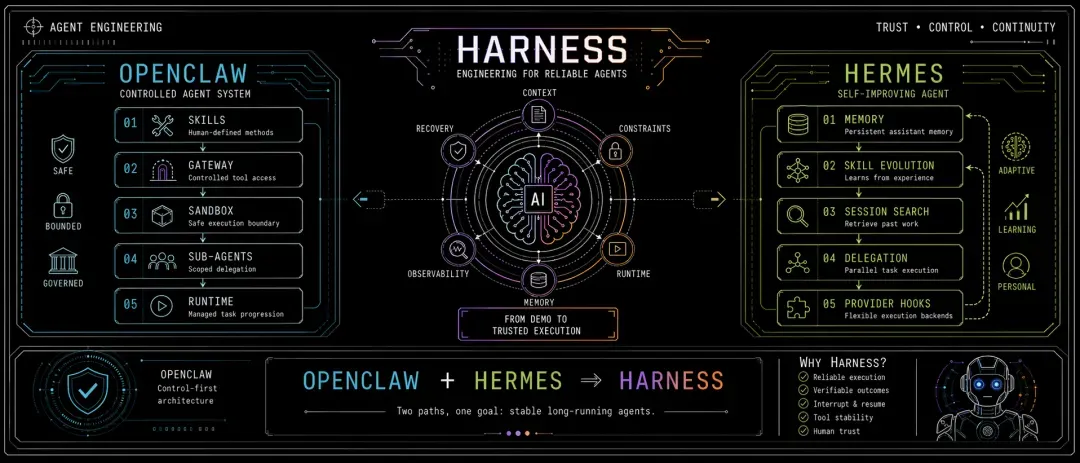
从OpenClaw解构Harness:打造稳定生产级AI Agent的工程方法论
Harness 最近吸引了越来越多的关注,但它与 OpenClaw、Hermes 并不完全同类——它还未落地成具体的产品,至今仍停留在框架性定位:为 Agent 的稳定执行而生。
目前平台上关于它的内容,要么过于抽象,要么又失之琐碎。
若想真正理解 Harness,不能只看概念,最好将它与当下运行优秀的 Agent 框架(如 Claude Code、OpenClaw、Hermes)结合起来,才能将其拉回到工程现场审视。
Harness 诞生背景
伴随着 Agent 技术的演进,尤其是 OpenClaw、Hermes 的发布以及 Claude Code 源码的亮相,全球对 Agent 开发范式的认知被推到了新的层次。
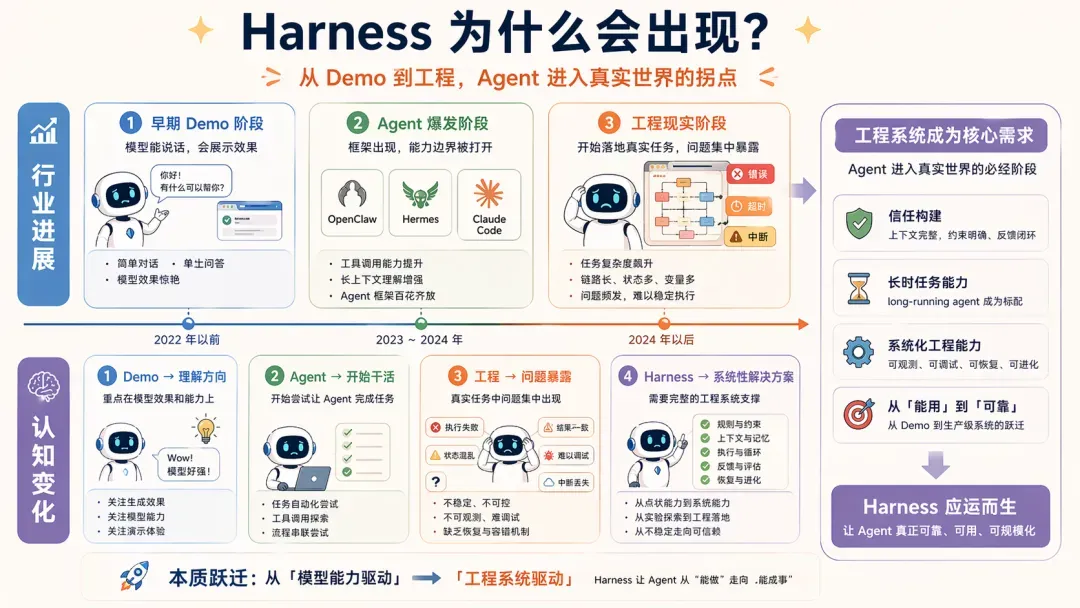
在此背景下,Harness 一词的走红并不突兀——当 Agent 真正开始承担任务,工程上的矛盾再也遮掩不住。
正如业界常说的:
Demo 展示的是范式方向,而工程实践才能真正定义范式是什么。
Martin Fowler 在 2026 年 4 月的文章中,将 Harness Engineering 定义为围绕编码类 Agent 建立的信任体系,其核心是通过上下文、约束条件、反馈回路和工程结构,让人一步步敢于把任务交托给 Agent。
Anthropic 官方工程文章同样把 Claude Code 视为一种优秀的 harness,并深入讨论了长时运行 Agent 以及长时应用开发场景中的 harness 设计。
补充一点:Claude 总爱强调自身优势不仅在于模型,也在于工程;但在我们使用国内框架并接入 Claude 模型后,能力提升同样显著。因此我认为 Claude 真正的强项是 Coding,而国内工程水平未必落后。
基于这些,我们如今探讨工程范式的集大成者 Harness,自然不能继续在提示词工程的圈子里打转,上下文工程似乎也不足以覆盖其全部含义。问题已经回归到了本质:
为什么 OpenAI、Hermes、Claude Code 等 Agent 框架,在演进过程中都会发展出一整套工程系统?
而这套系统,为什么越来越像决定 Agent 成败的关键?
