智能便携干衣机独立站蓝海商机:2026年市场规模与DTC品牌策略分析
一、市场全景
全球便携式干衣机行业正步入结构性增长阶段。Verified Market Research 数据显示,2025 年市场体量约 12 亿美元,预计 2033 年将扩大至 24.2 亿美元,2027‑2033 年复合年增长率达到 9.2%。DataIntelo 的调研进一步揭示,电动型便携干衣机在 2025 年以 12.2 亿美元的规模拿下 72.4% 的市场份额,牢牢占据统治地位。
智能干衣机大类同样为便携品类带来更高的溢价想象空间。依据 DataIntelo 报告,2025 年全球智能干衣机市场规模已达 185 亿美元,到 2034 年将突破 312 亿美元,年复合增长率 6.8%。细分来看,物联网机型贡献 38.5%,传感器机型占 31.2%,远程控制类占 21.4%。需要关注的是,便携式产品仅占干衣机总盘的 15.2%,但在小户型租房、大学宿舍、房车和 Vanlife 等居住形态的刺激下,增速大幅领先传统大容量机型。
区域格局
| 地区 | 2023 年占比 | 核心特征 |
|---|---|---|
| 亚太 | 35% | 制造端主导,城市化驱动,增速领跑 |
| 北美 | 27% | 公寓/RV/宿舍需求强劲,DTC 接受度高 |
| 欧洲 | 22% | 能效法规严苛,偏好节能与紧凑型设计 |
| 拉美 | 9% | 新兴中产推动基础款消费 |
| 中东及非洲 | 7% | 基数小,酒店与公寓场景潜力可观 |
趋势洞察:微型居住、远程办公日常化、房车与移动生活的流行,共同催生出“小体积、全功能”的衣物护理诉求。消费者期待产品占地省、免安装、有智能化加持且低噪音运行,这正是主流品牌尚未充分响应的空白地带。
二、竞争生态
当前亚马逊平台上的便携干衣机呈现明显的两极分化:低价端是 40‑80 美元的折叠暖风式干衣袋,容量有限、体验欠佳;高端端是 170‑400 美元的传统滚筒式紧凑干衣机,功能基础、外观偏工业风。融合智能传感器、App 互联与精美设计的 DTC 品牌几乎缺席。
| 品牌/型号 | 价格 | 亚马逊评分 | 容量/功率 | 核心卖点 | 主要缺陷 |
|---|---|---|---|---|---|
| Euhomy MJC‑T03 | $178 | 5.0★ | 1.5 cu.ft / 10 lb / 850W | 三层过滤、广角门、运行安静 | 无智能功能、烘干时间长 |
| Panda PAN760SF | $197 | 4.8★ | 1.5 cu.ft / 6 lb / 850W | 湿度传感器、可壁挂、口碑稳固 | 外观老旧、无 App、品牌感薄弱 |
| ROVSUN 110V | $229 | 4.6★ | 5.5 lb / 850W | 不锈钢内筒、壁挂/台面两用 | 容量偏小、程序单一 |
| MOJOCO 折叠式 | $39‑59 | 4.4★ | 9 件衣物 / 暖风 | 折叠便携、UV 消毒、低价 | 厚重衣物难干、功率不足 |
| Effidry S3 | $299 | 4.3★ | 150W / 8 种模式 | 湿度感应、8 种程序、可烘鞋 | 定价过高、功率仅 150W、烘干慢 |
| Black+Decker BCED37 | $388 | 4.1★ | 3.5 cu.ft / 13.2 lb / 1500W | 大容量、多段温控、过热保护 | 体积庞大、能耗高、无智能 |
| Rolitwils 折叠式 | $56 | 3.9★ | 33L / 4‑6 件 / 900W | 遥控、UV、可折叠 | 容量极小、塑料感强、品控不稳定 |
竞争综述:Euhomy 与 Panda 靠性价比和口碑占据滚筒式品类头部,但产品思维仍停留在传统家电阶段;Effidry 试探智能化路线,却在定价与功率上失衡;折叠暖风机虽价廉,但体验天花板十分明显。120‑180 美元价格区间、集智能传感器 + App + 静音 + 设计感于一身的滚筒式便携干衣机,是尚未有 DTC 玩家进入的绝对蓝海。
2026 Codex 十大必备 Skills 实战指南:从规划到安全,榨干 AI 编程的全部潜能
一位 Reddit 开发者感叹:“给 Codex 装上合适的 Skills 之后,对我来说它甚至比 Claude Code 更顺手。”这绝非孤例。2025 年末,OpenAI 将 Skills 正式集成到 Codex 中,SKILL.md 随之成为跨工具的开放标准——短短几周,公开技能数量就从两千多爆发到超过 4 万个。但面对海量选择,绝大多数人根本不知道该装哪几个。这篇文章帮你把范围压缩到 10 个:依照真实安装量与 GitHub 星标排序,依次覆盖规划、联网、安全、前端、MCP、会话交接等高频刚需场景。装完这 10 个,你的 Codex 才真正进入“满血”状态。
一、先说清:Skills 为何如此火爆
很多人分不清 Skills、提示词与 MCP 的区别。先把概念厘清,才会理解为什么要安装。
Skills 是什么:它是一种可复用的行为模块,存放在 .agents/skills/(或 .claude/skills/)目录下,核心是一个 SKILL.md 文件。文件结构包含 YAML 头部(名称、描述、触发条件)+ Markdown 正文(具体执行步骤)。
