Mac实战指南:OpenClaw与Hermes共存部署的完整避坑记录
在过去的一段时间里,Hermes框架的热度持续攀升。尽管半个月前就已听闻其名,但直到上周我才在一台已经稳定运行OpenClaw的Mac电脑上,真正开始了Hermes的安装与配置。这个过程并非一帆风顺,仅配置调试就耗费了三天时间,期间遇到了诸多预料之外的挑战。
本文将详细记录从环境准备到最终成功联动的完整历程,尤其是那些耗费大量时间才解决的典型问题,旨在为计划部署类似环境的同行提供一份详实的参考手册。
首先给出明确的结论:
- Hermes与OpenClaw完全可以在同一台Mac上和谐共存,即便在仅有8GB内存的设备上也能流畅运行。
- 两者之间不存在端口冲突问题,能够作为独立的服务各自运行。
- 整个过程中最棘手的部分并非基础安装,而在于大型语言模型的正确调用配置以及与Telegram的通信链路搭建。
一、框架选择:为何最终锁定Hermes?
当前市场上的AI助手与自动化框架选择众多。我最终决定采用Hermes,主要基于以下三个核心考量:
- 自托管特性:所有数据与运算过程均保留在本地,彻底杜绝了隐私数据外流的风险,实现了完全的数据自主可控。
- 深度可定制性:框架架构开放,允许用户自由接入各类平台与服务,后续的功能扩展完全由自己主导。
- macOS原生支持:能够直接在Mac电脑上原生运行,无需额外租赁或配置VPS服务器,有效节约了长期运维成本。
我的核心需求非常明确:确保数据安全可控、能够灵活对接我需要的第三方平台、并且能够作为常驻服务长期运行而不过度消耗系统资源。综合比较之下,Hermes完美契合了所有这些条件。
二、部署前的环境检查与准备
在开始安装之前,对现有环境进行彻底清查是避免后续问题的关键一步。
硬件基础环境
- 设备:一台正在运行OpenClaw的MacBook Pro。
- 内存:8GB。实测表明,在同时运行Hermes和OpenClaw后,系统仍有大部分内存余量可供其他应用使用。
- 网络:需要具备能够稳定访问Telegram Bot API的网络条件。
软件与依赖环境
- OpenClaw:已预先安装,版本号为0.68.0。
- Node.js环境:由于OpenClaw本身依赖Node.js,其运行环境已就绪,可供Hermes复用。
- Homebrew:macOS的包管理器,用于安装Hermes可能需要的其他系统级依赖。
服务端口占用分析
- Hermes:在客户端模式下运行,自身不主动监听任何网络端口。
- OpenClaw:通常占用
localhost:18789和localhost:18791等端口用于内部通信与管理界面。
最终判断:经过检查,两者在端口资源上完全独立,没有冲突的可能。

三、核心配置实战:踩坑记录与解决方案
配置阶段是本次部署的核心攻坚点,以下是三个最具代表性的问题及其解决过程。
难题一:MINIMAX模型接口调用失败
- 问题现象:在手动配置MINIMAX模型参数后,无论如何尝试都无法成功发起调用。尽管API密钥和模型名称字段均已填写,但始终返回空响应或无反应。
