深入解析Google AI Agent架构:从白皮书到实践指南
导读:本文基于Google长达60页的官方白皮书《初创公司技术指南:AI Agents》,将其核心内容系统性地拆解为一个可执行的Agent心智模型。本文避免使用华而不实的新术语,而是聚焦于模型、工具、编排、记忆与训练这几件核心要事,为希望深入了解Agent的初学者提供一份完整、清晰的学习路径。
Google近期发布的这份报告,虽然从其宣传来看意在区别于以往偏理论性的文章,也确实披露了不少实践细节,但总体而言,其提供的具体技巧相对常规。不过,它不失为一份非常优质的Agent入门学习材料。
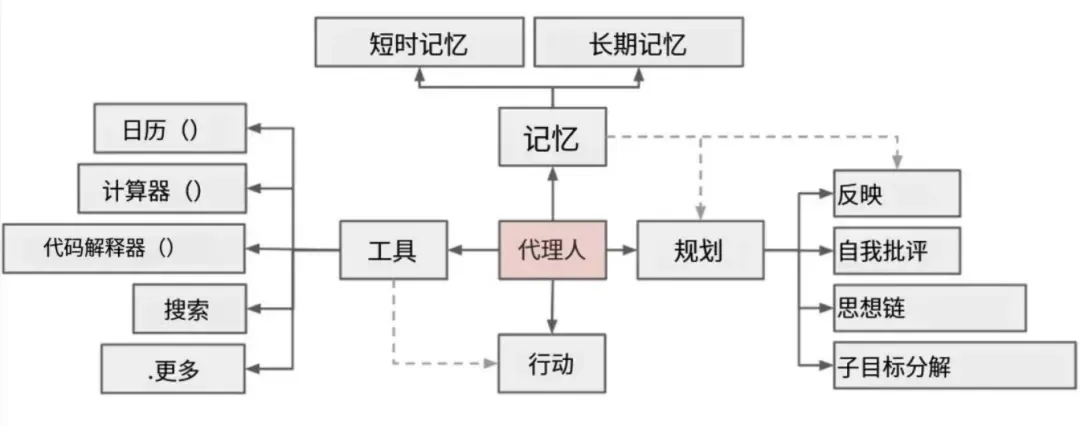
Agent能力的基础,或者说其对工具进行调用的能力,源自于模型的“函数调用(Function Calling)”功能。而模型识别在何种情境下应该调用特定工具的能力,通常是微调训练的结果。例如,Agent可以调用数据库工具获取客户订单以进行个性化推荐,可以根据用户指令调用邮件API发送电子邮件,甚至可以自动执行金融交易。上述每一个功能都要求模型与外部世界(包括工具和数据)进行交互。简而言之,任何具备自主规划与多步任务执行能力的系统,都可被视为Agent。
Agent架构概览
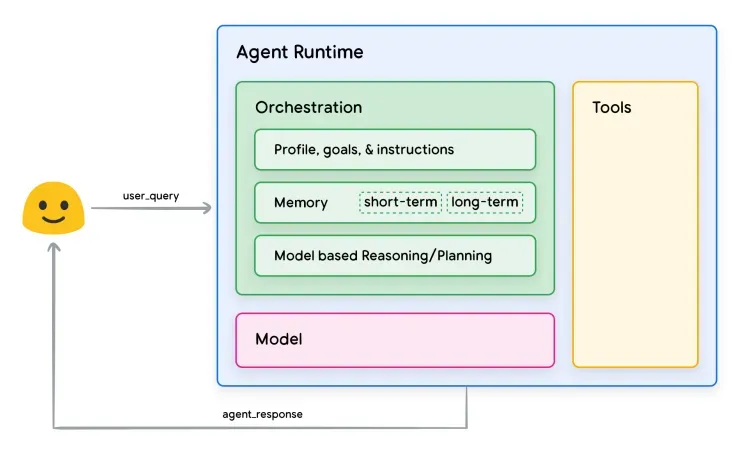
现代AI Agent通常由四个核心层级构成,其经典架构如下图所示:
一、模型层 这是系统的基础,通常由大型语言模型担任,负责自然语言的理解与生成。在实际生产应用中,往往不会依赖单一模型,可能会采用多种模型组合,甚至会对小型模型进行微调以处理特定简单任务。
二、工具层 这包括了各种外部工具与服务,例如数据库、搜索引擎等API。工具层是Agent感知并作用于外部世界的关键。现阶段,工具调用是Agent真正的核心能力,但工具调用的准确性也是当前Agent架构面临的最大挑战。即使在生产环境中采用技能(Skills)技术与强意图识别,其准确率也大致在90%左右,这预示着整个Agent技术的成熟仍需时日。
三、编排层 这一层堪称Agent的“大脑”,负责协调整个系统的运行。具体职责包括编写提示词、执行推理框架、维护对话状态以及决策何时调用工具。它实现了智能体的计划、推理、决策与反馈循环。用更通俗的话来说,广为人知的ReAct架构便是编排层的具体实现,也是代码的主要组成部分。它主要承担以下工作:
- 组织历史对话(状态管理);
- 决策何时调用模型,何时调用工具;
- 判断何时结束推理过程;
- 决定如何构建提示词。 它定义了每一轮循环中语言生成的结构:思考(Thought)、行动(Action)、观察(Observation)。
... → 推理(Thought) → 行动(Action) → 观察(Observation) → ...
