Lasso回归量化交易全攻略:从因子筛选到实战建模
量化交易挑战:因子爆炸与 Lasso 回归的应对之道
在量化交易的领域内,研究人员与实战者每日都需要处理规模庞大的因子集合。从经典的市盈率指标、移动平均收敛发散指标,到精密的量价关系因子、资金流向指标,乃至基于高频数据生成的微观结构因子,因子的数量时常达到数百甚至数千个。这些因子仿佛迷宫中的众多路径——过量的选择反而容易让模型陷入困惑:冗余的因子会引发过拟合问题(模型在历史数据上表现优异,但在实际交易中效果糟糕),高度相关的因子会干扰模型的判断精度,而结构复杂的模型则难以理解,通常也无法通过严格的风险控制审查。
应对“因子数量激增”这一难题,我们迫切需要一种能够从大量候选变量中识别出关键特征,同时维持模型简洁度的有效方法。Lasso 回归(即 L1 正则化线性回归)正是为此目标而设计。它的核心优势在于:在建立预测模型的过程中,能够自动将那些不重要的因子系数“压缩”至零,从而实现“一边建模,一边筛选”的高效流程。这一特性使得 Lasso 回归在量化交易中展现出广泛的应用潜力,无论是在因子挖掘、投资组合构建,还是在风险管理环节,都能提供独特的价值。
Lasso 回归解析:自动特征选择的线性模型
要掌握 Lasso 回归的原理,我们可以从最基础的线性回归模型开始回顾。线性回归的核心目标是:寻找到一组最优的“权重”(即回归系数),使得多个因子(自变量)的线性组合能够最大限度地逼近目标变量(例如股票的未来收益率)。举例来说,如果我们试图通过成交量、波动率等因子来预测股票收益,线性回归会给出类似“成交量每上升 1%,收益平均变动 X%;波动率每增加 1%,收益平均变动 Y%”的量化关系。
然而,传统的线性回归存在一个明显的缺陷:当输入因子数量过多时,它会“全盘接收”所有变量,甚至可能为那些预测能力微弱的因子分配不合理的权重。这好比烹饪时将所有调味料都加入锅中,反而掩盖了食材的本味——模型会过度拟合历史数据中包含的随机噪声,导致其对未来走势的预测能力大幅下降。
Lasso 回归的改进方法十分巧妙:它在标准线性回归的损失函数基础上,额外引入了一个“正则化惩罚项”。这个惩罚机制就像一位严格的审计员,会对每个因子权重的绝对值“征税”——权重绝对值越大,所需缴纳的“税费”就越高。为了最小化总的损失(包括拟合误差和惩罚项),模型会主动将那些贡献度较低的因子权重压缩至零(相当于将这些因子从模型中彻底剔除),只保留少数真正具有预测影响力的核心因子。
简而言之,普通线性回归倾向于“做加法”(尽可能纳入所有因子),而 Lasso 回归则善于“做减法”(自动筛选出关键因子)。这种“自主精简”的能力,使其特别适合处理量化交易中常见的“因子过剩”问题。
Lasso 回归在量化交易中的三大应用场景
在整个量化交易的流程链条中,Lasso 回归所具备的“特征自动选择”能力可以在多个关键环节发挥重要作用:
第一,因子筛选:从海量指标中“沙里淘金”。 量化研究通常涉及大量技术指标(如 MACD、RSI)、基本面数据(如市盈率 PE、净资产收益率 ROE)以及资金流数据(如大单净流入比例)来构建成百上千个候选因子。但并非所有这些因子都具备稳定的预测价值,其中一部分可能仅是随机噪音。Lasso 回归能够通过检查回归系数是否为零,快速识别出对目标变量(例如未来收益率)有显著影响的因子子集。例如,在后续的代码演示中,我们计算了股票的全部常见技术指标,然后利用 Lasso 自动剔除了系数为零的指标,显著提升了后续分析效率。
第二,多因子模型构建:简化模型结构,增强预测稳定性。 多因子模型是量化选股的核心框架,但其性能经常受到因子之间冗余和相关性的负面影响。例如,如果同时将“5 日收益率”和“10 日收益率”纳入模型,由于两者高度相关,会导致模型估计的权重不稳定且难以解释。Lasso 回归会主动移除这些冗余因子,保留少数独立且有效的预测变量,从而使模型更加简洁、可解释性更强。在实际交易系统中,结构简洁的模型更易于持续跟踪和维护,也能降低由参数频繁波动带来的操作风险。
第三,风险控制:识别并聚焦关键风险驱动因子。 投资组合的净值波动往往受到多种风险因子的共同影响(例如市场整体风险、行业板块风险、流动性风险等)。Lasso 回归可以帮助识别出对组合波动贡献最大的少数几个风险因子,从而指导投资者进行针对性的风险对冲。例如,通过 Lasso 回归分析投资组合净值变化与一系列风险因子的关系,如果发现“市场波动率指数(VIX)”的系数显著不为零且绝对值较大,则表明该因子是组合风险的主要来源之一,可以考虑使用期权等衍生工具进行对冲。
实战演示:使用 Lasso 回归筛选股票预测因子
下面将结合具体的代码示例,详细阐述如何运用 Lasso 回归在 A 股市场中筛选影响股价收益的关键因子(以中国平安股票为例)。以下是完整的代码逻辑与核心步骤解读:
步骤一:数据准备——获取股价数据并构建预测目标变量
import numpy as np
import pandas as pd
from sklearn.linear_model import LassoCV
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import TimeSeriesSplit
import statsmodels.api as sm
from statsmodels.regression.linear_model import OLS
from statsmodels.stats.outliers_influence import variance_inflation_factor
from scipy import stats
import matplotlib.pyplot as plt
import pandas_ta as ta
import warnings
warnings.filterwarnings("ignore")
import qstock as qs # 用于获取A股市场数据
# 获取中国平安2020年至2025年的历史行情数据
df0 = qs.get_data('中国平安', start='2020-01-01', end='2025-07-17')
# 构建目标变量:下一期的5日收益率(即需要预测的对象)
df0['target_return'] = df0['close'].pct_change(5).shift(-1)
df0 = df0.dropna() # 删除包含缺失值的行
- 将目标变量设定为“下一期5日收益率”,这符合量化交易中预测未来短期收益的实际需求。
- 删除缺失值是为了确保后续模型训练过程的顺利进行,避免程序报错。
步骤二:因子生成——批量计算各类技术分析指标
- 关于使用 pandas_ta 库生成技术指标的详细方法,可参考相关技术文档。
# 复制原始数据框并计算所有可用的技术指标
df1 = df0.copy()
df1.ta.strategy('all', verbose=True) # 一次性生成MACD、RSI、布林带等所有技术指标
df_clean = df1.dropna(axis=1) # 剔除所有值均为缺失值的指标列
[+] Strategy: All
[i] Indicator arguments: {'append': True}
[i] Excluded[12]: above, above_value, below, below_value, cross, cross_value, long_run, short_run, td_seq, tsignals, vp, xsignals
[i] Multiprocessing 131 indicators with 3 chunks and 16/16 cpus.
131it [00:05, 24.31it/s]
[i] Total indicators: 131
[i] Columns added: 218
[i] Last Run: Sunday July 20, 2025, NYSE: 17:09:14, Local: 21:09:14 中国标准时间, Day 201/365 (55.00%)
- 使用 pandas_ta 库的
strategy('all')功能一键生成所有常见技术指标,以此模拟真实研究中面临的“因子数量爆炸”场景。 - 剔除全部为缺失值的指标列,是为了减少无效的数据处理计算。
步骤三:模型构建——应用 Lasso 回归与时间序列交叉验证
# 划分特征矩阵(X)与目标变量向量(y)
X = df_clean.iloc[:,10:] # 选取第10列之后的所有技术指标作为特征
y = df_clean['target_return']
# 设置时间序列交叉验证(避免未来信息泄露)
tscv = TimeSeriesSplit(n_splits=5) # 按时间顺序将数据拆分为5折(前4折用于训练,最后1折用于验证)
# 构建处理管道:先标准化,再执行 LassoCV(自动选择最优正则化强度)
pipeline = Pipeline([
('scaler', StandardScaler()), # 标准化:Lasso回归对特征的数值尺度敏感
('lasso', LassoCV(
alphas=np.logspace(-6, 2, 100), # 设置候选的正则化参数范围
cv=tscv, # 使用时间序列交叉验证
max_iter=10000,
random_state=42
))
])
# 训练 Lasso 回归模型
pipeline.fit(X, y)
- 关键细节:使用
TimeSeriesSplit而非普通的随机交叉验证,因为股票数据具有严格的时间顺序依赖性(不能用未来的数据预测过去),必须模拟真实的滚动预测场景。 - 特征标准化是必要步骤:由于 Lasso 施加的惩罚项受特征自身数值大小影响(例如“成交量”的原始数值可能很大,若不标准化会承受不成比例的巨大惩罚),标准化能确保所有特征在平等的基础上被评估。
步骤四:因子验证——从统计显著性检验到共线性诊断
Lasso 初步筛选出的系数非零因子,还需要通过进一步的统计检验来验证其可靠性:
# 提取 Lasso 模型筛选后系数不为零的因子
coefs = pipeline.named_steps['lasso'].coef_
non_zero_mask = coefs != 0
selected_features = X.columns[non_zero_mask]
non_zero_coefs = coefs[non_zero_mask]
print(f"\n初步筛选后保留的特征数量: {len(selected_features)}")
# 执行统计显著性检验
print("\n正在进行统计显著性检验...")
significant_features = []
p_values = []
t_values = []
coef_values = []
# 准备数据用于标准的 OLS 回归,以获取统计量
X_selected = X[selected_features]
X_selected = sm.add_constant(X_selected) # 添加截距项
# 使用 Newey-West 方法调整标准误,以处理时间序列可能存在的自相关
model = OLS(y, X_selected)
results = model.fit(cov_type='HAC', cov_kwds={'maxlags': 5})
# 提取并评估每个特征的统计结果
for i, feature in enumerate(selected_features, start=1): # 从1开始,跳过索引0的常数项
p_value = results.pvalues[i]
t_value = results.tvalues[i]
coef_value = results.params[i]
if p_value < 0.05: # 在95%的置信水平下判断显著性
significant_features.append(feature)
p_values.append(p_value)
t_values.append(t_value)
coef_values.append(coef_value)
print(f"{feature}: 系数={coef_value:.4f}, t统计量={t_value:.2f}, p值={p_value:.4f}")
print(f"\n通过统计显著性检验的特征数量: {len(significant_features)}")
# 进行多重共线性诊断
print("\n多重共线性诊断(方差膨胀因子 VIF):")
vif_data = []
for i, feature in enumerate(significant_features):
vif = variance_inflation_factor(X[significant_features].values, i)
vif_data.append(vif)
print(f"{feature}: VIF={vif:.2f}")
初步筛选后保留的特征数量: 27
正在进行统计显著性检验...
AMATe_SR_8_21_2: 系数=-0.0045, t统计量=-1.99, p值=0.0461
OBV: 系数=0.0000, t统计量=2.19, p值=0.0282
CDL_DOJI_10_0.1: 系数=0.0001, t统计量=2.45, p值=0.0141
LDECAY_5: 系数=0.0128, t统计量=2.74, p值=0.0061
HA_open: 系数=-0.0252, t统计量=-10.61, p值=0.0000
PVR: 系数=0.0035, t统计量=3.83, p值=0.0001
SUPERTd_7_3.0: 系数=0.0042, t统计量=4.31, p值=0.0000
TTM_TRND_6: 系数=0.0054, t统计量=4.69, p值=0.0000
通过统计显著性检验的特征数量: 8
多重共线性诊断(方差膨胀因子 VIF):
AMATe_SR_8_21_2: VIF=4.48
OBV: VIF=2.58
CDL_DOJI_10_0.1: VIF=1.16
LDECAY_5: VIF=4356.41
HA_open: VIF=4464.27
PVR: VIF=7.10
SUPERTd_7_3.0: VIF=1.14
TTM_TRND_6: VIF=2.42
- p 值检验:用于确保因子的预测效果不太可能是由随机偶然性导致的(p值小于0.05通常表示在95%的置信水平下该因子有真实影响)。
- VIF(方差膨胀因子)诊断:用于检测因子间的多重共线性。VIF 值大于10通常表明因子之间高度相关,这会扭曲回归系数的估计,需要进一步处理或剔除。
步骤五:结果可视化——直观展示筛选因子的重要性排序
# 创建汇总结果的 DataFrame
results_df = pd.DataFrame({
'Feature': significant_features,
'Coefficient': coef_values,
't-value': t_values,
'p-value': p_values,
'VIF': vif_data
})
# 添加基于系数绝对值的特征重要性排序
results_df['Abs_Coefficient'] = np.abs(results_df['Coefficient'])
results_df = results_df.sort_values('Abs_Coefficient', ascending=False)
# 可视化特征重要性
plt.figure(figsize=(12, 8))
plt.barh(results_df['Feature'], results_df['Abs_Coefficient'])
plt.xlabel('系数绝对值')
plt.title('特征重要性排序 (经Lasso筛选且统计显著)')
plt.gca().invert_yaxis() # 将最重要的因子显示在顶部
plt.tight_layout()
plt.savefig('feature_importance.png', dpi=300)
plt.show()
# 保存最终筛选出的因子数据
df_selected = df_clean[['close', 'target_return'] + significant_features].copy()
print("\n最终筛选结果已保存至变量 df_selected")
# 输出完整的特征选择结果表格
print("\n最终特征选择结果详情:")
print(results_df[['Feature', 'Coefficient', 't-value', 'p-value', 'VIF']])
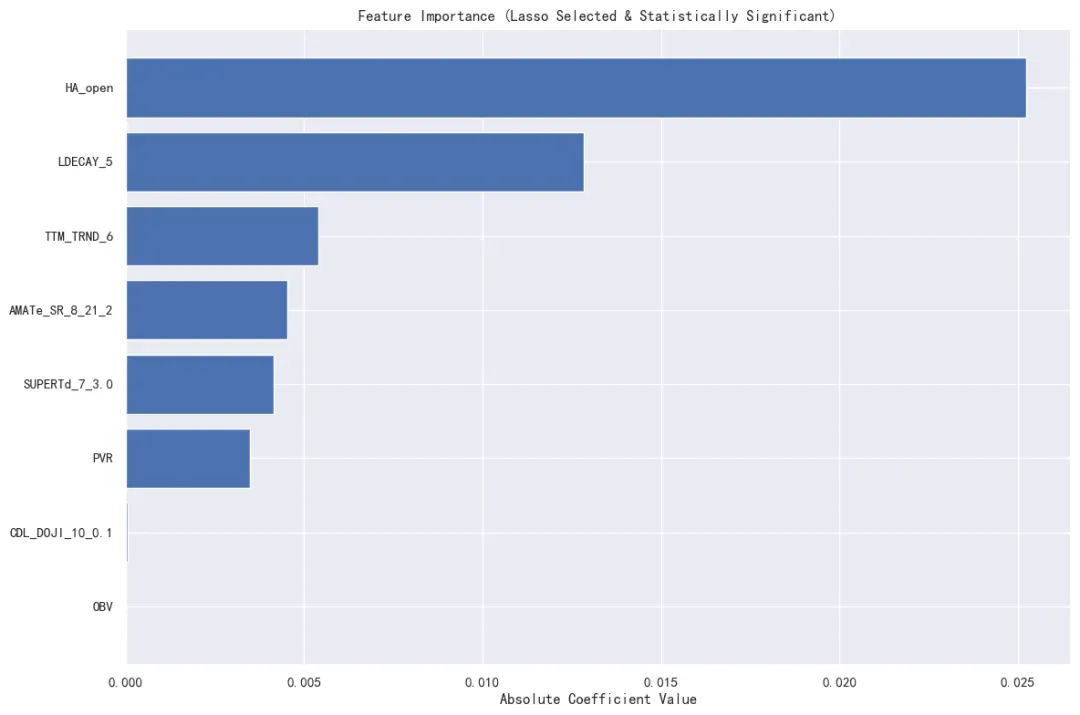
最终筛选结果已保存至变量 df_selected
最终特征选择结果详情:
Feature Coefficient t-value p-value VIF
4 HA_open -2.522249e-02 -10.608727 2.714229e-26 4464.273023
3 LDECAY_5 1.283205e-02 2.743989 6.069751e-03 4356.405675
7 TTM_TRND_6 5.405516e-03 4.686776 2.775418e-06 2.418098
0 AMATe_SR_8_21_2 -4.544720e-03 -1.994725 4.607293e-02 4.483580
6 SUPERTd_7_3.0 4.153977e-03 4.314576 1.599095e-05 1.136135
5 PVR 3.482774e-03 3.831917 1.271484e-04 7.104271
2 CDL_DOJI_10_0.1 6.713647e-05 2.454005 1.412752e-02 1.163486
1 OBV 3.984477e-10 2.194195 2.822136e-02 2.577751
总结:Lasso 回归的价值与局限性
Lasso 回归凭借其“自动特征选择”的内在机制,为量化交易中的因子处理提供了强有力的高效工具:它能够从海量的候选因子中快速锁定关键变量,简化模型结构,并增强模型在实际应用中的稳定性。在上述代码示例中,我们完整演示了从因子批量生成到最终统计验证的完整流程,实证了 Lasso 回归在股票收益率预测任务中的实用价值。
然而,必须认识到 Lasso 回归并非解决所有问题的“万能钥匙”。它存在一定的局限性:当多个输入因子之间存在高度相关性时,Lasso 可能会随机地选择其中一个进入模型,而非理论上最优的那个;此外,其纯数据驱动的筛选结果,仍需结合金融先验知识与经济逻辑(例如理解“换手率”因子背后的市场含义)进行交叉验证,以避免陷入过度依赖数据挖掘的陷阱。
在实际的量化策略开发中,建议采用融合的方法:首先利用 Lasso 回归强大的筛选能力快速缩小候选因子范围,然后借助领域专业知识对筛选出的因子进行逻辑合理性评估,最终构建起“数据驱动与逻辑支撑并重”的稳健量化模型。量化交易的核心智慧在于“在不确定性中寻找确定性模式”,而 Lasso 回归,正是帮助我们拨开重重因子迷雾、聚焦于核心市场规律的得力工具之一。