OpenClaw系统架构深度解析:一条消息如何触发多Agent协作执行链路
在上一篇文章中,我们探讨了OpenClaw项目的工程价值。今天,我们将深入技术源头,剖析这个智能体(Agent)系统的实现机制,并厘清它与其他同类系统的本质区别。
为了避免按功能模块介绍可能带来的零散感,我们将回归最根本的问题进行审视:
当用户发送一条真实消息时,OpenClaw这套多Agent系统内部,究竟是如何运转的?
深入理解这一执行链路,其重要性远超表面认知。当你完整追踪一条消息从输入到输出的全过程,便会发现OpenClaw与普通聊天机器人、传统工作流系统,以及众多仅具备基础工具调用能力的Agent框架之间的差异,并非在于其对话能力,而在于其背后一整套严密、完整的运行时链路:
消息接收、协议适配、路由分发、会话隔离、上下文组装、技能注入、流式执行、工具调用、持久化存储,以及在处理复杂任务时所依赖的多Agent协作机制。
为了更清晰地阐述,我们假设一个典型业务场景:
用户在钉钉中发送如下指令:
“帮我整理今天的重要邮件,提炼待办事项,并生成一份给老板的简报。”
接下来,我们将跟随这条消息的足迹,探索它如何从外部世界的一段文本,最终被转化并执行为一套结构化的任务链路。
建议读者在阅读时思考以下三个核心问题:
- OpenClaw的整体架构设计哲学是什么?
- 一条消息在系统中经历怎样的完整执行路径?
- 其宣扬的多Agent协作机制在实际中如何落地实现?
OpenClaw是如何运行的
初次接触OpenClaw,很容易将其理解为一种能够跨平台聊天、调用工具并执行任务的智能助手。然而,从工程实现视角看,OpenClaw更像是一个围绕智能体(Agent)构建的运行时网关系统(Agent Runtime)。
它并非简单地将用户输入抛给大语言模型(LLM)并直接返回输出,而是将整个处理过程拆解为一条清晰的执行链路,并在每个关键节点实施了严格的工程治理。
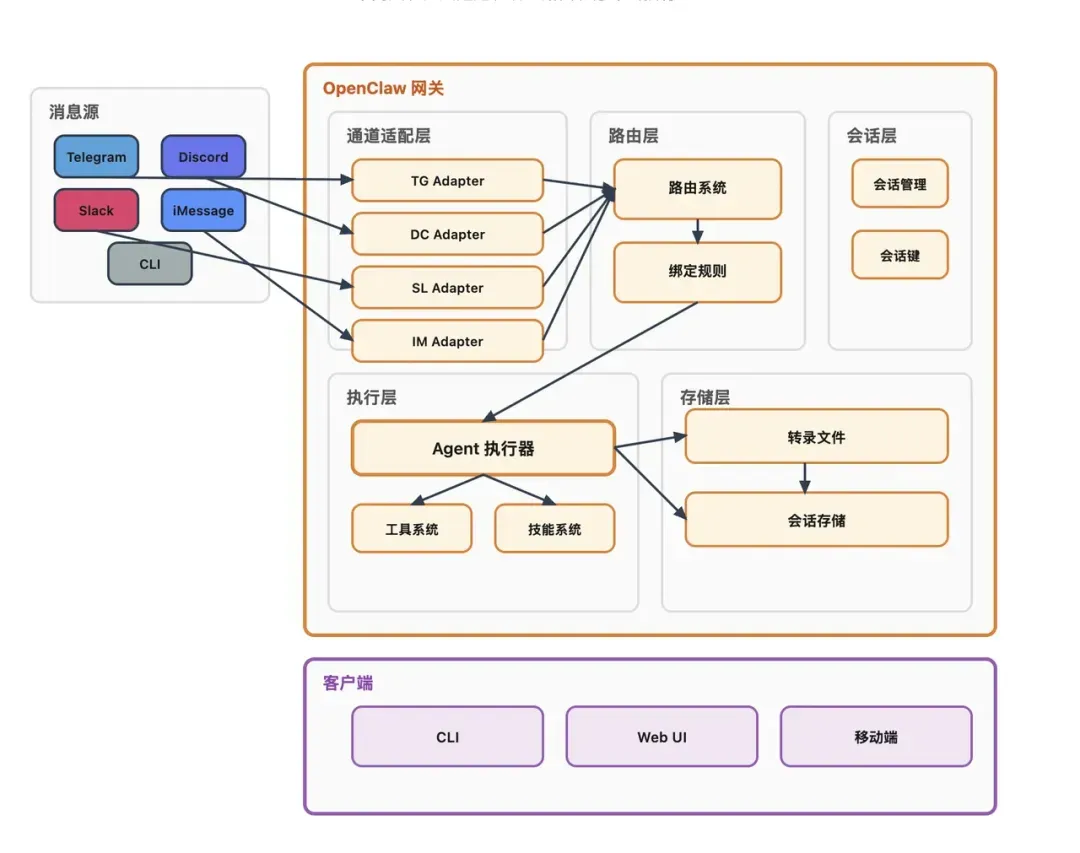
其整体架构可抽象为五个层次:
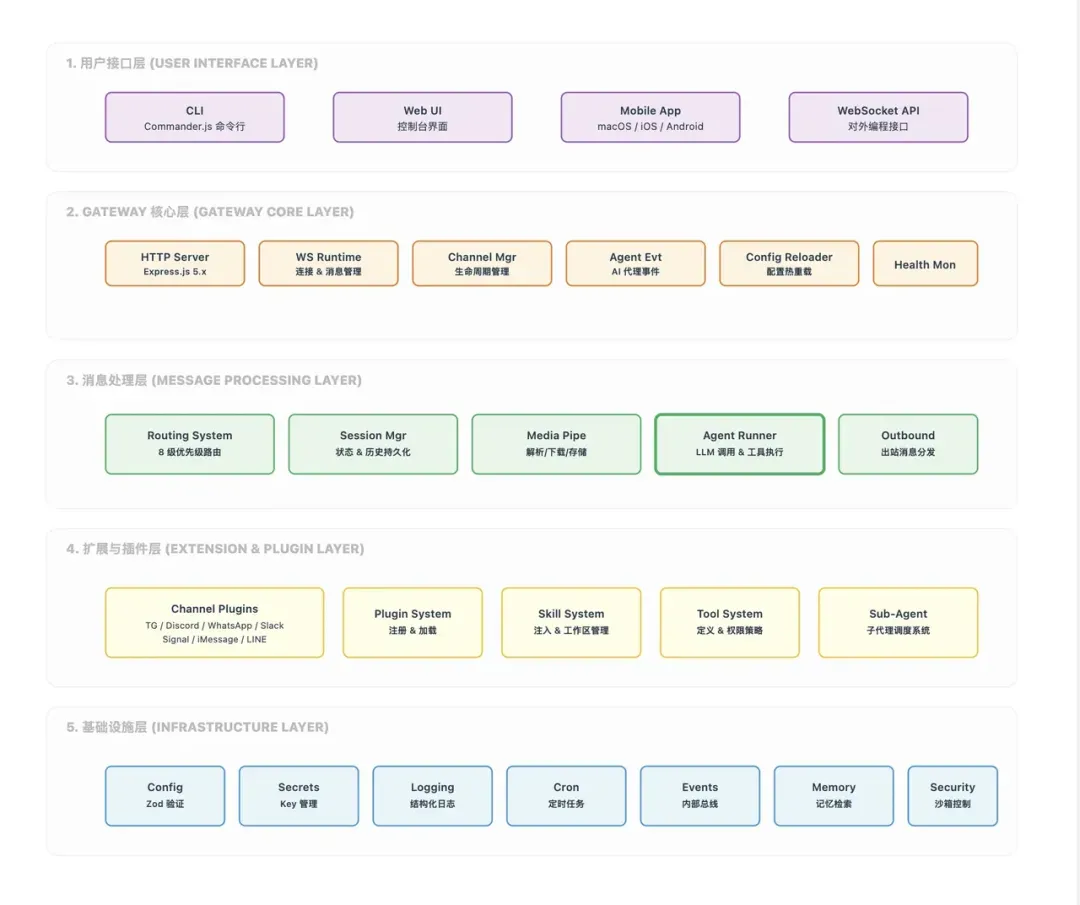
第1层:用户接口层
提供包括命令行界面(CLI)、Web界面、移动应用、WebSocket API在内的多种入口,旨在将用户操作统一转换为内部请求格式。对用户而言,操作可能是在网页中输入一句话或在钉钉、飞书中发送消息;但对系统而言,所有入口最终都将收敛于统一的内部消息模型。
第2层:网关核心层
作为OpenClaw的核心运行时,该层负责连接管理、请求接入、配置热加载、健康监控等基础治理工作。简而言之,确保整个系统能够常驻运行、接收并响应消息、维持会话状态的,并非单个Agent,而是这个网关层。
第3层:消息处理层
此处是业务逻辑真正流转的核心地带,主要组件包括:
- Agent执行器
- 路由系统
- 会话管理器
- 媒体处理器
- 出站消息投递模块 从消息进入系统到最终产生响应,最核心的执行动作都发生在此层。
第4层:扩展与插件层
所有可插拔的扩展功能均集中于此:
- 通道插件,用于对接钉钉/飞书、Telegram、WhatsApp、Slack等外部平台。
- 技能与工具系统。
- 子Agent(sub-Agent)协作机制。 正是得益于这一层的设计,OpenClaw才能够持续接入新通道、扩展新工具,并在内部实现复杂的多Agent协作。
第5层:基础设施层
该层为整个系统提供通用支撑能力,涵盖:
- 配置与密钥管理
- 结构化日志记录
- 定时任务调度
- 事件总线通信
- 记忆检索服务
- 沙箱安全隔离 虽然日常不显眼,但若缺乏这一层的支持,上层架构将难以稳定运行。
从数据流转视角审视,一条消息的完整路径非常清晰:
消息源 → 协议适配 → 路由分发 → 会话构建 → Agent执行 → 响应投递 → 状态持久化
接下来,我们将沿此路径逐步深入。
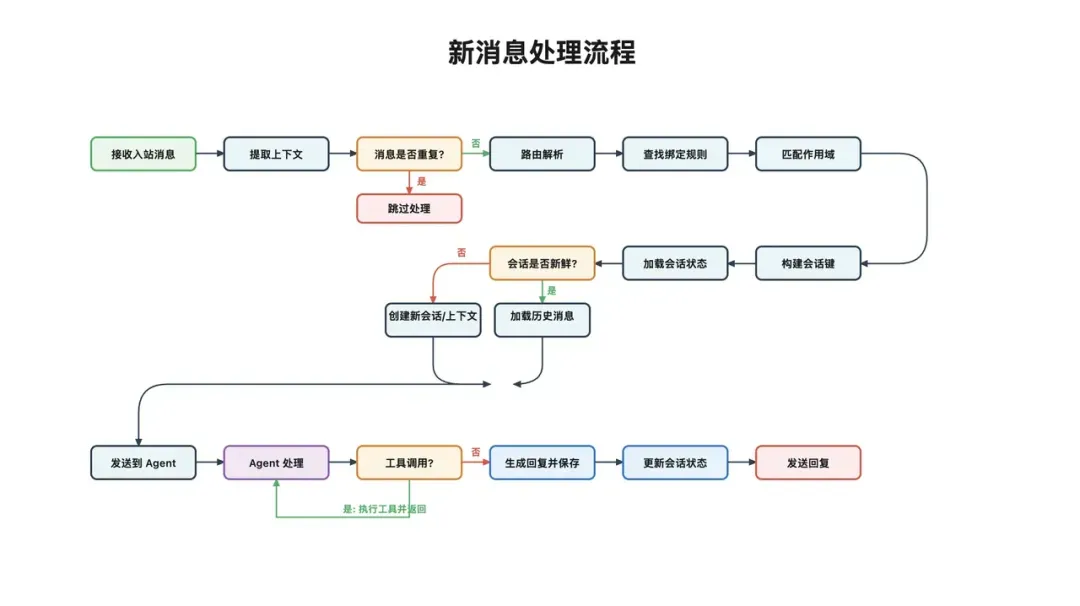
消息的初始接入
让我们回到之前的示例指令。从用户视角看,这只是一条普通消息。但从系统视角出发,一系列复杂问题立即浮现:钉钉的消息格式与飞书不同,Discord与WhatsApp各异,Telegram与内部WebSocket通道也各有其规。
