Harness Engineering解析:为何AI模型外的管控层能带来性能翻倍
最近在技术社群的讨论中,“Harness”一词的出现频率陡然升高。从OpenAI的官方博客到Martin Fowler的技术文章,再到各类AI智能体(Agent)开发团队的口头禅,“Harness Engineering”似乎成了新的焦点。查阅字典,其本意是“马具”,这与人工智能有何关联?
本质上,Harness可以被理解为套在AI模型外部、用以管理和约束其行为的一整套系统。模型核心负责“思考”与生成,而Harness则负责“管控”——决定模型能调用哪些工具、可以访问哪些数据、如何对输出进行验证,以及在出现错误时如何提供安全兜底。
这套管控层并非全新概念,过去它常以“脚手架”(Scaffolding)或“包装器”(Wrapper)等名称出现。直至今年二月,OpenAI在一篇博文中正式使用并阐述了“Harness”这一术语,随即被行业广泛采纳与讨论。
那么,这套外围系统究竟有多关键?
同一模型,性能差异可达一倍
其重要性可以通过一个事实直观体现:使用完全相同的AI模型,仅更换或优化其外部的Harness系统,在基准测试中的得分差距可能高达一倍。
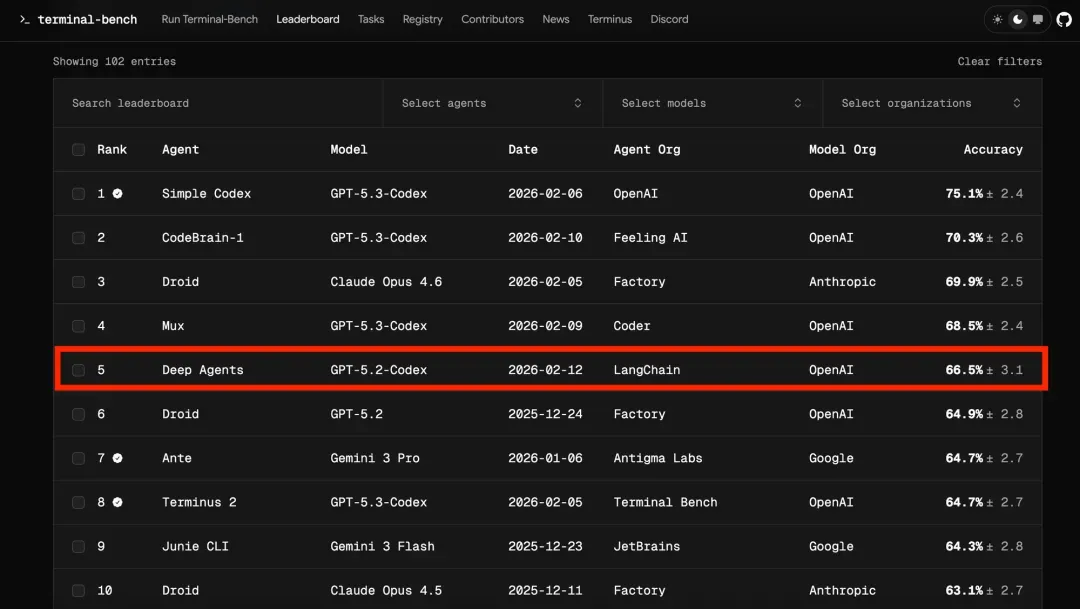
例如,LangChain团队上个月进行了一项实验。他们开发的代码生成智能体在Terminal Bench 2.0基准测试中最初得分为52.8%,排名在30名开外。随后,团队对其Harness进行了三项关键改进:
- 在提示词中引入了“自验证循环”,要求智能体生成代码后必须自行运行测试。
- 编写了一个中间件,用于检测并阻止智能体陷入对同一文件进行数十次无效修改的死循环。
- 在任务启动时,预先将工作目录的环境信息注入上下文。
模型本身并未更换,仍是GPT-4(此处原文“GPT-5.2-Codex”疑为笔误,根据上下文修正为业内已知模型)。经过上述Harness优化后,得分跃升至66.5%,排名一举进入前五。
团队在博客中揭示了一个核心发现:智能体最常见的失败模式是,生成代码后仅进行“肉眼检查”,认为无误后便提交,而忽略了实际运行测试。引入强制性的自验证环节后,失败则必须修正,仅此一项改变就弥补了大部分的性能差距。
另一组由Nate B Jones在三月发布的数据更为直接:同一模型、同一套测试题目,在更换运行环境(即Harness)后,得分从42%提升至78%。
三人团队的构建实践
认识到Harness的重要性后,如何构建它呢?OpenAI内部提供了一个极为前沿的实践案例。
其Codex团队曾立下一个极端规则:整个代码库从零开始,必须完全由AI智能体生成。仓库结构、持续集成(CI)配置、代码格式规范等,全部由Codex编写,没有任何人类编写的代码作为初始锚点。最终,3名工程师在5个月内,通过大约1500次代码合并请求(PR),管理了约100万行由AI生成的代码。
这三位工程师的日常工作是什么?他们主要专注于:搭建初始仓库结构、编写约束规则、配置代码检查工具(Linter)、以及建立有效的反馈循环。当智能体工作卡顿时,他们思考的是:智能体缺失了哪种能力?如何让它理解并执行某项任务?随后,他们会引导Codex将所需的改进方案自行编写并提交回代码库。