模型与工程
过去两年,大模型公司主要围绕 Agent 生态投入:
- 语义理解
- 视觉生成
- 长上下文
- 工具调用
- 多模态
- 电脑操作、浏览器操作等 Agent 能力
行业内一度流行一个思路:面向未来半年进行设计,因为模型能力的增强会降低工程侧成本。此时一个关键假设是:只要模型持续强大,应用就会自然涌现。
实际发展印证了部分假设——当长上下文和工具调用的稳定性提升后,Agent 的可行性确实大幅改善。
可问题在于:**模型变强,不代表工程就稳。**依然有诸多边界不断暴露,比如:
- 工具调用仍有不准、不稳定的情况;
- 模型能理解复杂输入,但在持续推进长任务时依旧吃力;
- 模型能产出代码,却难以判断自己是否正确;
- ……
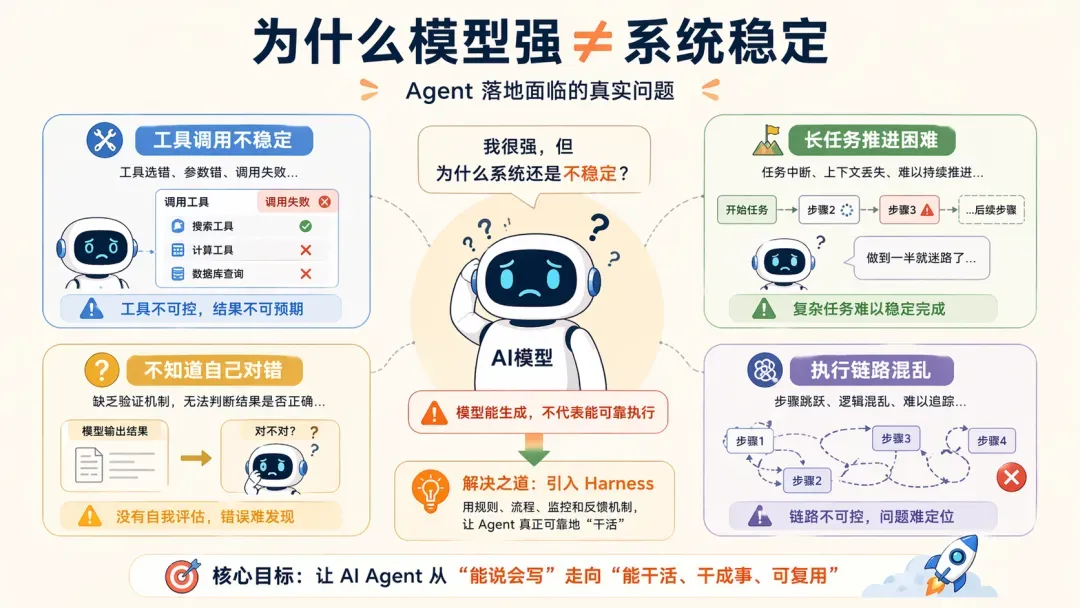
工程架构的意义,恰在于让 Agent 能够稳定地把事情完成。正因如此,从 2025 年到 2026 年,Agent 讨论重心发生了明显偏移:
- 从前人们琢磨 Prompt 怎么写;
- 后来转而研究 Context 怎么喂;
- 如今真正开始追问:Agent 运行时,到底还缺哪些系统能力?
这便是 Harness 登场的完整背景。
什么是 Harness
当前对 Harness 的定义不一而足,一个较好理解的说法是:
模型 = 大脑
Harness = 身体 + 工作台 + 操作规程 + 监督机制
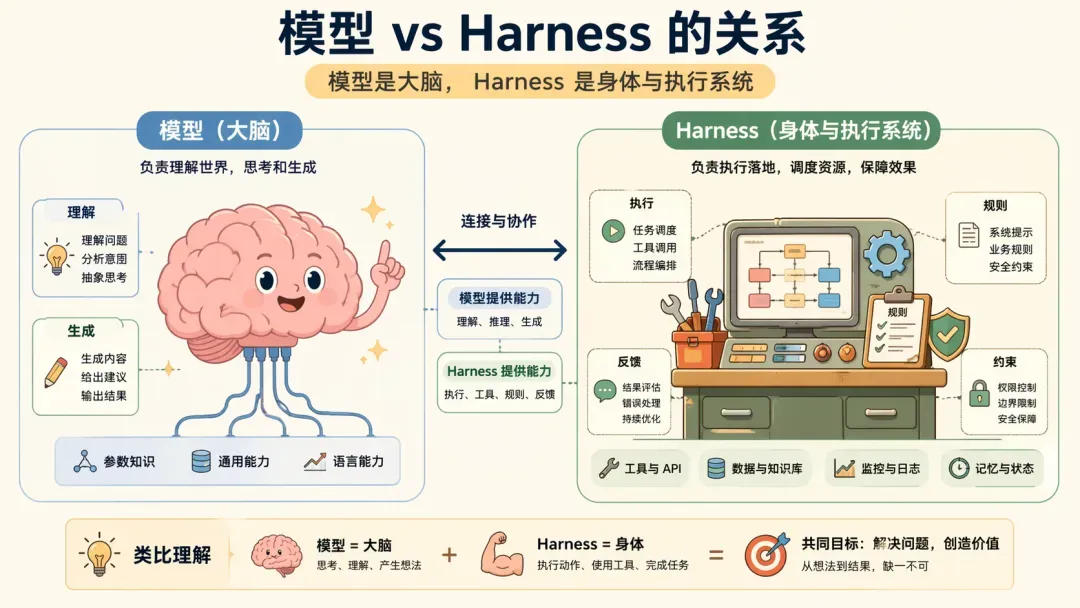
不过如果追求严谨,这类比喻并不能帮助具体展开。Harness 是工业化的产物,它不会只是一个 SDK 或提示词技巧,而是在项目中逐一啃下来的硬骨头的集合。所以更准确的理解是:
Harness,是把模型能力转化为持续、稳定、可验证产品能力的那套系统集合。
归纳起来,就是大量的规则、约束和设计。
Prompt → Context → Harness
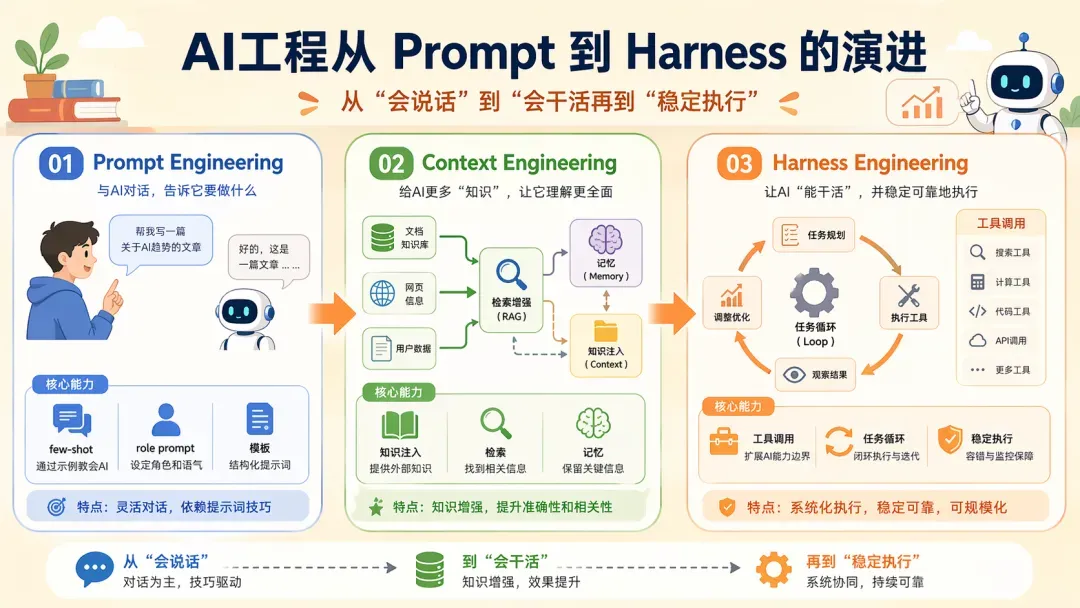
前面提到,Harness 是 Agent 开发过程中工程实践的产物,并不是凭空出现的。在其之前,工程产物分别是 Prompt Engineering 和 Context Engineering。因而可以认为:
上下文工程是对提示词工程的延续,而 Harness 则是这两种工程思想的结果。
1. Prompt Engineering
