GPT-Image-2登场:五大升级与横向实测,AI图像生成王座易主?
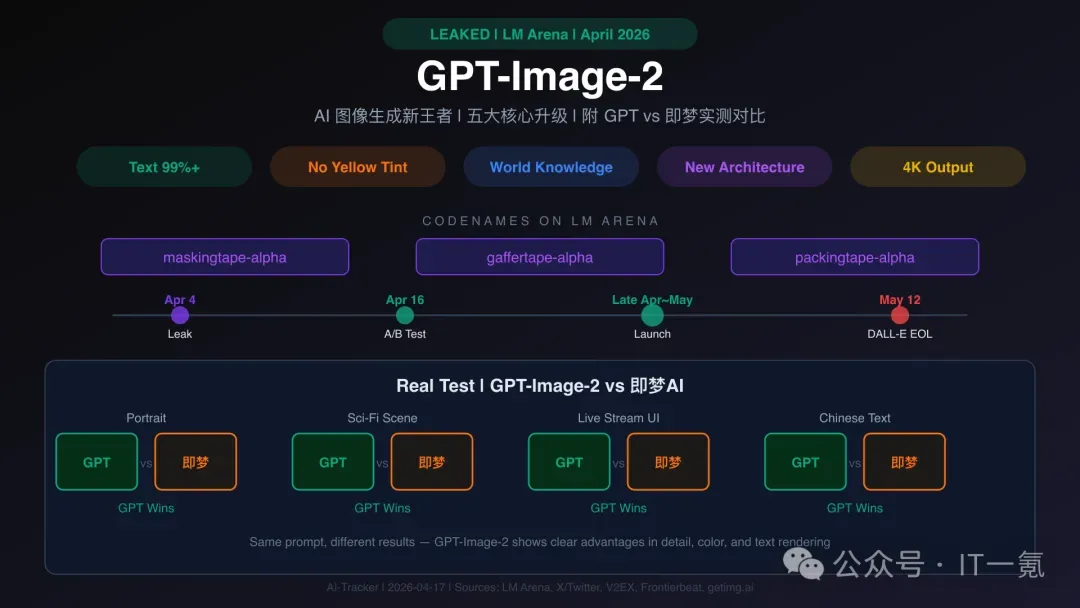
一场由“胶带”引发的技术风暴
2026年4月4日,AI模型评测平台LM Arena(前身为Chatbot Arena)上悄然出现了三个匿名的图像生成模型,它们分别是:
- maskingtape-alpha(遮蔽胶带)
- gaffertape-alpha(布基胶带)
- packingtape-alpha(封箱胶带)
这三个模型在平台的盲测中展现出了令人惊叹的性能,短短数小时内便被敏锐的社区用户发现并引发了广泛讨论。知名独立开发者Pieter Levels率先公开指出,这些模型在理解世界知识和渲染文字方面能力“极其出色”,甚至可能超越当时领先的Nano Banana Pro模型。随后,这三个神秘模型迅速从LM Arena上消失。
社区推测,Reddit用户泄露的截图显示,正是这三个代号为“胶带”的匿名模型出现在LM Arena的排行榜上。
AI爱好者社区迅速将这三个匿名模型统称为 “Duct Tape”系列,并普遍认为它们是OpenAI尚未正式发布的下一代图像模型——GPT-Image-2的不同配置版本。
深度剖析:GPT-Image-2的五大核心革新
1. 文字渲染准确率实现历史性突破
这无疑是AI图像生成领域的一项里程碑式成就。无论是DALL-E 3还是Midjourney,过往所有主流模型在图片中生成文字时,都难以避免地会出现拼写错误、字形扭曲等问题。而GPT-Image-2在此方面取得了飞跃:
- 能够正确渲染出现在弧形表面上的文字,例如咖啡杯或瓶身上的标签。
- 对于手写体风格或漫画中的对话气泡文字,也能做到精准还原。
- 支持包括中文、日文、韩文在内的CJK字符集,以及阿拉伯语、梵文等多语言文字。
示例图片显示,模型可以精确地在弧形瓶身上生成完整的单词。
2. 彻底消除标志性黄色色偏