- 排查步骤:
- 反复核验API Key的有效性,甚至尝试重置密钥,问题依旧。
- 详细查看Hermes的运行日志,发现没有明确的错误信息,但也无任何模型响应记录。
- 尝试更换多种不同的模型参数格式与书写方式,均告失败。
- 解决方案:最终通过Claude Code辅助分析,直接检查了Hermes的配置文件深层结构。发现症结在于
model字段的格式——必须使用完整的模型路径标识符anthropic/MiniMax-M2,而不能使用任何形式的缩写或别名。 - 经验总结:大型语言模型的配置参数往往非常严格,一个字符的差异就可能导致整个功能失效。遇到此类底层配置问题时,直接借助AI工具进行代码或配置结构分析,远比人工盲目试错的效率高出十倍。
难题二:Telegram机器人通信链路中断
- 问题现象:在成功配置模型后,希望进一步将Hermes接入Telegram群聊。然而,在TG中向机器人发送消息后,Hermes端完全收不到任何信息。
- 排查步骤:
- 多次检查并确认Bot Token准确无误。
- 查看Hermes日志,显示已成功连接到Telegram API,但消息流始终为空。
- 困惑于Telegram Bot的两种工作模式(Webhook与Polling),怀疑是模式配置错误导致。
- 解决方案:利用OpenClaw内置的故障诊断工具执行了全面检测:
诊断报告明确指出,问题出在Telegram Bot的Webhook URL设置上,其指向的本地端口号与Hermes实际监听的端口不匹配。修正配置文件中的端口地址后,消息即刻成功接收。
openclaw doctor - 经验总结:OpenClaw的
doctor诊断命令是一个被低估的实用工具。在遇到复杂的通信或集成问题时,首先运行该命令进行系统级检查,可以快速定位很多隐蔽的配置错误,大幅节省排查时间。
潜在疑虑:双AI系统并行时的消息干扰
- 问题场景:当OpenClaw和Hermes都配置了各自的Telegram机器人后,用户担心两者是否会处理到同一条消息,造成响应混乱。
- 明确结论:完全不会。OpenClaw和Hermes分别使用各自独立申请的Bot Token,监听的是两个完全不同的机器人账号。从Telegram服务器的角度看,这是两个毫无关联的服务。实测证实,两个机器人接收和处理的消息流完全隔离,互不干扰。
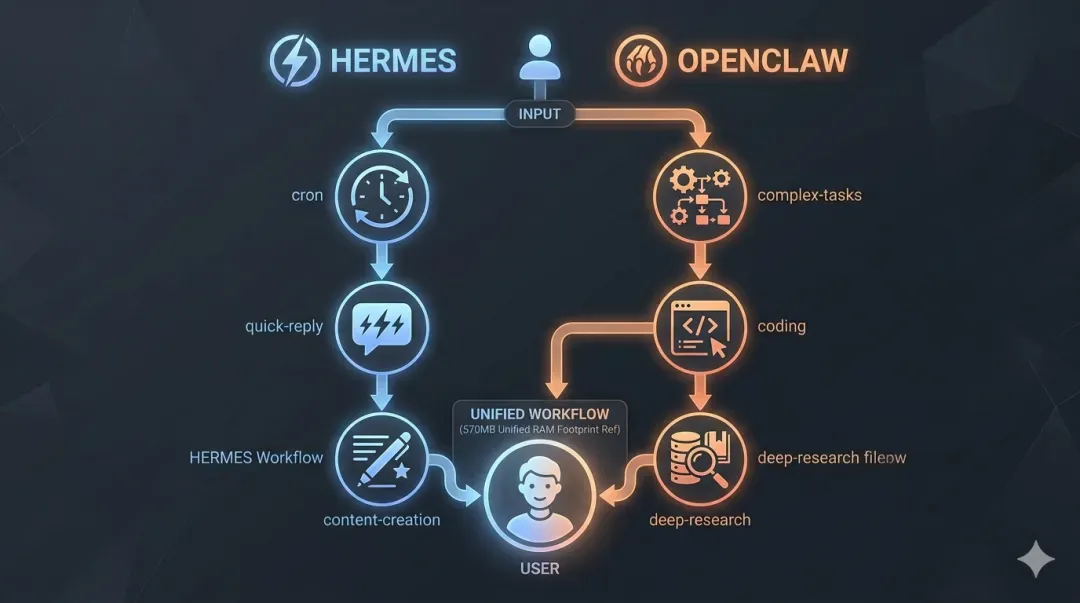
四、功能定位:Hermes与OpenClaw如何协同工作
许多人会疑惑,同时运行两个AI框架,它们的具体分工是怎样的?以下是基于实践总结出的核心互补逻辑。
| 应用场景 | OpenClaw 擅长度 | Hermes 擅长度 |
|---|---|---|
| 复杂的多步骤规划与执行任务 | ✅ 核心主力,擅长拆解与执行 | 可作为辅助,进行初步规划 |
| 快速的实时信息查询与应答 | 较慢(存在冷启动开销) | ✅ 秒级响应,体验流畅 |
| 定时任务触发与系统监控 | 非原生强项 | ✅ 原生支持cron表达式,非常方便 |