提示词工程直接解决“如何与模型交互”的问题,因其简单有效而最早受到关注,包括:
- few-shot
- role prompt
- CoT
- 输出格式约束
- 提示词模板
- ……
这一层的本质是把行业专有知识转化为自然语言指令。需要强调的是:无论工程怎么演进,最终都会回落至提示词,不少人认为现阶段的各类工程优化仍是提示词工程的延伸,这种看法并非全无道理。
2. Context Engineering
当任务变得复杂,仅仅写好一句 prompt 已然不够,于是出现了上下文工程,具体涵盖:
- 哪些私有知识需要带进上下文;
- 哪些历史对话应该保留;
- 如何处理超长上下文压缩;
- 如何做信息检索;
- 如何避免模型既不失忆,又不被信息淹没;
- ……
走到这一步,系统已经不再只是按标准操作流程作答,而是开始结合材料进行回答,其核心始终围绕 CoT 来做文章。上下文工程的本质是数据工程,所以真正做生产级 AI 应用的人往往陷入一个怪圈:80% 的时间都耗在数据处理上,甚至让人困惑:这种枯燥繁琐的工作究竟和炫酷的 AI 有什么关系?
3. Harness Engineering
再进一步,Agent 不再满足于简单问答,开始:
- 调用工具
- 运行代码
- 拆分任务
- 浏览页面
- 撰写文档
- 多轮循环
- 长时执行
- 子 Agent 委派
- 中断恢复
- 测试与验收
- ……
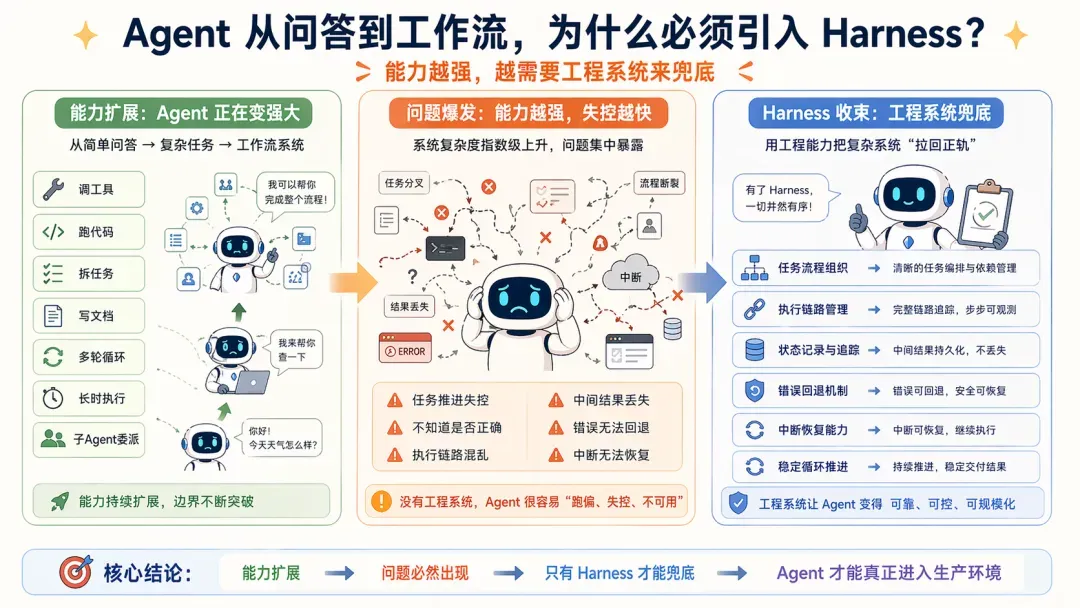
此前提到,Agent 的诞生本来就是为了解决 Workflow 泛化不足带来的繁重维护问题。 当工程复杂度急剧上升,上下文工程也不再够用,因为问题已经从数据范畴转向了:
- 任务如何持续推进而不失控;
- 模型如何判断自己的工作是否正确;
- 执行链路如何组织;
- 中间结果如何留痕;
- 出错了如何回退;
- 暂停后如何续接;
- ……
于是 Harness 便应运而生,而且其出现过程非常自然:
当 Agent 从问答介入工作流,从单轮对话走向长链任务时,被工程现实催生的一整套解决方案。
从 OpenClaw 与 Hermes 看 Harness
很多人觉得 Harness 很“虚”,问题往往在于我们脱离了真实框架来讨论。真正要谈,就必须回到 Agent 框架本身,把 Harness 放进 OpenClaw、Hermes、Claude Code 里去观察,马上就会变得具体。