GPT-Image-1及其1.5版本生成的图像普遍带有一层类似“复古滤镜”的暖黄色调。GPT-Image-2成功地解决了这一色彩倾向问题,使其生成的图片色彩还原更加真实和自然,不再有统一的色彩滤镜感。
3. 对真实世界的理解能力大幅跃升
新模型不再仅仅是根据提示词拼凑出“看似合理”的图像,而是展现了对于真实世界细节的深刻理解。例如:
- 能够精确还原宜家(IKEA)门店的特定外观。
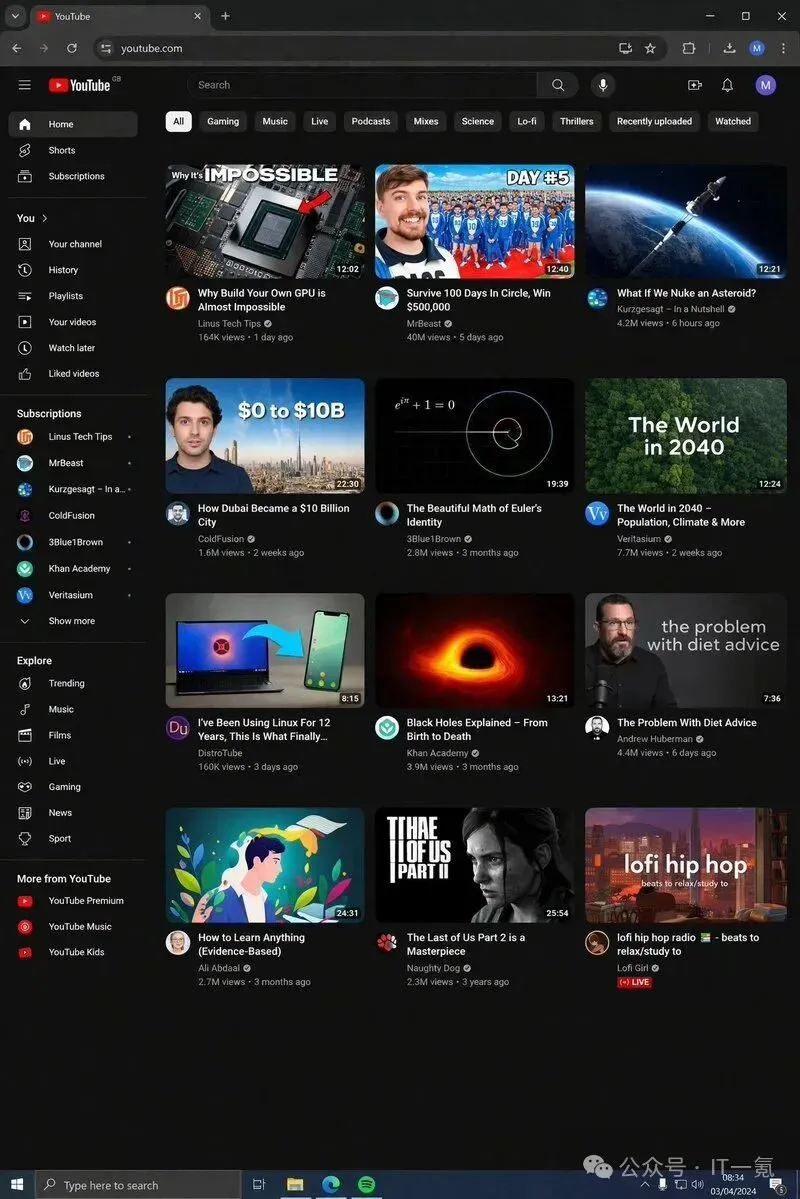
- 生成足以以假乱真的YouTube界面或Windows系统截图。
- 准确描绘地图细节、人体解剖结构图以及复杂的建筑构造。
社区测试显示,其生成的YouTube界面截图已几乎无法与真实界面区分。
4. 采用全新的独立架构
GPT-Image-2不再作为GPT-4o图像生成管线中的一个附属环节存在,而是一个完全独立的图像生成模型。其技术路径从依赖“两阶段推理”(先由语言模型理解,再由扩散模型生成)转向了 “单次自回归生成”,这意味着整个图像生成过程在单一的语言模型内部即可完成,无需调用外部的扩散模型。
5. 原生支持高分辨率输出
新模型原生支持更高的图像分辨率:
- 能够直接输出2048x2048乃至4096x4096分辨率的图像。
- 新增了对16:9等宽屏比例的支持。
- 支持生成WebP格式的图片以及带有透明通道的背景。
技术演示:精准复现张雪峰直播场景
GPT-Image-2对真实世界用户界面的理解和复现能力达到了新的高度。下图展示了其根据描述生成的网红教师张雪峰的直播画面——模型几乎完美地还原了抖音直播间的所有典型UI元素、实时滚动的弹幕文字以及主播本人的神态细节。
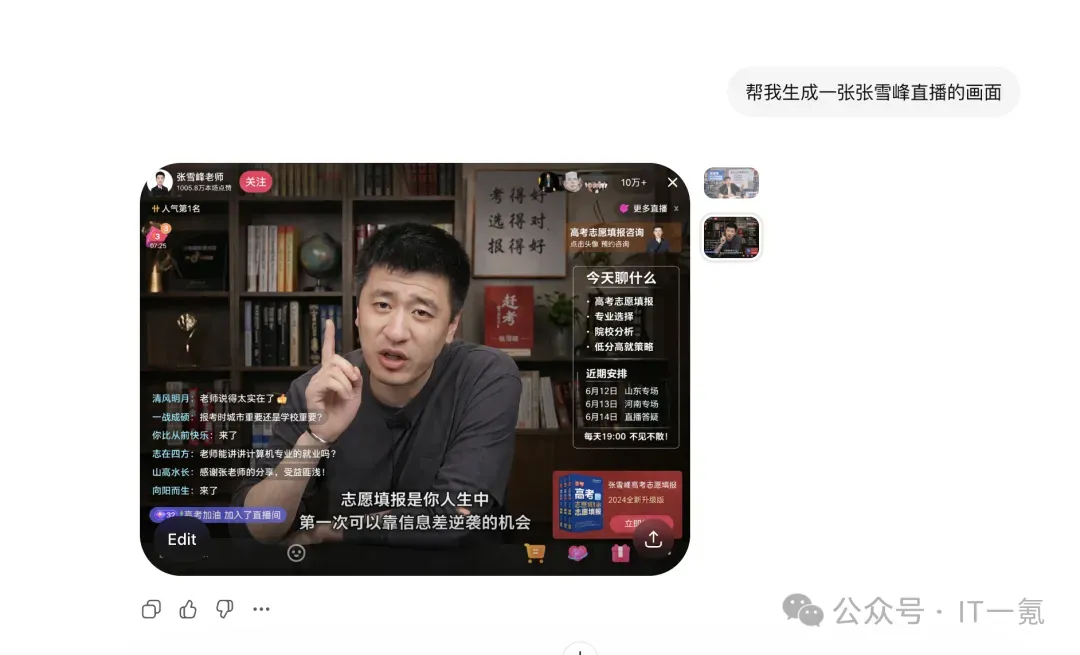
由GPT-Image-2生成的张雪峰直播画面,在界面布局、弹幕内容和人物表情上都做到了高度逼真的还原。
