GLM-5.2 正式发布:1M 上下文国产第一,编程能力与审美双双领跑
GLM-5.1-HighSpeed 面世时,我就曾表示十分期待 1M 长上下文版本。没想到仅仅数周之后,大家翘首以盼的 GLM-5.2 就带着 1M 上下文窗口如约而至。

全新发布的 GLM-5.2 可以这样概括:**1M 上下文窗口 + 国产模型中编程能力第一,**并且设计审美极具水准。
相较于此前 200K 上下文的旧版模型,GLM-5.2 在下列场景中的表现有了质的飞跃:整库级代码分析、Agentic Coding、超大规模代码仓库重构、一键网页翻新以及超长文档处理。
这些任务的共同点是上下文必须完整覆盖,任何压缩都会带来信息损失。
近几天我消耗了 3800 万 Token,也颇为认同社区用户的一则调侃:从这周开始,你很可能会发现中转站里那个看起来像 Opus 的服务,背后其实跑的是 GLM-5.2。

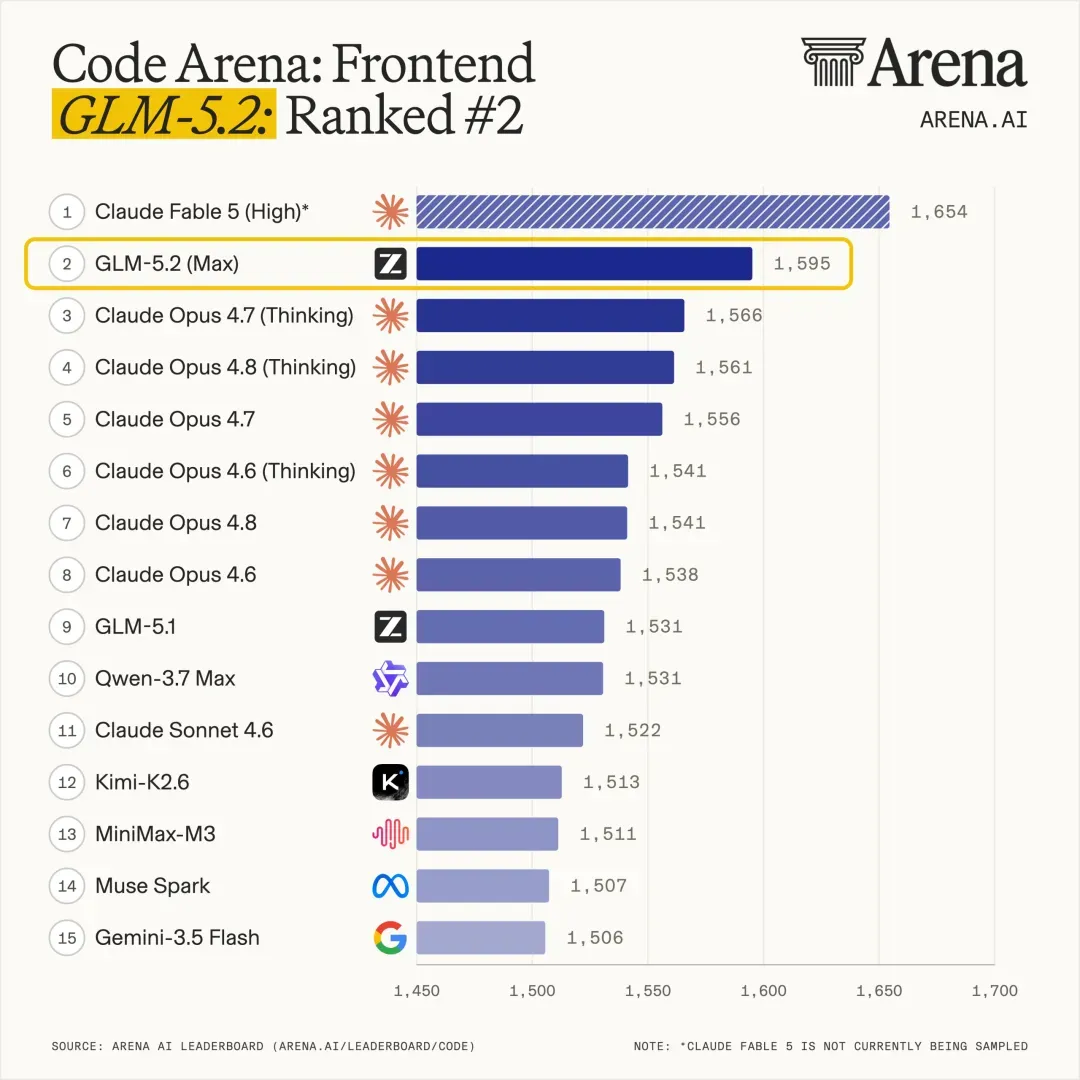
