如何用NAS弥补MacBook存储与接口短板?极空间实战指南
苹果新推出的MacBook Neo,其市场热度似乎超越了早前发布的Mac mini M4。这两款设备我都有亲身使用,客观而言,基础配置的Mac mini M4在性能层面确实显著领先于MacBook Neo。
两者的价位处于同一区间,但Mac mini M4缺少内置屏幕、键盘及电池。相比之下,Neo虽然在性能上稍逊一筹,却因其便携特性更契合移动轻办公的需求。

然而,MacBook Neo的不足之处也相当明显。不仅基础内存仅为8GB,其接口配置也被大幅简化,最高传输速率限制在10Gbps,且起步存储容量仍是256GB。我入手的正是这款256GB的最低配版本。鉴于我已拥有NAS设备,实在没有必要额外花费700元去升级至512GB版本。
总体来看,这一配置足以满足对电脑性能要求不高的用户,或作为备用机使用。当然,如果和我一样拥有一台NAS,实际的使用体验还能得到更进一步的优化。

接下来,我将以自己正在使用的极空间NAS为例,分享几个通过搭配NAS来提升MacBook Neo使用体验的具体方法与功能,供各位参考。需要说明的是,这些技巧不仅限于Neo,几乎适用于所有Mac设备,毕竟Mac与NAS的组合堪称天作之合。
一、 必开功能:时间机器备份
如果您正在使用Mac设备,并且非常看重系统与数据的安全,同时又拥有一台极空间NAS,那么完全可以利用极空间自带的Mac备份功能。它能让您的Mac自动将系统、文件、照片、软件设置等所有重要数据备份到NAS中。日后无论是系统重置需要恢复,还是更换新机迁移旧数据,都将变得异常轻松。

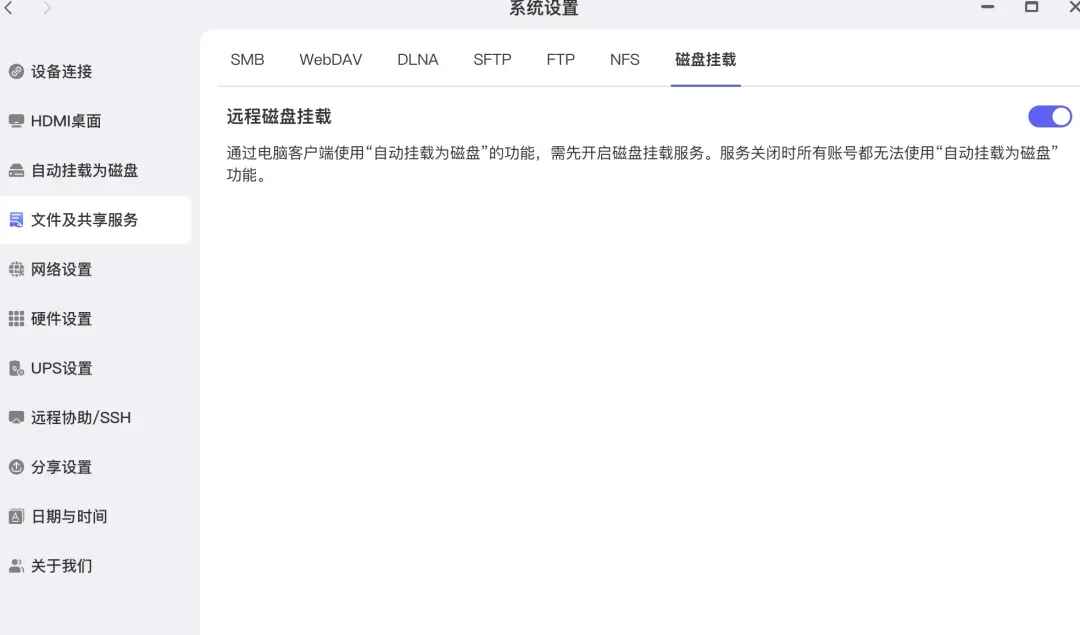
操作流程十分简便。首先,在极空间的管理后台,找到“文件及共享服务”设置,开启其中的SMB协议。
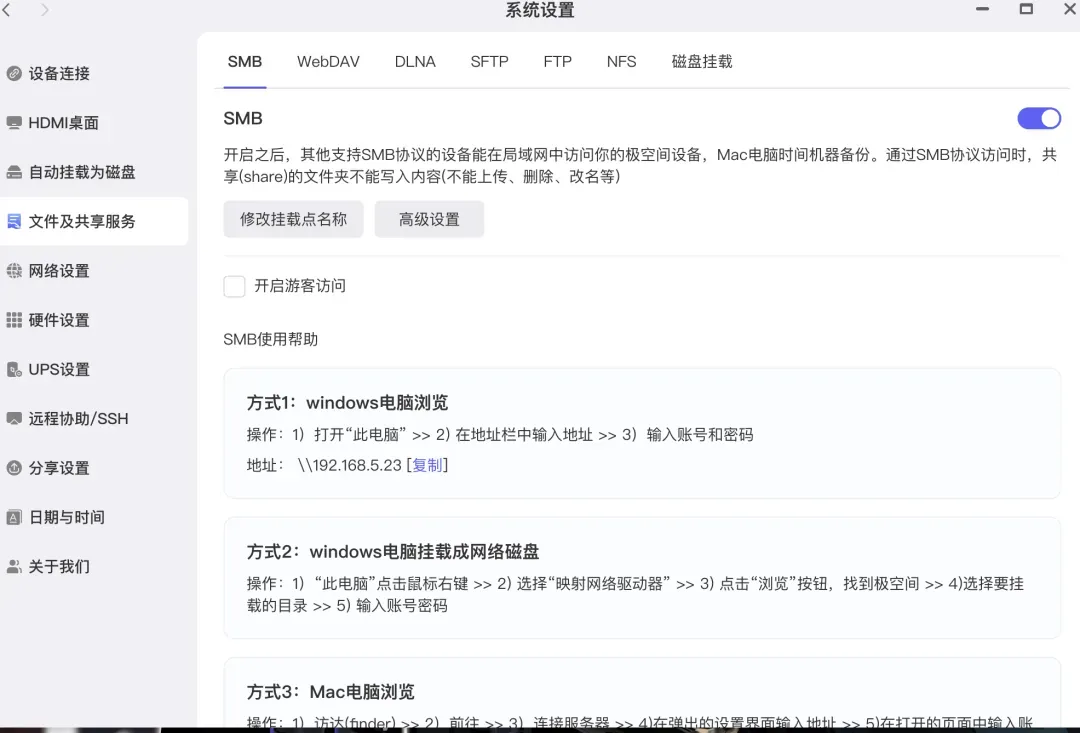
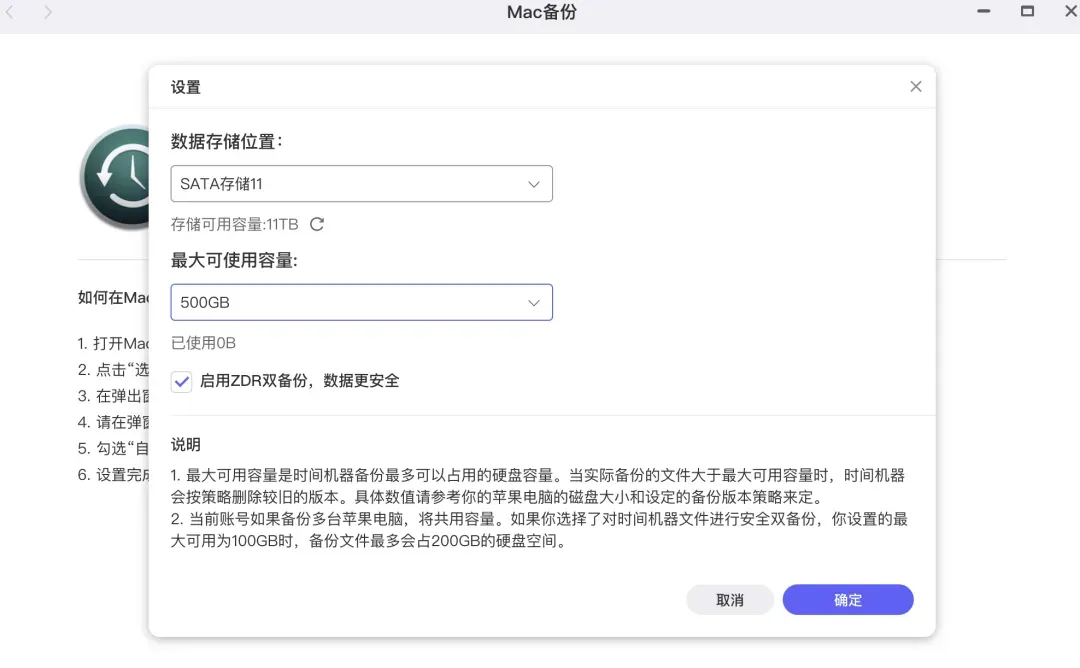
接着,在极空间桌面应用中找到“Mac备份”功能并启用,根据提示设置好备份数据的存储位置、最大使用容量等参数,然后确认即可。
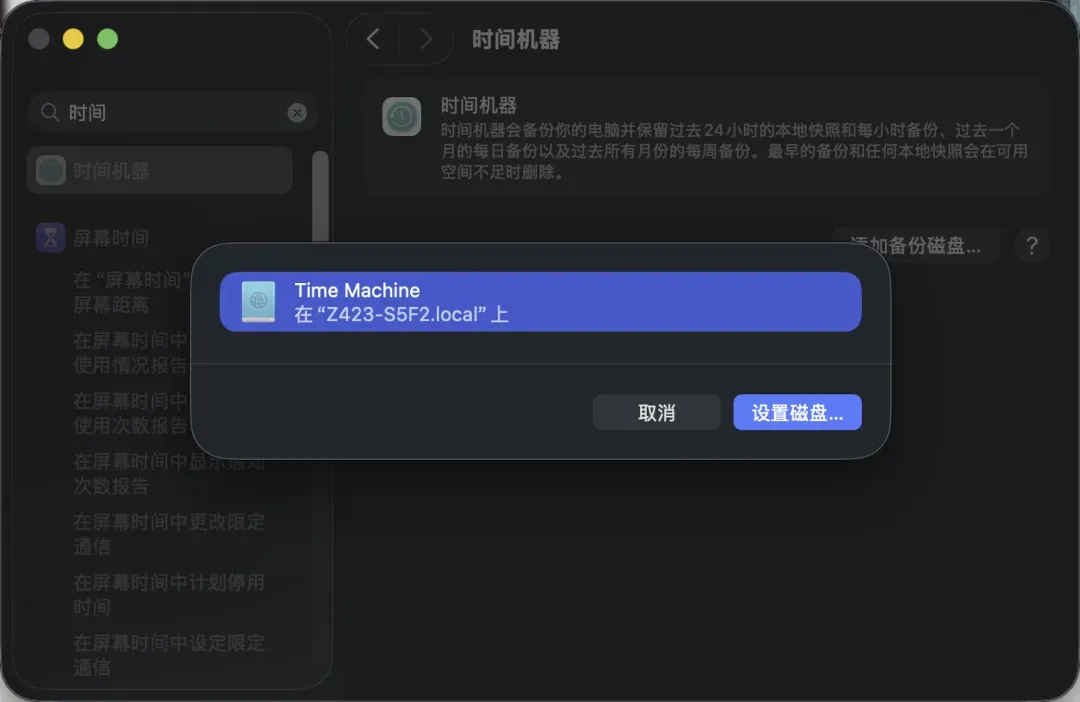
接下来,在Mac电脑上打开“系统设置”,找到“时间机器”选项并进入,将备份磁盘选择为您刚刚设置好的极空间NAS。
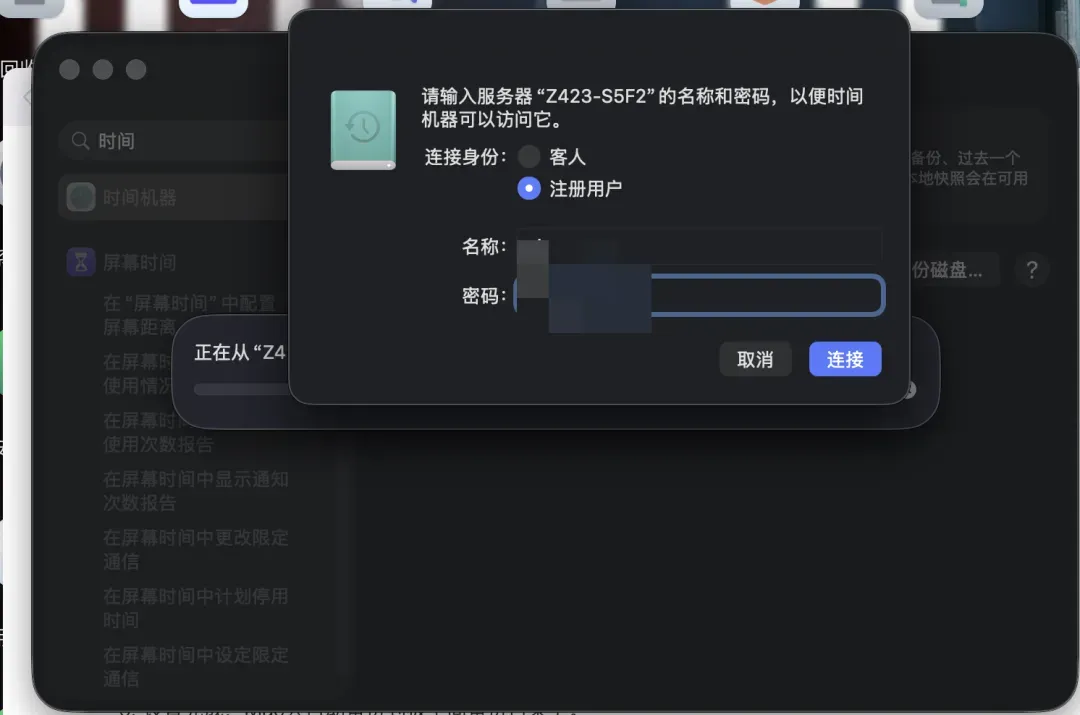
输入极空间NAS的账号和密码,点击连接。
如果需要更高的安全性,可以开启加密备份并设置密码;若无需加密,则关闭该选项。同时,可以自定义备份磁盘的使用空间比例。全部设置完成后,点击“完成”。
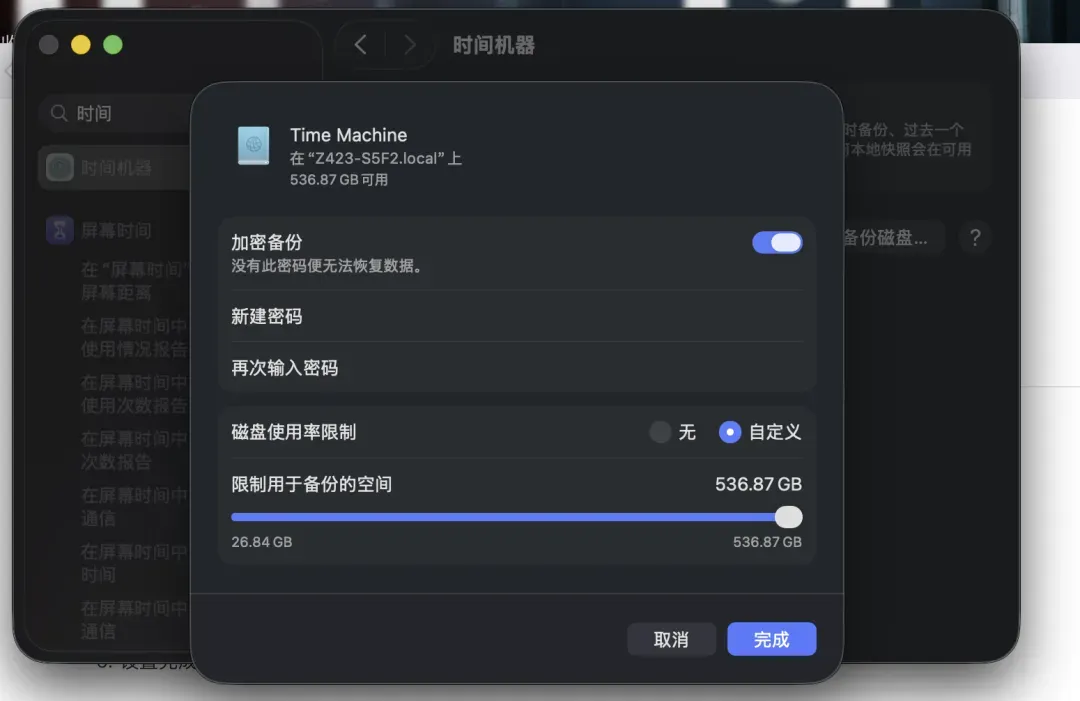
此后,您便能在时间机器中看到新创建的备份任务。只要Mac处于联网状态,它就会按照您预设的条件自动进行备份,完全无需担心遗忘。当未来需要时,随时可以从中恢复数据。
Mac备份不仅仅是简单的文件拷贝,它相当于为Mac数据购买了一份“保险”,能够实现系统级别的完整恢复。整个过程自动、安全且省心。此外,一台NAS可以为多台Mac设备提供独立的备份空间,非常适合团队协作或家庭成员共同使用。
二、 存储“扩容”:本地挂载硬盘
熟悉苹果产品的用户都清楚其设备存储容量的昂贵,并且无法像大多数Windows笔记本那样自行加装或更换硬盘。升级设备往往意味着连同存储一起更换。对于已经选择了Neo的我而言,更没有必要投入更多成本去追求更大的内置存储。
然而,现实情况是,256GB的存储空间确实容易捉襟见肘。如果仅用于WPS处理文档尚可,但一旦安装PS进行图像处理、下载Final Cut Pro进行视频剪辑,再配合几个提升效率的截图、翻译等工具软件,存储空间很快便会告急。
不过,正如前文所言,拥有NAS便无需焦虑!
