GPT-image-2引发信任海啸:互联网步入黑暗森林时代
昨日,GPT-image-2 横空出世。
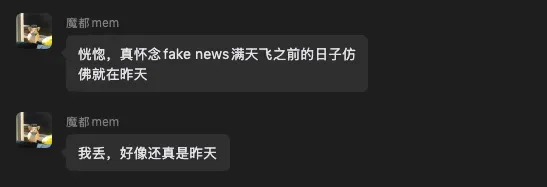
顷刻间,各大社群与社交媒体陷入一片狂欢。其生成的梗图迅速爆红,一度登顶微博热搜榜第一。
这就是那一张图片。为避免大家误解,我特意打上了硕大的水印。
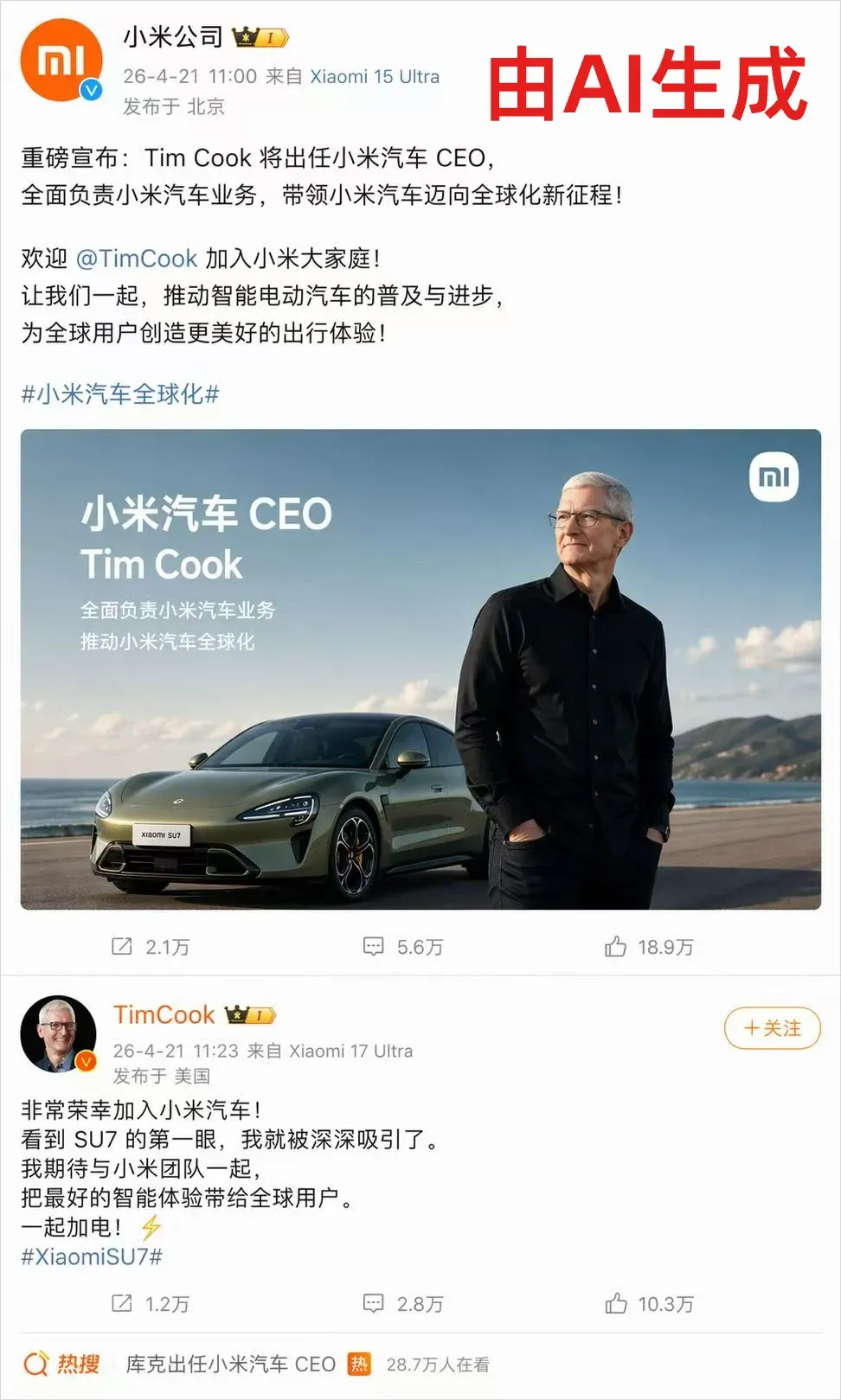
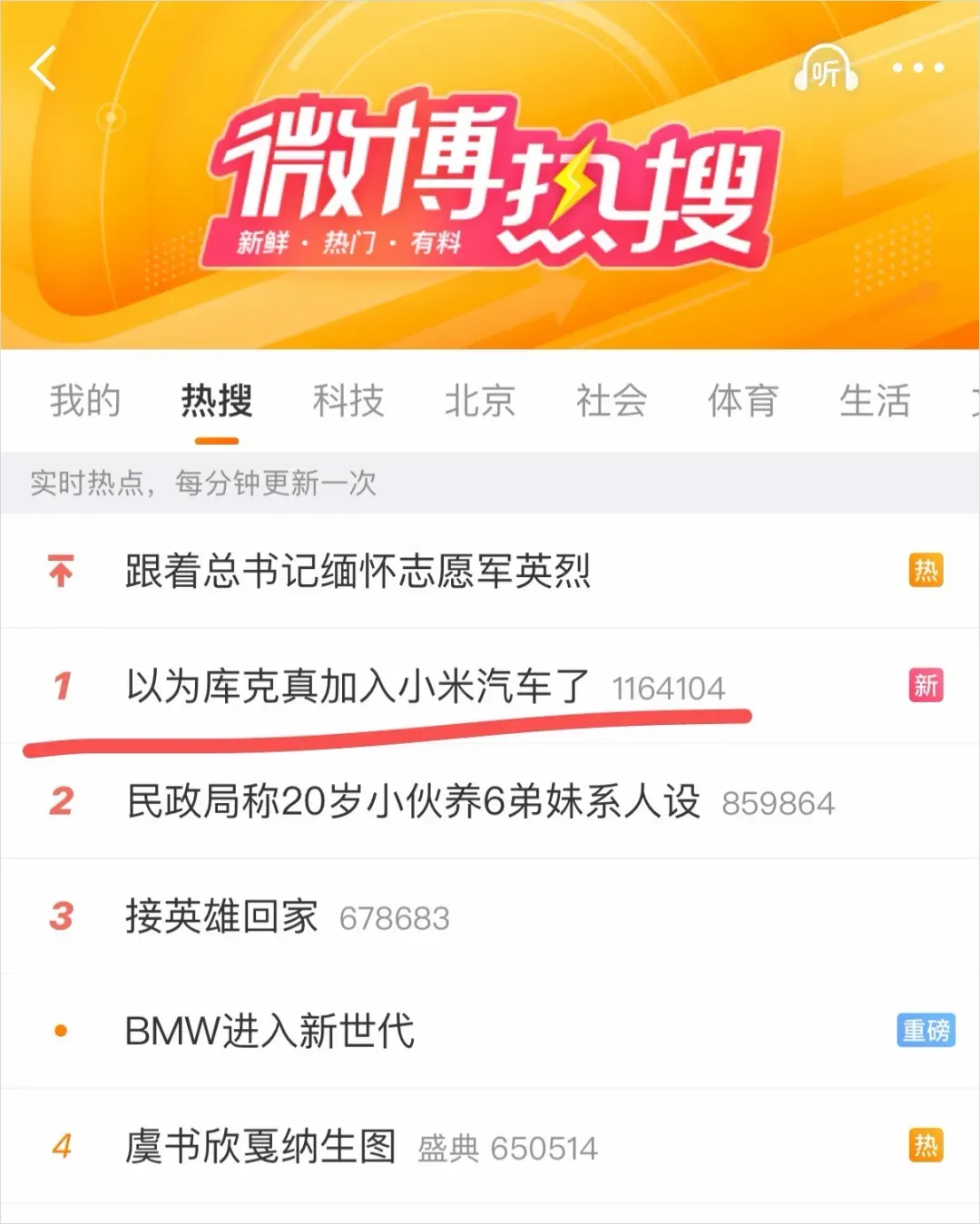
而除了这一张,我还看到了难以计数的、因内容过于离奇或我们太过熟悉而极易识破的 GPT-image-2 合成图片。
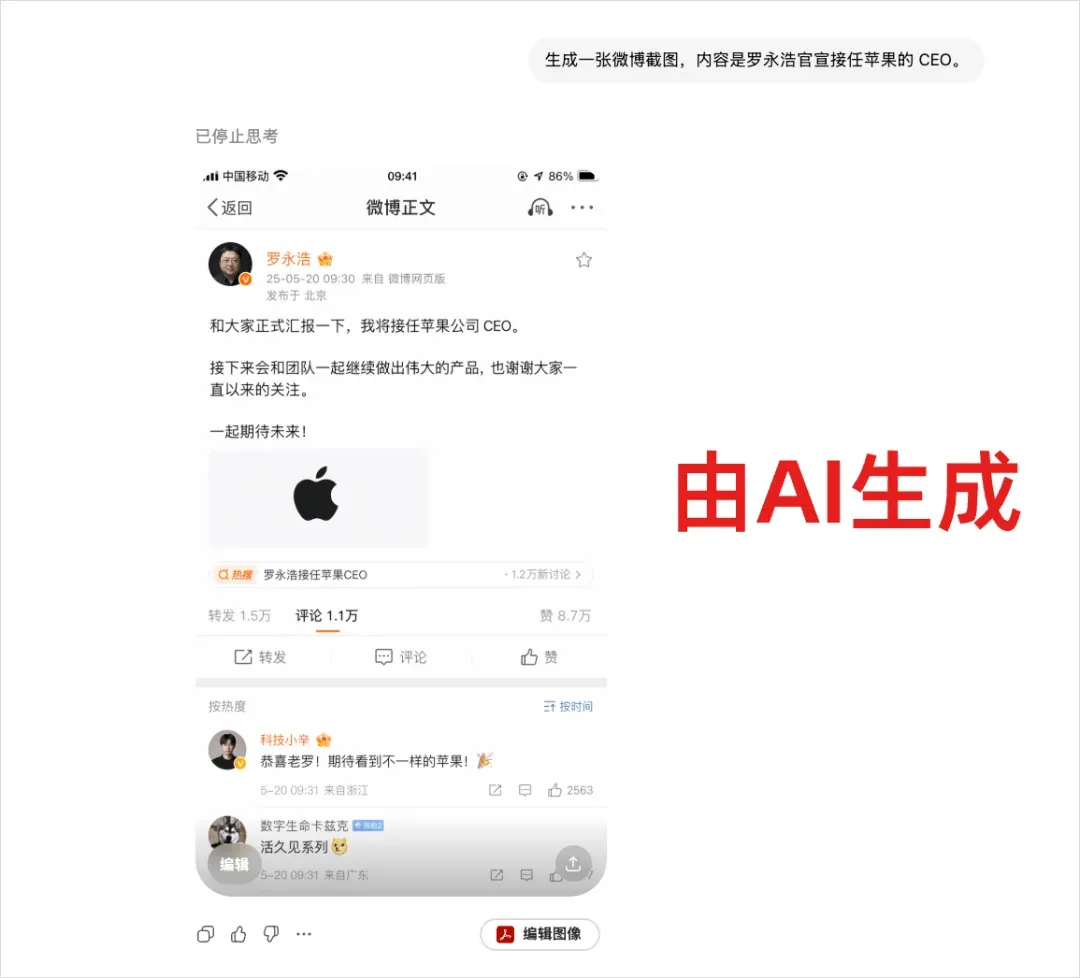

甚至还有这种逼真程度的照片。

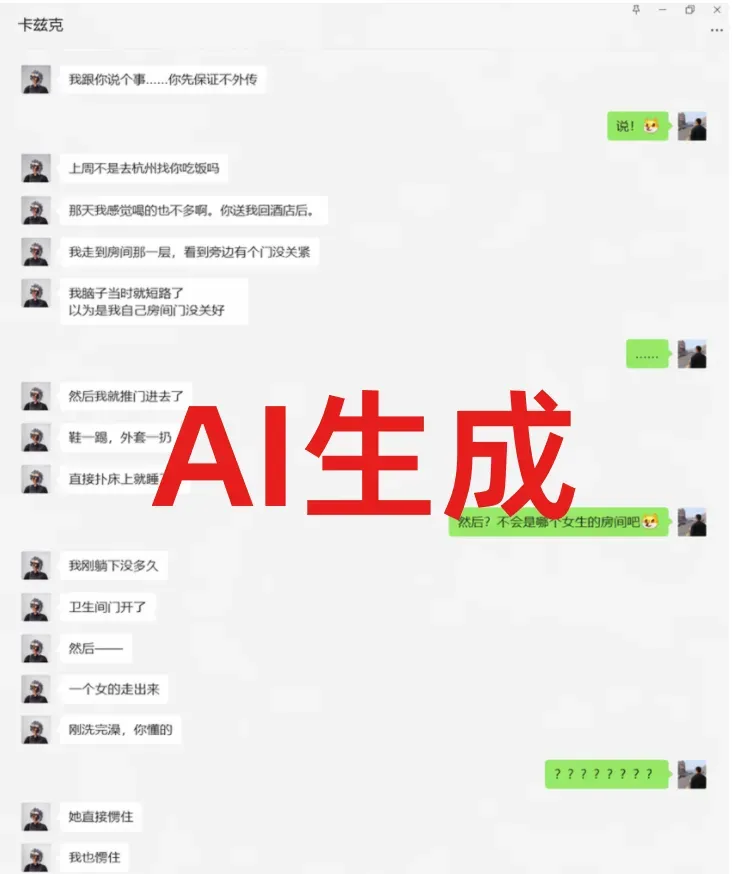
更有甚者,朋友“鲜虾包”还炮制了可以乱真的微信对话截图。
大家虽然玩得酣畅淋漓,但这一日下来的感受,却让我猛然发觉:世界已经变成了一座幽暗的“黑暗森林”。