此外,在拥有全球百万用户参与盲测的前端开发评估系统 Code Arena 上,GLM-5.2 取得了全世界所有可用模型中的第一名。
这里要强调“全球可用模型”这一限定,因为表现最惊艳的 Fable 5 尚处于被封禁状态,无法公开使用。
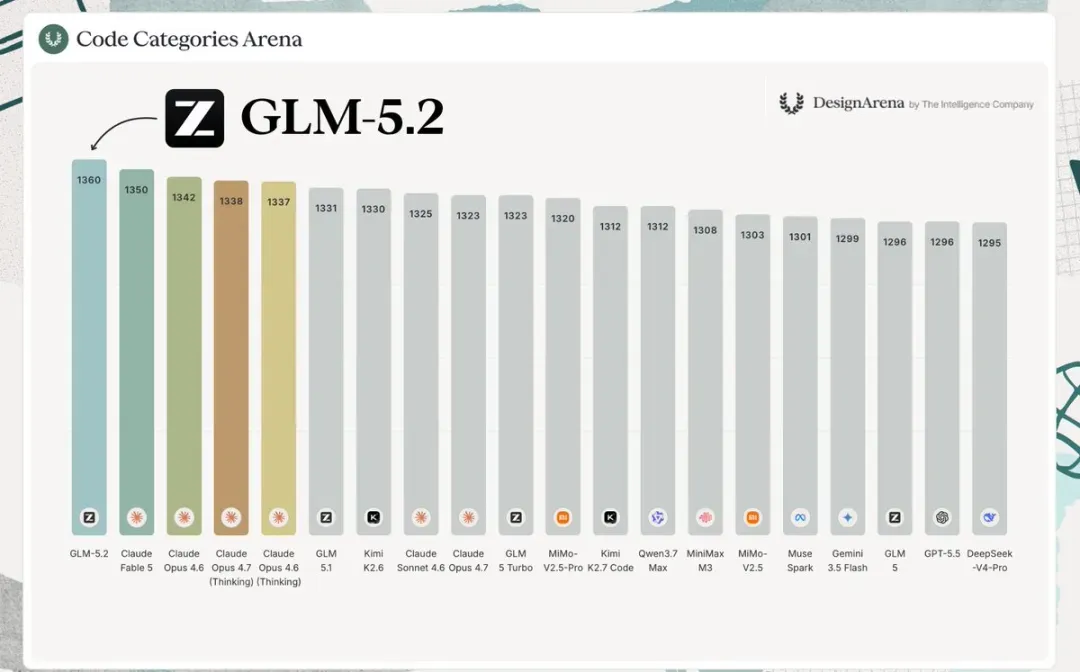
在专门衡量模型设计审美的 Design Arena 榜单上,GLM-5.2 同样摘得全球第一。
三重核心升级
第一重:真正可用的 1M 上下文窗口
如果你是一名 Claude Code 或其他 Agent 工具的深度用户,一定经常通过 /context 命令或者状态栏来监控当前上下文窗口占用了多少。
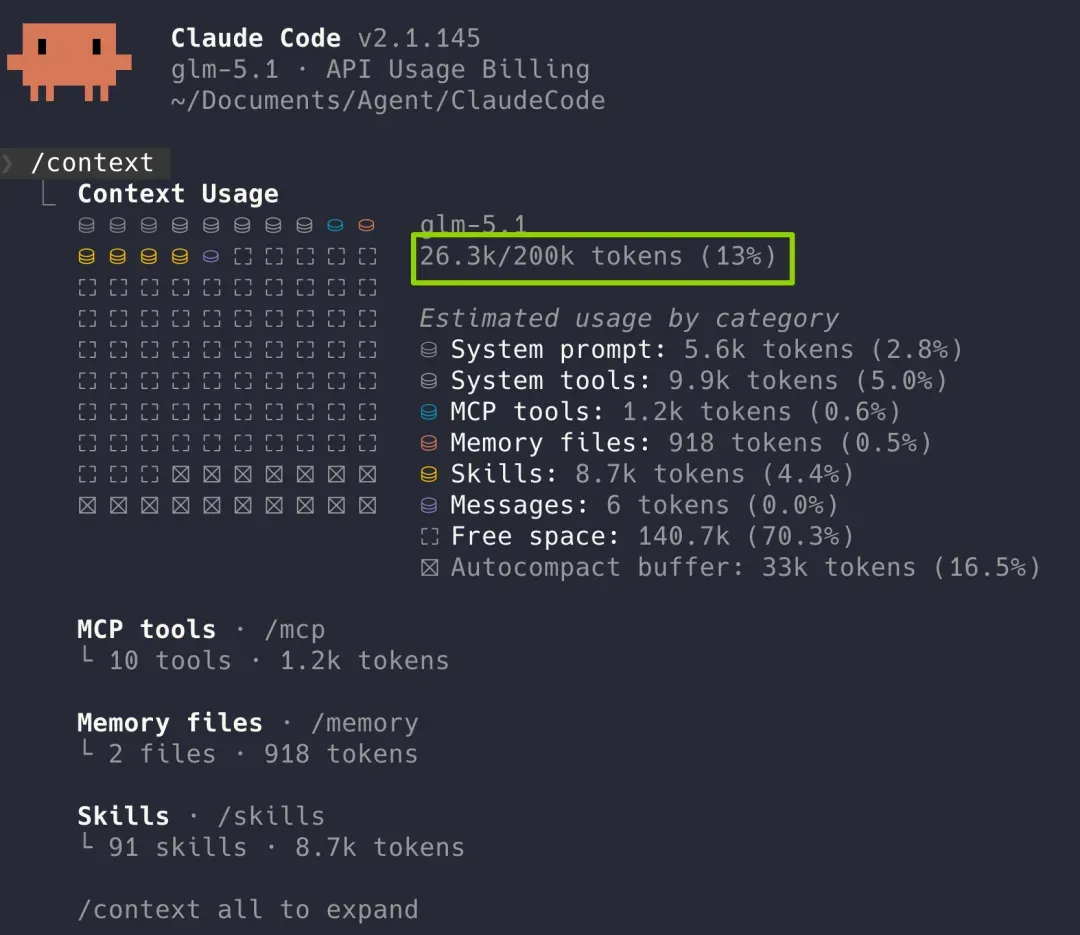
一旦占用率超过 70%,模型就很容易给人一种“变笨”的感觉。这正是上下文窗口不够长带来的副作用——不敢直接读大文件,也不敢频繁使用搜索功能,几次操作之后可用的窗口空间就所剩无几了。