将MacBook Neo与极空间NAS搭配使用,可以直接把NAS的存储空间挂载为Mac本地的一个虚拟磁盘,专门用于存放大型文件。此功能在极空间的系统设置中即可一键开启。
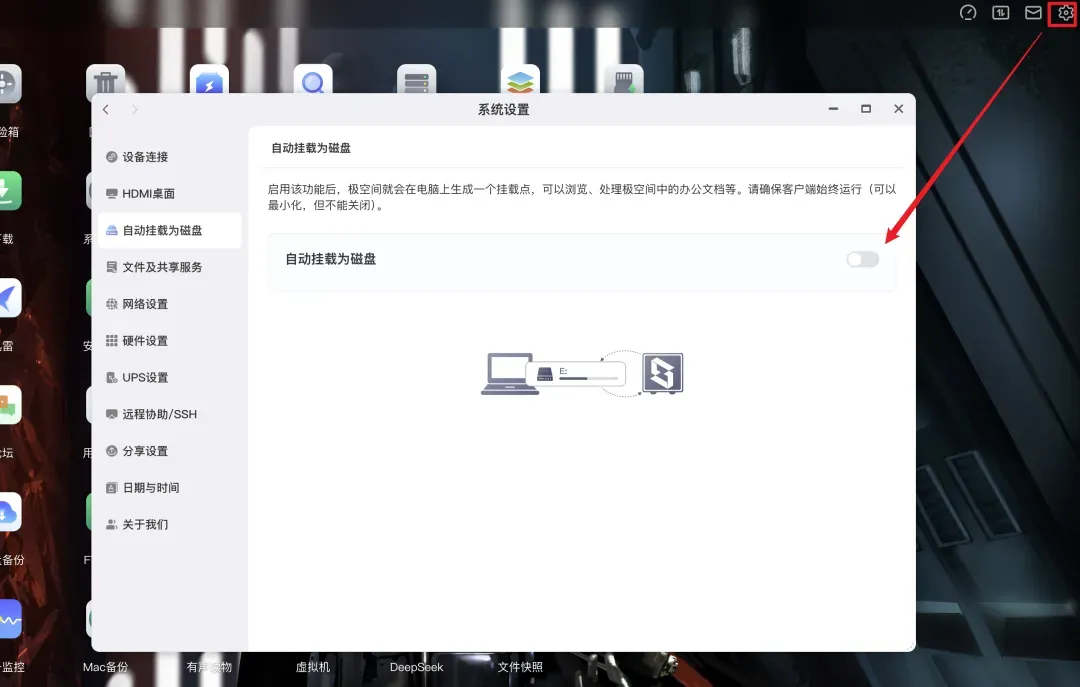
首次开启时,需要下载一个小插件,并设置一个本地临时缓存目录。整个设置界面极其简洁明了,操作起来毫无难度。
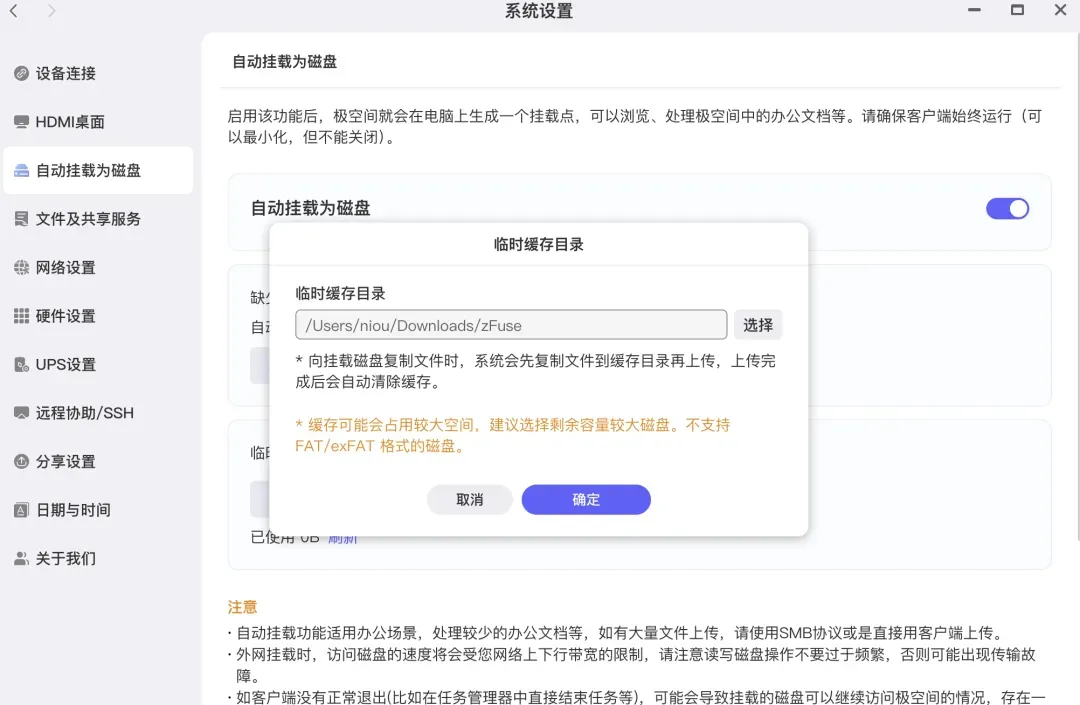
既然选择MacBook Neo是为了满足移动办公需求,那么在外出使用、处于外网环境时,挂载的磁盘是否还能访问?答案是完全可行。只需在极空间的“文件及共享服务”中,同时开启“远程磁盘挂载”功能即可。
开启本地与远程挂载后,MacBook Neo仅有的两百多GB本地存储几乎可以完全用于安装应用程序。下载的各种文件则可以直接绕过本地存储,保存到NAS上。甚至是从网盘下载的资源,也能直接存入NAS。方法同样简单,借助极空间自带的“网盘备份”或“远程网盘挂载”功能即可实现。
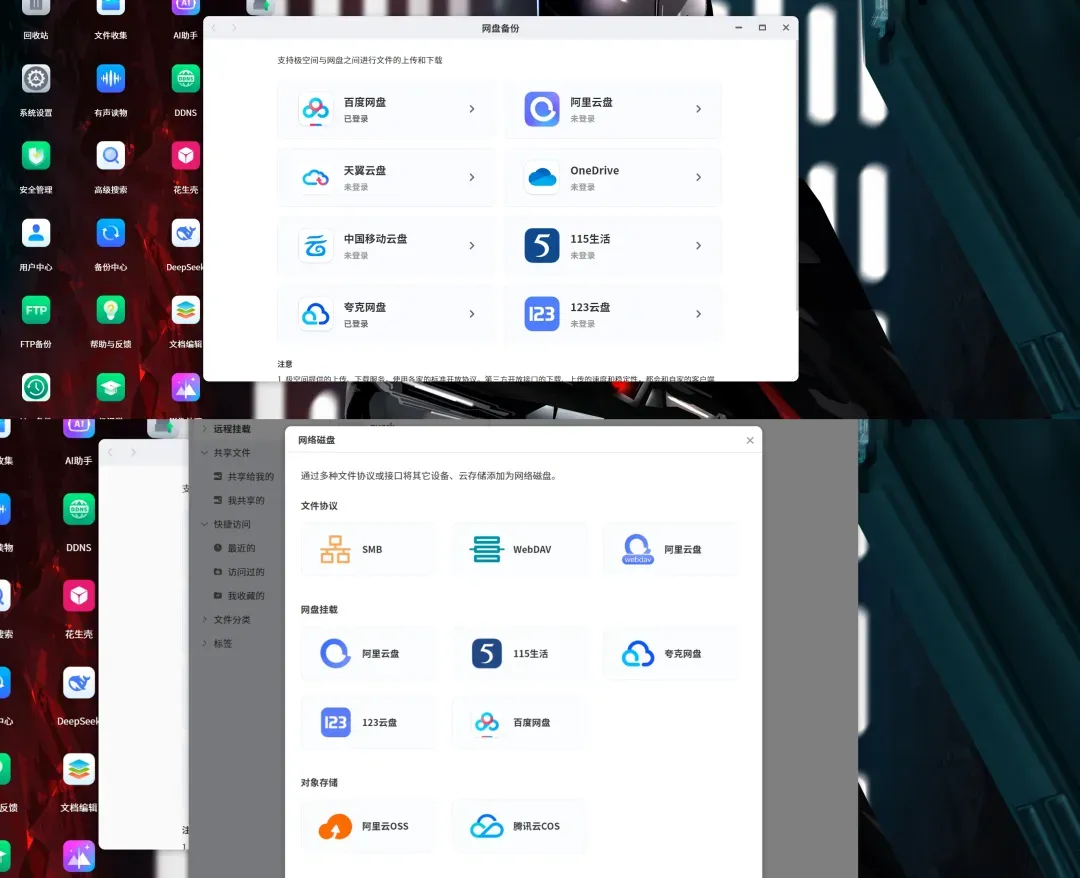
对于通过浏览器下载的文件,大部分浏览器都允许自定义下载保存位置。我个人习惯使用夸克浏览器,并在极空间上专门建立了一个文件夹,将浏览器的下载路径指向此处。这样既便于文件管理,也能及时清理无用内容。
三、 Win+Mac双系统:Windows虚拟机
很多时候,我们既欣赏macOS的简洁优雅,又离不开某些Windows独有的功能或软件。同时购置两台笔记本电脑显得多余且浪费,而通过Mac远程访问家里的Windows台式机虽然可行,却不够便捷。在拥有MacBook Neo的情况下,其实还有另一个优雅的解决方案:在NAS上安装一个Windows虚拟机,随时启动或关闭。
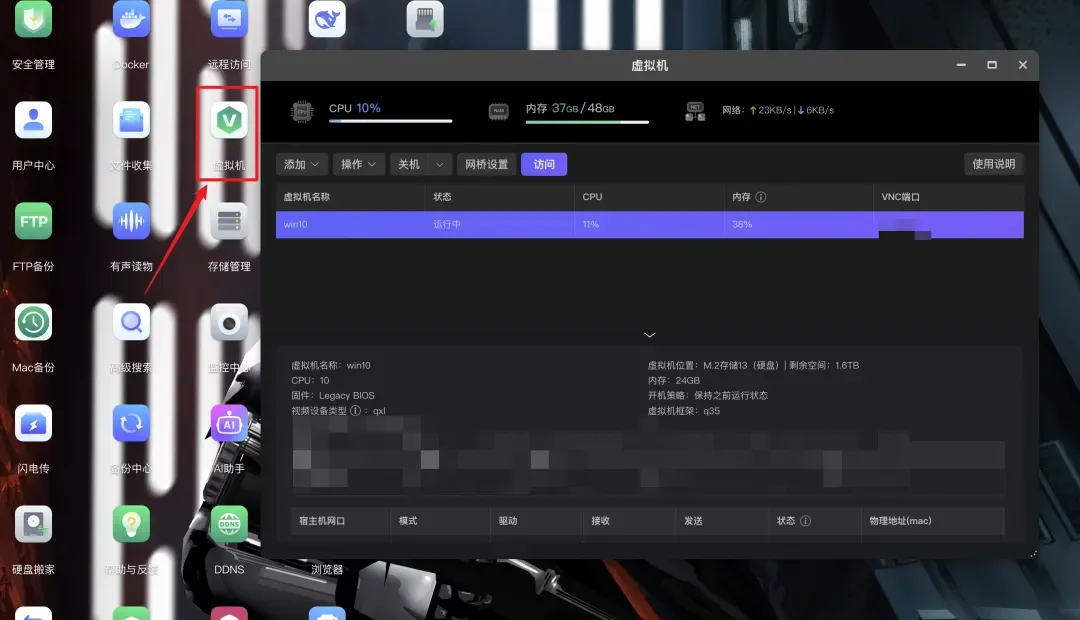
极空间自带的虚拟机功能可以快速部署Windows系统。我的这台Win10虚拟机已经稳定运行了近两年。关于虚拟机的具体安装步骤,如果不太熟悉,极空间官网提供了非常详尽的图文教程,只需跟随指引操作即可,此处不再赘述。
由于极空间NAS支持直接的外网访问,因此在外出办公时,只要Mac设备能够联网,打开极空间客户端就能随时随地访问这台Windows虚拟机。同一个虚拟机也支持被不同的电脑访问,在公共电脑上使用虚拟机处理敏感文件,相比直接在本地操作也更为安全。
当然,如果工作流中需要其他操作系统(如Linux),同样可以通过虚拟机功能进行安装。
四、 工作文件备份:文档同步
对于日常办公中频繁使用电脑的用户而言,通常会积累大量文件,且同一文件可能衍生出多个甚至数十个不同的版本。对于仅有256GB存储空间的MacBook Neo来说,要妥善且高效地管理这些文件,压力不小。但有了“文档同步”功能,局面将大为改观。
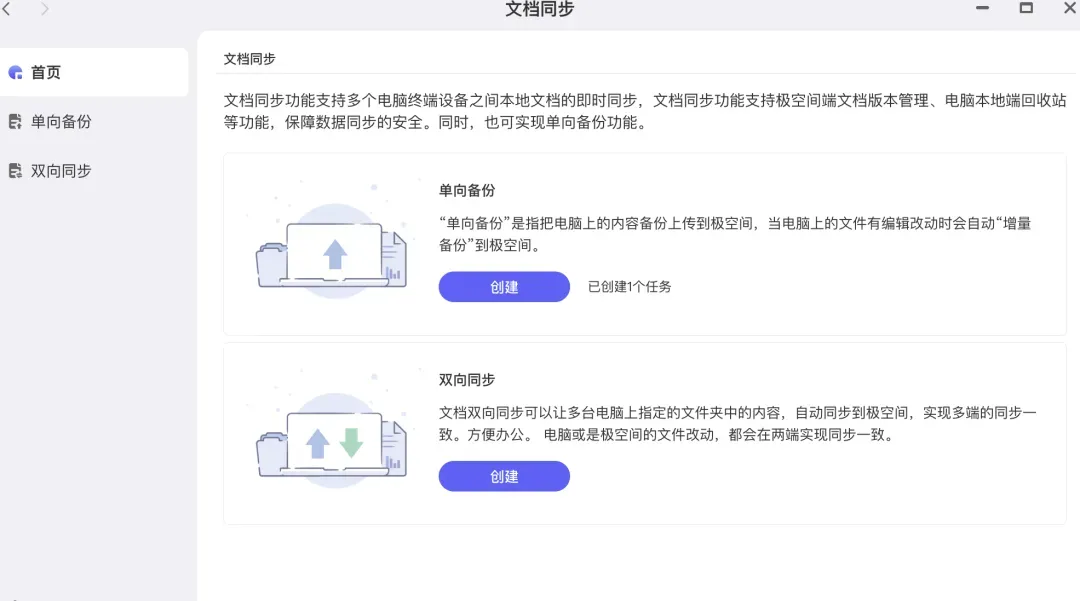
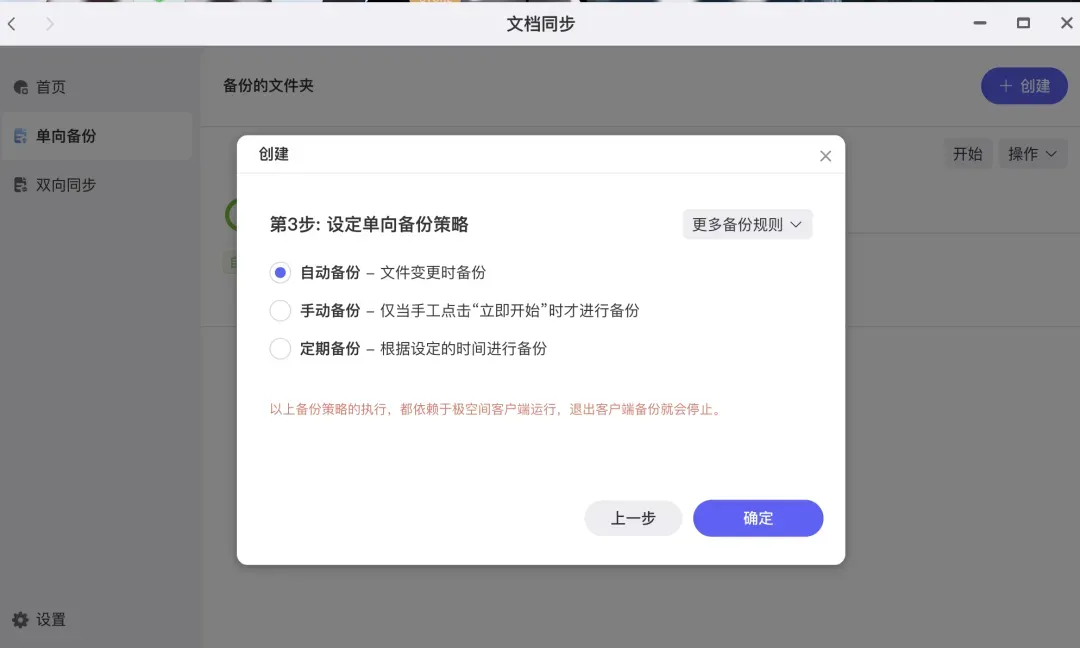
极空间的文档同步支持两种模式:单向备份和双向同步。单向备份是指将电脑上的文件同步到极空间NAS中,即使后续在电脑上删除了原文件,NAS上的备份副本依然会保留。
如何用家用NAS轻松搭建本地AI助手:基于LocalAI的完整部署与体验指南
想象一下,你的家庭网络附加存储设备不仅用于存放文件与媒体,还能化身为一个在本地运行的智能助手。这一切可以通过一款名为 LocalAI 的开源工具实现。下面将详细介绍如何将其部署在NAS上,并开启私有的AI对话体验。

LocalAI是一款遵循开源协议、完全免费且以本地运行为优先的AI推理框架。它的核心目标在于提供一个与OpenAI API规范高度兼容的本地REST API接口,同时也能适配Elevenlabs、Anthropic等其他服务的协议。该框架支持在消费级硬件上私有化部署大语言模型、图像生成与音频合成等多种AI能力,其突出特点是无需依赖独立GPU也可顺畅运行,并能兼容多种模型架构。
核心特性解析
- API 高度兼容:作为OpenAI API的即插即用式替代方案,任何基于OpenAI API开发的现有应用程序都可以低成本、无缝地迁移至本地环境。
- 彻底的本地化部署:支持在普通的消费级硬件上运行,即使没有独立显卡也能正常工作。所有数据处理均在本地完成,数据无需上传至外部服务器,充分满足用户对隐私保护和数据合规性的严格需求。
- 支持多模态能力:不仅局限于大语言模型的文本推理,其功能范畴还扩展至图像生成、文本转语音等音频合成领域,提供了一个较为全面的本地AI工具箱。
- 丰富的模型生态:内置了“模型画廊”,支持通过命令行或API便捷地安装来自HuggingFace等平台的模型。默认提供了大量采用宽松许可协议的模型库,同时也允许用户添加自定义的模型仓库地址。
- 灵活的后端支持:其底层设计兼容多种由不同语言(如C++、Go、Python)实现的后端引擎,能够灵活适配不同AI模型对运行环境的特定要求。
- 强大的扩展性:可与LocalAGI(用于AI智能体编排)、LocalRecall(知识库系统)、Cogito(LLM工作流程库)等关联工具组合使用,共同构建起一套功能完整的本地人工智能基础设施套件。
安装部署指南
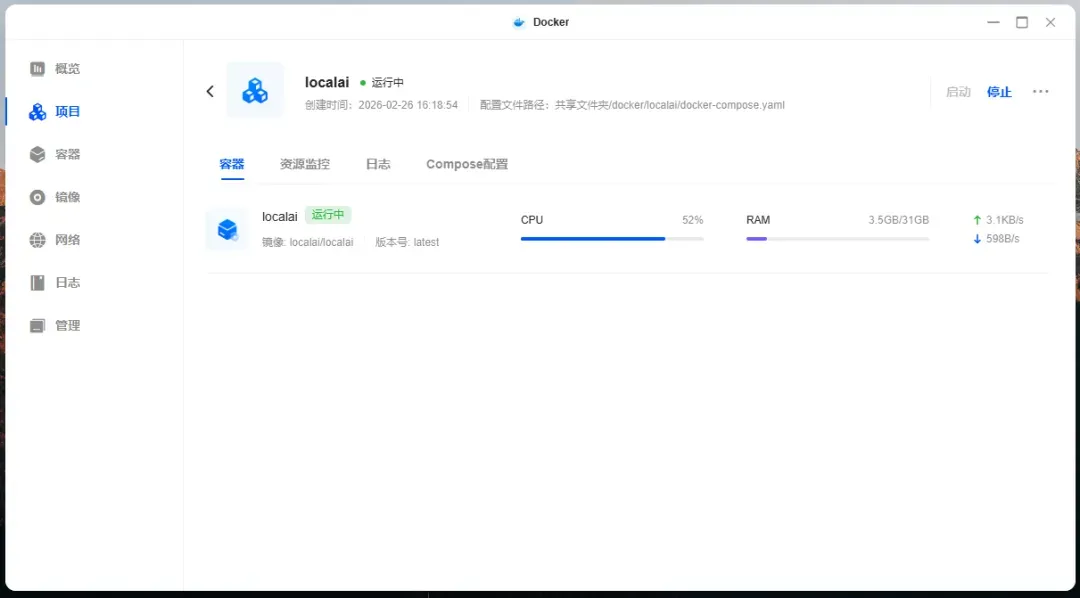
部署过程非常简单,尤其适合通过Docker容器化进行。以下是一个适用于纯CPU环境的基础Docker Compose配置示例:
services:
localai:
image: localai/localai:latest
container_name: localai
ports:
- 8080:8080
volumes:
- ./models:/models
restart: always
将上述配置保存为docker-compose.yml文件,在相同目录下执行docker-compose up -d命令即可启动服务。其中,./models目录将用于持久化存储所有下载的AI模型文件。
实际使用体验
服务启动后,在浏览器中输入 http://你的NAS的IP地址:8080 即可访问LocalAI的Web管理界面。
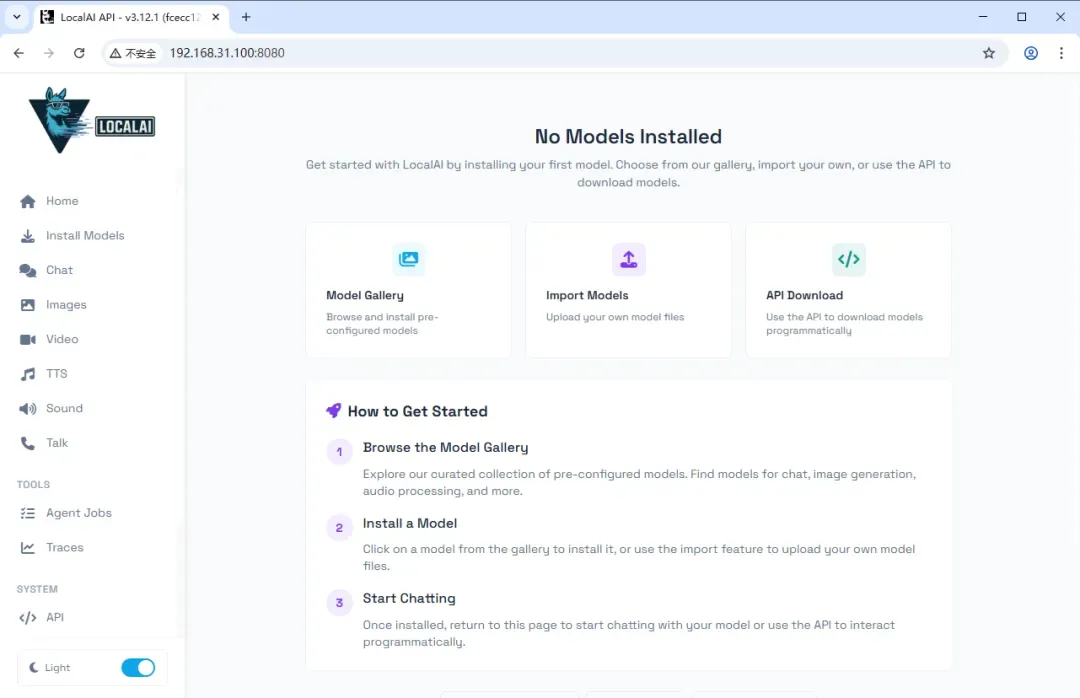