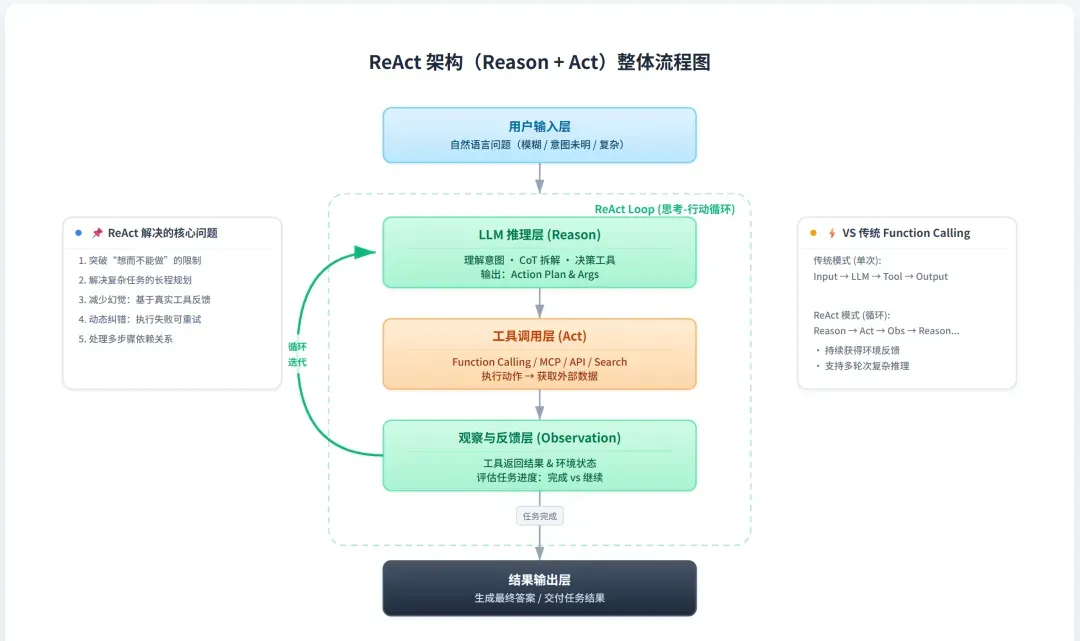
ReAct = 推理(Reason) + 行动(Act):
- 推理(Reasoning): 引导大型语言模型思考“为何”以及“如何”执行下一步行动。
- 行动(Acting): 指导大型语言模型执行具体行动并与环境进行交互。
- 循环反馈: 通过观察行动结果来驱动下一轮的推理步骤。
四、记忆层 记忆层包含短期记忆(如当前对话上下文、近期交互记录)和长期记忆(如知识库、历史数据、用户偏好等)。它用于存储和检索与任务相关的信息,以支持多轮对话和知识补充。
严格来说,记忆层的处理是Agent系统中最棘手的问题之一,这本质上就是“上下文工程(Context Engineering)”。其核心挑战在于:如何确保数据能与AI有效交互,并让AI在每次推理时都能获取到最相关的数据。具体可分解为三个层面:
- 检索的完整性:每次信息检索能否成功获取到对应的数据。
- 数据的适切性:检索到的数据是否“恰到好处”,既不会信息过载(过多信息会浪费Token并可能干扰模型),也不会信息不足(信息过少则无法解决问题)。
- 生成的准确性:在检索正确、数据组织合理的前提下,模型的最终输出是否符合预期。
以下是Agent整体交互架构的图示:
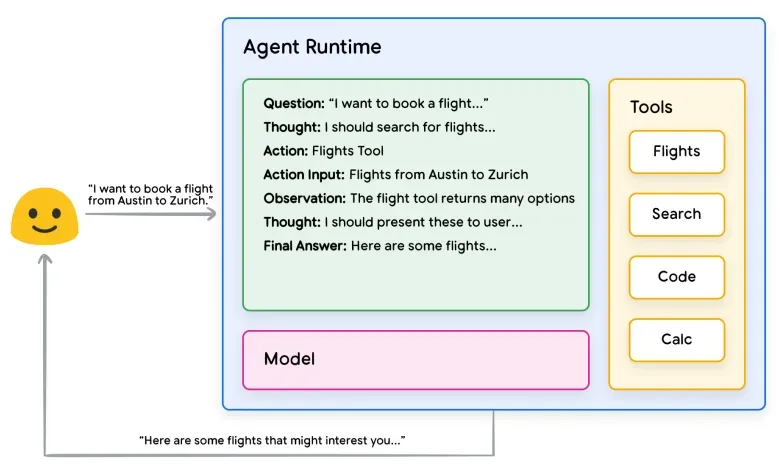
概括来说,Agent的执行流程为:用户输入 → 编排层处理 → 模型生成思考 → 决策调用工具或直接输出结果 → 工具执行并获取反馈 → 更新记忆并进入下一轮循环,直至任务完成。在ReAct框架下,Agent会不断重复**思考(Thought)→ 行动(Action)→ 观察(Observation)**的循环,直至得出最终答案。
最后,与单纯的大型语言模型相比,Agent具有以下几个关键区别:
- 知识来源:模型的知只源于其静态的训练数据,而Agent可以通过工具实时访问外部世界信息,扩展其知识边界。
- 上下文管理:模型通常仅处理单次推理,缺乏会话记忆;而Agent能够维护完整的交互历史,实现连续的多轮对话。
- 推理框架:模型的输出往往依赖于单一的提示词;而Agent则内置了认知架构和复杂的推理策略(如思维链、反思框架、思维树等),使其能在编排层中进行循环迭代式的多步推理。
接下来,我们将对Agent的这四个核心组件进行详细展开说明。
编排层与认知架构