不同平台可能携带message_id、thread_ts等不同字段,消息体内还可能嵌套着附件、引用回复、线程信息等复杂结构。若核心业务逻辑直接处理这些异构数据,代码将迅速陷入混乱。
因此,OpenClaw的第一步并非让Agent理解任务,而是首先进行协议适配。
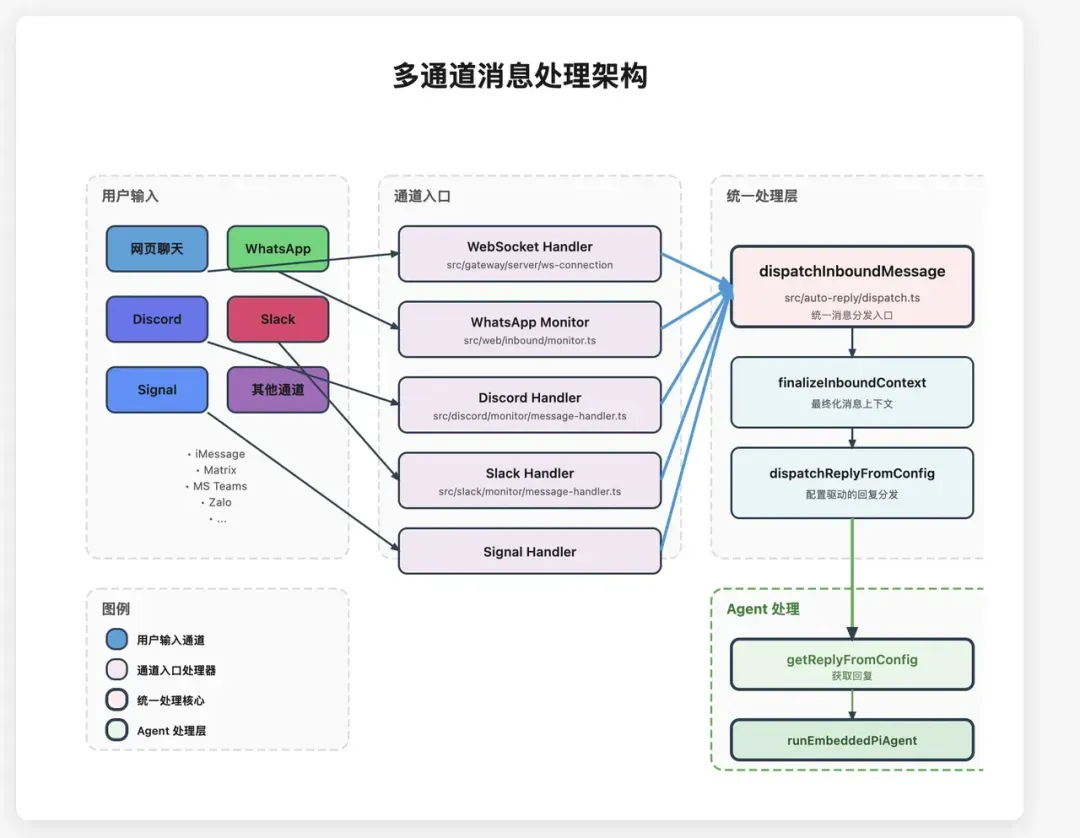
每个外部渠道都配备一个专属的适配器插件,其职责是将原始消息“清洗”并映射为统一的内部数据对象——MsgContext。其结构大致如下:
interface MsgContext {
Body: string;
BodyForAgent?: string;
BodyForCommands?: string;
RawBody?: string;
SessionKey: string;
Provider: string;
Surface?: string;
ChatType?: "direct" | "group";
SenderId?: string;
SenderName?: string;
SenderUsername?: string;
OriginatingChannel?: string;
OriginatingTo?: string;
AccountId?: string;
MessageThreadId?: string;
CommandAuthorized?: boolean;
MessageSid?: string;
GatewayClientScopes?: string[];
}
此处的关键在于统一抽象。无论消息来自哪个平台,一旦进入网关,都会被转换为这一标准格式。后续所有处理流程仅需关注MsgContext对象,而无需操心其原始来源。
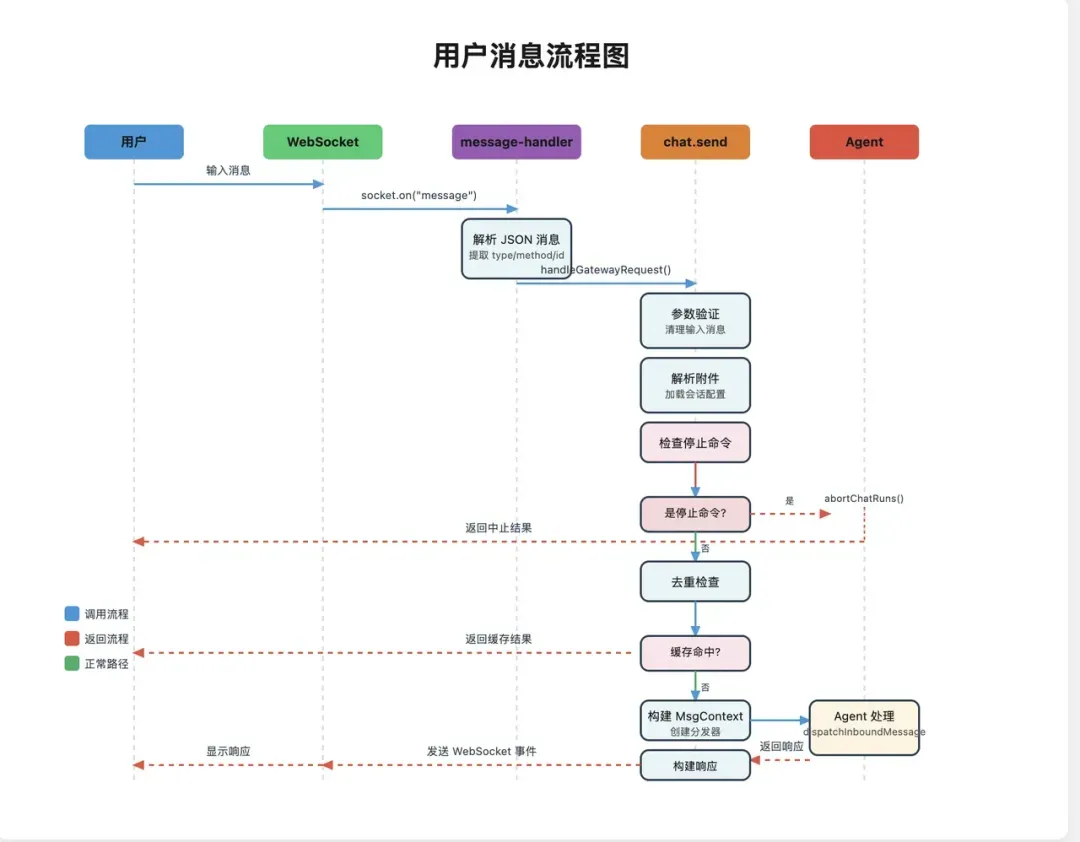
这一步将平台差异性隔离在网关入口处,避免了其对整个Agent执行链路的污染。未来如需接入新通道,通常只需完成四步:
- 在注册中心添加通道元数据。
- 实现对应的
ChannelPlugin接口。 - 在插件加载器中注册新插件。
- 更新配置模式(Schema)及相关文档与测试。 整个过程无需修改核心系统代码,这正是插件化设计的价值所在。
信息的初步处理
所有经过封装的MsgContext对象,最终都会流入一个统一的处理关卡:dispatchInboundMessage函数。
此步骤的目的并非执行复杂业务逻辑,而是将所有入站消息的处理入口收敛至同一个总开关。其源码结构大致如下:
export async function dispatchInboundMessage(params) {
const finalized = finalizeInboundContext(params.ctx);
return await withReplyDispatcher({
dispatcher: params.dispatcher,
run: () => dispatchReplyFromConfig({
ctx: finalized,
cfg: params.cfg,
dispatcher: params.dispatcher,
replyOptions: params.replyOptions,
replyResolver: params.replyResolver,
}),
});
}
从结构上看,它主要完成两件事:
1. 最终化入站上下文
即执行finalizeInboundContext。此步骤主要负责:
- 补全可能缺失的字段。
- 标准化数据格式。
- 统一上下文表示方式。 其意义在于,尽管前期已完成通道适配,但不同通道在细节上仍可能存在不一致。因此,在消息真正进入核心处理逻辑前,需进行最终的一致性收束。
2. 移交回复分发器进行后续处理
此步骤之后,消息才正式开始进入OpenClaw的核心处理主干。换言之,至此为止,系统所做的工作并非“理解任务”,而是首先确保: 这条消息在格式上是系统能够安全且一致地处理的。
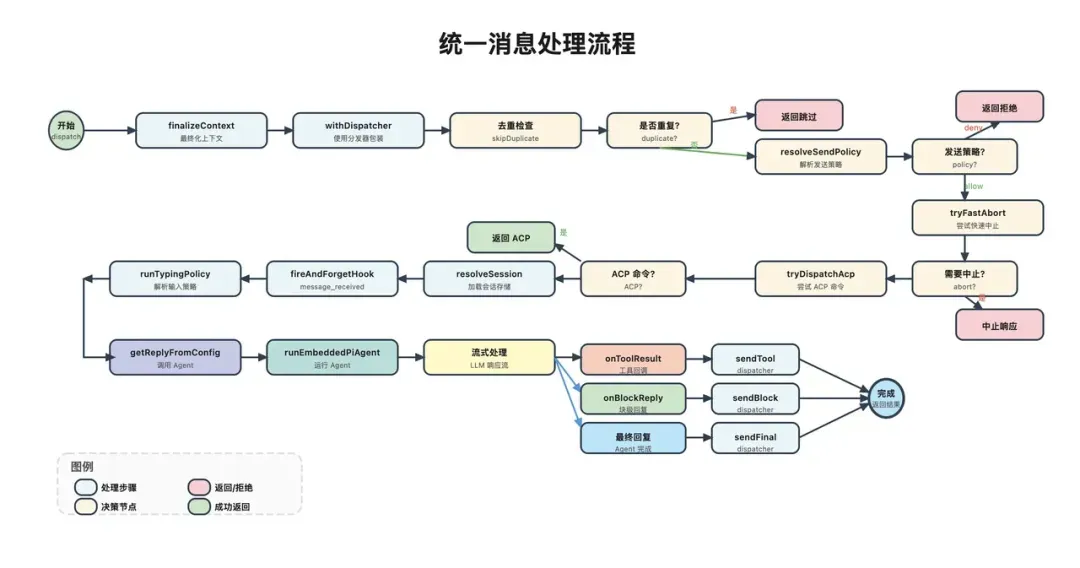
路由决策系统
消息一旦进入主处理链路,OpenClaw不会立即将其抛给大模型,而是首先进行三类关键判断:
- 是否应该处理此消息?