昨天清晨便发生了一个标志性事件。大约中午十二点,极有可能是 OpenAI 在部署 Codex 模型时出现了故障,致使 GPT-5.5 意外流出。
若搁在往常,凭我们群友的脾性,必然火速打开 Codex 尝鲜,再回到群里通报:“真上线了!”。但昨天中午,我目睹的反常景象令人错愕。
而由于确实是系统故障,这个泄露很快就被 OpenAI 回收。稍迟一步的群友再去看时,发现 GPT-5.5 已不见踪影,只剩 5.4。群里的气氛便成了这样。
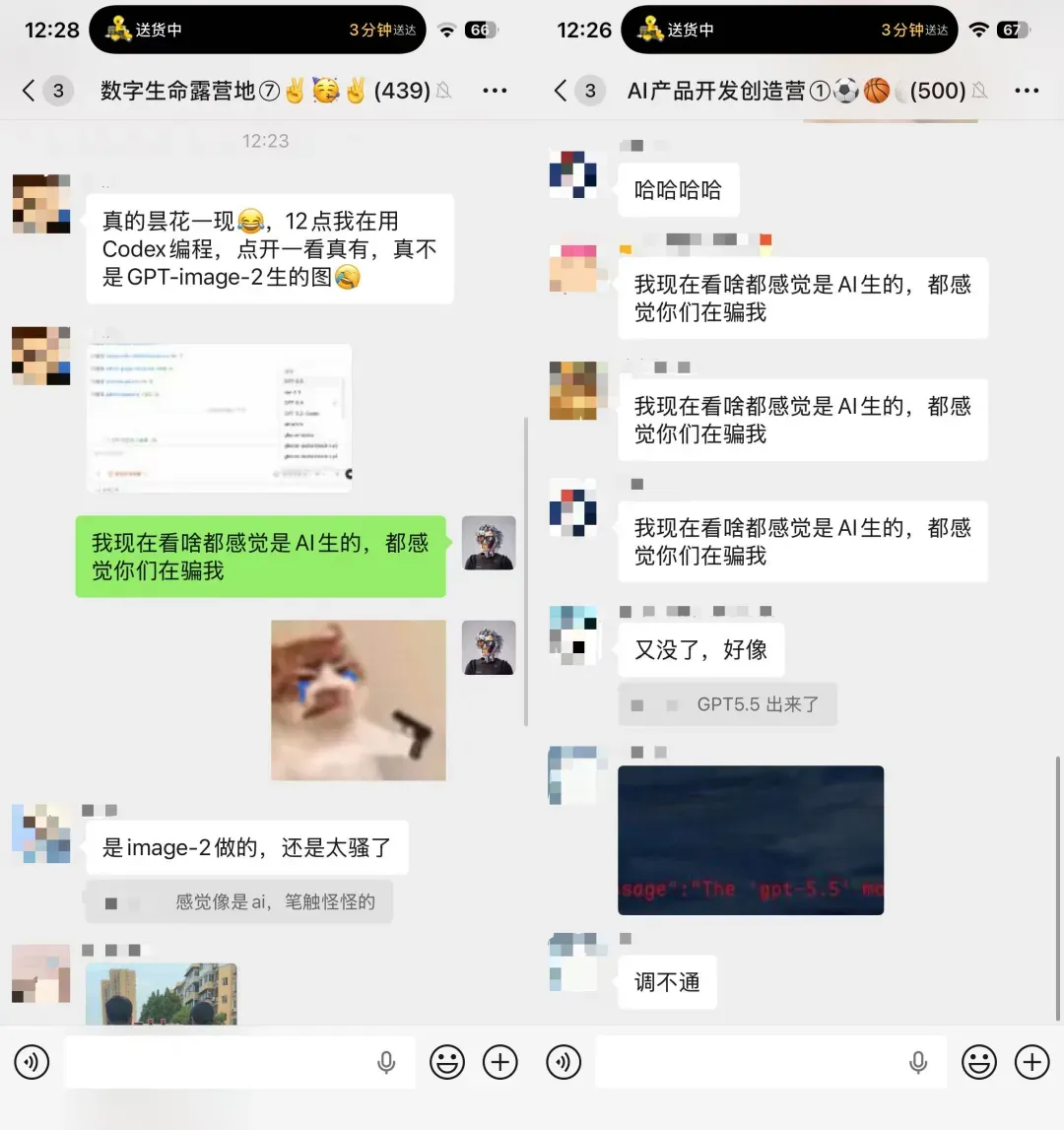
最魔幻的是,我把这段截图转发到朋友圈,感慨了一句。结果评论区竟然是这样的——纷纷说那两张群聊截图本身就是 AI 编造的。
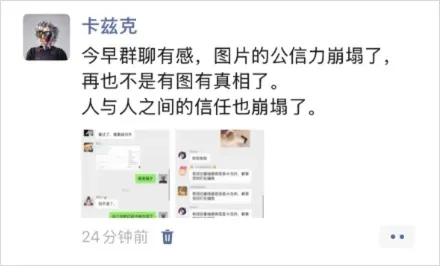
我把朋友圈截图发回群里,想展示这诡异的评论景象。不料他们说,我发到群里的这张朋友圈截图,同样出自 AI 之手。
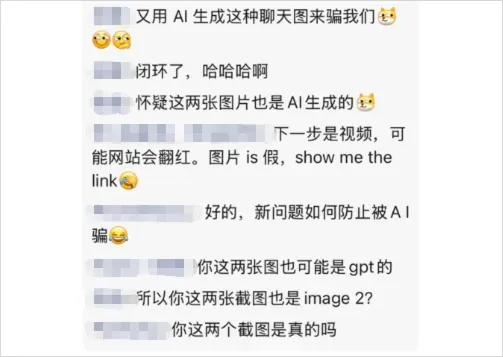
