NAS部署VideoCaptioner:字幕识别与翻译工具完整教程
VideoCaptioner是一款基于大语言模型(LLM)的视频字幕处理工具,它能够通过API或本地离线方式进行语音识别,并利用大语言模型实现字幕的智能断句、校正与翻译。该工具支持从字幕生成到视频处理的全流程一键操作,为用户提供便捷的字幕解决方案。

需要提醒的是,电脑版VideoCaptioner提供了更全面和丰富的功能,而Docker版本在功能上相对有限,更适合轻量级使用场景。
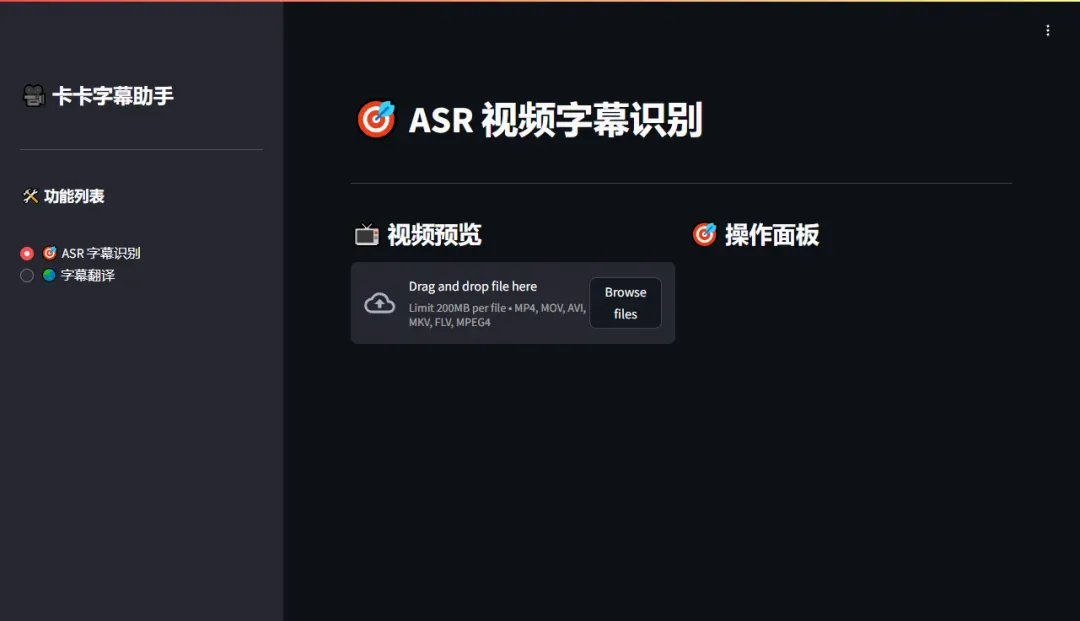
部署VideoCaptioner
使用Docker Compose可以快速部署VideoCaptioner。以下是一个基本的配置示例:
services:
video-captioner:
image: ywsj/video-captioner:latest
container_name: video-captioner
ports:
- 8501:8501
volumes:
- ./temp:/app/temp
restart: always
在配置中,可以通过环境变量设置OpenAI相关参数,例如OPENAI_BASE_URL和OPENAI_API_KEY,这些参数为可选项,用于连接外部API服务。建议查阅官方文档以获取更多高级配置选项。
使用VideoCaptioner
部署完成后,在浏览器中访问http://NAS的IP:8501即可打开VideoCaptioner的操作界面。
界面支持深色模式切换,便于在不同光线环境下使用。
首先点击“上传视频”按钮,选择需要处理的视频文件。注意视频文件大小不能超过200MB,以确保处理效率。
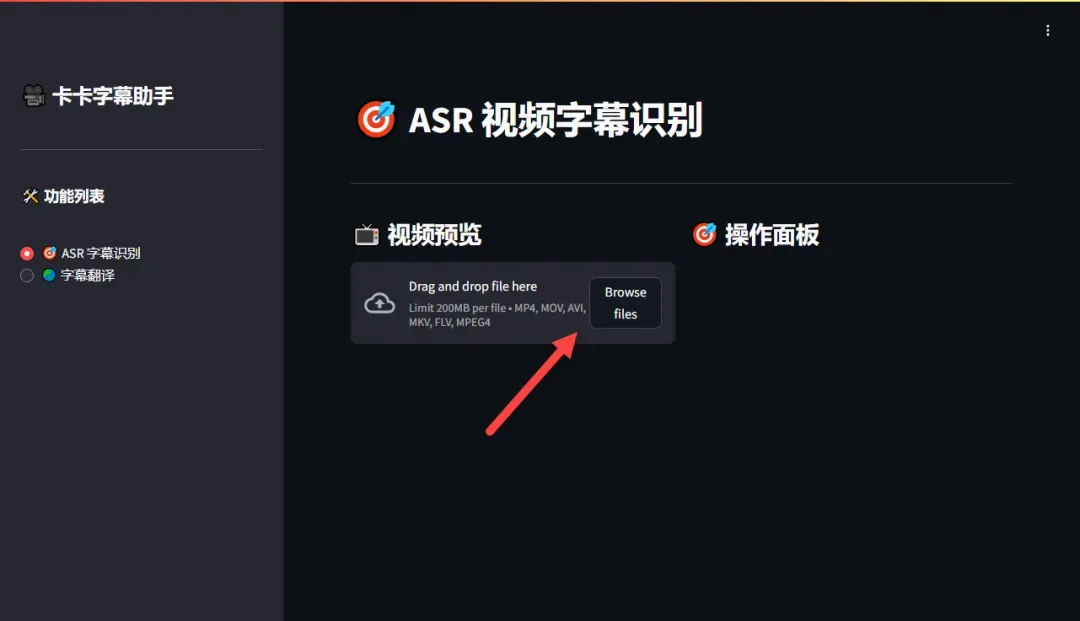
视频上传成功后,点击“开始识别”按钮,工具将自动进行语音识别和字幕生成。
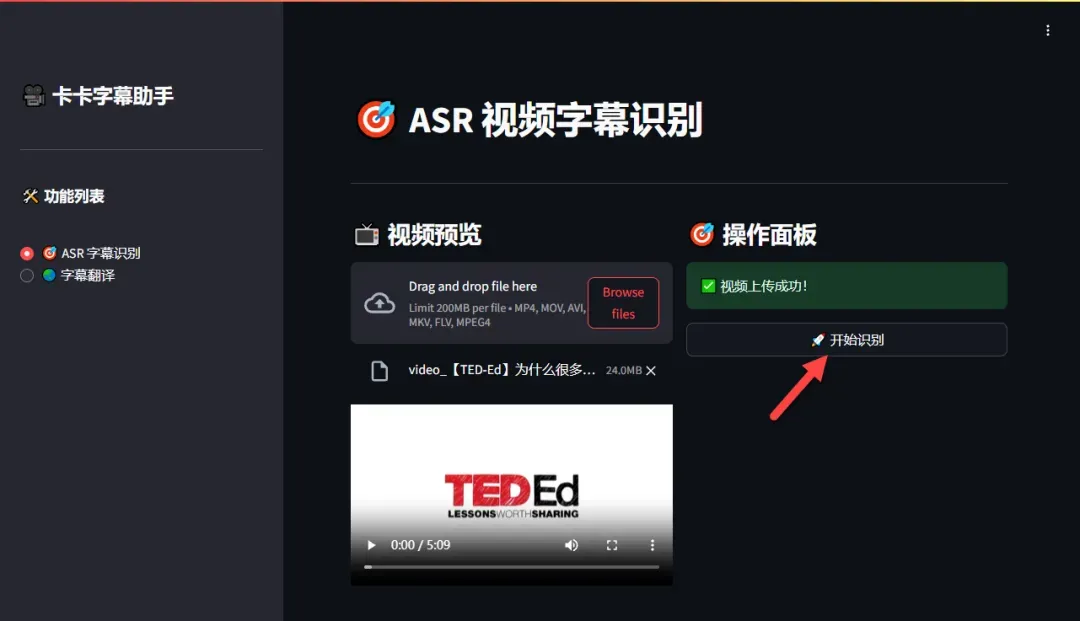
处理过程中资源消耗较低,即使是本地运行也能高效完成任务。
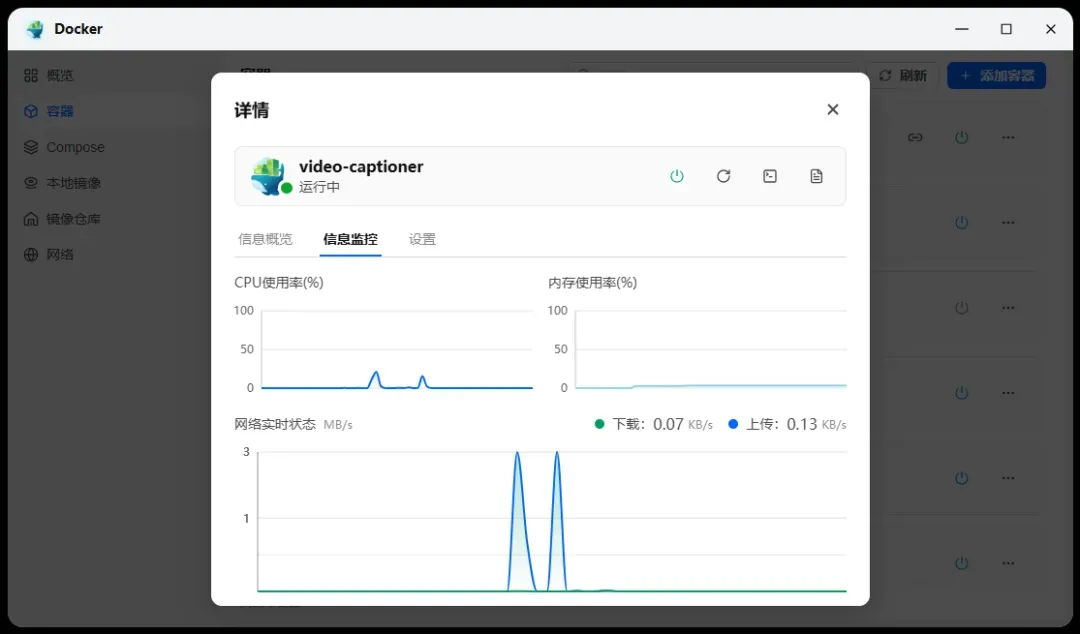
对于较短的视频,字幕识别通常在几秒钟内即可完成,结果会实时显示在界面上。
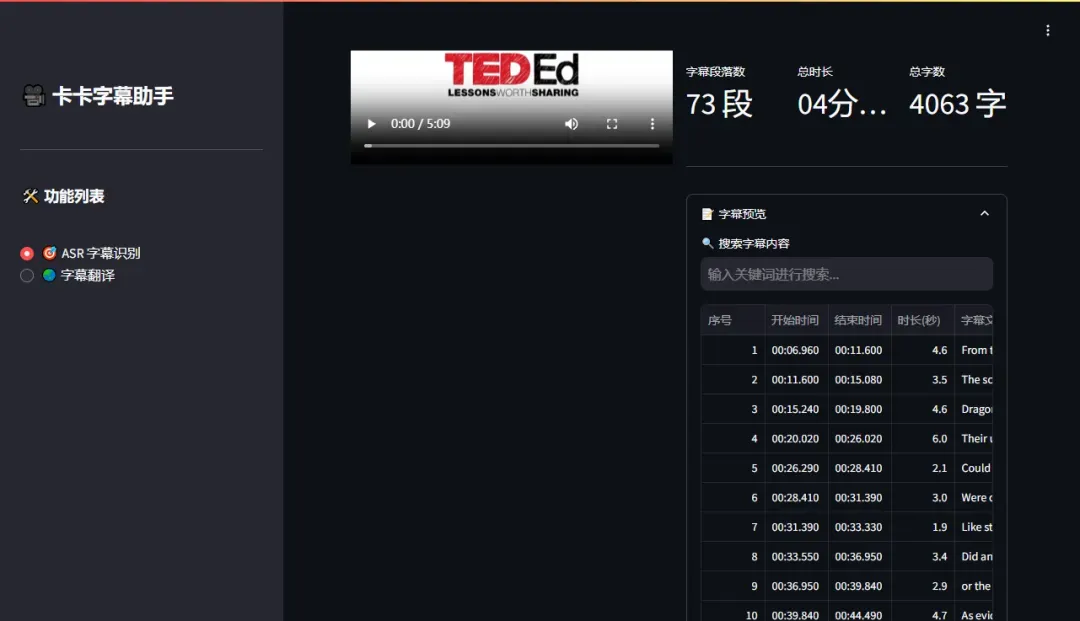
识别完成后,滑动到页面下方,点击“下载字幕文件”按钮,即可保存生成的字幕文件。
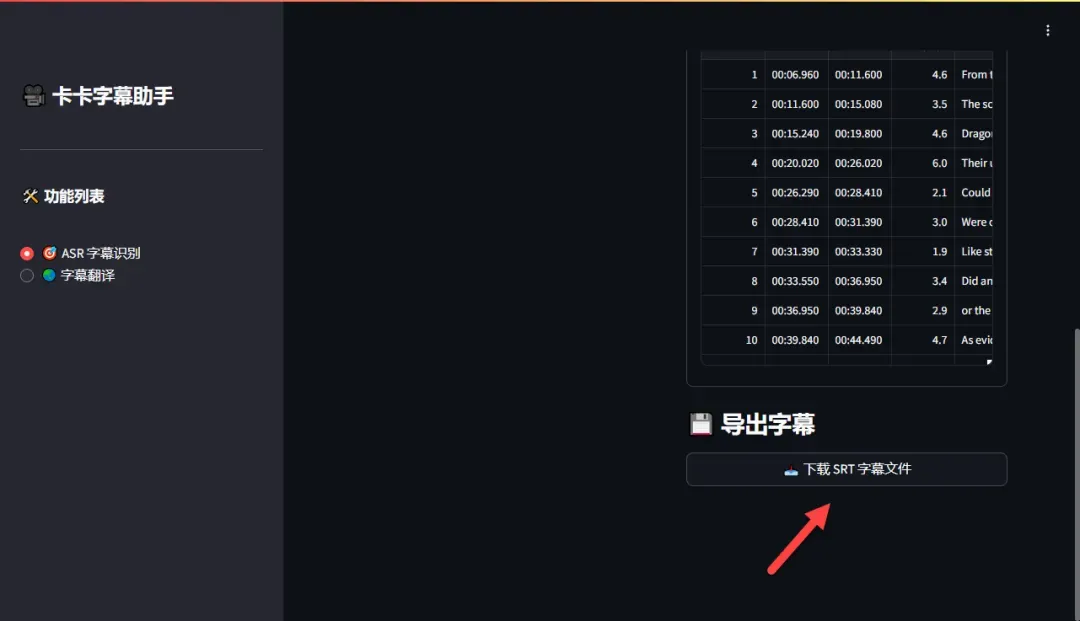
生成的字幕准确度较高,能够满足日常使用需求。

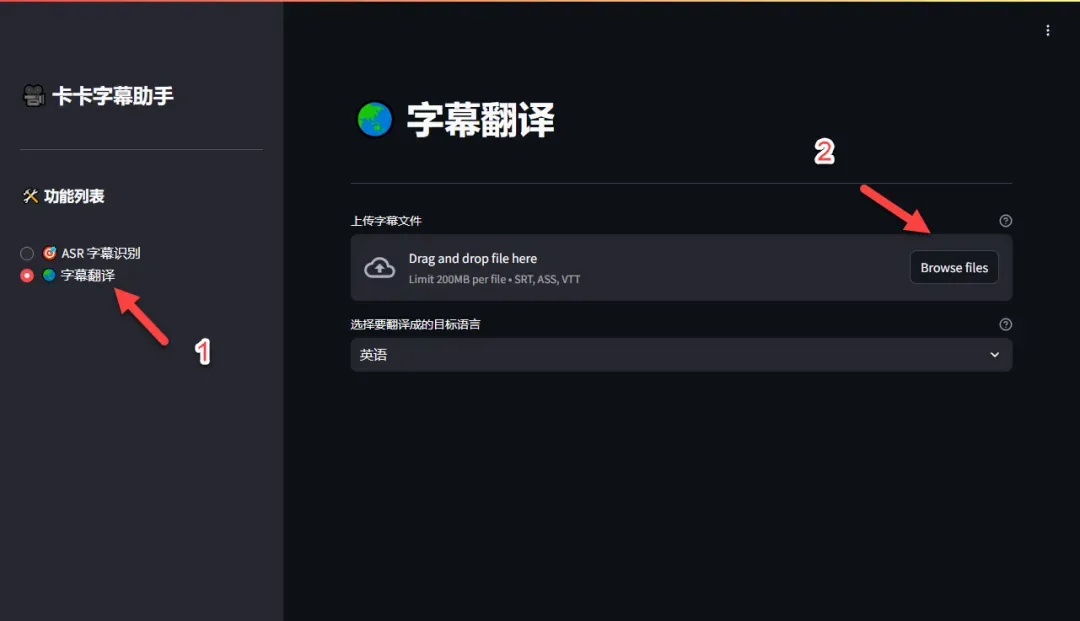
接下来切换到“字幕翻译”功能,上传之前下载的字幕文件。
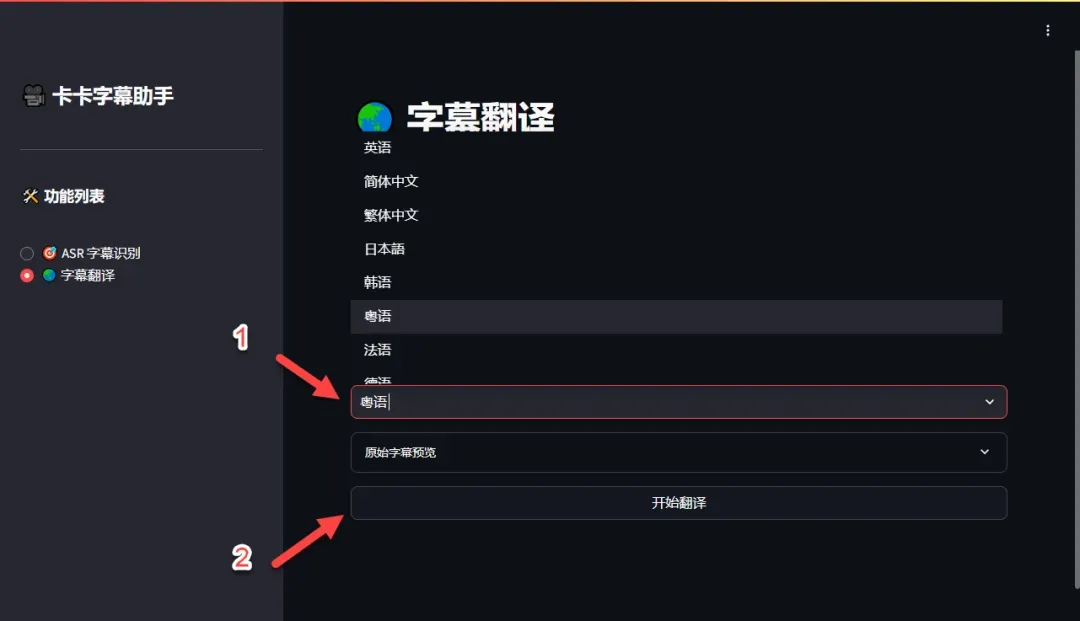
选择目标翻译语言,例如粤语或其他方言,然后点击“开始翻译”按钮。
翻译过程非常迅速,几乎瞬时完成,且翻译结果自然地道。
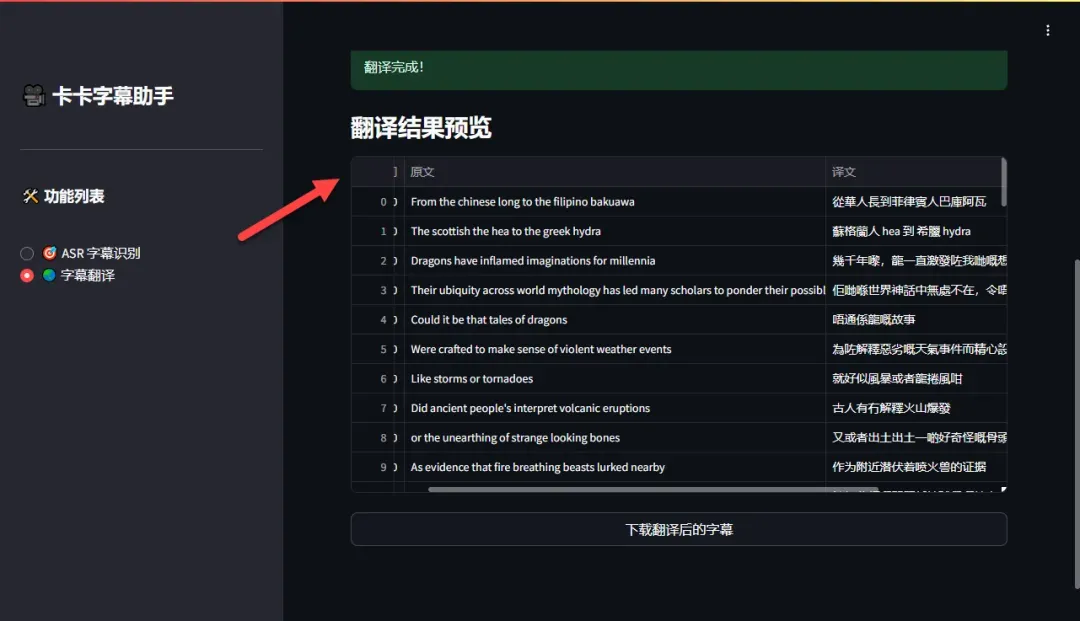
确认翻译无误后,点击“下载字幕”按钮保存翻译后的字幕文件。
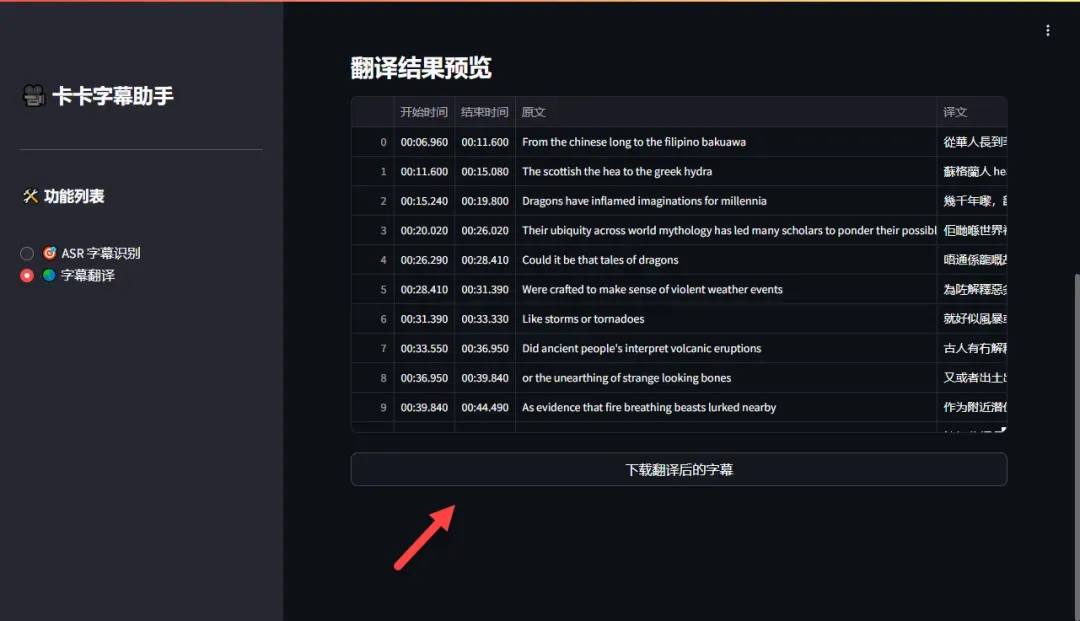
翻译后的字幕支持双语显示,方便对照查看。

总结与推荐
VideoCaptioner作为一个视频字幕处理项目,在电脑版上表现优秀,功能全面。然而,Docker版本的功能相对较少,且维护更新可能不够频繁。尽管如此,对于处理小体积视频并需要快速翻译的用户而言,Docker版本仍然是一个可行的选择,因为它资源消耗低、处理速度快。
综合推荐:⭐⭐⭐(适用于小体积视频的快速翻译)
使用体验:⭐⭐⭐(功能较为基础,期待后续增强)
部署难度:⭐⭐(配置简单易上手)