编排层是智能体系统的核心控制单元,负责组织信息流并驱动整个推理循环。它模拟了人类处理复杂任务时的认知过程:首先获取信息,然后制定计划,执行行动,再根据反馈调整计划,如此循环往复直至目标达成。一个常见的比喻是“厨师准备复杂菜品”:厨师会根据顾客需求获取食材信息,规划烹饪步骤,然后动手操作,并可能根据试味反馈不断调整方法。
类似的,Agent的编排层会按照预设的推理框架进行反复迭代,驱动模型生成“思考”并做出“行动”决策。常见的推理框架虽各有侧重,但底层逻辑相通。其中,必须了解的两个核心概念是ReAct(推理与行动)和CoT(思维链,Chain-of-Thought),在此基础之上还可延伸到ToT(思维树,Tree-of-Thoughts)。
ReAct如前文所述,强调模型在回答前进行连续的内省与行动选择,从而提升答案的准确性与推理过程的可追溯性。 CoT(思维链) 引导模型通过生成中间推理步骤来分解复杂问题,迫使模型在给出最终答案前先展示其思考过程,这一框架有助于提升模型处理复杂问题时的准确性(即缓解幻觉问题)。 ToT(思维树) 在CoT的基础上更进一步,允许模型在多个备选思路之间进行比较和探索,适用于需要多方案权衡的策略性任务,旨在进一步增强解决复杂问题的能力。
限于篇幅,我们重点讨论ReAct与CoT的配合使用(其他框架逻辑类似)。
ReAct 与 CoT 的协同
首先,ReAct与CoT都属于推理策略框架,是Agent四大组件中“编排层”的具体化实现。它们描述的都是如何组织模型的推理过程、生成逻辑步骤以及构建提示词的结构。
换句话说,ReAct是代码实现的核心,是AI工程的核心框架,它决定了系统如何与记忆模块、工具模块进行协同工作。
在逻辑上,ReAct与CoT是同级概念,但现在更多是组合使用,以至于CoT看起来像是ReAct过程中的一个产物。实际上并非如此,CoT本身也可以独立调用工具。但从当前流行的实践范式来看,ReAct更多地被用作主框架,而在此过程中会大量融入CoT的思维过程。因此,可以理解为:ReAct是容器,CoT是内容。ReAct最具“Agent”特性,而CoT则是最基础的推理增强手段。
ReAct规定了一个循环流程:先思考(Thought)→ 行动(Action)→ 等待结果(Observation)→ 再思考…
那么,这个“Thought”部分具体写什么?通常,它就是一个Chain-of-Thought推理块。
举个简单的例子:让Agent回答“某公司员工请假流程是什么?”的问题。 Agent需要:1. 理解用户问题;2. 从知识库检索相关文档;3. 分析内容结构;4. 输出清晰的步骤。 其简要流程可能如下:
用户:请问我们公司请假流程是什么?
步骤1:
思考(Thought):首先需要查找关于“请假流程”的文档。
行动(Action):搜索文档(“请假流程”)
观察(Observation):找到《员工手册》第4章,其中列出了请假流程步骤。
步骤2:
思考(Thought):
首先阅读这部分内容,理解流程的先后顺序。
- 第一步:员工提交请假申请。
- 第二步:直属上级审批。
- 第三步:人力资源部门备案。
因此,我可以组织一份清晰的回答。
行动(Action):无
最终答案:请假流程如下:1)提交申请;2)主管审批;3)HR备案。
在这个例子中,“步骤2”的思考(Thought)部分就是一个简单的CoT。模型在没有采取外部行动之前,通过分步思考来提取和组织信息,这正是典型的思维链。
之所以如此使用,原因很直接:在Agent架构中,并非每一步都需要调用外部工具。很多时候,模型只是在“组织思维或语言”,而CoT能有效降低在此过程中产生幻觉的概率。
总而言之,ReAct框架中经常穿插着多个CoT片段,这种组合也是当前最常见、最稳定的实践方式。大家只需记住这一点,便把握住了Agent编排层的精髓。
再结合Google报告中的案例,大家应该能完全理解了:
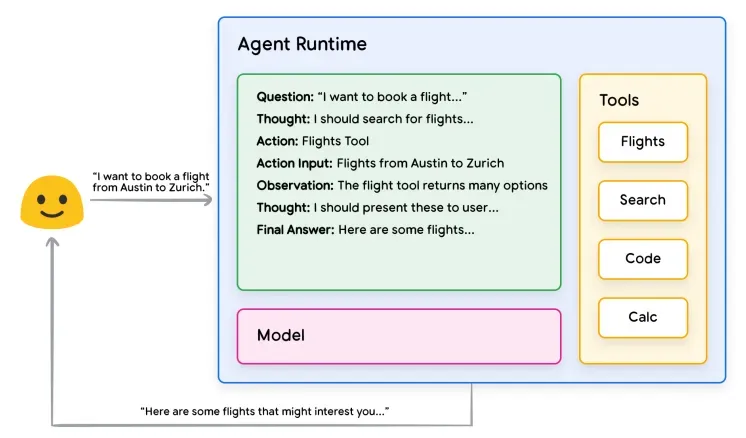
用户:我想订一张下周从北京到上海的机票。
思考(Thought):我需要查询航班信息并进行比较。
行动(Action):调用【航班搜索】工具
行动输入(Action Input):{"from": "北京", "to": "上海", "date": "下周"}
观察(Observation):航班工具返回了多班次航班信息。
思考(Thought):我应该挑选价格和时间合适的航班。
最终答案:根据查询结果,下周从北京到上海的航班有...(列出具体信息)。
状态管理
除了基本的推理框架外,编排层还负责维护交互状态与历史记忆。与模型的单轮对话不同,Agent需要管理完整的对话历史,将先前的对话内容、用户指令以及工具反馈都纳入当前状态。否则,在多轮对话中Agent就容易出现上下文错乱或“胡言乱语”的情况。
例如,在咨询类对话中,Agent需要记住用户之前提出的问题和相关上下文,并不断积累信息,这对于解决复杂问题和提供连续性的服务至关重要。
总之,编排层就如同Agent的“大脑”,通过循环的反馈机制和精心的提示工程框架,引导模型合理利用已有信息和工具,一步步实现目标。状态管理的好坏直接关系到Agent产品的最终表现。然而,需要指出的是,状态管理本身极其困难,若要深入展开,万字的篇幅也难以穷尽。
工具体系
