Kimi注意力残差新架构:训练效率提升25%,高中生参与研发获马斯克点赞
💡 重构Transformer的记忆方式,在几乎不增加推理延迟的前提下,将训练成本降低约20%。
📌 核心亮点
3月16日,月之暗面Kimi团队发表了一篇题为Attention Residuals(注意力残差) 的研究论文。

命名虽显专业,但核心思路异常明快:
🧠 让模型学会“选择性记忆”,而不是把每一层信息都不加区分地叠加起来。
在Kimi自家的大模型上,该技术带来了可观的收益:
⚡ 训练效率提升25%(可节省约20%的算力与电力成本)
🐢 推理延迟增加不足2%,几乎不影响实际体验
📈 各项能力均获改善,尤其在数学推理和代码生成方面表现突出
更具吸引力的是,这套方案属于即插即用,无需调整原有模型架构的其他部分。
01
记忆负担:AI为什么要学会选择性关注
要理解这项技术,我们需要先看看当前模型是如何“记忆”信息的。
📚 从日常学习说起
假设你每天学习一些新知识:第一天学A,第二天学B,第三天学C……到了第100天,头脑中理应有A+B+C+……第100天的全部内容。
但如果每天的重要性完全相等,你将所有知识以“均匀”的方式刻入大脑,就会出现:
📉 早期知识(比如第一天的A)被后来大量信息所稀释,难以清晰回忆
🔍 想要定位某条具体知识时,需要在混杂的背景中费力搜索
🎒 记忆负担逐日加重,处理效率不断下滑
这正是当下AI模型面临的困境。
🏢 把模型看作一栋百层建筑
你可以将一个AI模型想象成一栋100层的大楼。信息从第1层进入,逐层向上传递,经过第2层、第3层……直至第100层,最终形成输出。每一层对信息做出加工,并将处理结果交给下一层。
传统的做法是:
第N层的输出 = 第N层的处理结果 + 第N-1层的输出
这样层层累加,似乎每一层都“记住”了前面所有层的特征。
乍看很理想,但两个问题随之而来:
📝 所有层的贡献被同等对待 — 就像把每天的日记都用相同的字号、相同的墨水记录下来,重要信息和琐碎细节混在一起,区分变得困难
📦 信息不断堆积 — 到了高处,早期输入已被稀释得所剩无几,想回溯最初的细节就需要付出极高代价
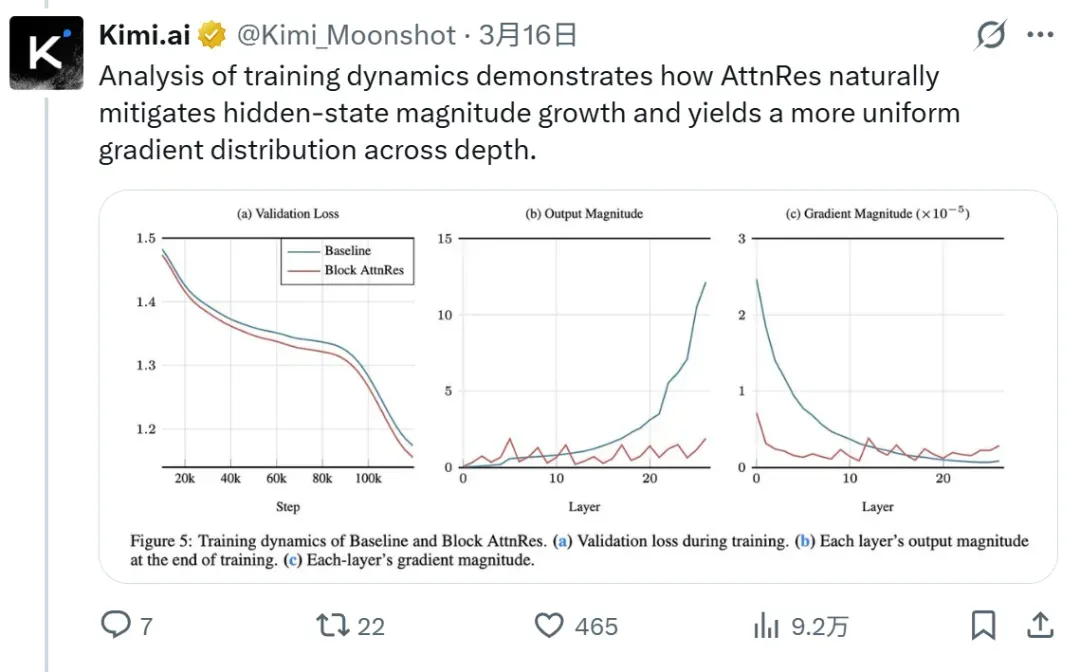
Kimi团队注意到,这种现象在学术界被称为“PreNorm Dilution”(预归一化稀释)。通俗地说,就是:信息被平均分配,导致关键部分难以凸显,不重要的内容却占用了大量容量。
02
解决方案:让模型自行决定“该记住什么”
团队的思路很直接:
✨ 既然“记住一切”会出问题,那就让网络自己学会决定哪些信息值得保留,哪些可以略过。
🎯 一个更贴近的类比
准备一次大考时,有两种复习策略:
❌ 传统方法:把教材从第一页背到最后一页,每一行都力求记住
✅ 高效策略:先梳理大纲,找出核心章节,对重点部分投入更多精力,次要内容快速浏览
显然,后者的效率远高于前者。
AttnRes(注意力残差)所做的,正是类似的选择性聚焦。
当第N层需要信息时,它不再简单地“把前面所有层的输出求和”,而是:
🤔 首先判断:“我现在最需要关注哪些信息?”