猜疑链就此闭合。世界,终究蜕化成一座硕大的黑暗森林。还有这张图,猜疑链进一步延伸,昨日引发海量讨论,因为谁也分不清它究竟是真还是假。
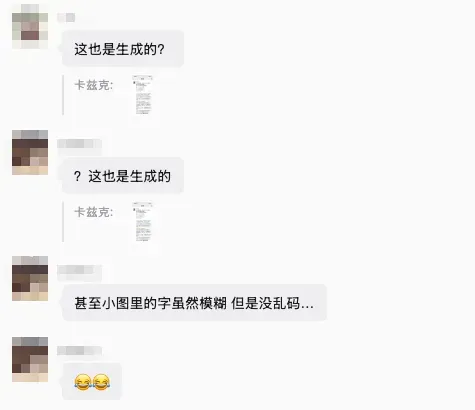
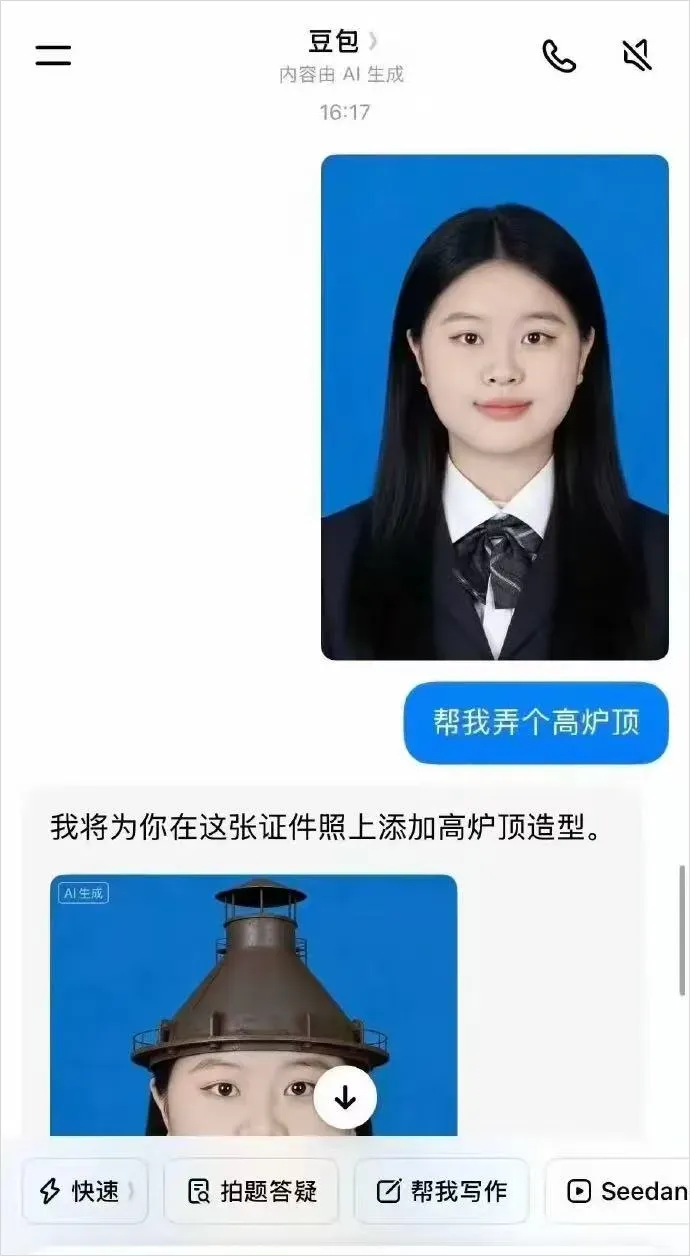
纵使我至今把原图交给豆包实测,依然无法百分之百断定其真伪。
我知道大伙是在玩梗,图个乐,本意都是善意。但当你看到这些画面,会不会也和我一样,后背渗出冷汗?

还有一些更敏感的,比如转账凭证、银行流水、护照信息等,我就不放出来了。放了,恐怕连这篇文章都发不出去。
我隐约感到,随着这个模型的发布,有种我们赖以生存的东西悄然消亡——那就是信任。更准确地说,是“相信自己所见为真”这一预设本身。
在 GPT-image-2 出现之前,我们每天在互联网汲取信息时,都默认一个底层假设:截图是真的,照片是真的,聊天记录是真的。“有图有真相”这句话流传得太久太久。我们无需对它们的真实性耗费半点心神。
看见一张微博截图,我们讨论内容;瞧见一张聊天记录,我们关心事件;瞥见一张新闻图片,我们思考的是新闻。这种默认的信任,正是整个互联网信息生态运转的基石。