现在 GLM-5.2 把上下文支持从之前 GLM-5.1 的 200K 直接拓展到了 1M 级别。
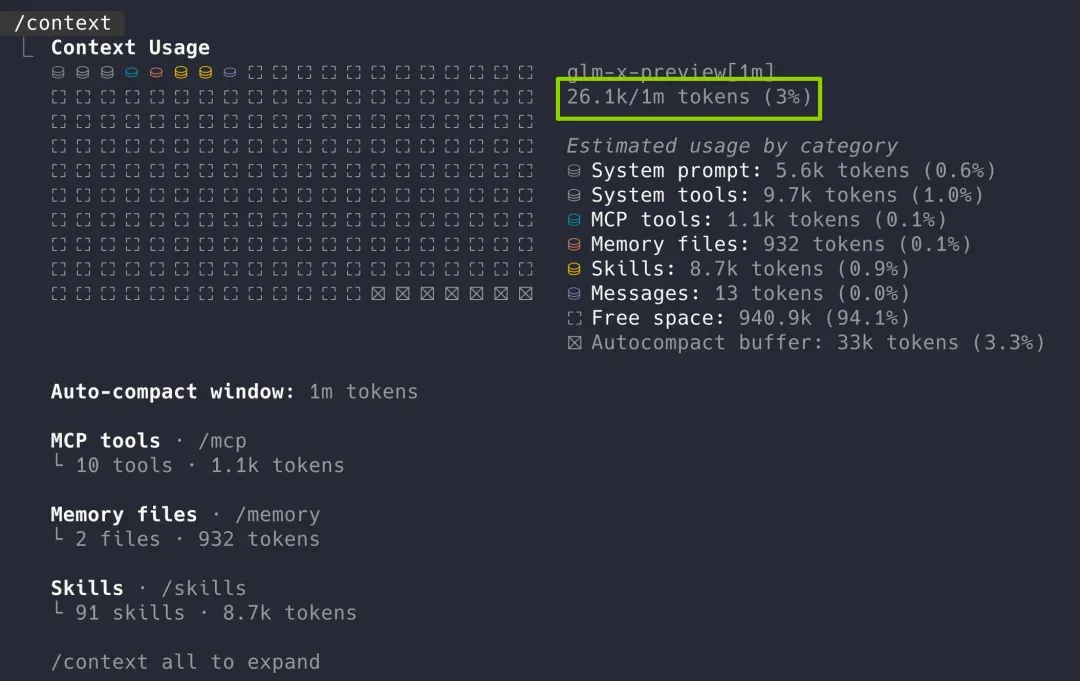
官方数据显示:在 1M 长度下,检索和推理效果的衰减显著优于同类模型。这要归功于 GLM-5.2 在注意力结构上所做的优化——KV8、LayerSplit、IndexShare 4 与 HiSparse 这一套组合拳,同时压低了长序列的效果衰减与推理成本。在 MRCR、GraphWalk 两项长文本基准测试中,模型持续到 1024K 长度时依然能够维持稳中有控的衰减。
第二重:编程能力稳居国产与开源模型双料第一
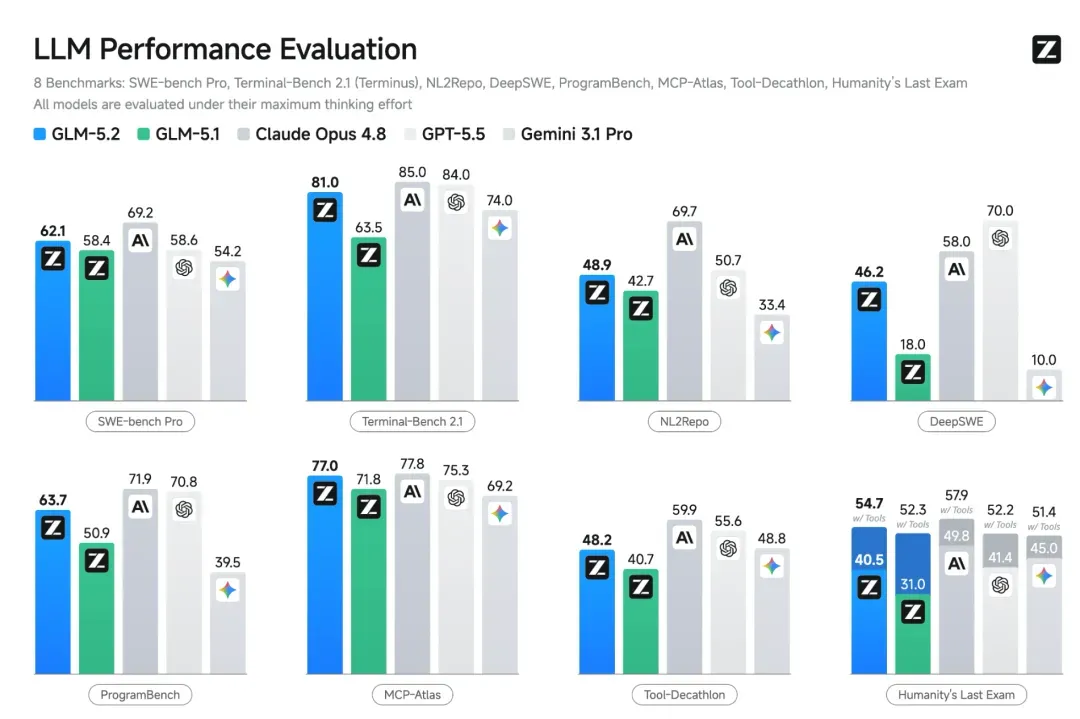
在 SWE-Bench、Coding Arena 等核心编程评估基准上,GLM-5.2 继续保持国产模型第一、开源模型第一的位置,性能直接对标 Claude Opus 4.8。