👀 然后“回望”之前的各个层
⭐ 对关键层赋予更高权重,对次要层降低权重
➕ 最后将这些层的信息加权聚合
用公式可以表达为:
第N层的输出 = 第1层×权重₁ + 第2层×权重₂ + … + 第N-1层×权重_{N-1}
这些权重是动态学习的,每一层、每个位置都会根据当前需求实时调整。
🔬 关键创新:把注意力延伸到深度维度
这里有一条非常巧妙的思想线索。
常规的注意力机制(Attention)最初是为了处理序列信息而设计的。比如在读“我爱吃苹果”时,注意力可以让模型在理解“苹果”这个词时,侧重关注“爱”和“吃”,减少对“我”的关注。
Kimi团队提出:
既然注意力可以用来关注“序列中的前面位置”,那为何不能用于关注“深度上的前面层”?
答案是可以的。
他们称之为“时间-深度对偶性”。用最直白的话来说就是:“关注前面的词”和“关注前面的层”,本质上属于同一类操作。
03
如何应对随之而来的计算压力?
新思路很快碰到了一个现实挑战。
如果模型有100层,每一层都要“回看”前面的99层…… 计算量将爆炸式增长。
这就像一个学生每学一个新知识点,都要把之前学过的所有内容重新翻看一遍 — 进度将难以为继。
📦 分块管理:用摘要来压缩历史
Kimi团队的做法是把100层分成大约8个块(block),每个块容纳若干层。
具体策略是:
📌 块内部依然沿用传统的累加方式,保持微观信息的连贯性
🗜️ 每个块结束时,将该块内的信息“压缩”为一个摘要表示
🎯 后续层只需要关注:各块的摘要 + 当前块内部的细节
通过这种块式组织,计算复杂度从“100层 × 100层”降到了“100层 × 8块”,大幅缓解了算力压力。
📝 再类比一次年终总结
- 笨办法:把365天的日记重新翻一遍
- 聪明办法:按月撰写总结,年终只需回顾12个月的摘要 + 最近的几天日记
Block AttnRes正是这种“先压缩、再聚焦”的智慧。
04
实际效果:是否经得起检验?
理论再动人,终究要用数据说话。
Kimi团队在自家大模型上展开了系统评测:
模型规模:480亿总参数,激活参数30亿
训练数据:1.4万亿词
对照对象:同等规模、未引入新技术的模型
🎯 关键数据一览
1. 训练效率提升25% 💰
在达到相同性能水准时,使用AttnRes的模型仅需原来80%的训练量。这意味着,假如一次大模型训练原本需要100万美元,引入这项技术后可以节省约20万美元。对于频繁进行大模型训练的企业来说,这是非常实在的成本削减。
2. 推理速度几乎无影响 🐢
很多人担心新技术会拖慢推理响应。实测结果是:延迟增加不到2% — 在实际应用中几乎感知不到。
3. 各维度能力均有增长 📈
| 能力类型 | 测试项目 | 提升幅度 |
| 综合知识 | MMLU | +1.1 分 |
| 复杂推理 | GPQA | +7.5 分 |
| 逻辑推理 | BBH | +1.7 分 |
| 数学 | MATH | +3.6 分 |
| 代码 | HumanEval | +3.1 分 |
| 中文 | C-Eval | +2.9 分 |
提升最显著的区域恰好落在复杂推理和代码生成上 — 这正好是AttnRes最擅长的跨层信息整合场景。因为复杂推理要求模型能够灵活检索不同层的特征,而注意力残差机制让网络以选择性方式关注关键层,自然在这一方向上取得突破。
05
17岁共同第一作者的故事
论文由37位作者共同完成,均来自Kimi团队。
最引人瞩目的,是共同第一作者中有一位17岁的高中生 — 陈广宇(Nathan)。
📖 他的成长轨迹
| 时间 | 事件 |
| 2024年初 | 才开始接触大模型,连Transformer为何物都不清楚 |
| 2024年2月 | 在北京一场中学生黑客松上展出“第三只机械手”项目,得到投资人关注 |
| 2024年中 | 加入青年培养计划,开始系统学习人工智能 |
| 2024年底 | 在GitHub上发布对技术博客的反思文章,被一家硅谷AI初创公司CEO注意到 |