横向实测对比:GPT-Image-2 vs 即梦AI
为了更直观地评估GPT-Image-2的实际能力提升,我们使用完全相同的提示词,分别在GPT-Image-2与国内流行的即梦AI平台上生成图片,并进行多维度对比。
对比场景一:沙漠环境人像
GPT-Image-2生成结果:

即梦AI生成结果:

对比可见,GPT-Image-2在人物皮肤质感、首饰细节纹理、发丝的光影处理上更为细腻真实,整体色彩也更为自然,没有明显的色偏。
对比场景二:科幻风机械鲸鱼
GPT-Image-2生成结果:

即梦AI生成结果:

两者均能生成具有视觉冲击力的科幻场景。但GPT-Image-2在机械结构的复杂细节、场景的光影层次以及城市背景的纵深感塑造上表现更佳。
对比场景三:直播界面还原
GPT-Image-2生成结果:
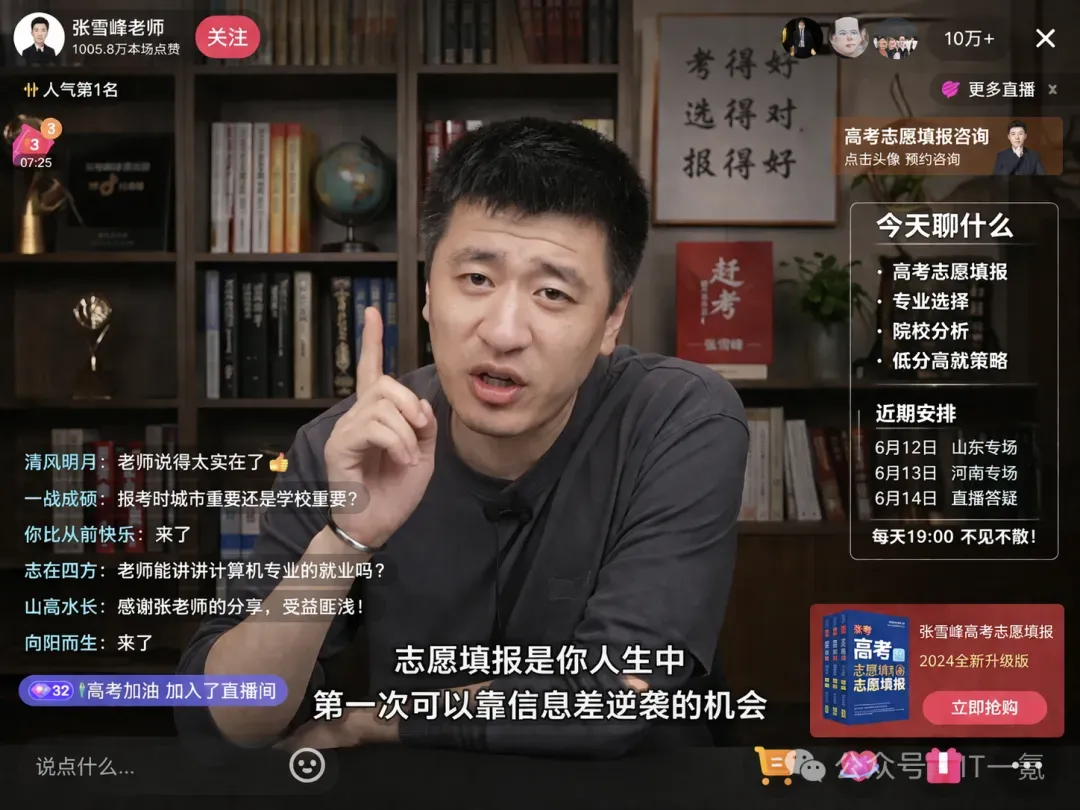
即梦AI生成结果:

这一场景最能体现GPT-Image-2的“世界知识”优势。它精确地复现了抖音直播间的典型UI布局,包括弹幕区、礼物图标和侧边栏信息。而即梦AI生成的则更像一个通用的直播场景,缺乏特定平台的细节特征。
对比场景四:中文手写体生成
GPT-Image-2生成结果:

即梦AI生成结果:

实测总结表格
| 评估维度 | GPT-Image-2 表现 | 即梦AI 表现 |
|---|---|---|
| 文字渲染准确性 | 接近完美,中文几乎无错字 | 基本可读,但偶尔出现字形变形 |
| 色彩还原度 | 自然准确,无明显色偏 | 存在一定的色彩倾向性 |
| UI/真实场景还原 | 能精确复现特定UI元素和细节 | 倾向于生成简化或通用的场景 |
| 人像真实感与细节 | 皮肤、发丝、饰品等细节极佳 | 质量尚可,但在细腻度上有明显差距 |
| 复杂科幻场景 | 光影层次丰富,细节刻画深入 | 整体效果尚可,但层次感稍弱 |
发布状态与社区动向