第三重:长链任务不“忘事”
GLM-5.2 在长程任务上的表现也明显增强。在多项长序列基准测试中,它的成绩处于 Claude Opus 4.7 与 4.8 之间,是所有开源模型中排名最高的。我本人长时间深度使用的体感也证实了这一点。
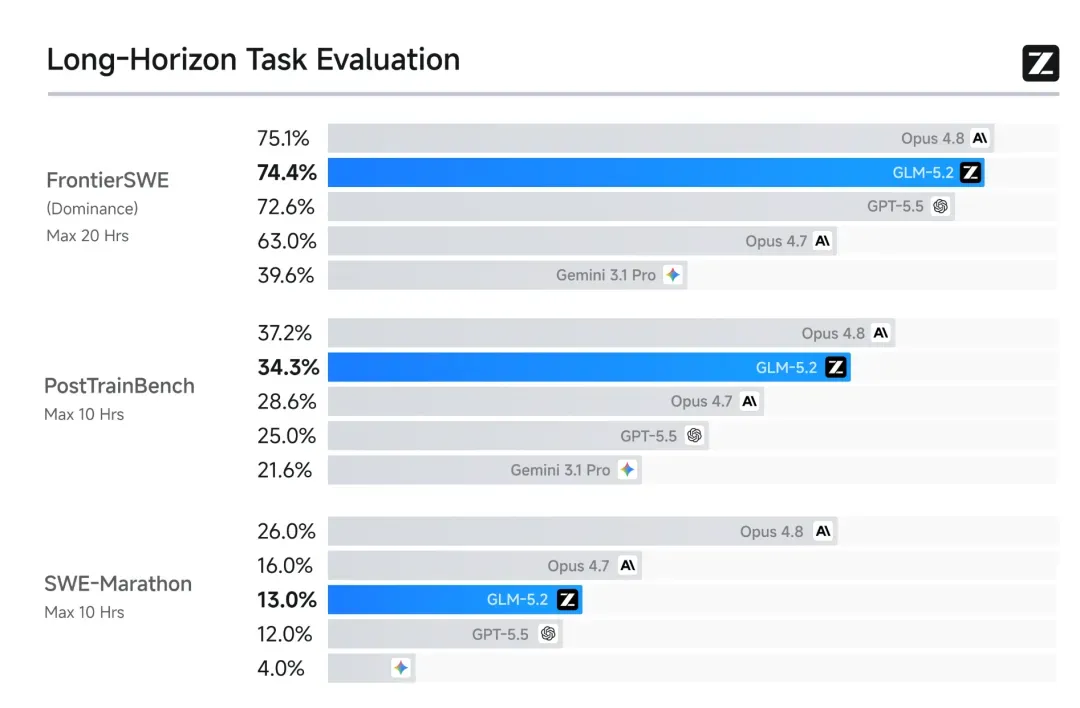
实战案例对比
我们分别让 GLM-5.1 与 GLM-5.2 对同一个开源项目的仓库进行深度读取,各自生成一份详细的分析报告。之后我精读了两份报告,并请其他模型进行评判。结论是:GLM-5.2 的输出明显更有效,无论是全面性、深度还是准确度,都优于前代版本。

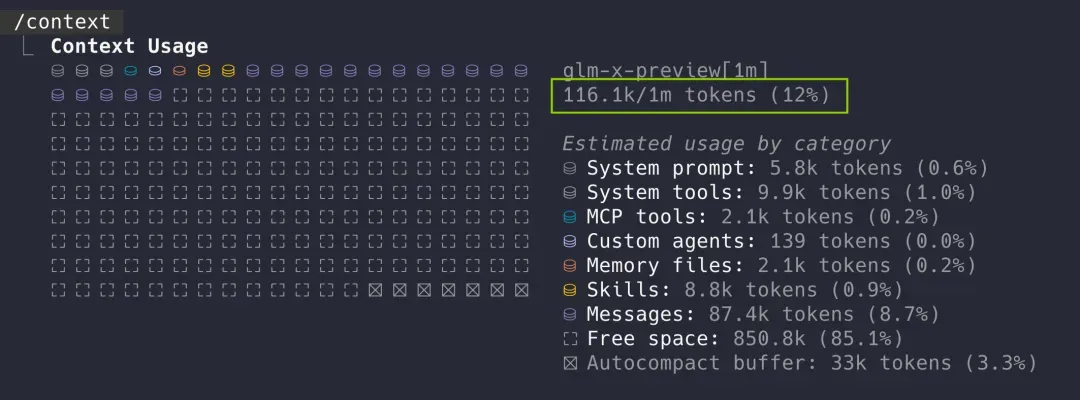
更令人欣喜的是,完成同样的仓库分析后,GLM-5.2 的上下文窗口仅使用了 12%。
