GLM-5.2 逼近闭源王者:开源模型用实力击碎芯片封锁
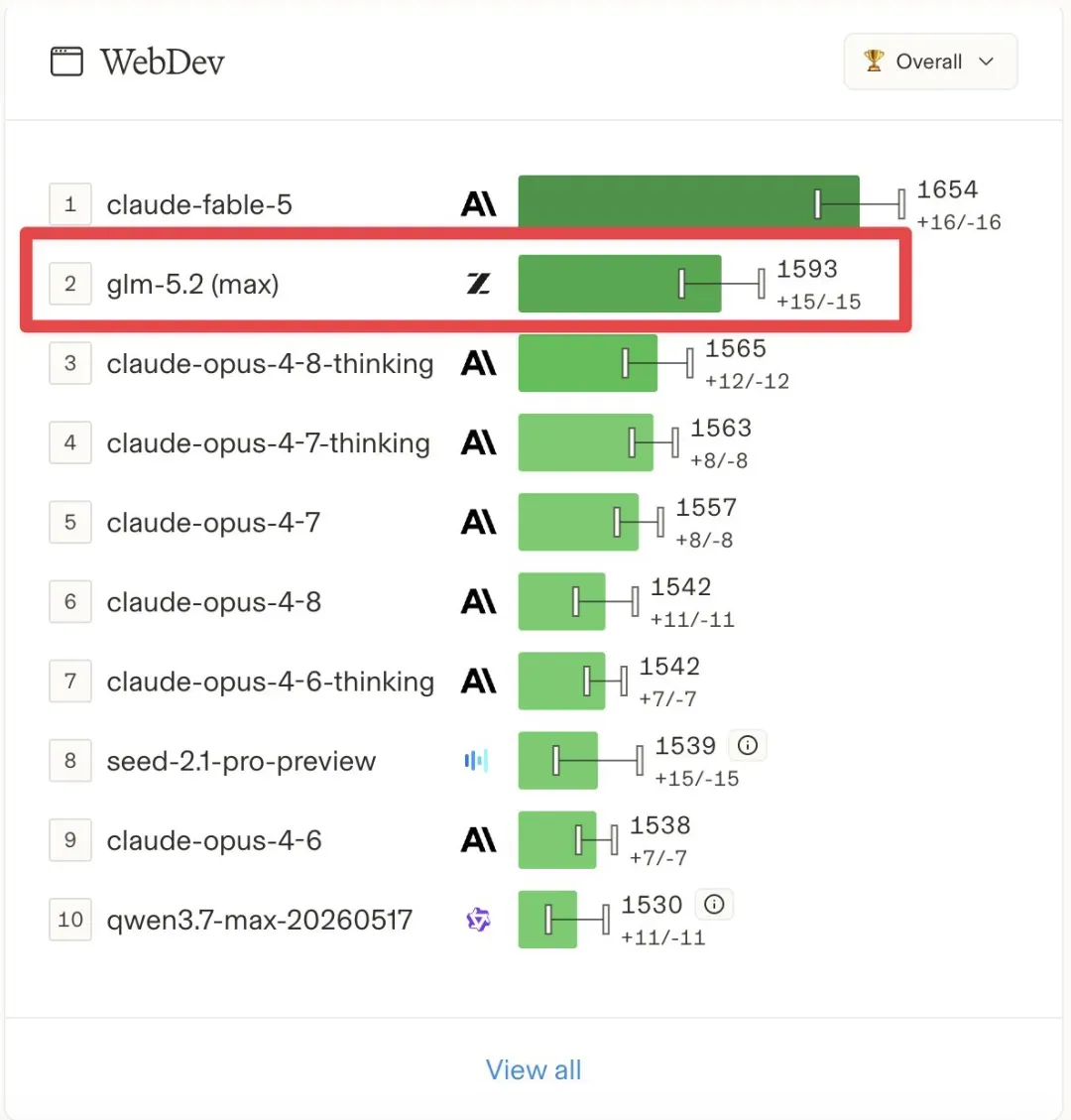
智谱推出的GLM-5.2在Code Arena前端榜单中高居第二,其得分较Claude Opus 4.8 Thinking高出29分;同时在Agent Arena跻身第十,成为排名最靠前的开源模型。这款基于MIT协议开放的753B参数MoE模型,输出成本仅为Claude Opus 4.8的1/5.7。美国持续两年、历经四轮升级的芯片封锁,终究没能挡住中国人工智能的突进。
6月16日,智谱AI(Z.AI)正式发布GLM-5.2,一款采用753B参数混合专家架构的模型,以MIT许可证全面开源,支持1M上下文窗口和128K token输出。发布后仅一周,它便在Arena的Code Arena Frontend排行榜上跃升至第二位,仅次于Anthropic的Fable 5;在Text Arena综合榜上排名第25,领先于多个GPT-5.5变体。每百万token输出费用仅为4.4美元,而Claude Opus 4.8需要25美元,成本差距达到5.7倍,使GLM-5.2成为业界首个在多项基准上紧逼最强闭源模型,同时又完全开源且成本仅为对手零头的产品。
若仅看开源赛道,GLM-5.2在所有公开榜单上均形成断层式领先。Agent Arena第十名与Claude Opus 4.8(非思考模式)几乎持平;FrontierSWE得分74.4%,仅比Opus 4.8的75.1%低0.7个百分点;MCP Atlas上的差距也不过0.8分。输出价格4.4美元对25美元,这5.7倍的成本优势让它成为第一个逼近闭源天花板、且保持开源并让对手成本相形见绌的模型。
智能体能力逆袭:开源模型的历史性突破
GLM-5.2与Claude Opus 4.8同样拥有1M上下文长度,并且兼容Anthropic API,可以直接替换Claude Code的后端模型。在前端代码生成、React组件开发、HTML/CSS实现三个子任务中,GLM-5.2仅落后于专门强化前端能力的Fable 5,位列第二。在Agent Arena评测中,其智能体能力获得81分,以微弱优势反超Opus 4.8的80.1分。BenchLM细分类别打分显示,这是GLM-5.2唯一领先Opus 4.8的大类。Terminal-Bench 2.1得分则达到81.0%,同样创下开源模型的历史最高纪录。Arena官方账号评价道:“GLM-5.2(Max)在Agent Arena排名第十,与Claude Opus 4.8(非思考模式)非常接近,是开源模型中遥遥领先的第一名。”
芯片封锁的逻辑被现实击穿
过去两年半,美国对华AI芯片出口管制经历了四轮加码:2023年11月引入先进芯片许可要求,2025年1月拜登政府推出AI扩散规则,同年5月特朗普政府废除旧规后又于2026年3月酝酿全球封锁,最终在5月31日由BIS发布最新指引——彻底堵死中资企业海外子公司的采购通路。每一轮都比前一轮更严苛。然而,每次收紧之后,总有一款中国模型跨过关键的能力门槛:2023年10月管制升级后,2024年初DeepSeek V2以MoE架构证明有限算力也能训练出优秀模型;2025年5月AI扩散规则废除后,GLM-5.1闯入Arena前20名;2026年5月BIS封锁海外子公司通道后,GLM-5.2在多项基准上直逼闭源最强。
英伟达CEO黄仁勋在5月接受采访时已公开坦承:美国出口限制正持续重塑全球AI芯片格局,英伟达已将中国市场“基本上拱手让给”中国公司。这并非谦辞,而是冷硬的财报数字——英伟达中国区Hopper芯片出货量已跌至零,而上一财年同期该业务收入尚达46亿美元。
封锁的悖论:为开源生态添砖加瓦
BIS新规执行“推定拒绝”标准,实质性堵死了中资企业海外子公司的采购通道。审查逻辑从“看注册地”转变为“看最终母公司”,被普遍视为对“中企在马来西亚、新加坡等地设立壳公司绕道采购”的最终清算。但这套政策链内含一个结构性悖论:封锁越紧,中国公司的自研投入越是被迫加大,结果反而越不可逆。GLM-5.2选择以MIT协议发布,意味着全球任何公司——包括Anthropic、OpenAI的直接客户——都可以自由下载模型权重、自行部署、微调并用于商业目的。美国出口管制的边际成本,就这样转化成了中国开源模型在全球范围内传播的收益。你可以把最先进的芯片扣押在海关,却无法阻止一个MIT授权的模型权重被全球60亿人下载。后者对AI格局的冲击,远比前者更为深远。
判断 当一个MIT模型在多个基准上与输出费用高达25美元/百万token的闭源模型仅有0.7分之差时,管制芯片的边际收益已经转为负值。开源模型的进化速度,已经超过了政策迭代的节奏。对开发者而言,GLM-5.2是极具竞争力的新选择;对政策制定者来说,这更是需要重新审视整套管制框架的强烈信号。接下来值得关注的是,Fable 5之后,下一个封闭超大规模模型还能拉开多大的差距?
SOURCES
Arena.ai - Leaderboard Changelog & Agent Arena
LLM Stats - GLM-5.2 vs Claude Opus 4.8 Full Comparison
CodingFleet - Claude Opus 4.8 vs GLM-5.2: 0.7 Points From the King
BIS Official Guidance - Export Controls for Advanced Computing (May 31, 2026)
Z.AI - GLM-5.2 Technical Report & Model Card