GLM-5.2 海外评测直逼闭源冠军,开源权重正在改写全球人工智能竞赛规则

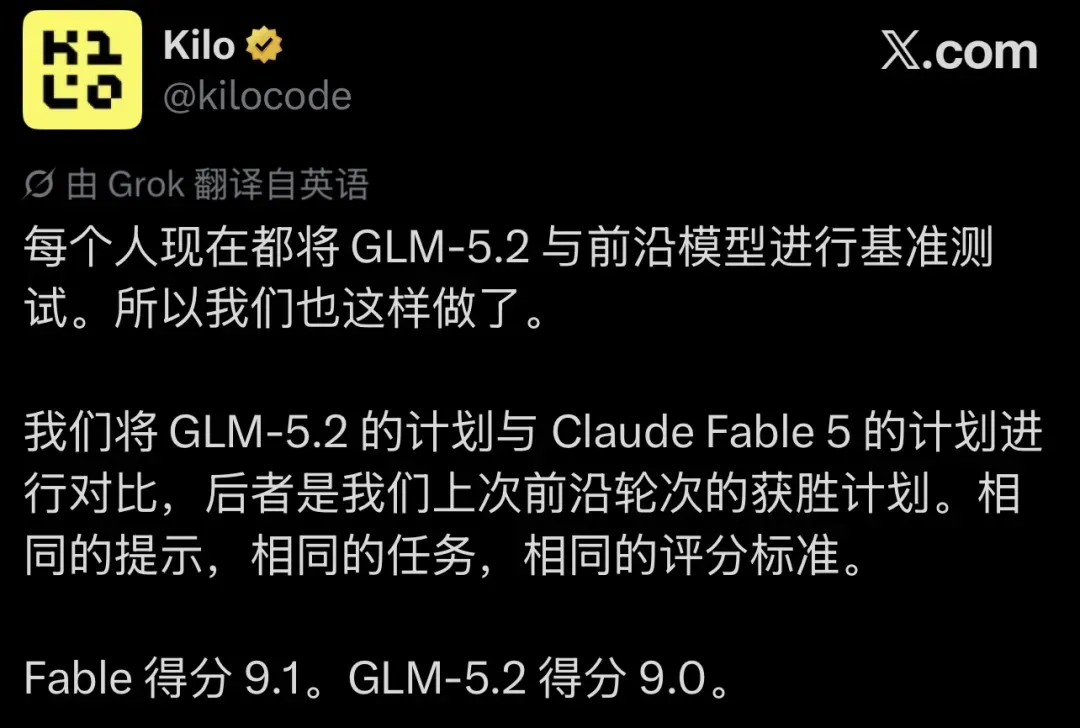
一家海外编程平台用同一套评分标准,把智谱刚刚推出的开源权重模型 GLM-5.2 与 Anthropic 上一轮闭源旗舰 Claude Fable 5 放在一起衡量。结果:9.0 对 9.1。不到 0.1 分的差距几乎可以忽略,但两个模型的身份标签却隔着巨大的鸿沟。

图注:Kilo 平台的评测对比卡片。左侧 GLM-5.2 标注 open weights,右侧 Claude Fable 5 标注 frontier,评分来自同一套标准。
海外开发者到底在兴奋什么
拥有超过三百万用户的海外编程平台 Kilo,其业务直接扎根于 AI 辅助工程,利润命脉系于模型的选择——用什么模型、花多少钱、产出质量有多高。因此,他们对模型的任何风吹草动都极度敏感。
在上一轮测试中,Claude Fable 5 以 9.1 分的成绩成为冠军。这一次,Kilo 把 GLM-5.2 拉进同样的擂台:相同的 prompt、相同的任务、相同的评分指标,最终得分 9.0。开源权重模型与闭源旗舰之间的性能差距,被压缩到了小数点后一位。
这条推文发出后,迅速获得了 421 个赞、13 条深度引用讨论和 2.1 万次浏览。评论区里最高频出现的一个词是 game changer——游戏规则改变者。
对海外开发者而言,开源权重意味着三样东西:可以自行部署、可以自主调优、不必被任何一家 API 供应商锁定。当一个开源模型的性能逼近闭源旗舰时,商业逻辑就被彻底改写了。
拼的不是性能排行榜,而是经济账