这三种框架,刚好代表了三种典型的 Agent 工程取向。
1. OpenClaw:先把 Agent 管住
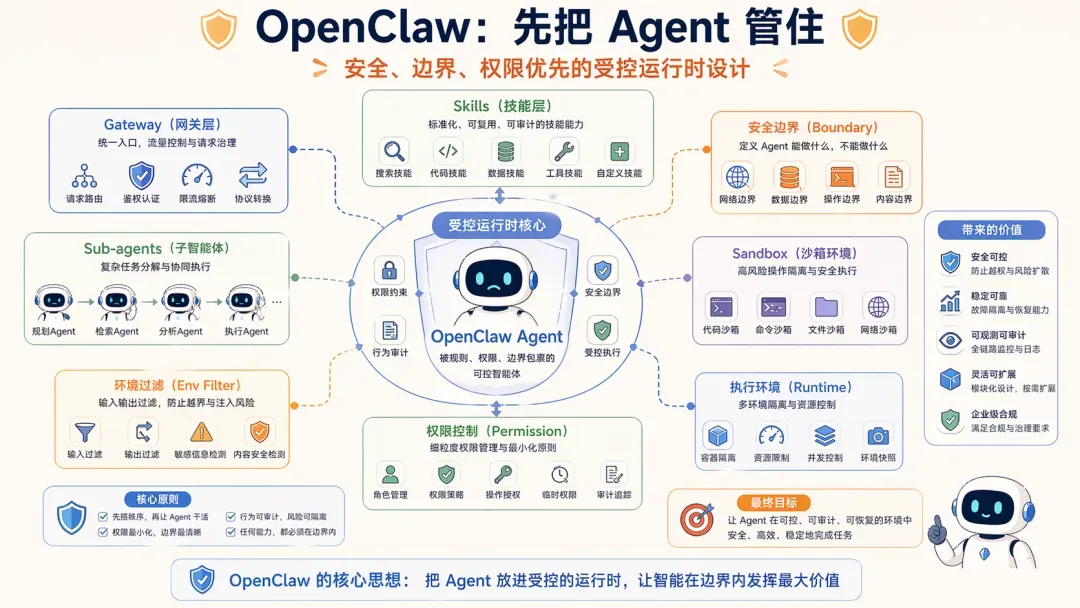
OpenClaw 的官方文档和公开仓库明显偏向受控运行时的设计。它把 Skills、Gateway、安全边界、Sub-agents、Sandbox 这些模块拆得很清楚。
例如,官方 Skills 文档明确指出 OpenClaw 使用 AgentSkills-compatible 的 skill folder,每个技能目录内都有 SKILL.md,加载时会根据环境、配置和依赖进行过滤。安全文档也反复强调:OpenClaw 目前假定部署在个人助理的安全模型下,即一个受信任的边界内运行,而不是无边界地授权给生产环境。
这种设计的系统工程目标非常清晰:先把权限、边界、角色、技能、执行环境组织起来,再让 Agent 执行任务。
因为 OpenClaw 的一个长远愿景是成为真正的企业 Agent 标配,因此其工程发力方向也很直白:如何让 Agent 安全、稳定、受控地执行任务? 当然当前产品在多人协作等方面仍不成熟,但这不代表方向错误。
2. Hermes:先让 Agent 长本事
Hermes 的 README 呈现出另一番气质。
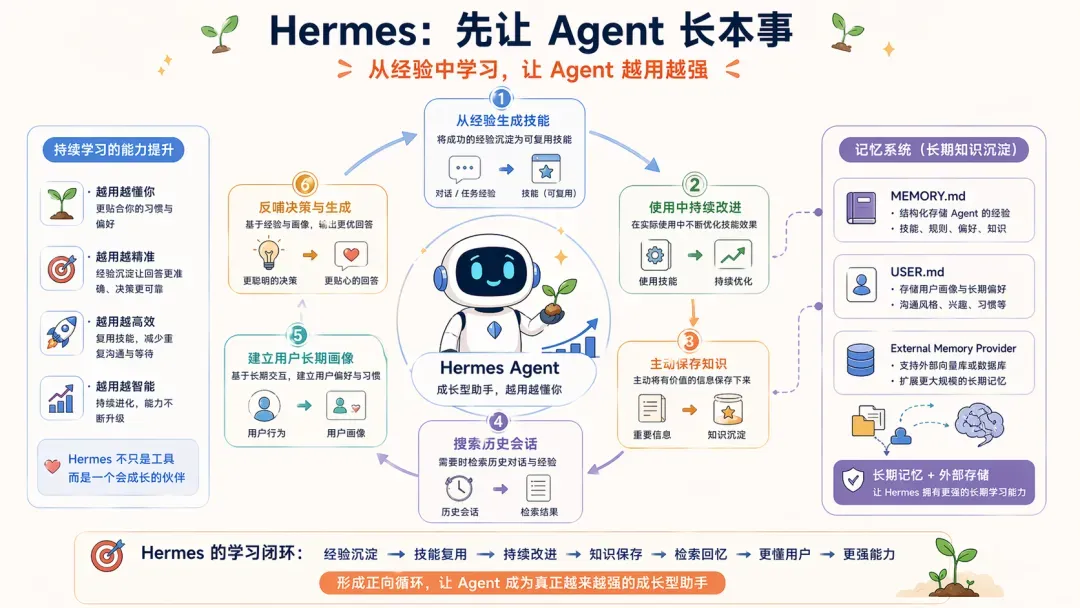
它将自身定义为“the self-improving AI agent”,并直接把核心能力概括为一串学习闭环:
- 从经验中创造技能;
- 在使用中改进技能;
- 自我督促沉淀知识;
- 搜索之前的对话历史;
- 跨会话逐渐建立对用户的深度认知模型。
Hermes 的官方文档还提供了 8 种 external memory provider,并说明内置 MEMORY.md / USER.md 始终可用,同时只允许启用一个外部 provider,以避免 schema 膨胀和冲突。
这也是我常觉得 Hermes 比较“鸡贼”的原因:它没有 OpenClaw 那般宏大的野心,暂时更专注于让个人用户获得良好体验,甚至是针对 OpenClaw 的一些痛点进行迭代。它的工程目标也很明确:先让 Agent 学会从经验中成长,再逐步补上边界和治理。
Hermes 瞄准的问题是:如何让 Agent 越用越强,越来越像一个长期助手?
