纯文本模型GLM5.2,如何在网页设计上击败所有能看见的对手
一个没有视觉感知的纯文本模型,在网页设计评测中碾压了所有具备“视觉”能力的竞品。这听起来不可思议,却真实发生了。
01
一个开源模型,冲上了设计评测榜首
6 月 19 日,评估平台 Design Arena 放出了最新报告。GLM 5.2 在单轮网页设计(非智能体模式)排行榜上位列第一,将 Claude Fable 5、Opus 4.6、Opus 4.7 等明星模型尽数甩开。Fable 5 此前长期霸占 Design Arena 胜率头名,数月未遇敌手。GLM 5.2 是第一个终结这一格局的模型。
GLM 5.2 由 Z.ai 推出,参数量 7440 亿,采用 MIT 开源协议。最令人意外的是它根本没有视觉能力——却要在“看”的细分领域里击败各路“视觉”高手。更惊人的是价格:每百万 token 输入仅 $1.40、输出 $4.40,仅为 Fable 5 的八分之一(Fable 5 为 $10/$50)。
Design Arena 评测报告指出:“它是 MIT 协议开源模型。尤为难得的是,Z.ai 用与 GLM-5.1 完全相同的 7440 亿参数规模,在不具备视觉能力的条件下实现了这一成绩,而其最接近的竞争对手,参数规模据推测足有 6.7 倍之多。”
02
它写出的网页,天然更讨喜
Design Arena 团队对大量案例逐项分析后,归纳出 GLM 5.2 三个关键行为特征。
第一,它掌握了一套优雅的模板体系。 团队将 GLM 5.2 与 Fable 5 各自生成的 1000 个网页截图进行聚类,发现 GLM 5.2 存在明显的模板化倾向——不同提示词下输出结构高度一致。但这套模板的设计质量远超其他模型的惯用套路:没有早期 AI 生成那种紫色渐变、过度装饰的拙劣风格,代之以用户更青睐的成熟布局。
第二,它生成的代码“开箱即跑”。 不少模型在调用 chart.js、three.js 等库时容易出错,GLM 5.2 却利用它们游刃有余。在需要使用这些库的 21% 评测对话里,它的胜率直接拉高了 6 个百分点。此外,它在 91% 的会话中都采用了 TailwindCSS,而 Opus 4.8 仅为 57%。
第三,它写得更慢、更细、更用心。 GLM 5.2 平均生成耗时 304.7 秒,是 Fable 5 的两倍;输出代码字符数量多出 25%,行数同样多出 25%。这些多出来的篇幅被用于注入动画、排版变化和交互细节,尤其适合营销落地页。评测用户在打分时,明显更偏好这种“有雕刻感”的产出。
03
它看不见自己的作品,但子 Agent 可以一眼洞察
GLM 5.2 有一个先天短板:没有视觉能力。它能编织出网页,却无法看到页面最终的模样。这使得它在设计评测中拿第一,更增添了几分黑色幽默。
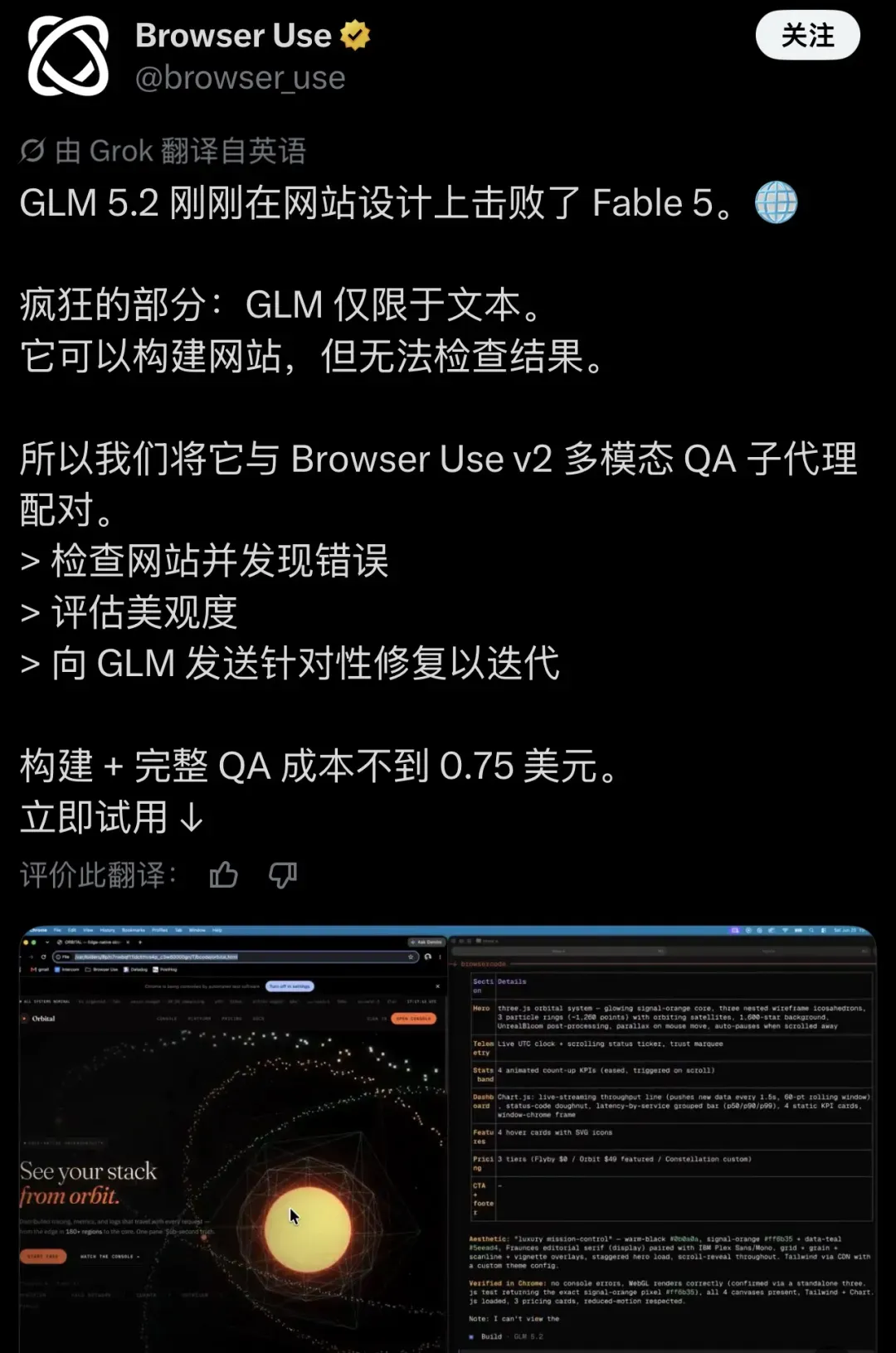
Browser Use 团队做了一件事,直接补上了这个漏洞。他们在 v2 版本中提供了多模态 QA 子 Agent,专门承担视觉验收。工作流是这样的:GLM 5.2 只专注生成,把网页写出来;接着,多模态子 Agent 截图、审查、找 bug、评判美观度,再把这些改进建议递回给 GLM 5.2 进行迭代。一个从生成到质检再到修复的全自动闭环就这样形成,无需任何人工介入。
