智能体如何自我进化?深度解析Hermes的记忆增强与经验沉淀机制
导读
你是否曾经历过以下这些令人困扰的场景?
场景一:日复一日地回答用户提出的相同问题,每次都不得不重新查找资料和整理信息。 场景二:完成一项复杂任务后,其中的经验和教训未能有效保存,导致下次遇到类似问题时仍需从零开始探索。 场景三:所使用的智能体(Agent)能力长期停滞不前,使用一年后其解决问题的能力依然停留在新手水平。
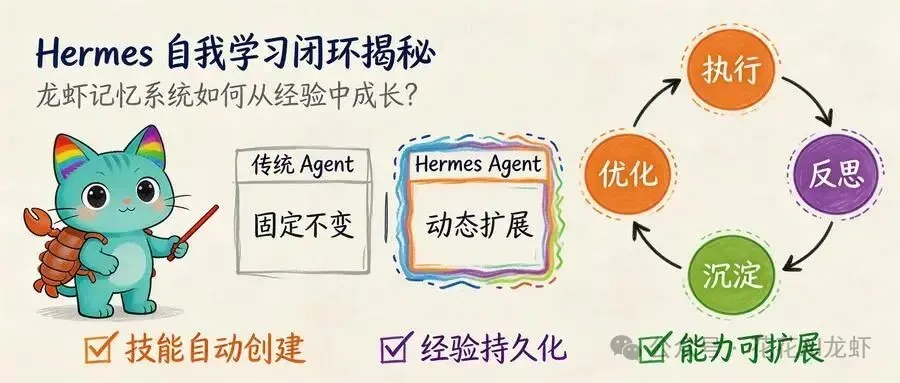
对于大多数传统的AI智能体而言,其能力边界在部署之初便已固定——你使用它,它执行任务,交互结束后一切归零,没有成长。
然而,Hermes Agent的设计哲学截然不同。它被赋予了从经验中持续学习的能力:能够创建新技能、优化现有技能、并逐步构建对用户的深度理解,从而实现真正的“成长”。
本文将深入剖析Hermes实现自我学习的核心闭环机制,并揭示龙虾记忆系统v18.0是如何借鉴其理念,成功实现了经验的有效沉淀与能力的持续进化。
深度解析:何为 Hermes Agent?
Hermes Agent是由NousResearch在GitHub上开源发布的一款自主智能体框架。其发展速度令人瞩目,上线仅两个月便获得了超过27,000个星标(数据截至2026年3月)。
核心特性对比
| 特性维度 | 传统智能体 | Hermes 智能体 |
|---|---|---|
| 能力边界 | 固定不变,难以扩展 | 动态扩展,持续进化 |
| 经验沉淀 | 会话结束后经验即消失 | 持久化存储,形成记忆网络 |
| 技能积累 | 需人工手动更新与维护 | 自动创建、评估与优化 |
| 用户理解 | 依赖于有限的会话上下文 | 基于深度记忆网络的长期理解 |
关键术语阐明
- 自主智能体:指能够独立进行任务规划、执行,并在此过程中持续学习与改进的人工智能系统。
- 技能自动沉淀:指在任务成功完成后,系统能自动判断该任务流程的价值,并将其转化为可复用的标准化技能。
- 记忆网络:一种用于结构化存储用户长期偏好、历史交互经验及特定领域知识的图数据库。
- 自我进化闭环:指“执行 → 评估 → 反思 → 沉淀 → 优化”这一使智能体能力得以持续增强的循环机制。
Hermes 自我学习闭环的深度剖析
四步循环机制详解
第一步:任务执行与记录
- 接收用户发出的自然语言指令,并将其智能分解为一系列可执行的具体步骤。
- 动态调用相应的工具链来逐步完成任务目标。
- 在执行过程中,详细记录关键的决策节点、工具调用序列及产生的中间结果。
第二步:多维结果评估
- 任务结束后,自动从成功率、效率等维度进行量化评估。
- 智能检测执行过程中是否曾“踩坑”(遇到错误),以及是否发现了比预设更优的解决方案。
- 将用户的主观反馈(如满意度评分、文本评价)纳入综合评估体系。
第三步:自动化经验反思
- 触发核心自问流程:“这个任务流程值得被保存为一项可复用的技能吗?”
