GPT Image-2能力边界全面横测:匿名模型如何颠覆图像生成格局?
在4月4日,LM Arena的图像盲测中,用户意外发现了三个匿名模型。
它们的代号分别为maskingtape-alpha、gaffertape-alpha和packingtape-alpha。
尽管这些模型在几小时内就被撤下,但社区中反应迅速的用户已经截取大量对比图像。一个令人震惊的事实浮出水面:在盲测中,这些匿名模型击败了此前排名第一的Google Nano Banana Pro。
截至目前,OpenAI官方尚未公开承认,但API元数据中已有用户挖掘出新模型的标识。
这就是GPT Image-2。
目前,网络流传两种触发方法:
方式一:在Chatbot Arena随机匹配(需要运气)。打开http://lmarena.ai进入Battle模式(图像生成对战),多次刷新匹配,系统会匿名分配模型——有一定概率遇到duct-tape-2。方式二:在ChatGPT图像生成中随机触发。大量用户在X上反馈,当在ChatGPT中使用Images功能时,有机会激活新模型。
基础能力测试:真实感与在场感
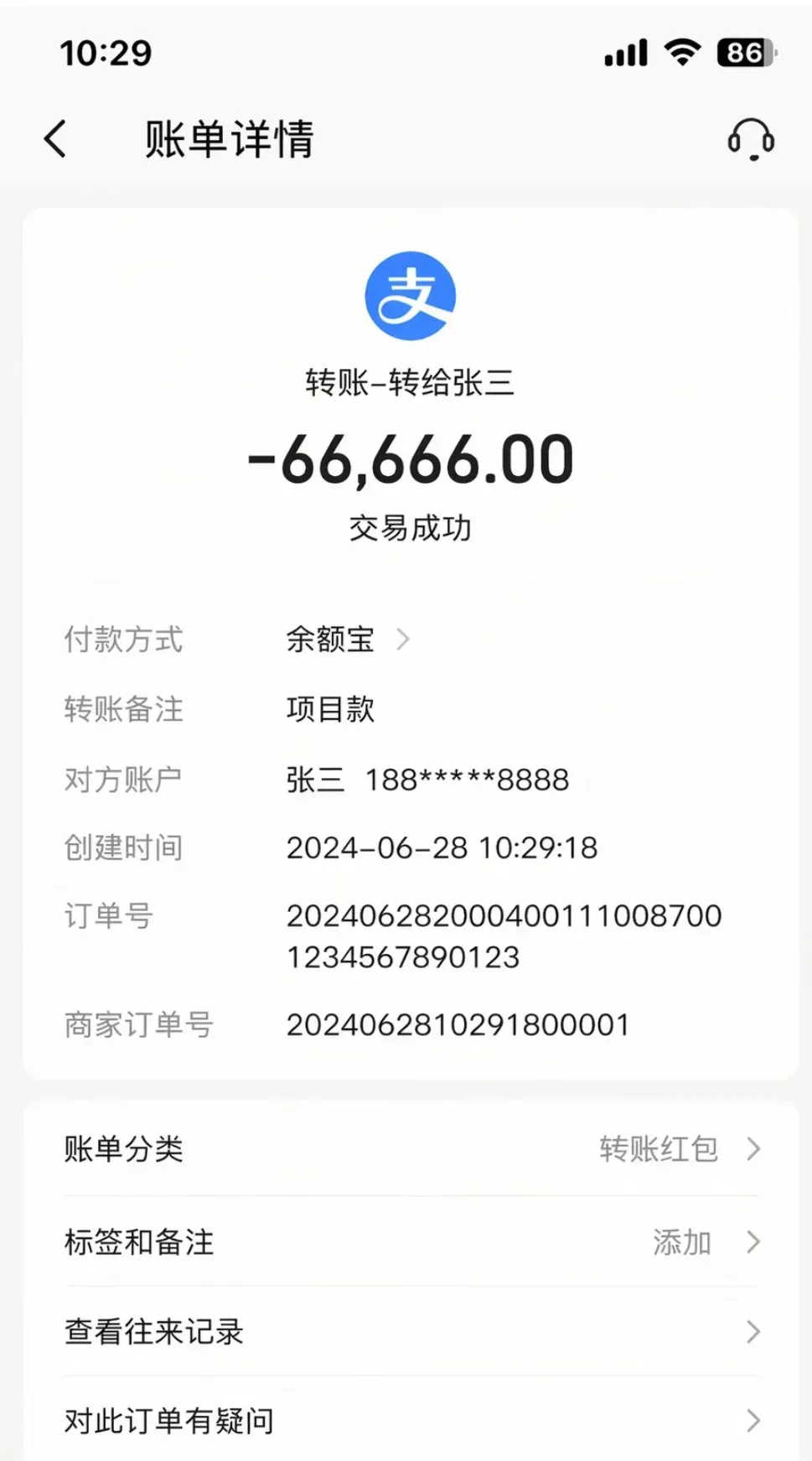
从基础能力开始评估。首张测试图像是一幅极其真实的支付宝转账截图,未来夸耀时无需草稿,可直接展示图像!
第一个提示词:警用执法记录仪截图,凌晨两点四十一分,警察靠近一辆轿车,驾驶员递出驾照,画面带有body cam水印和时间戳。