海外开发者对大模型的关注点,与国内存在一个微妙的错位。国内讨论大多聚焦于谁登上了哪个榜单、谁又宣布了降价,话题围绕 DeepSeek、Qwen、Kimi 的日常体验展开。这些模型在国内已经遍布足够多的免费入口,用户几乎不需要关心底层模型到底是哪一家。
但海外的情况截然不同。Claude、GPT 的 API 价格严格按照 token 计费,企业级调用成本高得惊人。一个中等规模的编程辅助平台,月均 token 消耗可以轻松突破数十亿。在这个规模上,模型单价每差 0.01 美元,月度账单就是数十万美元的起伏。
GLM-5.2 的定位恰好击中了这个痛点:开源权重意味着可以自部署,推理成本由自己的 GPU 决定;它的 API 调用价格远低于 Claude;而输出质量又完全够用。对海外的中小团队和独立开发者来说,这根本不是性价比选项,而是生存选项。
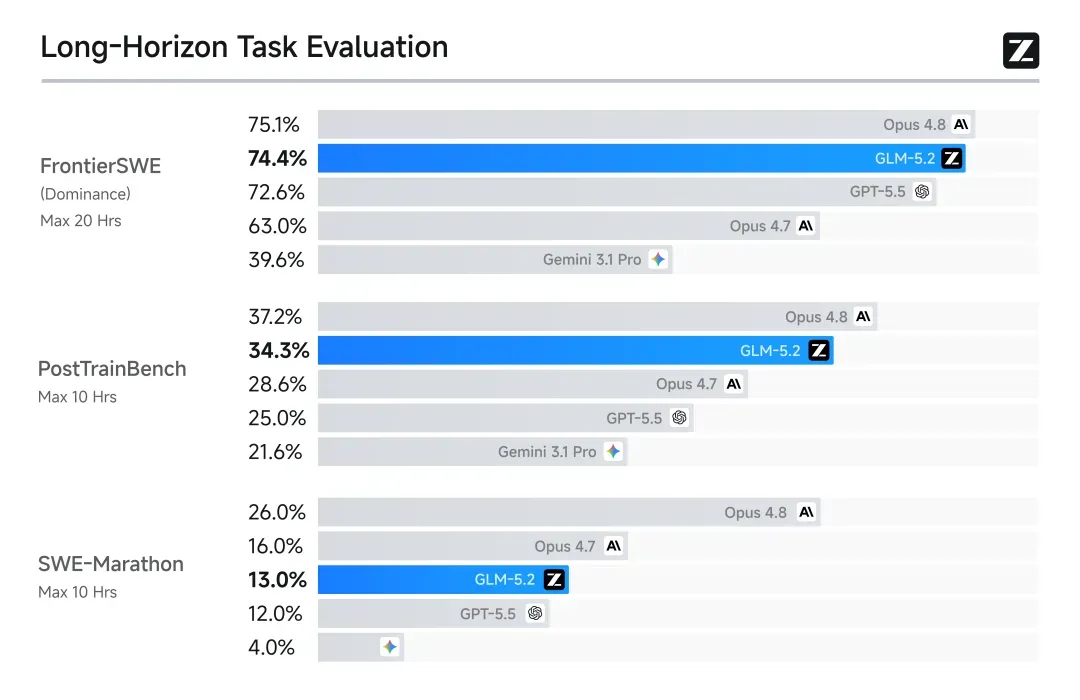
图注:智谱官方公布的 FrontierSWE 长程任务基准。GLM-5.2 整体表现介于 Claude Opus 4.7 与 4.8 之间,是该榜单上排名最高的开源模型。
国内为什么没能同样沸腾
国内并非不关注 GLM-5.2,而是关注的维度完全不同。智谱的 GLM 系列已经在国内更新了好几个主要版本,从 GLM-4 到 GLM-5,再到 5.1 和现在的 5.2,用户对版本号的敏感度早就被稀释了。每一代都宣称自己“更强”,但普通用户很难真实感知到从 5.1 跨越到 5.2 的具体差别。
更关键的是,国内大模型市场已经进入极度内卷的阶段。DeepSeek V4 Flash 的单周调用量超过 3.4 万亿 token,腾讯 Hy3 preview 也超过了 3 万亿,各家都在用价格和流量入口疯狂争夺用户。智谱在 2025 年的营收为 7.24 亿元,净亏损却高达 31.82 亿元。在这样的市场环境中,单款模型的发布很难激起持续的水花。
