揭秘GPT Image 2:如何成为科研绘图新标杆?实测对比与Nano Banana的差异
今天下午,我将前几天撰写的科研绘图专用提示词(Nano Banana 科研技术配图提示词,拿走即用)在ChatGPT中进行了实测。
生成的图像效果之好,让我几乎难以置信。OpenAI难道在不声不响中就发布了一个重磅更新?
我此前并未预料到GPT Image 2在语义理解和指令遵循方面的能力如此强大。提示词中的每一条具体要求几乎都被完美实现,甚至对中文的渲染也异常精准,其表现可谓全面超越了Nano Banana 2。
后者的风格偏向于视觉元素的堆砌,生成信息图时常常将所有内容一并呈现,那些夸张的渐变与色彩效果难以抑制。
我曾经一度认为问题出在提示词不够精确。然而,当我将完全相同的指令,一字未改地输入给GPT Image 2时,所生成的图像在质感上瞬间提升了好几个层次,与Nano Banana的产出完全不在一个维度上。
通过下方这几个案例的对比,你可以试着判断它们各自出自谁手。
Banana,还是GPT?
案例一:InstructGPT技术路线示意图
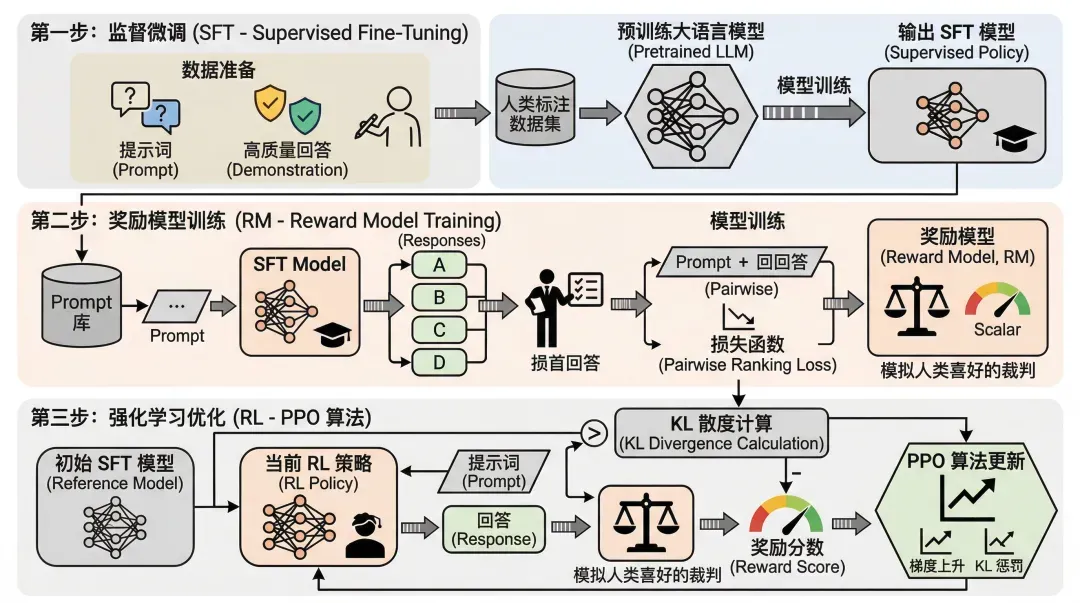
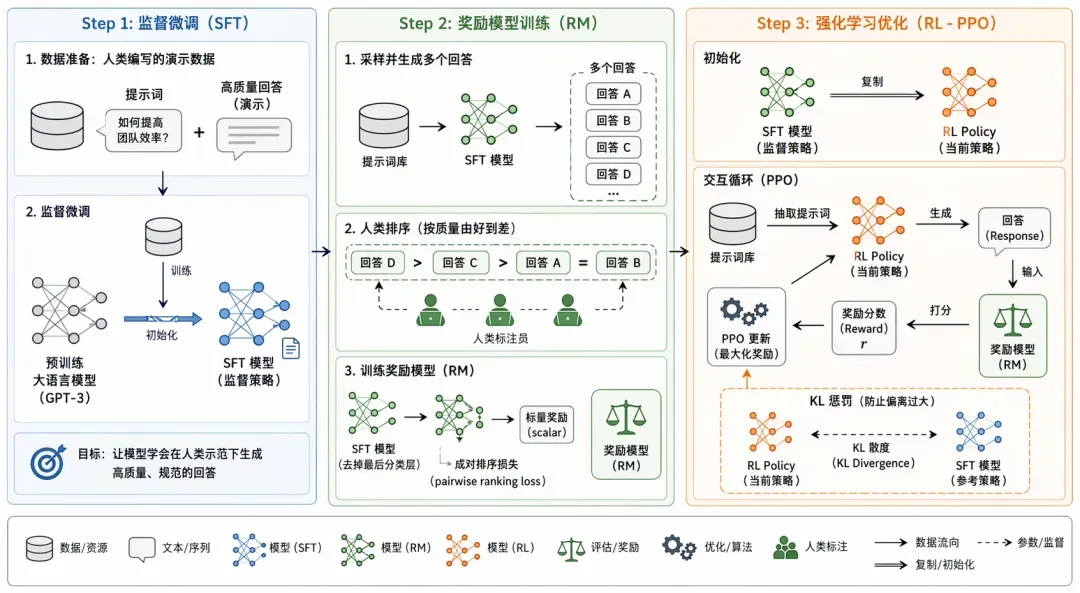
--通用绘图风格指令省略--
## 需要绘制的内容
📄 论文: Training language models to follow instructions with human feedback (InstructGPT)
🎯 核心思想: 通过“人类反馈强化学习(RLHF)”技术,将预训练语言模型(如 GPT-3)的行为与人类的意图和价值观对齐。
🛠️ 技术路线与绘图拆解:
1. 整体架构布局(绘图建议:分为三个并列或递进的清晰阶段(Step 1, Step 2, Step 3))