3. Claude Code
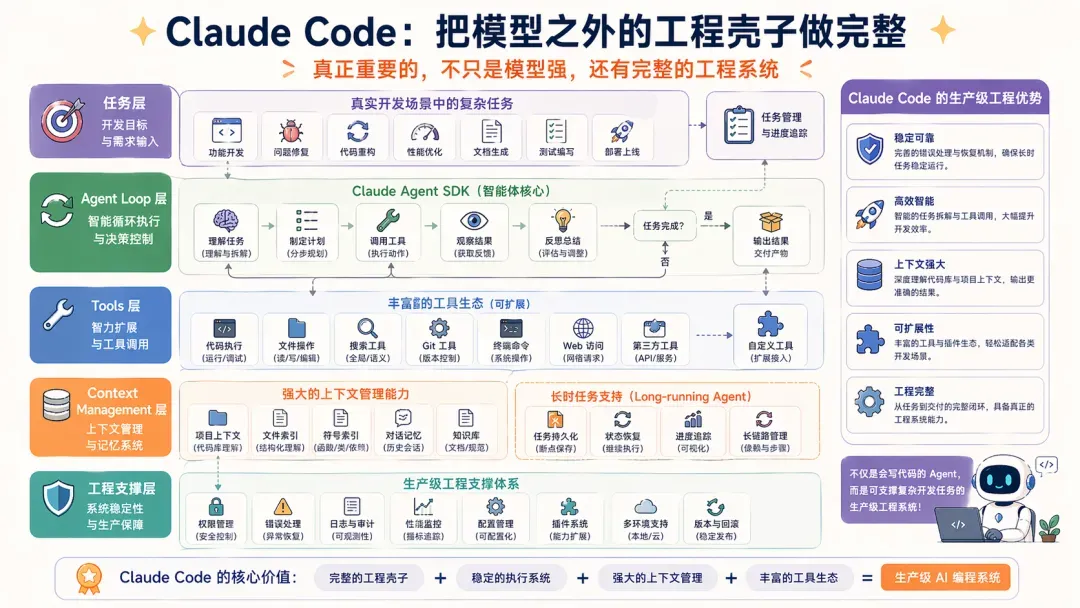
Claude Code 面临的场景与其他两者完全不同,它是正经的生产级应用,早已不只是一个“会写代码的 agent”。
Anthropic 已经把与 Claude Code 同源的能力开放为 Claude Agent SDK,并明确指出该 SDK 提供的正是 Claude Code 背后的 tools、agent loop 和 context management。同时,Anthropic 连续撰写了多篇工程文章,专门探讨长时 agent 的 harness 设计、应用开发场景下的 harness 优化,以及为什么 Claude Code 本身就是一个优秀的 harness。
可见,Claude Code 的价值不仅在于模型强大,更在于:它已经把模型之外那一整套工程壳子,做成了极具竞争力的存在。
因此,若想深入学习 Harness,从逻辑上讲 Claude Code 是最好的范例,但其完整代码并不公开,从复杂度来看,OpenClaw 或许是最佳的学习切入口。
拆解 Harness
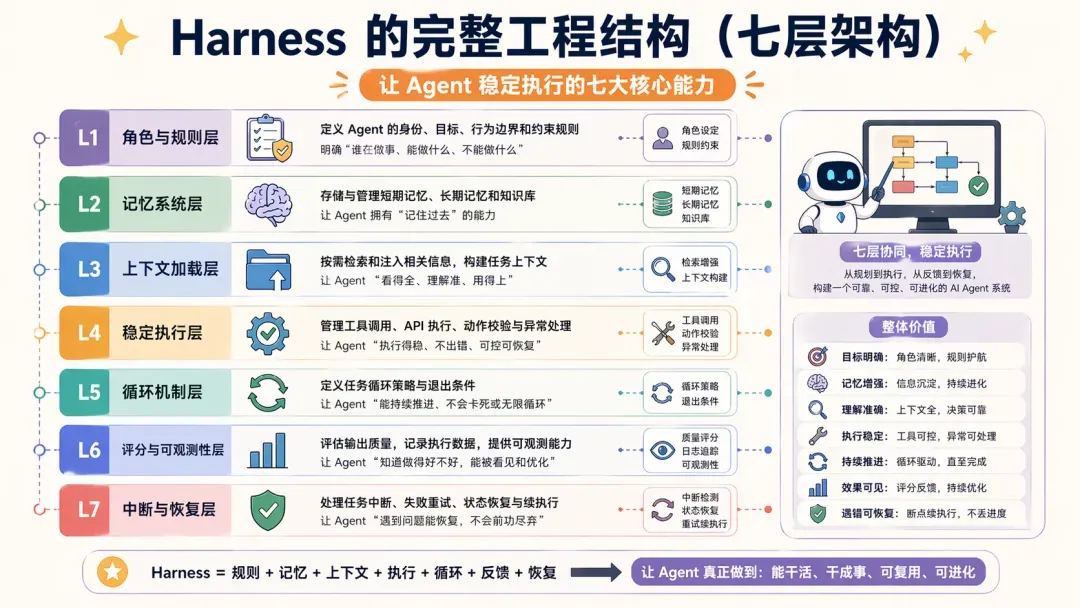
如果要把 Harness 拆开来看,我认为它至少包含七个层次。以下将结合自己的认知,并尽量用 OpenClaw、Hermes、Claude Code 来落地说明。
第一层:角色与规则
模型接到任务后,第一步往往不是调用工具,而是先明确几件事:
- 它是谁;
- 负责规划、执行还是验收;
- 边界在哪里;
- 遇到不确定的情况怎么办;
- ……
只要这些定位顶住,后续的所有动作就有了基本的控制力。
OpenClaw 在这一层做得非常标准:Skill 由人来写,规则是人定的,边界由系统设置,Agent 更多是在框架内执行。
Hermes 则更加灵活,它同样有系统提示词、角色定义和运行时规则,但更倾向于把一部分能力判断交给 Agent 自身,比如什么时候生成新 Skill,什么时候更新旧 Skill。
Claude Code 更接近工具即流程的思路:Anthropic 反复强调 agent loop、context management,以及长时任务中 initializer 和 coding agent 的分工,其实就是把角色与节奏预先嵌入系统。
因此,搭建 Harness 时最先要做的事,就是确定你当前以什么身份工作。
第二层:记忆系统
任务一旦拉长,必然会产生大量中间产物,例如:
- 拆解出的子任务;
- 讨论过的方案;
- 目前进行到哪一步;
- 用户偏好;
- 历史错误;
- 成功经验;
- ……
再长的上下文窗口也经不起无节制的浪费,于是不同框架的工程差异便显现出来。
OpenClaw 对记忆的态度是克制的,本质上更接近于可替换的能力位,意思是:我提供最基础的实现,你根据自己的情况来替换。
Hermes 则将记忆构建成一套完整体系:内置 MEMORY.md、USER.md,再加上 external memory provider,以及 session search。官方文档明确说 built-in memory 始终启用,外部 provider 只允许同时存在一个,核心原则仍是:别折腾了,用我的就对了。
正因如此,用户会有明显的感受:OpenClaw 经常不在意我昨天说了什么,而 Hermes 虽然偶尔也犯糊涂,但我知道为什么……
Claude Code 的官方文章则更强调另一条路线:在长时任务中,清晰的 artifact 和 handoff 格外重要,它们能让下一次 session 接续前一次的工作。
系统工程里,记忆系统的本质始终围绕着同一个命题:任务过程能否留下痕迹,系统下一次还能否接得上去。
第三层:上下文加载机制
到底给模型看什么? 这是所有 AI 应用都会碰上的难题,有时甚至怎么做都感觉不够理想。
因为在真实的 Agent 场景中,模型可获取的信息越来越庞杂:角色与规则、历史对话、记忆、技能、工具结果、当前任务……
问题由此而来:不是信息不够,而是信息太多。
OpenClaw 的 Skills 加载逻辑,本质上就是一种上下文过滤:按环境、配置和依赖进行筛选。