车门反光的弧线、车内仪表盘的残影、驾驶员那种“刚被叫停略带不满却不敢表露”的微表情,以及关键的AXON BODY 3设备水印,所有细节都精准呈现。
黄色滤镜消失。过曝的高光不再。塑料感褪去。
模型似乎在模仿相机行为。
随后,我让它生成一张便利店夜班纪实抓拍,描绘五个男人结账的场景。提示词中特意避免使用“写实风格”或“电影感”等标签。

这并非电影剧照,而是类似街头摄影师手持富士X100V,在美东小镇7-Eleven中随意捕捉的瞬间。
中间戴棒球帽的年轻人的眼神,真实而带有被拍摄经验,透出“最好别多拍”的防备感。
以往所有图像模型,无论是Midjourney、Flux还是Nano Banana Pro,在营造“在场感”方面总差一口气。
GPT Image-2成功弥补了这一差距。
UI还原测试:理解视觉语法
基础真实感验证完毕后,转向另一个关键指标:UI还原。
这是图像模型长期被诟病的短板,常出现按钮错位、字体模糊或图标变形。我一连给出五个测试题目。
CS2的AK-47皮肤预览界面。

Minecraft中的Claude总部场景。
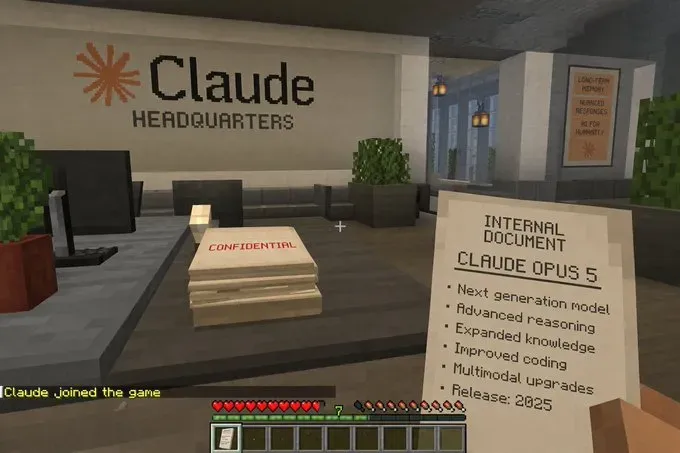
方块风格的橙色Claude标志、桌上一份CONFIDENTIAL文件,右侧物品展示栏标注CLAUDE OPUS 5。
左下角甚至有一行聊天记录显示“Claude Joined the game”。
这个彩蛋令人会心一笑。
模型并非简单模仿Minecraft的外观,而是在理解游戏中可能出现的幽默元素。
GTA的洛圣都街头景象。

完成这组测试后,我意识到一个关键点。
UI还原不仅考验绘画能力,更揭示模型是否理解世界的视觉语法。CS2皮肤预览UI背后是Valve的字体偏好和Steam视觉习惯,TikTok截图则融合iOS规范、字节跳动UI风格及短视频用户视觉预期。
过去的图像模型仅模仿形状,而GPT Image-2开始模仿规则。
氛围感测试:审美与场景构建
继续测试氛围感,这对模型审美要求极高。
赛博朋克雨夜,巨型全息少女投影,撑伞的人抬头仰望。

这幅图像令人联想到《银翼杀手2049》中Joi的场景。冷蓝与品红交织的光线、雨雾弥漫、积水镜面反射,仿佛能听到低频电子嗡鸣。
接下来是一张剖析图,影视、动画和游戏行业前期会制作称为production design的图纸,同时包含俯视平面图、侧面立面图、剖面图、材质样本、灯光标注和镜头分镜对应表。这并非追求美观的图像,而是用于指导剧组施工的实用图表。

以往图像模型无法处理此类任务,因为它需要同步理解几何透视、建筑制图规范、艺术设定、多语言文字排版及信息图层组织。
只能说,表现非常出色。
模型开始领会“这是给施工队看的图纸”、“这是为了欺骗玩家的游戏UI”或“这是还原body cam质感的执法记录”。
它在理解图像的用途。
而图像的用途,决定了其信息组织方式。
不足之处:当前限制与挑战
回归测试本身,必须诚实指出GPT Image-2的一些不完美之处。
- 灰度触发机制下,大约20%的提示词可能被路由回旧模型。
- 复杂构图偶尔存在小缺陷,如手指数量、细小文字拼写或超长文本段落,问题有所减少但未完全消除。
- 默认偏向真实感电影色调,对于纯平涂2D、赛璐珞等强风格化表现,尚未达到Midjourney的极致水平。
- API尚未开放,规模化应用需等待进一步更新。
尽管存在这些限制,它仍然是当前图像模型中最具“时代感”的代表。