界面提供了清晰的上手引导。基本使用流程分为三步:首先浏览并选择所需的模型,然后将其下载安装到本地,最后即可开始对话或调用其功能。
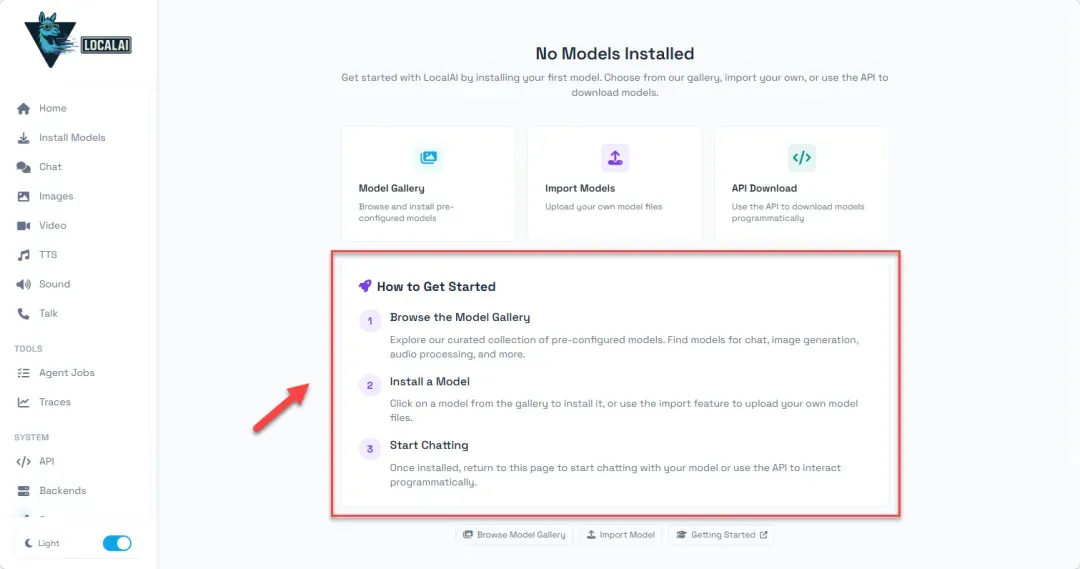
LocalAI的内置模型库提供了相当丰富的选择,涵盖不同参数规模和用途的模型,大部分可以直接在线下载。请注意,下载过程需要相对稳定流畅的网络环境,有时可能会遇到模型列表暂时加载不出的情况,通常等待一段时间或重试即可。
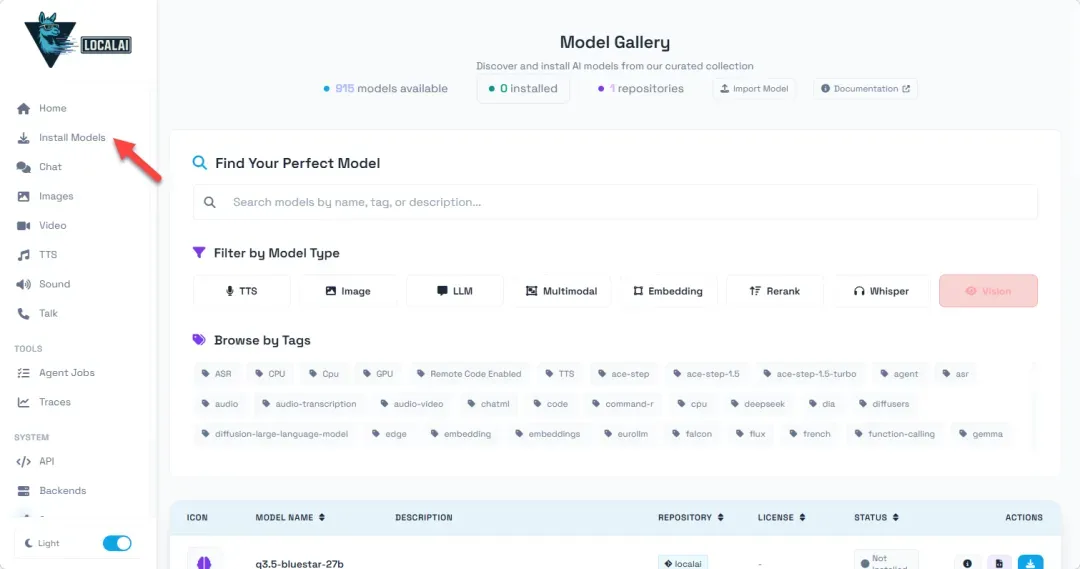
实用提示:系统也支持离线模型。你可以将从其他渠道获取的兼容模型文件(通常是GGUF格式)直接放入之前映射的./models目录中,刷新界面后即可识别并使用。
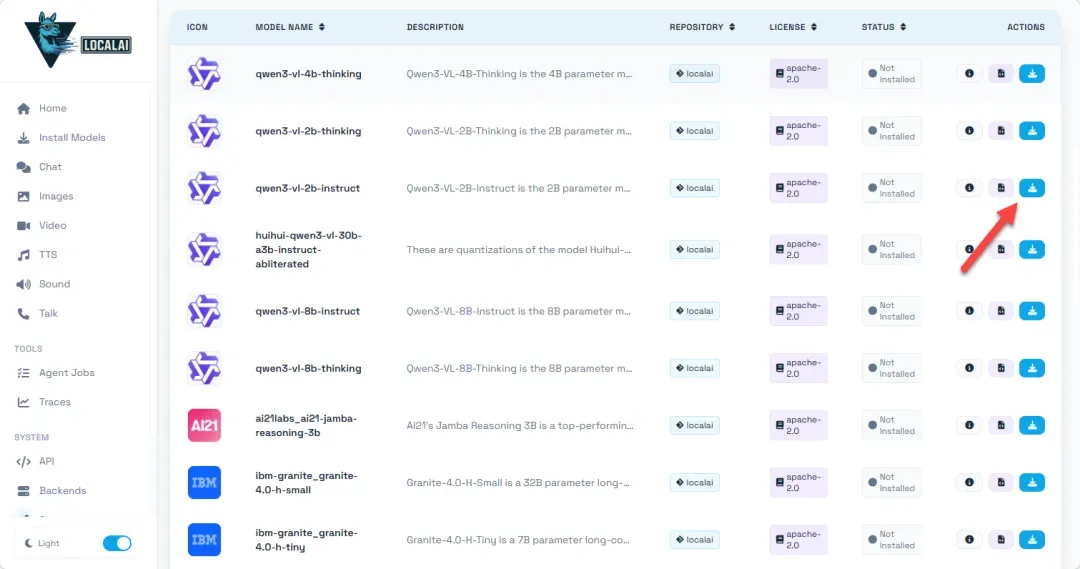
你可以根据需求(如对话、代码生成、创意写作等)筛选模型。对于主要依赖CPU运行的NAS环境,建议优先选择参数量较小、对硬件要求更低的模型。

选中模型后,点击下载安装。由于我们假设在CPU环境下运行,此处示例选择了一个体积较小的模型。
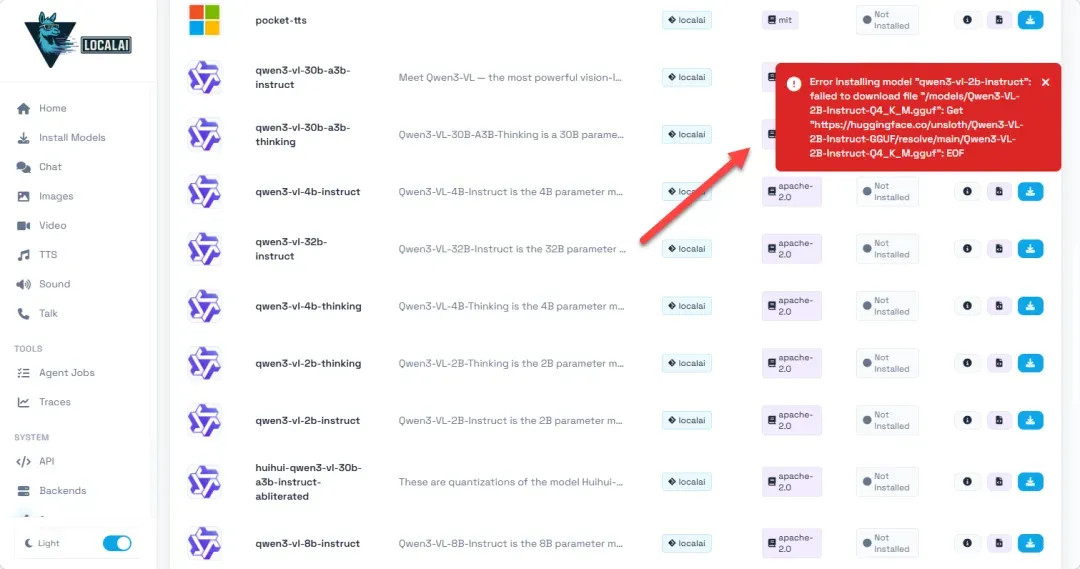
另一个重要提示:模型下载过程有时可能因网络问题而中断或失败,确保NAS设备连接至良好的网络是成功下载的关键。
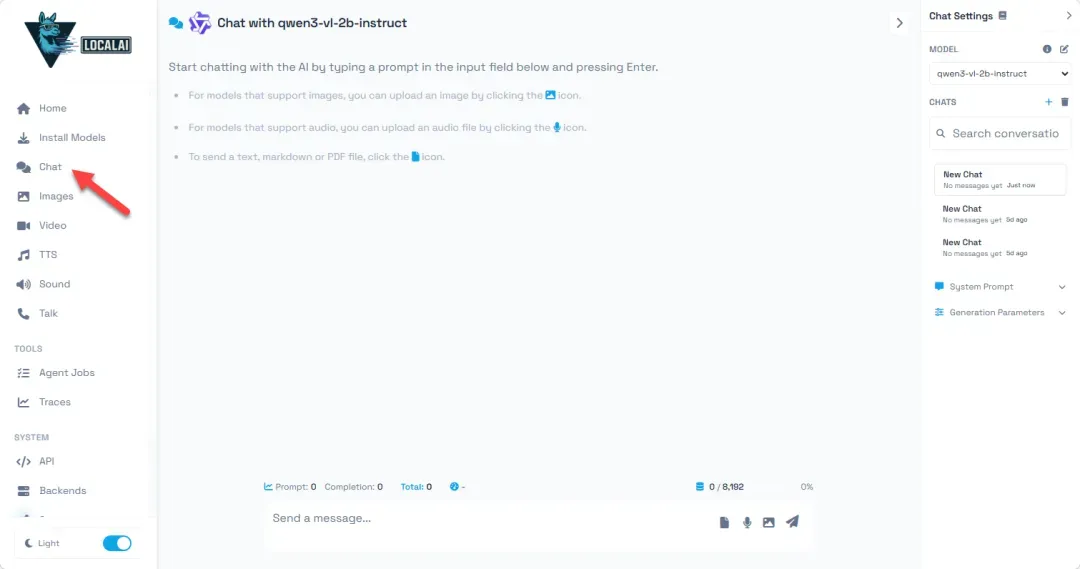
模型安装完成后,便可以进入对话界面开始使用了。
在对话框中输入文字,AI助手便会开始生成回复。在纯CPU环境下,生成速度可能不会太快(例如实测可能只有每秒3-4个token),但对于不追求实时响应的本地化应用而言,这个体验仍然是可以接受的。
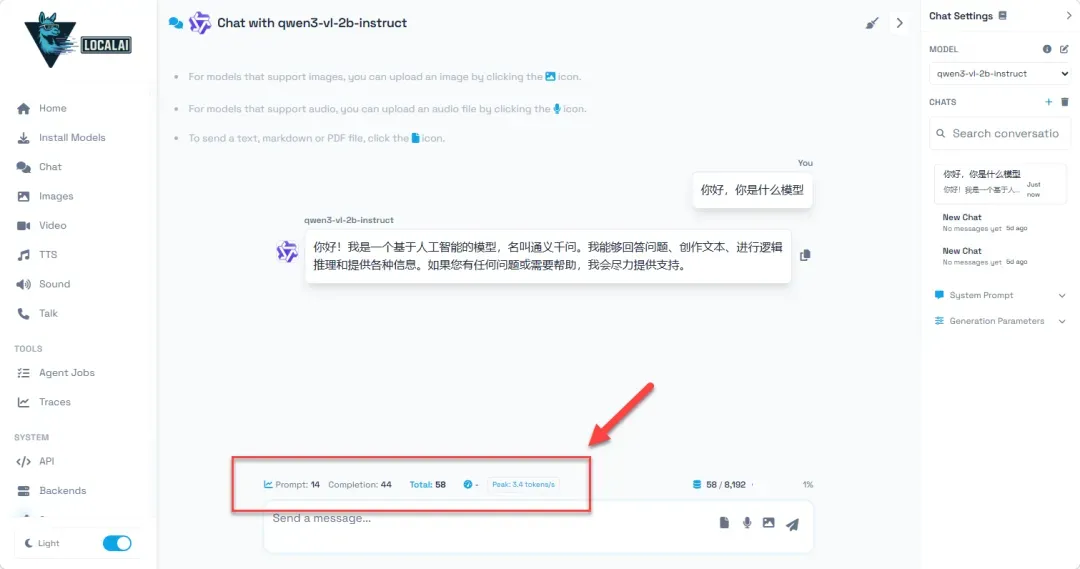
受限于小模型的认知能力,其回答的深度和广度自然无法与云端超大规模模型相媲美。然而,其最大的优势在于完全的本地运行,无需互联网连接,所有交互内容都私密地保留在自家设备中。
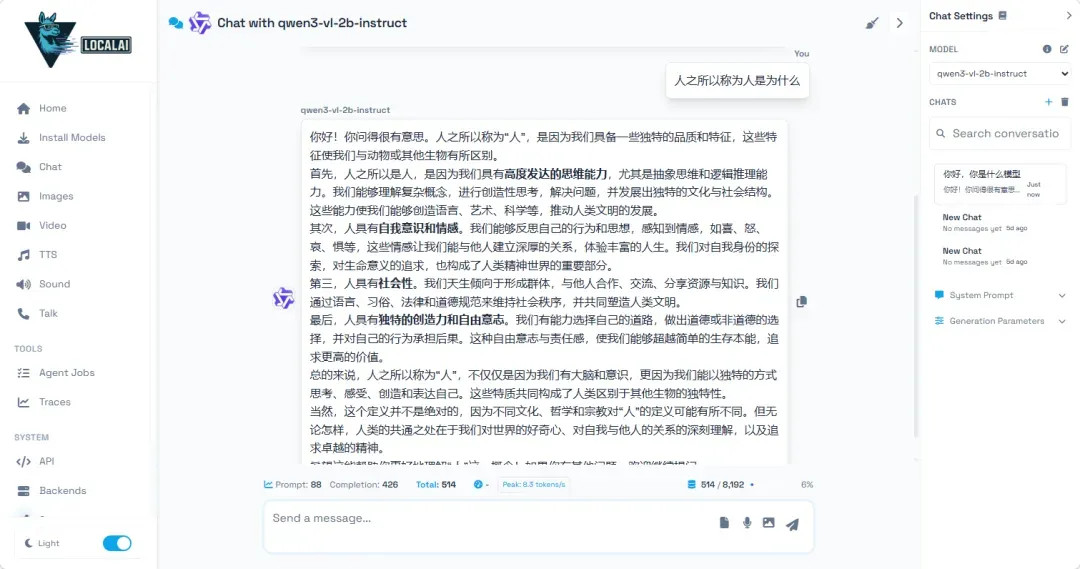
在API调用层面,LocalAI完美模拟了OpenAI的接口规范。这意味着你可以将本地服务的地址(http://NAS-IP:8080/v1)直接配置到支持OpenAI API的各种第三方客户端或自行开发的程序中,实现无缝替换。
对于有更高性能要求的用户,LocalAI甚至支持在多台设备上部署形成集群,进行混合推理以加速处理过程。
除了基础的对话功能,LocalAI还集成了图像生成、音频处理等众多功能,有兴趣的用户可以深入探索其完整的潜力。
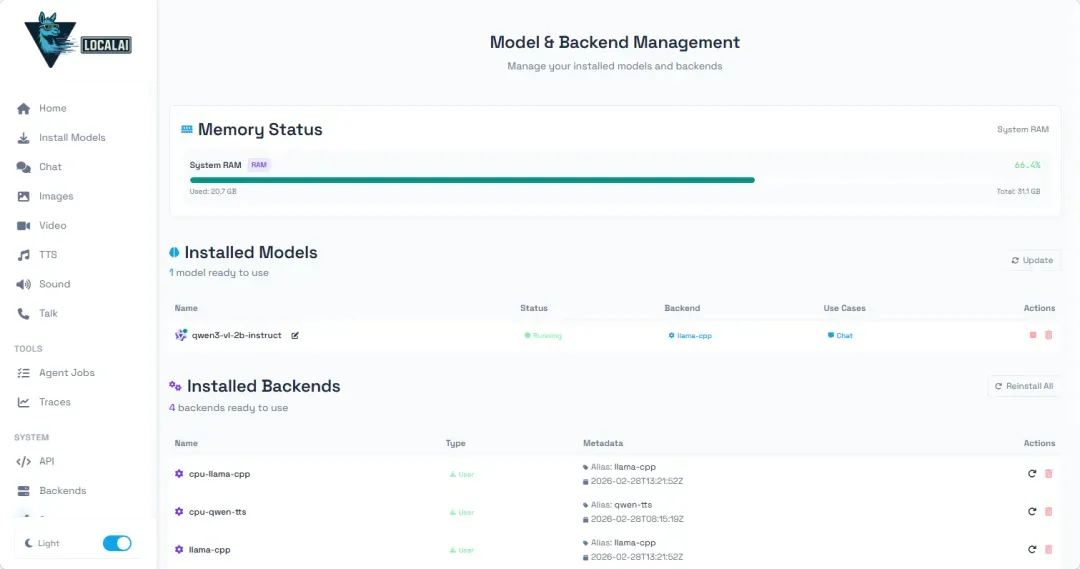
关于资源占用,以一个20亿参数的小模型为例,其在运行时会占用大约3.5GB的内存。在进行文本生成时,CPU的利用率通常会达到接近满载的水平。
总结与评价
总体而言,LocalAI带来了极其友好的入门体验,其可视化Web界面极大地降低了普通用户在本地部署AI模型的技术门槛。该方案支持完全离线部署,即使在无网络环境中也能提供可用的生成能力;仅依赖CPU即可运行的特性,使其对硬件异常包容;同时,对OpenAI API规范的兼容性让现有生态应用能够轻松迁移。此外,其对GGUF格式模型的良好支持,使用户能便捷地获取和尝试最新的社区模型。
三步搭建私有网盘:ownCloud私有云存储完整部署与使用指南
ownCloud是一个开源的平台,专门用于文件同步、共享和内容协作。它使用户能够在私有服务器上建立自己的云存储服务,从而确保数据的完全控制和隐私保护。
安装步骤:使用Docker Compose快速部署
Docker Compose(自带数据库)配置示例如下:
services:
ownCloud:
image: dlandon/owncloud:latest
container_name: ownCloud
privileged: true
ports:
- 8443:443
environment:
- PGID=1000
- PUID=1000
- TZ=Asia/Shanghai
- DB_PASS=owncloud
volumes:
- ./config:/config
- ./data:/data
restart: always
关键参数说明如下(更多参数建议查阅官方文档):
- PGID(环境变量):表示用户组ID,用于设置用户组权限。
- PUID(环境变量):表示用户ID,用于设置用户权限。
- TZ(环境变量):用于配置时区,例如Asia/Shanghai。
- DB_PASS(环境变量):设置数据库的访问密码。
- /config(路径):该目录用于存储配置文件和数据库文件。
- /data(路径):该目录用于存储用户上传的数据和文件。
使用指南:从配置到高级功能
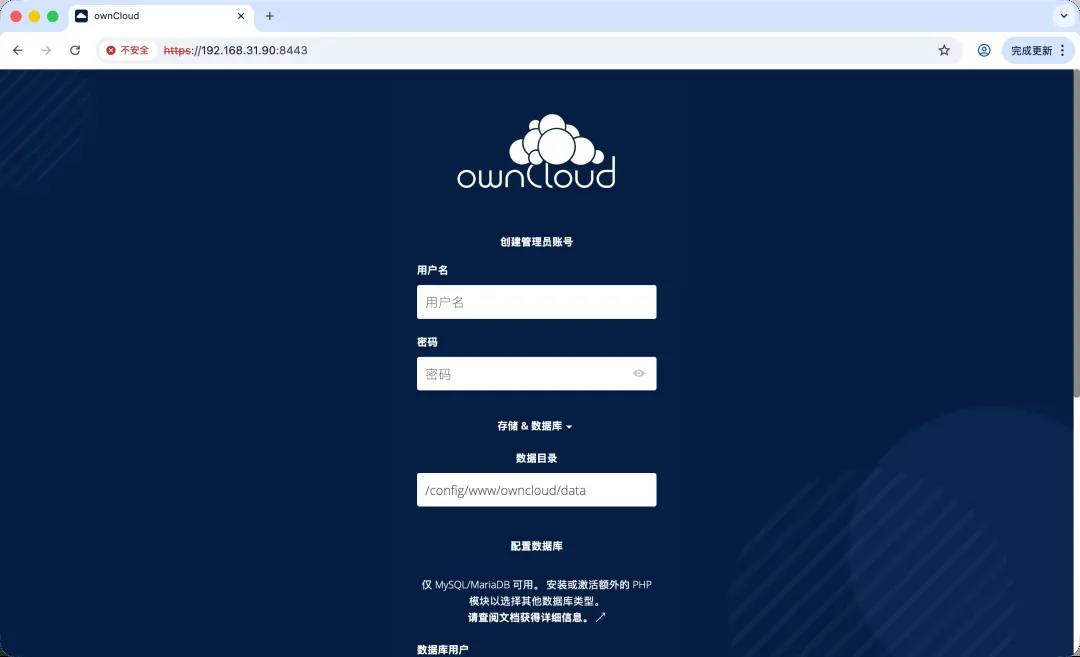
在浏览器中输入https://NAS的IP:8443即可访问界面,请注意使用HTTPS协议(初始启动可能需要一些时间加载)。
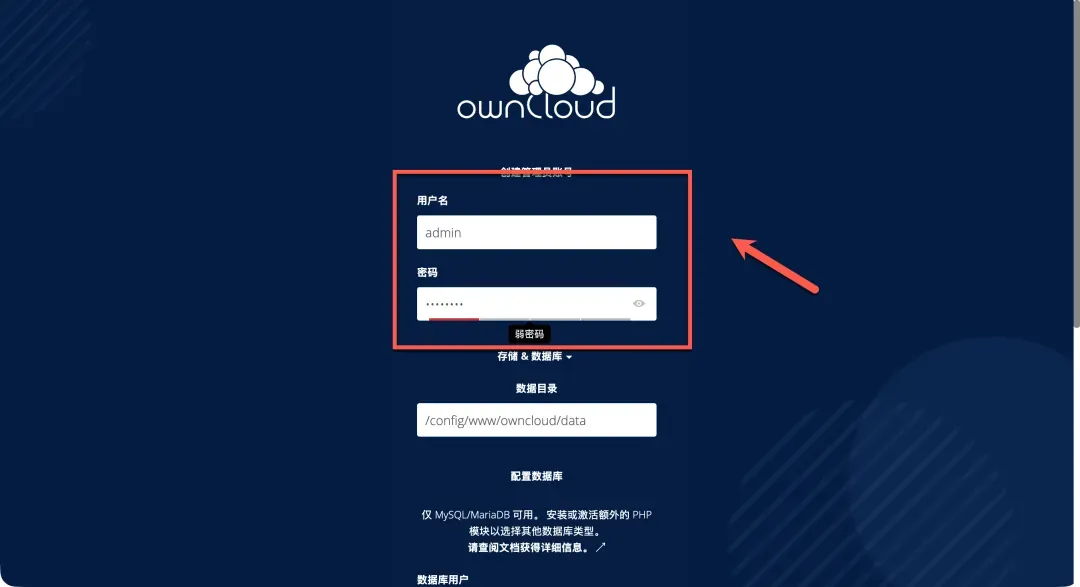
首先创建管理员账号,填写必要的用户名和密码信息。
建议将数据目录修改为“/data”以匹配挂载卷(此步骤可选,但能优化存储管理)。
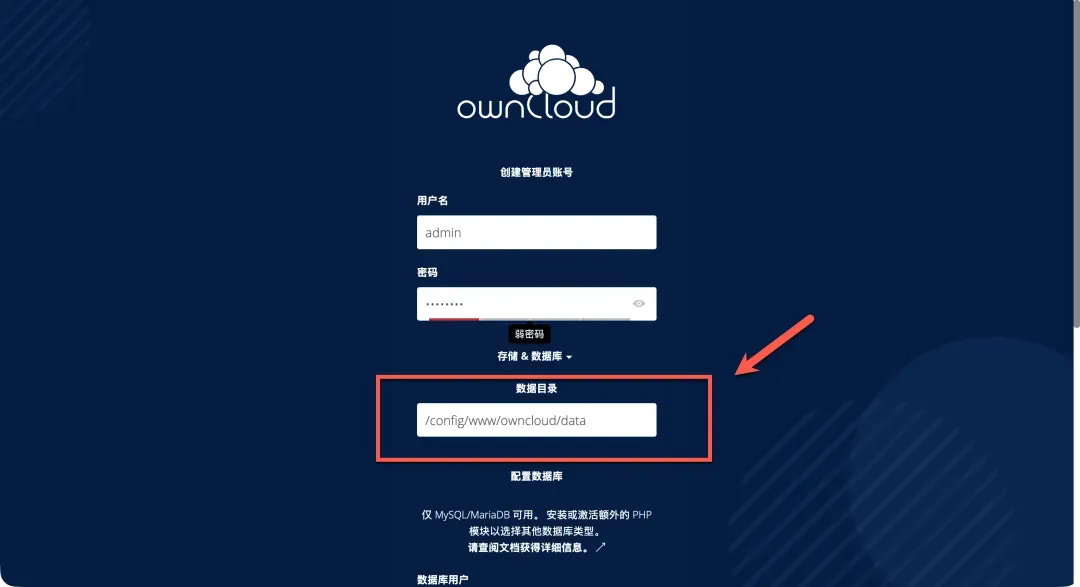
配置数据库时,使用以下预设参数(该Docker镜像已封装数据库):
- 数据库用户名:root
- 数据库密码:owncloud
- 数据库名:owncloud
- 数据库主机:localhost
确认无误后点击安装按钮,系统可能需要短暂加载以完成初始化设置。
加载完成后,输入之前设置的管理员账号和密码进行登录。
作为老牌应用,ownCloud支持全平台客户端,包括Windows、macOS、Linux以及移动设备。
整体界面设计简洁大方,没有过多复杂元素,注重功能实用性。
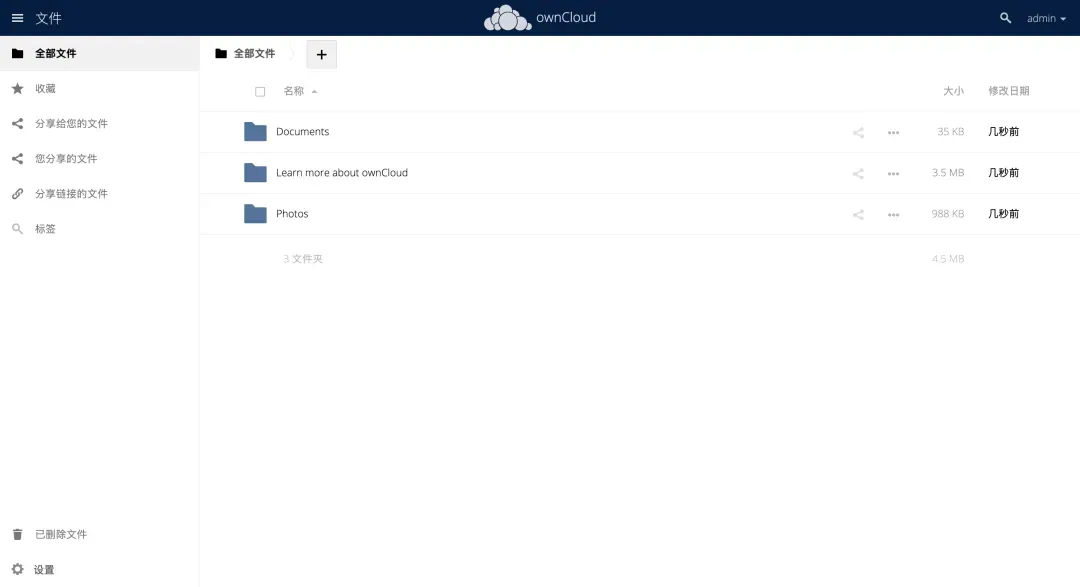
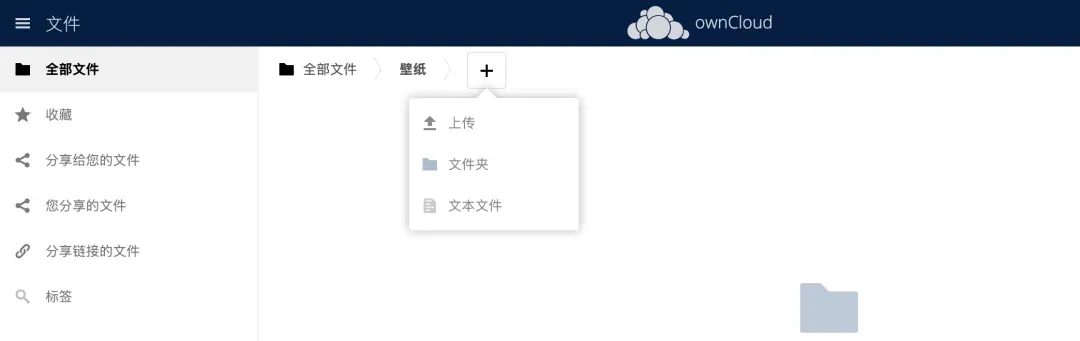
点击界面上的“➕”按钮,可以创建新文件夹、文本文件或直接上传本地文件。
支持批量上传功能,用户可以直接将文件拖拽到网页区域完成快速上传。
