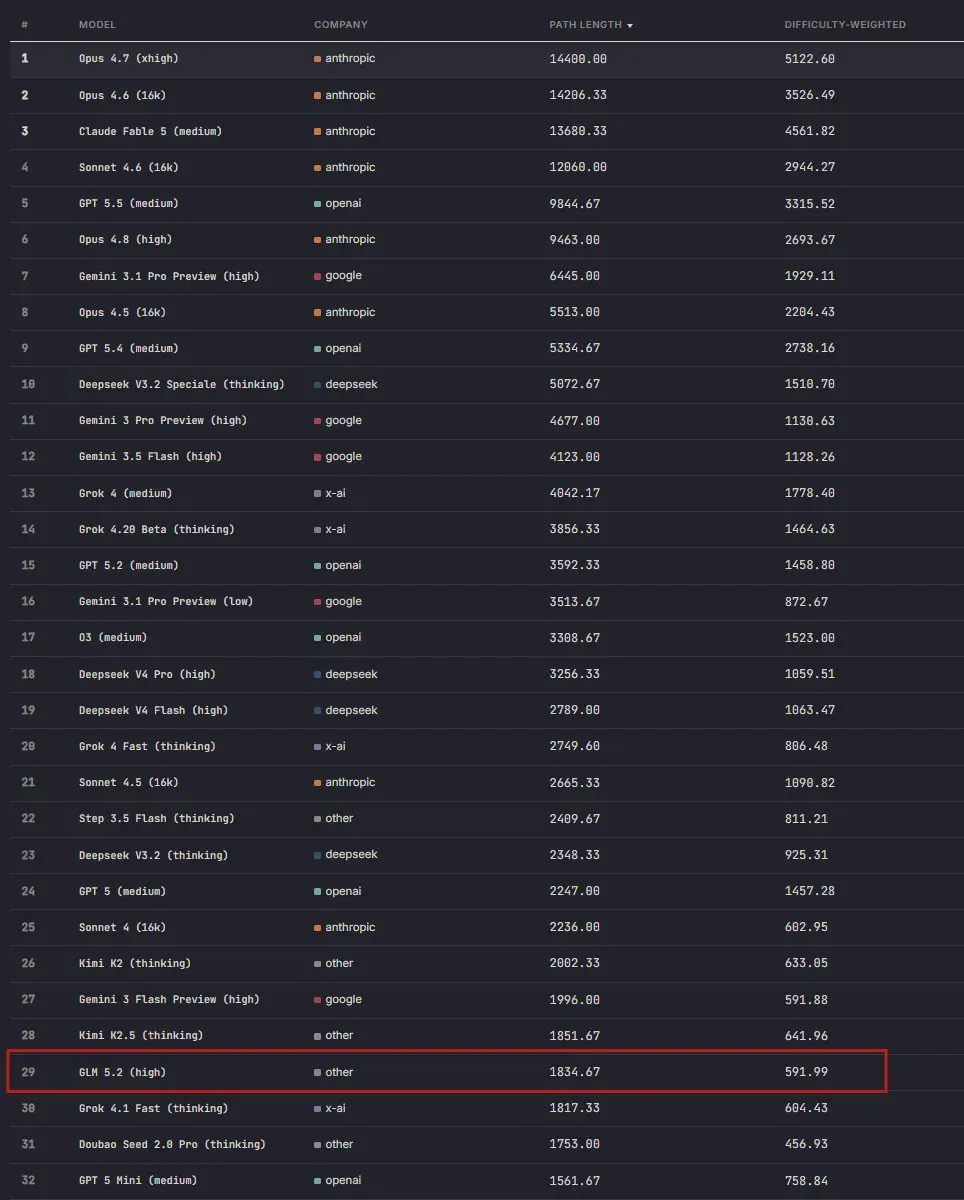
GLM-5.2 在最近一次词链评测中拿到 1834 分,位列全部 139 个模型中的第 29 名。这个位置多少有些尴尬:相比上一代 GLM-5 仅 987 分,进步幅度相当可观,可在整个榜单里依然够不到第一集团,更不用说与 DeepSeek-V4、Kimi 等竞品正面竞争。
- 排名:29 / 139
- 分数跃升:GLM-5(987)→ GLM-5.2-high(1834)
- Token 消耗对比:Kimi-K2.5(≈19k) vs GLM-5.2(≈32k)
LisanBench 考的并非复杂数学,而是一种特殊的词链推理
第一次看到“LisanBench”这个名称,很容易联想到高等数学或代码生成,实际规则却很纯粹:给出一个英文单词作为起点,模型每一步只能插入、替换或删除一个字母,不断生成不重复的有效词汇,尽可能拉长链条。每一步都必须保证新词真实存在,并且不能重复使用之前的单词,更不能走进死胡同。每个起点词会被测试 3 次,最终在 50 个不同起点上统计总分和难度加权分。
举个例子,如果起点是 love,一条可能的链条可以是:
- 插入 r →
lover - 替换 l 为 c →
cover - 删除 r →
cove - 再删 e →
cov(如果字典中没有cov,这一步就算无效)
一句话总结:LisanBench 检测的不是知识储备,而是规则执行、词汇广度、路径规划、记忆去重与持续执行这五项基础能力的综合在线表现。
成绩单看涨幅喜人,但排名与效率不足同样真实
榜单上,GLM-5.2-high 的 Path Length 达到 1834.67,比前代 GLM-5 的 986.83 增长了近一倍。单从纵向提升看,这无疑是一次实实在在的阶段性突破。
但当把视线拉到横向,第 29 名在 139 个模型里仅属中等偏上。榜首被 Anthropic 的 Opus 4.7(xhigh)以 14408 分占据,紧随其后的 GPT-5.5(medium)、Gemini 3.1 Pro、Grok 4 等组成领跑阵营。DeepSeek-V3.2 Speciale(thinking)排名第 9,Difficulty-Weighted 达到 1510;DeepSeek-V4 Pro(high)位列 18,而 Kimi-K2.5(thinking)正好排在第 28 名。也就是说,GLM-5.2 与同圈的 Kimi-K2.5 互有胜负,但还不具备压制这些直接对手的实力。