- 是否为重复消息?
- 应该交由哪个Agent处理?
这一步非常类似于实际生产系统中的“前置治理层”。
去重机制:防止消息被重复处理
在生产环境中,消息重复投递是常见现象。Webhook可能重试,平台可能重复推送,网络抖动也可能导致同一条消息被系统接收两次。若缺乏幂等性控制,最糟糕的结果并非“多回复一句”,而是可能导致:
- 同一任务被重复执行。
- 同一工具被重复调用。
- 同一个外部API被重复触发。
- 同一笔计算成本被重复消耗。
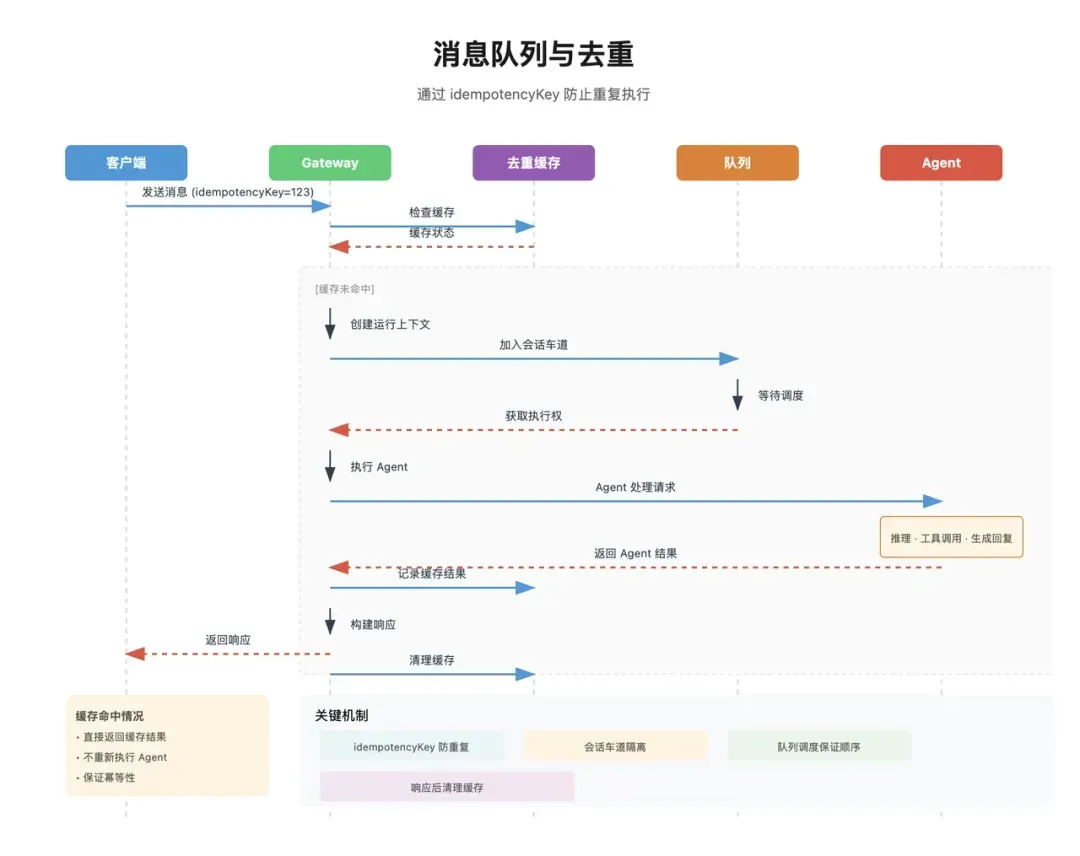
因此,OpenClaw会为每条消息生成一个幂等键(idempotencyKey)。其核心逻辑由buildInboundDedupeKey函数控制:
export function buildInboundDedupeKey(ctx: MsgContext): string | null {
const provider = normalizeProvider(
ctx.OriginatingChannel ?? ctx.Provider ?? ctx.Surface
);
const messageId = ctx.MessageSid?.trim();
if (!provider || !messageId) {
return null;
}
const peerId = resolveInboundPeerId(ctx);
if (!peerId) {
return null;
}
const sessionKey = ctx.SessionKey?.trim() ?? "";
const accountId = ctx.AccountId?.trim() ?? "";
const threadId = ctx.MessageThreadId ? String(ctx.MessageThreadId) : "";
return [provider, accountId, sessionKey, peerId, threadId, messageId]
.filter(Boolean)
.join("|");
}
生成的键格式大致为:{provider}|{accountId}|{sessionKey}|{peerId}|{threadId}|{messageId}。
例如:
whatsapp||main:+1234567890|msg_123discord|default|agent:assistant:123|987654321||11223slack|default|main:default|U12345678||C12345678
系统会为每条消息生成唯一的标识符。若在缓存中发现该键已处理过,系统将直接返回,避免重复调用昂贵的LLM API(默认的生存时间TTL为20分钟)。
消息拦截
部分消息并非用于驱动Agent执行任务,而是向系统发送控制指令。因此,除了去重,系统还会执行快速拦截逻辑。
例如,若用户输入/stop指令,则该消息不应继续执行任务理解和工具调用,而应立即中断对应的AbortController,强制停止正在运行的Agent任务。
这表明OpenClaw并非一个简单的“一问一答”外壳,其本质是一个长期运行的任务系统,支持控制指令是其必需的基础能力。
快速响应机制
对于Web请求,系统通常首先通过WebSocket返回一个started状态,随后再异步执行后续处理。
此步骤虽小,但至关重要。因为模型思考、工具调用、网络请求都可能耗时较长,若前端一直等待最终结果,极易引发超时或给用户造成“卡死”的错觉。
因此,从用户体验角度,OpenClaw会首先告知用户:任务已进入执行状态。
Agent的正式登场
去重和拦截仅是前置治理。在真正开始执行业务逻辑前,系统仍需回答一个根本性问题:**这条消息应由谁来处理?**这正是路由系统的核心职责。
OpenClaw的路由策略根据通道类型分为两套。
Web内部通道
Web客户端通常可直接传递sessionKey,其格式一般为:{agentId}:{scope},例如:assistant:main。
在此情况下,系统可直接使用此会话键,无需查询绑定规则。
外部通道
对于Slack、WhatsApp、Discord等外部通道,客户端本身并不知晓系统内部的会话组织方式,因此必须依据配置中的绑定规则来确定应由哪个Agent处理。 配置示例如下:
{
"bindings": [
{
"agentId": "assistant",
"match": { "channel": "whatsapp", "accountId": "my_bot" }
},
{
"agentId": "vip-assistant",
"match": { "channel": "whatsapp", "peer": { "id": "+1234567890" } }
}
]
}
每个绑定规则可根据不同维度进行匹配:
- 通道标识
- 账户ID
- 对等体(用户或群组)信息
- Discord服务器ID