Hermes 则采用了另一种方式:其 session search 并非把历史原文一股脑灌进去,而是先检索,再经过处理。它还支持 context engine plugin,用插件替代内置的上下文压缩器。
因此,如何做到每一轮只给模型提供当前最需要的那部分信息,在我看来是所有模型工程中最困难的一环。这一层再往下延伸,会涉及到私有数据加载的问题。如果做不好,系统就会陷入两种极端:
- 提供的信息太少,表现得像失忆;
- 塞入的信息太多,开始变得愚蠢。
第四层:稳定执行
Agent,或者说 ReAct 框架,是模型时代我们选定的范式。从这一层开始,Agent 真正开始动手干活,主要涉及:
- 工具怎么接入;
- 指令怎么执行;
- 文件怎么读写;
- 页面怎么浏览;
- 代码怎么运行;
- 结果怎么回收;
- ……
这些 Tools 相关动作全部属于工程范畴,而且由于它们依赖第三方,频繁出问题几乎是必然的。
OpenClaw 在这一块是典型的安全优先运行时设计。Hermes 则更像是执行后端可切换,官方 README 表明它可以运行在本地、VPS、GPU 集群或者接近零空闲成本的 serverless 环境中。
所以 Harness 的第四层要解决的是:将语言判断稳定地变成真实世界的动作。缺少这一层或做得不好,就会频频出错。
第五层:有效循环
普通的聊天问答已是 AI 1.0 的产物,自 DeepSeek 之后,我们已进入追求多轮交互的阶段,而 Agent 则因为处理复杂任务的需要,不可避免地要进入循环:
- 理解任务;
- 决定下一步;
- 执行;
- 读取结果;
- 判断下一步怎样走;
- 反复循环直到收敛。
OpenClaw 的多 Agent、Skills、Runtime 都是在为这种循环推进提供支撑。Hermes 则将 delegate、skills、memory、search、provider hooks 都嵌入到这个循环里。
前面讲过,更多的智能必然意味着更高的 Token 消耗,Agent 循环的核心问题也在于此:会不会白白消耗 token 和时间,却没有实质推进?
在工程系统的设计里,我们担心的从来不是循环本身,而是钱花出去了,事情却没有进展……
第六层:评分与可观测性
大模型存在一个显著的缺陷,并非它做不到,而是它常常误以为自己已经完成了任务。
表面看,代码写了,页面渲染了,回复也发出了,好像事情已经闭环。可一旦实测,就会发现很多地方其实根本没有走通。
因此,在系统工程的各个关键节点上,我们都会埋设评价点,目的就是建立评分与可观测性机制。
也就是说,系统不能只听模型自己汇报“我完成了”,而要能通过测试、日志、页面验收、运行指标、人工审查、Benchmark 等多种方式,确凿地看到它做了什么、做到何种程度、结果到底是否达标。
如何让人类对 agent 的结果产生信任? 这种信任不可能仅靠模型自述来建立,而必须依赖外部反馈回路。
Anthropic 的 harness design 文章也在探讨类似问题:为了让长时应用开发表现更好,仅有 agent loop 不够,还需要更强的环境与反馈壳体。
OpenClaw 通过规则、沙箱和受控执行来约束结果,走的是制度化路线。Hermes 则更偏重学习闭环:将执行结果、错误路径和成功经验逐步沉淀为 Skill 或 Memory。
这一层的目标十分明确:别让模型稀里糊涂地给自己打高分。
第七层:中断修复
这一层是工程控制的核心环节。
我们习惯希望流程一次性完美结束,但现实并非如此。人以 SOP/Workflow 做设计时也常常应付不了边界的回退需求,模型在此处同样会面临类似困境。因此,Agent 在循环往复的过程中,整体的流程会不会倒退、如何优雅地倒退,就显得尤为关键。
第七层平时看起来烦琐,可一旦任务真正跑起来,你会发现它极其重要,因为任务真的会中断、会超时、会切换 session、会失败重试……
Hermes 通过 MEMORY、USER、session search、external provider 将接续能力系统化。OpenClaw 则更强调流程与痕迹的受控机制。
所以做系统工程,最终就要面对这一层:如何把断掉的任务重新接上?