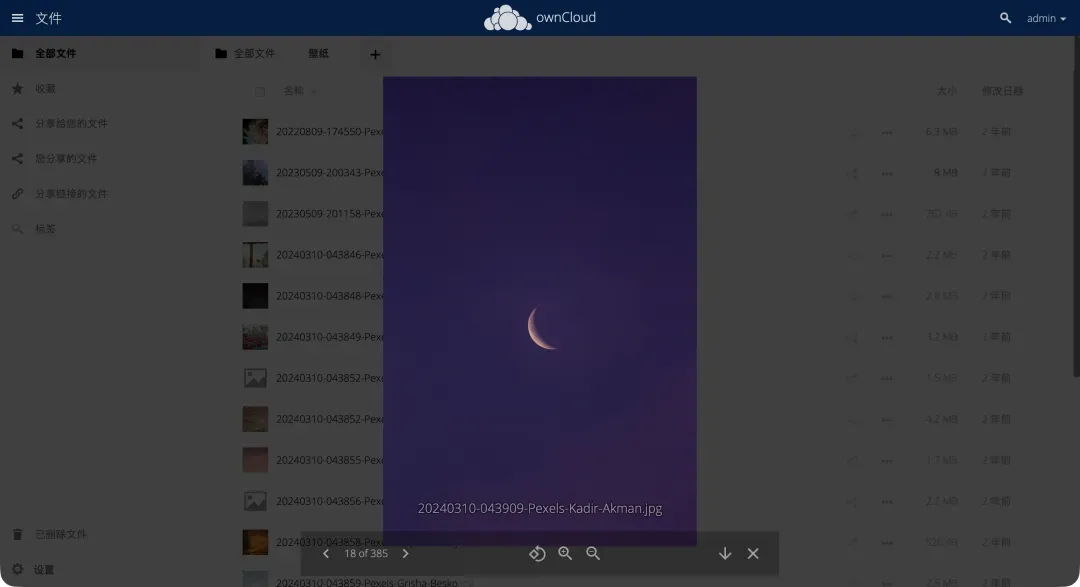
图片文件可以在线预览,方便用户快速浏览内容。
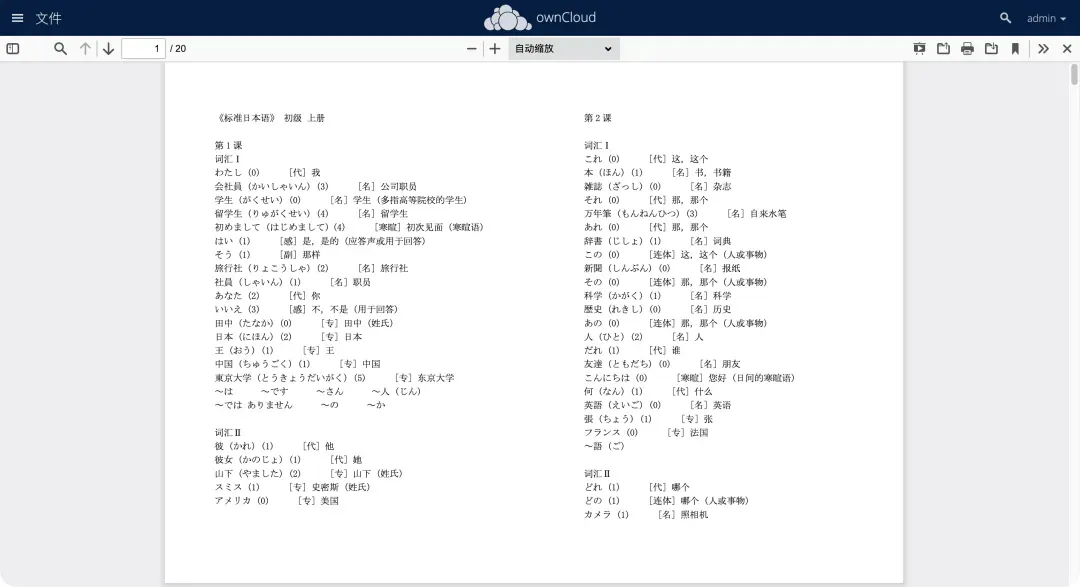
TXT文本文件同样支持在线预览,便于直接查看和编辑。

PDF文件可以在线预览,但常见的Word、Excel、PPT格式可能不支持;不过可以通过安装ONLYOFFICE等插件来扩展功能。
深度体验Wolfcha:基于AI博弈推理的狼人杀单人游戏全攻略与部署指南
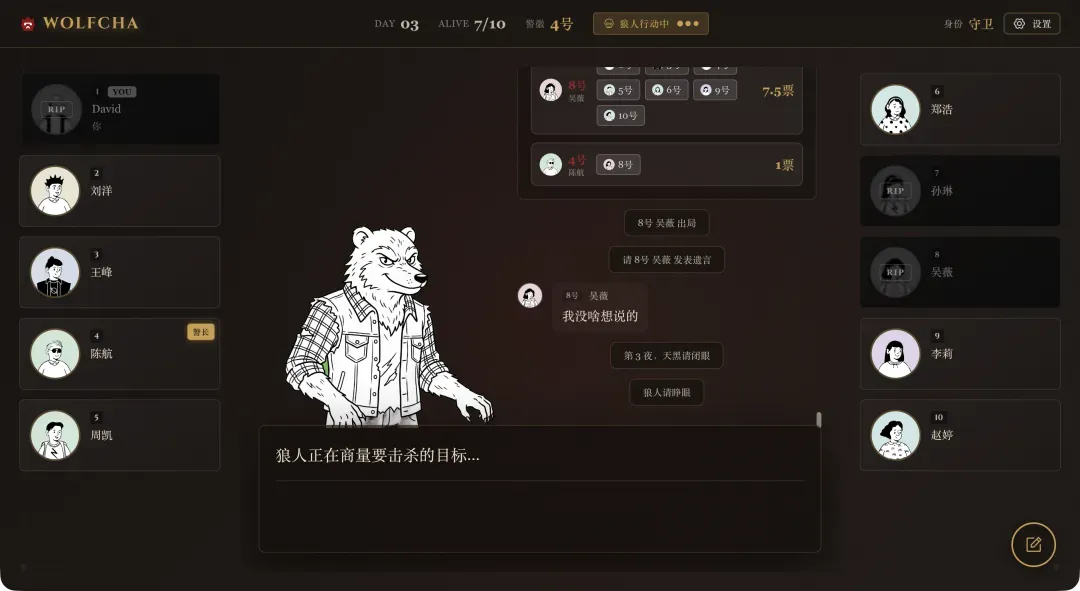
本文将详细介绍一款名为Wolfcha的AI驱动单人狼人杀游戏。在这款游戏中,你将作为唯一的人类玩家,与9位拥有独立性格与策略的AI角色共同参与一场完整的狼人杀对局。这些AI角色能够根据实时的游戏局势进行复杂的逻辑推理、公开发言、投票决策,甚至实施欺骗行为。

你可以通过其在线演示站立即体验:https://wolfcha.a3e.top
部署安装步骤
使用Docker Compose是部署该服务最简便的方式。具体配置如下:
services:
wolfcha-web:
image: heizicao/wolfcha-web:v1
container_name: wolfcha-web
ports:
- 7860:7860
restart: always
详细使用指南
完成部署后,在浏览器地址栏中输入 http://你的NAS_IP地址:7860 即可访问游戏主界面。
进入界面后,首先点击右上角的设置按钮进行游戏配置。

在设置菜单中,你可以自由选择游戏难度和玩家数量,初次体验使用默认配置即可。
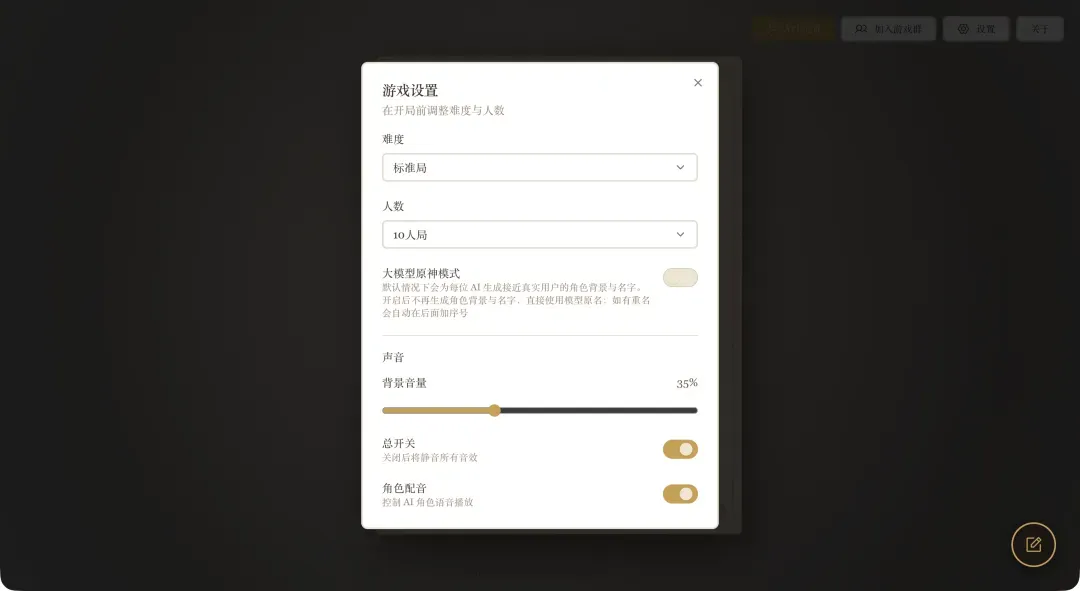
接下来,在下方输入你的玩家名称,点击开始按钮即可创建对局。

提示:游戏需要配置大语言模型API。本文演示使用的是硅基流动的API服务,你可以通过此邀请链接注册(可获得2000万Tokens的赠送额度):https://cloud.siliconflow.cn/i/1kFLquql
在设置中填写你选择的API服务商信息,模型选择默认选项即可(语音合成功能非必需,如需使用需额外注册MiniMax账号)。
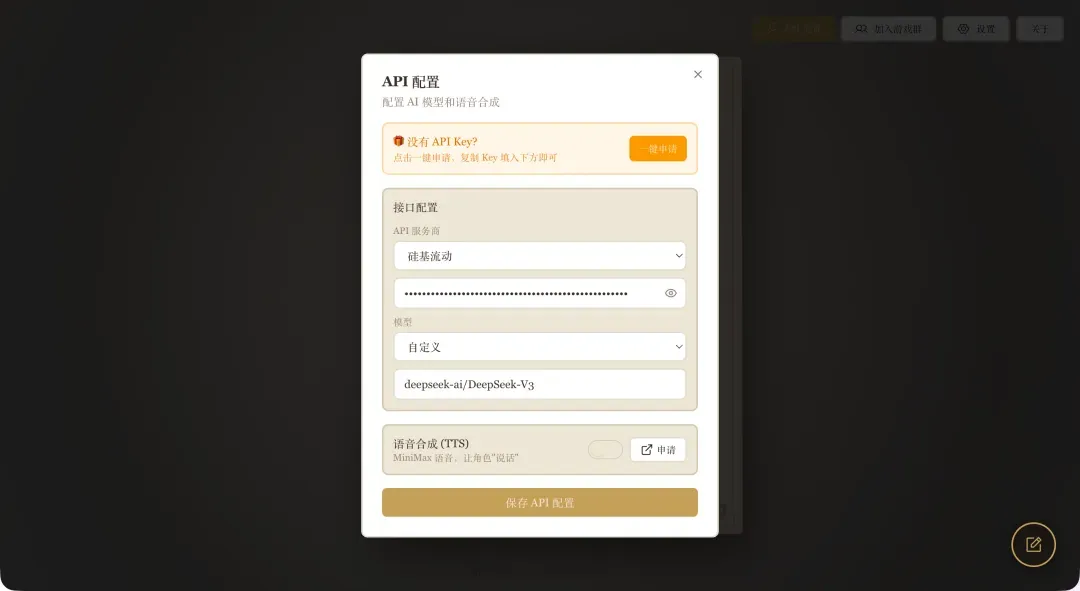
配置完成后系统需要一些时间进行初始化,请耐心等待游戏加载。
加载完毕后游戏正式开始,你将随机抽取并获得本局游戏的身份角色卡。
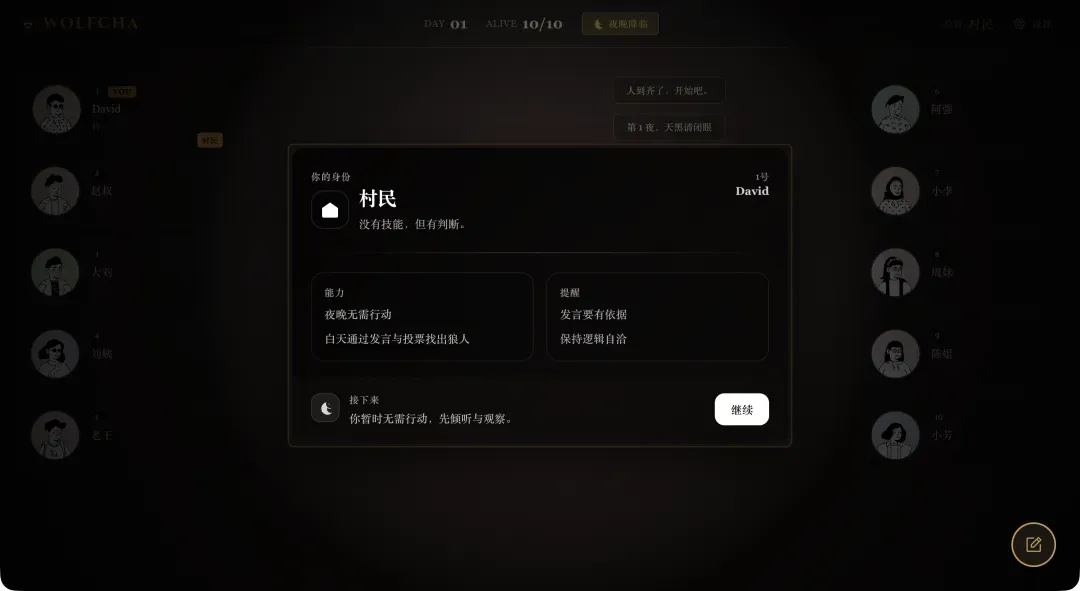
提示:如果你是首次接触狼人杀游戏,也无需担心,游戏内提供了简洁明了的新手教程指引。
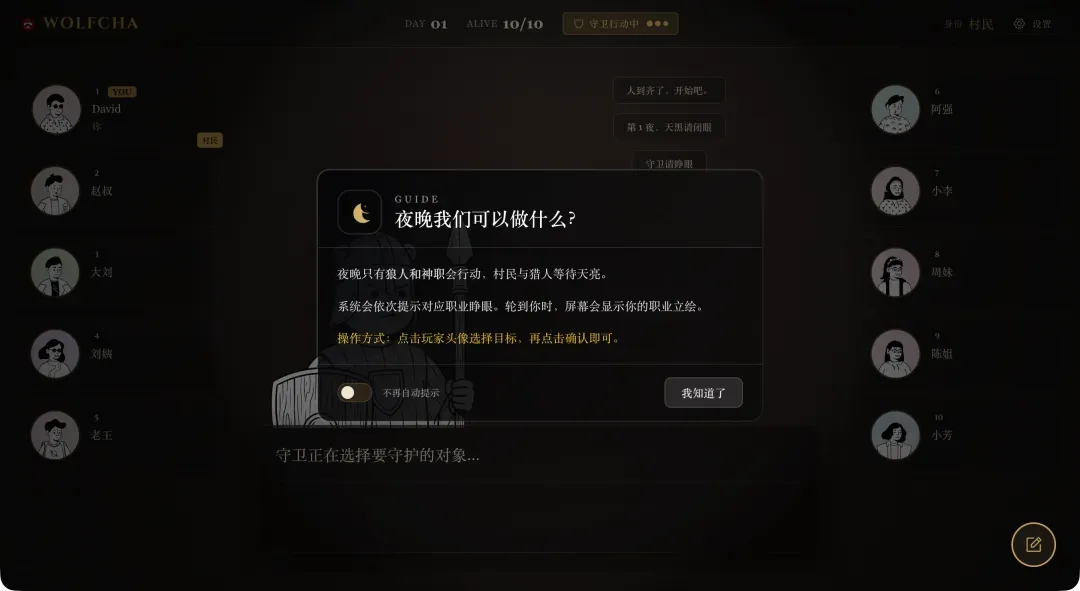
必须承认,这款游戏的整体制作水准相当精良,界面与交互设计都很出色。

与传统脚本化的狼人杀游戏最大的不同在于,融合了AI技术的本作拥有极高的自由度和动态性。例如,游戏中的对话并非预设选项,而是充满了AI根据语境实时生成的不确定性,这正是其核心乐趣所在。
在游戏过程中,如果你担心遗忘某些关键信息或发言,可以随时点击界面右下角的笔记功能进行记录。
游戏结束后,系统会公布所有玩家的真实身份(偶尔可能因数据格式问题导致显示略有异常,但不影响结果判定)。
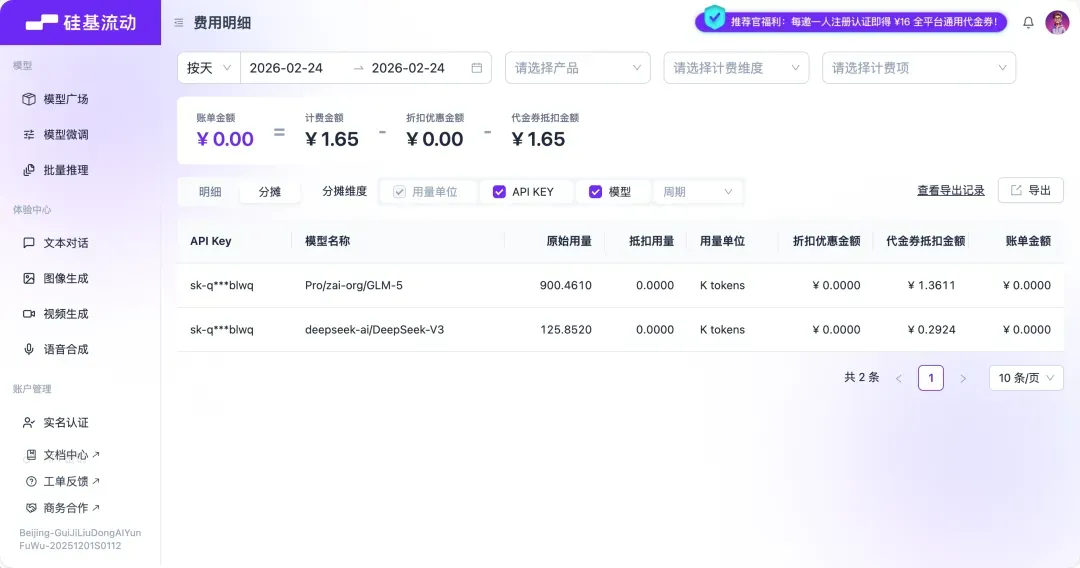
根据实测,完成一局游戏大约消耗价值1.5元人民币的API Tokens,不过由于平台赠送的额度,实际体验成本可以忽略不计。
体验总结与评价
这款游戏确实兼具趣味性与创新性,其核心魅力在于AI能够深度理解对话上下文并进行动态分析,使得玩家与AI之间的互动感非常强。在完成本指南的编写后,笔者自己也忍不住连续体验了数局。即便是选择普通难度,对于新手玩家而言也颇具挑战。个人感受是,游戏中的狼人AI显得智商超群且团队协作紧密,相比之下,好人阵营的AI有时则较为沉默。在笔者的对局中,拿到好人身份时胜率较低。我们强烈建议感兴趣的玩家亲自尝试,这款游戏堪称AI与桌游结合的典范,提供了独特且沉浸的体验。
综合推荐指数:⭐⭐⭐⭐⭐(极力推荐,真正展现了AI与游戏结合的优秀潜力)
使用体验评价:⭐⭐⭐⭐(整体体验流畅,制作精良)
部署难易程度:⭐(部署过程极为简单)
使用Docker Compose一键部署MiroFish:打造你的AI预测与数字沙盘系统
今天我们来探讨一个近期在GitHub上颇为热门的AI项目:MiroFish。初次见到这个名字时,一种奇特的联想涌上心头——难道我们NAS社区也迎来了自己的“库洛·里德”,拥有了能够预知未来的数字占卜师?这个项目的核心理念在于,它将新闻动态、舆论风向、社会关系与各类事件统统纳入一个复杂的系统中,驱使一群自主的智能体(Agent)进行推演与分析,最终生成一份形似“未来预言”的结果报告。

实际上,同期我也尝试过另一个侧重于舆情监控方向的项目,但实际体验下来,其信息更新往往存在明显的滞后性。相比之下,MiroFish这种带有“电子预言家”特质,致力于模拟与推演的项目,反而显得更具新意与探索价值。当下正值人工智能浪潮汹涌之际,本文便顺势为大家分享如何动手部署这一有趣的MiroFish系统。
项目概述
项目的完整名称是 666ghj/MiroFish,以下内容提炼自其官方页面介绍:
MiroFish是一款基于多智能体技术构建的新一代AI预测引擎。它通过提取现实世界中的种子信息(例如突发新闻、政策草案、金融信号等),自动构建出一个高保真度的平行数字世界。在这个虚拟空间内,成千上万个拥有独立人格、长期记忆与行为逻辑的智能体进行自由交互与社会演化。使用者可以透过“上帝视角”动态注入变量,从而精准推演事件未来的可能走向——让未来在数字沙盘中预先上演,助力决策在百般模拟后赢得先机。
- 您只需:上传初始材料(可以是数据分析报告,也可以是引人入胜的小说故事),并用自然语言描述您的预测需求。
- MiroFish将返回:一份详尽的预测分析报告,以及一个可供深度交互的高保真数字世界。
设计愿景
MiroFish致力于打造一个能够映射现实的群体智能镜像,通过捕捉个体互动所引发的群体涌现现象,旨在突破传统预测方法的局限:
- 宏观层面:它旨在成为决策者的预演实验室,让政策制定与公关策略能够在零风险的环境中进行试错与优化。
- 微观层面:它试图成为个人用户的创意沙盘,无论是推演小说情节的多种结局,还是探索天马行空的脑洞设想,都能变得有趣、好玩且触手可及。