截至2026年4月17日,GPT-Image-2的发布状况如下:
- OpenAI 仍未官方宣布 GPT-Image-2。
- 自4月16日起,已有部分ChatGPT Plus用户在网页端界面中遇到了A/B测试,疑似是灰度测试。
- 相关API尚未对外开放,目前可用的官方图像API版本仍停留在
gpt-image-1.5。 - 社区有用户反馈,通过特定的提示词指令组合,有概率触发使用新模型的生成过程。
发布时间线预测
结合多方信息,我们对GPT-Image-2的发布时间做出如下预测:
| 关键时间节点 | 相关事件 |
|---|---|
| 2026-04-04 | “胶带”系列模型在LM Arena上泄露并被发现 |
| 2026-04-16 | ChatGPT平台开始疑似新模型的灰度A/B测试 |
| 2026年4月底至5月中旬 | 预计正式发布 (基于社区分析与产品更替逻辑) |
| 2026-05-12 | DALL-E 2 及 DALL-E 3 模型将按计划正式停止服务 |
一个关键的发布依据是:OpenAI早已于2025年11月14日公告,将在2026年5月12日下线DALL-E 2和DALL-E 3服务。因此,公司必须在截止日期前提供一个功能强大的替代产品。加之其视频生成模型Sora已于2026年3月关停并释放出部分算力资源,这一时间窗口显得非常明确。
行业竞争态势一览
当前,AI图像生成领域的竞争已进入白热化阶段,各大厂商纷纷推出或更新其核心模型:
| 模型名称 | 所属公司 | 当前状态 |
|---|---|---|
| GPT-Image-2 | OpenAI | 处于灰度测试阶段 |
| Nano Banana Pro | 已公开发布 | |
| Grok Imagine | xAI | 已公开发布 |
| Midjourney v7 | Midjourney | 已公开发布 |