很多时候,我们根本意识不到它的存在,就像鱼大多时候也察觉不到水,我们也鲜少感知空气。唯有当它开始湮灭的瞬间,才觉得窒息。
我并非声称我们从此会立刻开始质疑每一张图,但怀疑的种子已然埋下。从今往后,每当你看到一张图,但凡与直觉稍稍相悖,或者触动了哪个心理伤口,脑海里便会冒出一个声音:这是不是AI生成的?这个声音或许很轻,或许一闪而过,但它会像种子般扎根,随着AI的发展愈长愈大,绝不会缩小。
这就是黑暗森林——刘慈欣在《三体》中描绘的黑暗森林法则:宇宙是一座黑暗森林,每个文明都是带枪的猎人。

黑暗森林的核心,正是猜疑链假设。你无法判断对方究竟怀有善意还是恶意,为了保护自己,只能先行预设对方是恶意的。今日的互联网亦如此,我无法辨别信息源背后的人是善是恶,能做的,唯有默认不信。因为造假变得太过容易。
当造假成本趋近于零,信任的成本便趋近于无穷——这是一道极简单的数学题。
2023年初,ChatGPT 爆火之时,我决定写下第一篇文字、开始打造个人IP,前后思忖了许多。那时我非常焦虑,因为在AI时代,我不知什么才是无法被替代的。思索良久,最终答案只有一个词:信任。