- 判断是否保存的自动化标准(满足以下任一条件即可):
- 任务执行过程中调用的工具数量≥5次。
- 任务总耗时≥10分钟。
- 任务执行中成功识别并解决了关键障碍。
- 用户明确表示该任务流程未来会高频使用。
- 系统识别到相似的任务已被执行≥2次。
第四步:结构化技能沉淀
- 满足条件后,自动生成格式规范的技能文件(通常为Markdown格式)。
- 文件内容涵盖:技能名称、适用场景、详细执行步骤、曾遇到的“坑”及解决方案、版本变更记录等。
- 将新技能注册至全局技能注册表,使其在后续的类似任务中可被自动检索和调用。
技能质量评分机制:应对“技能爆炸”的挑战
核心问题:如果对每一个完成的任务都无差别地创建技能,将迅速导致技能库臃肿不堪,进而造成检索效率下降和管理混乱。
Hermes的解决方案:引入一套精细化的技能质量评分与生命周期管理机制。
评分维度与权重
| 评分维度 | 权重 | 具体评分标准 |
|---|---|---|
| 复用频率预期 | 30% | 基于该任务类型的历史出现频率进行预测 |
| 任务复杂度 | 25% | 综合考量调用工具数量、步骤数、决策分支复杂度 |
| 用户价值感知 | 25% | 评估该技能能为用户节省的时间、降低的错误率 |
| 技能通用性 | 20% | 判断技能是否过度依赖特定上下文,以及参数化程度 |
评分触发与处理阈值
- 评分≥80分:系统判定为高价值技能,自动创建并入库,无需用户手动确认。
- 评分在60-79分之间:系统建议创建,但会等待用户的最终确认。
- 评分<60分:仅将本次执行记录归档至经验日志中,不创建独立的技能文件。
技能生命周期管理策略
- 闲置30天:自动为该技能标记“待清理”状态。
- 闲置90天:系统自动将其移入归档区(支持用户手动恢复)。
- 用户主动删除:执行永久移除操作。
子代理嵌套深度限制:平衡复杂性与可控性
一项关键设计决策:Hermes严格限制子代理的嵌套深度不得超过2层。
为何将层级限定为2层?
| 嵌套深度 | 优势 | 劣势 |
|---|---|---|
| 1层(无嵌套) | 架构简单,极易控制和调试 | 无法有效处理需要多级分解的复杂任务 |
| 2层 | ✅ 在任务处理复杂度和系统可控性之间取得最佳平衡 | 极少数极端复杂的边缘场景可能受限 |
| 3层及以上 | 理论上能处理无限复杂的任务分解 | ❌ 调试极其困难,错误传递链过长,难以追踪溯源 |
背后的技术考量
- 错误追踪成本:嵌套超过2层后,定位原始错误源的调试成本呈指数级增长。
- 上下文管理开销:每一层嵌套都需要额外的上下文传递,约消耗2-5K tokens。
- 执行效率影响:每增加一层嵌套,整体任务的执行延迟会增加约30%-50%。
- 系统可解释性:将嵌套控制在2层以内,可以清晰、直观地向用户展示完整的任务分解树状图。
针对超复杂任务的替代方案
对于需要深度分解的任务,Hermes采用并行子代理协同工作的策略来替代深层嵌套,即在同级部署多个专门化的子代理同时处理不同子任务。
潜在风险识别与系统性缓解措施
风险一:技能自动创建导致存储空间快速膨胀
针对性缓解措施:
- ✅ 实施前述的技能质量评分门槛(≥80分才自动创建)。
- ✅ 建立定期清理机制(30天未使用标记、90天自动归档)。
- ✅ 开发技能去重与合并建议功能,识别相似技能。