工具是模型与外部世界之间不可或缺的桥梁,它们使Agent能够感知并处理真实世界的信息。
根据实践经验:Agent系统中最难的部分是状态管理,最不稳定(烦人)的部分是意图识别,而工作量最大的部分便是构建和管理工具体系。
常见的工具类型包括扩展(Extensions)、函数调用(Functions)和数据存储(Data Stores)等。它们各自承担不同的职责,共同构建了智能体与外部环境交互的能力。
扩展
所谓“扩展”,就是一套预先配置好的、可被调用的API模块,并附带模型能够理解的调用说明。其底层基础是模型的Function Calling能力。目的是让模型无需了解API的具体技术细节,只需给出核心参数即可调用。
行动(Action):search_flights
行动输入(Action Input):{from: "北京", to: "上海", date: "2025-12-10"}
下面是一个扩展的配置信息示例:
{
"name": "search_flights",
"description": "查询指定日期的航班信息",
"params": {
"from": "出发城市",
"to": "目的城市",
"date": "出发日期(YYYY-MM-DD)"
},
"example_calls": [
{
"user_input": "我想查明天从北京飞上海的航班",
"action": "search_flights",
"action_input": {
"from": "北京",
"to": "上海",
"date": "2025-12-10"
}
}
]
}
函数调用
函数调用与扩展类似(同样基于Function Calling),也是提供给模型用以调用外部功能的接口。但它更侧重于在客户端(或应用端)执行,而非在Agent服务器端直接执行。
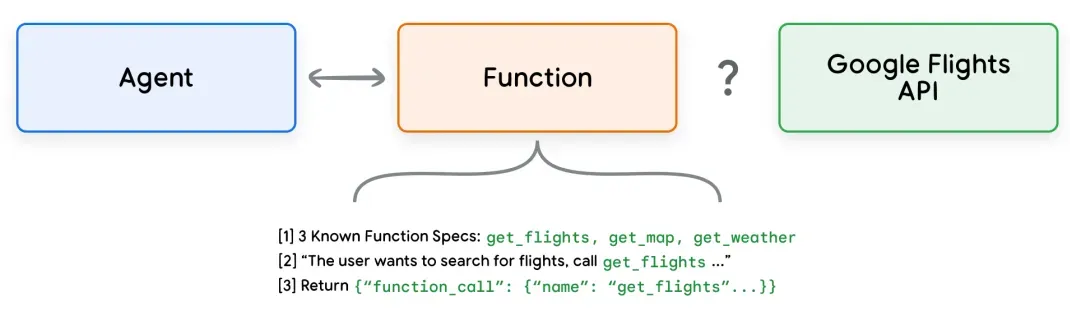
与扩展相比,核心差异在于:扩展是在Agent服务端执行并调用外部服务,而函数则由客户端(如前端应用、其他服务)来执行。这意味着即使模型选择调用了某个函数,实际的API调用或功能执行可能会在另一个服务层面完成。
为了让理解更清晰,我们举例说明:扩展是系统“自己动手”,例如用户说“帮我查天气”,Agent系统会自己调用天气API、自己获取数据并处理。而函数调用则是模型“发号施令”,它告诉客户端“你应该去做这件事”,例如模型返回指令playVideo({videoId: 123}),然后由前端应用来执行播放视频的函数。