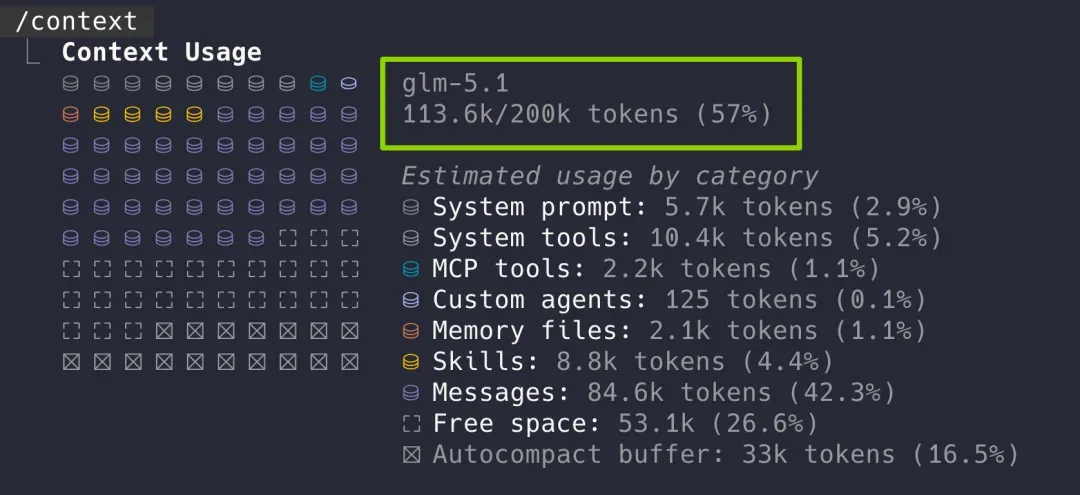
而拥有 200K 窗口的 GLM-5.1 在执行同样任务时,窗口占用已接近 60%。这意味着还没正式开始开发,仅是全面读懂项目就消耗掉超过一半的上下文容量,后续多轮迭代的效果必然会大打折扣。
得益于长上下文的加持,GLM-5.2 即便面对大批量文件处理、需要多文件协同生成的长链办公任务,也表现得游刃有余。例如:一次性阅读上万字的 PRD 文档并生成上百个 APP 界面,或学习上百份合同文件后输出专业的审批意见。
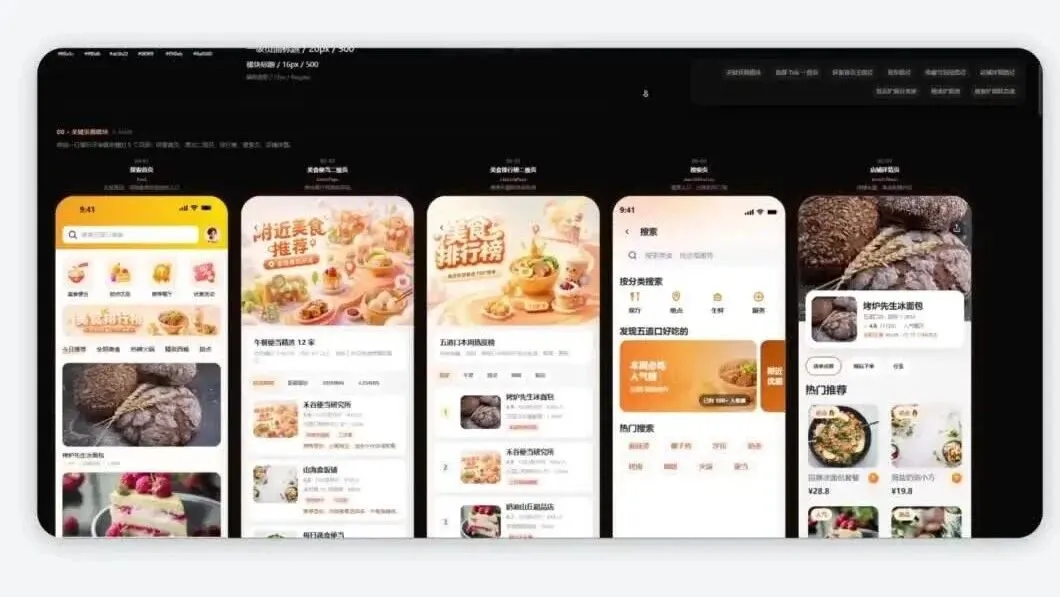
继续观看:GLM-5.2 终于能用了:1M 上下文,Coding 继续国产第一。
同时,我对 GLM-5.2 的直出设计审美也进行了测试。仅使用一句提示词,不调用任何 Skill:“帮我生成一个 2026 美加墨世界杯宣传网站,要求大气、上档次。” 模型直接生成的页面告别了那种充满“AI 味”的紫红色调,设计理念自带审美。