- 团队ID
- 角色列表
系统会按照优先级从高到低进行匹配:
- 精确对等体匹配
- Discord服务器 + 角色匹配
- Discord服务器匹配
- 通道账户级匹配
- 通道级匹配
- 默认Agent
回到我们的例子:这条来自钉钉的消息首先被识别出其通道、账户、用户及频道信息,随后系统依据配置规则决定,最终是由assistant处理,还是交由某个专门的support-agent、vip-assistant或coder处理。
唯一会话键的生成
一旦确定了负责处理的Agent,系统便会为此次对话构建sessionKey,其格式通常为:{agentId}:{scope}。
例如:
assistant:mainassistant:whatsapp:direct:+1234567890assistant:discord:channel:987654321support:telegram:group:-1001234567890
此键至关重要,因为它后续将承担两项关键职责:会话隔离与并发控制。 这意味着,用户看到的只是一条消息,但系统实际管理的是:这条消息隶属于哪个Agent的哪一条具体会话。
车道执行机制
至此,消息已完成路由,明确了应由哪个Agent处理,也知晓了自己所属的会话。
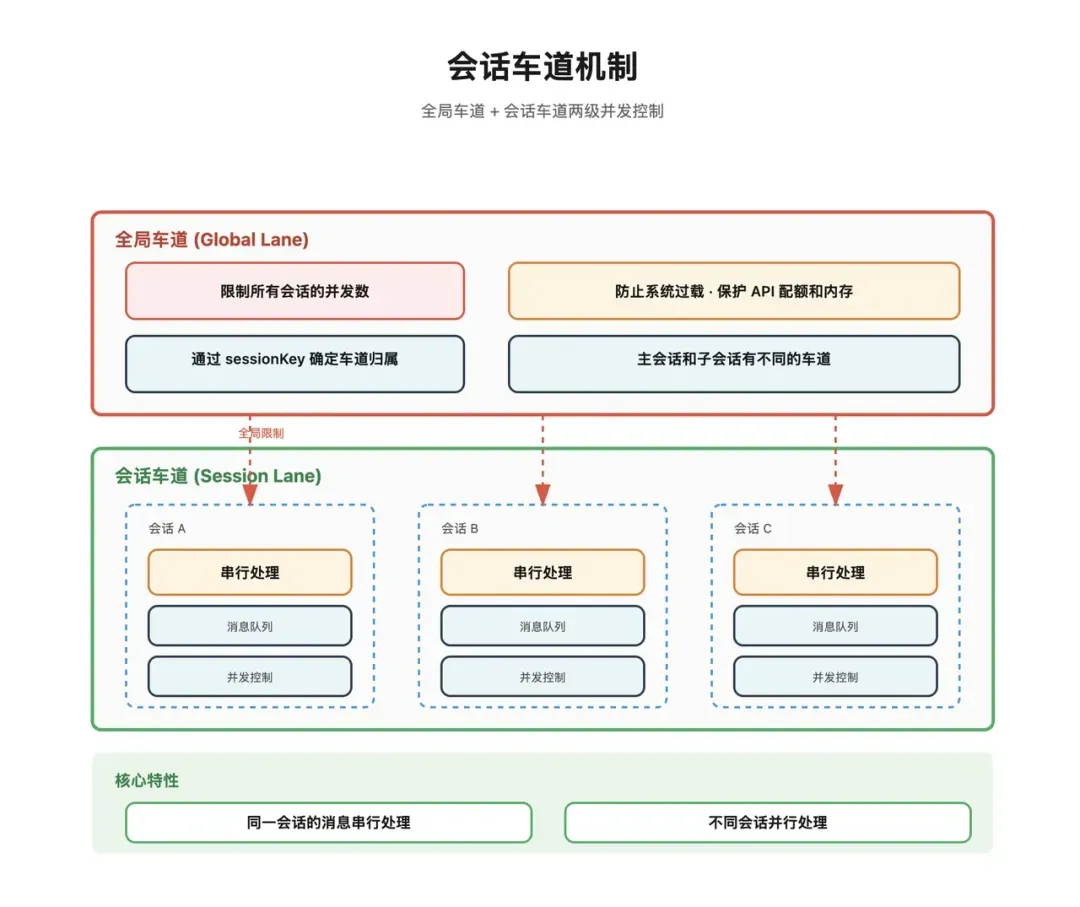
然而,系统仍不会立即开始执行。原因很直接:若同一会话中的多条消息并行处理,极易导致上下文错乱。 假设用户先发送:“帮我整理今天的重要邮件”,紧接着又发送:“顺便把待办改成按优先级排序”。若两条消息并行处理,则可能出现:
- 第二条消息先完成处理。
- 第一条消息后完成处理。
- 上下文互相污染。
- 输出顺序颠倒。
- 工具调用状态不一致。
因此,OpenClaw设计了会话车道机制。
会话级车道
相同sessionKey的消息必须串行执行,以确保上下文的连贯性。此机制本质上保证了:任意时刻,一个会话中只有一条消息真正占用其执行上下文。
这使得同一次对话能够被理解为“连续对话”,而非并发乱流。
全局级车道
除了会话级串行控制,系统还可配置全局最大并发数。若同时涌入过多消息超出系统容量,后续消息将进入等待队列。 这相当于两层流量控制:
- 会话层:防止同一次对话内的消息乱序。
- 系统层:防止整个运行时被过量请求打垮。
此机制体现了OpenClaw的工程思维:它并非单纯依赖模型能力,而是在运行时层面主动实施资源治理。
执行阶段的启动
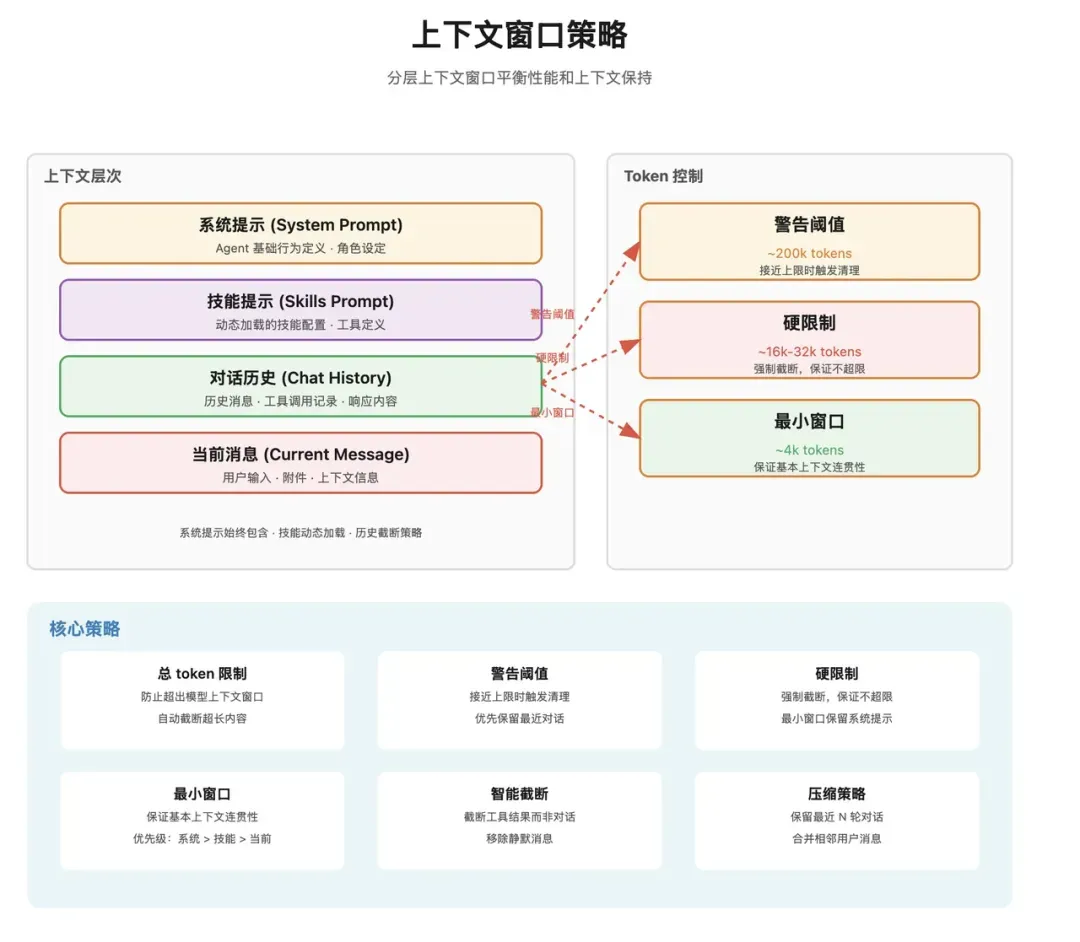
当消息终于排到执行队列时,便正式进入Agent执行阶段。此时最重要的一环是:系统需要为模型组装完整的上下文环境。 许多人理解Agent时,容易简化为:用户输入 → 模型理解 → 调用工具 → 结束。但在OpenClaw的实际实现中,模型接收的并非孤立的用户输入,而是一整套精心组装的上下文环境。组装顺序大致如下:
系统提示词 → 技能提示 → 对话历史 → 当前消息
这个顺序至关重要,因为它定义了模型的认知层级:
- 首先知晓自己的身份与角色。
- 其次了解自己具备的能力(技能)。
- 然后回顾之前发生的对话历史。
- 最后才处理用户最新的输入。
系统提示词的注入
系统提示词的职责是定义Agent的角色、行为规则和安全边界。OpenClaw在此处的实现非常工程化,并非将一长段提示词硬编码,而是通过引导(Bootstrap)文件系统进行注入。 系统大致会将以下文件内容装入上下文:
AGENTS.md:定义Agent行为规则和工具使用指南。SOUL.md:定义Agent的个性和人格。TOOLS.md:工具使用说明。IDENTITY.md:身份标识信息。USER.md:用户偏好设定。HEARTBEAT.md:心跳检测提示。BOOTSTRAP.md:初始化引导。MEMORY.md/memory.md:长期记忆文件。
这些文件通常位于工作区目录(默认路径如~/.openclaw/workspace)。这意味着,在真正回答“整理邮件”之前,模型首先被告知:
- 我是谁。
- 我应遵守哪些规则。
- 我能使用哪些工具。
- 当前用户有何偏好。
- 系统存在哪些长期记忆。
这与普通聊天机器人有本质区别:它并非每次对话都从零开始,而是从一个被预先定义和塑造的Agent身份出发。
记忆召回规则
在src/agents/system-prompt.ts文件中,系统提示词还明确包含了记忆召回规则:
## Memory Recall
Before answering anything about prior work, decisions, dates, people, preferences, or todos:
run memory_search on MEMORY.md + memory/*.md; then use memory_get to pull only needed lines.
If low confidence after search, say you checked.
这段指令颇具深意。它并非简单地告诉模型“要尽量记住”,而是明确规定: 当遇到涉及历史决策、用户偏好、待办事项、日期等相关问题时,必须先检索记忆文件,再基于检索结果进行回答。 这将“记忆”从模型模糊的上下文残留,提升为一种显式的、可检索的机制。
上下文大小限制
由于这些文件内容在每次运行时都会消耗Token,因此系统会实施限制:
- 单个文件的最大字符数。
- 总注入字符数的上限。
- 在内容被截断时是否显示警告。 这表明OpenClaw的设计思路并非将所有信息都喂给模型,因为系统提示词本身也需要受限于上下文窗口的预算约束。
核心环节:Skills载入
系统提示词组装完毕后,下一步是技能提示的注入。此部分极为关键,因为许多人在讨论OpenClaw时,最容易误解Skills的概念。
从源码实现来看,Skills并非简单的函数列表。它更像是:
首先向模型说明一组可用能力的使用方法、调用边界及适用场景;然后,当模型决定调用时,再连接真实的工具实现。
换言之,Skills首先是让Agent知晓如何运用工具的方法包。 技能加载流程大致分为四步:
1. 技能发现
系统从多个来源扫描技能定义文件:
- 工作区目录。
- 用户全局目录。
- 系统内置目录。
- 插件目录。
2. 技能过滤
并非所有发现的技能都可直接使用。系统会根据多个条件进行过滤:
- 运行平台限制。
- 消息通道限制。
- 发送者权限级别。
- 黑白名单配置。
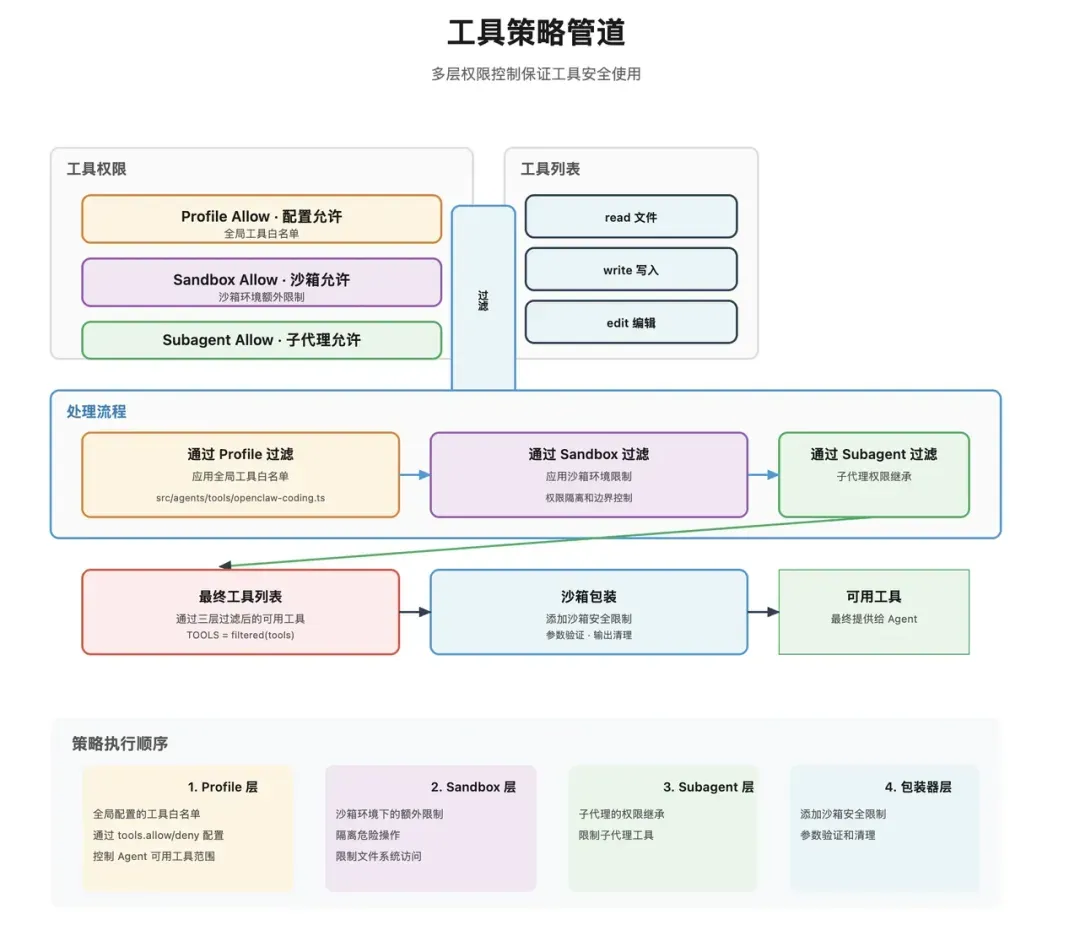
3. 安全检查
OpenClaw对Skills实施三层安全策略管道:
- Profile过滤(基于身份配置文件)。
- Sandbox隔离(在沙箱环境中运行)。
- Subagent继承(控制子Agent对技能的继承权限)。 这意味着,一个技能能否被调用,不仅取决于其是否存在,还取决于当前Agent的权限、安全边界是否允许,以及子Agent是否继承了相应能力。
4. 提示词生成
最后,系统将可用的技能描述格式化为文本,注入系统提示词,供LLM在需要时参考和调用。 因此,在我们的案例中,当用户提出“帮我整理今天的重要邮件,提炼待办,并生成给老板的简报”时,模型并非凭空想象自己能做什么,而是会依据这套技能描述进行判断:
- 是否存在邮件处理相关能力。
- 是否存在摘要生成能力。
- 是否存在文档组织能力。
- 是否需要进一步调用子Agent来协作完成。 这才是Skills真正发挥的作用。
会话与记忆系统
系统提示词和Skills就绪后,接下来才轮到组装对话历史和当前消息。
会话历史管理
OpenClaw采用双层存储结构管理会话历史。
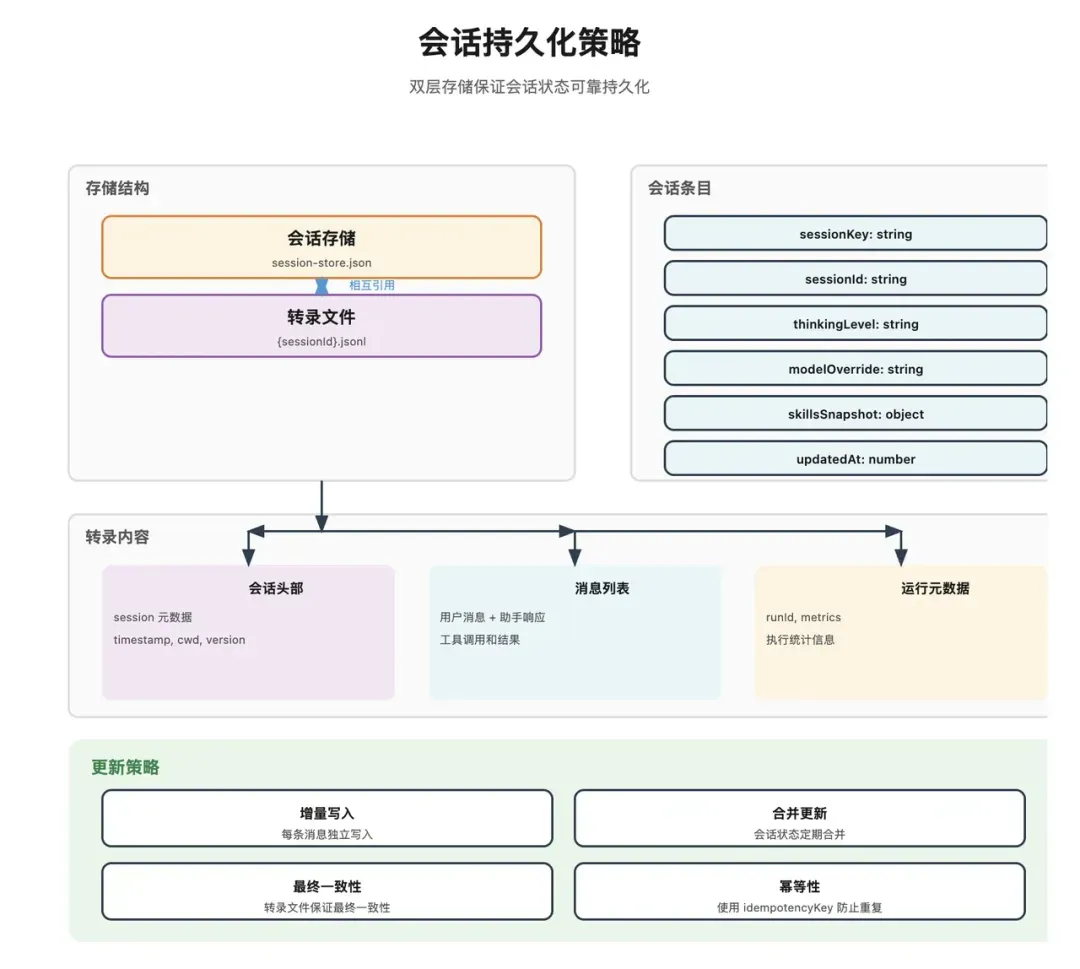
一、轻量级索引:sessions.json
此文件存储会话元数据,例如:
- 会话ID
- 会话键(sessionKey)
- 转录文件路径
- 最后更新时间
- 模型覆盖配置
- 技能快照
文件通常位于:
~/.openclaw/agents/{agentId}/sessions/sessions.json。 内容示例如下:
二、详细转录文件:{sessionId}.jsonl
此文件记录完整的对话历史,采用JSON Lines格式(每行一个JSON对象),便于流式读取和追加。文件同样位于Agent目录下的sessions文件夹中。
历史消息加载策略
系统从转录文件读取历史消息时,会执行以下操作:
- 从最新消息开始,向前读取指定Token数量的对话轮次。
- 过滤掉不需要的消息类型(如系统消息)。
- 确保时间顺序正确。
- 估算历史消息占用的Token数量。 因此,在真正调用模型之前,系统已在处理一个非常现实的问题:在当前上下文的预算内,究竟还能容纳多少历史对话。
当前消息的注入
当前消息作为上下文的最后一部分被注入,内容包括:
- 用户输入的文本。
- 发送者信息。
- 时间戳。
- 相关元数据。
- 来源通道信息。
- 所属会话键。 这意味着,模型在处理这次请求时,并非只看到一句孤立的用户输入,而是站在一整条连续对话历史的尾部,基于完整的上下文来理解当前消息的语义。
上下文记忆压缩机制
一旦将系统提示词、技能提示、历史记录和当前消息全部装入上下文,另一个问题便随之而来:上下文窗口迟早会满。 因此,OpenClaw专门设计了一整套防溢出机制。
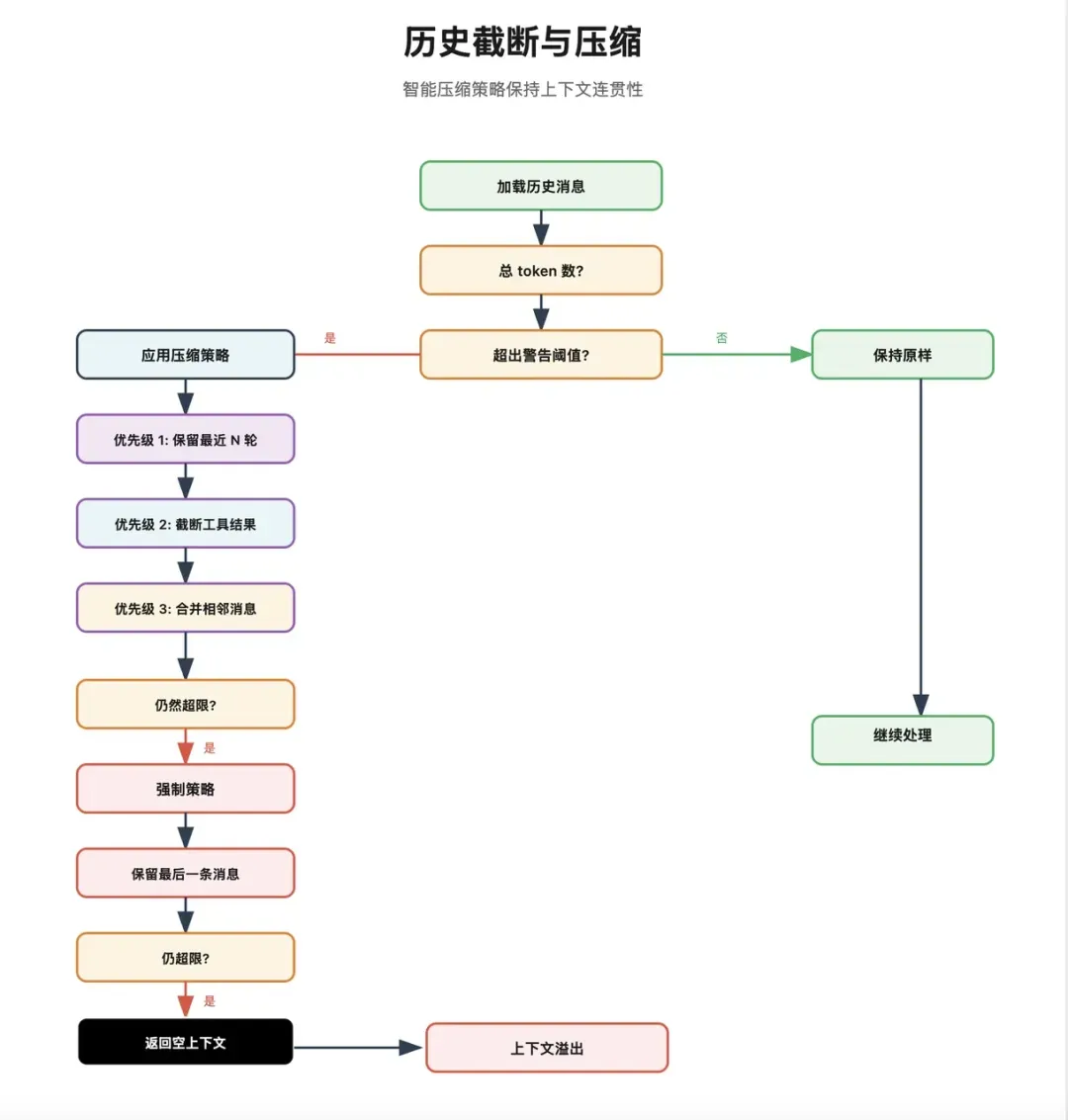
1. 历史轮次限制
系统会根据通道配置限制保留的历史对话轮数,从最新消息开始向前扫描,丢弃更早的部分。这是最简单直接的一层防线。
2. 工具调用结果截断
工具调用的返回结果可能非常庞大,例如:
- 长篇文本。
- 大型JSON对象。
- 多页日志内容。
- 大段网页抓取内容。 如果将这些结果原封不动地塞回上下文,极易撑爆窗口。因此,系统会自动截断工具输出,并智能判断是否保留尾部关键信息(如错误信息或JSON结构的尾部)。若尾部包含重要信息,则采取“保留头部和尾部”的策略;否则,仅保留开头部分。
3. 自动语义压缩
当上下文窗口接近模型限制时,系统会将早期的历史对话分块,并为每块生成摘要。随后,用生成的摘要替换掉原始的早期历史,同时保留最近几轮完整的对话。 摘要生成的要求是保留关键信息,例如:
- 仍在进行的活跃任务。
- 当前的操作进度。
- 用户的最后请求。
- 已作出的重要决策。
- 后续步骤的依赖信息。 因此,这并非简单的机械裁剪,而是一种基于语义的智能压缩。
4. 容错与降级策略
如果压缩后上下文仍然超出限制,系统会尝试进一步措施:
- 自动切换到支持更大上下文的模型。
- 降低Agent的“思考”级别(如减少chain-of-thought的步骤)。
- 最终回退为提示用户重置当前会话。 这表明OpenClaw并非将上下文管理完全交给模型自身,而是将其视为运行时层面必须解决的硬约束问题。
记忆系统的工作原理
除了会话历史,OpenClaw还独立维护着两类记忆:
一、长期记忆
文件通常命名为:MEMORY.md 或 memory.md。
用于存储“常青”知识,例如:
- 项目规则与流程。
- API文档要点。
- 重要的设计决策。
- 用户的长期偏好设置。 这类记忆在Agent启动时,通过Bootstrap系统直接注入系统提示词。
二、每日记忆
存储于:memory/YYYY-MM-DD.md 文件中。
用于记录具有时效性的内容,例如:
- 当天的会议纪要。
- 每日待办事项列表。
- 临时作出的决策。
- 工作日志。 这类记忆不直接注入提示词,而是通过记忆搜索工具按需检索。系统会为检索结果施加时间衰减权重,越新的内容权重越高。
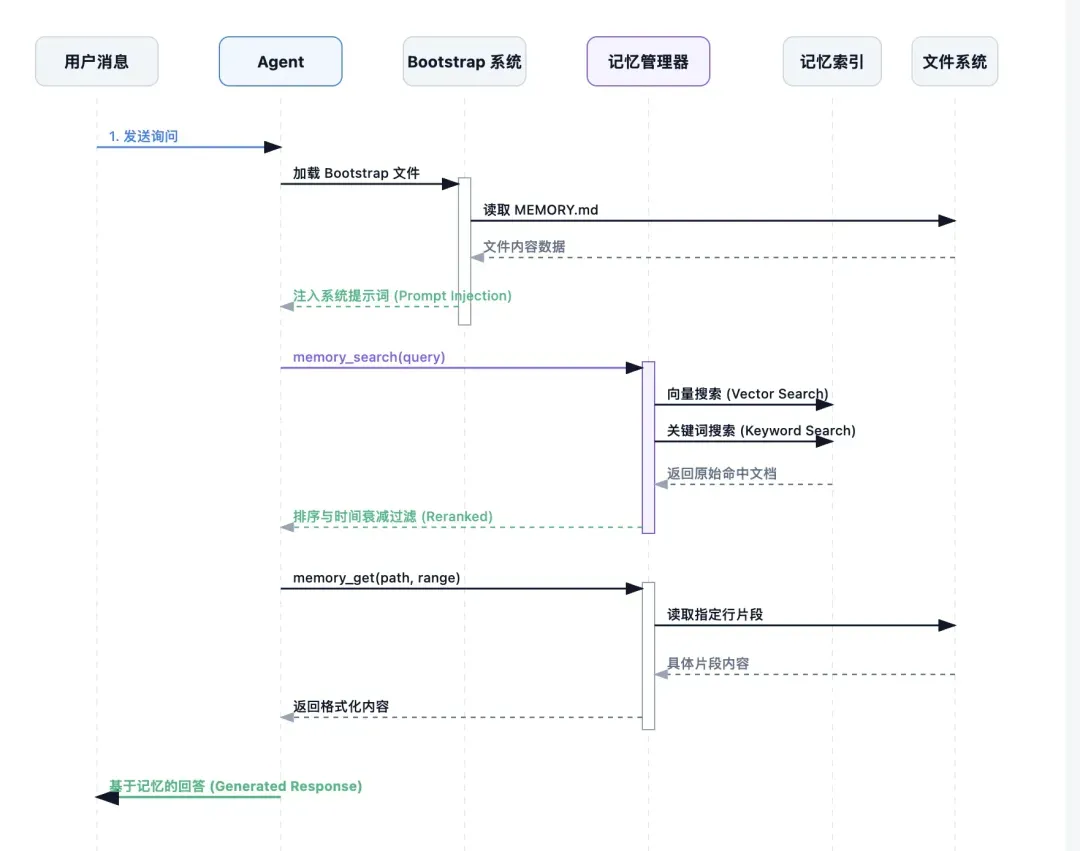
三、记忆的写入时机
长期记忆通常由用户或Agent通过编辑工具手动维护。而每日记忆则会通过“记忆刷新”(Memory Flush)机制自动触发。 触发条件包括:
- 会话的Token使用量接近上下文窗口上限(默认软阈值为4000 tokens)。
- 会话转录文件大小超过设定阈值(默认约为2MB)。 当系统检测到会话即将触及压缩阈值时,会先向Agent发送一条特殊提示:
Pre-compaction memory flush.
Store durable memories now (use memory/YYYY-MM-DD.md; create memory/ if needed).
IMPORTANT: If file already exists, APPEND new content only and do not overwrite existing entries.
这意味着,在上下文压缩发生前,系统会先提醒Agent:将本轮对话中值得长期保留的信息,沉淀到每日记忆文件中。 这相当于在压缩前,先构筑一道记忆护城河,避免有价值的信息在压缩过程中丢失。
任务的真正执行
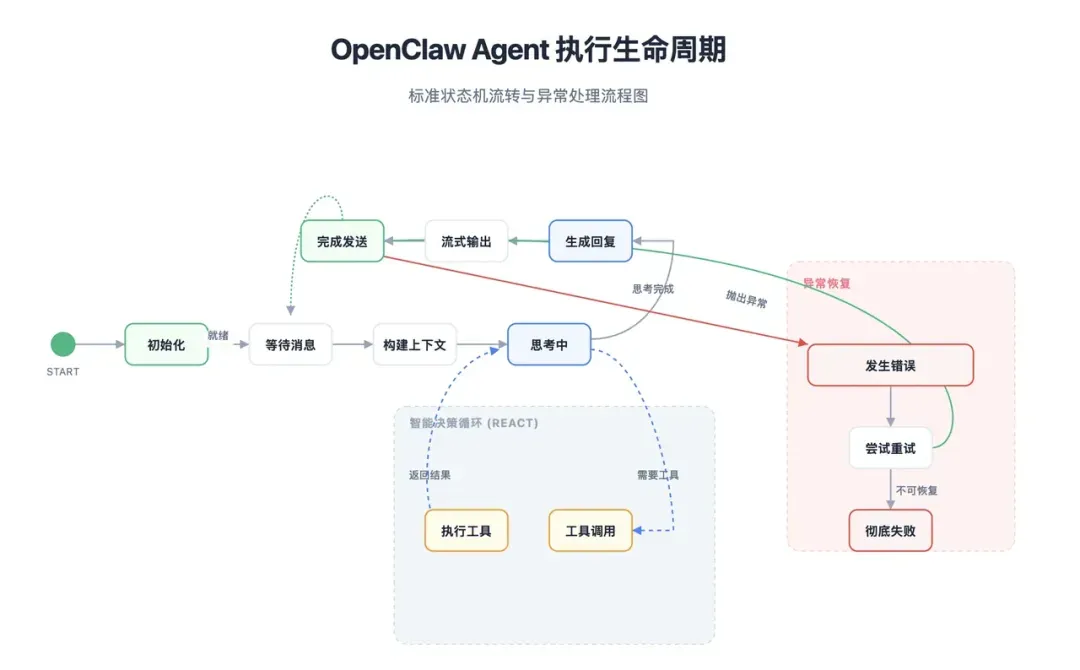
至此,完整的上下文环境已准备就绪,Agent才正式开始执行任务。
在我们的例子中,此时模型可能会进行如下判断:
当前任务不属于简单的问答类型。
它是一个需要执行的操作型任务。
任务包含邮件整理、待办提炼、简报生成三类子需求。
需要调用相应的技能和工具来完成。
如果任务过于复杂,可能需要拆分并由子Agent协作处理。
此阶段最核心的三项工作是:
1. 流式响应输出
OpenClaw使用Server-Sent Events (SSE) 或 WebSocket 实现流式输出。当LLM开始生成内容时,系统会将内容块实时推送给客户端。这使得用户可以立即看到输出开始,而无需等待整个任务完成后一次性接收全部结果。这显著降低了用户的感知延迟,尤其适合执行时间较长的任务。
2. 工具调用循环
当LLM判断需要调用工具时,系统会暂停文本流生成,执行对应的工具(例如:读取文件、调用API、搜索记忆、访问邮件、执行脚本等)。工具执行完成后,再将结果反馈给LLM,让它基于新信息继续推理。对用户而言,可能只是看到“正在执行工具…”的提示或一段短暂中断后的继续输出;但对系统而言,这是一次完整的推理 → 执行 → 再推理的循环。
3. 错误处理与模型回退
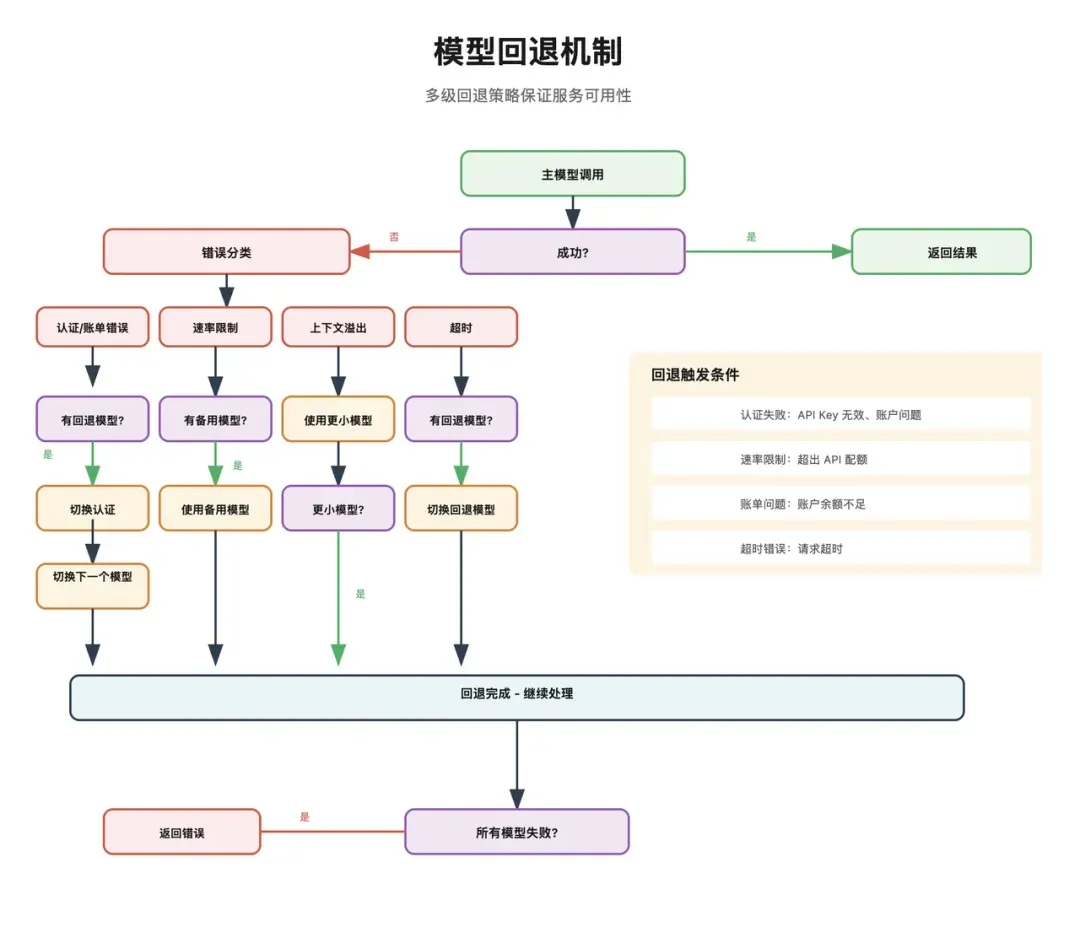
在生产环境中,出错是常态。因此,OpenClaw设计了多级回退策略:
- 限流处理:采用指数退避策略或自动切换到备用模型。
- 认证错误:轮换使用多个可用的API Key。
- 超时错误:降低模型的“思考”级别,或切换到响应更快的模型。
- 上下文溢出:触发上下文压缩,或自动切换到支持更大上下文的模型。 这部分设计充分体现了OpenClaw的工程导向:它不假设模型和外部服务永远稳定,而是预设运行过程随时可能出错,并提前规划好各种兜底路径。
任务完成与收尾
当Agent完成“整理今天的重要邮件,提炼待办,并生成给老板的简报”这项任务后,系统仍不能立即宣告结束,还需执行三类收尾操作:
1. 响应投递
回复分发器会根据消息上下文中的来源通道和目标地址,调用相应通道的出站适配器发送最终回复。如果配置了跨通道回复规则,甚至可以覆盖原始目标。例如,允许在钉钉发起任务,而将最终结果发送到用户的WhatsApp。这体现了OpenClaw作为智能网关,而不仅是聊天框内模型的思路。