从严肃的商业政治预测到轻松的个人趣味仿真,MiroFish的目标是让每一个“如果”都能被看见结果,让预测万物成为可能。
Docker Compose部署指南
以下以威联通(QNAP)NAS为例,演示通过Docker Compose部署MiroFish的完整流程。部署代码的核心部分如下所示,所需的环境变量将在后续列出,您可以根据自身情况将其直接补充进部署代码中,或选择创建独立的.env环境变量文件进行调用。
services:
mirofish:
image: ghcr.io/666ghj/mirofish:latest
# 若拉取缓慢,可尝试使用下方加速镜像地址
# image: ghcr.nju.edu.cn/666ghj/mirofish:latest
container_name: mirofish
# 请将实际路径更改为您NAS上的有效目录
env_file:
- /share/Container/mirofish/.env
ports:
- "3003:3000" # 端口号可能冲突,请按需修改
- "5001:5001"
restart: always
volumes:
- /share/Container/mirofish/backend/uploads:/app/backend/uploads # 请修改为您的NAS实际映射目录
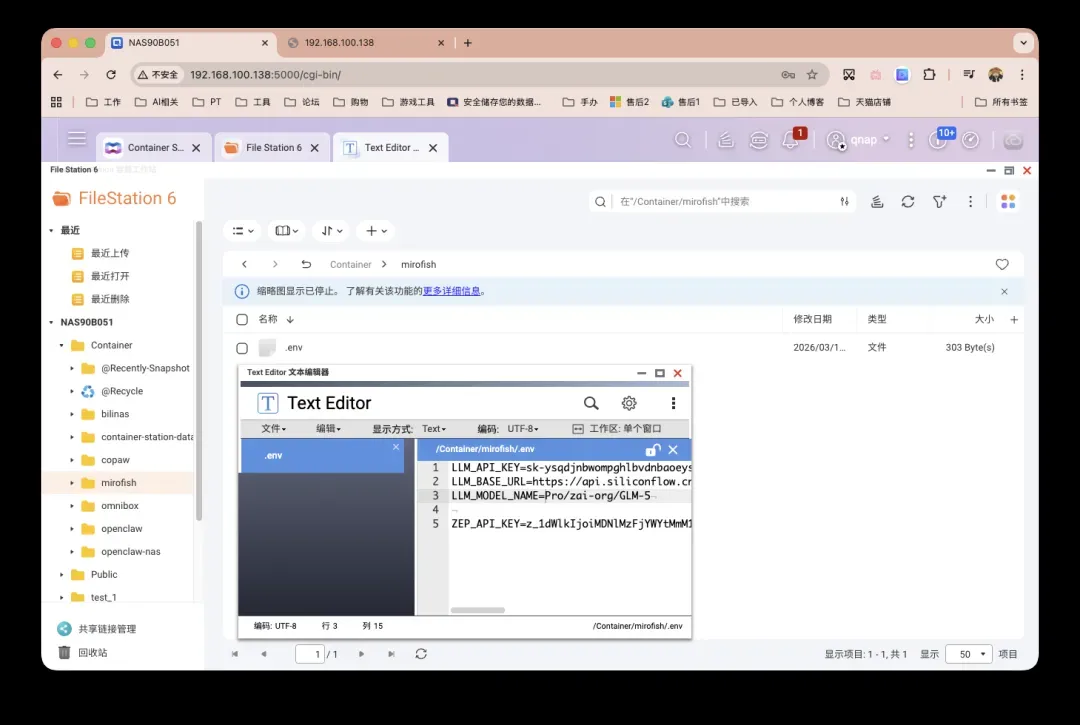
接下来是关键的环境变量配置,请将其保存至上述env_file指定的路径(例如/share/Container/mirofish/.env)中:
# LLM API配置(支持任何符合OpenAI SDK格式的LLM API)
# 推荐使用阿里百炼平台的qwen-plus等模型
# 请注意,完整推演消耗较大,建议先进行少于40轮的模拟尝试
LLM_API_KEY=sk-xxxxxx
LLM_BASE_URL=https://api.siliconflow.cn/v1/
LLM_MODEL_NAME=Pro/zai-org/GLM-5
# ===== ZEP记忆图谱配置 =====
# 其每月免费额度足以支撑简单使用,注册地址:https://app.getzep.com/
ZEP_API_KEY=your_zep_api_key_here
# ===== 加速LLM配置(可选) =====
# 注意:如果不使用此加速功能,请确保.env文件中不出现以下配置项
LLM_BOOST_API_KEY=your_api_key_here
LLM_BOOST_BASE_URL=your_base_url_here
LLM_BOOST_MODEL_NAME=your_model_name_here
关于第一部分的大模型API配置,相信经过多期AI项目部署实践的读者已经非常熟悉,此处不再赘述。
使用Docker在威联通NAS上部署泰拉瑞亚(Terraria)联机服务器完整教程
项目介绍
本文方案基于 GitHub 上的一个开源项目。该项目提供了一个 Dockerfile,旨在将 TShock 服务端与泰拉瑞亚官方服务器程序(TerrariaServer.exe)一同容器化,从而实现在 Linux 系统环境中便捷运行。通过 Docker 容器技术,用户可以免去在 Linux 系统上手动安装游戏服务器、配置运行环境以及处理各种依赖库的繁琐步骤。
该项目在 GitHub 上的完整名称为:ryansheehan/terraria。
部署流程
我们以威联通(QNAP)NAS 为例,采用 Docker Compose 的方式来部署服务器。这种方法通过配置文件定义服务,使得部署和管理更为清晰和可重复。
以下为 Docker Compose 的部署代码示例,其中已包含必要的配置与说明。
services:
terraria:
# 请注意镜像版本应与游戏客户端版本匹配
# 本文撰写时,最新稳定游戏版本为 v1.4.5,因此拉取对应镜像
# ‘latest’ 标签可能指向旧版本(如v1.4.4.9),请根据实际情况选择
# 后续更新时,拉取新版本镜像并重新部署容器即可
image: ryshe/terraria:vanilla-1.4.5.2
container_name: terraria
stdin_open: true # 开启标准输入,用于后续交互式创建世界
tty: true # 分配一个伪终端,防止容器自动退出
# environment:
# - WORLD_FILENAME=world.wld # 可指定加载的特定世界文件
# - CONFIGPATH=config.json # 可自定义服务器配置文件路径(可选)
ports:
- "7787:7777" # 映射端口:主机端口7787 -> 容器内游戏服务端口7777
- "7878:7878" # 映射端口:主机端口7878 -> 容器内REST API端口7878
volumes:
- /share/Container/terraria/world:/root/.local/share/Terraria/Worlds # 持久化保存世界文件(.wld)
- /share/Container/terraria/plugins:/plugins # 挂载插件目录
- /share/Container/terraria/logs:/tshock/logs # 持久化日志文件
restart: always # 设置容器始终重启,确保服务高可用
需要特别注意的是,挂载卷 /terraria/world 目录中若存在 config.json 配置文件,容器启动时会自动加载。若后期需要调整服务器参数,可直接修改此文件。插件文件通常为 .dll 格式,需手动放入对应的挂载目录。
手把手部署BookLore魔法电子书库:打造你的私人云端图书馆
电子书的管理方式似乎总是落后于时代。相信许多朋友已经尝试过Calibre Web、Kavita或Komga这类服务。本期我们将介绍另一款功能强大的图书馆项目——BookLore。它拥有硬核的界面和丰富的功能,特别适合漫画与电子书收藏爱好者用来系统性地整理个人藏书库。
如果你热爱阅读,却又苦于在不同设备间整理与访问书籍的繁琐流程,那么不妨尝试一下这个项目。它能够帮助你轻松地存储、管理各类电子书,并支持直接从浏览器进行同步阅读。倘若你觉得网页版阅读体验尚有不足,还可以将其连接到其他第三方阅读应用,从而获得更佳的阅读感受。