这正是 Browser Use 在推文中强调的重点:GLM 5.2 能建站,却看不清成品,所以用多模态 QA 子 Agent 完成视觉回路。 整条流程走下来,从设计到质检,成本还不到 0.75 美元。
一个看不见的建造者,配上一群视力敏锐的质检员。这种分工,以前只存在于人类的工地上。
04
刷屏背后,是三条平行线的交汇
这条推文 24 小时内收获 4.2 万浏览、442 个点赞、377 次收藏。评论区中最普遍的情绪就是惊叹——一个 MIT 开源的参数量模型,在纯文本的局限下,仅凭写代码的“手艺”就战胜了顶尖视觉模型。
但如果把这件事拆开来看,会发现三条主线正在同时推进。
第一条,开源模型的能力飞跃。 GLM 5.2 的 744B 参数与 MIT 协议,意味着任何人都能部署、微调、商用。就在几个月前,开源模型还在追赶闭源模型,如今已在细分赛道完成反超。Z.ai 通过 Agent Trace Distillation 和 token 级别优化实现突破,而对手中最大的模型,规模推测是其 6.7 倍。
第二条,Agent 编排弥补模型短板。 纯文本模型不擅长视觉质检,那就让多模态子 Agent 来补位。GLM 5.2 输出更充裕(代码量多 25% 以上)、子 Agent 审查更精准、迭代更快速。这种“看不到但做得到,能看到还能修好”的系统化能力,比单一的模型本领更为关键。
第三条,成本降至可随意试错的阈值。 完成一次设计到质检的闭环,只需不到 0.75 美元。这意味着,你可以让 GLM 5.2 一次生成 100 个着陆页方案,每个都由子 Agent 检查验收,总花费不到 80 美元。而在 Fable 5 上,仅输入输出 token 费用就不止这个数。
05
纯文本的局限,恰恰是它的支点
GLM 5.2 并非全能选手。在游戏开发、数据可视化、3D 设计和 UI 组件等多个排行榜上,它依然落后于 Fable 5。但在网页设计这条赛道上,它找到了一条独特的路径:写得更多、用更成熟的模板、让代码一次跑通,然后借助子 Agent 系统补上视觉盲区。
GLM 5.2 的胜利,本质是“分工式”的胜利。写代码的模型只管写代码,质检的模型只管质检。双方在各自擅长处做到极致,中间由 Agent 编排来桥接。这不再是一个模型击败另一个模型,而是一个体系打败了一个孤立的模型。
对那些正在构建 Agent 的人而言,这件事的启示更直接:当你的模型存在短板时,不要坐等下一次版本升级,让另一个模型来补位就好。一个纯文本模型,加一个视觉质检子 Agent,两块加起来的成本不到一块钱,却做出了当下最顶尖的网页设计效果。
Fable 5 依然是综合实力更强的模型。但如果你只需要做网页设计,GLM 5.2 配合 Browser Use 的子 Agent 系统,是当前性价比最高的组合——没有之一。
一个开源模型在一个细分领域上打败了所有闭源对手,接着另一个团队用 Agent 补上了它天生的短板。这种“队友补位”式的协作,比单个模型的能力突破更值得深究。
来源:Design Arena, Browser Use