2. Step 1: 监督微调 (SFT - Supervised Fine-Tuning)数据准备: 收集人类编写的“提示词 (Prompt)” + “高质量回答 (Demonstration)”。模型训练: 取一个预训练大语言模型 (Pretrained LLM) $\xrightarrow{输入}$ 人类标注数据集 $\xrightarrow{训练}$ 输出 SFT 模型 (Supervised Policy)。这一步确立了模型“应该如何规范回答”的基础。
3. Step 2: 奖励模型训练 (RM - Reward Model Training)数据采样: 从 Prompt 库中抽取提示词,使用 Step 1 的 SFT 模型生成多个不同的回答 (Outputs: A, B, C...)。人类排序: 人类标注员对这些回答按质量进行排序 (比如 $D > C > A = B$)。模型训练:以 SFT 模型去掉最后的分类层作为基础,改为输出一个标量值 (Scalar Reward)。输入“Prompt + 回答”,使用成对排序损失 (Pairwise Ranking Loss) 优化网络。产出: 奖励模型 (Reward Model, RM)(相当于一个模拟人类喜好的裁判)。
4. Step 3: 强化学习优化 (RL - PPO 算法)初始化: 复制一份 SFT 模型作为当前的 强化学习策略 (RL Policy)。交互循环(画一个闭环):从库中抽取新 Prompt $\xrightarrow{输入}$ RL Policy $\xrightarrow{生成}$ 回答 (Response)。Prompt + 回答 $\xrightarrow{输入}$ Reward Model (裁判) $\xrightarrow{打分}$ 得到标量奖励分数 (Reward Score)。利用打分,使用 PPO (Proximal Policy Optimization) 算法更新 RL Policy 的参数,最大化奖励。