项目概览
该项目的完整名称是 booklore-app/booklore,可以在GitHub上直接搜索到。项目作者在其主页提供了体验Demo,有兴趣的读者可以先行试用一番。
简而言之,BookLore 是一款专为自托管环境打造的数字图书馆Web应用程序。通过它,你可以实现以下一系列功能:
- 上传、分类与整理:支持 PDF、ePub、CBZ、CBR 和 CB7 等多种主流电子书格式。
- 自动抓取书籍元数据:自动从网络获取书籍的封面、作者、简介、评分等信息。
- 多用户协作:支持创建多个用户账户,并可设置不同的操作权限,便于账号管理。
- 内置阅读器:提供可直接在网页中在线阅读的功能。
- 阅读进度跟踪:记录你的阅读进度并提供书籍相关的统计信息。
- 同步与连接:支持通过 OPDS 协议与 Kobo、KOReader 等设备或其他阅读应用同步阅读进度。
- 便捷导入:利用 BookDrop 功能,通过拖放文件即可实现自动导入。
- 全设备响应:在手机、平板和电脑上均能获得良好的浏览体验。
核心亮点与深度功能
1. 智能图书管理体系
BookLore 采用“图书馆 (Library) + 书架 (Shelves)”的层级系统,允许你按照作者、主题、阅读状态等维度自定义分类。其独有的“魔法书架 (Magic Shelves)”功能,能够根据你预设的规则(如“最近添加”、“未读漫画”)动态地更新图书集合。此外,高级搜索功能支持通过关键字和特定元数据字段进行检索,帮助你快速定位目标书籍。
2. 强大的元数据抓取引擎
应用能够自动从多个在线图书信息源抓取书籍的元数据。当然,你也可以随时手动编辑或调整这些自动获取的信息。这一功能对于维护一个外观专业、信息完整的个人图书库而言至关重要。
3. 多格式在线阅读支持
BookLore 内置的阅读器提供了良好的格式兼容性,包括:
- PDF 文档阅读
- ePub 电子书阅读
- CBX / 漫画文件阅读 你无需下载文件即可直接在浏览器中浏览内容,系统还会自动跟踪你的阅读进度。
4. 完善的多用户与权限管理
管理员可以轻松创建多个用户账户,并为不同的用户分配差异化的操作权限,例如上传、编辑或删除书籍的权限。这使得 BookLore 不仅适用于个人用户,也非常适合家庭或小型团队共同使用和管理一个共享书库。
5. 灵活的连接与同步机制
除了支持标准的 OPDS 协议,方便连接各类阅读器客户端外,BookLore 还能够与 Kobo 和 KOReader 等专用阅读设备同步阅读进度。此外,它还提供了通过电子邮件分享书籍的便捷功能。
6. BookDrop 自动导入功能
这是一个极具实用性的特性:你只需将电子书文件拖入NAS上指定的“bookdrop”文件夹,BookLore 便会自动检测到新文件,并完成导入与元数据抓取的全过程,极大简化了书籍添加的步骤。
手把手教程:使用Docker快速部署轻量级Markdown博客PaperGrid
在之前的分享中,我们探讨了使用 Halo 2.0 搭建个人博客的方法。对于部分用户而言,这类项目功能虽然全面,但整体架构可能略显繁重。相比之下,许多用户更青睐于轻量化、界面简洁,甚至仅需一个能够稳定托管内容的简易站点。
近期,我发现了一个名为 PaperGrid 的新兴博客项目,其整体设计风格倾向于轻量化,完美支持 Markdown 编辑,并且前端视觉效果相当出色!同时,它还具备不错的可定制性与探索空间。本文将简要介绍如何部署并开始使用它。
就我个人而言,博客已经逐渐取代了传统的笔记工具。将思考过程、技术实践与使用心得记录下来,不仅便于日后回顾,也能分享给有共同兴趣的伙伴。像 PaperGrid 这样部署过程相对简单、界面设计也足够清晰的项目,非常适合用来构建一个专属的个人记录空间。
PaperGrid项目概览
完整项目名称:xywml/PaperGrid,可以在 GitHub 上进行搜索。
这是一个基于 Next.js App Router 构建的轻量化个人博客与后台管理系统。它内置了用户认证、文章管理、评论功能和系统设置模块,并支持中文/英文双语界面与深色模式切换。
作者说明:项目目前处于快速开发迭代阶段,欢迎部署使用、给予 Star 评价或反馈建议。
核心功能特性
- 现代技术栈:采用 Next.js App Router 与 React 19。
- 数据管理:集成 Prisma ORM 进行数据库操作。
- 用户认证:使用 NextAuth 实现安全的身份验证。
- 完整后台:提供文章、标签、分类、评论、用户、系统设置及文件管理的后台界面。
- 文件管理:支持本地图片上传、预览、删除以及 URL 自动回填至编辑器。
- 强大内容支持:兼容 MDX 格式,具备代码高亮、数学公式渲染与图表绘制能力。
- 国际化与主题:支持多语言切换,并内置深色模式。
- 多样前端主题:管理员可在后台“样式”设置中一键切换多套前台主题(例如:纸格笔记、终端机能、清透视窗、像素账本)。
- 扩展可能:具备集成智能 AI 助手的潜能。
详细部署步骤
本文以威联通(QNAP)NAS 为例,演示通过 Docker Compose 进行部署的过程。
以下部署代码可实现服务的快速启动,请根据你的环境调整配置:
services:
papergrid:
image: ghcr.io/xywml/papergrid:latest
container_name: papergrid
ports:
- "6066:3000"
environment:
DATABASE_URL: "file:/data/db.sqlite"
# 可选:为 AI 向量索引使用单独的 SQLite 文件
# AI_VECTOR_DATABASE_URL: "file:/data/ai-index.sqlite"
# SQLITE_JOURNAL_MODE: "DELETE"
# 初始使用 NAS IP 加端口访问,后续若配置反向代理或域名,需修改此处
NEXTAUTH_URL: "http://192.168.100.138:6066"
NEXT_PUBLIC_APP_URL: "http://192.168.100.138:6066"
# 生产环境务必设置一个足够长且复杂的随机字符串
NEXTAUTH_SECRET: "请替换成一串足够长的随机字符串"