它与 MCP 的关键差异,正是它迅速走红的根源:
| 维度 | Skills | MCP |
|---|---|---|
| 上下文开销 | 仅当任务匹配时才加载,不匹配零消耗 | 每个会话都占用上下文 |
| 启动负担 | 只读取名称和描述(约占 2% 上下文) | 服务器定义常驻内存 |
| 加载方式 | 渐进式,按需展开详细指令 | 全量暴露工具定义 |
Hacker News 上一条高赞评论一语中的:“Skills 成为标准意义重大,从长期看甚至比 MCP 更重要。” 原因就在于架构设计——Skills 上下文效率极高,MCP 则不然。一个 Skill 只在任务匹配时被唤醒,其余时间处于休眠状态;而 MCP 的服务器定义无论你用不用,都会在每个会话中持续占用上下文。
2026 Prime Day首日战况解析:TK直播拍卖引爆流量,夏季爆款选品与复购飞轮全攻略
本期跨境精选聚焦5大热点:亚马逊Prime Day首日开抢,TikTok Shop直播拍卖成流量新引擎;夏季爆款选品全景图揭示太阳镜、便携风扇、世界杯周边三大爆点;独立站复购率从12%飙至45%的5步法与盈亏平衡ROAS公式;以及美线运价高位与菜鸟荷兰履约中心落地带来的物流新格局。

Prime Day首日开战:4天大促开启“决胜时刻”
2026年亚马逊Prime Day于6月23日正式开抢,持续至6月26日,覆盖美国、加拿大、英国、德国、法国、日本等23个国家,是自2021年以来首次在6月举办的Prime Day。88%受访Prime会员明确表示计划参与本届大促,叠加初夏购物热潮,亚马逊官方预计本届有望成为上半年销量冲刺的最强引擎。
首日实况呈现三大特征:
流量爆发与转化压力并存——大促首日流量普遍上涨200%‑400%,但因折扣门槛收紧(60天最低价+95折),转化率较平日仅提升15%‑25%,中小卖家利润空间被进一步压缩。
AI推荐新算法主导曝光——亚马逊对搜索推荐算法完成新一轮AI迭代,权重从“历史销量”转向“用户行为预测”,新品曝光机会提升30%,但要求Listing具备更精准的人群标签数据。
IP风控黑箱化加剧——TRO(临时限制令)侵权冻结同比增加32%,AI自动识别系统对未授权品牌词和图案的敏感度大幅提升。
卖家首日行动建议:①密切监控ACOS数据,将广告预算向ROAS小于2的高转化关键词倾斜;②针对首页坑位失守的SKU立即启动BD/LD紧急补救;③大促期间客服响应时长需控制在4小时内,避免因迟发率超标影响Q3表现。
值得关注的原因是,今年是史上最早的Prime Day,与沃尔玛Walmart Deals(6/22‑28)、TikTok Shop DFYD(6/17‑7/3)三大平台大促窗口完全重叠。首日数据将直接决定后续三天的预算分配与补货节奏。
TikTok Shop美区DFYD年中促:直播拍卖点燃流量新引擎
TikTok Shop美区“Deals For You Days”年中大促(6/17‑7/3共16天)已进入第7天冲刺阶段。平台公布的中期战报显示:跨境总GMV同比增长106%,单日GMV达平日1.6倍,内容场GMV更达到平日1.7倍。今年最受关注的玩法是直播拍卖首秀——6月26日拍卖日TikTok Shop将开放3%佣金让利,时均GMV达普通直播的4倍。
三大消费窗口叠加:
- 6/17‑23:年中开门红(美妆/家居主推)
- 6/24‑29:直播拍卖周(3%佣金让利)
- 6/30‑7/3:世界杯决赛周+暑期返校季启动
卖家实操要点:
- 直播间运营——日均直播时长需不少于6小时,每小时至少安排3次互动抽奖(点赞/关注/分享),达人带货佣金建议设置阶梯激励。
- 小店内嵌商品卡——视频内容中“小黄车”商品卡的点击率比传统链接高出40%,需在视频发布后30分钟内完成挂车。
- 美区回流——TikTok Shop美区已支持PayPal支付,回流的美区用户可实现跨平台再营销。
值得关注的原因在于,TikTok Shop内容电商模式与传统货架电商的运营逻辑差异巨大。本届DFYD首次引入“直播拍卖”玩法,3%佣金让利是历史最低。跨境卖家应将其作为亚马逊、沃尔玛之外的第三战场重点布局。
夏季选品全景:太阳镜、便携风扇与世界杯主题三大爆点
Prime Day开抢当日,跨境夏季选品已进入“黄金窗口”。基于近30天亚马逊、TikTok Shop、Walmart三平台销售数据,本期梳理出三大夏季爆款选品方向:
选品方向一:太阳镜+时尚配饰——6月正值欧美度假季与户外婚礼高峰,太阳镜在亚马逊美站月销近2万件,毛利率高达85.8%,比3C、家居品类高出20‑30个百分点。重点关注偏光太阳镜、儿童太阳镜、运动墨镜等细分赛道。
选品方向二:便携风扇+夏季小家电——便携风扇霸榜亚马逊“夏季热销TOP10”中的6席(美森/JOY/OPOLAR等品牌),10000mAh以上长续航款占据70%的销量。延伸品类包括颈挂风扇、桌面加湿风扇、便携冰雾仪等。
选品方向三:世界杯主题周边——2026美加墨世界杯(6/11‑7/19)持续放量,跨境卖家应聚焦三类商品:①通用足球周边(护腿板/训练背心/哨子),侵权风险低;②观赛场景(投影仪/大屏电视/看球零食);③POD定制(国旗球衣/纪念徽章)。义乌Q1体育用品出口达28.3亿元(+12%),对美加墨出口5.5亿元(+21.3%)。
| 选品方向 | 代表品类 | 月销量(头部SKU) | 毛利率 | 侵权风险 |
|---|---|---|---|---|
| 太阳镜配饰 | 偏光/儿童/运动 | 19,820件 | 85.8% | 中(需避大牌) |
| 便携风扇 | 颈挂/桌面/USB | 8,500+件 | 55‑65% | 低 |
| 世界杯周边 | 通用训练/观赛 | 12,000+件 | 50‑70% | 中(避开官方) |
| 夏季宠物 | 凉垫/冰丝窝 | 6,200件 | 60%+ | 低 |
夏季选品窗口期短(6‑8月),选对赛道决定整个Q3利润。建议卖家本周锁定2‑3个高毛利夏季品类,结合Prime Day、DFYD与世界杯决赛三轮流量高峰实现爆单。
2026年618 AI硬件爆款:钉钉A1 Pro录音卡深度测评,如何将语音转化为智能工作流
2026 年的年度关键词,非“Vibe Coding”莫属。这股风潮不仅席卷了软件圈,也开始感染硬件爱好者,从 PCB 板、宏键盘到单片机芯片,年轻人纷纷在 618 购物节为 AI 购置装备,开启了一股“为 AI 消费”的新趋势。

在众多 AI 硬件中,今年 618 有两款音频设备格外抢眼,它们的思路截然不同,却同时瞄准了“声音的价值”。
一款是 Teenage Engineering 的 TP-7,这个让硬件控一眼沦陷的 field recorder。顶级的工业设计,转动起来的“磁带盘”、侧边摇杆和精密金属机身,不仅录播俱佳,还能多轨音频剪辑,为纯粹的声音创作而生。

另一款是钉钉的录音卡 A1 Pro,它走的是全然不同的产品逻辑。机身吸在手机背板上,轻轻一按开始录音,但真正的价值在录音之后才涌现:文件自动同步至钉钉 AI 听记,紧随其后的是高精度转写、AI 纪要、章节与发言人自动划分,所有整理工作悄然完成,像一桌子菜直接端到面前。
TP-7 关注声音本身,而 A1 Pro 更在意声音里承载的信息,以及这些信息接下来要流向哪里。

从一代 A1 升级到 Pro 版本,A1 Pro 的设计与易用性都明显提升。硬朗的机身厚度仅 6.4 毫米,新增的磁吸功能让它能直接吸附在 iPhone 背板上,收音系统更精细,使用起来毫无累赘感。更难能可贵的是,这块录音卡还是一个应急充电宝——通过右侧按键一键切换,内置的 2980mAh 电池可为手机反向充电,关键时刻能解燃眉之急,也让随身携带的理由又多了一个。
把 A1 Pro 这样的 AI 硬件顺畅接入内容生产流程,是很多资深用户最认可的一点。走路时闪现一个点子,可以按住语音备忘键口述记录;面聊或访谈时,只需长按两秒录音键,再把设备往桌上一放,毫无侵入感。对话结束后,钉钉 AI 听记立即接管,转写、摘要、重点提炼,甚至情绪都能完整复述。遇到来不及看的英文视频和播客,用 A1 Pro 超低音量收音,它也能悄无声息地完成任务。之后整理音频与文字,创作墨问、公众号、播客等内容,整个过程顺滑得像一条流水线。
2026 年的 618 战报,印证了 AI 硬件的热度。数据显示,截至 5 月 31 日,天猫 618 AI 智能硬件整体同比增长 80%,AI 眼镜品类同比翻了 9 倍,AI 陪伴精灵增长 270%。AI 录音卡赛道的爆发同样值得关注,钉钉 A1 同时拿下天猫、抖音、京东三大平台销量第一,成为今年 618 AI 硬件领域的现象级单品。
2026年Prime Day启幕:沃尔玛抢跑首出海加拿大,速卖通本地仓占比破50%,跨境新规密集落地
【跨境动态】6月25日 第46期
本期导读 精选五条跨境头条:1) Prime Day大促(6.23‑26)迎来史上最严折扣新规,60天最低价屏障、AI算法与IP风控叠加,6月卖家集体承压;2) 沃尔玛 Walmart Deals 今日(6.22)抢先开跑,Walmart+ 会员服务首次走出美国、落地加拿大,月费8.97加元;3) 速卖通覆盖五国的官方本地配送“平台配”上线,本地仓发货占比首次突破50%,平均履约时效从5天压缩至3天;4) Kickstarter 独立站成功案例解析,大件出海澳洲站18个月GMV从35万元飙升至2000万元;5) 6月外贸八项新规密集生效,美国301关税听证会申请今日截止,亚马逊欧洲站COO强制标注进入倒计时。一文速览本周关键变量。

01 | Prime Day倒计时:史上最严折扣新规落地,6月卖家集体“渡劫”
2026年亚马逊Prime Day于**6月23日至26日(为期4天)**正式开跑,这是自2021年以来首次将大促档期提前至6月。大幕拉开前,大量卖家却陷入订单骤降的被动局面:6月中旬以来,美国站众多卖家的后台单量出现30%‑70%的断崖式下滑,部分中小卖家日销量直接腰斩。
订单“速冻”背后是三重因素叠加:① 美加墨世界杯分流:6月11日开幕的世界杯覆盖约5亿受众、50亿观赛人次,户外配饰类卖家开赛首日单量即遭拦腰横斩,店铺访客跌幅逼近60%;② 大促前持币观望:3C数码、家居等品类的卖家普遍反映,店铺加购数据持续走高,但转化率断崖式下降;③ 四大平台16天促销重叠抢单:TikTok Shop“Deals For You Days”(6.17‑7.3,长达16天)、沃尔玛Walmart Deals(6.22‑6.28)、Target(6.23‑6.26)以及Temu(预计6月下旬)在同一时段集中发力,超七成美国消费者习惯在多平台间比价后下单。
今年的Prime Day规则升级堪称“史上最严”:60天内的历史最低价参考基准、至少95折的折扣门槛、迭代后的AI推荐算法以及IP风控日趋黑箱化(TRO侵权冻结案件同比上升32%),三重绞杀让中小卖家的利润空间被急剧压缩。差异化应对思路建议如下:主力爆款(高毛利、高转化、库存充裕)可适度冲排名,折扣幅度控制在10%‑18%;利润款以守利润为主,广告预算可暂时缩减30%‑50%;滞销款不计利润深度清仓;新品则以小额预算试水,把获取评论作为主要目标。
来源:知乎《单量腰斩,6月亚马逊卖家集体“渡劫”!》(2026‑06‑17),原文链接:https://zhuanlan.zhihu.com/p/2050702566518941508
02 | 沃尔玛Walmart Deals今日抢跑+首出海加拿大:8.97加元/月,正面硬刚Prime Day
沃尔玛年度大促Walmart Deals于6月22日至28日(为期7天)开启,较去年7月大幅提前。Walmart+会员可自6月21日起享受24小时提前购特权。本次促销覆盖电子产品、家居、玩具、户外、服饰等全品类,同步联动线上平台与线下全部门店。
更值得跨境卖家关注的是Walmart+会员服务首次走出美国:6月6日沃尔玛正式宣布加拿大成为首个国际试点市场,用户每月支付8.97加元或年付89加元,即可享受不限金额的门店当日配送、网站免邮、2小时内极速送达,并附赠Crave流媒体权益。这是继沃尔玛上线墨西哥站跨境收款(PingPong 6月16日已支持)并拓展加拿大市场之后的又一国际化举措。中国卖家“美墨加跨境三角”已正式成形。
卖家应对建议:① 沃尔玛平台卖家:昨日(6月21日)已进入Walmart+会员提前购窗口,建议借助美西海外仓提前备货;② 有意入局沃尔玛的卖家:美西FBA入库费25%的降幅红利仍在,叠加此次大促流量高峰,恰是低成本测款窗口;③ 加拿大跨境卖家:Walmart+会员出海标志着北美市场进入“会员深度运营”阶段,订阅+配送+流媒体的组合拳将深刻改变平台流量分配逻辑。
来源:搜狐《沃尔玛大促定档6月22日》(2026‑06‑11),原文链接:https://www.sohu.com/a/1035296433_100263953;网经社《沃尔玛会员服务Walmart+在加拿大试点上线》(2026‑06‑08),原文链接:https://www.100ec.cn/detail–6659988.html
03 | 速卖通五国本地仓发货占比首破50%:时效5天→3天,定价低于市场10%‑20%
6月11日,阿里速卖通AliExpress正式在美国、波兰、法国、西班牙、墨西哥五国上线官方本地配送服务“平台配”,覆盖欧洲、北美、拉美三大经济圈。商家接入后可依托海外仓实现本地发货与本地配送,平均履约时效从原先的5天缩短至3天,物流定价较市场均价低10%‑20%,并同步获得六大权益支持:揽收及到货延迟免除惩罚、NR不计入考核、自动举证、搜索加权、大件保障以及专属客服。
更具标志性的转折点出现于:速卖通夏季大促期间,在西班牙、法国、波兰等核心市场,欧洲本地仓发货订单占比首次突破50%,反超跨境直发订单。这是速卖通欧洲业务自启动“Local‑to‑Local”战略以来的里程碑。同一时期,6月15日速卖通在澳大利亚正式推出“Local‑to‑Local”业务模式,将其在欧洲、韩国验证成功的本地化策略延伸至南半球。
对跨境卖家的影响:① 海外仓从“可选项”升级为“必选项”——本地仓发货订单在NR不计入考核、自动举证、搜索加权等六大权益加持下,已获得显著的流量倾斜;② 海外仓+小包直邮“双轨”供应模式成型——大件、高价值、复购商品走本地仓,低值小件依靠直邮;③ 拉美市场加速布局——墨西哥本地仓配合沃尔玛墨西哥站收款(PingPong 6月16日已支持),中国卖家在拉美可形成“本地仓+本地收款+本地平台”的完整闭环。
来源:网经社《速卖通在欧美拉五国上线本地配送服务》(2026‑06‑11),原文链接:https://100ec.cn/detail–6660129.html;DoNews《速卖通上线平台配服务》(2026‑06‑13),原文链接:https://www.donews.com/news/detail/4/6594420.html
04 | 30岁入行Kickstarter打造千万品牌:5步法+复购率12%→45%独立站成功案例
独立站圈最新标杆案例浮现:一位创业者在30岁入行,从零起步借助Kickstarter众筹出海,五年内打造出年营收千万级的品牌,复购率从12%大幅攀升至45%。其核心方法论可以概括为“五步法”——精准选品验证(众筹测试)、极致产品打磨(与用户共创并迭代十余个版本)、KOL矩阵化营销(YouTube深度测评+红人种草)、Shopify独立站承接(将众筹流量沉淀为私域资产),以及邮件营销+订阅制组合驱动复购率持续拉升。
另一个值得借鉴的**“大件出海”案例**同期走红:某家居品牌以超大件品类(家具、家电)切入澳洲站,18个月内GMV从35万元飙升至2000万元人民币,增长约57倍。其核心打法包括:① 选品避开了红海竞争,转向高客单价、高壁垒的大件品类;② 高度重视本地化履约,与澳洲本地3PL深度合作,将配送时效稳定在5‑7天;③ 以视频内容营销为主力,在TikTok、YouTube和Instagram三大平台协同种草;④ 依靠高客单价和强服务构建竞争壁垒,主动避开价格战。
当前独立站存在三大红利窗口:① AI搜索流量——Google AI概览、ChatGPT Shopping等AI驱动的搜索结果成为新流量入口,其转化率可以达到常规搜索的23倍;② 套装化营销——“露营套装、家庭后院套装、返校宿舍套装”等组合能够将客单价提升30%‑50%,有效避免单品低价竞争;③ 私域复购——独立站+邮件营销+订阅制三者结合,将复购率从10%级提升到40%级,正是2026年独立站运营的核心指标。2025年独立站出海成交增速已达到45%,“独立站+GEO优化+套装营销”正在成为2026年跨境出海的新三角。
2026年智能宠物烘干箱赛道全解析:百亿市场缺口与DTC突围路径

产业背景:从“养活”到“养好”的跃迁
全球宠物经济正经历一场深刻的范式转移——美国年宠物消费已经突破1500亿美元,9600万个观鸟家庭则从另一侧面印证了人宠关系的情感化升级。在这一轮浪潮中,洗护后的干燥护理环节成为增长最快的隐性赛道之一。诞生仅三年的宠物烘干箱品类,以8%至9.1%的年均复合速度持续扩张,吞噬着传统手持吹风机的市场份额,而当前正处在用户教育深化、DTC品牌空白的黄金切入期。
本文将从市场格局、竞品缺陷、品牌真空地带以及品牌化解决方案四个维度,完成对这一品类的系统性拆解。
一、行业全景:一个加速走向大众的细分市场
全球宠物烘干箱(Pet Dryer Box / Pet Drying Cabinet)正在完成从早期尝鲜者到早期大众的跨越。
1.1 规模与增长曲线
- 2025年基准市场规模:1.5亿美元(数据来源:Data Insights Market)
- 2030年预测值:2.2亿美元
- 年复合增长率:8.0% – 9.1%(研究区间2020-2034,保守取8%)
- 2031年展望:2.37亿美元
另一份来自QY Research的中国市场数据显示,2023年国内宠物智能烘干机市场约合33亿元人民币,预计到2030年达到48亿元,对应CAGR为5.6%。中美市场体量差异的核心原因在于两国宠物洗护店密度悬殊,使得独立家用烘干箱在国内的渗透仍处于较早阶段。
1.2 区域市场结构
| 区域 | 市场份额 | 显著特征 |
|---|---|---|
| 东亚(中国主导) | 35–40% | 全球制造与消费双中心,品牌出海活跃 |
| 北美 | 28–32% | 67%家庭养宠、高客单价、线上增速强劲 |
| 欧洲 | 22–25% | 德国/英国/法国为主,宠物美容文化深厚 |
| 亚太(中国以外) | 8–12% | 增速最快,印度、东南亚中产阶层宠物消费年增超15% |
1.3 正在成型的结构性趋势
- 线上渠道领跑:2024–2030年线上渠道预计以超过10%的复合增长推进,DTC独立站构成最大增量。
- 体型兼容性上升:适配20–30kg中大型犬的烘干箱份额持续上升,同时城市小户型对大容量小体积设计同样抱有旺盛需求。
- 智能功能成为标配:Wi-Fi/App远程控制、负离子、UV杀菌、恒温等技术已从加分项变为准入门槛。
- 静音性能转化为刚需:低于40dB的工作噪音成为高端产品的护城河,典型如Homerunpet Drybo Plus。
二、竞争版图:制造端成熟,品牌端真空
当前赛道表现出“中国制造主导+海外品牌高端化”的二元结构,而中间地带的品牌化机会极为醒目。
| 品牌/型号 | 价格(USD) | Amazon评分 | 容量/功率 | 核心卖点 | 主要短板 |
|---|---|---|---|---|---|
| Homerunpet Drybo Plus | 329–399 | 4.5★(4200+) | 63L / 350W | 40dB超静音、300万负离子、专利新风系统、兽医推荐 | 无WiFi/App、最高温度仅40°C |
| PawGalaxy Pet Dryer Box | 189–249 | 4.3★(2800+) | 65L / 1000W | 3000万负离子、LED照明、儿童锁 | 噪音偏高55–60dB、塑料质感 |
| ROOPET Pet Drying Box | 219–299 | 4.1★(680,新品) | 65L / 1200W | 360°内外循环、去异味 | 58dB噪音、样本评价较少 |
| Goodmom Pet Dryer | 159–219 | 4.4★(1200+) | 63L / 1000W | 双模式(静音/快速)、360°气流 | 部分宠物抗拒、材质塑料感 |
| Pridcier Pet Dryer | 179–239 | 4.2★(850) | 63L / 1000W | 双模式、360°气流 | 材质耐久性存疑 |
| iPettie Pet Dryer Box | 199–269 | 4.3★(920) | 60L / 800W | 触控面板、4档风速 | 风扇噪音仍偏大、容量有限 |
| BESTZONE Pet Dryer | 99–149 | 4.0★(410) | 65L / 1000W | 负离子+银离子、儿童锁 | 机身沉重近20磅、塑料感突出 |
| AEOLUS(Shernbao代理) | 249–349 | 4.4★(600+) | 60–80L | 工业级品质、线下专业渠道强 | C端品牌认知弱、无App |
竞争格局三条关键发现
2026智能纳米补水仪跨境选品深度洞察:DTC品牌真空带与HydraMist突围路径
一、市场全景洞察
全球蒸面仪(Facial Steamer)赛道正在经历一场“家用普及化叠加智能升级”的双重变革。据权威研究机构GMI(Global Market Insights)统计,2024年全球市场规模约为6.273亿美元,2025年有望攀升至6.703亿美元,至2034年将增长至12.3亿美元,预测期内复合年增长率(CAGR)达7.0%。与此同时,QYResearch针对纳米离子细分品类的估值更为乐观——2024年约9.03亿美元,预计2030年将达13.86亿美元,CAGR约为7.4%。Deep Market Insights的补充数据显示,纳米离子蒸面仪在专业线渠道(美发沙龙、水疗中心及医美机构)的应用增速尤为突出,2025至2030年复合增速维持在**6.5%至7.4%**之间。
推动市场持续扩张的三大核心动力分别是:① Z世代护肤仪式感经济 —— TikTok平台中#skincareroutine话题累计播放量已突破600亿次,“蒸汽开脸”正迅速成为每周居家SPA的固定环节;② 极简护肤(Minimalist Skincare)浪潮 —— 补水、促渗、打开毛孔三元需求被一台设备集成,对比六瓶精华的复杂步骤,更符合当代消费者“化繁为简”的偏好;③ 医美术后修复场景的刚性需求 —— 激光、刷酸、微针等专业项目后,必须辅以冷热敷护理,而纳米级蒸汽被业内公认为最安全温和的修复方案。以上三大场景相互叠加,促使该品类从边缘性“小众美护工具”跃升为“家庭SPA生态的核心入口”。
从区域版图看,北美市场以约38%的占比稳居首位(受益于DIY SPA文化的盛行与皮肤科医生的广泛推荐),欧洲市场约占28%(法国、德国等高端美容护理市场发展成熟),亚太地区占比在**25%左右,但增速领跑全球,CAGR高达8.5%**以上,日本、韩国及中国台湾地区历史悠久的“蒸脸文化”为品类增长提供了深厚的土壤。

二、竞争态势深度解析
| 品牌/型号 | 价格区间(美元) | Amazon 评分 | 核心卖点 | 关键短板 |
|---|---|---|---|---|
| Panasonic EH-SA31 | $130-180 | 4.5★ (2600+) | 纳米水离子技术、温冷交替护理、日本精工品质 | 不支持App与WiFi、水箱仅180毫升、2014年上市型号陈旧 |
| Pure Daily Care NanoSteamer PRO | $45-65 | 4.4★ (28,000+) | 三合一功能(蒸面+热毛巾+香薰)、纳米离子 | 塑料材质廉价感明显、无智能模块、运行噪音偏大、存在塑料异味 |
| Conair True Glow | $30-50 | 4.2★ (4,300+) | 传统知名品牌、价格极具亲和力、全塑料机身 | 无纳米离子技术、无精准温控、无App连接、产品寿命相对较短 |
| TaoTronics TT-AH002 | $35-55 | 4.1★ (2,800+) | 大容量水箱、90秒快速加热、6档可调 | 设计廉价、塑料异味较重、缺乏智能功能 |
| Kinga Facial Steamer Pro | $80-110 | 4.3★ (1,500+) | 木质+玻璃+金属混搭设计、具备温度控制 | App体验较差、水箱偏小、缺乏耗材订阅生态 |
| PMD Beauty Facial Steamer | $150-200 | 4.0★ (900+) | 网红效应、品牌溢价、温冷双重模式 | 无App及WiFi功能、塑料外壳与高价不符、价格虚高 |
| TASALON Ozone Steamer | $40-60 | 4.2★ (1,100+) | 臭氧杀菌功能、专业线背景 | 造型传统、无智能联动、无耗材体系、品牌力薄弱 |
市场整体呈现鲜明的哑铃型结构:① $30-50低位红海区间 聚集了大量全塑料白牌产品,且Conair、TaoTronics等代表型号缺乏智能属性;② $80-110中段价格真空带 几乎只有Kinga一家,但其智能化和设计短板明显,尚无真正意义上的DTC品牌;③ $130-200高端封闭区间 由Panasonic、PMD把持,然而产品停留在2014年时代的技术水平,完全缺失AI驱动、App交互及订阅服务。因此,DTC品牌最佳切入的价格窗口维持在**$89-99**这一黄金点位。
AGENTS.md 团队落地复盘:被 Codex 无视的规范文件如何救活 8 人后端组