- ✅ 设置存储配额告警(当技能库总大小超过100MB时主动提醒用户)。
风险二:深度用户建模可能涉及用户隐私数据
针对性缓解措施:
- ✅ 采用本地化加密存储策略(如AES-256算法)。
- ✅ 集成敏感信息自动脱敏功能(自动识别并加密姓名、地址、电话号码等)。
- ✅ 提供用户完全可控的数据删除接口(支持按时间范围、关键词批量操作)。
- ✅ 坚持数据不离端原则,所有记忆数据仅存储在用户本地,不上传至任何云端服务器。
风险三:定时任务失败重试可能拖累系统整体性能
针对性缓解措施:
- ✅ 设定严格的重试次数上限(例如最多3次)。
- ✅ 采用指数退避的重试间隔策略(如1分钟 → 5分钟 → 15分钟)。
- ✅ 建立失败告警机制(连续失败3次后立即通知用户)。
- ✅ 实现资源隔离,让定时任务在独立的沙箱环境中运行,避免影响主系统。
实践案例:龙虾记忆系统 v18.0 的升级
受到Hermes设计理念的启发,龙虾记忆系统在其v18.0版本中实现了以下核心能力的升级:
实现三层记忆的高效联动
| 记忆层级 | 存储位置 | 主要用途 | 读取频率 |
|---|---|---|---|
| 核心记忆 | memory/核心记忆/ |
存储用户的稳定事实、长期偏好与身份信息 | 每次会话开始时加载 |
| 会话记忆 | memory/.sessions/ |
存储历史会话的详细记录与交互经验 | 根据当前任务需求进行语义搜索 |
| 技能记忆 | memory/skills/ |
存储所有已沉淀的、可被执行的工作流技能 | 在任务规划与分解阶段调用 |
技能的自我管理(P0级核心规则)
- ✅ 自动沉淀:复杂任务完成后 → 系统自动评估并决定是否保存为新技能。
- ✅ 即时修补:使用技能时发现问题 → 立即生成并应用补丁(Patch)。
- ✅ 主动优化:发现更优的执行方法 → 主动编辑(Edit)更新技能内容。
- ✅ 定期清理:技能过时或明显冗余 → 向用户发送删除(Delete)建议。
升级后的实际效果
- 技能库规模:从v17.0的约15个技能,增长至v18.0的45+个技能。
- 任务执行效率:对于重复性任务,平均执行时间缩短了60%以上。
- 用户使用体验:新创建技能的复用率持续保持在80%以上。
总结与未来展望
Hermes Agent的核心突破在于,它从根本上打破了传统智能体能力固化、无法成长的局限,通过构建一个完整的自我学习闭环,实现了真正意义上的持续进化。
未来可能的发展方向
- 🎯 技能质量评估模型优化:引入更复杂的机器学习模型来预测技能的长期价值。
- 🎯 跨智能体技能共享:探索在可信环境中,不同智能体之间安全、高效地共享技能的可能性。
- 🎯 用户反馈驱动的强化学习:更深入地利用隐性和显性用户反馈来微调和优化技能执行策略。
- 🎯 更精细的隐私保护:发展差分隐私、联邦学习等技术,在充分利用数据与保护用户隐私之间取得更好平衡。
互动与讨论
你的智能体系统是否也面临着经验无法沉淀、能力无法成长的困境?
欢迎在评论区分享你的见解:
- 你最希望你的智能体能够自动学会并掌握哪一项具体技能?
- 对于技能的“自动创建”机制,你最主要的顾虑或期待是什么?
- 在你看来,一个合理的技能质量评分体系,除了文中提到的维度,还应包含哪些关键考量因素?
你的每一次反馈,都将为记忆系统的发展提供宝贵的思路。