惩罚机制 (KL Penalty): 在 PPO 优化的同时,计算当前 RL Policy 与初始 SFT 模型的 KL 散度 (KL Divergence),作为惩罚项加入,防止模型为了刷高分而“面目全非”(过度拟合奖励模型)。
案例二:Text-to-SQL技术路线示意图
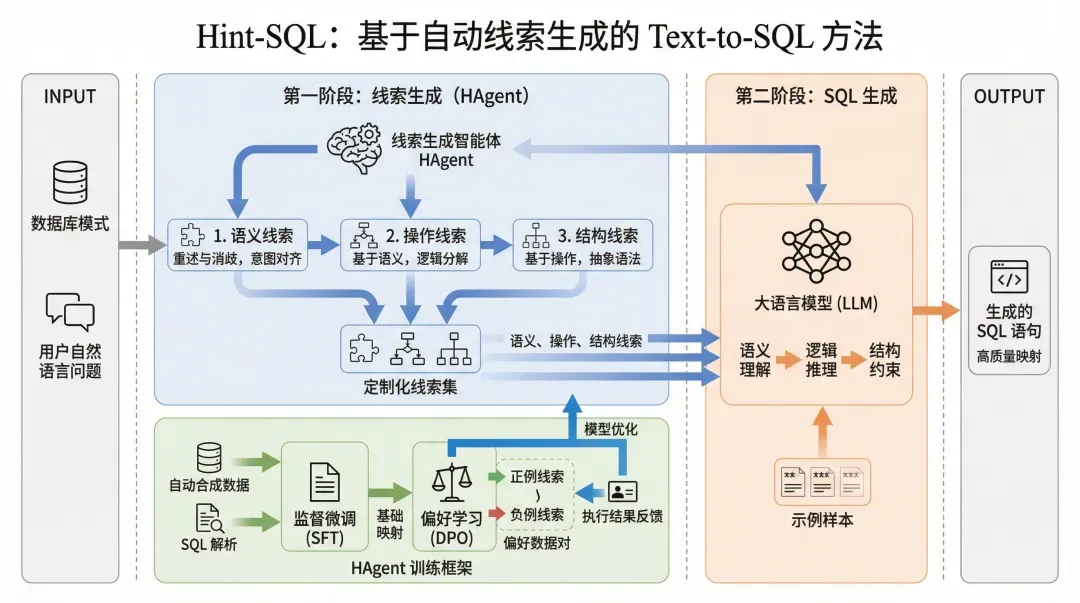
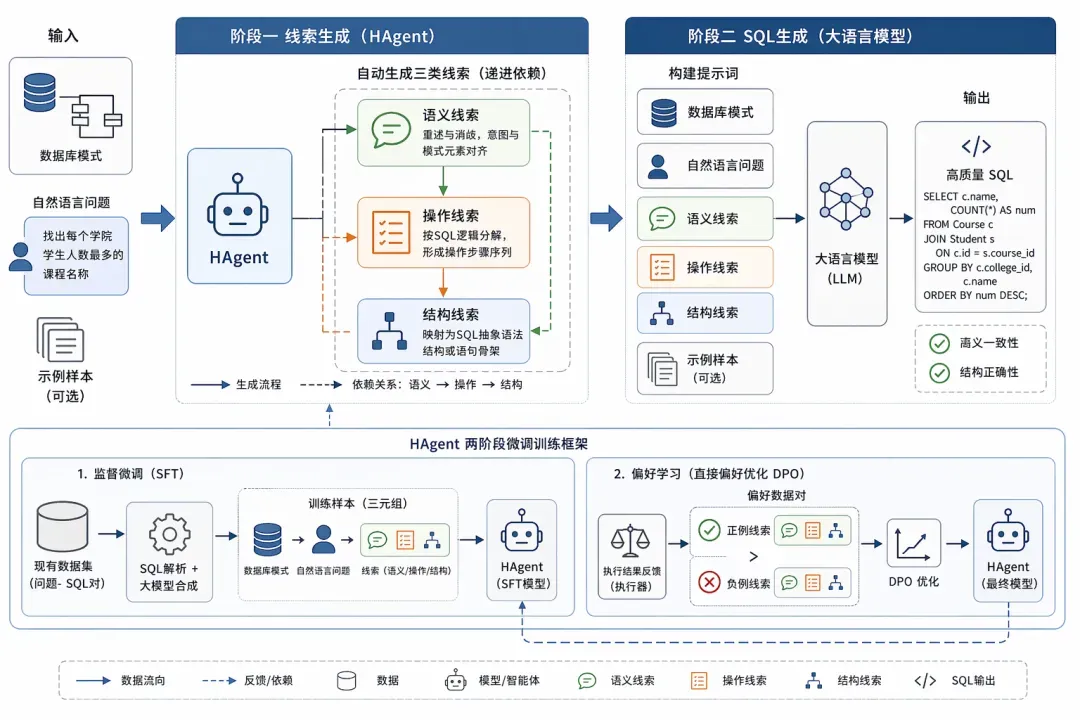
--通用绘图风格指令省略--
## 需要绘制的内容(从中提取关键信息)
本文围绕 Text-to-SQL 任务中“语义理解不充分、推理过程不清晰、SQL结构易出错”等关键问题,提出一种基于自动线索生成的提示方法 Hint-SQL,构建“线索生成—SQL生成”两阶段协同的技术路线体系。该方法以线索生成智能体 HAgent 为核心,通过动态生成多层次线索,引导大语言模型完成从自然语言到 SQL 的高质量映射。
在整体流程上,首先以数据库模式信息与用户自然语言问题作为输入,在第一阶段中由 HAgent 采用递进式策略自动生成三类定制化线索,包括语义线索、操作线索与结构线索。其中,语义线索通过对用户问题进行重述与消歧,实现查询意图与数据库模式元素的精确对齐;操作线索在语义理解基础上,按照 SQL 逻辑对查询过程进行分解,形成清晰的操作步骤序列;结构线索则进一步将操作步骤映射为 SQL 抽象语法结构或语句骨架,实现从逻辑到结构的过渡。三类线索在生成过程中具有严格的递进依赖关系,即语义线索作为操作线索的前提,语义与操作线索共同作为结构线索的生成依据,从而在降低单步生成复杂度的同时保证整体逻辑一致性。
为实现高质量线索的自动生成,本文设计了 HAgent 的两阶段微调训练框架。首先,在监督微调阶段,通过解析已有数据集中的 SQL 语句并结合大语言模型能力自动合成训练数据,构建包含“数据库模式—用户问题—线索”三元组的样本集合,使模型学习从问题到线索的基础映射关系;随后,在偏好学习阶段,引入基于执行结果反馈的线索质量评估机制,通过构建“正例线索—负例线索”的偏好数据对,采用直接偏好优化方法进一步提升模型对细粒度语义与逻辑差异的判别能力,从而显著提高线索生成的准确性与可靠性。该训练机制实现了无需人工标注的数据驱动优化过程,增强了方法的可扩展性。
在第二阶段的 SQL 生成过程中,将生成的语义线索、操作线索与结构线索嵌入到大语言模型的提示词中,与数据库模式、用户问题以及示例样本共同构成完整输入。多类型线索从“语义理解—逻辑推理—结构约束”三个层面对模型生成过程进行协同引导,使模型能够在理解查询意图的基础上,按照规范的推理路径逐步构建 SQL 语句,从而有效提升生成结果在语义一致性与结构正确性方面的表现。
案例三:3D-GloBFP技术路线示意图
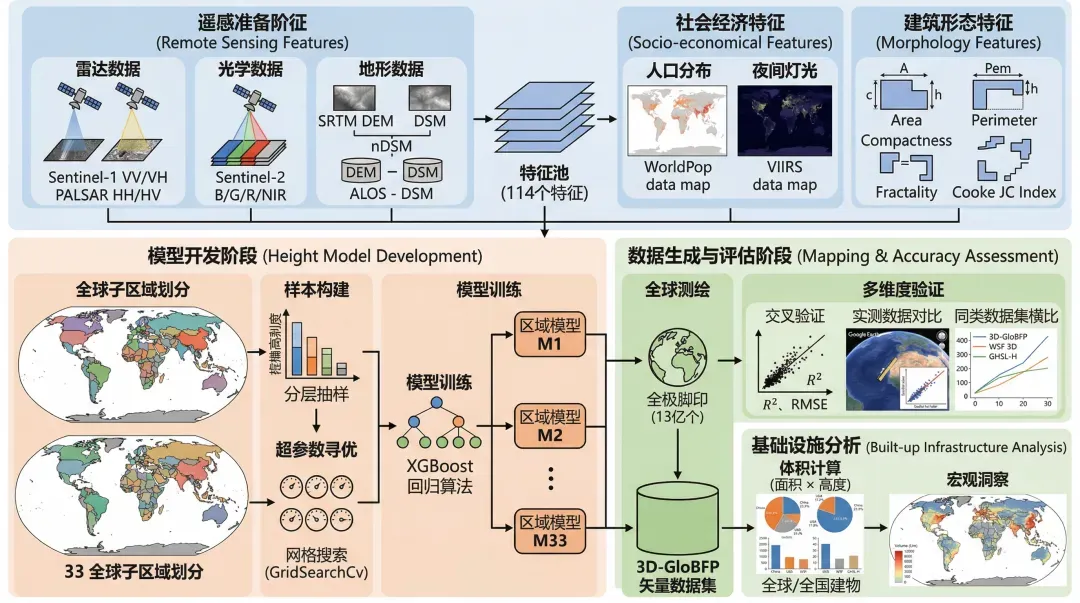
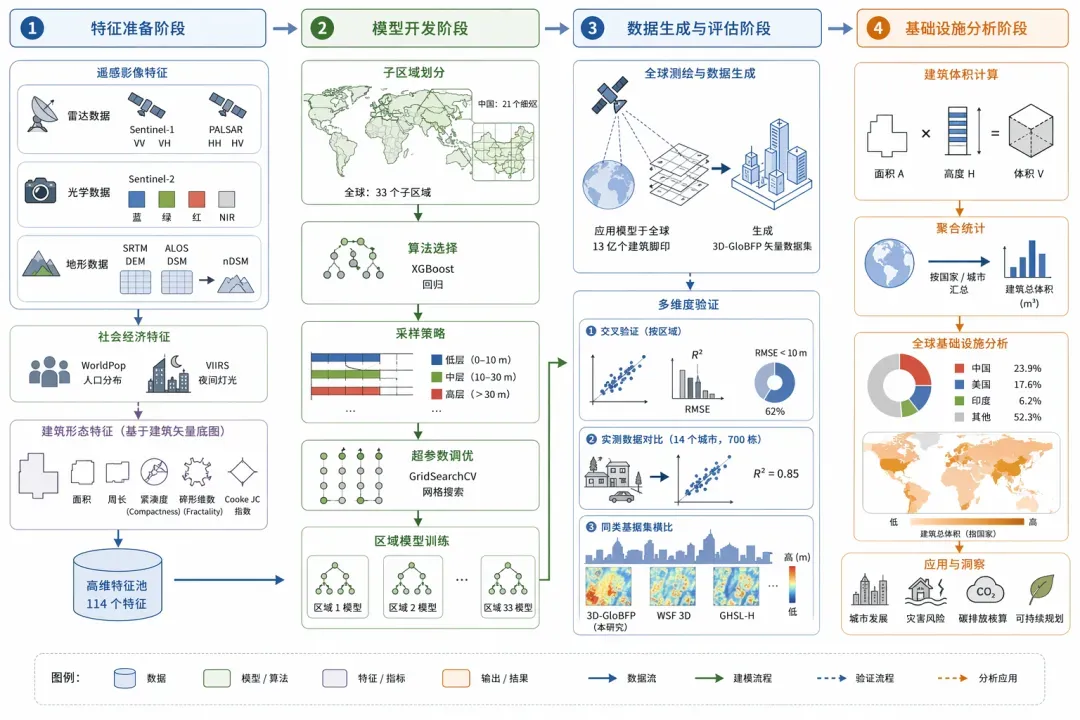
--通用绘图风格指令省略--
## 需要绘制的内容(从中提取关键信息)
1. 特征准备阶段 (Feature Preparation)
研究者并没有依赖单一的数据源,而是构建了一个高维度的特征池(共 114 个特征),主要包括:
遥感影像特征 (Remote Sensing Features):
雷达数据:利用 Sentinel-1 的 VV 和 VH 双极化回波强度,这些信号对建筑物的表面粗糙度和结构高度非常敏感 。同时辅以 PALSAR (HH, HV) 数据 。
光学数据:利用 Sentinel-2 的蓝、绿、红及近红外波段 。近红外波段能通过反射地表材料的热辐射能力来间接提供高度信息 。
地形数据:利用 SRTM DEM 和 ALOS DSM,计算两者的差值 (nDSM),这能直接反映地表物体的垂直高度 。
社会经济特征 (Socio-economical Features):集成 WorldPop 人口分布和 VIIRS 夜间灯光数据作为辅助信息,反映人类活动的强度与建筑密度的关联 。
建筑形态特征 (Morphology Features):基于建筑矢量底图,计算了面积、周长、紧凑度 (Compactness)、碎形维数 (Fractality) 和 Cooke JC 指数等指标 。这些几何指标对于区分不同功能的建筑(如商业区高楼与居住区低层建筑)至关重要 。
2. 模型开发阶段 (Height Model Development)
为了处理全球范围内巨大的建筑异质性,研究者采取了“分而治之”的策略:
子区域划分 (Subregion Division):全球被划分为 33 个子区域(包括中国的 21 个细分区),目的是确保每个区域的模型都能学习到当地独特的建筑风格和发展模式 。
算法选择:选用 XGBoost (极限梯度提升) 回归方法 。该算法在处理复杂非线性关系和大尺度数据集方面表现卓越 。
采样策略与调优:
采用分层抽样 (Stratified Sampling),确保训练集中不同高度区间(低层、高层)的样本分布比例符合实际情况 。
利用 GridSearchCV (网格搜索) 对学习率、树的最大深度等超参数进行寻优,最终为 33 个区域分别训练了最优模型 。
3. 数据生成与评估阶段 (Mapping & Accuracy Assessment)
全球测绘:将训练好的模型应用于全球 13 亿个建筑脚印,生成 3D-GloBFP 矢量数据集 。
多维度验证:
交叉验证:计算 $R^2$ 和 RMSE 值。结果显示 62% 的区域 RMSE 低于 10 m 。
实测数据对比:通过 Google Earth 街景手动测量了 14 个城市的 700 栋建筑,验证了模型在现实世界中的可靠性($R^2 = 0.85$)。