还有一个常被忽略的因素:国内开发者获取免费大模型的渠道实在太多了。通义、豆包、Kimi 都有慷慨的免费额度,智谱自家的 GLM-4-Flash 同样是免费的。当用户根本不需要为 token 埋单时,开源权重的经济价值就被大幅削弱了。开源的意义在于自部署,但国内绝大多数开发者根本没有自己部署的刚性需求。
开源权重的真正价值在于可控:数据留在自己手里,部署节奏完全由自己掌控,不用排队等 API 配额。当一家海外公司需要把模型部署在自己的服务器上、处理敏感数据,或者对推理延迟有严格要求时,开源就成了唯一不妥协的选择。
不只是 GLM,整个中国开源模型都在海外升温
GLM-5.2 在海外的热度并非孤例。DeepSeek V4 系列和 Qwen3 系列在海外开发者社区的讨论量持续攀升。OpenRouter 平台的数据显示,中国模型的周调用量已经超过 9 万亿 token,实现了连续五周的上扬,环比增长接近 20%;同一时期,美国模型的调用量约在 4.9 万亿 token 左右。
这些数字清晰地指向一个趋势:海外开发者正在用脚投票。不是因为他们天然偏爱中国模型,而是因为在价格、质量和可控性这三个核心维度上,中国开源模型集体提供了一个此前根本不存在的选项。
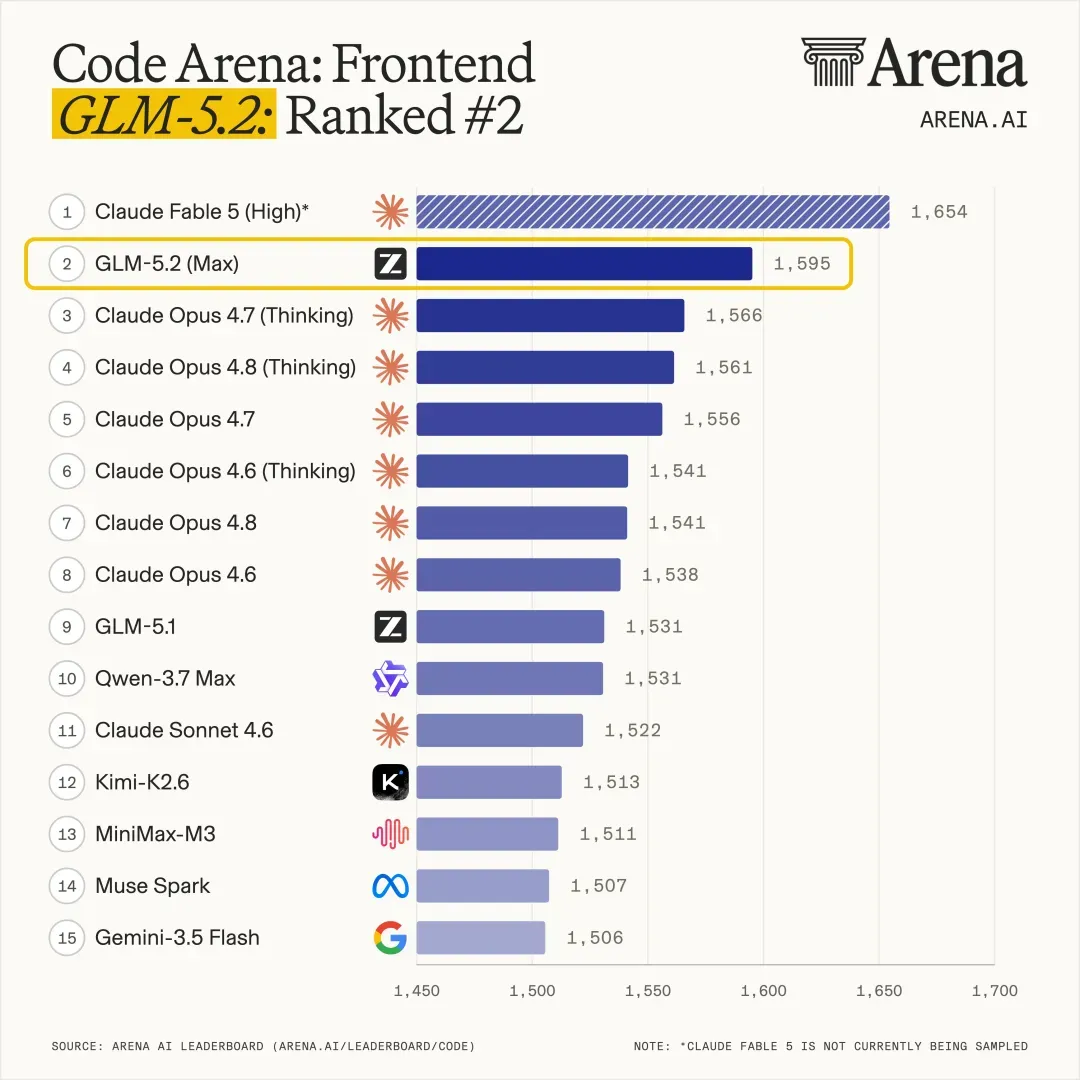
图注:Code Arena 全球前端开发盲测排名,GLM-5.2 取得全球可用模型第一。百万级别的用户参与,使得这个结果比厂商自测更具参考价值。
智谱的 Coding Plan 产品也进一步印证了这一点。GLM-5.2 提前向 Coding Plan 用户开放后,开发者的反馈集中在几个关键词上:项目级上下文承载能力更强、长程任务执行更稳定、工程规范遵循更可靠。这些评价都指向同一个方向——这个模型不只是跑分漂亮,实际可用性也正在扎实地跨过门槛。