# 设置本地媒体文件与缓存存储路径
MEDIA_ROOT: "/data/uploads"
NEXT_CACHE_DIR: "/data/.next-cache"
# 首次初始化容器时的可选配置(用于创建管理员)
# INIT_ADMIN_TOKEN: "请替换为随机字符串"
# ADMIN_INIT_PASSWORD: "请替换为强密码"
# 可先跳过 OAuth / SMTP 配置,待基础服务运行后再补充
NEXT_PUBLIC_DEFAULT_LOCALE: "zh"
# 在内网环境且未配置反向代理时,允许信任 Host 头
AUTH_TRUST_HOST: "true"
volumes:
- /share/Container/boke/data:/data
restart: unless-stopped
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "5"
以下是完整的的环境变量列表,你也可以选择创建独立的 .env 文件进行配置:
手把手教程:使用开源项目在NAS上搭建私人H5棋牌游戏室
今天将介绍一款基于H5技术的棋牌游戏平台。这是一个商用级别的项目,旨在让用户摆脱公共平台的种种限制,创造一个无后台监控、无人工干预、完全公平公正的游戏环境。该平台兼容性强,支持在手机、电脑、平板等任何带有浏览器的设备上运行,真正做到即开即玩。
重要提示:对于初次尝试部署的朋友,强烈建议严格遵循本教程的每一步操作。请勿在没有充分理解的情况下随意修改配置文件,也无需急于配置外网访问,按部就班完成内网部署是成功的第一步。
准备工作
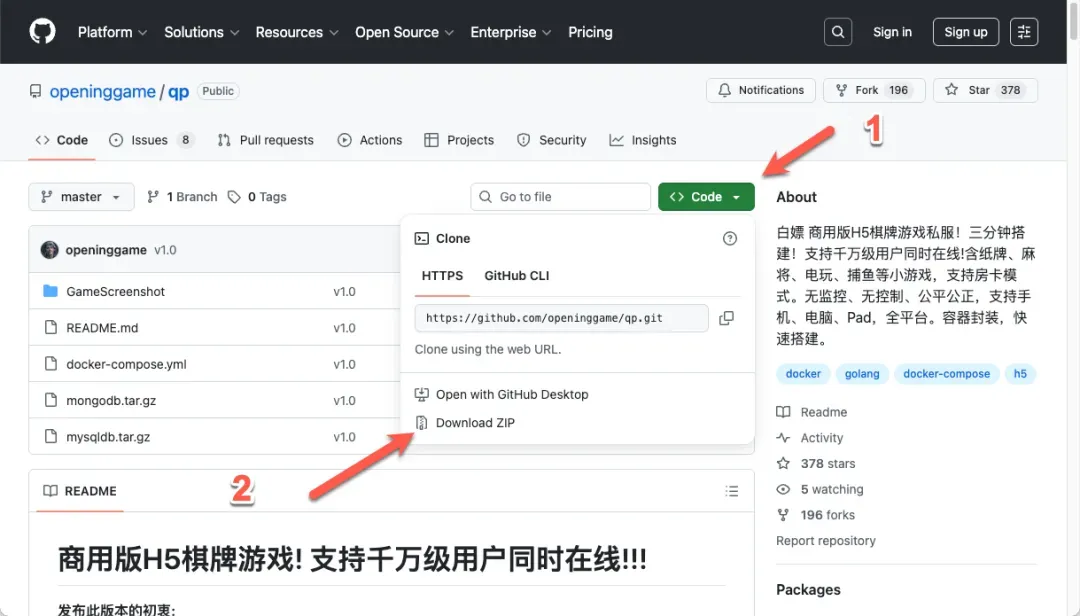
首先,访问该项目的GitHub仓库地址:https://github.com/openinggame/qp,下载整个项目源码。
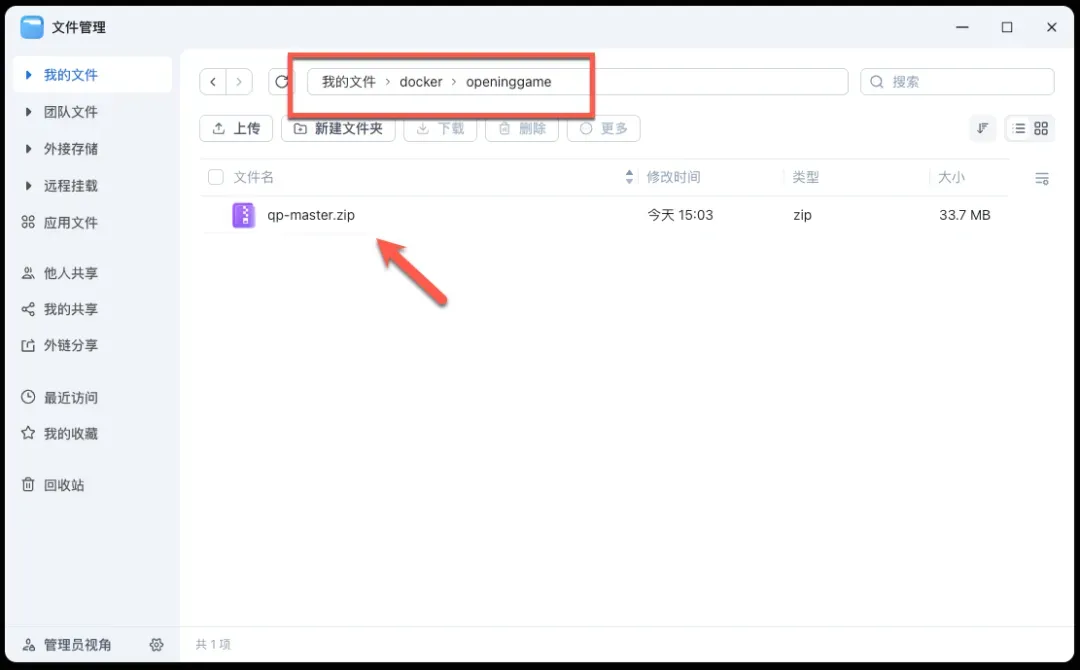
在你的NAS设备上,创建一个名为openinggame的文件夹,并将刚刚下载的ZIP压缩包放入其中。
解压这个ZIP文件。解压后,你会看到多个文件和文件夹,为了部署清晰,我们只需要保留以下三个核心文件:docker-compose.yml、mongo_data.tar.gz和mysql.tar.gz。可以将其它不必要的文件暂时移开或删除。
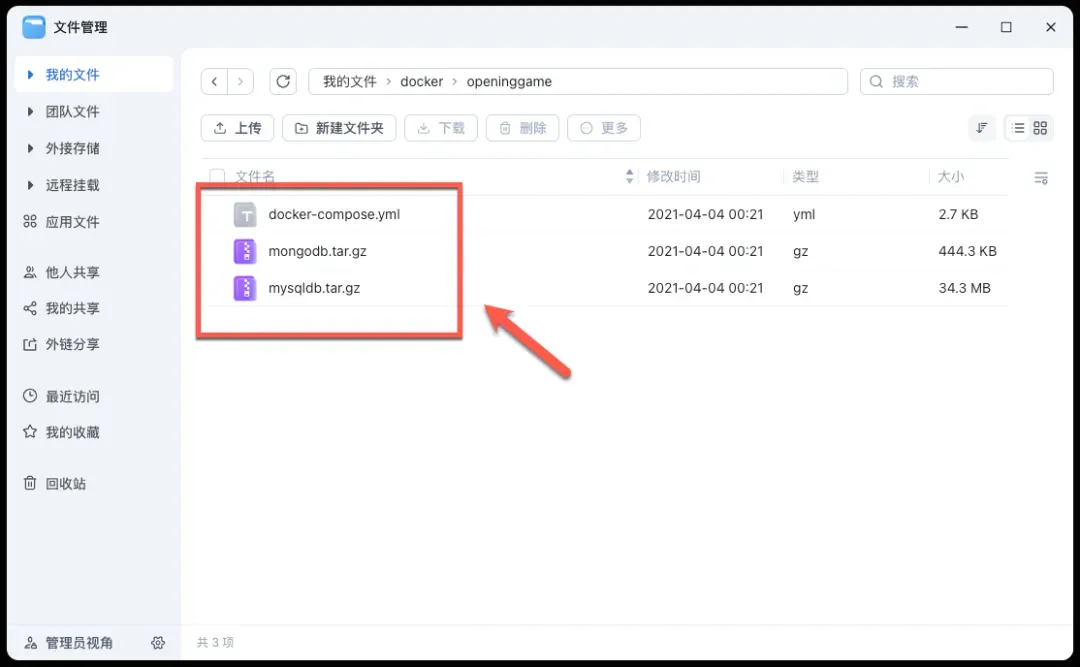
接下来,分别解压mongo_data.tar.gz和mysql.tar.gz这两个压缩包。解压完成后,你的文件夹结构应整理成类似下图所示的样子,包含必要的数据库数据目录和配置文件。
目录说明:mongo_data文件夹内部用于存放MongoDB数据库的数据文件。
目录说明:mysql文件夹内部则用于存放MySQL数据库的数据文件。
安装与部署
现在进入部署环节。在你的NAS的Docker管理界面(如Portainer或群晖的Docker套件)中,创建一个新项目(Stack)。选择项目路径为我们刚才准备的openinggame目录,并导入其中的docker-compose.yml文件作为模板。
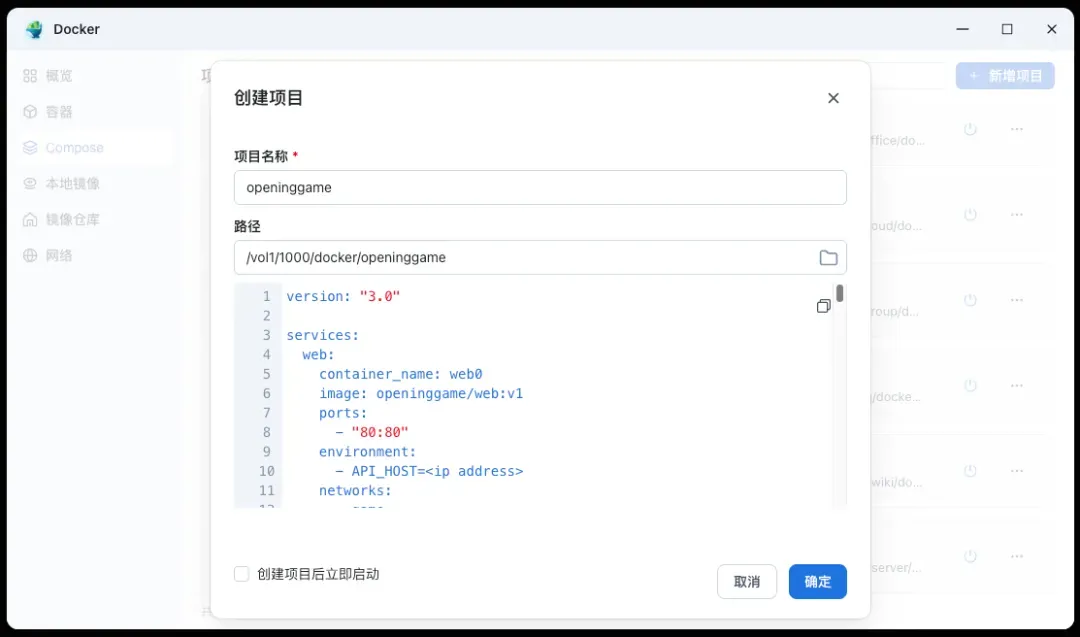
原始的docker-compose.yml模板内容较为全面,但部分配置可能需要根据你的实际环境进行调整,例如网络配置等。其完整内容如下:
version: "3.0"
services:
web:
container_name: web0
image: openinggame/web:v1
ports:
- "80:80"
environment:
- API_HOST=<ip address>
networks:
- game
depends_on:
- server
server:
container_name: server0
image: openinggame/server:v1
ports:
- "81:81"
networks:
- game
depends_on:
- etcd
- kafka
- redis1
- mysql
- mongodb
mysql:
image: mysql:8.0.23
container_name: mysql0
command:
--default-authentication-plugin=mysql_native_password
--character-set-server=utf8mb4
--collation-server=utf8mb4_general_ci
restart: unless-stopped
environment:
MYSQL_ROOT_PASSWORD: root
volumes:
- /data/mysql:/var/lib/mysql
- mysqlconf:/etc/mysql/conf.d
networks:
- game
redis0:
container_name: redis0
image: redis:latest
volumes:
- redisdata0:/data
command: redis-server --requirepass 123456
networks:
- game
depends_on:
- etcd
redis1:
container_name: redis1
image: redis:latest
volumes:
- redisdata1:/data
command: redis-server --requirepass 123456
networks:
- game
depends_on:
- etcd
redis2:
container_name: redis2
image: redis:latest
volumes:
- redisdata2:/data
command: redis-server --requirepass 123456
networks:
- game
depends_on:
- mysql
- etcd
- redis1
zookeeper:
container_name: zookeeper
image: wurstmeister/zookeeper
restart: always
networks:
- game
kafka:
container_name: kafka0
image: wurstmeister/kafka:2.12-2.3.0
environment:
- KAFKA_BROKER_ID=0
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka0:9092
- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092
volumes:
- /var/run/docker.sock:/var/run/docker.sock
restart: always
depends_on:
- zookeeper
networks:
- game
etcd:
image: quay.io/coreos/etcd:v3.2.32
container_name: etcd0
environment:
ETCDCTL_API: 3
command:
- etcd
- --name=etcd0
- --data-dir=/data/etcd-data
- --advertise-client-urls=http://etcd0:2379
- --listen-client-urls=http://0.0.0.0:2379
restart: always
volumes:
- etcd0_data:/etcd-data
networks:
- game
mongodb:
container_name: mongodb0
image: mongo:4.4.4
restart: always
volumes:
- /data/mongo_data:/data/db
- mongodb_logs:/data/logs
command: --auth
networks:
- game
depends_on:
- etcd
volumes:
mysqlconf:
mongodb_logs:
etcd0_data:
redisdata0:
redisdata1:
redisdata2:
networks:
game:
external:
true
为了简化部署过程,我使用了一个经过调整的模板。这个简化版主要修改了卷的挂载方式(使用相对路径./),并移除了自定义网络声明,让Docker Compose自动管理。你唯一需要修改的地方就是将environment中的API_HOST值,替换为你自己NAS在内网中的实际IP地址。
手把手教程:在NAS上部署E视界(DongguaTV),打造专属私人影院
本文将介绍如何将您的网络附加存储设备(NAS)转变为一个功能强大的个人流媒体中心。通过部署 E 视界(可视为冬瓜 TV 的增强与重构版本),您可以获得媲美主流平台的观影体验。E 视界是一款基于现代 Node.js 与 Vue 3 技术栈构建的流媒体聚合播放器,其设计理念强调智能化与沉浸感。
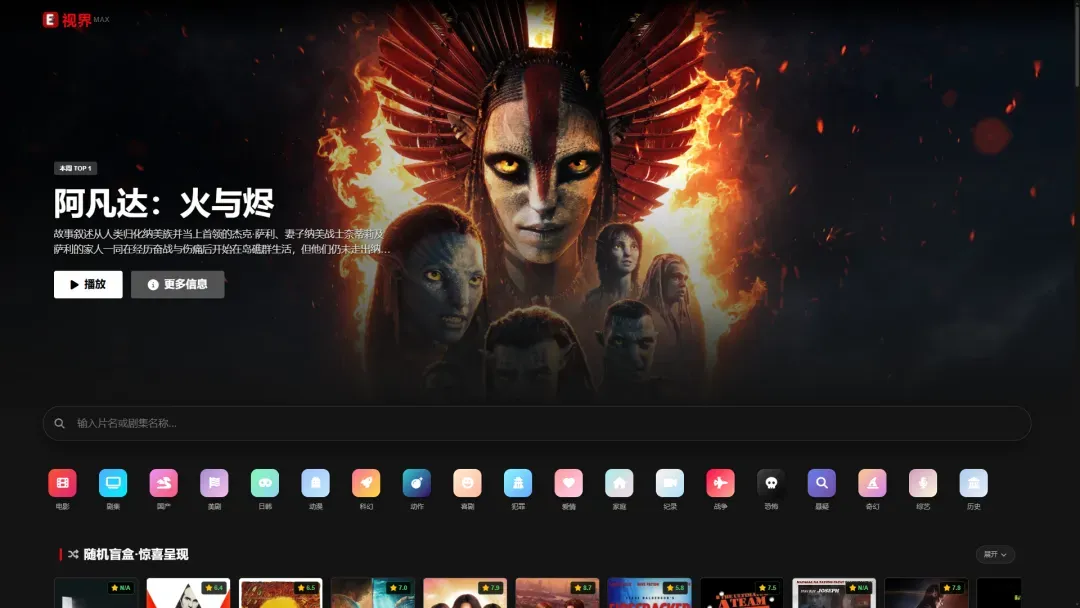
该软件的核心优势在于其双引擎架构与高度智能化的资源管理。一方面,它深度整合 TMDb(The Movie Database),为影视内容提供高质量的海报、背景图、评分、剧情简介及演职员表等元数据,界面风格向 Netflix 看齐。另一方面,它集成了超过 48 个第三方资源站点的 API(基于 Maccms),并具备自动测速与失效源过滤机制,确保播放线路的可用性与流畅度。
在搜索体验上,E 视界采用了实时流式搜索技术,搜索结果会即时呈现,无需等待所有源站返回。系统能自动将同一影片的不同播放线路进行分组与合并,并在卡片上动态显示可用源的数量。所有搜索记录与元数据均通过内置的高性能 SQLite 数据库进行缓存,实现秒级响应。
播放功能也经过精心设计。全新的影院模式播放页采用暗色系布局,支持剧集网格化选择。播放前会进行线路测速,并在播放失败时自动切换至下一个可用源,无需人工干预。软件还支持 DLNA/AirPlay 投屏功能。
针对中国大陆用户可能遇到的网络问题,E 视界进行了专门优化。它采用双重 IP 检测机制来准确判断用户地域,并自动切换至 TMDB 反代模式以保障元数据正常加载。所有核心前端依赖库均已本地化部署,彻底避免了因公共 CDN 访问不畅导致的加载缓慢问题。项目提供一键式安装脚本,简化配置流程。
在设备兼容性方面,E 视界表现全面。它提供专为 Android TV 或电视盒子优化的 APK 安装包,完美适配遥控器操作。移动端应用封装精良,支持沉浸式状态栏,提供接近原生应用的流畅体验。同时,它也支持 PWA,可添加到设备主屏幕快速启动。
安全管理功能包括可选的全局访问密码,支持长达一年的记住登录状态,兼顾安全与便利。此外,还支持从远程 URL 加载配置文件,便于多实例的统一管理。
请注意,本教程内容仅限用于技术学习与交流目的。在使用相关软件与服务时,请您务必严格遵守所在地的法律法规及各平台的使用协议,切勿将其用于任何商业用途或非法领域。
前期准备工作
在开始部署之前,您需要完成两项关键配置:准备采集源配置文件 db.json 以及获取 TMDb API 密钥。
配置采集源文件 (db.json)
影视资源的获取依赖于 db.json 文件中定义的采集源(站点)。配置的采集源越多,理论上可检索到的资源范围就越广。请注意,公开分享具体的采集源地址可能涉及侵权风险,因此需要您自行寻找和添加。
项目在首次运行时通常会尝试自动生成 db.json 文件。如果未能生成,建议您手动创建该文件。文件内容结构如下:
{
"sites": [
{
"key": "unique_key1", // 每个站点的唯一标识符(英文字母,不可重复)
"name": "站点名称1", // 在软件界面中显示的名称
"api": "https://...", // Maccms V10/JSON 接口地址
"active": true // 是否启用该站点
},
{
"key": "unique_key2",
"name": "站点名称2",
"api": "https://...",
"active": true
}
// 您可以继续添加更多站点
]
}
获取 TMDb API Key
TMDb 的 API 密钥用于拉取影片的详细信息、海报和评分等元数据,这对于提升界面美观度和使用体验至关重要。获取步骤如下: