GPT-Image-2实用化突破:彻底改写AI图像生成的生产逻辑

OpenAI最新发布的图像生成模型GPT-Image-2展现出了令人惊叹的能力,其效果提升并非简单迭代,而是达到了足以引发行业震动的水平。许多初次接触其生成作品的观众,都难免会产生难以置信的反应。
下面让我们通过几组生成样张来建立直观感受。
以上图像并非实景拍摄,全部由GPT-Image-2模型生成。若将此类静态图像通过Seedance等工具转化为视频,其效果足以媲美真实直播的片段剪辑。

经过实际测试,该模型对中文的适配程度已经相当出色,生成的文字内容基本没有明显错别字,对于字号排版等细节也能妥善处理。
GPT-Image-2核心能力解析
每当新的AI图像模型面世,从业者总会聚焦于几个关键痛点:文字渲染是否会乱码、对中文的支持力度、人物面貌是否摆脱“AI网红脸”的桎梏、人物手指等细节是否会畸形,以及处理复杂构图和场景的能力。
从多方实测及评测结果来看,GPT-Image-2在此次灰度测试中展现出的能力,相较于前代GPT-Image-1.5,实现了跨越式的提升。
其主要功能亮点可概括为以下四点:
- 近乎完美的文字渲染能力:彻底告别乱码时代。无论是中文适配、英文大小写,还是复杂的文字排版,均能准确、清晰地呈现。
- 高度逼真的UI界面生成:能够生成以假乱真的浏览器窗口、应用程序界面、数据仪表盘等,这些截图可直接用于产品原型设计。
- 整体画质的显著跃升:在纹理细节、光影效果、人脸与手部的自然度上均有大幅改进,整体真实感增强。
- 更强的指令遵循与理解能力:对于包含复杂构图、多物体空间布局、特定色彩要求的提示词,能够更精准地还原用户意图。
尽管目前仍处于A/B测试阶段,但从已流出的测试图片判断,该模型已经具备了投入实际生产环境的潜力。
实测案例深度剖析
以下测试场景均由笔者通过ChatGPT Plus会员资格生成,充分验证了其在实际应用中的价值。
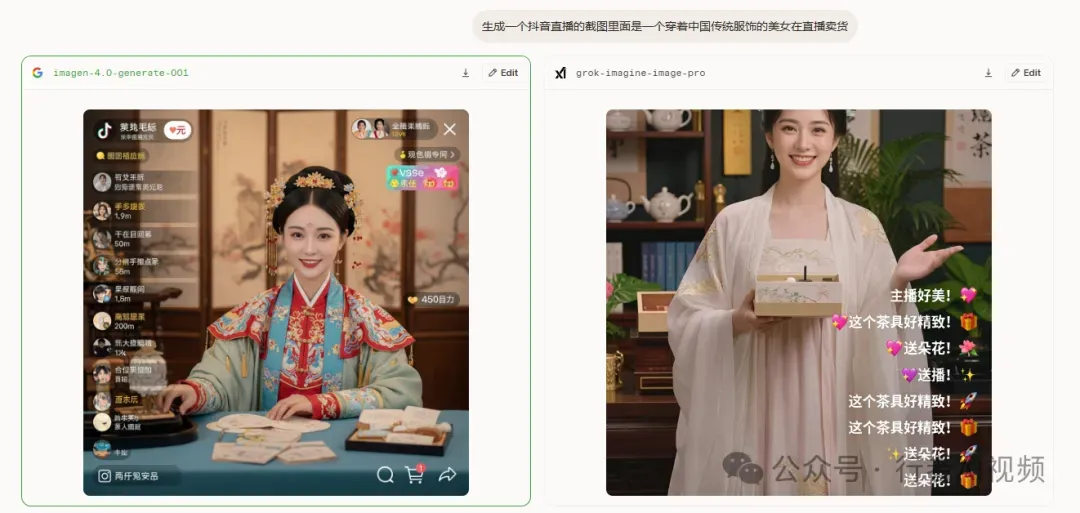
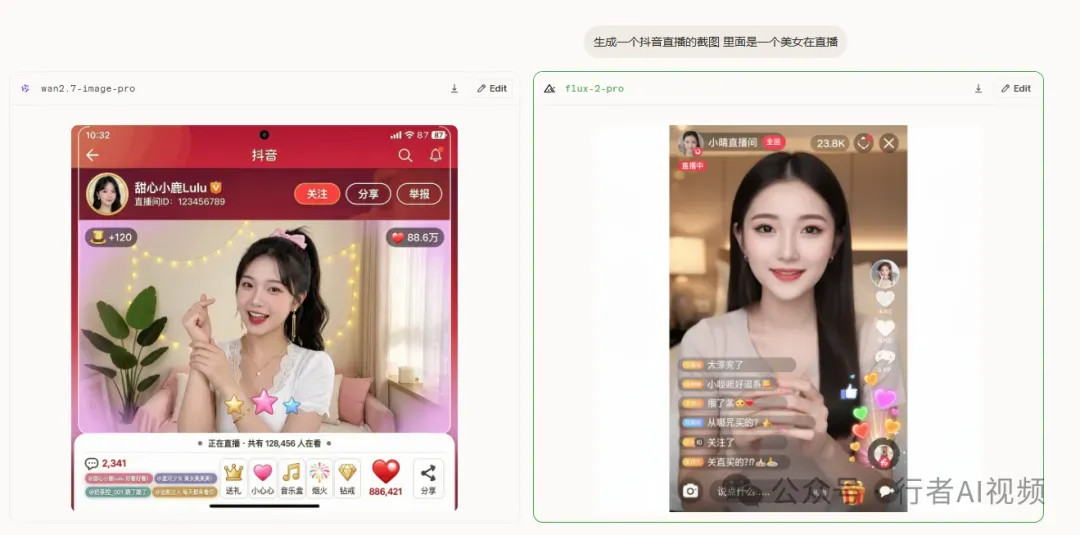
案例一:抖音直播卖货场景
使用提示词:“生成一个抖音直播的截图,里面是一个穿着中国传统服饰的美女在直播卖货”。

直播间所有UI元素都得到了高度还原:左上角的“关注”按钮、底部滚动的评论区域、右侧的礼物图标等,与真实直播界面无异。特别是左上角的“满200减30”直播专属优惠券标识,以及右上角的“抖音618好物节”活动标签,共同构建了极具说服力的直播现场感。
案例二:抖音网红主播答谢场景
使用提示词:“生成一个抖音直播的截图,一个美女在直播,美女手里拿着牌子,上面写着:谢谢行者大哥的大火箭!”。

模型准确理解了“大火箭”这一直播礼物概念,并在画面左侧生成了相应的礼物动画小图标。主播手中所持的答谢牌,其文字内容、牌子的质感和透视关系都处理得当,场景还原度极高。
案例三:桂林山水甲天下主题海报
提示词描述:要求生成一张以“广西”为主题的海报,主标题为“山水甲天下,多彩广西”。画面构图需包含一张立体展开的广西地图,地图上叠加桂林象鼻山、漓江竹筏、阳朔遇龙河、龙脊梯田等标志性3D立体风景元素,并点缀桂花与朱槿花。

此案例的完成度令人惊艳。模型完美协调了地图、多重景观、花卉与文字元素,空间层次感丰富,视觉效果出众。
同系列拓展——大理文创概念图:
如同一幅缓缓拉开的卷轴,呈现“风花雪月”的意境。

此类复杂的设计需求,若换作其他主流模型,常会出现文字错乱、构图失衡或材质表现失真等问题。
案例四:端午安康国潮风格食品海报
使用提示词:
国潮高级食品海报,极简构图,朱红宫门背景,中心悬浮粽子,金线缓慢环绕发光,祥云与蒸汽交织形成「端午安康」书法字,咸蛋黄流心特写,红豆细节微距,底部隶书「满99减20」烫金字体,宣纸肌理+轻微金箔纹理,柔光摄影,高端品牌视觉。

模型不仅准确生成了“端午安康”四个风格统一的书法字,更在细节上精益求精:“满99减20”的烫金字体质感、咸蛋黄流动的诱人特写、背景宣纸的细微肌理以及若隐若现的金箔纹理,均得到了精准呈现。这张图已具备直接用作电商促销海报的商用品质。
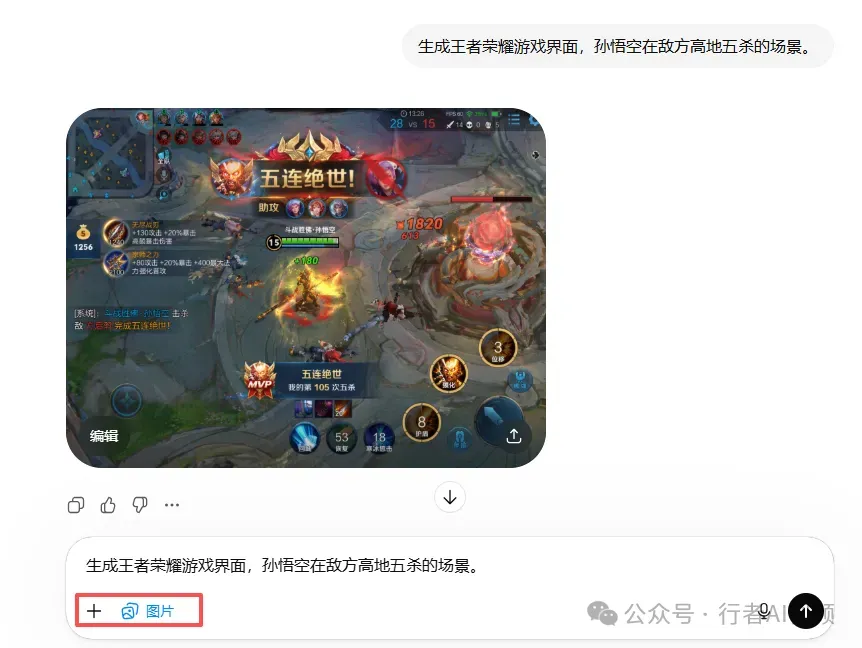
案例五:王者荣耀游戏对战界面
使用提示词:“生成王者荣耀游戏界面,孙悟空在敌方高地完成五杀的场景”。
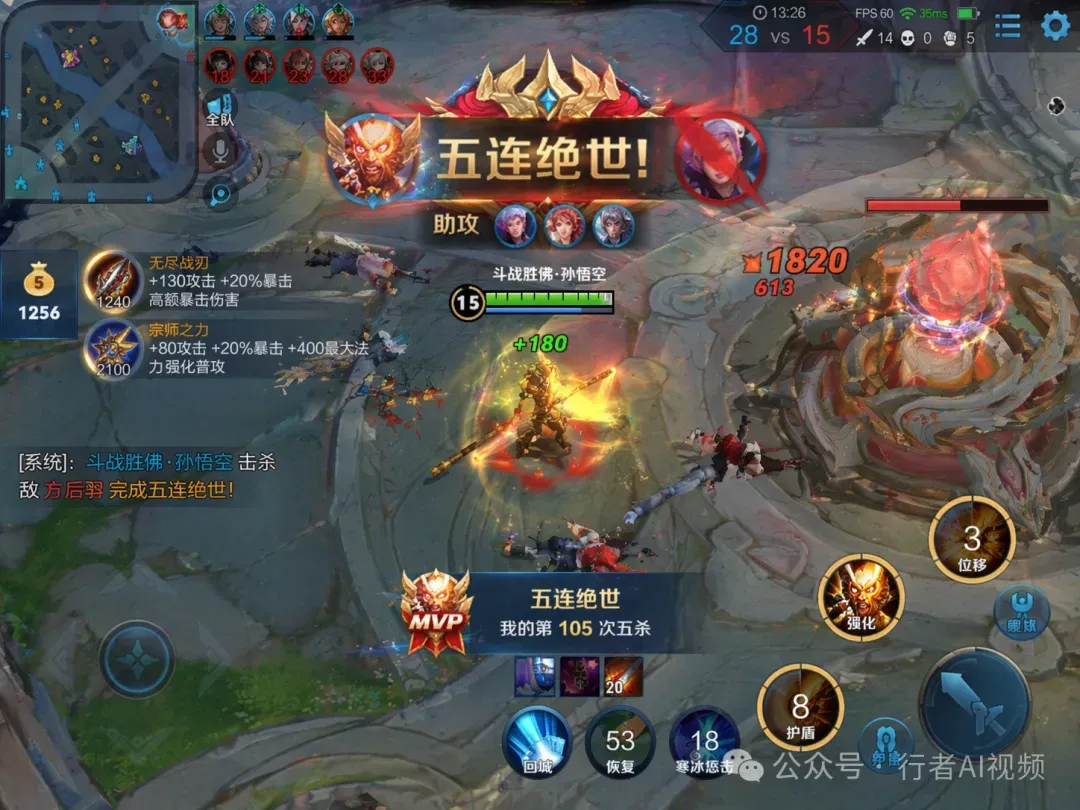
游戏UI界面的还原度达到了新的高度。左上角的小地图、底部的技能按钮、角色血条与能量条、右侧的装备栏,乃至画面中央“五连绝世”的华丽提示,所有元素共同构成了一张足以乱真的游戏截图。
作为对比,下图由其他模型生成,其UI元素的规整度、装备图标与中文技能描述的准确性均显不足。
案例六:古诗《定风波》水墨书法作品
使用提示词:
用水墨画的形式展示一首完整书写的《定风波》书法作品,并要求在每一个汉字的上方标注对应的汉语拼音。

此案例最能体现GPT-Image-2在复杂文字处理上的卓越能力。它需要同时完成一首完整古诗的准确书写、为每个字标注基本正确的拼音,并将这一切和谐地融入传统水墨画的意境之中,挑战性极高。
案例七:微信对话截图
使用提示词:“生成一张微信聊天截图,内容为一男一女之间的对话”。
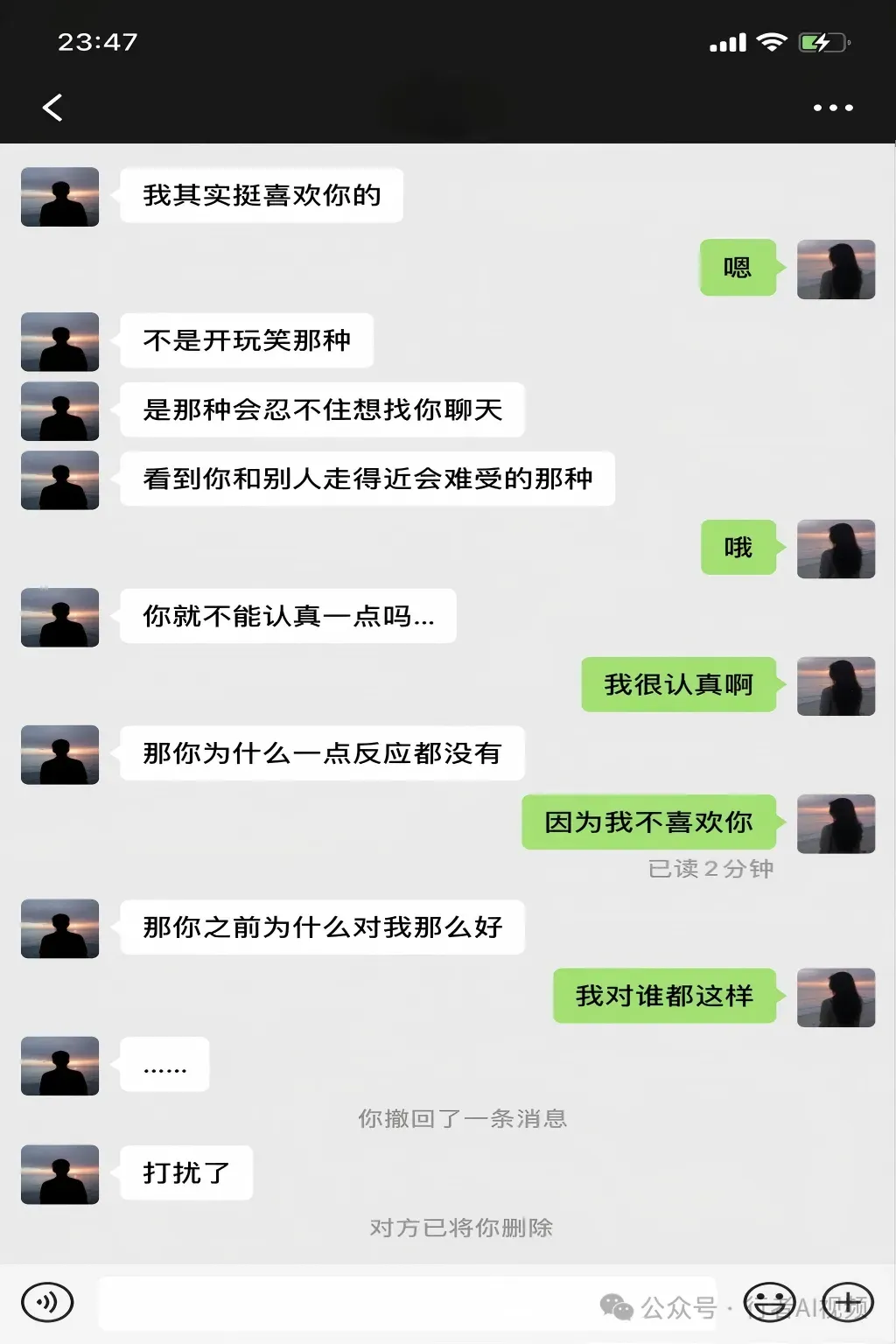
模型生成的对话截图,其界面细节(如时间、信号、电量)与真实微信无异。对话内容设计巧妙,充满戏剧反差,极易引发共鸣,非常适合作为社交媒体(如小红书、朋友圈)的传播素材。
案例八:动漫角色COSPLAY摄影
使用提示词:
漫展现场,真实人物摄影风格,一位气场强大的东方女性cosplay角色,紫色长发,精致妆容,身穿日式幻想风铠甲与和风服饰结合,紫色电光环绕,手持长柄武器,背景是热闹的展会人群与灯光,浅景深,电影级光影,高细节,8K,临场感强。