| 2025年暑假 | 前往旧金山实习7周,负责一个涉及144张高端显卡的项目 |
| 2025年11月 | 正式加入月之暗面Kimi团队 |
| 2026年3月 | 以共同第一作者身份发表这篇影响力巨大的研究 |
🌟 推动他前进的力量
媒体报道总结出几条关键因素:
1. 从兴趣出发
最初他被Kimi的“高效注意力”技术吸引,觉得“很有趣”,然后开始自发探索。
2. 扎根底层
他并不满足于“怎么用”,而是深入研究“为什么这样设计”,甚至亲手写代码复现。
3. 遇到引路人
在成长路上,他获得了一些前辈的指导,包括投资人、研究者和工程师。
4. 持续深耕
从2024年初到2026年初,两年时间,他从一个对Transformer完全陌生的新手,成长为能参与核心研究的成员。
AI领域的门槛正在快速降低。只要真正投入兴趣并愿意下功夫,年轻一代同样有机会参与前沿技术的创造。
06
这项技术的意义
1. 动摇了屹立十年的“地基” 🏗️
自2017年Transformer架构诞生以来,残差连接一直是其基石之一。十一年来,很少有人去质疑这个底层设计。Kimi团队不仅提出了问题,还给出了可落地的答案。这提醒我们:即便是被普遍视为“理所当然”的基础构件,也可能存在巨大改进空间。关键在于保持追问与好奇。
2. 中国AI公司的底层创新 🇨🇳
过去有一种观点认为,国内AI公司更多集中在应用层创新,基础架构层面的突破相对较少。但本次工作在基础架构上做出了显著改进,并在arXiv等国际平台上发布。这说明中国AI公司在底层研究上的投入正在产出实质成果。
3. 效率提升的商用价值 💰
25%的训练效率提升,数字上看或许不够“炸裂”,但放在大模型训练的巨额成本背景下,这是实打实的经济收益。而且该技术“即插即用”,其他团队可以直接复用,无需重新构建整个模型,进一步加速了技术扩散。
07
可以延伸的思考
你不必是AI从业者,也能从这项技术的思路中获得启发。
1. 练习“选择性关注” 🎯
正如AttnRes让模型学会选择性记忆,我们也可以:
不是每条信息都值得投入同等精力,对重要事项多花时间,对次要内容快速略过
定期对知识和经历进行“压缩总结”,减轻认知负荷
2. 质疑“理所当然” ❓
残差连接被众星捧月般使用了十一年,所有人都觉得原本就该这样。但Kimi团队问了一个简单的问题:“为什么一定要这样?” 在工作与生活中,我们也值得多问:“目前的做法,真的是最优解吗?”
3. 年轻人拥有入局机会 🚀
17岁共同一作的事例告诉我们:
年龄从来不是绝对的障碍
关键是找到正确的方向并持续钻研
主动动手与深度思考远比被动接收课程更有力量
4. 效率永远值得追求 ⚡
无论是在模型训练还是日常工作中,效率提升都能释放出时间与精力,让你投入到更有价值的事情上。
08
研究资源
如果你想进一步探索这项技术:
📄 arXiv 论文:https://arxiv.org/abs/2603.15031
💻 GitHub 仓库:https://github.com/MoonshotAI/Attention-Residuals
📥 PDF 直接下载:https://github.com/MoonshotAI/Attention-Residuals
✨ 最后一点思考
这项技术的本质可以用一句话归纳:
🧠 让AI学会聪明地记忆,而不是机械地累加。
它既是底层架构的一次进化,也是一种思维方式的映照。
留一个问题给你: 💭 如果“残差连接”都可以被重新设计,那么我们在日常工作、学习中那些习以为常的流程和习惯,又有哪些值得被重新审视?
下一个效率跃迁的契机,很可能就藏在这些往日的理所当然之中。
📚 参考资料:
arXiv:2603.15031 Attention Residuals 技术论文
GitHub: MoonshotAI/Attention-Residuals 官方代码库
多家科技媒体报道