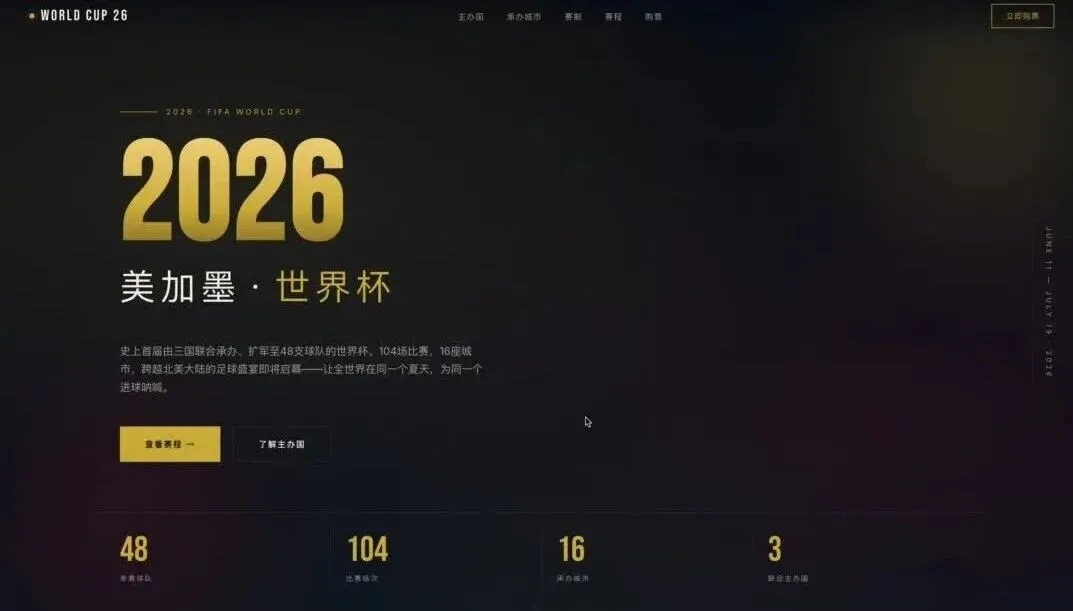
继续观看:GLM-5.2 终于能用了:1M 上下文,Coding 继续国产第一。
长上下文实现的工程难题
要将上下文窗口拓展到 1M 级别,会面临计算量和 KV 缓存两大瓶颈:令牌数量上升后,原始注意力机制的计算复杂度呈平方级增长,从 128K 到 1M,稠密注意力几乎无法运行;同时每增加一个 token,KV 缓存都会持续膨胀,显存压力急剧攀升。这正是很多模型虽然标称支持 1M 上下文,但实际使用中又慢又贵,最终大家只能退回到 200K 的原因。
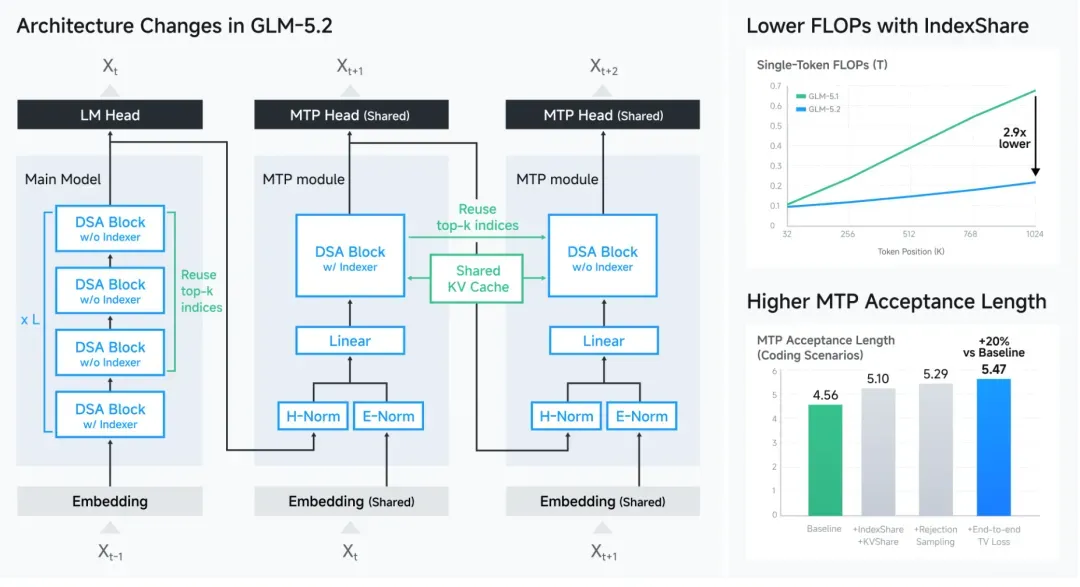
根据 GLM-5.2 的技术报告,团队在注意力结构上做出了创新设计:KV8 将每个 key/value 的分组数从常规的几组扩展到 8 组,实现更细粒度的注意力分流;LayerSplit 