这种差异主要是出于安全性、离线能力、异步执行等方面的考虑。通常,中断式、需要用户端交互的调用使用函数,而非中断式、后台静默完成的调用使用扩展。
# 扩展案例:
行动(Action): query_weather
行动输入(Action Input): {"city": "北京", "date": "2025-12-10"}
# Agent系统逻辑(自动执行):
def agent_runtime():
if action == "query_weather":
result = requests.get(f"https://api.weather.com?city={city}&date={date}")
send_back_to_model(result)
# 函数案例(中断式):
函数调用(Function Call): open_camera
参数(Args): {"resolution": "1080p"}
# 客户端/浏览器执行(由开发者实现):
def on_function_call(fn_name, args):
if fn_name == "open_camera":
open_webcam(args["resolution"])
数据存储
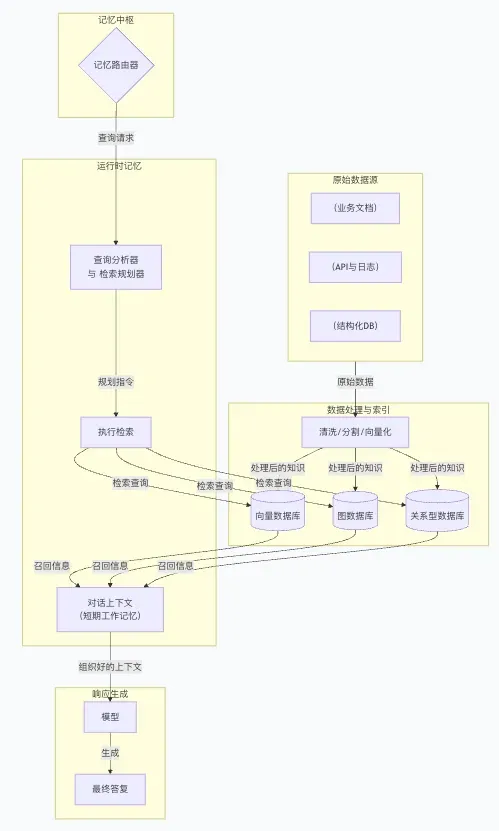
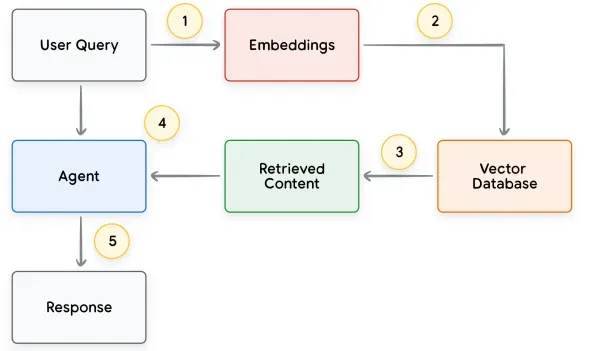
数据存储为Agent提供了“长期记忆”和知识库的功能,尤其适用于需要查询大量结构化或非结构化信息的场景。其核心思想是将外部文档或数据库内容转换为向量索引,让模型在运行时通过检索来动态获取最新知识,从而极大地扩展其知识边界。常见的做法是构建向量数据库或知识库,将文档、网页、表格等预处理为高维向量进行存储。

例如,在一个公司内部知识库问答系统中,Agent会先将用户问题转换为向量,然后从预先建立好索引的内部文档库中检索最相关的文档段落。这些检索到的内容作为补充信息提供给模型,从而使得生成的回答能够基于最新的业务手册或法规文本,而非仅仅依赖于模型训练时记忆的有限数据。
如图例所示,当用户查询“公司在北美的最新业务规模如何?”时,Agent会先检索相关的财经报告和市场数据,然后在ReAct循环中利用这些检索结果进行综合推理并生成回答:
客观而言,白皮书在这部分内容的质量上表现平平,更多是作为科普读物,介绍了一些基础概念。
记忆系统
在Agent系统中,记忆层不仅负责保存上下文以支撑多轮对话,它更深层的职责是回答一个根本性问题:数据应如何与AI交互,才能让大模型“真正理解”并有效完成任务?