至此,Harness 的主体已经基本探讨清楚。接下来,让我们用 OpenClaw 来具体走一遍,帮助大家更直观地理解 Harness 的形态。
以 OpenClaw 来理解 Harness
上文用概念讨论了大量关于 Harness 的内容,那么当一个 Agent 框架真正跑起来后,这套所谓的 Harness 具体长什么样? 下面将以我比较熟悉的 OpenClaw 展开说明。
第一,MCP / 工具链
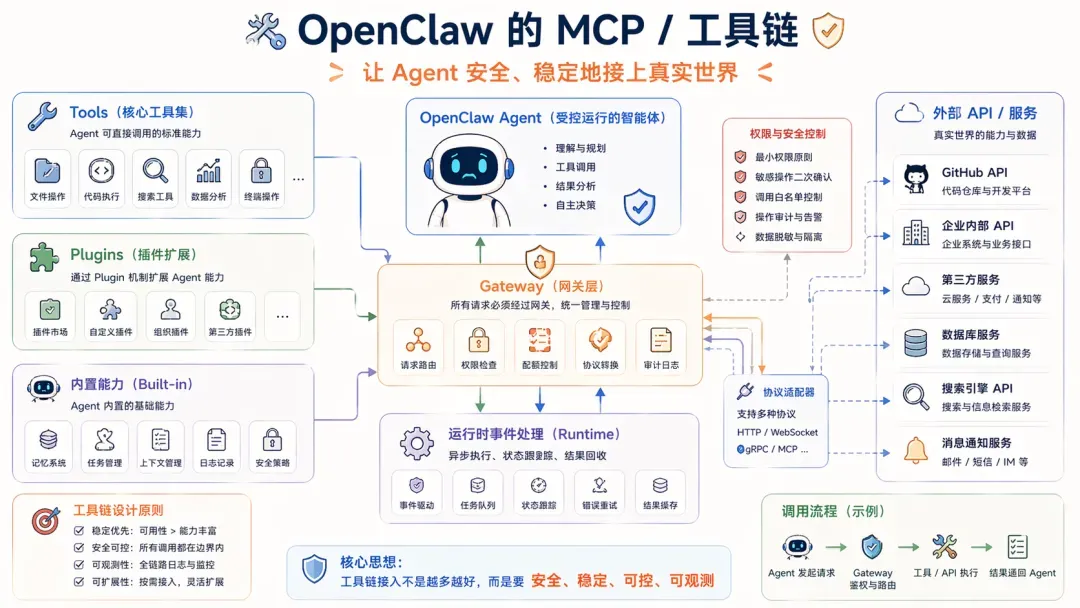
很多人一提到 OpenClaw 就会想到 Skills,这确实没错,Skills 很核心,也是每个人与 Agent 交互的入口。但如果从 Harness 工程稳定性的角度出发,MCP/工具链这一层其实更为关键,因为 Agent 一旦开始实际工作,首先要解决如何安全、稳定地连接真实世界的问题。
Skills 是方法稳定器,目的是不让模型过于发散;MCP/工具链则是能力底座。
Skills 出问题,系统就会乱做,同样的输入得到不同的输出;而 Tools 一旦出问题,整个流程就会中断,而且这部分主要依赖第三方,本身就容易出问题,比如:
- API 变动;
- 权限变更;
- 插件失效、参数变化;
- ……
因此工程系统必须先定义能力规范。OpenClaw 在这点上相当典型,它将 Tools、Plugins、Gateway、外部能力接入都收拢到一个有明显边界的系统中,目的在于:让模型在一个被约束的能力平面里,稳定地调用工具。
举个常见场景:某个外部 API 挂了。 如果缺乏工程控制,模型可能根本分不清这是自己理解有误还是上游接口出错。此时模型的表现会像个笨拙的循环机器,白白燃烧 token 和时间,甚至直接告诉下游:“我搞定了。”
此刻 Harness 的价值就表现得淋漓尽致。以 OpenClaw 这类系统为例,正确处理方式是把 API 调用失败当作运行时事件来对待,将工具调用纳入由 Gateway 管控的运行时平面。具体细节太多,这里不展开……
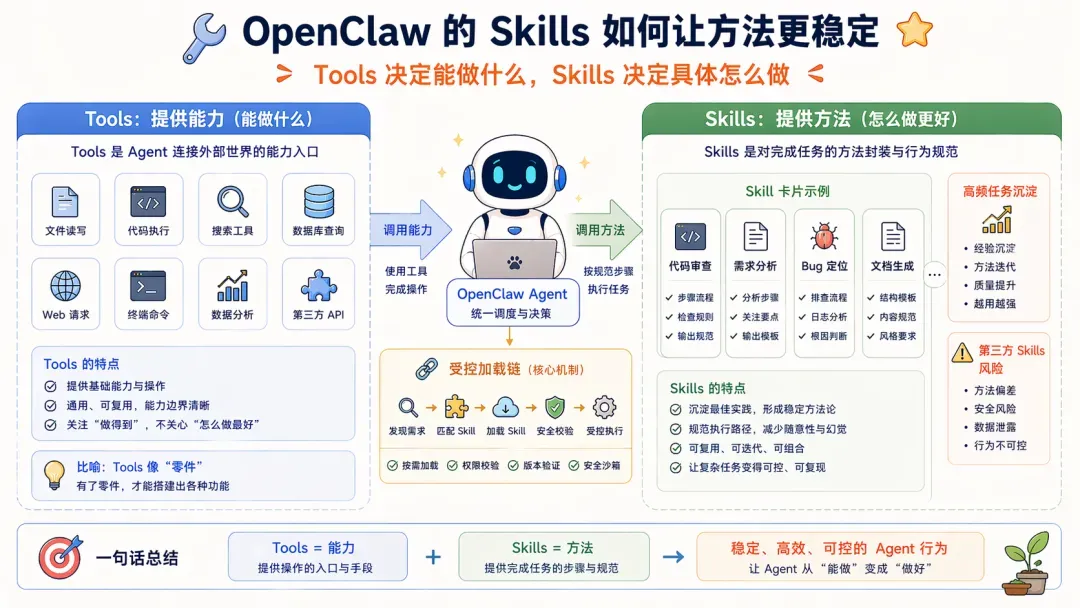
第二,Skills
在能力底座搭好之后,Skills 才登场,这东西非常重要:
- Tools 解决能做什么;
- Skills 解决这些事具体该怎么做;
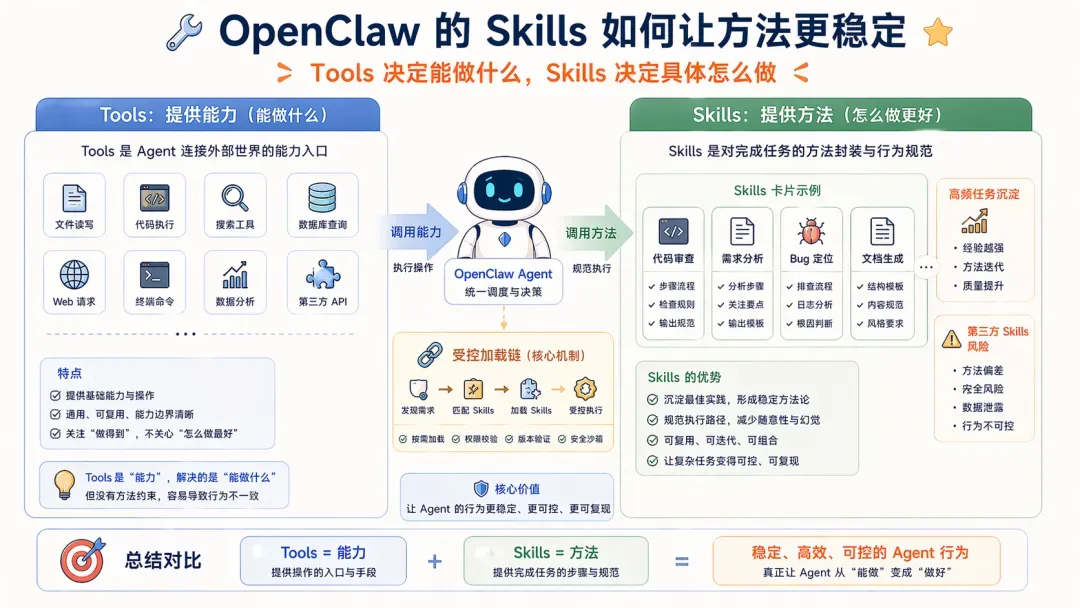
Skill 这一概念先天优秀,其按需加载的机制从诞生起就能部分缓解工具调用错误的问题,而 Workflow 提示词进一步带来了稳定性,比如可以把高频任务的方法沉淀下来。
但在 OpenClaw 这类平台型 Agent 里,Skills 的问题同样突出:
- skill 可能来自第三方;
- skill 会实质性地进入 prompt 构建链路;
- 模型本身脆弱,很容易被恶意或低质量的提示词污染;
- 一旦 skill 机制失控,Agent 的方法层就会出现整体失真。