| 处理飞书/Telegram等即时消息 | 可以胜任 | ✅ 轻量级响应,资源占用低 |
| 复杂代码编写与调试 | ✅ 能力强大 | 能够完成基础编码任务 |
| 内容创作与营销策划 | 表现一般 | ✅ 更为擅长创意与结构化输出 |
| 调用丰富的第三方工具与API | 生态相对有限 | ✅ 插件生态更广泛,扩展性强 |
具体协作实例: 当需要研究“MINIMAX公司最新的模型有哪些”这一课题时,我可以将复杂的调研和整理任务交给OpenClaw去异步执行。同时,在等待结果的过程中,我可以在Telegram里直接向Hermes提问,它能立刻给出基于现有知识的快速解答,无需等待OpenClaw的启动与思考过程。这充分体现了响应速度与任务深度的互补。
简单概括:
- OpenClaw 扮演“深度执行者”的角色,负责处理那些需要长时间思考、多步骤操作的复杂任务。
- Hermes 扮演“即时助手”的角色,负责处理日常对话、信息快速检索、提醒通知等轻量级、碎片化的需求。 两者并非竞争或重复关系,而是构成了从快速响应到深度处理的任务协作流水线。

五、实际运行时的系统资源占用评估
在8GB内存的MacBook Pro上同时运行两者,其资源消耗情况如下:
| 系统状态 | 内存占用概况 | 补充说明 |
|---|---|---|
| 仅运行 OpenClaw + Hermes(空闲状态) | 总计约 570 MB | 这是AI服务进程在静止待命时的基础占用 |
| 叠加正常办公负载(浏览器、通讯软件、文档编辑) | 额外增加 2~4 GB | 取决于同时打开的应用程序数量与使用强度 |
| 8GB Mac 的最终可用内存余量 | 大约剩余 3.4~5.4 GB | 该余量足以保障整个系统的流畅运行 |
重要提示:上述570MB是系统空载时的基准数字。在实际使用中,当你同时打开数个浏览器标签页、运行微信、并启动VS Code进行开发时,8GB内存的Mac依然能够从容应对。最初看到两个AI框架合计占用近600MB时或许会感到惊讶,但实际上,这部分内存占用尚不及一个现代浏览器标签页的典型消耗量。
六、当前稳定运行状态总结
目前,两套系统已在同一台Mac上稳定协同运行,分工明确:
- OpenClaw:作为主AI大脑,主要负责需要复杂推理链、长期规划和重型工具调用的任务。
- Hermes:作为辅助AI助手,主要负责日常对话交互、即时信息整理、定时提醒以及轻量级任务触发。
两者在资源分配上互不争夺,在功能上形成有效互补。如果你正在Mac上使用OpenClaw,完全可以放心地集成部署Hermes,以获得更立体的AI辅助体验。
写在最后
回顾整个配置过程,虽然历经三天的调试才打通所有环节,但核心障碍其实高度集中在两个关键点:模型配置参数的精确性与外部通信链路(如Telegram)的正确配对。一旦突破这两个技术瓶颈,后续的使用体验便十分顺畅。
如果你也计划在OpenClaw的基础上部署Hermes,希望这份详细的避坑指南能为你铺平道路。如果在实践过程中遇到新的问题,欢迎交流探讨。