这个问题的答案,近来常被包装成一个新术语:上下文工程(Context Engineering)。但从本质上看,它仍是对“如何构造有效Prompt”这一核心问题的深化和结构化设计,是提示词工程在复杂任务落地场景下的自然演进。
上下文工程
通常,我们将Agent的记忆系统划分为两个层次:
一、短期记忆 指当前会话的上下文历史,包括用户输入、模型回复以及中间的推理痕迹。这部分信息通常保存在编排层的对话状态中,用于构建Prompt的上下文。
二、长期记忆 指跨会话的知识存储,例如用户偏好、历史交互数据、组织内部资料、文档库等。这部分通常通过向量检索(如RAG)等技术动态取用,目的是在运行时“补全”模型的知识。
然而,在真实的应用场景中,记忆系统远比简单的“存储+检索”复杂。它的核心目标是:为大模型提供“恰到好处”的信息,既不过多、造成干扰,也不遗漏任何关键细节。
这引出了上下文工程在实践中的三大难点:
- 检索完整性:检索逻辑是否合理?是否会漏掉关键信息?
- 数据适切性:检索到的内容是否高度相关?是否存在信息过载(干扰模型)或信息严重缺失的问题?
- 应用有效性:最终组织进Prompt的方式,是否能有效激发模型输出正确、有用的结果?
从工程角度看,上下文就像是Prompt的“RAM”(随机存取存储器),容量有限但其质量直接决定了模型的“运行”表现。因此,设计合理的上下文组织策略,是构建有竞争力Agent系统的关键之一。
基于实践经验,可以将上下文工程的操作模式归纳为四类:
| 手法 | 核心思路 | 类比 | 常见场景 |
|---|---|---|---|
| 1. 记录式(Write) | 让AI随时把重要细节写入“随身笔记” | 人类做会议速记 | ChatGPT记忆用户常点外卖的餐厅、口味偏好等 |
| 2. 甄选式(Select) | 从海量资料中挑选出最相关的部分再喂给模型 | 图书管理员查找指定章节 | 代码生成Agent检索相关的函数文件、API文档 |
| 3. 精简式(Compress) | 当信息过多时,通过摘要、提炼、去冗余等手段减轻模型负担 | 给长论文写内容摘要 | Claude在对话即将满窗口时自动压缩历史对话 |
| 4. 分隔式(Isolate) | 将复杂任务拆解,分配给多个“助手”,各自维护不同的上下文 | 项目经理分派子任务 | Swarm(多智能体协作)架构中,多个子模型分工协作 |
这些方法的组合运用,构成了真正实用、可落地的上下文工程体系。不难看出,尽管“上下文工程”、“Agent记忆系统”听起来非常前沿,其本质仍然是复杂的、系统化的提示词工程。
最后,让我们回到Agent ReAct框架,重新审视四大组件的关系。
ReAct 框架中的记忆层角色
在ReAct框架中,每一次“思考(Thought)”的质量,严重依赖于思维链(CoT)的逻辑性,而CoT的有效性又严重依赖于记忆系统所提供的信息是否充足、准确且干扰最小。
在执行过程中,记忆系统负责为每一次“思考”构建上下文输入,即Prompt中的“记忆(Memory)”区块。一个典型的ReAct调用链如下:
用户:我需要找一张明天下午从北京去上海的高铁票
-----------------
思考(Thought):我需要查询高铁票信息。
行动(Action):查询高铁API(输入城市和时间)。
观察(Observation):API返回了多个班次和时间段。
思考(Thought):我应该挑选一个下午出发、价格合适的车次。
行动(Action):无。
最终答案:为您找到两张明天下午从北京到上海的高铁票...(输出具体结果)。
在这个过程中:
- 如果用户此前表达过“只要一等座”、“不坐动车”等偏好,长期记忆系统需要提供这些信息。
- 如果用户此前提过“和昨天流程一样”,短期记忆系统需要准确提取并引用那次会话的内容。
- 如果调用查询工具返回了海量内容,记忆系统需要判断并提取哪些“观察(Observation)”应被纳入下一步的Prompt。
由此可见,ReAct是推动整个推理循环向前演进的基础框架。同时,这也说明了为什么上下文工程是整个Agent架构中最容易被忽视、但也最容易出问题的部分——一旦设计不佳,模型生成的“思考”就会陷入空转、偏离主题,甚至产生幻觉。
总而言之,记忆系统与上下文工程是Agent落地实践中的核心难点,需要深入理解和精心设计。
强化与训练
大模型的发展在过去三年大致经历了三个阶段:百模大战的模型训练时代 → 以“套壳”应用为荣的提示词工程时代 → 强调推理的CoT时代。目前,业内普遍对从头开始训练大型模型持审慎态度,因为这往往意味着巨大的技术投入和预算压力。