所以在系统工程里,Skills 这套机制在成为流行之前,它本身就应该被归入 Harness 框架,我们也确实有过类似实践。而如今 Skills 被底层实现后,我们更关心的是:怎么让这套开放机制不至于把整个系统拖垮。
这里又使用了各种规则约束,大家会发现工程系统会产生大量约束。以 OpenClaw 为例,首先就强调,第三方 Skills 本来就是不可信的。接着还需要做进一步的兜底策略,比如把 Skills 放入受控的加载链中:
- plugin skills 仅是低优先级路径,同名 skill 会被 bundled / managed / agent / workspace skill 覆盖;
- workspace 和 extra-dir 的 skill 发现,只接受解析后 realpath 仍在配置根目录内的 skill root 和 SKILL.md,避免路径穿越和任意逃逸。
另外还有很多兜底策略,细节不再展开……
第三,Runtime
再往下走,问题就不再是工具与技能调用了,而变成:一个复杂任务到底该怎么持续推进?
OpenClaw 在执行复杂任务时会进入一个循环:
- 先理解问题;
- 决定下一步;
- 然后调用工具、读文件、跑代码;
- 接着查看返回结果;
- 再判断接下来做什么;
- 持续循环,直到任务真正收口。
但真实情况总是 Bug 频出。模型一旦进入长任务,就开始展现各种问题:
- 可能还没做完就提前收尾,明明事情未完却告诉你已经搞定;
- 可能做了一半又绕回原点,反复调用同一个工具;
- ……
因此,从工程侧一定期望有一个东西能厘清:
- 当前任务进展到哪一步;
- 下一步该谁来做;
- 什么时候继续;
- 什么时候暂停;
- 什么时候打回重做;
- ……
OpenClaw 的 Runtime 正是在承担这一角色,它会尝试将 Agent 的一系列零散动作,组织成一条真正可以推进任务的流程。这个 Runtime 里包含了整个项目的可观测性和中断重试逻辑,内容同样比较复杂,不再展开……
但相信到这里,大家对于 Harness 到底是什么,已经又有了更深一层的认识。
结语
Harness 不是一个模块,而是一条路——一条啃过无数硬骨头后走出来的方法论。
我们可以清晰看到一个 Demo Agent 怎样一步一步走向 OpenClaw 这样的系统:
- 一开始只是接入工具;
- 随后发现工具不稳定,于是加上规则;
- 再发现规则不够,又引入 Skills;
- 之后意识到 Skills 还不够,就补充 Runtime 和 Workflow;
- 又发现任务会虚假完成,于是补上评分与可观测性;
- 再发现任务会中断,进而补全恢复能力;
- ……
当所有问题差不多被覆盖一遍之后,你会发现,所有的动作已经不能用某个小优化来概括:
Agent 从会说到会做,再到能稳定做完,整条链路上所缺失的全部工程能力,合在一起便是 Harness。
所以,Harness 以后未必还叫 Harness,但这条路,一定不会消失。