价格、能力与工具链的同步咬合
中国大模型在海外的影响力,靠的不是单点突破。DeepSeek 用极致压缩的训练成本证明了技术路线的可行性,Qwen 在 Agent 和长程任务上持续迭代,而 GLM-5.2 则把开源权重的输出质量推到了几乎与闭源旗舰持平的水平。三条线正在同时向前推进。
背后的底层逻辑是算力路线的分化。当美国对华芯片出口管制持续收紧,中国厂商被迫在有限的算力条件下做出更多成果。这种约束反而催生了更高效的训练方法和推理优化。尽管华为的 Tau Scaling 和 LogicFolding 并不直接等同于制程的物理突破,但它代表了一条可行的绕行路径:用架构、封装和系统级的协同来弥补工艺代差。
海外开发者看到的已经是一个相对完整的生态:开源权重、合理的定价、活跃的社区、持续的版本迭代。这些要素叠加在一起,让中国开源模型从“便宜的替代品”进化成了“值得认真对待的选项”。
如果你是海外开发者,想尝试 GLM-5.2 的理由非常简单:同一级别的输出质量,开源权重的自主可控,以及低一个量级的价格。而如果你身处国内,也不妨切换一下视角:海外同行对这个模型的热情,恰恰说明中国开源模型正在建立实实在在的国际竞争力。
下一次当你在海外社区看到中国模型被热议时,不妨留意评论区的关键词。不再是“遥遥领先”,也不再是“吊打”,而是“可用”“够用”“值得部署”。这三个词,比任何跑分都更有分量。
参考来源:Kilo 平台 X 帖子(2026.06.19)| 智谱 GLM-5.2 官方文档 docs.bigmodel.cn | OpenRouter 2026 年 5 月调用数据 | 智谱 2025 年财报数据