尽管如此,虽然基础模型已具备强大的通用能力,但要让模型在特定的Agent架构中发挥最佳效果,通常仍需针对性地学习如何使用新工具、处理新知识。白皮书总结了三种主要方法:
一、上下文内学习 在推理时直接为模型提供与任务相关的提示、工具说明和少量示例,让模型“在线”学习如何使用工具。例如,通过几个示例对话来展示在类似场景下应使用哪种工具、如何调用,这可以显著提升模型工具调用的准确率。ReAct框架本身就是一种典型的、由上下文示例驱动的提示框架。
二、检索式上下文学习 这是一种更动态的方法。系统会自动从外部记忆库(如“示例库”或知识库)中检索和选择与当前任务最相关的知识片段、示例或工具说明,并将其作为提示词的一部分动态地喂给模型。这就像为模型提供了一本“活的菜谱”,能根据具体查询即时找到最合适的指导方案。
三、微调训练 最后是经典的微调方法。使用大量特定任务的示例数据对预训练模型进行进一步训练,可以使其更适应目标场景。例如,为一个客服智能体微调模型,可以教会它优先调用知识库工具来查找答案,而不是依赖于可能不准确的“自由发挥”。
以下是一些训练数据格式的案例:
// 案例1:知识问答格式
{
"context": "【内部文档摘录】本公司标准退货政策为:自收货之日起7日内可无理由退货,超过7日不予受理。",
"question": "你们退货政策是怎样的?",
"answer": "根据我们的标准退货政策,自收货之日起7日内您可以无理由退货,超过7日则无法办理退货。"
}
// 案例2:任务规划格式
{
"goal": "帮用户规划一个3天的东京自由行,预算适中,喜欢美食和动漫文化。",
"tools": ["search_flights", "search_hotels", "search_attractions"],
"plan": {
"steps": [
{
"step_id": 1,
"description": "确定出发和返回日期,并查询往返机票选项",
"tool": "search_flights",
"inputs": ["出发城市", "东京", "出发日期", "返回日期"]
},
{
"step_id": 2,
"description": "根据预算和地理位置搜索酒店(优先新宿、涩谷附近)",
"tool": "search_hotels",
"inputs": ["东京", "3晚", "预算范围"]
},
{
"step_id": 3,
"description": "根据用户兴趣筛选景点(动漫文化、美食街)并按天分配",
"tool": "search_attractions",
"inputs": ["东京", "动漫", "美食"]
}
]
}
}
// 案例3:对话格式(用于微调指令遵循和输出格式化)
{
"messages": [
{
"role": "system",
"content": "你是一个任务规划助手,收到用户目标后只输出JSON格式的任务拆解计划。"
},
{
"role": "user",
"content": "帮我规划一个3天的东京自由行,预算适中,我喜欢美食和动漫。"
},
{
"role": "assistant",
"content": "{\"steps\": [{\"step_id\": 1, \"description\": \"确认出发/返回日期并查询机票\", \"tool\": \"search_flights\"}, {\"step_id\": 2, \"description\": \"根据预算和位置选择酒店\", \"tool\": \"search_hotels\"}, {\"step_id\": 3, \"description\": \"为3天分别安排景点和美食\", \"tool\": \"search_attractions\"}]}"
}
]
}
在生产环境中,上述三种方法往往会结合使用,以达到最佳效果。
结语
白皮书的后续部分还涉及了多Agent协作架构、高并发系统设计、安全性等议题,但这些内容相对泛泛而谈。鉴于本文定位为入门级指南,我们便不在此展开。
总结来说,这份Google的Agent白皮书全面地梳理了AI Agent技术架构的核心要素。虽然其中包含了一些实践技巧,但也有为自身云服务“背书”的嫌疑,我们已对此进行了客观过滤。
无论如何,希望本文能对大家有所帮助。作为一份入门级的科普与解读内容,我认为其价值是合格的。当然,撰写这份解读也同样耗费了不少时间与精力。