在不同层采用差异化的稀疏策略;IndexShare 4 让相邻 token 共享索引;HiSparse 则实现层级稀疏。整套体系的目标就是大幅提升长序列吞吐、显著降低 KV 缓存开销。与 DSA 等稀疏注意力方案相比,这套组合在成本端仍有进一步的压缩空间。最终的结果是,1M 上下文不再是“能跑但用不起”的纸面规格。
如何快速用上 GLM-5.2
模型在发布当天就已经全面可用。好消息是 Coding Plan 用户也可直接体验,但坏消息是你可能需要拼手速才能抢到资源:
购买 Coding Plan:https://www.bigmodel.cn/glm-coding?ic=UX7NF0VZ4S

Coding Plan 用户可以通过 cc-switch 复制之前 GLM 的配置,然后把模型字段改为 GLM-5.2,将上下文窗口设置为 [1m],重启 Claude Code 即可生效。同样适用于 OpenCode 以及其他支持自定义模型配置的工具,具体配置方式可参考以下文档:
配置说明:https://docs.bigmodel.cn/cn/coding-plan/latest-model
开源仓库及模型链接
GitHub:https://github.com/zai-org/GLM-5Hugging Face:https://huggingface.co/zai-org/GLM-5.2ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-5.2
官方 API 接入
BigModel 开放平台:https://docs.bigmodel.cn/cn/guide/models/text/glm-5.2Z.ai:https://docs.z.ai/guides/llm/glm-5.2
在线体验入口
Z.ai:https://chat.z.ai智谱清言 App / 网页版:https://chatglm.cn