可以说,他们的核心工作正是在构建和完善一套高效的Harness系统。

实践中的三个关键教训
构建Harness过程中最具价值的经验,往往来自踩过的“坑”。OpenAI团队总结了三点核心教训:
1. 配置文件应简洁精炼。 初期,他们创建了一份冗长的AGENTS.md文件,试图将所有规则塞入其中。结果却导致智能体因上下文过长而难以抓住重点,有效指令空间被规则文件挤占。后来他们改为维护一份约100行的核心规则索引,将详细内容移至docs/目录下,智能体仅在需要时按索引查询。
2. 代码质量需主动治理。 AI智能体会模仿仓库中现有的代码模式,包括不良实践。久而久之,冗余和低质代码会逐渐累积。团队起初每周花费20%的时间手动清理,但不堪重负。最终,他们将清理标准编码为自动化规则,交由Codex定期扫描并自动发起修复PR。
3. 规则必须被自动化执行。 将架构约束仅写在文档中,智能体未必遵守。后来,团队把关键分层规则嵌入持续集成(CI)流程,违反规则的PR会被自动阻断。这确保了规则的执行依靠系统机制,而非智能体的“自觉”。
工具数量:少即是多
构建Harness还有一个反直觉的经验:提供给智能体的工具并非越多越好,适度精简反而能提升其表现。
Vercel团队曾开发一个内部数据查询智能体,起初为其配备了17个专用工具。然而成功率仅80%,平均每次查询耗时近5分钟,最差情况甚至运行12分钟后仍告失败。
 (图为Vercel博客中引用的内部Slack截图)
(图为Vercel博客中引用的内部Slack截图)
随后,团队将工具数量大幅削减至仅剩2个核心工具。结果,成功率提升至100%,且平均处理速度加快了3.5倍。
GitHub的Copilot项目也有类似发现:当工具数量从40多个减少到13个时,其任务准确率从19%大幅跃升至72%。
工具过多时,智能体需要在“选择使用哪个工具”上耗费决策时间,选错则易导致任务路径迂回。减少选项,反而能让其行动路径更直接、高效。
行业共识:一个核心配置文件
目前,Anthropic的Claude Code在仓库中放置了CLAUDE.md,OpenAI使用AGENTS.md,Vercel也在测试AGENTS.md的效果。这三家公司不约而同地走向了同一种实践:创建一个专门的配置文件,用以集中定义和传达对AI智能体的各项“规矩”。
至于这个文件的最佳长度、应包含的内容范畴以及如何持续更新,整个行业仍在共同探索与优化中。
参考资料:
- OpenAI 官方博客:Harness Engineering
- Martin Fowler 博客文章:Exploring Harness Engineering in Generative AI
- LangChain 博客:Improving Deep Agents with Harness Engineering
- Vercel 博客:How We Improved Our Agent by Removing 80% of Its Tools
- Terminal Bench 2.0 排行榜