老王是一个 8 人后端组的技术负责人。他照着网上的模板,把公司 Java 开发规范整理成一份 200 行的 AGENTS.md 提交进仓库,心想这下团队用 Codex 总算有章可循了。一周后他拉了个新人问:“Codex 现在按咱规范写代码了吧?”新人一脸懵:“啥 AGENTS.md?Codex 该咋写还咋写啊。”——这不是老王一个人的遭遇,而是 90% 团队落地 AGENTS.md 的真实写照:写了一份文件,不等于它生效了。 这篇文章,就是复盘一个团队是怎么从“形同虚设”一步步走到“全员提效”的。
一、模板照搬为何必然失败
先看老王团队踩的第一个坑,也是绝大多数团队的第一反应——从网上找一份“最佳实践模板”粘贴进项目根目录。
老王那份 AGENTS.md 长这样(节选):
# 项目开发规范
我们团队高度重视代码质量,遵循阿里巴巴 Java 开发手册。请大家
在使用 Codex 时,务必保证:
- 编写干净、可维护的代码
- 充分重视单元测试
- 注意数据库安全,避免 SQL 注入
- 优雅地处理异常
- 性能上尽可能优化
结果呢?Codex 该不写测试还是不写测试,该用 SELECT * 还是用 SELECT *。团队成员试了两周,得出了一个结论:“AGENTS.md 这东西,没用。”
失败的真正原因
GitHub 分析过 2500 个包含 AGENTS.md 的仓库,得出一个扎心的结论:大多数 Agent 指令文件失败,不是因为技术限制,而是因为太“模糊”。
老王的文件犯了 AGENTS.md 的四个典型错误:
| 反模式 | 老王文件里的原文 | 为什么无效 |
|---|---|---|
| 散文段落 | “我们高度重视代码质量” | 没有可执行指令,只是模糊偏好 |
| 模糊指令 | “充分重视单元测试” | “充分”没有定义,没法验证 |
| 模糊指令 | “尽可能优化性能” | “尽可能”不是触发条件 |
| 无强制执行 | “遵循阿里手册” | 没有 lint 命令,Agent 无法自检合规 |
记住这条铁律(上一篇文章讲过,这里再强调一次,因为它是团队落地的命门):没有验证命令的指令是“建议”,不是“规则”。 Agent 读到“重视测试”这种话,会把它标记成一个模糊偏好,然后继续按自己的来。
AI还原3D坦克大战再进化:原版地图与子弹逻辑完美复刻,外加自制关卡编辑器
在上一篇文章中,我们借由 Claude、Fable 与 Codex 的协作,成功让经典游戏《坦克大战》以 3D 形态重生,且网页版与桌面版均已同步发布。但玩过之后总觉得仍有些许遗憾——不妨先用 AI 生成的 2D 参考图做个对比。
这是 AI 绘制的结果:
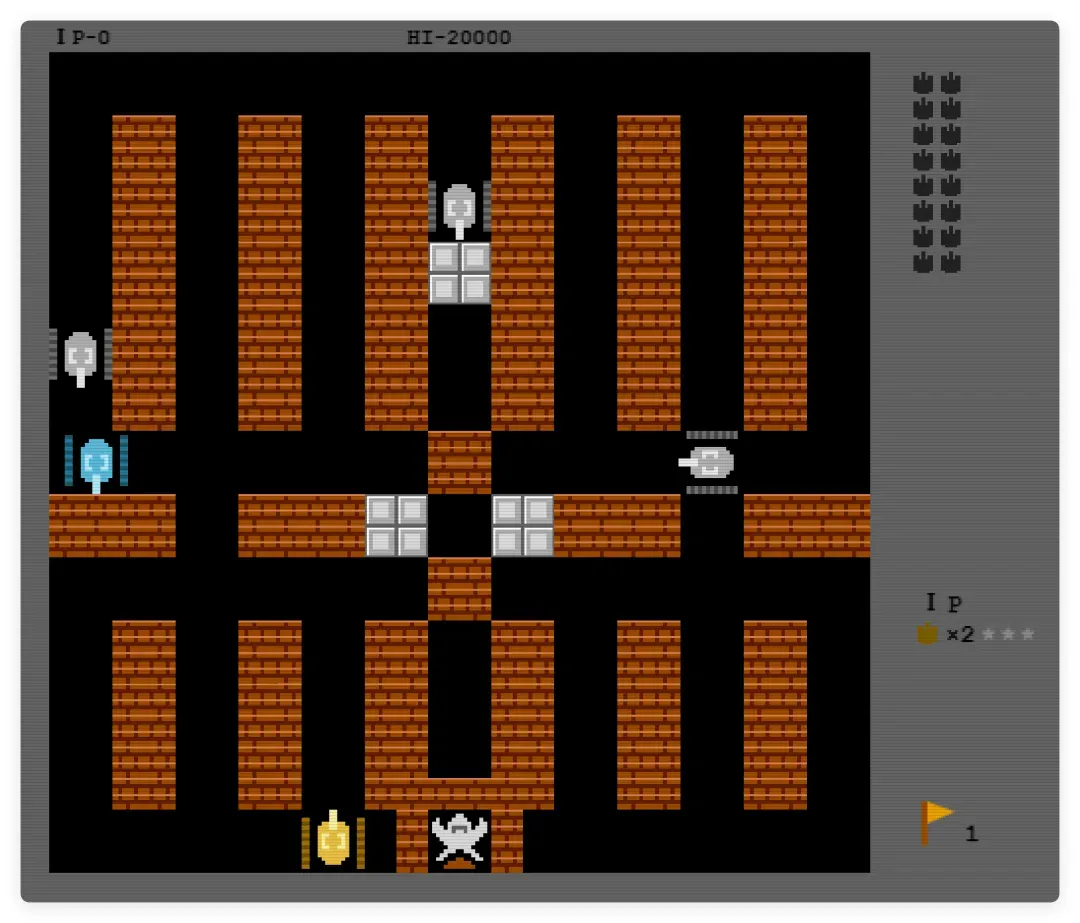
为了精准对照,我特地找来模拟器,加载《坦克大战》的 NES 原版 ROM,截取了原始画面的第一关:
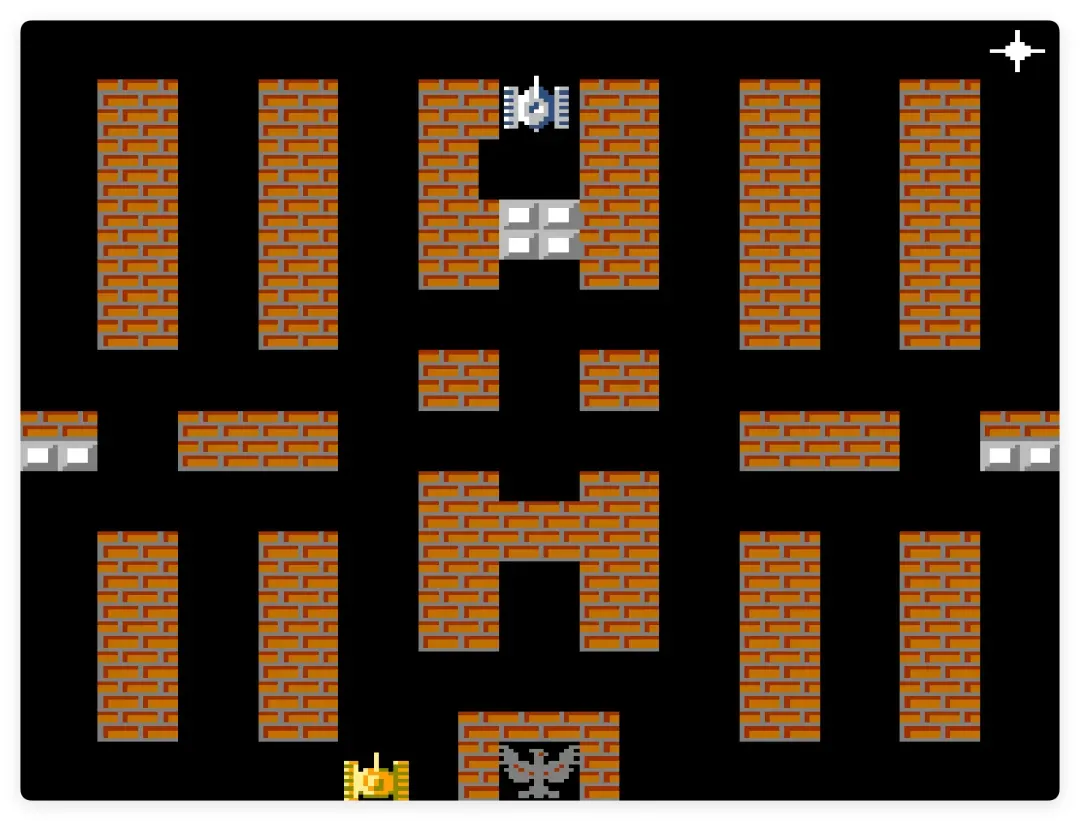
两相比较立刻能看出:地图布局存在差异,更关键的是消墙逻辑也不一致。原版中攻击基地砖墙需要两发子弹才能摧毁一块,而我的 3D 版却是一枪就击碎,导致大本营极易失守,难度无形中提高了一大截。
这两个问题即使不做调整,游戏的乐趣已经足够。但我还是希望再逼自己一把,让复刻更趋完美。于是今天的目标就定为:精准还原第一关地图、修正射击破坏效果,以及额外制作一个地图编辑功能。
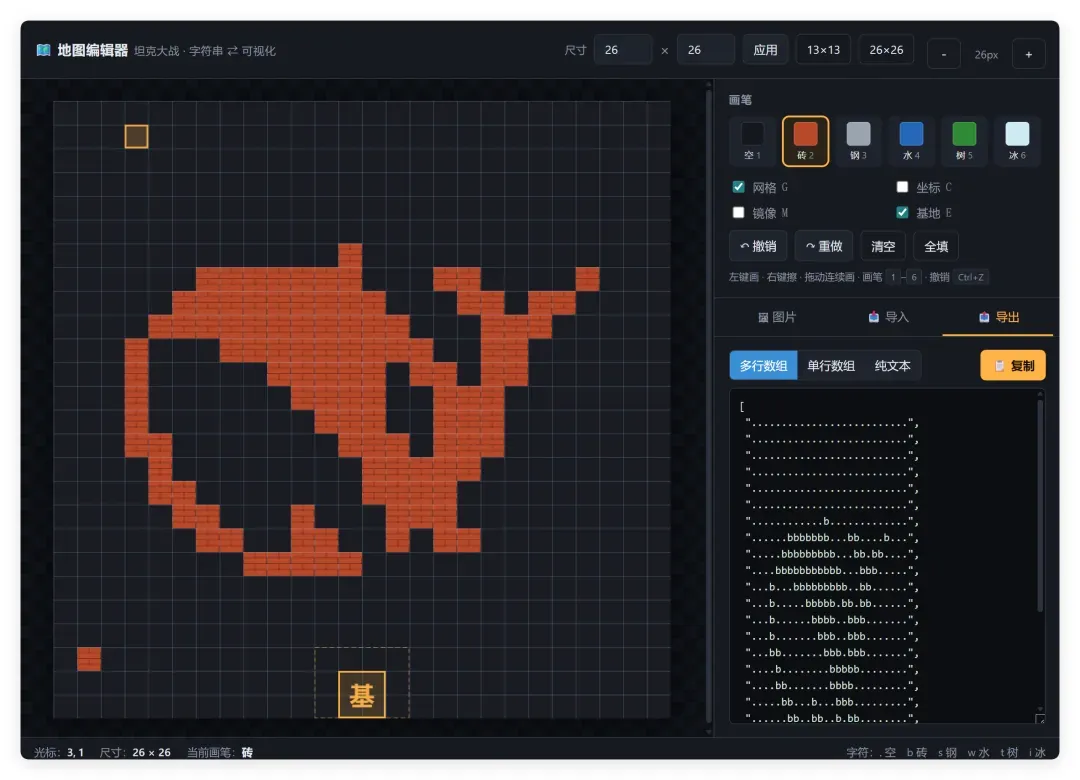
为落地这三大功能,我又投入了整整一天。细节调整最磨人,却也沉淀出大量宝贵的思路与实战经验。游戏成品与体验网址会附在文末,先来回顾修改历程。
一、地图还原:在 26×26 网格上死磕每一个坐标
让 AI 理解我的地图修改需求,是整个过程里最耗神的环节。起初我希望用几句简单描述就完成复原,事实证明这简直难如登天。我先给到一张游戏截图和原版平面图,让 AI 照着还原:

我期望的目标效果大概是这个样子:
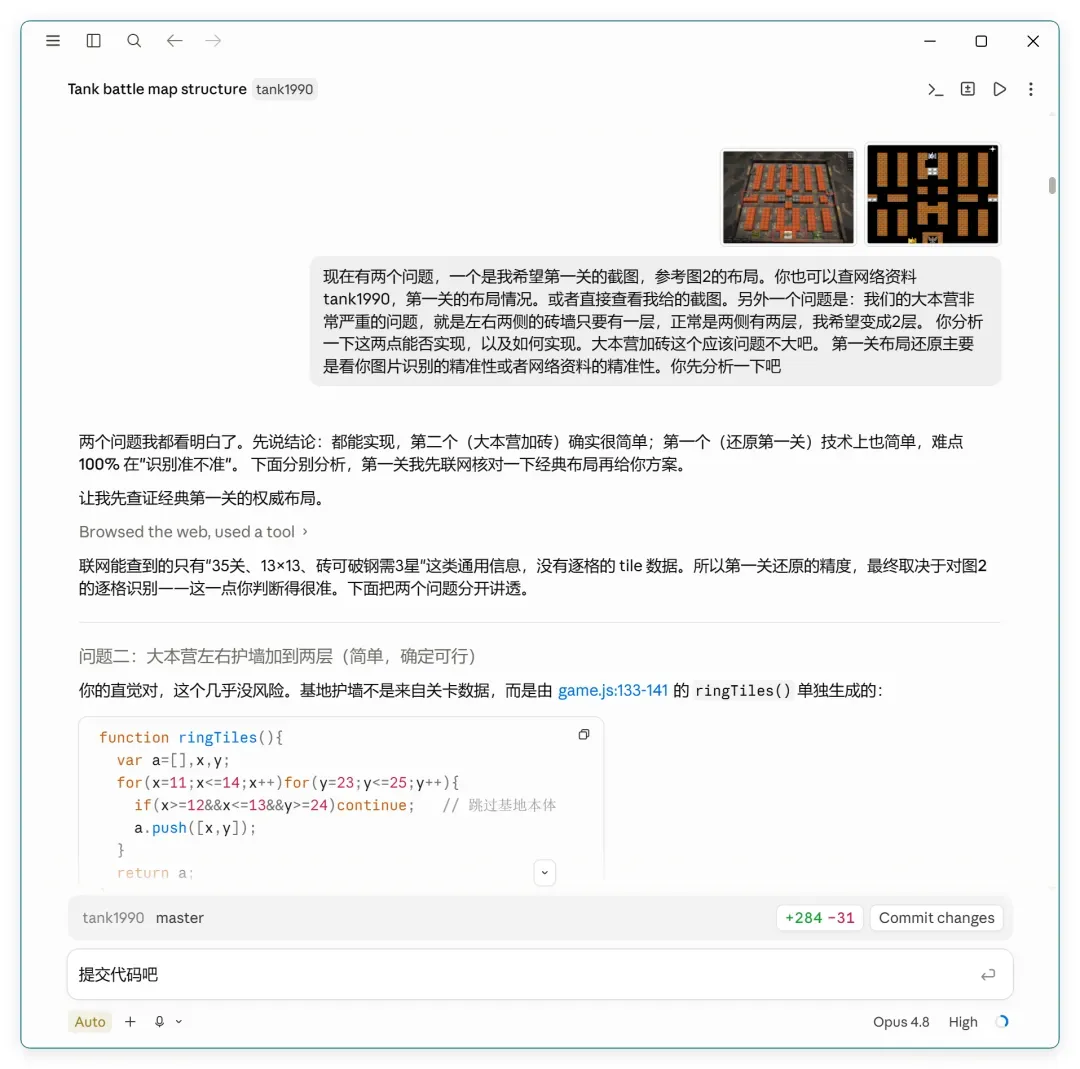
它看上去像是理解了,可实际返回的结果仍然差强人意。

地图的确发生了变化,但细节错漏不少。于是我尝试用画红框的方式一步步标注修改区域,结果不仅没有纠正,反而越改越离谱。平时 Opus 4.8 修改网页能力极强,可面对这张 3D 地图,它就像突然断了弦。折腾中,不知不觉就把 5 个小时的配额跑光了,显然这条路行不通。
好在劳动人民的智慧总能绝处逢生。我转而让它分析地图的底层构成逻辑,发现地图实际上是用一种类似文本网格的形式表达的:
row0 .............
row1 .b.b.b.b.b.b.
row2 .b.b.b.b.b.b.
row3 .b.b.bsb.b.b. ← 中央 2×2 钢,上方留凹槽入口
row4 .b.b.b.b.b.b.
row5 .....b.b..... ← 中央两块孤立小砖
row6 ss.bbb.bbb.ss ← 左右边墙嵌钢 + 中部横墙
row7 .............
row8 .b.b.bbb.b.b. ← 下半柱 + 中央 H 横梁
row9 .b.b.b.b.b.b.
row10 .b.b.b.b.b.b.