同类数据集横比:将结果与 WSF 3D、GHSL-H 等现有的全球格网数据集进行对比,证明了 3D-GloBFP 在捕捉城市微观形态(如 CBD 高层中心)方面的优势 。
4. 基础设施分析 (Built-up Infrastructure Analysis)
技术路线的最后一步是将生成的“点位”数据转化为“宏观”洞察:
通过计算每个建筑的体积(面积 $\times$ 高度)并求和,得出全球各国和城市的建筑总体积 。
分析全球基础设施的地理差异,例如中国(23.9%)和美国(17.6%)在全球建筑存量中的占比 。
科研绘图领域格局重塑
对于经常使用Nano Banana(小香蕉)创作图表的朋友而言,应该能轻易地从以上案例对比中辨认出来:位于上方、色彩更为鲜艳、图示元素更为繁复和视觉冲击力更强的,正是Nano Banana的典型作品。
而下方看起来更为简洁、清爽、布局干净的图表,则是GPT Image 2的杰作。需要特别指出的是,这几张效果出色的图表均是一次生成,并未经过反复“抽卡”尝试。
两个模型的出图风格差异极为显著:一个如同浓妆艳抹,将所有信息扑面而来;另一个则似清水芙蓉,风格简约而克制。
GPT Image 2真正理解了何为“克制”的艺术,以及“留白”所带来的高级感。
尽管尚未在其他众多应用场景中进行全面测试,但仅凭这三次“零抽卡”直接产出高质量图表的结果来看,图像生成模型领域的新王者已然显现。
对于信息复杂度高、要求严谨准确的科技信息图与技术路线图而言,GPT Image 2堪称当前无可争议的佼佼者。
不过,目前该模型仍处于灰度测试阶段。令我感到意外的是,我的免费账户竟然获得了测试资格。询问了多位已开通会员的朋友,他们使用的仍是上一代旧模型。
这着实有些令人费解,OpenAI,你再一次赢得了我的关注与尊重。
那么,如何测试自己是否已被灰度到新模型呢?