| Stable Diffusion 4 | Stability AI | 仍在开发过程中 |
值得注意的是,根据LM Arena的盲测结果,泄露的“胶带”系列模型(即GPT-Image-2)已经展现出超越Nano Banana Pro的性能,尤其在图像的真实感和文字渲染精度上优势明显。

社区用户分享的早期样本图像,其质量令人惊叹,进一步证实了模型的强大能力。
全球开发者社区反响
**海外社区(X/Twitter):**包括Pieter Levels、Blake Robbins在内的多位知名开发者与投资人均已发表评论,相关推文获得大量转发。用户@kimmonismus直言:“GPT-Image-2将碾压一切竞争对手。”
**中文社区:**在V2EX等技术论坛,已有开发者开始讨论基于GPT-Image-2开发独立产品的可能性与商业前景。搜狐、知乎等平台也出现了针对此次泄露事件的专题分析文章。
**Hacker News:**目前相关讨论热度一般,仅有一些小型帖子,预计模型正式发布后会引发大规模的技术辩论。
**GitHub:**由于模型尚未正式发布且API未开放,目前尚无针对GPT-Image-2的专属代码仓库。现有的开源生态主要围绕 gpt-image-1 及 1.5 版本的API构建。
给开发者的前瞻性建议
面对即将到来的模型更新潮,开发者可以提前做好以下准备:
- 密切关注官方渠道: 定期查看OpenAI官方博客,正式发布的公告可能随时到来。
- 熟悉现有API: 深入理解
gpt-image-1.5的API调用方式与参数,因为GPT-Image-2很可能会沿用相似的结构。 - 规划迁移路径: 如果当前产品依赖DALL-E 2/3的API,务必在2026年5月12日服务下线前,完成向新模型的迁移方案测试。
- 关注成本变化: 目前
gpt-image-1系列模型的定价区间为每张图片$0.005至$0.20,需留意新模型的定价策略,以便评估对项目成本的影响。