今年年初,我曾对外分享过当时的思考。

那时我归纳了三个自己视作公理的判断,虽然看着非常地摊、近似胡言,却实打实指引了我后来的所有动作:
- 在AI加持之下,信息生产效率呈指数级爆发,而人类消费的效率始终恒定或线性增长,两者之间形成永久性、持续扩大的结构性失衡。
- 无论信息总量如何爆炸,一个社会在某一时段的总注意力仍是恒定的稀缺资源,某个领域注意力的增加必然导致另一领域注意力的减少。
- 分辨内容究竟由AI还是人类创作的成本,将系统性地高于这段内容本身所带来的价值。因此,绝大多数人将理性地放弃辨别。
第三条,在2023年与许多朋友交流时,不少人很是不屑。“AI生成的东西那么假,我怎么可能看不出来?”
然而昨天,这一天,在图片领域,它终于降临了。而且来得比我想象的更迅猛、更彻底。辨别的成本实在太高,你花五分钟去验证一张截图是真是假,也许它就是真的,你的五分钟白费了;也许它是假的,那又怎样?你每天要浏览数百张图,不可能张张花五分钟去验证。于是,最理性的策略便是默认任何信息都可能为假,或者,默认真假已无所谓。
所以,当年我由这三条公理推导出的结论是:传统的信息筛选因失衡而难以为继,因不可辨识而失去意义,终将走向失效。在有限的注意力面前,我们或许只剩一条路——放弃筛选信息,转而筛选信息的源头。信任不再附着于信息本身,信任附着在人身上。
这正是我选择做个人IP的初衷。不光因为它能赚钱、能出名,更因为,在一个真假莫辨的世界里,一个你长期关注、长期验证、长期建立了信赖关系的真实的人,才是你在信息洪流中可以牢牢抓住的锚。
从运营这个公众号的第一天起,我就给自己定了一条底线:真诚是唯一的捷径。这绝非什么鸡汤,而是我在这座黑暗森林里的生存策略,也是对抗这个操蛋的AI时代,唯一的解法。
但说实话,今天,此时此刻,我毫无半点三年前就说对了的得意,也完全不想炫耀什么。一点都没有。我只是感到一种深深的惶恐。我不知道互联网的黑暗森林最终会演化成何等模样,也不知道信任的重建需要多少时日、需要何种技术、需要怎样的共识。
就像时下最主流的识别方案是添加AI水印,可见水印和数字水印并举,比如 C2PA。

然而,去除它们实在轻而易举。以 C2PA 为例,它只能证明带有此标签的图片是 AI 生成,却无法反证没有此标签的图片就是真的。所以,面对一张无 C2PA 标签的图片,你仍然无法判断它是真实照片,还是被人抹去了标识。
Google 有一项名为 SynthID 的技术,思路略有不同,它直接在图像像素层面嵌入不可见水印,理论上更难以去除。这确实是我目前见过效果最好的 AI 检测方式,但仅限 Google 自家生态,并不兼容其他平台。而且在 reddit 一类论坛上,攻破它的方式依旧层出不穷。坦率地讲,当下没有任何技术手段,能可靠地判断一张图片是否由 AI 生成。这就是现实。
就如同昨天群友在群里发的一段话:
技术靠不住的时候,我们普通人能做些什么?我琢磨了许久,可以给出的建议实在不多,但每一条都实用:
- 截图不等于证据——这个观念,必须从今天起刻进脑海。
- 传播任何图片之前,先暂停三秒。
- 关注信息的源头,而非信息本身。
最后,如果非说一句话不可,我只能说:在这片黑暗森林里,努力做一个值得被信任的人。这或许是我们唯一能做的事,或许,也是最重要的事。