方法很简单:在ChatGPT中勾选“创建图片”功能,尝试让它生成一张包含中文的、信息结构较为复杂的技术图表。如果模型能够准确无误地渲染所有文字,并且排版布局也没有出现混乱崩坏的情况,那么你使用的很可能就是第二代模型了。
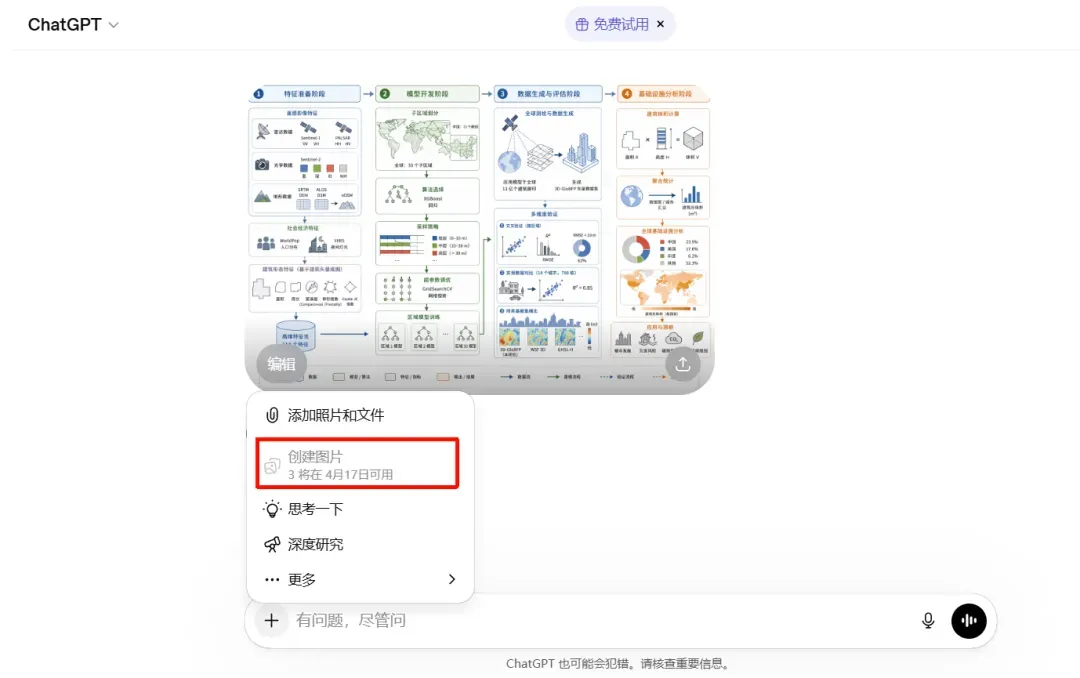
回想去年底Nano Banana Pro刚面世时,其表现确实令人惊艳,众人无不感慨图像模型竟能达到如此高度。
未曾想,其王座尚未坐稳数月,竞争对手的策略调整便已开始。与此同时,另一家巨头Google似乎正在降低其模型的“智力”表现,当前的Gemini模型效果已今非昔比,让付费会员感到些许失望。
在此背景下,OpenAI此刻的强势表现可谓恰逢其时,来得正是时候。
这个时代的AI产品领域,用户的忠诚度极为有限。规则简单明了:哪家的工具更好用,用户就会流向哪里。