row11 ......b...... ← 基地正上方引导墙
row12 ............. ← 基地及护墙由 ringTiles 生成
游戏默认地图是 13×13 的网格,为还原原版中一半钢板、一半砖墙的布局,第一关被升级成了 26×26 的大网格,信息量瞬间膨胀数倍。既然是网格就必有坐标,于是我让 Opus 把全部坐标编号显示在地图上,再依据坐标进行精确修改。
Claude Code + Obsidian:打造自我进化的 AI 知识库,越用越聪明
Karpathy 2026 年 4 月在 GitHub 上分享过一则 gist,标题为《LLM Wiki》。
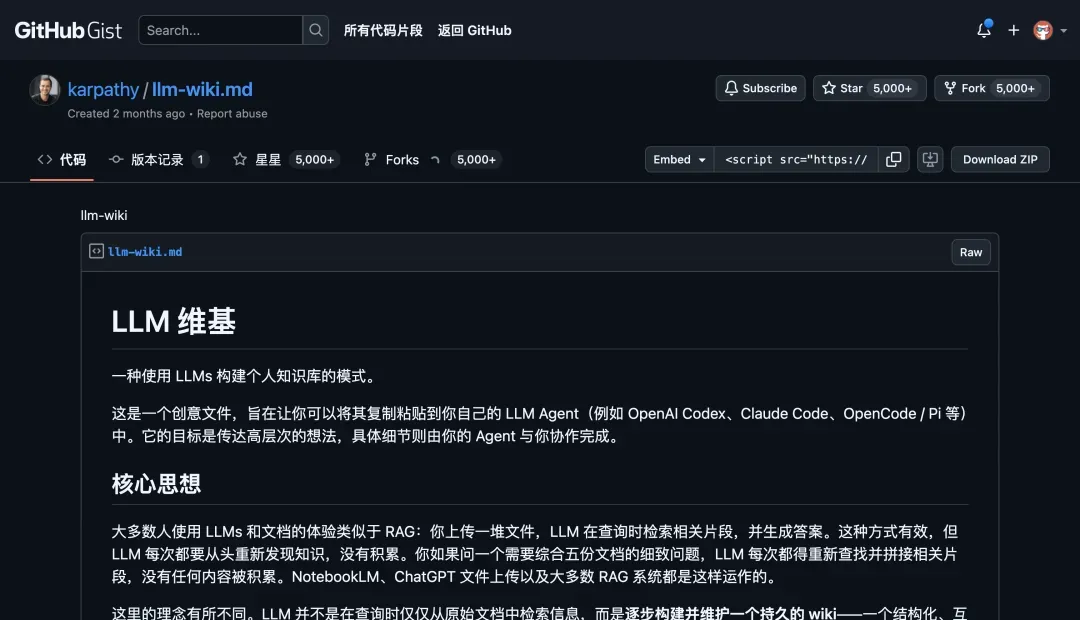
他的核心理念是:理想的知识库应该交给大语言模型自己去阅读、去建立链接、去持续维护。你只需要把资料扔进去,模型会自动将碎片编织成一张互联的知识网。提问时,它直接从这张网络中提取答案,而不是从训练数据里凭空猜测。
这种想法当时引发了大量讨论,我也亲身体验过不少基于该思路的工具。那个 gist 帖子的评论区里就列出了很多方案。
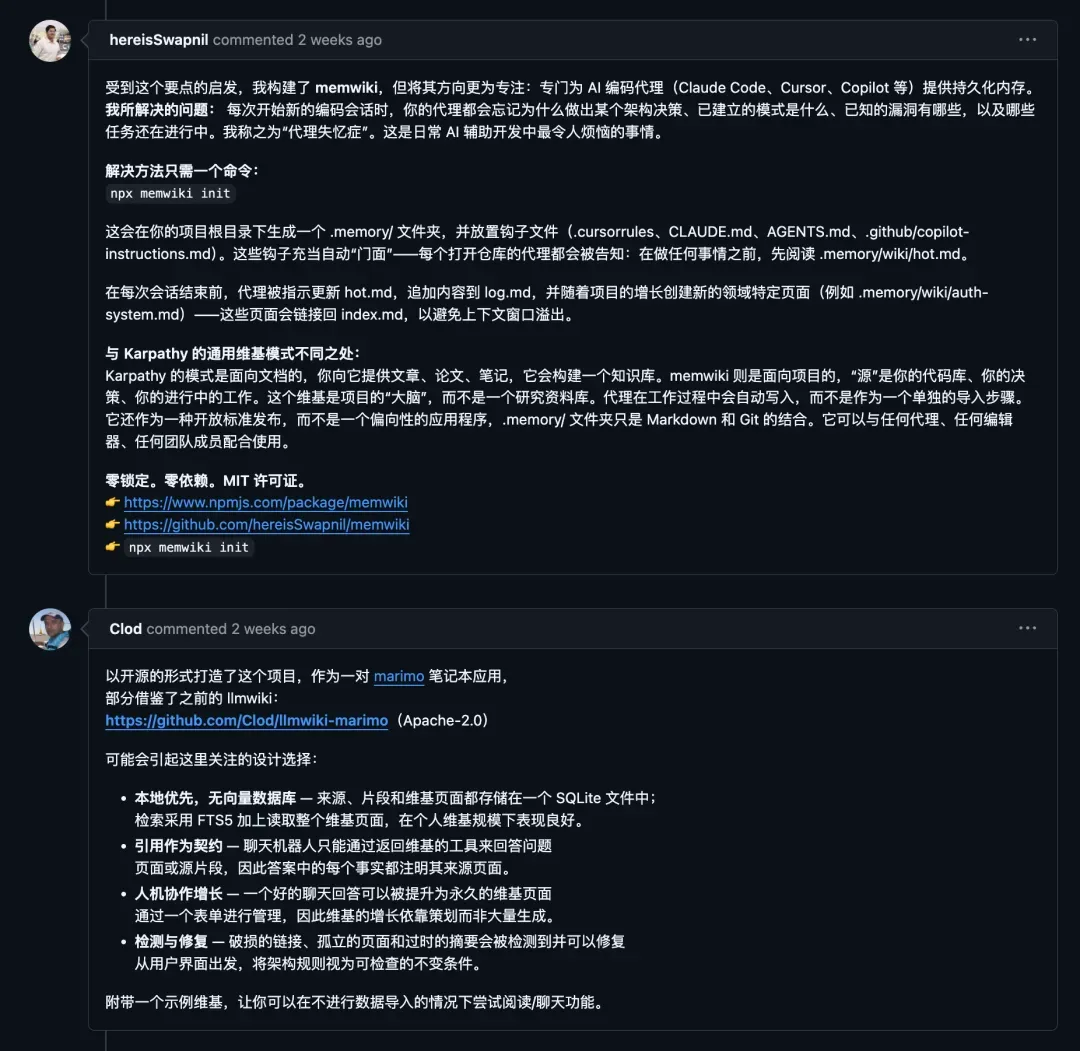
近来我频繁使用的是一个名为 claude-obsidian 的项目,同样是对 Karpathy 理念的一次实践。强烈推荐,目前该项目已收获 7200+ Star。
项目解读:自动整理、监测矛盾的知识引擎
你可以将任何来源的资料——网页、PDF、代码、聊天记录、YouTube 视频笔记——扔进仓库,Claude 会自己去读完、抽取核心概念、建立双向链接,并归档为一套完整的 Markdown 知识图谱。每一次提问,它回答的并非训练数据中的记忆残片,而是它自己阅读、整理过的笔记。

作者反复强调一个词:compounding knowledge,即“知识复利”。每份新资料被纳入后,都会整合进现有的知识网络,让整个库越用越增值,越问越聪明。这种心智模型与常规的 AI 笔记插件完全不同。它继承了 Karpathy 的 LLM Wiki 构想,但 claude-obsidian 更像一部知识引擎。
它会自动整理笔记:为每份输入的资料自动生成实体页(人物、机构、项目)、概念页(理论、模式、方法)和来源页(原始材料),并建立双向交叉引用。
它会进行矛盾检测:能发现笔记中相互冲突的论点,标记出来并附上来源。
它具备会话记忆:每次会话结束前自动更新 hot.md,下次启动时无需重新交代背景。
它还提供 8 类健康检查:把孤儿笔记、死链、过期声明、缺失引用全部列出来。你的知识库会自行保持健康,免去每周手动清理的麻烦。
数据完全自主:全部为本地纯文本 Markdown 文件,无需数据库、云端或订阅费。
快速上手:两种安装方式,三分钟搭建
方式一:
git clone https://github.com/AgriciDaniel/claude-obsidian
cd claude-obsidian
bash bin/setup-vault.sh
然后用 Obsidian 打开该文件夹,再启动 Claude Code 进入同一目录,输入 /wiki,它会引导你逐步完成初始化。setup-vault.sh 会自动配置 graph view 的颜色、过滤规则及 CSS snippet,开箱即用。