一个常见的解读误区,是把榜单总分当作唯一否决项的稻草人。LisanBench 官方在 About 页面明确说明:该测试擅长发现模型在“规则执行 + 规划 + 记忆 + 坚持”这类基础能力上的短板,却不能覆盖代码推理、数学推导、多轮工具调用、创意写作等大量常见场景。仅凭这一扇窗口去框定整栋建筑,结论必然失真。
更值得关注的不是排名,而是 Token 效率
榜单同时披露了 Reasoning Efficiency 数据,即模型在产生相同分数时所耗费的输出 token。GLM-5.2 大约消耗了 32k token,而 Kimi-K2.5 仅用约 19k,GPT-5-medium 和 Gemini 3 Flash 则介于两者之间。
这意味着,为了拿到当前的得分,GLM-5.2 每一步都需要更多中间思考,信息密度偏低。对于习惯将模型嵌入内部工作流的团队来说,这个效率差极容易转化为真实的成本差距:同样的结果,GLM 可能比 Kimi 贵出近一倍,响应延迟也更高。
判断: 如果你最在意推理成本,LisanBench 的 Efficiency 散点图远比总排名更有参考价值。
普通用户与 Builder 是否该关心这个榜单?
LisanBench 最适合两类角色:一是模型选型初期做快速筛除的决策者,二是对推理消耗极度敏感的团队。如果你只是用它来写文章概要、润色邮件、整理资料,GLM-5.2 排第 29 的事实几乎不会带来显著影响——更切身的反而是模型能不能稳定支撑长上下文、API 延迟表现如何、中文场景词汇量够不够丰富。
Builder 则可以把 LisanBench 看作一次基础能力体检:如果模型在规则跟踪和记忆去重上只能拿到中位分数,将来在构建 Agent 或执行长链任务时,就需要额外加入审计层来兜住风险。
- 适合:做模型初筛、对比 token 效率、检验基础推理稳定性
- 适合:关心推理成本与长期 token 消耗的团队
- 不适合:仅凭单一榜单决定选型;测试不覆盖代码、数学、工具调用
- 不适合:无法直接推演到中文场景,只能视作英语词链能力的切片
总结
单看 LisanBench,GLM-5.2 的进步是实打实的,但两重短板同样明显:在竞争梯队中的中位排名,以及在同等分数区间里偏高的 token 消耗。如果你正在为团队拟定模型供应商短名单,不妨优先把 DeepSeek-V4、Kimi-K2.5、Gemini 3 系列放进对比池,GLM-5.2 可作为第三梯队后补继续观察。
SOURCES
LisanBench Leaderboard lisanbench.com
LisanBench About lisanbench.com/about