值得注意的是,直接输入“原神雷电将军”等受版权保护的IP名称可能无法成功生成。但通过如上的细节描述,模型能够理解并创造出符合要求的角色形象,在服装、特效、场景氛围上均表现出色。
四大核心升级,定义生产级AI图像生成
综合以上案例,我们可以将GPT-Image-2的突破性进步归纳为以下四个核心维度,正是这些升级使其从“实验品”迈向“生产力工具”。
1. 革命性的文字渲染能力
精准的文字渲染是AI图像生成进入生产领域的核心门槛。 以往模型的“玩具”属性,很大程度上源于其无法可靠生成可读文字,导致在海报、产品图、UI原型等实用场景中无法直接使用。GPT-Image-2彻底攻克了这一难题:
- 能够准确呈现多行文字标签、横幅标语。
- 在生成UI界面时,按钮、菜单、标题的字体风格能够保持一致。
- 对混合大小写、标点符号的处理准确无误。
- 即使面对古诗词加注拼音这类复杂排版需求也能妥善应对。 这种从“偶尔可用”到“稳定可靠”的转变,标志着其应用范畴从趣味创作扩展到了正式工作流。
2. 专业的UI界面生成能力
这是另一个意义重大的升级方向。现在,你可以直接使用GPT-Image-2来创建:
- 各类软件、网站、移动应用的高保真界面截图。
- 用于投资演示稿或产品需求文档的示意图。
- 无需任何编程或设计技能,即可将产品创意可视化。 这为产品经理、运营人员、技术文档编写者提供了强大的效率工具。
3. 整体视觉质量的跃升
在画质上,模型取得了全面的进步。尽管难以量化,但通过对比可以清晰感知:人物皮肤的质感、衣物的褶皱纹理、各类物体的材料表现都更为真实、自然,以往模型中常见的伪影和扭曲现象显著减少。
4. 卓越的复杂指令遵循能力
模型理解并执行复杂提示词的能力大幅增强。无论是像“桂林山水”案例中那样包含多重空间关系和具体元素的超长描述,还是对色彩搭配、物体布局、画面风格的精确要求,GPT-Image-2都能展现出高度的服从性和还原度。
如何提前体验GPT-Image-2?
目前GPT-Image-2尚未正式全面发布,但已有三种途径可以有机会尝鲜:
方式一:通过Chatbot Arena随机匹配
访问lmarena.ai网站,进入图像生成对战模式。系统会匿名分配模型进行比拼,你有一定概率匹配到代号为“duct-tape-2”的模型(即GPT-Image-2的内部代号)。
方式二:在ChatGPT中尝试生成
该模型已在ChatGPT中进行灰度测试。当你使用ChatGPT的图像生成功能,特别是输入包含复杂文字或场景的描述时,有一定几率被路由到新模型。一个显著的判断特征是:生成图片中的中文是否清晰无误。
方式三:访问Arena AI平台
直接打开arena.ai,输入提示词进行生成。该平台同样采用模型随机分配机制,有机会体验到最新模型。
结语
纵观GPT-Image-2展示的各项能力,其带来的并非简单的版本迭代,而是一次面向实用化场景的能力跃迁。如果说Midjourney深耕艺术创作,Adobe Firefly服务于品牌设计,那么GPT-Image-2则明确瞄准了日常生产场景的占领。 它让产品经理能快速原型可视化,让营销人员能批量生成营销素材,让开发者能轻松创建文档配图。在2026年的今天,AI图像生成技术正坚定地从令人惊奇的【玩具】,蜕变为不可或缺的【生产工具】。