2. 会话持久化
系统会将本次交互的完整记录写入存储:
- 更新
sessions.json文件中的会话元数据(如最后活跃时间)。 - 将用户消息、AI回复、工具调用及结果等内容作为新行追加到对应的
.jsonl转录文件中。 这确保了下次继续同一会话时,系统能够知晓之前发生过的所有事情。
3. 资源释放与清理
执行结束后,系统会进行清理工作:
- 释放该会话占用的车道锁。
- 释放全局并发配额。
- 将本次消息的幂等键标记为已处理。
- 定期清理过期的会话数据。
- 归档旧的转录文件。
- 轮换过大的日志或数据文件。 这一步体现了一个长期运行系统所必需的善后逻辑,缺乏它,系统资源将逐渐耗尽,性能随之下降。
记忆索引的构建与维护
既然记忆以Markdown文件形式存储,系统还需解决一个关键问题:如何让Agent高效地检索这些记忆?
OpenClaw的做法是为记忆系统单独建立索引。索引数据库通常位于:~/.openclaw/memory/index.db。
其中包含的主要表有:
files:文件元数据。chunks:文本分块信息。chunks_vec:向量化分块(用于向量检索)。chunks_fts:全文搜索索引。embedding_cache:向量嵌入缓存。 这意味着系统同时支持:
- 文件元数据管理。
- 文本智能分块。
- 基于向量的语义检索。
- 基于关键词的全文搜索。
- 向量嵌入的缓存以提升性能。
为了确保记忆文件与索引保持同步,系统实现了三种同步机制:
- 文件监视器:监控文件变化并自动触发索引更新。
- 定期同步:定时任务进行增量或全量同步。
- 手动触发同步:按需执行。 必要时,系统还可以执行全量索引重建:
- 创建临时数据库。
- 遍历所有记忆文件。
- 对文件内容进行分块。
- 为每个分块生成向量嵌入。
- 构建全文搜索索引。
- 最后原子性地替换旧的索引数据库。
综上所述,OpenClaw的记忆系统并非仅仅将Markdown文件当作静态备忘录存放,而是将其构建为一层真正可检索、可维护、可扩展的知识基座。
多Agent协作机制
前文所述,已经是一条完整的单Agent执行链路。对于简单的任务,至此即可形成闭环。 但现实中的许多复杂任务,并不适合由单个Agent独立完成。回顾我们的例子:“帮我整理今天的重要邮件,提炼待办,并生成一份给老板的简报。”这句话看似简单,实则可能包含至少三项工作:
- 筛选和归类重要邮件。
- 从邮件内容中提炼关键待办事项。
- 将结果组织成适合老板阅读的简报格式。 若将所有工作都交由一个Agent处理,虽然可以勉强完成,但往往会导致:
- 上下文过于臃肿。
- 推理链条过长。
- 工具调用混杂。
- 不同领域的专业能力混杂。
- 中间状态难以管理。
因此,OpenClaw在单Agent架构之上,构建了多Agent协作系统。
多Agent系统的核心能力
该系统实现了若干关键机制:
- Agent隔离:每个Agent在独立的上下文中运行。
- 动态任务分发:主Agent可将子任务动态分配给新创建的Agent。
- 层级化协作:形成树状或层级状的协作关系。
- 生命周期管理:管理子Agent的创建、运行和销毁。
- 安全边界控制:严格控制子Agent对资源和工具的访问权限。 这意味着,主Agent可以根据任务复杂程度,临时创建一个或多个子Agent,将特定子任务委托出去,自身则扮演总控和结果汇总的角色。
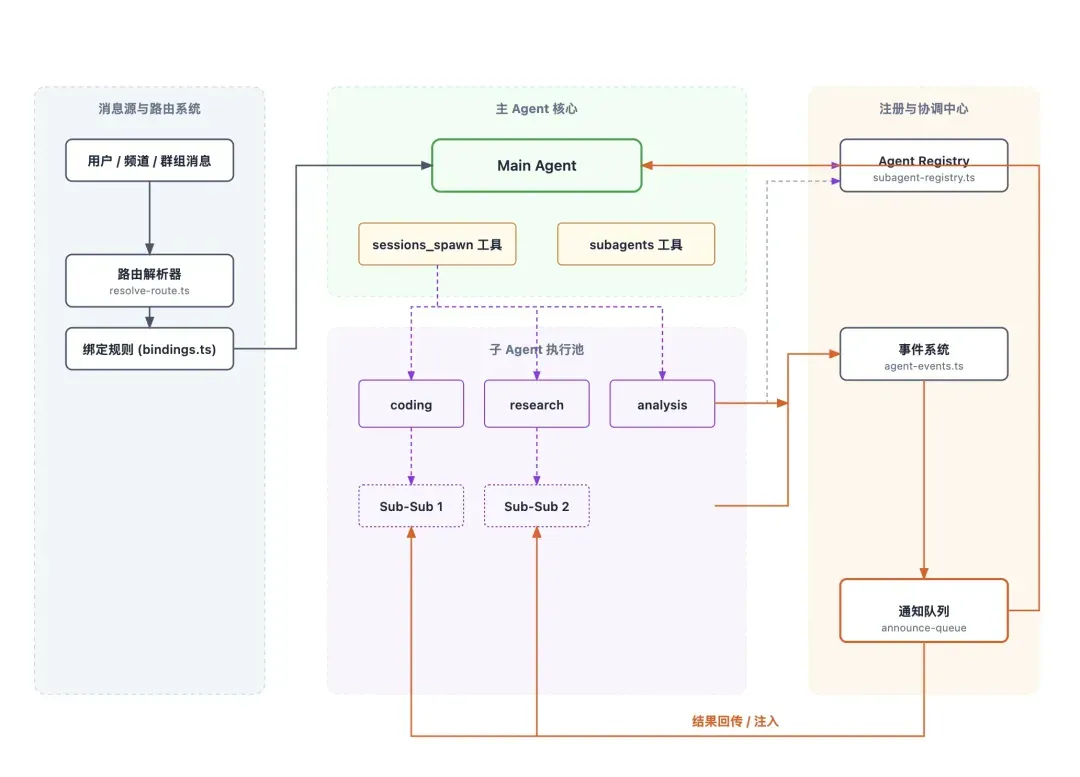
典型的多Agent工作流程
在我们的案例中,主Agent完全可以采取如下策略:
- 创建一个
research-agent,专门负责筛选和分类重要邮件。 - 创建一个
analysis-agent,负责从邮件内容中提炼待办事项和潜在风险点。 - 主Agent自身则负责整合前两个Agent的输出,最终形成给老板的简报。 此时,多Agent协作不再是一个抽象概念,而是成为一种具体的任务分解与执行策略。
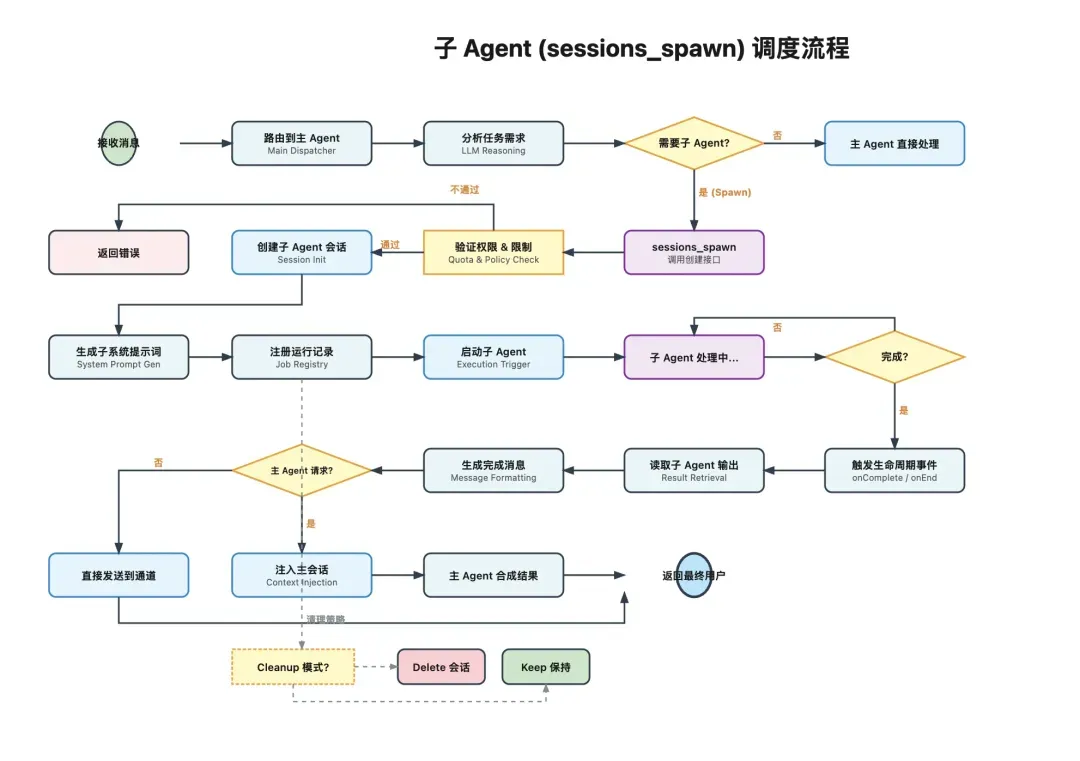
创建子Agent(subAgent)
当主Agent决定创建子Agent时,通常会通过sessions_spawn工具发起。系统首先会执行一轮严格的校验:
- 嵌套深度检查:防止Agent无限递归创建,导致系统崩溃。
- 并发限制检查:防止资源被过量占用。
- 允许列表检查:确认当前Agent有权创建指定类型的子Agent。
- 沙箱状态检查:确保在安全沙箱内运行(如果启用)。 校验通过后,系统会执行以下操作:
- 生成唯一的子会话键,格式如:
agent:{agentId}:subagent:{uuid}。 - 应用预设的模型配置和思考级别。
- 处理附件的传递和必要的上下文共享。
- 为子Agent生成专门的系统提示词。 例如,子Agent的系统提示词可能包含:
# Subagent Context
You are a subagent spawned by main agent for a specific task.
## Your Role
- You were created to handle: ${taskDescription}
- Complete this task. That's your entire purpose.
- You are NOT main agent. Don't try to be.
## Rules
1. Stay focused
2. Complete task
3. Don't initiate
4. Be ephemeral
这段提示词的目的并非强化子Agent的人格,而是明确其边界和职责:你不是主Agent,你的唯一使命就是完成被分配的特定子任务。
结果的返回与整合
子Agent完成任务后,系统会:
- 触发生命周期事件(如
subagent:done)。 - 读取子Agent的输出结果。
- 将结果通过内部通知队列传递。
- 判断结果的目标接收方(是主Agent还是直接给用户)。
- 决定将结果注入主Agent的会话上下文,或是直接发送给用户。 如果请求方是主Agent,那么子Agent的结果通常会以内部事件的形式重新注入主Agent的会话,供主Agent在下一轮推理时使用。 于是,完整的协作链路便形成:
主Agent接收用户任务 → 主Agent拆解任务并创建子Agent → 子Agent各自执行子任务 → 子Agent将结果回传给主Agent → 主Agent汇总所有结果 → 主Agent生成最终回复并返回给用户
这个过程本质上构建了一个层级化的任务执行与协作网络。
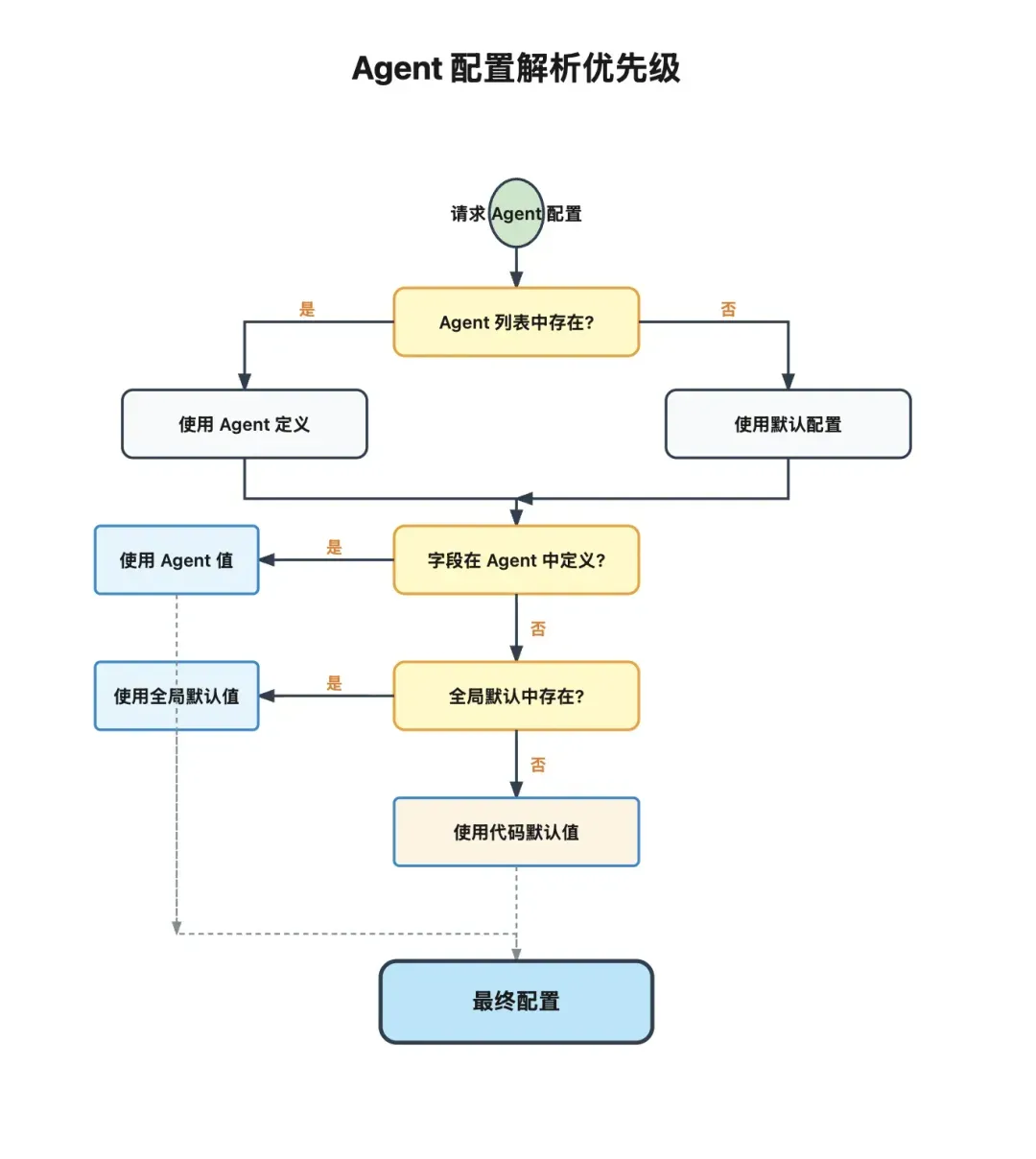
配置继承机制
OpenClaw在Agent配置上采用了三级继承机制:
- Agent级配置:优先级最高,为特定Agent单独定义。
- 全局默认配置:优先级次之,作为未单独配置Agent的默认值。
- 代码默认值:作为最终兜底。
例如,一个
coding-agent可以拥有自己独特的配置,如指定模型、工作区路径、可用工具列表、子Agent策略、沙箱模式等。对于未在Agent级配置中定义的部分,则回退使用全局默认值。这种设计使得多Agent系统在保持高度灵活性的同时,避免了配置的爆炸式增长。
OpenClaw的核心优势
让我们再次回顾最初的那条用户指令在OpenClaw内部经历的完整旅程:
钉钉原始消息进入系统 → 通道插件将其适配为统一的MsgContext对象 → 网关进行最终化处理 → 系统检查去重、拦截控制命令、并快速返回started状态 → 路由系统根据绑定规则确定目标Agent → 生成唯一的sessionKey → 进入会话车道排队,确保同一会话内消息有序执行 → 组装完整上下文(系统提示词、Bootstrap文件、Skills描述、历史记录、当前消息)→ 模型在技能描述和规则约束下开始推理 → 执行过程中可能调用工具,也可能创建子Agent → 子Agent完成任务后将结果回流给主Agent → 主Agent生成最终答复 → 回复分发器将结果投递回目标通道 → 会话和转录信息被持久化存储 → 记忆文件被更新,索引同步 → 资源被释放,执行闭环结束。
纵观整个过程,我们可以清晰地看到OpenClaw真正有价值之处,并非仅在于它能回答一句话,而在于:
它将一条消息从进入系统到完成执行的整个过程,构建成了一条可治理、可扩展、可追踪、可恢复的 Agent Runtime 链路。
结语
通过完整追踪一条消息在OpenClaw中的旅程,我们可以更清晰地提炼出其核心设计原则:
第一,分层架构,职责清晰。 从通道适配层、执行治理层到底层基础设施,各层边界明确,各司其职,共同构成一个稳定且可维护的系统。
第二,运行时导向,注重工程实践。 去重机制、会话车道、上下文压缩、错误回退、资源清理等一系列设计,表明它并非一个简单包装了Prompt和UI的玩具,而是认真解决了长期运行中的各类工程挑战。
第三,高度可扩展的插件化设计。 通道插件、技能系统、子Agent机制、记忆索引等模块都支持热插拔,使其更像一个开放的Agent网关平台,而非封闭的单体应用。
第四,初步具备了分布式协作的雏形。 多Agent机制的引入,意味着OpenClaw已不满足于“单一模型处理所有问题”的模式,开始朝着任务智能拆解、层级化协作与并行执行的方向演进。
因此,若要问OpenClaw究竟是什么,一个较为准确的回答或许是:
它不仅仅是一个更擅长对话的聊天机器人,也不只是一个会调用工具的Agent外壳。它更像是一个将消息入口、会话治理、上下文管理、技能调度、持久化存储以及多Agent协作能力深度融合在一起的 Agent Runtime + 智能网关系统。
理解其精髓的最佳方式,或许是尝试开发一个简化版本的“Mini-OpenClaw”,剥离复杂的工程兜底代码,聚焦其核心设计思想。这也将是我们后续探讨的方向。